The last time that I was on a plane was mid-February, when I attended the OpenText analyst summit in Boston. For people even paying attention to the virus that was sweeping through China and spreading to other Asian countries, it seemed like a faraway problem that wasn’t going to impact us. How wrong we were. Eight months later, many businesses have completely changed their products, their markets and their workforce, much of this with the aid of technology that automates processes and supply chains, and enables remote work.
By early April, OpenText had already moved their European regional conference online, and this week, I’m attending the virtual version of their annual OpenText World conference, in a completely different world than in February. Similar to many other vendors that I cover (and have attended virtual conferences for in the past several months), OpenText’s broad portfolio of enterprise automation products has the opportunity to make gains during this time. The conference opened with a keynote from CEO Mark Barrenechea, “Time to Rethink Business”, highlighting that we are undergoing a fundamental technological (and societal) disruption, and small adjustments to how businesses work aren’t going to cut it. Instead of the overused term “new normal”, Barrenechea spoke about “new equilibrium”: how our business models and work methods are achieving a stable state that is fundamentally different than what it was prior to 2020. I’ve presented about a lot of these same issues, but I really like his equilibrium analogy with the idea that the landscape has changed, and our ball has rolled downhill to a new location.

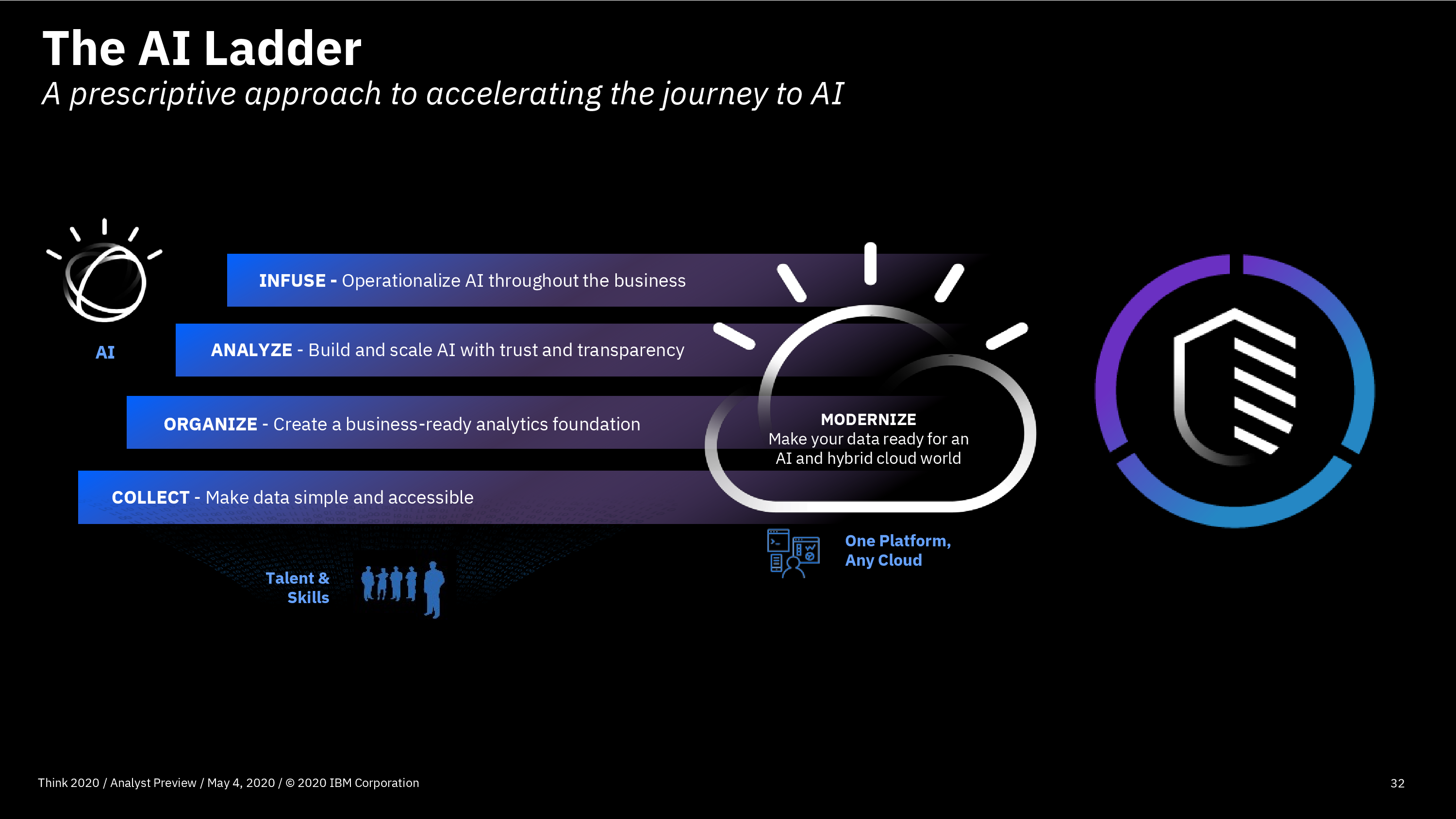
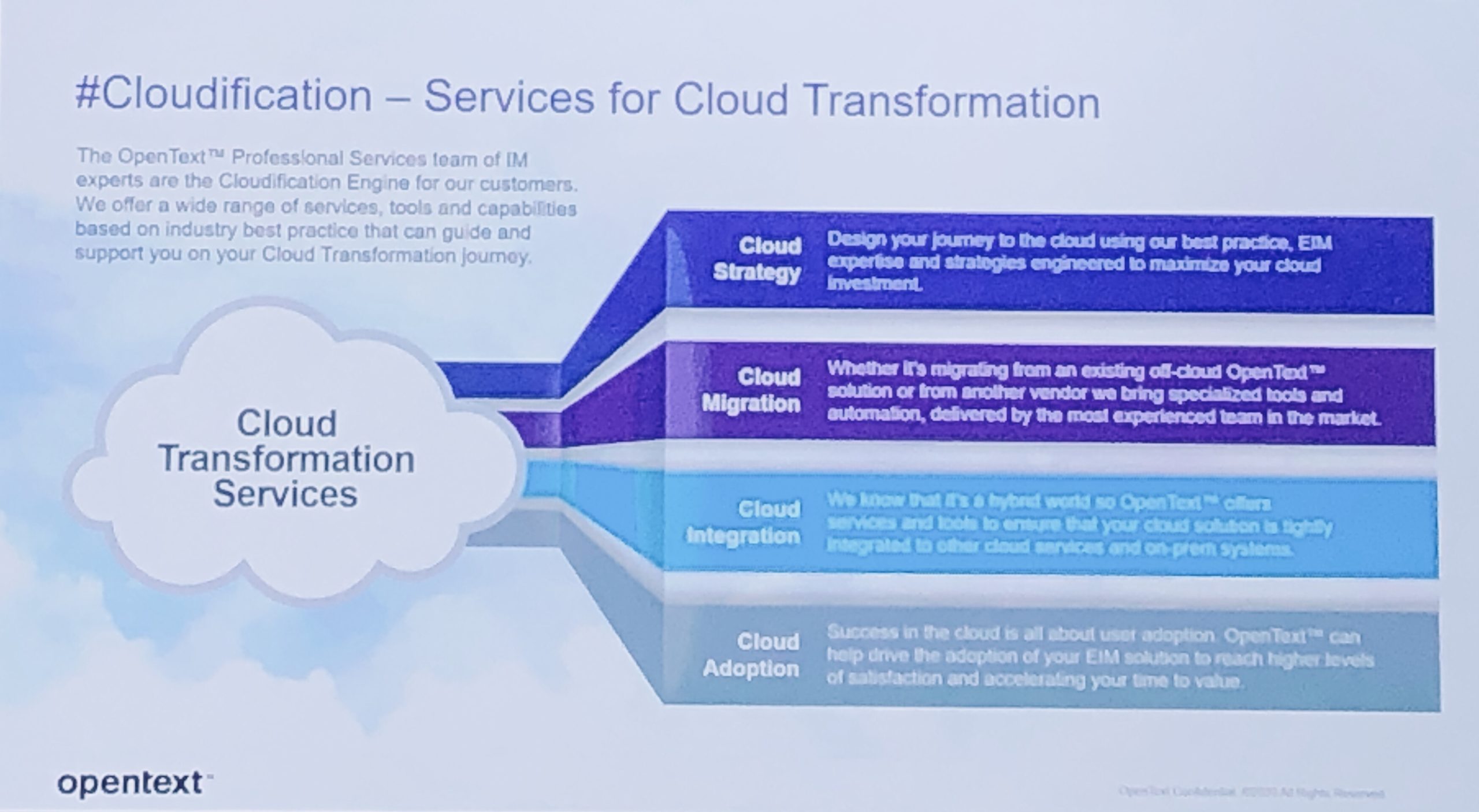
He announced OpenText Cloud Edition (CE) 20.4, which includes five domain-oriented cloud platforms focused on content, business network, experience, security and development. All of these are based on the same basic platform and architecture, allowing them to updated on a quarterly basis.
- The Content Cloud provides the single source of truth across the organization (via information federation), enables collaboration, automates processes and provides information governance and security.
- The Business Network Cloud deals directly with the management and automation of supply chains, which has increased in importance exponentially in these past several months of supply chain disruption. OpenText has used this time to expand the platform in terms of partners, API integrations and other capabilities. Although this is not my usual area of interest, it’s impossible to ignore the role of platforms such as the Business Network Cloud in making end-to-end processes more agile and resilient.
- The Experience Cloud is their customer communications platform, including omnichannel customer engagement tools and AI-driven insights.
- The Security and Protection Cloud provides a collection of security-related capabilities, from backup to endpoint protection to digital forensics. This is another product class that has become incredibly important with so many organizations shifting to work from home, since protecting information and transactions is critical regardless of where the worker happens to be working.
- The Developer Cloud is a new bundling/labelling of their software development (including low-code) tools and APIs, with 32 services across eight groupings including capture, storage, analysis, automation, search, integration, communicate and security. The OpenText products that I’ve covered in the past mostly live here: process automation, low-code application development, and case management.
Barrenechea finished with their Voyager program, which appears to be an enthusiastic rebranding of their training programs.
Next up was a prerecorded AppWorks strategy and roadmap with Nic Carter and Nick King from OpenText product management. It was fortunate that this was prerecorded (as much as I feel it decreases the energy of the presentation and doesn’t allow for live Q&A) since the keynote ran overtime, and the AppWorks session could be started when I was ready. Which begs the question why it was “scheduled” to start at a specific time. I do like the fact that OpenText puts the presentation slides in the broadcast platform with the session, so if I miss something it’s easy to skip back a slide or two on my local copy.
Process Suite (based on the Cordys-heritage product) was rolled into the AppWorks branding starting in 2018, and the platform and UI consolidated with the low-code environment between then and now. The sweet spot for their low-code process-centric applications is around case management, such as service requests, although the process engine is capable of supporting a wide range of application styles and developer skill levels.
