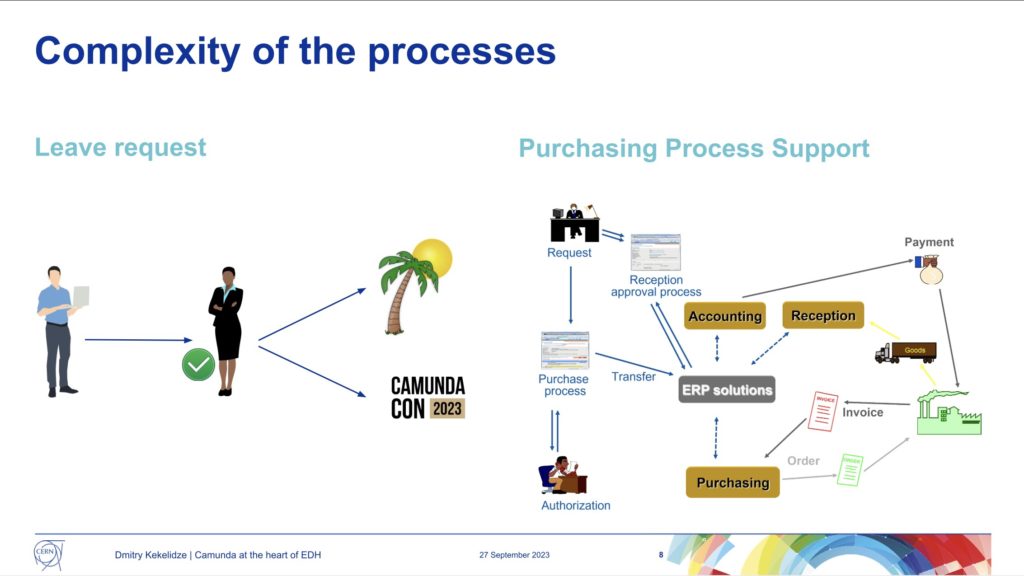
As we reached the end of the first day of CamundaCon 2023 in NYC, Dimitri Kekelidze of Conseil Européen pour la Recherche Nucléaire (CERN, or what we in English would call the European Council for Nuclear Research) presented on their use of Camunda for handling electronic documents. Although an “administrative” sort of workflow, it’s pretty critical: they started in the early 1990s to move from paper to electronic forms and documents, and those are used for everything from access requests to specific buildings to all types of HR forms to training requests to purchasing.
The volume is pretty significant: there have been 2 million leave requests alone since the system was started in 1992, and this is not just about filling out a form online, it’s the entire process of handling the request that is kicked off by the form. In short, document-driven processes where the document is an electronic form filled out on their employee portal.
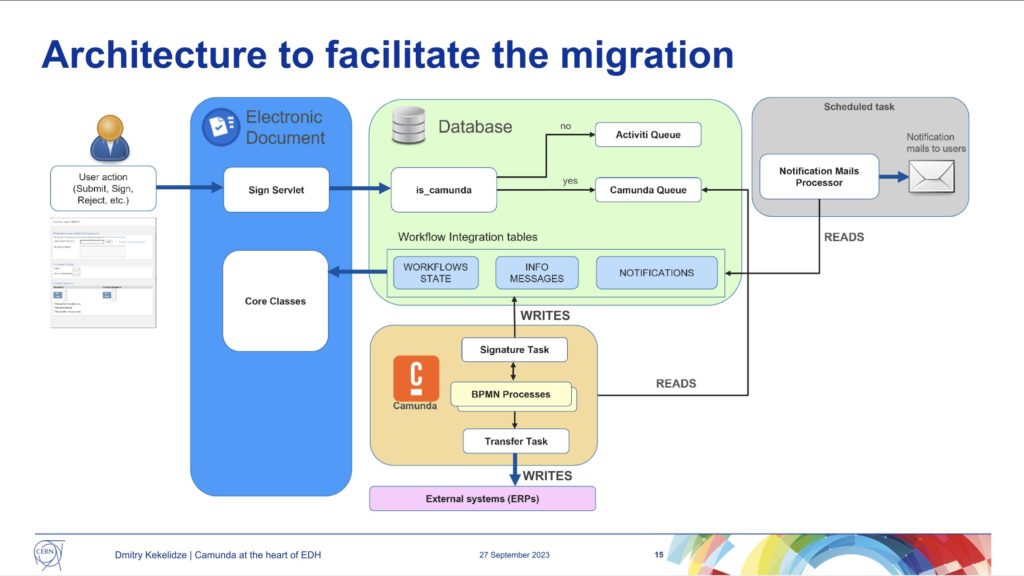
CERN started their electronic document handling in 1992 (long before Camunda) with a home-built workflow solution, then moved to Oracle workflow in 1998, then to ActiveVOS (a name I haven’t heard in years!) in 2006, Activiti in 2013, and Camunda in 2021. Making the move from Activiti to Camunda meant that they could migrate quite a bit of the BPMN and code, although there were specific functions that he discussed that required a bit of work for migration. Since then, they’ve migrated 65 processes, and have 9 still to migrate; this has necessitated an architecture that supports both Activiti and Camunda, depending on the type of workflow.
