Lots of interesting discussion, and it was fun to hear other perspectives from a large SI (Infosys) and a customer (PershingX) on the panel with me. Thanks to Camunda for the invitation, and my first European trip in almost three years!
I realize that I’m completely remiss for not posting about last week’s DecisionCAMP, but in my defense, I was co-hosting it and acting as “master of ceremonies”, so was a bit busy. This was the third year for a virtual DecisionCAMP, with a plan to be back in person next year, in Oslo. And speaking of in-person conferences, I’m in Berlin! Yay! I dipped my toe back into travel three weeks ago by speaking at Hyland’s CommunityLive conference in Nashville, and this week I’m on a panel at Camunda’s annual conference. I’ve been in Berlin for this conference several times in the past, from the days when they held the Community Day event in their office by just pushing back all the desks. Great to be back and hear about some of their successes since that time.
Day 1 started with an opening keynote by Jakob Freund, Camunda’s CEO. This is a live/online hybrid conference, and considering that Camunda did one of the first successful online conferences back in 2020 by keeping it live and real, this is shaping up to be a forerunner in the hybrid format, too. A lot of companies need to learn to do this, since many people aren’t getting back on a plane any time soon to go to a conference when it can be done online just as well.
Anyway, back to the keynote. Camunda just published the Process Orchestration Handbook, which is a marketing piece that distills some of the current messaging around process automation, and highlights some of the themes from Jakob’s keynote. He points out the problems with a lot of current process automation: there’s no end-to-end automation, no visibility into the overall process, and little flexibility to rework those processes as business conditions change. As a result, a lot of process automation breaks since it falls over whenever there’s a problem outside the scope of the automation of a specific set of tasks.
Jakob focused on a couple of things that make process orchestration powerful as a part of business automation: endpoint diversity (being able to connect a lot of different types of tasks into an integrated process) and process complexity (being able to include dynamic parallel execution, event-driven message correlation, and time-based escalation). These sound pretty straightforward, and for those of us who have been in process automation for a long time these are accepted characteristics of BPMN-based processes, but these are not the norm in a lot of process orchestration.
He also walked through the complexities that arise due to long-running processes, that is, anything that involves manual steps with knowledge workers: not the same as straight-through API-only process orchestration that doesn’t have to worry about state persistence. There are a few good customer stories here this week that bring all of these things together, and I plan to be attending some of those sessions.
He presented a view of the process automation market: BPMS, low-code platforms, process mining, iPaaS/integration, RPA, microservices orchestration, and process orchestration. Camunda doesn’t position itself in BPMS any more – mostly since the big analysts have abandoned this term – but in the process orchestration space. Looking at the intersection between the themes of endpoint diversity and process complexity that he talked about earlier, you can see where different tools end up. He even gives a nod to Gartner’s hyperautomation term and how process orchestration fits into the tech stack.
He finished up with a bit of Camunda’s product vision. They released V8 this year with the Zeebe engine, but much more than that is under development. More low-code especially around modeling and front-end human task technology, to enable less technical developers. Decision automation tied into process orchestration. And stronger coverage of AI, process mining and other parts of the hyperautomation tech stack through partnerships as well as their own product development.
Definitely some shift in the messaging going on here, and in some of Camunda’s direction. A big chunk of their development is going into supporting low-code and other “non-developer” personas, which they resisted for many years. They have a crossover point for pro-code developers to create connectors that are then used by low-code developers to assemble into process orchestrations – a collaboration that has been recognized by larger vendors for some time. Sensible plans and lots of cool new technology.
The rest of the day is pretty packed, and I’m having trouble deciding which sessions to attend since there are several concurrent that all sound interesting. Since most of them are also virtual for remote attendees, I assume the recordings will be available later and I can catch up on what I missed. It’s not too late to sign up to attend the rest of today and tomorrow virtually, or to see the recorded sessions after the fact.
