I feel like I’m barely back from the academic research BPM conference in Utrecht, and I’m already at Camunda’s annual CamundaCon, being held in New York (Brooklyn, actually) — the first time for the main conference outside of Germany. The location change from Berlin is a bit of a tough call since they will lose some of the European customers who don’t have a budget for international travel, but the opportunity to see their North American customers will make up for it. They’re also running the conference virtually for those of you who can’t be here in person, and you can sign up for free to attend the presentations online.
Although I don’t blog about anything that happens after the bar is open, I did have a couple of interesting conversations at the networking event last night about my relationship with Camunda. I’m here this week as an independent analyst, and although they are covering my travel expenses, I’m not being paid for my time and (as usual) the opinions that I write here are my own. This is the same arrangement I have with any vendor whose conference I attend, although I have got a bit pickier about which locations I’m willing to travel to (hint: not Vegas). I’ve been covering Camunda a long time, starting 10 years ago with their fork from Activiti, back when they didn’t capitalize their name. They’ve been a client of mine in the past for creating white papers, webinars and speaking at their conference. I’ve also worked with some of their clients on technical strategy and architecture, which is the other side of my business.
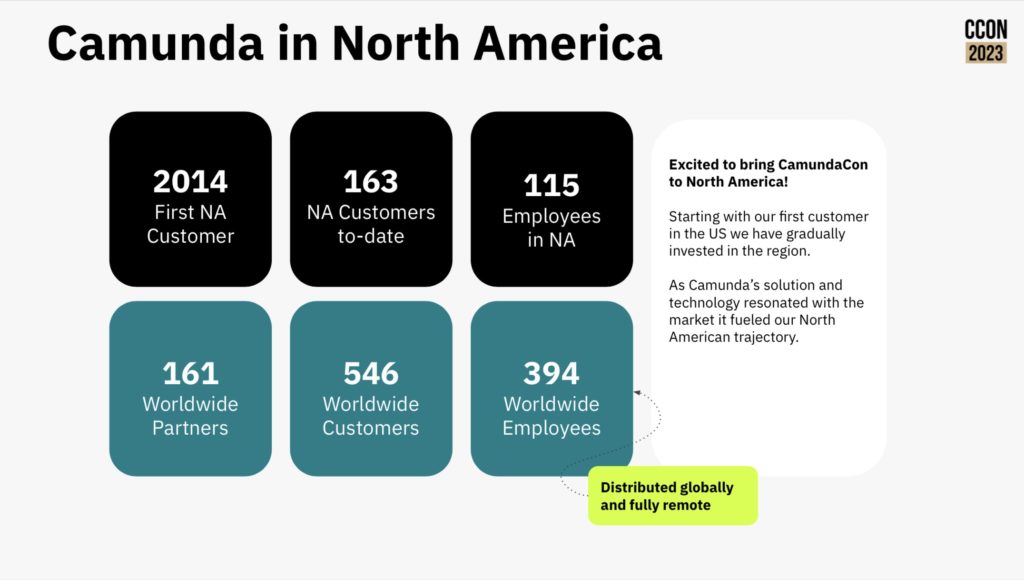
The first day opened with a keynote from Camunda CEO Jakob Freund giving a brief retrospective of the last 10 years of their growth and especially their current presence in North America. There’s over 200 people attending today in person at the 74Wythe event space, plus an online contingent of attendees. He started with a vision of the automated enterprise, and how this is made difficult by the complexity of mission-critical processes that cross multiple silos of systems and organizational departments. Process orchestration allows for automation of the end-to-end processes by acting a a controller that can invoke the right resource — whether a person or a system — at the right time while maintaining end-to-end visibility and management. If you’re not embracing process orchestration, you run the risk of having broken processes that have a significant impact on your customer satisfaction, efficiency and innovation.
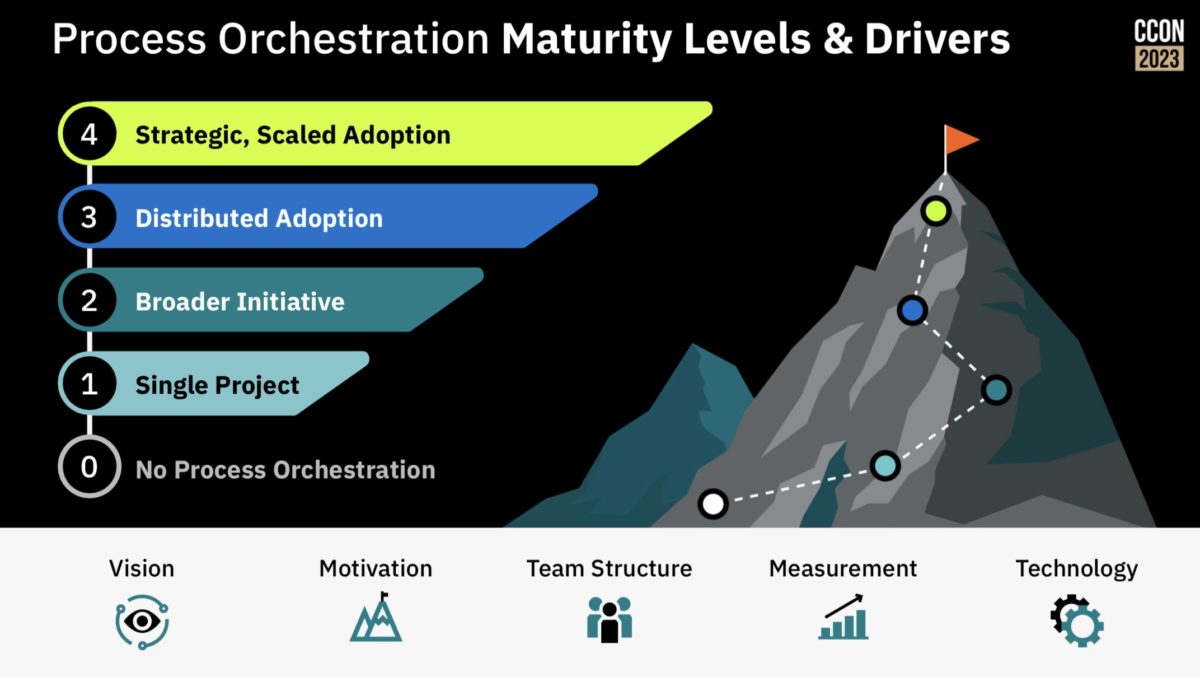
Camunda has more than 500 customers globally now, and has amassed over 5000 use cases for how those organizations are using Camunda’s software. This has allowed them to develop a process orchestration maturity model: from single projects, to broader initiatives, to distributed adoption, to a strategic scaled adoption of process orchestration. Although obviously Jakob sees the Camunda Process Orchestration Platform as a foundational platform, he looked at a number of other non-technical components such as stakeholder buy-in, plus technical add-ons and integration partners. I like that he started with strategic alignment and ended with value monitoring wrapping back to the alignment; this type of alignment between strategic goals and operational metrics is something that I strongly believe in and have written about quite a bit.
Since we’re in New York, his process orchestration in action part was focused on financial services, although with lessons for many other industries. I work a lot with my own financial services clients, and the challenges listed are very familiar. He walked through case studies of Desjardins (legacy BPMS replacement), Truist (merging systems from two merged banks), National Bank of Canada (automation CoE to radically reduce project development time), and NatWest (CoE to aid self-service projects).
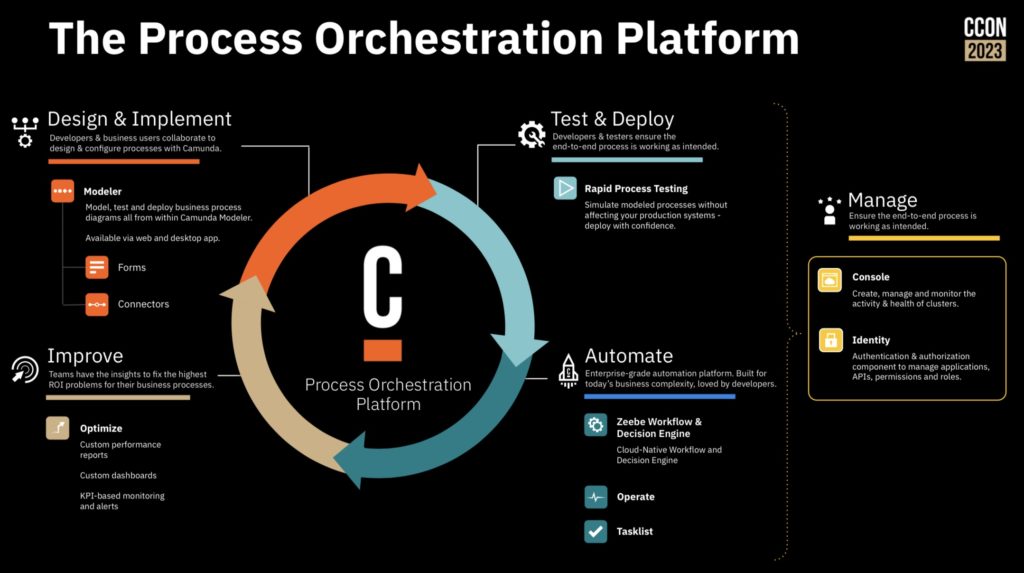
He moved on to talk about the innovation that Camunda is introducing through their technology. They now address more of the BPM lifecycle than they started out with — which was purely as a developer tool — and now provide more tools for business and IT to collaborate on process improvement/automation projects. They are also addressing the accelerating of solutions through some low-code aspects; this was a necessary move for them in the face of the current market. Their challenge will be keeping the low code tooling from getting in the way of the developers, and keeping the technical details from getting in the way of the business people.
