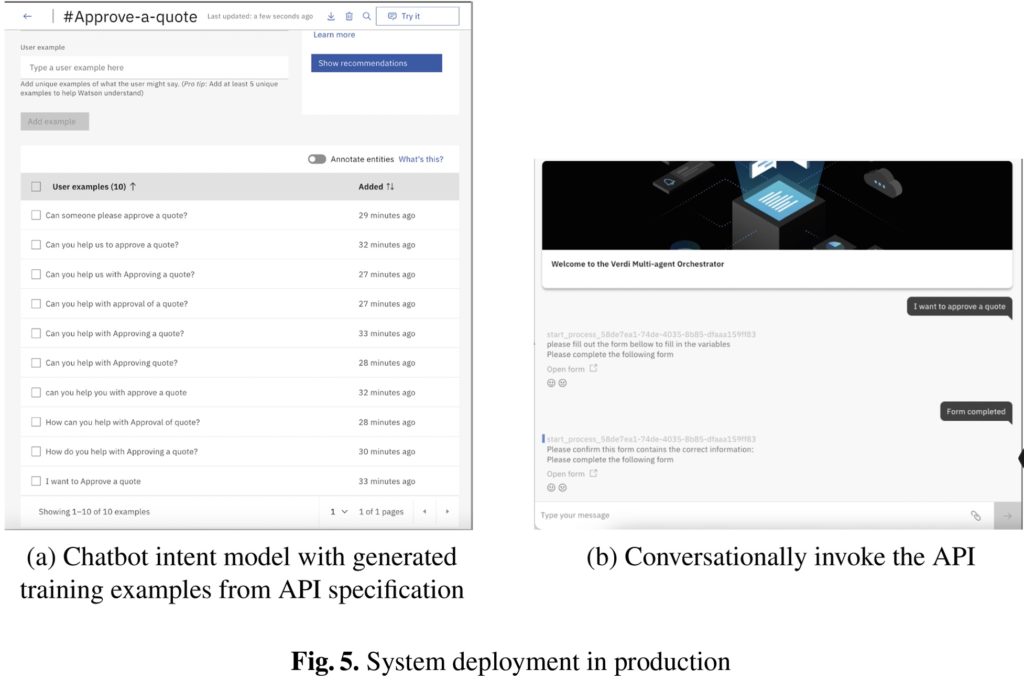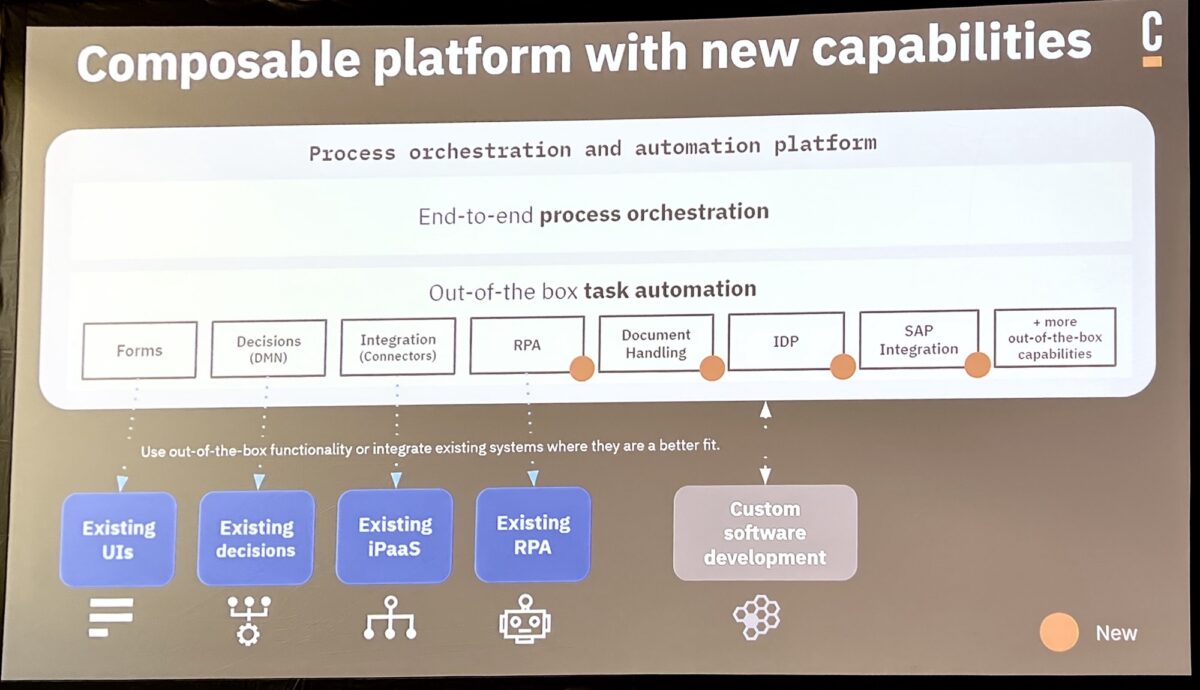
We’re kicking off day 2 of CamundaCon in New York with the technical keynote, featuring Bernd Rücker, Co-Founder and Chief Technologist; Daniel Meyer, CTO; and Bastian Körber, Principal Product Manager. Bernd opened the session talking about organizations’ conflicting goals to continue innovating their business while also transforming and modernizing their technical architecture. This was an interesting although possibly unintentional tie-in with the SAP integration session that I attended at the end of the day yesterday, where the migration example from SAP ECC to S/4HANA falls into the latter category, but the business leaders are pushing for the business