I was asked to contribute to 2018 prediction posts on a couple of different sites, along with various other industry pundits. Here’s a summary.
BPM.com: Predictions
 BPM.com published The Year Ahead for BPM – 2018 Predictions from Top Influencers, introduced by BPM.com’s Nathaniel Palmer and featuring mostly people who work for vendors but mostly whose opinions I respect. Many of the vendors’ predictions align with their product direction, either through good planning or happy coincidence.
BPM.com published The Year Ahead for BPM – 2018 Predictions from Top Influencers, introduced by BPM.com’s Nathaniel Palmer and featuring mostly people who work for vendors but mostly whose opinions I respect. Many of the vendors’ predictions align with their product direction, either through good planning or happy coincidence. 
A few ideas that stood out:
Blockchain may be almost ready for its close-up. Miguel Valdés Faura (Bonitasoft) and Setrag Khoshafian (Pega) both mentioned the potential for integrating blockchain with processes using DPA (digital process automation) platforms. I’ve been watching this space for a couple of years, waiting for the connections to be made between BPM and blockchain, and in addition to these mentions in the predictions article, Bernd Ruecker (Camunda) published a post yesterday with a practical use case and MWD Advisors published a report on IBM Blockchain Platform that mentions its integration with IBM BPM.
Automated decisioning, whether DMN-based or AI/ML, is going to improve process automation significantly but there’s still a lot of trepidation. Denis Gagné (Trisotech) said that decision auditability – a legal requirement in some countries – could favor DMN-based decision services over AI/ML, while Roger King (TIBCO) sees AI-based automation as the key to having RPA replace workers. Keith Swenson (Fujitsu) predicts that deep learning will be both the most important and most disappointing innovation in 2018, while Peter Fingar is bullish on intelligent (AI) agents integrated with BPM. James Taylor (Decision Management Solutions) seemed a bit disheartened that DM is being trivialized as a “feature” of BPM rather than an independent stateless service where it can have the greatest impact.
Microservices architectures are replacing monolithic BPM systems. Brian Reale (ProcessMaker) predicts that microservices will disrupt the BPM market this year, and Roger King gave a nod to dynamically-orchestrated process fragments although didn’t explicitly mention microservices. I’m seeing microservices approaches from a few of the BPM vendors, and I agree that this has a lot of potential to shift away from the monolithic (and proprietary) platforms; watch for an article that I wrote for Alfresco on BPM and microservices to be published shortly on their blog.
Low code is allowing business users (analysts, really) to participate in DevOps directly. Malcolm Ross (Appian) sees low code as a catalyst for developer diversity and the blurring of lines between business and IT. Phil Simpson (Red Hat) states that low code and citizen developers are the only way to meet the need for constantly-changing applications. My concern is that, much like how business analysts were going to develop their own BPM applications when model-driven development came around several years ago, this isn’t actually going to happen in such an optimistic fashion.
Customer journey matters. Gero Decker(Signavio) is seeing top-level value chains being replaced by customer journey maps. To me, customer journey mapping feels like a bit of old wine in new bottles, 10 years after outside-in process modeling and other customer-centric views, but whatever it takes to get some traction around modeling process to include the customer and optimize from their point of view. I’m speaking on this topic at next week’s OPEX Week conference.
BPM is no longer BPM. The term is being replaced by digital process automation, digital transformation and a number of others as the platforms expand beyond just process modeling and execution. Neil Ward-Dutton (MWD Advisors) envisions different types of tools vying for the place that BPM platforms occupy now within organizations, from RPA to model-driven application development tools. As I wrote in my section the article, “BPM is dead…long live BPM!”
Lots of great insights in there, check out the entire article on BPM.com.
BPMtips.com: Skills
 Zbigniew Misiak on BPM tips takes a slightly different predictions approach, asking what BPM-related skills and techniques will be most in demand in 2018, where to learn those skills, and what’s no longer relevant in BPM Skills in 2018 – Hot or Not.
Zbigniew Misiak on BPM tips takes a slightly different predictions approach, asking what BPM-related skills and techniques will be most in demand in 2018, where to learn those skills, and what’s no longer relevant in BPM Skills in 2018 – Hot or Not.
Unlike the BPM.com list, which was dominated by vendors, this one has mostly opinions from consultants with some practitioners thrown in. There’s a lot of generic “people need to keep up on the latest technology trends” (duh), but some specific advice stood out:
Process/business architecture to connect processes to value. This ties in with the customer journey mapping trends that we saw in the BPM.com article; here, Roger Burlton (Process Renewal/BPTrends) stresses the importance of including the customer and other external stakeholders in the processes and value definition, and Sandeep Johal (PPB Advisory) reminds us that the focus of process management is (or should be) on improving customer experience via a variety of technologies. Ian Gotts (Q9 Elements) identifies business analysis and critical questioning as key skills, linking to broader business requirements such as GDPR, and Jim Sinur (Aragon) lists journey mapping.
BPMN, CMMN and DMN for standardized modeling. Alan Fish (FICO) sees formal modeling of processes and decisions as important, and Juergen Pitschke (Process Renewal) believes both BPMN and DMN are important, but some say that this is no longer required in low code process application development tools. BJ Biernatowski (Nordstrom) wonders if BPMN has a future, Roger Burlton thinks that process analysts only need to know how to use the core elements, and Sandeep Johal advocates getting rid of manual current-state modeling as automated process discovery, analysis and improvement takes over.
RPA bot training. Abhijit Kakhandiki (Automation Anywhere) suggests this somewhat depressing skill – train the robot to do your job! – but I agree that learning this would help a lot of people create helper functions for their tasks or even completely automate some tasks. Much in the same way that we used to create Excel macros… On a similar note, I recommended that people gathering requirements become proficient with the low code BPM platforms to at least create prototypes, if not the full applications, and Phil Simpson (Red Hat) recommends that less-technical BPM practitioners start to gain an understanding of things that are likely to significantly impact how applications are designed and deployed, such as RPA and microservices.
Interpersonal and soft skills in BPM and change management, in addition to technical skills. Adrian Reed (Blackmetric) listed influencing, stakeholder engagement and conflict resolution as important to making sure that the technology part of the projects fit into the business and people. I discussed some similar skills: the ability to translate need into action, and the need for developers to learn more about what the business does.
Again, lots more to read here, check out the original on BPMtips.com.




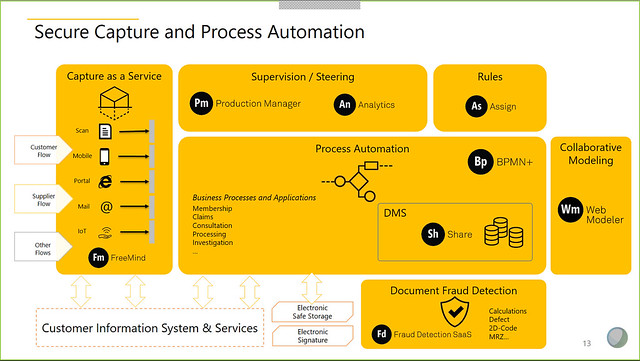


 I had the privilege this year of judging some of the entries for WfMC’s Global Awards for Excellence in BPM and Workflow, and next Tuesday the 12 winners will be announced in a webinar. Tune in to hear the results from
I had the privilege this year of judging some of the entries for WfMC’s Global Awards for Excellence in BPM and Workflow, and next Tuesday the 12 winners will be announced in a webinar. Tune in to hear the results from