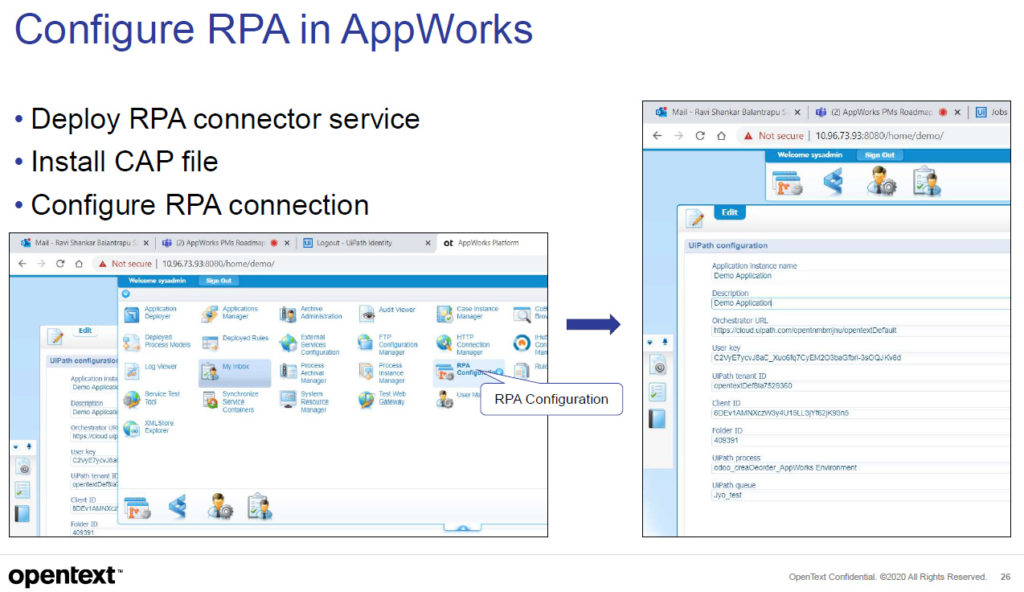

They walked through a number of developer and end-user feature enhancements in the 20.4 version, then covered new automation features. This includes enhanced content and Brava viewer integration, but more significantly, their RPA service. They’re not creating/acquiring their own RPA tool, or just focusing on one tool, but have created a service that enables connectors to any RPA product. Their first connector is for UiPath and they have more on the roadmap — very similar rollout to what we saw at CamundaCon and Bizagi Catalyst a few weeks ago. By release 21.2 (mid-2021), they will have an open source RPA connector so that anyone can build a connector to their RPA of choice if it’s not provided directly by OpenText.
There are some AppWorks demos and discussion later, but they’re in the “Demos On Demand” category so I’m not sure if they’re live or “live”.
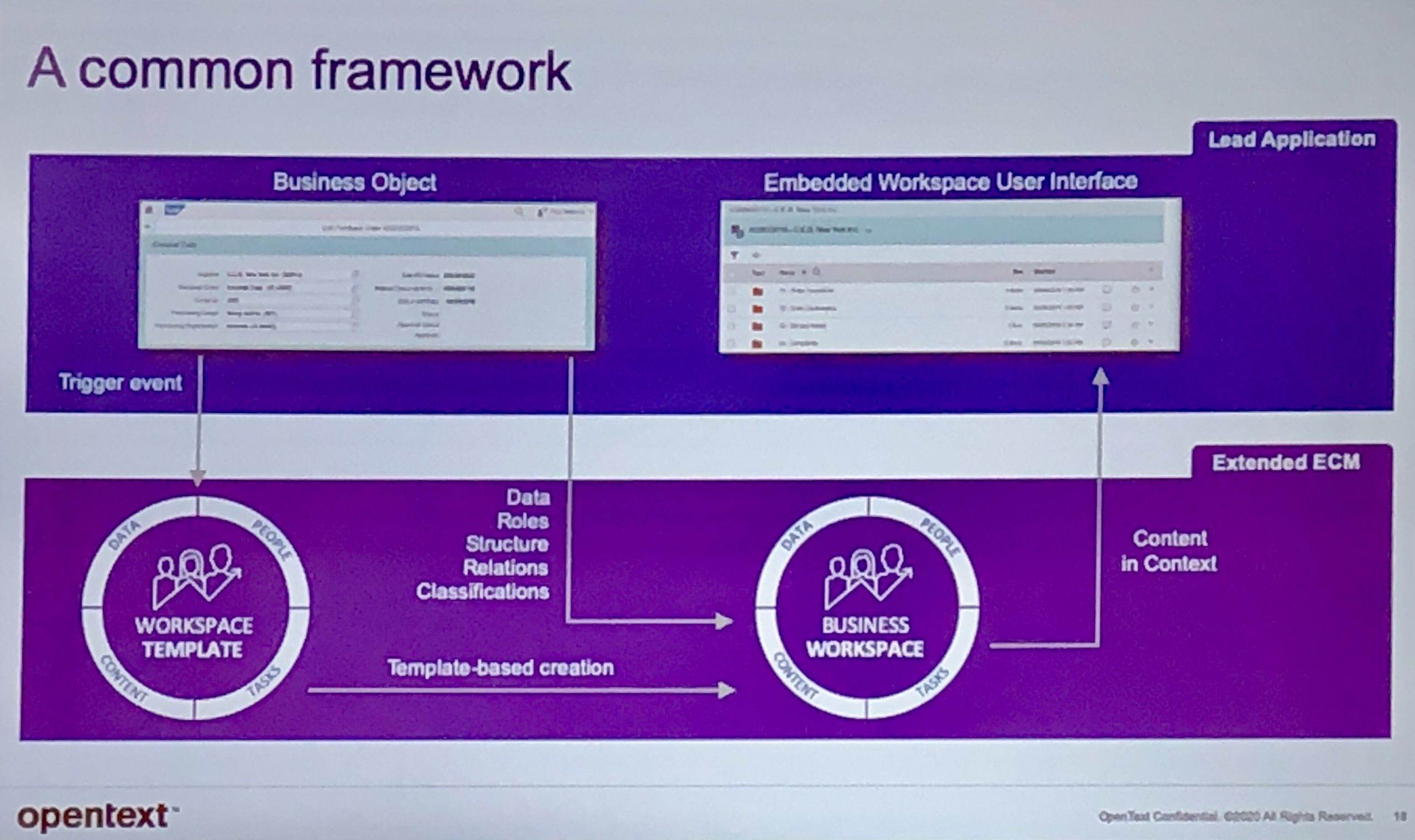
I checked out the content service keynote with Stephen Ludlow, SVP of product management; there’s a lot of overlap between their content, process, AI and appdev messages, so important to see how they approach it from all directions. His message is that content and process are tightly linked in terms of their business usage (even if on different systems), and business users should be able to see content in the context of business processes. They integrate with and complement a number of mainstream platforms, including Microsoft Office/Teams, SAP, Salesforce and SuccessFactors. They provide digital signature capabilities, allowing an external party to digitally sign a document that is stored in an OpenText content server.
An interesting industry event that was not discussed was the recent acquisition of Alfresco by Hyland. Alfresco bragged about the Documentum customers that they were moving onto Alfresco on AWS, and now OpenText may be trying to reclaim some of that market by offering support services for Alfresco customers and provide an OpenText-branded version of Alfresco Community Edition, unfortunately via a private fork. In the 2019 Forrester Wave for ECM, OpenText takes the lead spot, Microsoft and Hyland are some ways back but still in the leaders category, and Alfresco is right on the border between leaders and strong performers. Clearly, Hyland believes that acquiring Alfresco will allow it to push further up into OpenText’s territory, and OpenText is coming out swinging.
I’m finding it a bit difficult to navigate the agenda, since there’s no way to browse the entire agenda by time, but it seems to require that you know what product category that you’re interested in to see what’s coming up in a time-based format. That’s probably best for customers who only have one or two of their products and would just search in those areas, but for someone like me who is interested in a broader swath of topics, I’m sure that I’m missing some things.
That’s it for me for today, although I may try to tune in later for Poppy Crum‘s keynote. I’ll be back tomorrow for Muhi Majzoub’s innovation keynote and a few other sessions.