innovation and don’t want to “waste” time on technology modernization. Adding RPA/AI bots and moving to an orchestrated architecture allows for gradual architecture modernization while making the business processes much more agile by externalizing the processes from the legacy systems.
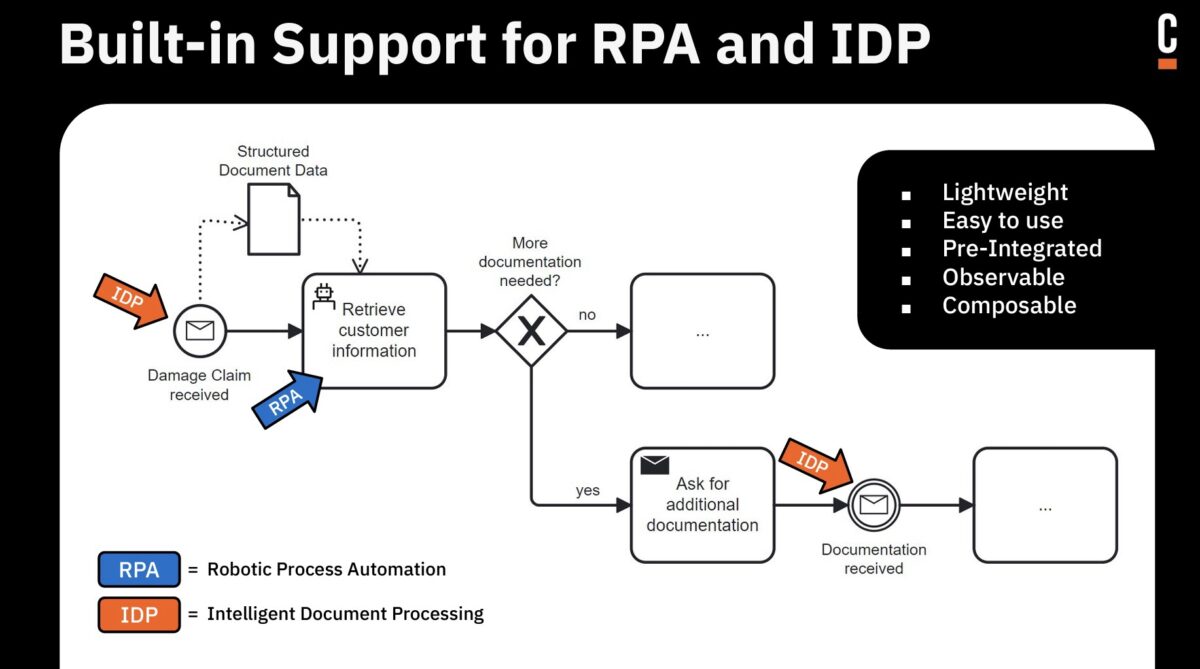
We saw a demonstration of claims handling showing their upcoming IDP (Intelligent Document Processing) capability, which calls AI to extract information from receiving documents then figures out what to do with the information. The goal is to map that information onto the data elements in the process model, which then allows documents to be automatically integrated into processes with little or no human intervention.