Hey, I gave a presentation yesterday, first time in person in almost three years! Here’s the slides, and feel free to contact me if you have questions. I can’t figure out how to get the embed short code on mobile, but when I’m back in the office I’ll give it another try and you may see the slideshow embedded below. Update: found the short code!
This might be the only breakout session that I make it to today, since I’m in an executive Q&A after this, then need a bit of time for final preparations for my own session later this afternoon. The insurance industry session was presented by Richard Medina of Doculabs, with the title “Don’t Just Survive – Thrive”, a phrase that I used quite a bit in talking about digital business during the pandemic era to stress that it’s not just about doing the minimum possible to survive, but leverage the new technologies and methods to go far beyond that and become a market leader. Here, he was specifically talking about digital insurance operations, which is coincidentally the use case that I will cover in my presentation is about insurance claims.
He started with a slide defining intelligent automation, specifically referencing workflow (process orchestration), RPA, intelligent document processing, natural language processing, and process mining, since these are the specific technologies that Doculabs covers. There was quite a bit on their market and methods, but he came back to a key point for those in the audience: a lot of organizations didn’t consider content management as a real part of digital transformation. So wrong. In applications like insurance claims, content is core to the process: the entire process of handling a claim is based on populating the claims file with all of the necessary documentation to support the claim decision. It doesn’t mean that all of this content is on paper any more, or even ever exists on paper within the organization: forms are created online and e-signed, spreadsheets are used to document a full statement of loss, and policyholders upload images related to their claim. This is, of course, not the same as claims operations of old, where everything was on paper in huge file folders, occasionally with the addition of a CD that holds some photos of damage, although those were often printed for the file. E-mails would be printed out and added to the paper folder.
This brings some challenges to insurance operations, particularly claims where there may be rich media involved. Not only do paper and possibly multiple online document repositories need to be consolidated (via merging or federation), but they also need to include other types of unstructured content: photos, videos, social media conversations, and more. The core content engine(s) needs to support all of this, but there’s much more: it needs to be cloud-based for today’s remote workforce, include NLP and AI during intelligent capture for automatic content classification and extraction, have process automation to move the content through its lifecycle and integrate with line-of-business systems, and include chatbots for simpler interactions with policyholders. Medina talked about the unicorn of intelligent automation applied to documents: AI/ML, intelligent capture, RPA, and BPM (orchestration). He walked through a couple of scenarios on policy administration, servicing and claims, showing how different technologies come into play at each point in these processes.
He showed some of the issues to consider for different levels of transformation at each stage in a potential roadmap, starting with content ingestion (capturing content, automating completion checklists, and integrating the content with the LOB systems), then workflow. He finished up with a bit on process mining to show how it can be used to introspect your current processes, do some root cause analysis, and optimize the process. A flying tour through how many of the technologies being discussed here this week can be applied in insurance applications.
If you’re interested in some of the best practices around projects involving these technologies, check out my presentation at 4:45pm today on maximizing success in business automation projects.
I’ve been remiss with blogging the past couple of months, mostly because I’ve been involved in several pretty cool projects that have been keeping me busy. As I mentioned in yesterday’s post, I recently wrote a paper for Flowable about end-to-end automation and the business model transformation that it enabled.
I’ve been working on a video series for a process mining startup, Futuroot, which specializes in process intelligence for SAP systems. We’re doing these as conversational videos between me and a couple of the Futuroot team, each video about 20 minutes of free-ranging conversation. In the first episode, I talk with Rajee Bhattacharyya, Futuroot’s Chief Innovation Officer, and Anand Argade, their Director of Product Development. Here’s a short teaser from the video:
You can sign up here to watch the entire video and be notified of the future ones as they are published. We’ve just recorded the second one, so watch for that coming out soon.
I recently created a paper for Flowable on end-to-end automation, including a look at how the Gartner “hyperautomation” term fits into the picture. End-to-end automation is really about enabling business model transformation, not just making the same widgets a little bit faster, and I walk through some of the steps and technologies that are required.