Because of the business criticality, volume and complexity of these processes, there is a significant amount of testing prior to migration. They had a number of bugs/glitches during the migration: some because they had some legacy code that was no longer required (such as marking workflow instances busy/free in an external database), and some due to overly complex BPMN diagrams that could be redrawn in a simpler fashion to remove manual escalations and error handling.
In the upcoming months, they plan to complete the migrate of the remaining 9 processes so that they can decommission Activiti. They will also be upgrading to Camunda 8, and adding some custom plugins to Cockpit for monitoring and managing the flows.
After hearing Heidi Badenhorst of aYo Holdings speak this morning at the Hyland CommunityLIVE 2002 general session, I knew that I wanted to see her breakout session for more details on what they’re doing. I use microinsurance as an example of a new business model that insurance companies can consider once they’ve automated a lot of their processes (otherwise, it’s not cost-effective), but this is the first chance that I‘ve really had to hear more about microinsurance in action.
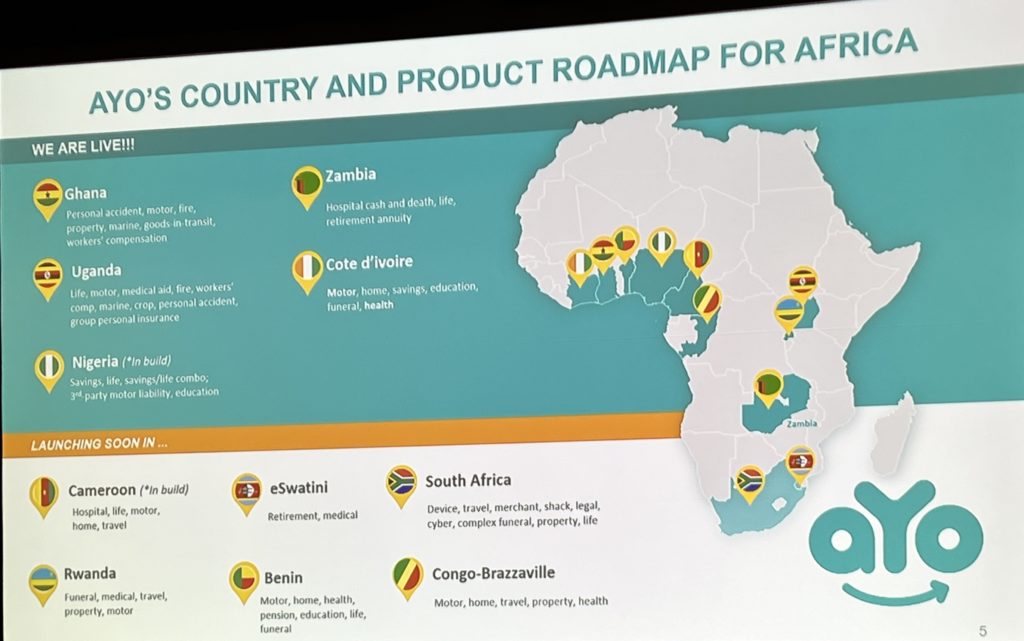
Ayo provides low-cost hospital and life insurance (as well as a few other types) for more than 17M people across several African countries, with the goal to scale up to more than 100M customers. As with a lot of other businesses spreading into developing countries, the customers use their mobile phones to interact with aYo’s insurance products through mobile money for receiving payments and WhatsApp chatbots for gathering information and submitting documents. aYo is owned by MTN, the largest mobile provider in Africa, and the insurance service was first started as a loyalty benefit for mobile customers.
Microinsurance is about tiny premiums and small payouts — small amounts in our rich countries, but a day’s pay in many African markets — and the only way to do this effectively is to maximize the amount of automation. Medical records are rudimentary, often hand-written and without standard treatment or claim codes, making it difficult to automate and subject to fraud.
They have been managing all of this with manual processes (including manual downloads of documents) and spreadsheets, but are moving to a greater degree of automation using Alfresco Process Automation (APA) and other components to pay 80% of the claims without human intervention. Obviously, they need content management and intelligent capture as well, but the content-centric process orchestration and AI for fraud detection are key to automation. They also needed a cloud solution to support their multi-national operations, and something that integrated well with their claims system. Since their solution is tightly integrated with the phone network, they can use location data from the claim to correlate with hospital locations as another potential anti-fraud check. They’re also using behavioral data from how their customers interact with WhatsApp to optimize their customer experience.
We saw a video of what a claim looks like from the customer side — WhatsApp chatbot with links for uploading documents — as well as the internal aYo operations side in more conventional Alfresco workspaces and dashboards. This was really inspirational on a number of levels. First of all, just from a business and technology standpoint, they’re doing a great job of improving their business through automation. More importantly, they are using this to allow for cost-effective processing of very small claims, and thereby enabling coverage for millions of people who have never previously had access to insurance. Truly, a transformational business model for insurance.