We also saw some of their upcoming lightweight RPA capabilities built on the open source Robot framework. The addition of IDP and RPA — necessary if Camunda wants to work their way into the new Gartner BOAT category — are intended to be relatively lightweight, and not replace the need for more robust IDP and RPA products if an organization is already using third-party products, which can just be treated as external services to be orchestrated as part of a Camunda process.. Hopefully these will actually be “good enough” to be generally used, rather than being toy versions that are just there to chase the analyst categorization that we’ve seen from many other vendors in the past.
The demo also includes other AI calls and SAP integration, highlighting their new/upcoming features. Worth watching the replay of the demo when the sessions are released next week to see Bernd walk through it all (with a bit of help from Daniel).
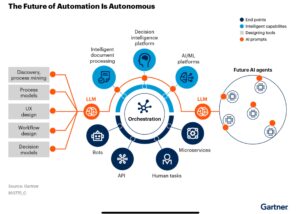
Daniel took over to discuss the next generation of automation platform, which expands their orchestration environment through the addition of AI at a number of different points. This is exposed in the modeler as IDP, RPA and AI connectors and services.

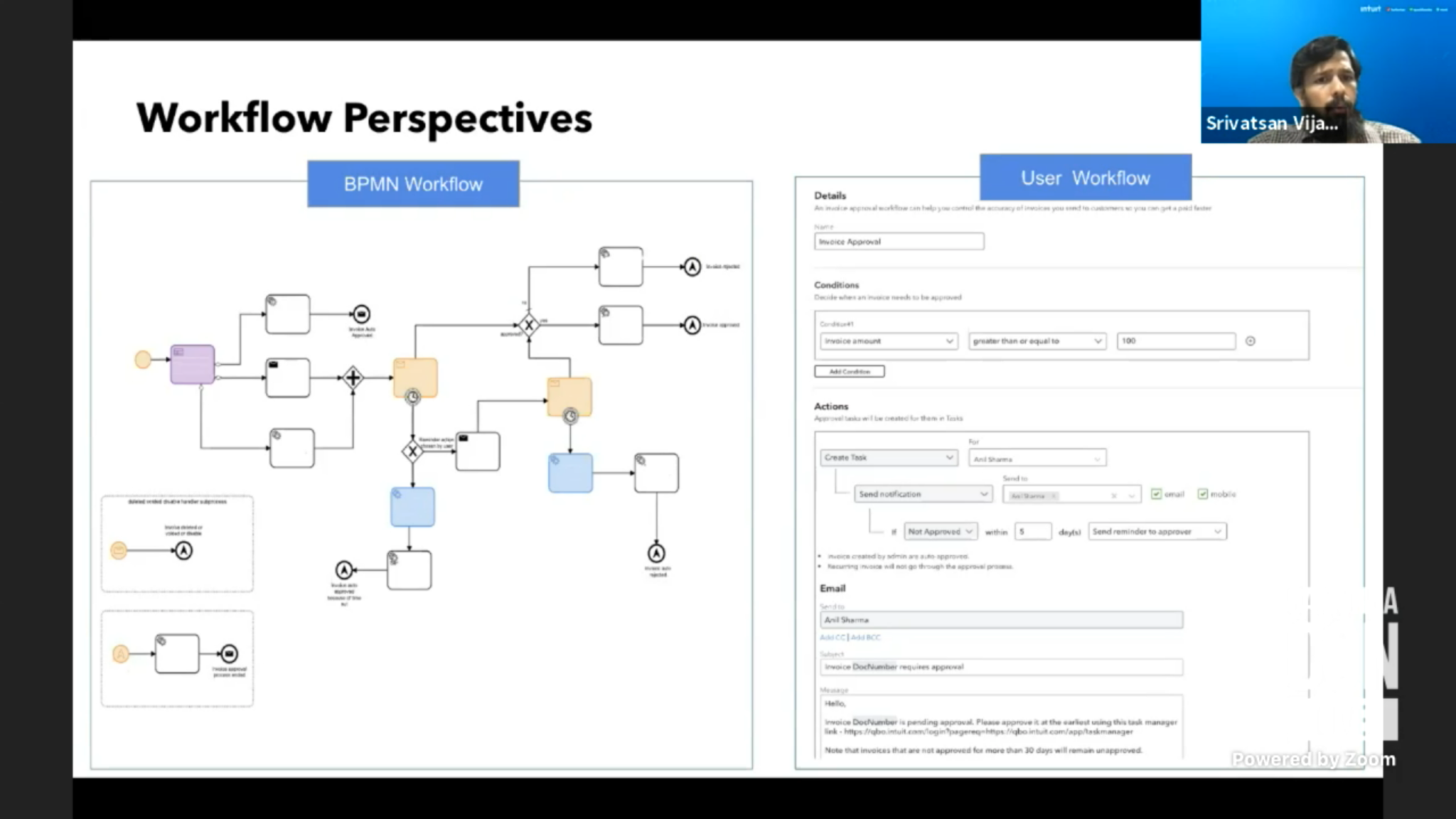
Bastian described the AI offerings in more detail, starting with the BPMN Copilot, which can be used to create BPMN diagrams based on text descriptions. There have been natural language processing interfaces to BPMN model generation around for quite a while, both in research and as some released products, but this adds LLMs behind the text processing for better results — the more text that is provided, the less AI hallucination. Output is not (necessarily) intended to be the final version, but a fairly advanced starting point for a human modeler to then continue modifying and completing. The LLM is using publicly available information to provide best practices for process models. The BPMN Copilot demos