Check it out on the Flowable site at the link above (registration required).
I first met Signavio CEO Gero Decker in 2008, when he was a researcher at Hasso Platner Institut and emailed me about promoting their BPMN poster — a push to have BPMN (then version 1.1) recognized as a standard for process modeling. I attended the academic BPM conference in Milan that year but Gero wasn’t able to attend, although his name was on a couple of that year’s modeling-related demo sessions and papers related to Oryx, an open source process modeling project. By the 2009 conference in Ulm we finally met face-to-face, where he told me about what he was working on, process modeling ideas that would eventually evolve into Signavio. By the 2010 BPM conference in Hoboken, he was showing me a Signavio demo, and we ended up running into each other at many other BPM events over the years, as well as having many online briefings as they released new products. The years of hard work that he and his team have put into Signavio have paid off this week with the announcement of Signavio’s impending acquisition by SAP (Signavio press release, SAP press release). There have been rumors floating around for a couple of days, and this morning I had the chance for a quick chat with Gero in advance of the official announcement.
The combination of business process intelligence from SAP and Signavio creates a leading end-to-end business process transformation suite to help our customers achieve the requirements needed to gain a competitive edge.
Luka Mucic, CFO of SAP
SAP is launching RISE with SAP today, with the Signavio acquisition a part of the announcement. RISE with SAP is billed as “business transformation as a service”, providing business process redesign (including Signavio), technical migration (which appears to be a push to get reluctant customers onto their current platform), and building an intelligent enterprise (which is mostly a cloud infrastructure message).
This is a full company acquisition, including all Signavio employees (numbering about 500). Gero and the only other co-founder still at Signavio, CTO Willi Tscheschner, will continue in their roles to drive forward the product vision and implementation, becoming part of SAP’s relatively new Business Process Intelligence unit, which is directly under the executive board. Since that unit previously contained about 100 people, the Signavio acquisition will swell those ranks considerably, and Gero will co-lead the unit with the existing GM, Rouven Morato. A long-time SAP employee, Morato can no doubt help navigate the sometimes murky organizational waters that might otherwise trip up a newcomer. Morato was also a significant force in SAP’s own internal transformation through analytics and process intelligence, moving them from the dinosaur of old to a (relatively) more nimble and responsive company, hence understands the importance of products like Signavio’s in transforming large organizations.
Existing Signavio customers probably won’t see much difference right now. Over time, capabilities from SAP will become integrated into the process intelligence suite, such as deeper integration to introspect and analyze SAP S/4 processes. Eventually product names and SKUs will change, but as long as Gero is involved, you can expect the same laser focus on linking customer experience and actions back to processes. The potential customer base for Signavio will broaden considerably, especially as they start to offer dashboards that collect information on processes that include, but are not limited to, the SAP suite. In the past, SAP has been very focused on providing “best practice” processes within their suite; however, if there’s anything that this past year of pandemic-driven disruption has taught us, those best practices aren’t always best for every organization, and processes always include things outside of SAP. Having a broader view of end-to-end processes will help organizations in their digital transformations.
Obviously, this is going to have an impact on SAP’s current partnership with Celonis, since the SAP Process Mining by Celonis would be directly in competition with Signavio’s Process Intelligence. Of course, Signavio also has a long history with SAP, but their partnership has not been as tightly branded as the Celonis arrangement. Until now. Celonis arguably has a stronger process mining product than Signavio, especially with their launch into task mining, and have a long history of working with SAP customers on their process improvement. There’s always room for partners that provide different functionality even if somewhat in competition with an internal functionality, but Celonis will need to build a strong case for why a SAP customer should pick them over the Signavio-based, SAP-branded process intelligence offering.