I’ll be heading home this afternoon, but wanted to grab a couple of the morning sessions while I’m here in Nashville. Nashville is really a music city, and we’ve started of each day with live music from the main stage, plus at the evening event last night. Susan deCathelineau, Hyland’s Chief Customer Success Officer, kicked things off with a review of some of the customer support and services improvements that they have made in response to customer feedback, and how the recent acquisitions and product improvements have resonated with customers. Sticking with the “voice of the customer” theme, Ed McQuiston, Chief Commercial Officer, hosted a panel of customers in a “Late Morning Show” format.
His guests were Heidi Badenhorst, Group Head of Strategy and Special Projects at aYo Holdings (South African micro-insurance provider); Adam Podber, VP of Digital Experience at PVH (a fashion company that owns brands such as Tommy Hilfiger and Calvin Klein); and Kim Ferren, Senior AP Manager at Match (the online dating company).
Badenhorst spoke first about how aYo is trying to bridge the financial gap by providing insurance to the low end of the market, especially health insurance for people who have no other support network in situations when they can’t work (and therefore feed their families). They use Alfresco to automatically capture and store medical documents directly from customers (via WhatsApp), and plan to automate the (still manual) claims processing using rules and process in the future. This is such an exciting application of automation, and exactly the type of thing that I spoke about yesterday in my presentation: what new business models are possible once we automate processes. I’m definitely going to hit her breakout session later this morning.
Podber talked about their experience with Nuxeo for digital asset management, moving from 17 DAMs across different regions to a consolidated environment that has different user experience depending on the user’s role and interests. With a number of different brands and a huge number of products within each brand, this provides them with a much more effective way to manage their product information.
Ferren was there to talk about accounts payable, but there was a hilarious Match.com ad shown first where Satan and 2020 go on a date in all the empty places that we couldn’t go back then, plus stole some toilet paper and ended up posing in front of a dumpster fire. Match is an OnBase customer, and although AP isn’t necessarily a sexy application, it’s a critical part of any business — one of my first imaging and workflow project implementations back in the 1990s was AP and I learned a lot about it how it works. Match used to combine Workday, Great Plains, NetSuite and several other local systems across their different geographic regions; now it’s primarily Workday with Hyland providing integrated support and Brainware intelligent capture.
There was a good conversation amongst the panelists about lessons learned and what they are planning to do going forward; expect some good breakout sessions from each of these companies with more details about what they’re doing with Hyland products.
Hey, I gave a presentation yesterday, first time in person in almost three years! Here’s the slides, and feel free to contact me if you have questions. I can’t figure out how to get the embed short code on mobile, but when I’m back in the office I’ll give it another try and you may see the slideshow embedded below. Update: found the short code!
We had a small analyst Q&A with Ed McQuiston (Chief Commercial Officer) and John Phelan (Chief Product Officer) this afternoon at Hyland’s CommunityLIVE, giving us a chance to hear more and ask some questions about the company and product direction. I’m particularly interested in the product roadmap in terms of convergence (or not) of the four content engines that they now have, both from a technology standpoint and go-to-market positioning. They mostly go to market through verticals, which begs the question whether they will position each engine as serving a specific industry to avoid customer confusion and also reduce the training cycle for their own industry-specific teams. There are definitely some places where that makes sense, such as using Nuxeo for digital asset management for rich media, but there’s arguably a lot of overlap between functionality in, for example, OnBase and Alfresco.
McQuiston addressed how they are consolidating the external view of the company and product pages: instead of having separate entry points for each product, they are consolidating the online experiences regardless of what product that you’re looking for information on. Their sales teams are very oriented around the industry verticals, and there is a strong alignment between products and verticals. However, they are finding that some of the verticals that were previously OnBase are shifting to be a more natural match with one of the other platforms, such that net new customers in those verticals may use a different platform than what they sold with OnBase previously. Not surprising, but its possible that the vertical sales teams end up in a Maslow’s Hammer situation of selling what they’re most familiar with.
Phelan (and I quizzed him at lunch about this) isn’t discussing any particular plans about core engine convergence/unification: their public message is that they are supporting all four content engines. As I said to them in the Q&A session, I hope we’re not sitting here in five years hearing the same message. Since their company value is based on ARR — annual recurring revenue — they have little financial basis for cutting any of their existing product lines, but from a technology standpoint, they will move faster as a company if they can start unifying at least the core engines under the covers, then gradually migrate the “product specific” capabilities to integrate with a shared core engine.
Hyland’s an old company in software terms, and could definitely benefit from shedding some of their legacy mindset. They’ve got a lot of solid technology in their portfolio, and a huge amount of industry vertical experience; they need to find the right product and go-to-market roadmap to best leverage that.