well but feels like a bit of a party trick. A cool party trick, but maybe not something that’s going to be mainstream for a while. Some of the underlying technology can definitely be used, however, for automated process optimization or at least optimization recommendations, by bringing process mining data and some natural language to bear.
Daniel referred to Forrester’s definitions of AI Agents (task automation) and Agentic AI systems (orchestration of multiple types of tasks including AI agents). AI agents may be descendants of RPA bots, where some level of AI is already in use, while Agentic AI is focused on autonomous systems that optimize themselves without human intervention.

We also saw a demo of a travel booking process that uses AI agents to organize, research and present options based on a general description of a desired trip booking. These agents are orchestrated into a process with some human touch points, where the AI options are shown as recommendations: calls to third-party AI/LLMs as part of an orchestrated process, demonstrating AI agents and agentic AI in the context of E2E business orchestration
There was another example of a claims process with an ad hoc subprocess, blending deterministic and ad hoc in the same process where AI can be used to decide which activities are executed in which order within the ad hoc subprocess. The ad hoc subprocess has been in BPMN for a long time, but usually used to represent case management with human decisions or standard decision management on which activity to perform next; now, an LLM acts as the Next Best Action selector.

Daniel finished up with release dates: all of the features discussed will be released in 8.7 or 8.8 within the 2025 calendar year.
As we kick off the second day with an informative keynote, I also want to give a shout out to the Camunda events team, who keep everything running smoothly when I’m sure there are mini disasters happening behind the scenes every minute. Kudos!