This is now my third day attending IBM’s online Think 2020 conference: I attended the analyst preview on Monday, then the first day of the conference yesterday. We started the day with Mark Foster, SVP of IBM Services, giving a keynote on building resilient and smarter businesses. He pointed out that we are in uncertain times, and many companies are still figuring out whether to freeze new initiatives, or take advantage of this disruption to build smarter businesses that will be more competitive as we emerge from the pandemic. This message coming from a large software/services vendor is a bit self-serving, since they are probably seeing this quarter’s sales swirling down the drain, but I happen to agree with him: this is the time to be bold with digital transformation. He referred to what can be done with new technologies as “business process re-engineering on steroids”, and said that it’s more important than ever to build more intelligent processes to run our organizations. Resistance to change is at a particular low point, except (in my experience) at the executive level: workers and managers are embracing the new ways of doing things, from virtual experiences to bots, although they may be hampered somewhat by skittish executives that think that change at a time of disruption is too risky, while holding the purse strings of that change.
 He had a discussion with Svein Tore Holsether, CEO of Yara, a chemical company with a primary business in nitrogen crop fertilizers. They also building informational platforms for sustainable farming, and providing apps such as a hyper-local farm weather app in India, since factors such as temperature and rainfall can vary greatly due to microclimates. The current pandemic means that they can no longer have their usual meetings with farmers — apparently a million visits per year — but they are moving to virtual meetings to ensure that the farmers still have what the need to maximize their crop yields.
He had a discussion with Svein Tore Holsether, CEO of Yara, a chemical company with a primary business in nitrogen crop fertilizers. They also building informational platforms for sustainable farming, and providing apps such as a hyper-local farm weather app in India, since factors such as temperature and rainfall can vary greatly due to microclimates. The current pandemic means that they can no longer have their usual meetings with farmers — apparently a million visits per year — but they are moving to virtual meetings to ensure that the farmers still have what the need to maximize their crop yields.
Foster was then joined by Carol Chen, VP of Global Lubricants Marketing at Shell. She talked about the specific needs of the mining industry for one of their new initiatives, leveraging the ability to aggregate data from multiple sources — many of them IoT — to make better decisions, such as predictive maintenance on equipment fleets. This allows the decisions about a mining operation to be made from a digital twin in the home office, rather than just by on-site operators who may not have the broader context: this improves decision quality and local safety.
 He then talked to Michael Lindsey, Chief Transformation and Strategy Officer at PepsiCo North America, with a focus on their Frito-Lay operations. This operation has a huge fleet, controlling the supply chain from the potato farms to the store. Competition has driven them to have a much broader range of products, in terms of content and flavors, to maintain their 90%+ penetration into the American household market. Previously, any change would have been driven from their head office, moving out to the fringes in a waterfall model. They now have several agile teams based on IBM’s Garage Methodology that are more distributed, taking input from field associates to know what it needed at each point in the supply chain, driving need from the store shelves back to the production chain. The pandemic crisis means that they have had to move their daily/weekly team meetings online, but that has actually made them more inclusive by not requiring everyone to be in the same place. They have also had to adjust the delivery end of their supply chains in order to keep up the need for their products: based on my Facebook feed, there are a lot of people out there eating snacks at home, fueling a Frito-Lay boom.
He then talked to Michael Lindsey, Chief Transformation and Strategy Officer at PepsiCo North America, with a focus on their Frito-Lay operations. This operation has a huge fleet, controlling the supply chain from the potato farms to the store. Competition has driven them to have a much broader range of products, in terms of content and flavors, to maintain their 90%+ penetration into the American household market. Previously, any change would have been driven from their head office, moving out to the fringes in a waterfall model. They now have several agile teams based on IBM’s Garage Methodology that are more distributed, taking input from field associates to know what it needed at each point in the supply chain, driving need from the store shelves back to the production chain. The pandemic crisis means that they have had to move their daily/weekly team meetings online, but that has actually made them more inclusive by not requiring everyone to be in the same place. They have also had to adjust the delivery end of their supply chains in order to keep up the need for their products: based on my Facebook feed, there are a lot of people out there eating snacks at home, fueling a Frito-Lay boom.
Rob Thomas,  SVP of IBM Cloud & Data Platform, gave a keynote on how AI and automation is changing how companies work. Some of this was a repeat from what we saw in the analyst preview, plus some interviews with customers including Mirco Bharpalania, Head of Data & Analytics at Lufthansa, and Mallory Freeman, Director of Data Science and Machine Learning in the Advanced Analytics Group at UPS. In both cases, they are using the huge amount of data that they collect — about airplanes and packages, respectively — to provide better insights into their operations, and perform optimization to improve scheduling and logistics.
SVP of IBM Cloud & Data Platform, gave a keynote on how AI and automation is changing how companies work. Some of this was a repeat from what we saw in the analyst preview, plus some interviews with customers including Mirco Bharpalania, Head of Data & Analytics at Lufthansa, and Mallory Freeman, Director of Data Science and Machine Learning in the Advanced Analytics Group at UPS. In both cases, they are using the huge amount of data that they collect — about airplanes and packages, respectively — to provide better insights into their operations, and perform optimization to improve scheduling and logistics.
He was then joined by Melissa Molstad, Director of Common Platforms, Stata Strategy & Vendor Relations at PayPal. She spoke primarily about their AI-driven chatbots, with the virtual assistants handling 1.4M conversations per month. This relieves the load on customer service agents, especially for simple and common queries, which is especially helpful now that they have moved their customer service to distributed home-based work.