This might be the only breakout session that I make it to today, since I’m in an executive Q&A after this, then need a bit of time for final preparations for my own session later this afternoon. The insurance industry session was presented by Richard Medina of Doculabs, with the title “Don’t Just Survive – Thrive”, a phrase that I used quite a bit in talking about digital business during the pandemic era to stress that it’s not just about doing the minimum possible to survive, but leverage the new technologies and methods to go far beyond that and become a market leader. Here, he was specifically talking about digital insurance operations, which is coincidentally the use case that I will cover in my presentation is about insurance claims.
He started with a slide defining intelligent automation, specifically referencing workflow (process orchestration), RPA, intelligent document processing, natural language processing, and process mining, since these are the specific technologies that Doculabs covers. There was quite a bit on their market and methods, but he came back to a key point for those in the audience: a lot of organizations didn’t consider content management as a real part of digital transformation. So wrong. In applications like insurance claims, content is core to the process: the entire process of handling a claim is based on populating the claims file with all of the necessary documentation to support the claim decision. It doesn’t mean that all of this content is on paper any more, or even ever exists on paper within the organization: forms are created online and e-signed, spreadsheets are used to document a full statement of loss, and policyholders upload images related to their claim. This is, of course, not the same as claims operations of old, where everything was on paper in huge file folders, occasionally with the addition of a CD that holds some photos of damage, although those were often printed for the file. E-mails would be printed out and added to the paper folder.
This brings some challenges to insurance operations, particularly claims where there may be rich media involved. Not only do paper and possibly multiple online document repositories need to be consolidated (via merging or federation), but they also need to include other types of unstructured content: photos, videos, social media conversations, and more. The core content engine(s) needs to support all of this, but there’s much more: it needs to be cloud-based for today’s remote workforce, include NLP and AI during intelligent capture for automatic content classification and extraction, have process automation to move the content through its lifecycle and integrate with line-of-business systems, and include chatbots for simpler interactions with policyholders. Medina talked about the unicorn of intelligent automation applied to documents: AI/ML, intelligent capture, RPA, and BPM (orchestration). He walked through a couple of scenarios on policy administration, servicing and claims, showing how different technologies come into play at each point in these processes.
He showed some of the issues to consider for different levels of transformation at each stage in a potential roadmap, starting with content ingestion (capturing content, automating completion checklists, and integrating the content with the LOB systems), then workflow. He finished up with a bit on process mining to show how it can be used to introspect your current processes, do some root cause analysis, and optimize the process. A flying tour through how many of the technologies being discussed here this week can be applied in insurance applications.
If you’re interested in some of the best practices around projects involving these technologies, check out my presentation at 4:45pm today on maximizing success in business automation projects.
I arrived a day early for my first time at Hyland’s CommunityLIVE conference to attend yesterday’s executive forum, and enjoy a very cool dinner experience at the Grand Ole Opry. This morning, the opening general session is back to IRL in a big way: big conference venue, live band before the start, lots of butts in seats (not wearing pajama pants). It’s their first live conference in 3 years, and for many of us it’s been almost as long. In fact, the first IRL conference that was cancelled for me was with Alfresco in New York that was scheduled for March 2020, and now Alfresco is part of Hyland.
The general session started with Hyland CEO Bill Priemer talked about trends in content management, and how the pandemic accelerated the shift towards a cloud-based digital workplace for many organizations. Hyland has done two significant acquisitions during the past two years — Alfresco and Nuxeo — which potentially positions then to address a wider range of customer needs, if they can move forward with a reasonable product roadmap that (eventually) converges their portfolio. It appears that they are only now moving their legacy OnBase product to the cloud, although their acquisitions add that capability already. Also, this puts them into the open source space, which is new to them but they appear to be embracing that. As he discussed yesterday at the executive forum, Priemer talked about plugging in other capabilities to their core content platform: not just with Hyland’s products, but with anything that adds value to an integrated digital workspace.
He spoke about upgrade challenges, which seems to be a bit of a sore point: with a 30-year-old content management company, there’s going to be a lot of legacy customers who have millions of documents in those systems, and upgrading is a non-trivial undertaking. Moving to the cloud is not only a big migration job, but a scary concept for organizations who believe that only their own on-premise servers are safe. That’s not true, of course, but the beliefs are there. Pre-acquisition, Alfresco already had a significant campaign showing customers moving from on-premise content management (such as IBM/FileNet and Hyland) to their cloud solution, and how much it could reduce costs while maintaining security and access. If there are any Alfresco marketing people left at Hyland, this would be a good tine to bring their views to bear on how to motivate on-prem customers to move to the cloud.
John Phelan, Chief Product Officer, was up next, and also stressed extensibility as a necessity as opposed to the old days of standalone content management systems. He stressed that Hyland is not just “the OnBase company” any more, but a company that offers four core content platforms (OnBase, Perceptive, Alfresco, Nuxeo), although that’s arguably not really a good thing since it divides focus of the product groups, can create islands of sales and support based on product, and confuses the customers.