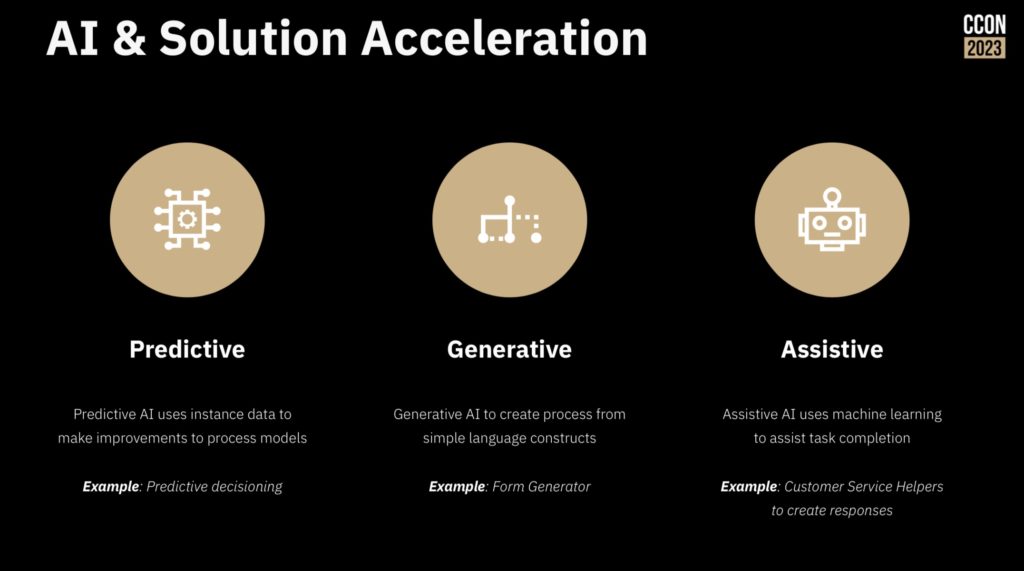
No technical conference today is complete without at least one slide on AI, and Jakob did not disappoint. He walked through how they see AI as it applies to process orchestration: predictive AI (e.g., process mining and decisioning), generative AI (e.g., form generator from simple language), and assistive AI (e.g., knowledge worker helper).
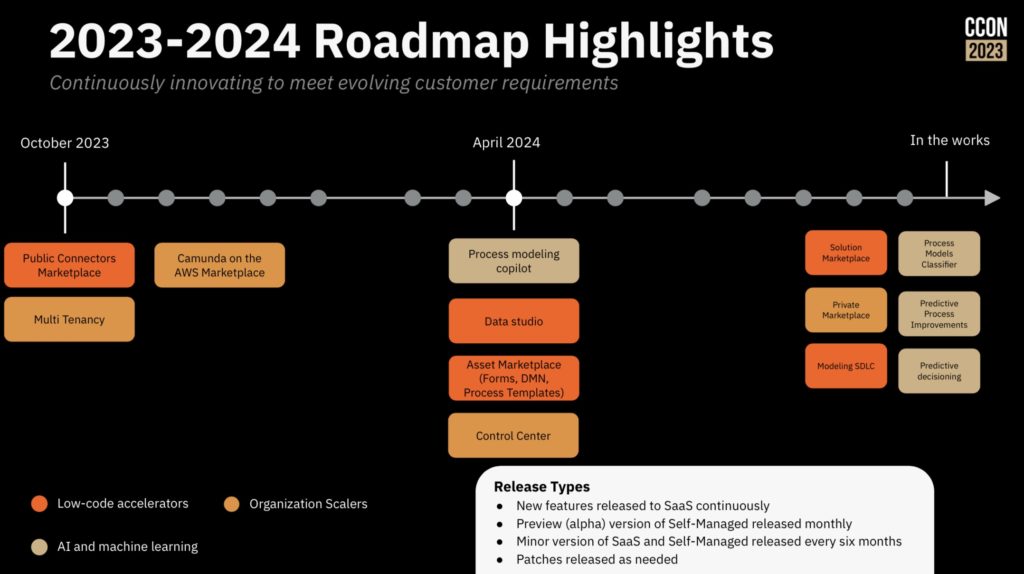
He described their connectors marketplace, which includes connectors created by them but also curated from their partners. Connectors are essential for integration, but their roadmap also includes process templates, internal marketplaces within an organization, and entire industry solutions and applications. This is an ambitious undertaking that a lot of vendors have done badly, and I’ll be very interested in seeing how this develops.
He finished up with some larger architecture issues: cloud support, security and compliance, multi-tenancy and how this allows them to support organizations both big and small. Their roadmap shows a lot of components that are targeted at broadening their reach while still supporting their long-term technical customers.
Flowable is holding their half-day online FlowFest today, and in spite of the eye-wateringly early start here in North America, I’ve tuned in to watch some of the sessions. All of these will be available on demand after the conference, so you can watch the sessions even if you miss them live.
There are three tracks — technical, architecture and business — and I started the day in the tech stream watching co-founder Tijs Rademakers‘ presentation on what’s new in Flowable. He spent quite a bit of the hour on a technical backgrounder, but did cover some of the new features: deprecation of Angular, new React Flow replacing the Oryx modelers, a new form editor, improved deployment options and cloud support, a managed service solution, and a quick-start migration path that includes an automatic migration of Camunda 7 process instance database to Flowable (for those companies that don’t want to make the jump to Camunda 8 and are concerned about the long-term future of V7).
For the second session, I switched over to the architect stream for Roman Saratz’ presentation on low-code integration with data objects. He showed some cool stuff where changes to the data in an external data object would update a case, in the example tied to a Microsoft Dynamics instance. The presentation was relatively short and there was an extended Q&A, obviously a lot of people interested in this form of integration. At the end, I checked in on the business track and realized that the sessions there were not time-aligned with the two technical tracks: they were already well into the Bosch session that was third on the agenda – not sure why the organizers thought that people couldn’t be interested in technology AND business.
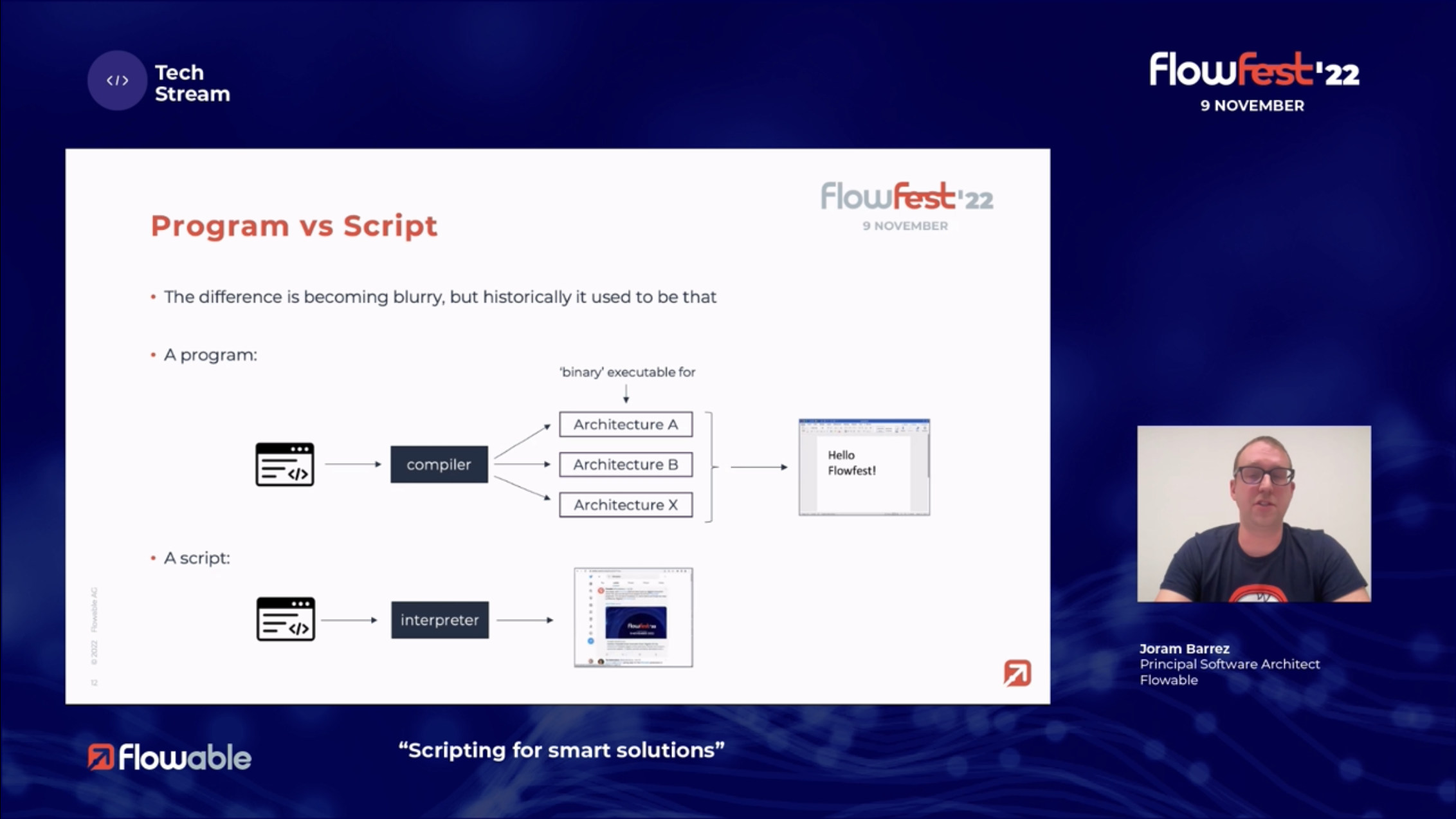
In the third session, I went back to the tech stream and attended Joram Barrez‘ presentation on scripting. Like a few of the other Flowable team, Joram came from Alfresco’s Activiti core development team (and jBPM before that), and is now Principal Software Architect. He looked at the historical difference between programs and scripts, which is that programs are compiled and scripts are interpreted, and the current place of pre-compiled [Java] delegates in service tasks versus script tasks that are interpreted at runtime. In short, the creation, compilation and deployment of Java delegates are definitely the responsibility of technical developers, while scripts can be created and maintained by less-technical low code developers. Flowable now allows for the creation a “service registry” task that is actually a Javascript or Groovy script rather than a REST call, which allows scripts to be reusable across models as if they were external service tasks rather than embedded within one specific process or case model. There are, of course, tradeoffs. Pre-compiled delegates typically have higher performance, and provide more of a structured development experience such as unit testing, and backwards-compatible API agreements. Scripts open up more development capability to the model developer who may not be Java-savvy. Flowable has created some API constructs that make scripts more capable and less brittle, including REST service request/response processing and BPMN error handling. It appears that they are shifting the threshold for what’s being done by a low code developer directly in their modeling environment, versus what requires a more technical Java developer, an external IDE and a more complex deployment path: making scripts first-class citizens in Flowable applications. In fat, Joram talked about ideas (not yet in the product) such as having a more robust scripting IDE embedded directly in their product. I am reminded of companies like Trisotech that are using FEEL as their scripting language in BPMN-CMMN-DMN applications, on the assumption that if you’re already using FEEL in DMN then using it throughout your application is a good idea; I asked if Flowable is considering this, and Joram said that it’s not currently supported but it would not be that difficult to add if there was demand for it.