Keep in mind that SAP hasn’t had a great track record of process products that aren’t part of their core suite: remember SAP NetWeaver BPM? Yeah, I didn’t think so. However, Signavio’s products are focused on modeling and analyzing processes, not automating them, so they might have a better chance of being positioned as discovering improvements to processes that are automated in the core suite, as well as giving SAP more visibility into how their customers’ businesses run outside of the SAP suite. There’s definitely great potential here, but also the risk of just becoming buried within SAP — time will tell.
Disclosure: Signavio has been a client of mine within the last year for creating a series of webinars. I was not compensated in any way for writing this post (or anything else on this blog, for that matter), and it represents my own opinions.
The key to designing metrics and incentives is to figure out the problems that the workers are there to solve, which are often tied in some way to customer satisfaction, then use that to derive performance metrics and employee incentives.
There are a lot of challenges with figuring out how to measure and reward experience and innovative thinking: if it’s done wrong, then companies end up measuring how long you spent with a particular app open on your screen, or how many times you clicked on your keyboard.
We’re going through a lot of process disruption right now, and smart companies are using this opportunity to retool the way that they do things. They also need to be thinking about how their employee incentives are lined up with that redesign, and whether business goals are being served appropriately.
Process automation has emerged as a linchpin for digital transformation, powering innovation across a company. Process automation is equally sought after to improve an organization’s top line as well as its bottom line – helping to improve customer service, lower costs and drive business growth.
I’m definitely on board with this statement. Companies that are most likely to emerge successfully from the current disruption are taking a hard look at their business processes, and considering how to include more intelligent automation.
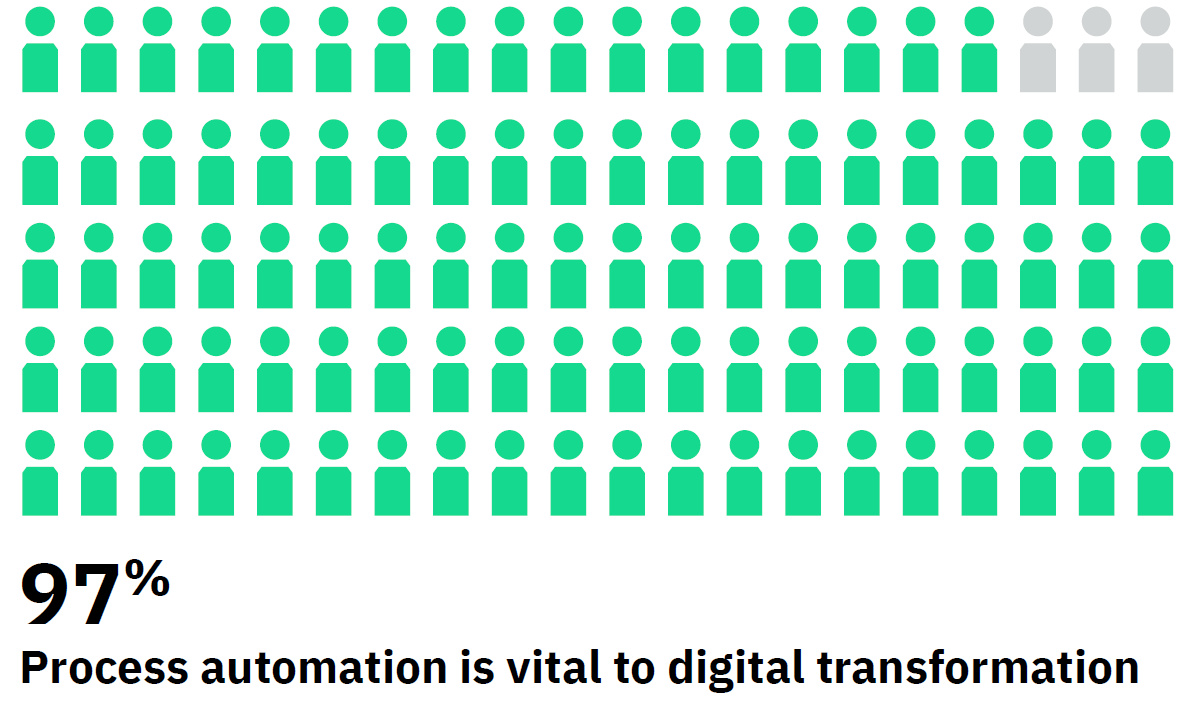
The report is based on the results of a survey that they commissioned, which included 400 IT decision makers in the US and Europe. Almost all of those interviewed (97%) agreed that process automation is vital to digital transformation, and I was encouraged that half of of the current initiatives are focused on growth rather than just efficiency or firefighting. As I’ve been saying for a while, efficiency and productivity are table stakes: you have to consider those, but you’re not going to get the biggest benefit until you start looking at what intelligent automation can do for top-line growth and customer satisfaction.