Sam Babic, Chief Innovation Officer, took the stage to expand his talk about hyperautomation that he gave yesterday at the executive forum. Interestingly, his first slide called out business process management and business process automation (although I’m a bit unclear on the distinction that he makes between them) as well as RPA and case management, and had a quick screen grab video of an Alfresco process manager orchestration. This is a much better message to the audience on how content and process work together in general, as well as in the context of the myriad technologies included in Gartner’s definition of hyperautomation.
Don Dittmar, who manages industry partner relationships, joined remotely (via a pre-recorded video) on how Hyland works together with partner companies that offer vertical or line-of-business systems, including Workday, ServiceNow and Guidewire. I’ll be talking about an insurance claims use case in my presentation this afternoon, and the integration with Guidewire fits right into that. This is a classic content management problem, and having pre-built integrations with these systems is a huge help for companies that want to better manage content that is directly related to transactions and cases in their LOB systems.
Alex Cameron, product manager for healthcare solutions showed us some of their solutions around healthcare enterprises. Intelligent medical records, which captures and classifies unstructured medical records (documents) then manages the content according to regulatory requirements. Then Max Gavanon, product manager for PAM and DAM, discussed their solutions for digital asset management (i.e., non-document content), such as 3D designs cross-referenced with materials for product design.
Up next was Eileen Thornton, AVP of user experience, to talk about their user experience development across the Hyland portfolio, and show a few screens of what this will look like. This seems to indicate that their initial integration/consolidation of their content engines will happen “at the glass” by providing a common UX. It sounds like most of their current OnBase customers are still on the old-style desktop UI, since she talked about using this new UX to move to a modern web-based experience.
Lots of good content, and now we’re off to individual industry sessions and later breakout tracks. I’ll be presenting at 4:45 this afternoon in the Business Transformation track, hope you can join me!
It’s been a long 2.5 years since I was last at a conference in person, and I’m kicking off the new era with Hyland’s CommunityLIVE in Nashville. I came in early to attend today’s Executive Forum, where we were welcomed by Stephanie Dedmon, CIO of the state of Tennessee. She gave us a brief view of their IT initiatives, one of which is process automation (specifically RPA). I will be giving a presentation tomorrow about some of the best practices around intelligent automation, and one of those is having process automation right on your strategic initiatives list, like what Dedmon tells us is the case with the local state government.
We had a corporate update from Hyland’s CEO, Bill Priemer. I haven’t been to a Hyland event before — I came to this from my past relationship with Alfresco prior to their acquisition by Hyland — and it’s good to see a more complete briefing including how their recent acquisitions are being handled. He covered some financials and other numbers that I have not included here since I usually just focus on the technology, and I’m not sure if I’m cleared to discuss those outside this venue.
Priemer said that they are “solely focused on content services”, which does not sound all that great for the process side of the former Alfresco product; recall that the absorption of Activiti into Alfresco which turned it into essentially (just) a content-centric process engine was controversial, and led to the departure of some of the original Activiti architects and developers. I expect that many Activiti customers/users that were not doing content-centric projects have already migrated to other platforms that came from the same core code base, such as Camunda and Flowable.
Their corporate priorities around product development are focused on developing their next-gen SaaS experience platform, and building a cloud core engine to migrate existing customers. I’m a bit surprised that they’re this far behind the curve on cloud technology, but they have a pretty significant on-premise customer base for their legacy OnBase product. Having acquired Perceptive (2017) and Nuxeo (2021) in addition to Alfresco (2020), they are also still busy digesting those: supporting (and advancing) each of them as separate products, while planning out a product roadmap for convergence. Interestingly, they have committed to their current 80% remote workforce (which used to be 80% in the office), and are likely learning to “eat their own dog food” and therefore coming to a full understanding of what their customers are facing as they move to cloud platforms to support remote work. If nothing else, they could become their own best testbed for cloud.
There was a panel hosted by Ed McQuiston, Chief Commercial 1Officer (which includes sales, marketing, customer success and a few other things); panels are difficult to capture in a post like this, but there was an interesting bit of the discussion on how automation is becoming paramount: costs are being cut after a couple of years of “drunken sailor” spending just to stay in business, and if you don’t start automating, you’re going to be in trouble. The easy stuff needs to get automated, to leave the hard stuff for the staff remaining after the Great Resignation. In my presentation tomorrow, I’m going to be talking about the “automation imperative” which expands these ideas a bit more.
I stepped out while they did some roundtable sessions, then returned at the end of the afternoon for the product update with Hyland’s Chief Product Officer, John Phelan. He will be covering some of this same territory in the general keynote tomorrow morning, but I’ve grabbed what I could from this session and can fill in some of the blanks tomorrow. He spoke quite a bit about platform extensibility, allowing many other types of capabilities to plug into Hyland’s content services core. Or rather, cores, since this could be any of their (competing) content services engines. I’m looking forward to hearing more about the roadmap for convergence of the engines; with content engines, this is an tough one because full platform convergence requires a migration pathway — at a reasonable cost — for clients. He showed a slide with different use cases for platform extensibility, being able to plug in RPA, or records management, or intelligent capture, or case management. But not mentioned (obvious to my process-centric ears) was process management, a capability that they now have in the Activiti/Process Services that came with the Alfresco acquisition. Even if they call it workflow, a term that most people in process management feel is a bit too simplistic, it still was missing from his slide. Case management and process management are highly related, but not the same thing, unless you’re going to restrict your process management to case management paradigms in order to have process exist only as an adjunct to content. RPA is, of course, task automation, not process management. I’m seeing a bit of a gap in the strategy, or maybe it’s a terminology issue; I’d like to see a more detailed briefing of the whole platform to gain a better understanding.