To wrap up the conference, I attend Paul Holmes-Higgin‘s architecture talk on Flowable future plans. Paul is co-founder of Flowable and Chief Product Officer. He started with a discussion of what they’re doing in Flowable Design, which is the modeling and design environment. Tijs spoke about some of this earlier, but Paul dug into more detail of what they’ve done in the completely rebuilt Design tool that will be released in early 2023. Both the technical underpinnings and the visuals have changed, to update to newer technology and to support a broader range of developer types from pro code to low code. He also spoke about longer term (2-3 year) innovation plans, starting with a statement of the reality that end-to-end processes don’t all happen within a centralized monolithic orchestrated system. Instead, they are made up of what he refers to as “process chains”, which is more of a choreography of different systems, services and organizations. He used a great example of a vehicle insurance claim that uses multiple technology platforms and crosses several organizational boundaries: Flowable Work may only handle a portion of those, with micro-engines on mobile devices and serverless cloud services for some capabilities. They’re working on Flowable Jet, a pared-down BPMN-CMMN-DMN micro-engine for edge automation that will run natively on mobile, desktop or cloud. This would change the previous insurance use case to put Flowable Jet on the mobile and cloud platforms to integrate directly with Flowable Work inside organizations. With the new desktop RPA capabilities in Windows 11, Flowable Jet could also integrate with that as a bridge to Flowable Work. This is pretty significant, since currently end-to-end automation has a lot of variability around the edges; allowing for their own tooling in the edge as well as central automation could provide better visibility and security throughout.
Tijs, Jorram and Paul are all open source advocates in spite of Flowable’s current more prominent commercial side; I’m hoping to see them shifting some of their online conversations over to the Fosstodon (or some other Mastodon instance), where I have started posting.
That’s it for FlowFest: a good set of informational sessions, and some that I missed due to multiple concurrent tracks that I’ll go back and watch later.
My little foldable keyboard isn’t playing nice, so I’m typing this directly on my iPad which is…not ideal. However, I will do my best and debug the keyboard later.
Day 2 of CamundaCon 2022 here in Berlin started off with a keynote from Bernd Ruecker, Camunda co-founder and chief technologist, and Daniel Meyer, CTO. Version 8.1 is coming up, and with it some new connectors as well as other core enhancements. Bernd started out with a reinforcement of some of Jakob Freund’s messages yesterday: the distinction between task (depth) and process (breadth) automation, and how process orchestration is characterized by endpoint diversity and process complexity. These are important points in understanding the scope of process orchestration, but also for companies like Camunda to distinguish themselves in an increasingly diverse and crowded “process automation” market.
Once Bernd had walked us through what an initial process orchestration could look like (for a bank account opening example), Daniel took over to take about moving from an initial project to a transformed, process-centric enterprise. Some of this requires tools that allow less technical developers to get involved, which means having more connectors available for these developers to create apps by assembling and configuring connectors, while more technical developers may be creating new connectors for what’s not offered out of the box by Camunda. Bernd, who loves his live demos, showed us how to create a new connector quickly in Java, then expose it graphically in the modeler using a connector template – this makes it appears as an activity type directly in the Camunda modeler. Once they are in the modeler, connectors can be used in any application, so that (for example) a connector to your bespoke mainframe monolith can be created and added to the modeler once, then used in a variety of applications.
The concept of connectors as a way for less technical developers to use a BPMN model as an application development framework isn’t new: many other BPMS vendors have been doing this for a long time. Camunda is obviously feeling the pressure to move from a purely developer-focused platform and address some level of low-code needs, and connectors is one if the main ways that they are doing this. The ease in creating new connectors is pretty cool – many products let you use their out of the box connectors but don’t make it that easy to make new ones. Camunda is positioning this capability (creating new connectors quickly) as core to automating the enterprise.
We heard about more of what they’ve been releasing this year, including the web modeler that allows new developers and business analysts to be onboarded quickly without having to install anything locally. The modeler includes BPMN validation so that correct process models are created and errors avoided before deploying to the server. They are also using FEEL (friendly enough expression language) – borrowed from the DMN specification – for scripting within tasks. This use of FEEL is also being done by other standards-focused vendors, such as Trisotech. We also saw some of the things that they’re working on, such as interactive debugging to step through processes, and an improved forms UI builder. Again, not completely new ideas in the BPM space, but nice productivity enhancements to their developer experience. Based on what they’ve seen within their own company, they’re integrating Slack and Microsoft Teams for human task orchestration to avoid the requirement for users to go to a separate app for their process task list.
Bernd addressed the issue of Camunda supporting low code, when they have been staunchly pro code only for most of their history. Fundamentally, the market (that is, their customers and prospective customers) need this capability, and it’s clear that you have to offer at least something low code (ish) to play in the process automation space these days. This is definitely a shift for them, and they are doing it fairly gracefully although are a bit behind the curve in much of the functionality because they stuck to their roots for so long. In their favour, they’re still a small and nimble company and can roll out this type of functionality in their product fairly quickly. They are mostly just dipping into the pro code end of the low code space, and it will be interesting to see how far they go in upcoming releases. Creating more low code tooling and more connectors obviously creates more long-term technical debt for Camunda: if they decide this isn’t the way forward after a while, or they change some of the underlying architecture, customers could end up with legacy versions of connectors and low code tooling that need to be updated. Definitely worth checking out for existing Camunda customers who want to accelerate adoption within their organizations.
By the way, I’ve had so much great feedback on our panel yesterday: happy to hear that we had some nuggets of wisdom in there. So many good conversations last night at the BBQ and continuing into today between sessions. I’ll post a link to the recorded session when it’s published.
I realize that I’m completely remiss for not posting about last week’s DecisionCAMP, but in my defense, I was co-hosting it and acting as “master of ceremonies”, so was a bit busy. This was the third year for a virtual DecisionCAMP, with a plan to be back in person next year, in Oslo. And speaking of in-person conferences, I’m in Berlin! Yay! I dipped my toe back into travel three weeks ago by speaking at Hyland’s CommunityLive conference in Nashville, and this week I’m on a panel at Camunda’s annual conference. I’ve been in Berlin for this conference several times in the past, from the days when they held the Community Day event in their office by just pushing back all the desks. Great to be back and hear about some of their successes since that time.
Day 1 started with an opening keynote by Jakob Freund, Camunda’s CEO. This is a live/online hybrid conference, and considering that Camunda did one of the first successful online conferences back in 2020 by keeping it live and real, this is shaping up to be a forerunner in the hybrid format, too. A lot of companies need to learn to do this, since many people aren’t getting back on a plane any time soon to go to a conference when it can be done online just as well.
Anyway, back to the keynote. Camunda just published the Process Orchestration Handbook, which is a marketing piece that distills some of the current messaging around process automation, and highlights some of the themes from Jakob’s keynote. He points out the problems with a lot of current process automation: there’s no end-to-end automation, no visibility into the overall process, and little flexibility to rework those processes as business conditions change. As a result, a lot of process automation breaks since it falls over whenever there’s a problem outside the scope of the automation of a specific set of tasks.
Jakob focused on a couple of things that make process orchestration powerful as a part of business automation: endpoint diversity (being able to connect a lot of different types of tasks into an integrated process) and process complexity (being able to include dynamic parallel execution, event-driven message correlation, and time-based escalation). These sound pretty straightforward, and for those of us who have been in process automation for a long time these are accepted characteristics of BPMN-based processes, but these are not the norm in a lot of process orchestration.
He also walked through the complexities that arise due to long-running processes, that is, anything that involves manual steps with knowledge workers: not the same as straight-through API-only process orchestration that doesn’t have to worry about state persistence. There are a few good customer stories here this week that bring all of these things together, and I plan to be attending some of those sessions.
He presented a view of the process automation market: BPMS, low-code platforms, process mining, iPaaS/integration, RPA, microservices orchestration, and process orchestration. Camunda doesn’t position itself in BPMS any more – mostly since the big analysts have abandoned this term – but in the process orchestration space. Looking at the intersection between the themes of endpoint diversity and process complexity that he talked about earlier, you can see where different tools end up. He even gives a nod to Gartner’s hyperautomation term and how process orchestration fits into the tech stack.
He finished up with a bit of Camunda’s product vision. They released V8 this year with the Zeebe engine, but much more than that is under development. More low-code especially around modeling and front-end human task technology, to enable less technical developers. Decision automation tied into process orchestration. And stronger coverage of AI, process mining and other parts of the hyperautomation tech stack through partnerships as well as their own product development.
Definitely some shift in the messaging going on here, and in some of Camunda’s direction. A big chunk of their development is going into supporting low-code and other “non-developer” personas, which they resisted for many years. They have a crossover point for pro-code developers to create connectors that are then used by low-code developers to assemble into process orchestrations – a collaboration that has been recognized by larger vendors for some time. Sensible plans and lots of cool new technology.
The rest of the day is pretty packed, and I’m having trouble deciding which sessions to attend since there are several concurrent that all sound interesting. Since most of them are also virtual for remote attendees, I assume the recordings will be available later and I can catch up on what I missed. It’s not too late to sign up to attend the rest of today and tomorrow virtually, or to see the recorded sessions after the fact.
I recently created a paper for Flowable on end-to-end automation, including a look at how the Gartner “hyperautomation” term fits into the picture. End-to-end automation is really about enabling business model transformation, not just making the same widgets a little bit faster, and I walk through some of the steps and technologies that are required.
Check it out on the Flowable site at the link above (registration required).