The survey included a few questions on the impact of the pandemic, with 80% of respondents saying that they are doing more automation because of remote work and (I assume) fewer workers in some cases. This is not unexpected, with 68% reporting that key business processes had breakdowns due to remote work, and most companies are working harder on automation initiatives in order to survive the current disruption.
When I write a present about the type of digital transformation that the pandemic is forcing on firms in order to survive, I usually use examples from financial services and insurance, since that’s where I do most of my consulting. However, we see examples all around us as consumers, as every business of every size struggles to transform to an online model to be able to continue providing us with goods and services. And once both the consumers and the businesses see the benefits of doing some (not all) transactions online, there will be no going back to the old way of doing things.
I recently moved, and just completed the closing on the sale of my previous home. It’s been quite a while since I last did this, but it was always (and I believe still was until a few months ago) a very paper-driven, personal service type of transaction. This time was much easier, and almost all online; in fact, I’ve never even met anyone from my lawyer’s office face-to-face, I didn’t use a document courier, and I only saw my real estate agent in person once. All documents were digitally signed, and I had a video call with my lawyer me to walk through the documents and verify that it was me doing the signing. I downloaded the signed documents directly, although the law office would have been happy to charge me to print and mail a copy. To hand over the keys, my real estate agent just left their lockbox (which contained the keys for other agents to do showings) and gave the code to my lawyer to pass on to the other party once the deal was closed. Payments were all done as electronic transfers.
My lawyer’s firm is obviously still struggling with this paradigm, and provided the option to deliver paper documents, payments and keys by courier (in fact, I had to remind them to remove the courier fee from their standard invoice). In fact, they no longer offer in-person meetings: it has to be a video call. Yes, you can still sign physical documents and courier them back and forth, but that’s going to add a couple of days to the process and is more cumbersome than signing them digitally. Soon, I expect to see pricing from law firms that strongly encourages their clients to do everything digitally, since it costs them more to handle the paper documents and can create health risks for their employees.
Having gone through a real estate closing once from the comfort of my own home, I am left with one question: why would we ever go back to the old way of doing this? I understand that there are consumers who won’t or can’t adopt to new online methods of doing business with organizations, but those are becoming fewer every day. That’s not because the millennial demographic is taking over, but because people of all ages are learning that some of the online methods are better for them as well as the companies that they deal with.
Generalizing from my personal anecdote, this is happening in many businesses now: they are making the move to online business models in response to the pandemic, then finding that for many operations, this is a much better way of doing things. Along the way, they may also be automating some processes or eliminating manual tasks, like my lawyer’s office eliminating the document handling steps that used to be done. Not just more efficient for the company, but better for the clients.
As you adjust your business to compensate for the pandemic, design your customer-facing processes so that they make it easier (if possible) for your customer to do things online than the old way of doing things. That will almost always be more efficient for your business, and can greatly improve customer satisfaction. This does not mean that you don’t need people in your organization, or that your customers can’t talk to someone when required: automating processes and tasks means that you’re freeing up people to focus on resolving problems and improving customer communications, rather than performing routine tasks.
As one of my neighbourhood graffiti artists so eloquently put it, “6 feet apart but close 2 my ❤”.