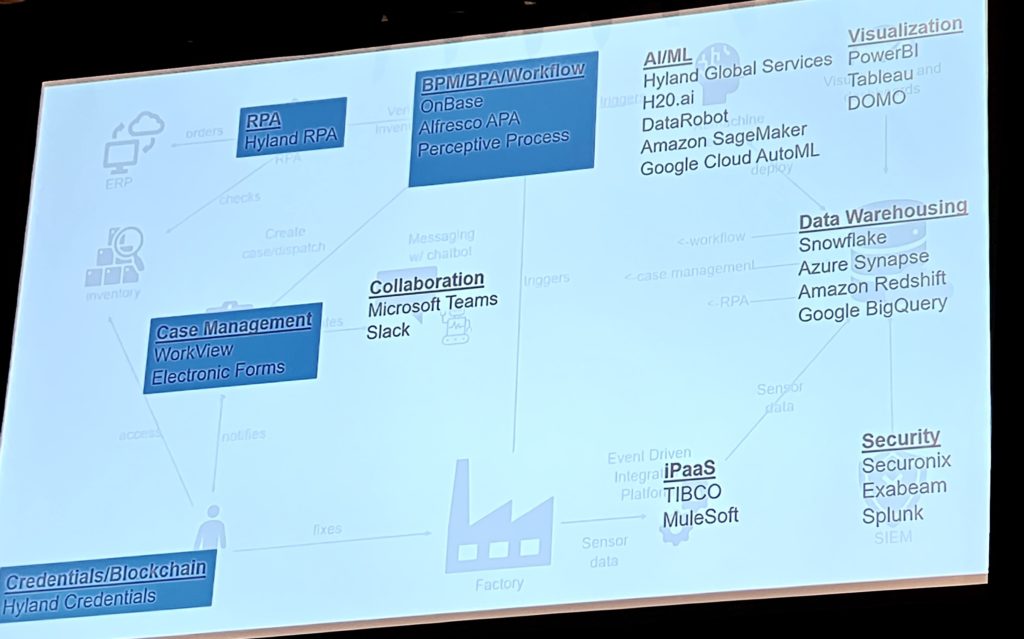
Phelan was followed by Hyland’s Chief Innovayion Officer, Sam Babic, who gave a bit of a review of Gartner’s definition of hyperautomation (a term that still makes me giggle a bit in spite of having written a paper on the topic recently). Every vendor has their spin on hyperautomation, and Babic spoke about some of the practical aspects of how to implement solutions in a hyperautomation fashion: leveraging multiple leading-edge technologies (IoT, event-driven architecture, AI/ML, RPA, chatbots, etc.) to be able to swiftly create new business solutions. He does include workflow as a (I believe) headless orchestration of triggers that can then instantiate a case, so that’s something, and included the phrase BPM/BPA/Workflow on his product capability word salad slide. Obviously, they have a very content-centric view of the product space, whereas I’m a column 2 kind of girl.
I’ll be presenting tomorrow afternoon in the Business Transformation track — in the least desirable time spot at the end of the day, where I’m contractually obligated to tell the attendees that I’m the only thing standing between them and the bar — with on the topic of maximizing success in automation projects. I’ve spent 30+ years building automation software (content and process) and building solutions using that same type of software, so have seen a lot of things go wrong, and some things go right. If you’re here at CommunityLIVE, stop by to hear about my best practices, plus a few anti-patterns to watch out for.
Back in May, I did a webinar with ASG Technologies on the importance and handling of (unstructured) content within processes. Almost every complex customer-facing process contains some amount of unstructured content, and it’s usually critical to the successful completion of one or more processes. But if you’re going to have unstructured content attached to your processes, you need to be concerned about governance of that content to ensure that people have the right amount of information to complete a step, but not so much that it violates the customer’s privacy. If everything is in a well-behaved content management system, that governance is an easier task — although still often mishandled — but when you start adding in network file shares and direct process instance attachments, it gets a lot tougher.
I also wrote a white paper for them on the topic, and I just noticed that it’s been published at this link (registration required). From the abstract of the paper:
Process automation typically provides control over what specific tasks and structured data are available to each participant in the process, but the content that drives and supports the process must also be served up to participants when necessary for completing a task. This requires governance policies that control who can access what content at each point in a process, based on security rules, privacy laws and the specific participant’s access clearance.
In this paper, we examine what is required for a governance-first approach to content within customer-facing processes, and finding the “Goldilocks balance” of just the right amount of information available to the right people at the right time
Head on over and take a look.