I had a quick briefing with Daniel Meyer, CTO of Camunda, about today’s release. With this new version 7.15, they are rebranding from Camunda BPM to Camunda Platform (although most customers just refer to the product as “Camunda” since they really bundle everything in one package). This follows the lead of other vendors who have distanced themselves from the BPM (business process management) moniker, in part because what the platforms do is more than just process management, and in part because BPM is starting to be considered an outdated term. We’ve seen the analysts struggle with naming the space, or even defining it in the same way, with terms like “digital process automation”, “hyperautomation” and “digitalization” being bandied about.
An interesting pivot for Camunda in this release is their new support for low-code developers — which they distinguish as having a more technical background than citizen developers — after years of primarily serving the needs of professional technical (“pro-code”) developers. The environment for pro-code developers won’t change, but now it will be possible for more collaboration between low-code and pro-code developers within the platform with a number of new features:
Create a catalog of reusable workers (integrations) and RPA bots that can be integrated into process models using templates. This allows pro-code developers to create the reusable components, while low-code developers consume those components by adding them to process models for execution. RPA integration is driving some amount of this need for collaboration, since low-code developers are usually the ones on the front-end of RPA initiatives in terms of determining and training bot functionality, but previously may have had more difficult integrating those into process orchestrations. Camunda is extending their RPA Bridge to add Automation Anywhere integration to their existing UIPath integration, which gives them coverage of a significant portion of the RPA market. I covered a bit of their RPA Bridge architecture and their overall view on RPA in one of my posts from their October 2020 CamundaCon. I expect that we will soon see Blue Prism integration to round out the main commercial RPA products, and possibly an open source alternative to appeal to their community customers.
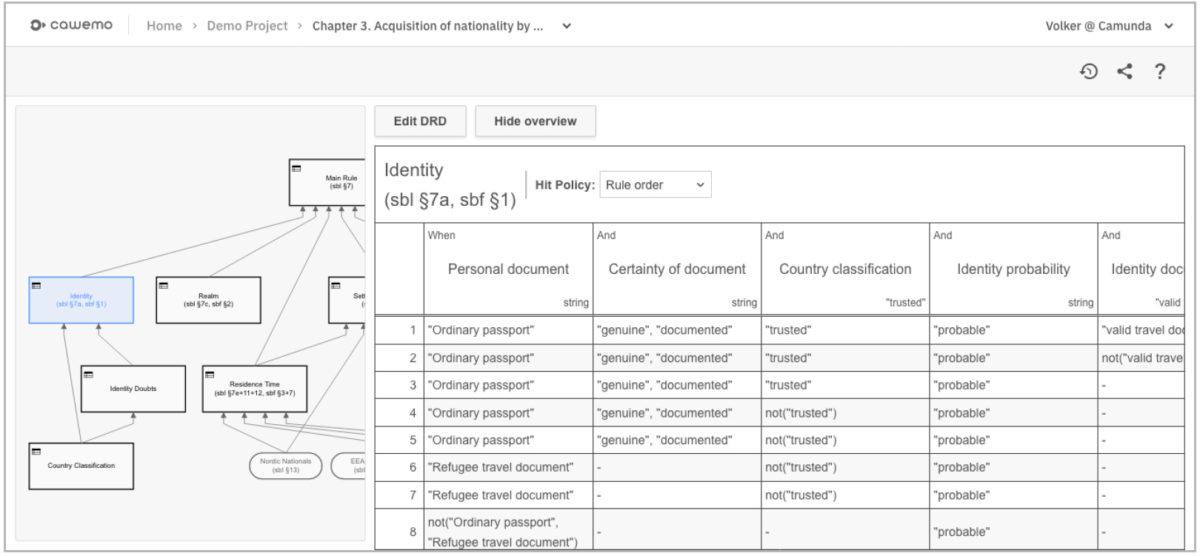
DMN support, including DRD and decision tables, in their Cawemo collaborative modeler. This is a good way to get the citizen developers and business analysts involved in modeling decisions as well as processes.
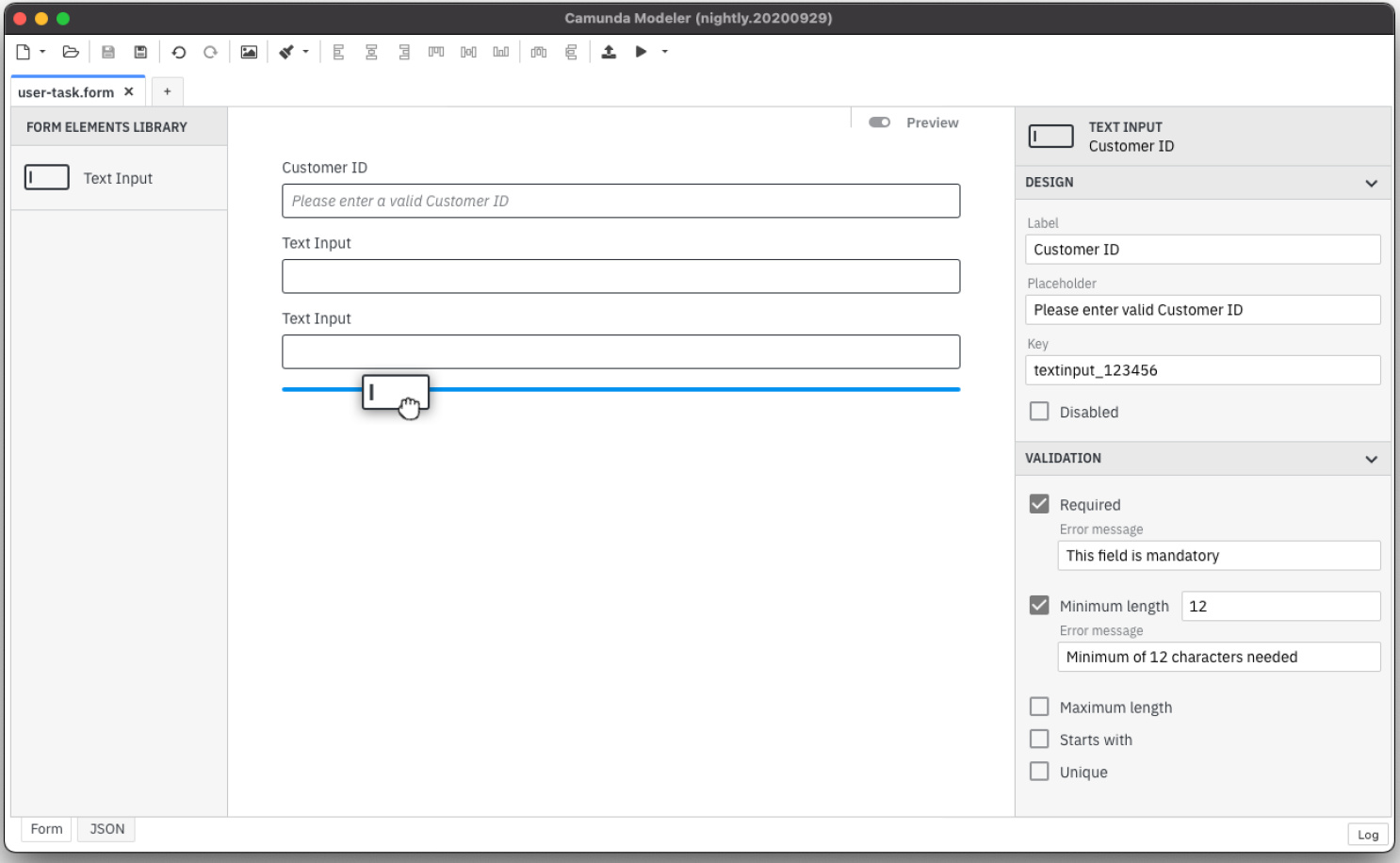
A form builder. Now, I’m pretty sure I’ve heard Jakob Freund claim that they would never do this, but there it is: a graphical form designer for creating a rudimentary UI without writing code. This is just a preliminary release, only supporting text input fields, so isn’t going to win any UI design awards. However, it’s available in the open source and commercial versions as well as accessible as a library in bpmn.io, and will allow a low-code developer to do end-to-end development: create process and decision models, and create reusable “starter” UIs for attaching to start events and user activities. When this form builder gets a bit more robust in the next version, it may be a decent operational prototyping tool, and possibly even make it into production for some simple situations.