ASG is holding their Evolve21 user conference as a virtual event in October, you can learn more about that here.
The last time that I was on a plane was mid-February, when I attended the OpenText analyst summit in Boston. For people even paying attention to the virus that was sweeping through China and spreading to other Asian countries, it seemed like a faraway problem that wasn’t going to impact us. How wrong we were. Eight months later, many businesses have completely changed their products, their markets and their workforce, much of this with the aid of technology that automates processes and supply chains, and enables remote work.
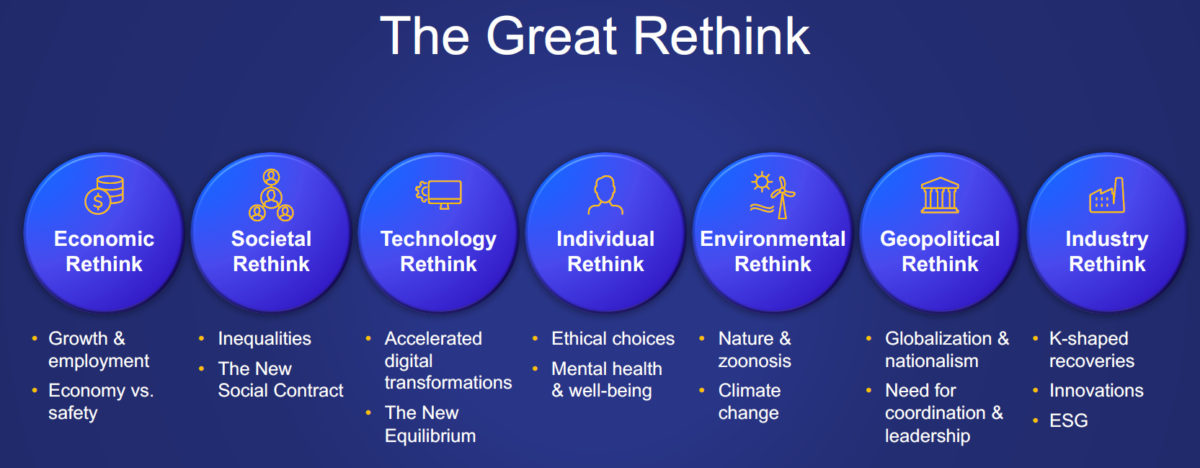
By early April, OpenText had already moved their European regional conference online, and this week, I’m attending the virtual version of their annual OpenText World conference, in a completely different world than in February. Similar to many other vendors that I cover (and have attended virtual conferences for in the past several months), OpenText’s broad portfolio of enterprise automation products has the opportunity to make gains during this time. The conference opened with a keynote from CEO Mark Barrenechea, “Time to Rethink Business”, highlighting that we are undergoing a fundamental technological (and societal) disruption, and small adjustments to how businesses work aren’t going to cut it. Instead of the overused term “new normal”, Barrenechea spoke about “new equilibrium”: how our business models and work methods are achieving a stable state that is fundamentally different than what it was prior to 2020. I’ve presented about a lot of these same issues, but I really like his equilibrium analogy with the idea that the landscape has changed, and our ball has rolled downhill to a new location.
He announced OpenText Cloud Edition (CE) 20.4, which includes five domain-oriented cloud platforms focused on content, business network, experience, security and development. All of these are based on the same basic platform and architecture, allowing them to updated on a quarterly basis.
The Content Cloud provides the single source of truth across the organization (via information federation), enables collaboration, automates processes and provides information governance and security.
The Business Network Cloud deals directly with the management and automation of supply chains, which has increased in importance exponentially in these past several months of supply chain disruption. OpenText has used this time to expand the platform in terms of partners, API integrations and other capabilities. Although this is not my usual area of interest, it’s impossible to ignore the role of platforms such as the Business Network Cloud in making end-to-end processes more agile and resilient.
The Experience Cloud is their customer communications platform, including omnichannel customer engagement tools and AI-driven insights.
The Security and Protection Cloud provides a collection of security-related capabilities, from backup to endpoint protection to digital forensics. This is another product class that has become incredibly important with so many organizations shifting to work from home, since protecting information and transactions is critical regardless of where the worker happens to be working.
The Developer Cloud is a new bundling/labelling of their software development (including low-code) tools and APIs, with 32 services across eight groupings including capture, storage, analysis, automation, search, integration, communicate and security. The OpenText products that I’ve covered in the past mostly live here: process automation, low-code application development, and case management.
Barrenechea finished with their Voyager program, which appears to be an enthusiastic rebranding of their training programs.
Next up was a prerecorded AppWorks strategy and roadmap with Nic Carter and Nick King from OpenText product management. It was fortunate that this was prerecorded (as much as I feel it decreases the energy of the presentation and doesn’t allow for live Q&A) since the keynote ran overtime, and the AppWorks session could be started when I was ready. Which begs the question why it was “scheduled” to start at a specific time. I do like the fact that OpenText puts the presentation slides in the broadcast platform with the session, so if I miss something it’s easy to skip back a slide or two on my local copy.
Process Suite (based on the Cordys-heritage product) was rolled into the AppWorks branding starting in 2018, and the platform and UI consolidated with the low-code environment between then and now. The sweet spot for their low-code process-centric applications is around case management, such as service requests, although the process engine is capable of supporting a wide range of application styles and developer skill levels.
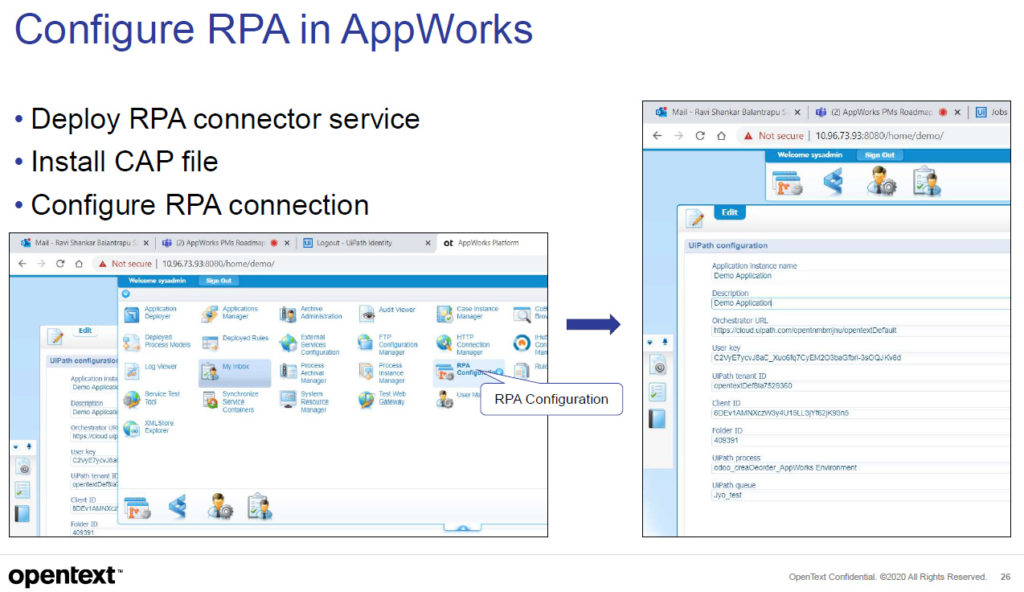
They walked through a number of developer and end-user feature enhancements in the 20.4 version, then covered new automation features. This includes enhanced content and Brava viewer integration, but more significantly, their RPA service. They’re not creating/acquiring their own RPA tool, or just focusing on one tool, but have created a service that enables connectors to any RPA product. Their first connector is for UiPath and they have more on the roadmap — very similar rollout to what we saw at CamundaCon and Bizagi Catalyst a few weeks ago. By release 21.2 (mid-2021), they will have an open source RPA connector so that anyone can build a connector to their RPA of choice if it’s not provided directly by OpenText.
There are some AppWorks demos and discussion later, but they’re in the “Demos On Demand” category so I’m not sure if they’re live or “live”.
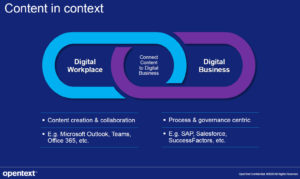
I checked out the content service keynote with Stephen Ludlow, SVP of product management; there’s a lot of overlap between their content, process, AI and appdev messages, so important to see how they approach it from all directions. His message is that content and process are tightly linked in terms of their business usage (even if on different systems), and business users should be able to see content in the context of business processes. They integrate with and complement a number of mainstream platforms, including Microsoft Office/Teams, SAP, Salesforce and SuccessFactors. They provide digital signature capabilities, allowing an external party to digitally sign a document that is stored in an OpenText content server.
An interesting industry event that was not discussed was the recent acquisition of Alfresco by Hyland. Alfresco bragged about the Documentum customers that they were moving onto Alfresco on AWS, and now OpenText may be trying to reclaim some of that market by offering support services for Alfresco customers and provide an OpenText-branded version of Alfresco Community Edition, unfortunately via a private fork. In the 2019 Forrester Wave for ECM, OpenText takes the lead spot, Microsoft and Hyland are some ways back but still in the leaders category, and Alfresco is right on the border between leaders and strong performers. Clearly, Hyland believes that acquiring Alfresco will allow it to push further up into OpenText’s territory, and OpenText is coming out swinging.
I’m finding it a bit difficult to navigate the agenda, since there’s no way to browse the entire agenda by time, but it seems to require that you know what product category that you’re interested in to see what’s coming up in a time-based format. That’s probably best for customers who only have one or two of their products and would just search in those areas, but for someone like me who is interested in a broader swath of topics, I’m sure that I’m missing some things.
That’s it for me for today, although I may try to tune in later for Poppy Crum‘s keynote. I’ll be back tomorrow for Muhi Majzoub’s innovation keynote and a few other sessions.