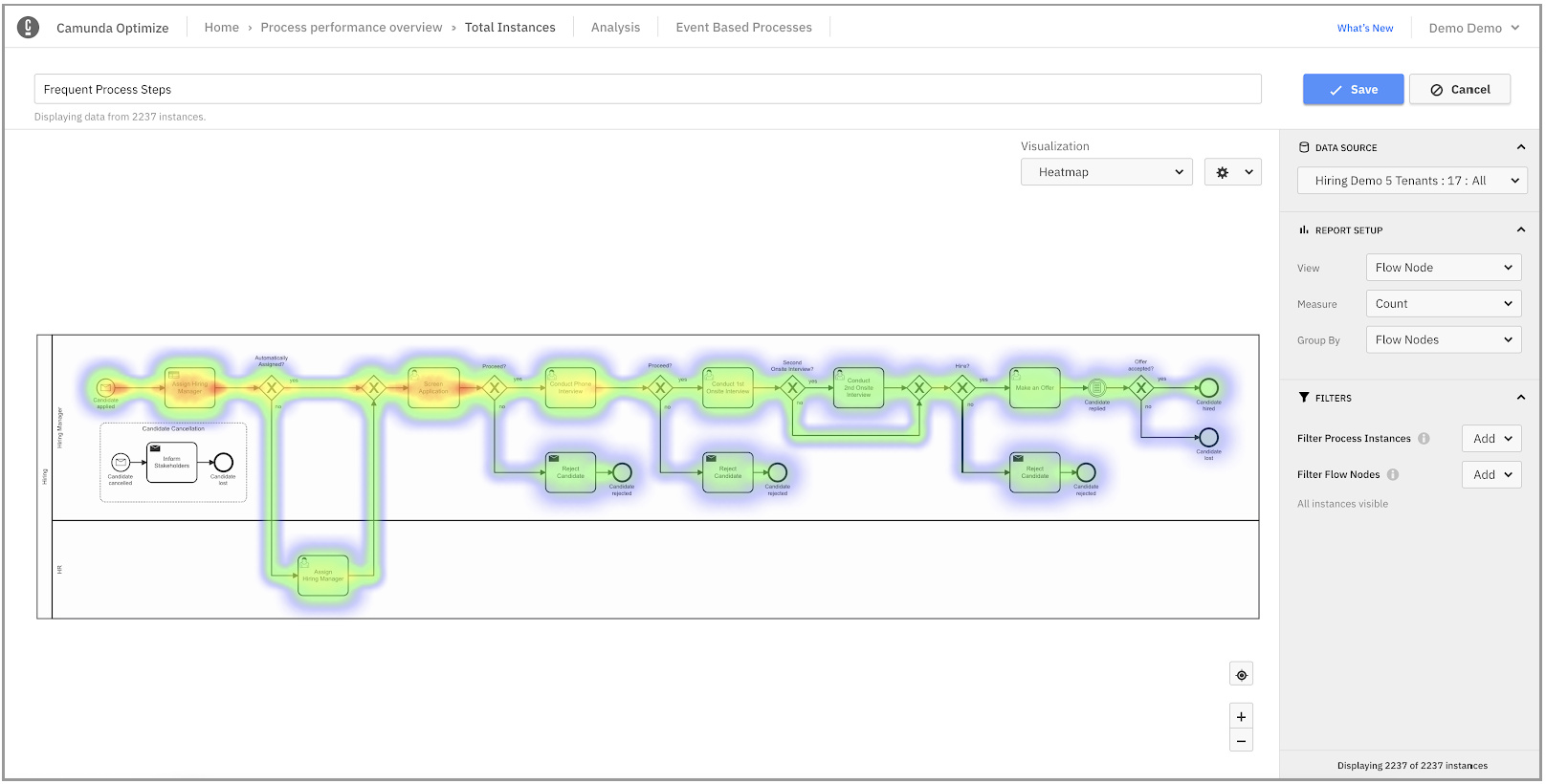
They’ve also added some nice enhancements to Optimize, their monitoring and analytics tool, and have bundled it into the core commercial product. Optimize was first released mid-2017 and is now used by about half of their customers. Basically, it pumps the operational data exhaust out of the BPM engine database and into an elastic search environment; with the advent of Optimize 3.0 last year, they could also collect tracking events from other (non-Camunda) systems into the same environment, allowing end-to-end processes to be tracked across multiple systems. The new version of Optimize, now part of Camunda Platform 7.15, adds some new visualizations and filtering for problem identification and tracking.
Overall, there’s some important things in this release, although it might appear to be just a collection of capabilities that many of the all-in-one low-code platforms have had all along. It’s not really in Camunda’s DNA to become a proprietary all-in-one application development platform like Appian or IBM BPM, or even make low-code a primary target, since they have a robust customer base of technical developers. However, these new capabilities create an important bridge between low-code developers who have a better understanding of the business needs, and pro-code developers with the technical chops to create robust systems. It also provides a base for Camunda customers who want to build their own low-code environment for internal application development: a reasonably common scenario in large companies that just can’t fit their development needs into a proprietary application development platform.
The last time that I was on a plane was mid-February, when I attended the OpenText analyst summit in Boston. For people even paying attention to the virus that was sweeping through China and spreading to other Asian countries, it seemed like a faraway problem that wasn’t going to impact us. How wrong we were. Eight months later, many businesses have completely changed their products, their markets and their workforce, much of this with the aid of technology that automates processes and supply chains, and enables remote work.
By early April, OpenText had already moved their European regional conference online, and this week, I’m attending the virtual version of their annual OpenText World conference, in a completely different world than in February. Similar to many other vendors that I cover (and have attended virtual conferences for in the past several months), OpenText’s broad portfolio of enterprise automation products has the opportunity to make gains during this time. The conference opened with a keynote from CEO Mark Barrenechea, “Time to Rethink Business”, highlighting that we are undergoing a fundamental technological (and societal) disruption, and small adjustments to how businesses work aren’t going to cut it. Instead of the overused term “new normal”, Barrenechea spoke about “new equilibrium”: how our business models and work methods are achieving a stable state that is fundamentally different than what it was prior to 2020. I’ve presented about a lot of these same issues, but I really like his equilibrium analogy with the idea that the landscape has changed, and our ball has rolled downhill to a new location.
He announced OpenText Cloud Edition (CE) 20.4, which includes five domain-oriented cloud platforms focused on content, business network, experience, security and development. All of these are based on the same basic platform and architecture, allowing them to updated on a quarterly basis.
The Content Cloud provides the single source of truth across the organization (via information federation), enables collaboration, automates processes and provides information governance and security.
The Business Network Cloud deals directly with the management and automation of supply chains, which has increased in importance exponentially in these past several months of supply chain disruption. OpenText has used this time to expand the platform in terms of partners, API integrations and other capabilities. Although this is not my usual area of interest, it’s impossible to ignore the role of platforms such as the Business Network Cloud in making end-to-end processes more agile and resilient.
The Experience Cloud is their customer communications platform, including omnichannel customer engagement tools and AI-driven insights.
The Security and Protection Cloud provides a collection of security-related capabilities, from backup to endpoint protection to digital forensics. This is another product class that has become incredibly important with so many organizations shifting to work from home, since protecting information and transactions is critical regardless of where the worker happens to be working.
The Developer Cloud is a new bundling/labelling of their software development (including low-code) tools and APIs, with 32 services across eight groupings including capture, storage, analysis, automation, search, integration, communicate and security. The OpenText products that I’ve covered in the past mostly live here: process automation, low-code application development, and case management.
Barrenechea finished with their Voyager program, which appears to be an enthusiastic rebranding of their training programs.
Next up was a prerecorded AppWorks strategy and roadmap with Nic Carter and Nick King from OpenText product management. It was fortunate that this was prerecorded (as much as I feel it decreases the energy of the presentation and doesn’t allow for live Q&A) since the keynote ran overtime, and the AppWorks session could be started when I was ready. Which begs the question why it was “scheduled” to start at a specific time. I do like the fact that OpenText puts the presentation slides in the broadcast platform with the session, so if I miss something it’s easy to skip back a slide or two on my local copy.
Process Suite (based on the Cordys-heritage product) was rolled into the AppWorks branding starting in 2018, and the platform and UI consolidated with the low-code environment between then and now. The sweet spot for their low-code process-centric applications is around case management, such as service requests, although the process engine is capable of supporting a wide range of application styles and developer skill levels.
They walked through a number of developer and end-user feature enhancements in the 20.4 version, then covered new automation features. This includes enhanced content and Brava viewer integration, but more significantly, their RPA service. They’re not creating/acquiring their own RPA tool, or just focusing on one tool, but have created a service that enables connectors to any RPA product. Their first connector is for UiPath and they have more on the roadmap — very similar rollout to what we saw at CamundaCon and Bizagi Catalyst a few weeks ago. By release 21.2 (mid-2021), they will have an open source RPA connector so that anyone can build a connector to their RPA of choice if it’s not provided directly by OpenText.
There are some AppWorks demos and discussion later, but they’re in the “Demos On Demand” category so I’m not sure if they’re live or “live”.
I checked out the content service keynote with Stephen Ludlow, SVP of product management; there’s a lot of overlap between their content, process, AI and appdev messages, so important to see how they approach it from all directions. His message is that content and process are tightly linked in terms of their business usage (even if on different systems), and business users should be able to see content in the context of business processes. They integrate with and complement a number of mainstream platforms, including Microsoft Office/Teams, SAP, Salesforce and SuccessFactors. They provide digital signature capabilities, allowing an external party to digitally sign a document that is stored in an OpenText content server.
An interesting industry event that was not discussed was the recent acquisition of Alfresco by Hyland. Alfresco bragged about the Documentum customers that they were moving onto Alfresco on AWS, and now OpenText may be trying to reclaim some of that market by offering support services for Alfresco customers and provide an OpenText-branded version of Alfresco Community Edition, unfortunately via a private fork. In the 2019 Forrester Wave for ECM, OpenText takes the lead spot, Microsoft and Hyland are some ways back but still in the leaders category, and Alfresco is right on the border between leaders and strong performers. Clearly, Hyland believes that acquiring Alfresco will allow it to push further up into OpenText’s territory, and OpenText is coming out swinging.
I’m finding it a bit difficult to navigate the agenda, since there’s no way to browse the entire agenda by time, but it seems to require that you know what product category that you’re interested in to see what’s coming up in a time-based format. That’s probably best for customers who only have one or two of their products and would just search in those areas, but for someone like me who is interested in a broader swath of topics, I’m sure that I’m missing some things.
That’s it for me for today, although I may try to tune in later for Poppy Crum‘s keynote. I’ll be back tomorrow for Muhi Majzoub’s innovation keynote and a few other sessions.
The second day of the Appian World 2020 virtual conference started with CTO Michael Beckley, who immediately set me straight on something that I assumed yesterday: at least some of the keynotes were pre-recorded, not live. So their statement on their website, that keynotes are “live” from 10am-noon, and other references to “live” keynotes just means that they are being broadcast at that time, not being broadcast live. Since there’s no interaction with the audience during keynotes it’s difficult to tell, and the content of most keynotes has been well done in any case. This may have been a special case for Beckley, since he has health conditions that make him higher risk, although this was still recorded in the Appian auditorium where there would have been some number of support staff.
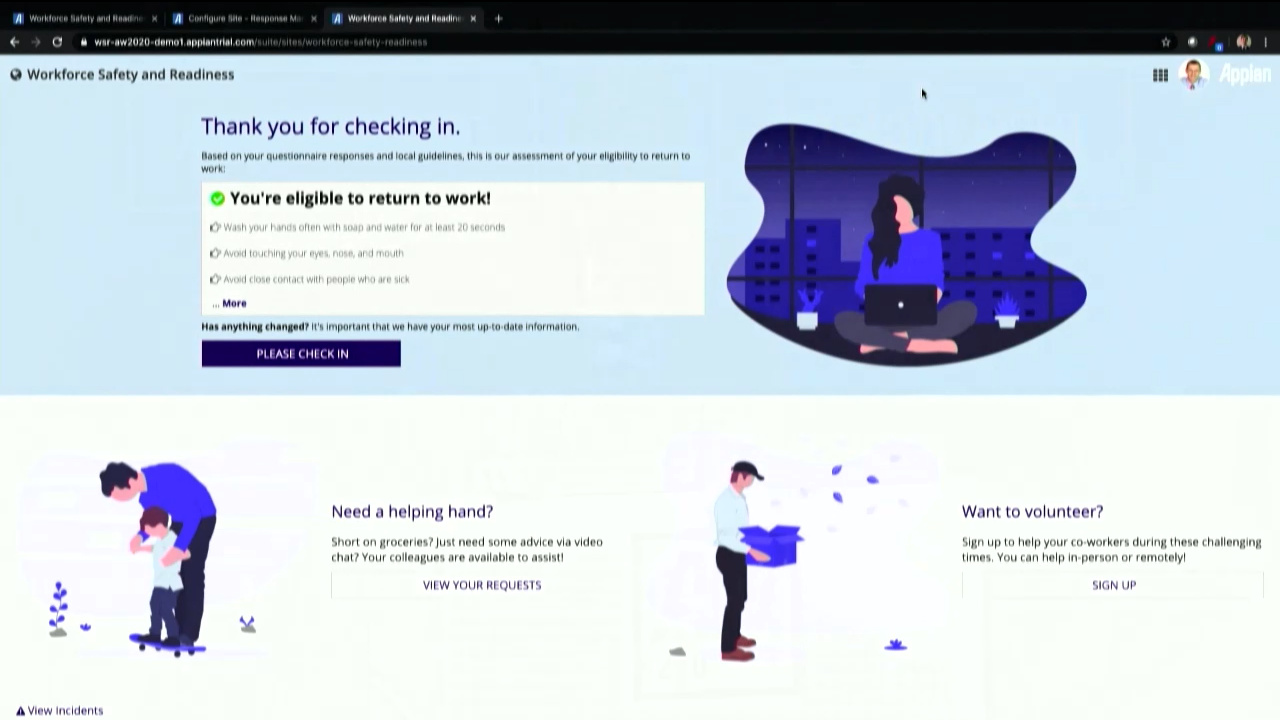
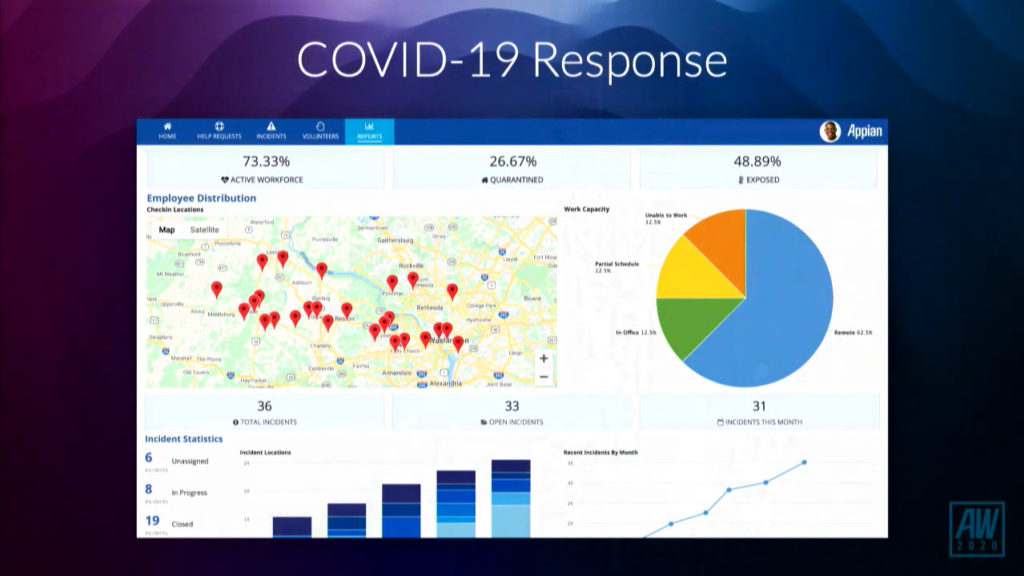
Beckley went into more detail on the COVID-19 apps that they have developed, with a highlight on their latest Workforce Safety and Readiness that helps to manage how workers return to a workplace. He walked through the employee view of the app, where they can record their own health check information, plus the HR manager view that allows them to set the questions, policies and information that will be seen by the employees. They’ve put this together pretty quickly using their own low-code platform, and are offering it at a reasonable price to their customers.
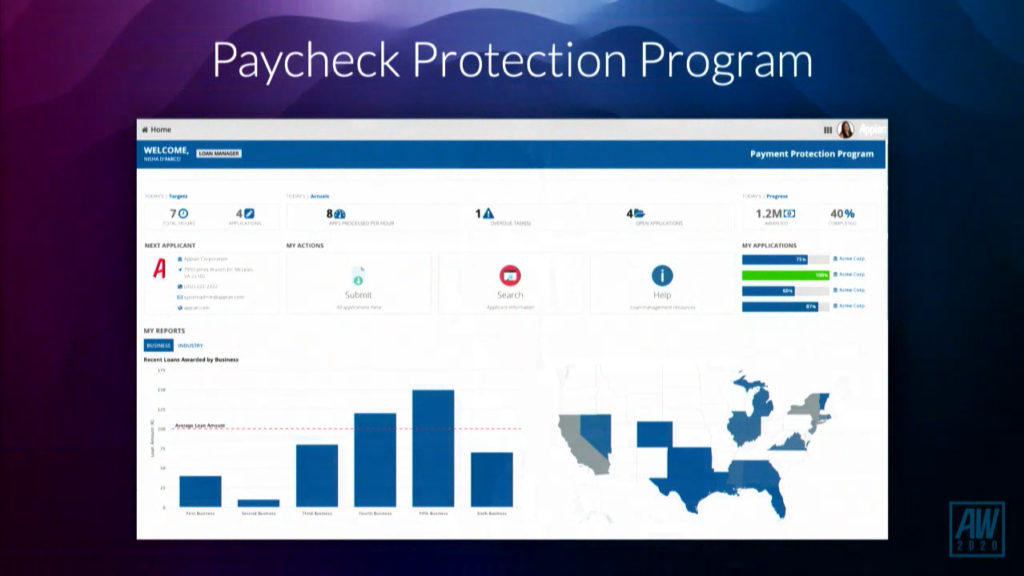
Next up was a customer presentation by Michael Woolley, Principal of IT Retail Systems at The Vanguard Group. They’re a huge wealth management firm spread over several countries, and they’re building Appian applications including ones that will be used by 6,000 employees. It appears that they are replacing their legacy workflow system of 20 years, which has hundreds of workflows. [I think the legacy system may be an IBM FileNet system, since I have a memory of doing some work for Vanguard over 20 years ago to develop requirements and technical design for just such a system – flashback!] They wanted to move to a modern low-code cloud platform, and although their standard workflow is pretty straightforward financial services transactional flows, they are incorporating business rules as well as BPM and case management, and RPA for interacting with legacy line of business systems. They are also planning to include AI/ML within the case management stages. He discussed their basic architecture as well as their development organization, and finished with some best practices for large projects such as this: it’s a multi-year program that covers many different workflows, so isn’t a greenfield application and has complex migration considerations.
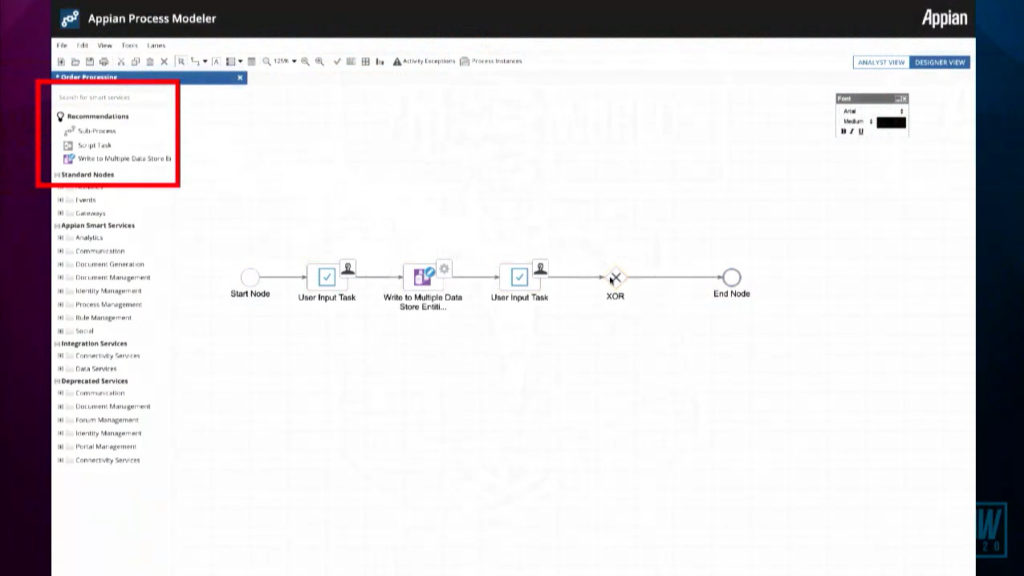
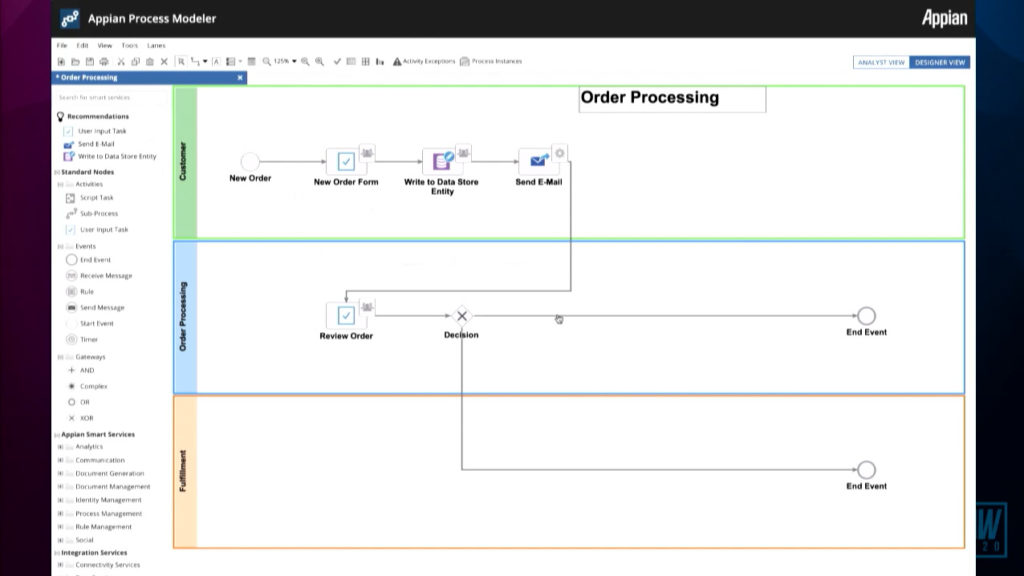
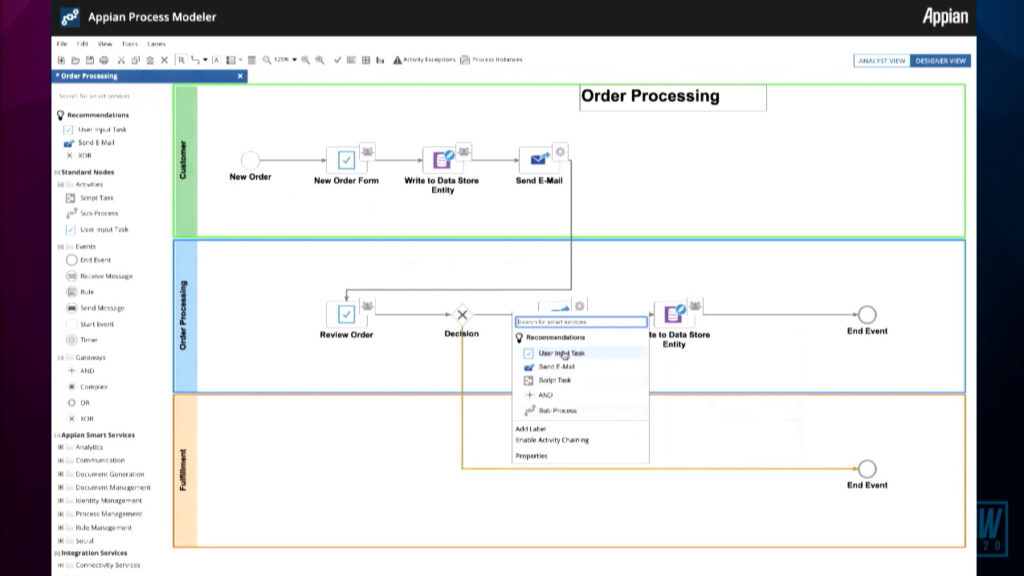
Deputy CTO Malcolm Ross returned to follow on from his talk yesterday, when he talked about AI and RPA, to discuss how they’re improving low-code development. He showed some pretty cool AI-augmented development that they are releasing in June, which looks at the design of a process as you’re building it, and recommends the next node that you will want to add based on the current content and goals of the process. I’m definitely interested in seeing where they go with this. He had a number of detailed product updates, including cloud security, details on testing/deployment cycles for application packages, and administrative tools such as (system) Health Check. They continue to push new features into their SAIL user interface layer, making it easier for developers to create new experiences on any form factor — one of the strikes against most low-code platforms is that their UI development is not as flexible as customers require, and Appian is definitely raising the bar on what’s possible. He finished up with their multi-channel communication add-ons, which allow the use of tools such as Twilio directly within an Appian application.
The final presentation of the morning keynote was Kristie Grinnell, Global CIO and Chief Supply Chain Officer at General Dynamics Information Technology with a presentation on how they are using Appian to help manage their 30,000 employees spread over 400 customer locations. They are a government contractor, and have to manage all things around being an outsourced IT company, such as assigning people to customer projects, timesheet adjustments and invoicing, while maintaining compliance and auditability. She spoke about some of their specific Appian applications that they have developed, and the benefits: an employee pay adjustment request application (to adjust people’s pay for when they work more hours than they were paid for) reduced backlog from three weeks to three days, and reduced errors. They also developed an international travel approval app (likely not getting used much these days), since most of their employees have a high security clearance and specific risks need to be managed during travel, which reduced the approval time from days to hours. Most of their applications to date have been administrative, but they are keen to look at how applying AI/ML to their existing data can help them to make better decisions in the future.
CMO Kevin Spurway and Malcolm Ross closed the keynotes with announcements of their awards to partners, resellers, app market contributors, and hackathon winners. On an optimistic note, Spurway announced that next year’s Appian World will be in San Diego, April 11-14, 2021. Here’s hoping.
This is the end of my Appian World 2020 coverage — some good information in the keynotes. As noted yesterday, the breakout session format isn’t sufficiently compelling to have me spend time there, but if you’re an Appian customer, you’ll probably find things of interest.
Another week, another virtual event! Appian World is happening two days this week, and will be available on-demand after. This has a huge number of sessions on several parallel tracks, which are pre-recorded, with keynotes in advance (not clear if the keynotes are actually live, or pre-recorded). From their site:
Keynote sessions are live from 10:00 AM – 12:00 PM EDT on May 12th and 13th. All breakout sessions will become available on-demand at 12:00 PM EDT on their scheduled day, immediately following the live keynote. Speakers will be available from 12:00 PM – 3:00 PM EDT for live Q&A on their scheduled session day.
They’re using the INXPO platform, and apparently using every possible feature. Here’s a bit of navigation help:
There’s a Lobby tab with a video greeting from Appian CMO Kevin Spurway. It has links to the agenda, solutions showcase and lounge, which is a bit superfluous since those are all top-level tabs visible at all times.
The Agenda tab lists the sessions for today, including the keynote (for some reason it showed as Live from 8:30am although the keynotes didn’t start until 10am), then all of the breakout sessions for the day, which you can dip into in any order since they are all pre-recorded and are made available at the same time.
The Sessions tab is where you can drill down and watch any of the sessions when they are live, but you can also do this directly from the Agenda tab. Sessions has them organized into tracks, such as Full Stack Automation Theater and Low-Code Development Theater.
The Solutions Showcase tab is virtual exhibit hall, with booths for partners and a pavilion of Appian product booths. These can have a combination of pre-recorded video, documents to download, and links to chat with them. It’s a bit overwhelming, although I supposed people will go through some of the virtual booths after the sessions, since the sessions run only 10-3 each day. I suppose that many of these partners signed on for Appian World before it moved to a virtual event, so Appian needed to provide a way for them to show their offerings.
The Lounge tab is a single-threaded chat for all attendees. Not a great forum for discussion: as I’ve mentioned on all of the other virtual conference coverage in the past couple of weeks, a separate discussion platform like Slack that allows for multi-threaded discussions where audience members can both lead and participate in discussions with each other is much, much better for audience engagement.
The Games tab has results for some games that they’re running — this is common at conferences, such as how many people send out tweets with the conference hashtag, or getting your ID scanned by a certain number of booths, but not something that adds value for my conference experience.
The keynote speakers appeared on a stage in Appian’s own auditorium, empty (except supposedly for each other and production staff). CEO Matt Calkins was up first, and talked about how the world has changed in 2020, and how their low-code application development can help with the changes that are being forced on organizations by the pandemic. He talked about the applications that they have built in the past couple of months: a COVID-19 workforce tracking app, a loan coordination app that uses AI and RPA for automation, and a workforce safety & readiness app that manages how businesses reopen to their workforce coming back to work. They have made these free or low-cost for their customers for the near term.
His theme for the keynote is automation: using human and digital workers, including RPA and AI, to get the best results. He mentioned BPM as part of their toolbox, and focused on the idea that the goal is to automate, and the specific tool doesn’t matter. They bought an RPA company and have rebranded it as AppianRPA: it’s cloud-native and Java-based, which is different from many other RPA products, but is more appealing to the CIO-level buyer for organization-wide implementations. They are pushing an open agenda, where they can interact with other RPA products and cloud platforms: certainly as a BPM vendor, interaction with other automation tools is part of the fabric.
They have a few new things that I haven’t seen in briefings (to be fair, I think I’ve dropped off their analyst relations radar). Their “Automation Planner” can make recommendations for what type of automation to use for any particular task. Calkins also spoke about their intelligent document processing (IDP), which addresses what they believe is one of the biggest automation challenges that companies have today.
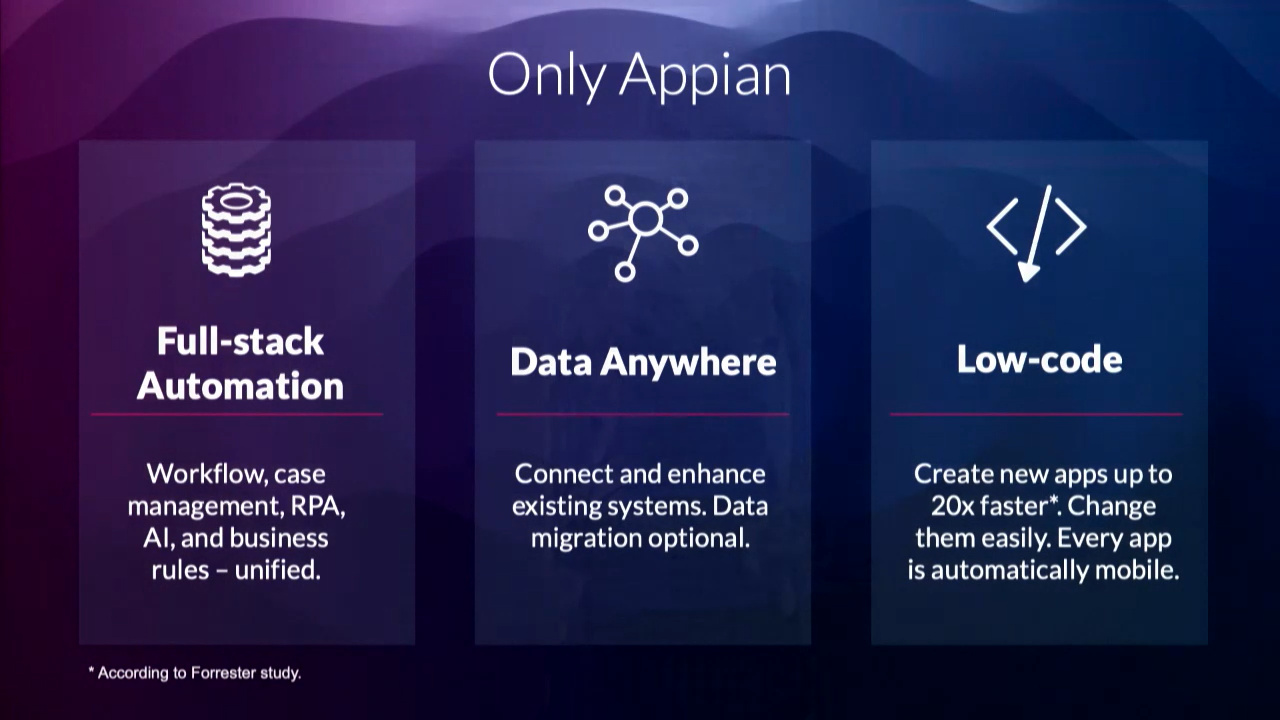
The Appian platform offers full-stack automation — workflow, case management, RPA, AI, business rules — with a “data anywhere” philosophy of integrating with systems to allow processing data in place, and their low-code development for which they have become known. If you’re a fan of the all-in-one proprietary platform, Appian is definitely one of main contenders. They have a number of vertical solutions now, and are starting to offer standardized all-inclusive subscription pricing for different sizes of installations that removes a lot of uncertainty about total cost of ownership. He also highlighted some of the vertical applications created by partners PWC, Accenture and KPMG.
I always like hearing Calkins talk (or chatting with him in person), because he’s smart and well-spoken, and ties together a lot of complex ideas well. He covered a lot of information about Appian products, direction, customers and partners in a 30-minute keynote, and it’s definitely worth watching the replay.
Darren Blake of Bexley Health Neighbourhood Care
Next up was a “stories from the front line of COVID-19” panel featuring Darin Cline, EVP of Operations of Bank of the West (part of BNP Paribas), and Darren Blake, COO of Bexley Health Neighbourhood Care in the UK National Health Service, moderated by Appian co-founder Mark Wilson. This was done remotely rather than in their studio, with each of the three having an Appian World backdrop: a great branding idea that was similar to what Celonis did with their remote speakers at Celosphere, although each person’s backdrop also had their own company’s logo — nice touch.
Blake talked about how they saw the wave of COVID-19 coming based on data that they were seeing from around the world, and put plans in place to leverage their existing Appian-based staff tracker to implement emergency measures around staff management and redeployment. They support home-based services as well as their patients’ visits to medical facilities, and had to manage staff and patient visits for non-COVID ailments as well as COVID responses and even dedicated COVID testing clinics without risking cross-contamination. Cline talked about how they needed to change their operations to allow people to continue accessing banking services even with lockdowns that happened in their home state of California. He said this disruption has pushed them to become a much more agile organization, both in business and IT departments: this is one of those things that likely is never going back to how it was pre-COVID. He credited their use of Appian for low-code development as part of this, and said that they are now taking advantage of it as never before. Blake echoed that they also have become much more agile, creating and deploying new capabilities in their systems in a matter of a few days: the vision of all low-code, but rarely the reality.
Interesting to hear these customers stories, where they stepped up and started doing agile development in the low-code platform that they were already using, listening to the voice of the customer in cooperation with their business people, executives and implementation partners such as Appian. So many things that companies said were just not possible actually are: fast low-code implementation, work from home, and other changes that are here to stay. These are organizations that are going to hit the ground running as the pandemic recedes — as Blake points out, this is going to be with us for at least two years until a vaccine is created, and will have multiple waves — since they have experienced a digital revolution that has fundamentally changed how they work.
Great customer panel: often these are a bit dry and unfocused, but this one was fascinating since they’ve had a bit of time to track how the pandemic has impacted their business and how they’ve been able to respond to it. In both cases, this is the new normal: Cline explicitly said that they are never going back to having so many people in their offices again, since both their distributed workforce and their customers have embraced online interactions.
Next up was deputy CTO Malcolm Ross (who I fondly remember as providing my first Appian demo in 2006) with a product update. He showed a demo that included integration of RPA, AI, IDP, Salesforce and SAP within the low-code BPM framework that ties it all together. It’s been a while since I’ve had an Appian briefing, and some nice new functionality for how integrations are created and configured with a minimum of coding. They have built-in integrations (i.e., “no code”) to many different other systems. Their AI is powered by Google’s AI services, and includes all of the capabilities that you would find there, bundled into Appian’s environment. This “Appian AI” is at the core of their IDP offering, which does classification and data extraction on unstructured documents, to map into structured data: they have a packaged use case that they provide with their product that includes manual correction when AI classification/extraction doesn’t have a sufficient level of confidence. Because there’s AI/ML behind IDP, it will become smarter as human operators correct the errors.
He went through a demo of their RPA, including how the bots can interact with other Appian automation components such as IDP. There is, as expected, another orchestration (process) model within RPA that shows the screen/task flow: it would be good if they could look at converging this modeling format with their BPM modeling, even though it would be a simple subset. Regardless, a lot of interesting capabilities here for management of robotic resources. If you’re an existing Appian customer, you’re probably already looking at their RPA. Even if you’re already using another RPA product, Appian’s Robotic Workforce Manager allows you to manage Blue Prism, Automation Anywhere and UiPath bots as well as AppianRPA bots.
The last part of the morning keynotes was a panel featuring Austan Goolsbee, Former Chairman of President Obama’s White House Council of Economic Advisers, and Arthur Laffer, Economist and Member of President Reagan’s Economic Policy Advisory Board, moderated by Matt Calkins. This was billed as a “left versus right” economists’ discussion on how to reopen the (US) economy, and quickly lost my interest: it’s not that I’m not interested in the topic, but prefer to find a much wider set of opinions than these two Americans who turned it into a political debate, flinging around phrases such as “Libertarian ideal”. Not really a good fit as part of a keynote at a tech vendor conference. I think this really highlights some of the differences between in-person and virtual conferences: the virtual tech conferences should stick to their products and customers, and drop the “thought leaders” from unrelated areas. The celebrity speakers have a slight appeal to some attendees in person, but not so much in the virtual forum even if they are live conversations. IBM Think had a couple of high profile speakers that I skipped, since I can just go and watch their TED Talk or YouTube channel, and they didn’t really fit into the flow of the conference.
The remaining three hours of day 1 were (pre-recorded) breakout sessions available simultaneously on demand, with live Q&A with the speakers for the entire period. This allows them to have a large number of sessions — an overwhelming 30+ of them — but I expect that engagement for each specific session will be relatively low. It’s not clear if the Q&A with the speaker is private or if you would share the same Q&A with other people who happened to be looking at that session at the same time; even if they were, the session starts when you pop in, so everyone would be at a different point in the presentation and probably asking different questions. It looks like a similar lineup of breakout sessions will be available tomorrow for the afternoon portion, following another keynote.
I poked into a couple of the breakout sessions, but they’re just a video that starts playing from the beginning when you enter, no way to engage with other audience members, and no motivation to watch at a particular time. I sent a question for one speaker off into the void, but never saw a response. Some of them are really short (I saw one that was 8 minutes) and others are longer (Neil Ward-Dutton‘s session was 36 minutes) but there’s no way to know how long each one is without starting it. This is a good way to push out a lot of content simultaneously, but there’s extremely low audience engagement. I was also invited to a “Canada Drop-In Centre” via Google Meet; I’m not that interested in any sort of Canadian-specific experience, a broader based engagement (like Slack) would have been a better choice, possibly with separate channels for regions but also session discussions and Q&A. They also don’t seem to be providing slide decks for any of the presentations, which I like to have to remind me of what was said (or to skip back if I missed something).
This was originally planned as an in-person conference, and Appian had to pivot on relatively short notice. They did a great job with the keynotes, including a few of the Appian speakers appearing (appropriately distanced) in their own auditorium. The breakout sessions didn’t really grab me: too many, all pre-recorded, and you’re basically an audience of one when you’re in any of them, with little or no interactivity. Better as a set of on-demand training/content videos rather than true breakout sessions, and I’m sure there’s a lot of good content here for Appian customers or prospects to dig deeper into product capabilities but these could be packaged as a permanent library of content rather than a “conference”. The key for virtual conferences seems to be keeping it a bit simpler, with more timely and live sessions from one or two tracks only.
I’ll be back for tomorrow’s keynotes, and will have a look through the breakout sessions to see if there’s anything that I want to watch right now as opposed to just looking it up later.
The ability to build apps quickly is a cornerstone in our industry of model-driven development and low-code, and it’s encouraging to see some good offerings on the table already in response to our current situation.
Appian was first out of the blocks with a COVID-19 Response Management application for collecting and managing employee health status, travel history and more in a HIPAA-compliant cloud. You can read about it on their blog, and sign up for it online. Their blog post says that it’s free to any enterprise or government agency, although the signup page says that it’s free to organizations with over 1,000 employees — not sure which is accurate, since the latter seems to exclude non-customers under 1,000 employees. It’s free only for six months at this point.
Pegasystems followed closely behind with a COVID-19 Employee Safety and Business Continuity Tracker, which seems to have similar functionality to the Appian application. It’s an accelerator, so you download it and configure it for your own needs, a familiar process if you’re an existing Pega customer — which you will have to be, because it’s only available for Pega customers. The page linked above has a link get the app from the Pega Marketplace, where it will be free through December 31, 2020.
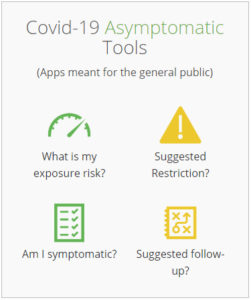
As a founding member of OMG’s BPM+ Health community, Trisotech has been involved in developing shareable clinical pathways for other medical conditions (using visual models in BPMN, CMMN and/or DMN), and I imagine that these new tools might be the first bits of new shareable clinical pathways targeted at COVID-19, possibly packaged as consumable microservices. You can click on the tools and try them out without any type of registration or preparation: they ask a series of questions and provide an assessment based on the underlying business rules, and you can also upload files containing data and download the results.
My personal view is that making these apps available to non-customers is sure to be a benefit, since they will get a chance to work with your company’s platform and you’ll gain some goodwill all around.