He discussed AIOps, which was already announced yesterday by Arvind Krishna; I posted a bit about that in yesterday’s post including some screenshots from a demo that we saw at the analyst preview on Monday. They inserted the video of Jessica Rockwood, VP of Development for Hybrid Multicloud Management, giving the same demo that we saw on Monday, worthwhile watching if you want to hear the entire narrative behind the screenshots.
Thomas’ last interview segment was with Aaron Levie, CEO of Box, and Stewart Butterfield, CEO of Slack, both ecosystem partners of IBM. Interesting that they chose to interview Slack rather than use it as an engagement channel for the conference attendees. ¯_(ツ)_/¯ They both had interesting things to add on how work is changing with the push to remote cloud-based work, and the pressures on their companies for helping a lot of customers to move to cloud-based collaboration all at once. There seems to be a general agreement (I also agree) that work is never going back to exactly how it was before, even when there is no longer a threat from the pandemic. We are learning new ways of working, and also learning that things that companies thought could not be done effectively — like work from home — actually work pretty well. Companies that embrace the changes and take advantage of the disruption can jump ahead on their digital transformation timeline by a couple of years. One of them quoted Roy Amara’s adage that “we tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run”; as distributed work methods, automation and the supporting technology get a foothold now, they will have profound changes on how work will be done in the future. This is not going to be about which organizations have the most money to spend: it will hinge on the ability and will to embrace AI and automation to remake intelligent end-to-end processes. Software vendors will need to accept the fact that customers want to do best-of-breed assembly of services from different vendors, meaning that the vendors that integrate into a standard fabric are going to do much better in the long run.
I switched over to the industry/customer channel to hear a conversation between Donovan Roos, VP of Enterprise Automation at US Bank, and Monique Ouellette, VP of Global Digital Workplace Solutions at IBM. She invited us at the beginning to submit questions, so this may have been one of the few sessions that has not been prerecorded, although they never seemed to take any audience questions so I’m not sure. Certainly much lower audio and video quality than most of the prerecorded sessions. US Bank has implemented Watson AI-driven chatbots for internal and external service requests, and has greatly reduced wait times for requests where a chatbot can assist with self-service rather than waiting for a live agent. Roos mentioned that they really make use of the IBM-curated content that comes as part of the Watson platform, and many of the issues are resolved without even hitting internal knowledge bases. Like many other banks during the current crisis, they have had to scale up their ability to process small business loans; although he had some interesting things to mention about how they scaled up their customer service operations using AI chatbots, I would also be interested to hear how they have scaled up the back-end processes. He did mention that you need to clean up your business processes first before starting to apply AI, but no specifics.
 I stayed on the industry channel for a presentation on AI in insurance by Sandeep Bajaj, CIO of Everest Re Group. I do quite a bit of work with insurance companies as a technical strategist/architect so have some good insights into how their business works, and Bajaj started with the very accurate statement that insurance is an information-driven industry, both in the sense of standard business information, but also IoT and telematics especially for vehicle and P&C coverage. This provides great opportunities for better insights and decisions based on AI that leverages that data. He believes that AI is no longer optional in insurance because of the many factors and data sources involved in decisions. He did discuss the necessity to review and improve your business processes to find opportunities for AI: it’s not a silver bullet, but needs to have relatively clean processes to start with — same message that we heard from US Bank in the previous presentation.
I stayed on the industry channel for a presentation on AI in insurance by Sandeep Bajaj, CIO of Everest Re Group. I do quite a bit of work with insurance companies as a technical strategist/architect so have some good insights into how their business works, and Bajaj started with the very accurate statement that insurance is an information-driven industry, both in the sense of standard business information, but also IoT and telematics especially for vehicle and P&C coverage. This provides great opportunities for better insights and decisions based on AI that leverages that data. He believes that AI is no longer optional in insurance because of the many factors and data sources involved in decisions. He did discuss the necessity to review and improve your business processes to find opportunities for AI: it’s not a silver bullet, but needs to have relatively clean processes to start with — same message that we heard from US Bank in the previous presentation.  Everest reviewed some of their underwriting processes and split the automation opportunities between robotic process automation and AI, although I would have thought that using them together, as well as other automation technologies, could provide a better solution. They used an incremental approach, which let them see results sooner and feed back initial results into ongoing development. One side benefit is that they now capture much more of the unstructured information from each submission, whereas previously they would only capture the information entered for those submissions that led to business; this allows them to target their marketing and pricing accordingly. They’re starting to use AI-driven processes for claims first notice of loss (FNOL is a classic claims problem) in addition to underwriting, and are seeing operational efficiency improvements as well as better accuracy and time to market. Looking ahead, he sees that AI is here to stay in their organization since it’s providing proven value. Really good case study; worth watching if you’re in the insurance business and want to see how AI can be applied effectively.
Everest reviewed some of their underwriting processes and split the automation opportunities between robotic process automation and AI, although I would have thought that using them together, as well as other automation technologies, could provide a better solution. They used an incremental approach, which let them see results sooner and feed back initial results into ongoing development. One side benefit is that they now capture much more of the unstructured information from each submission, whereas previously they would only capture the information entered for those submissions that led to business; this allows them to target their marketing and pricing accordingly. They’re starting to use AI-driven processes for claims first notice of loss (FNOL is a classic claims problem) in addition to underwriting, and are seeing operational efficiency improvements as well as better accuracy and time to market. Looking ahead, he sees that AI is here to stay in their organization since it’s providing proven value. Really good case study; worth watching if you’re in the insurance business and want to see how AI can be applied effectively.
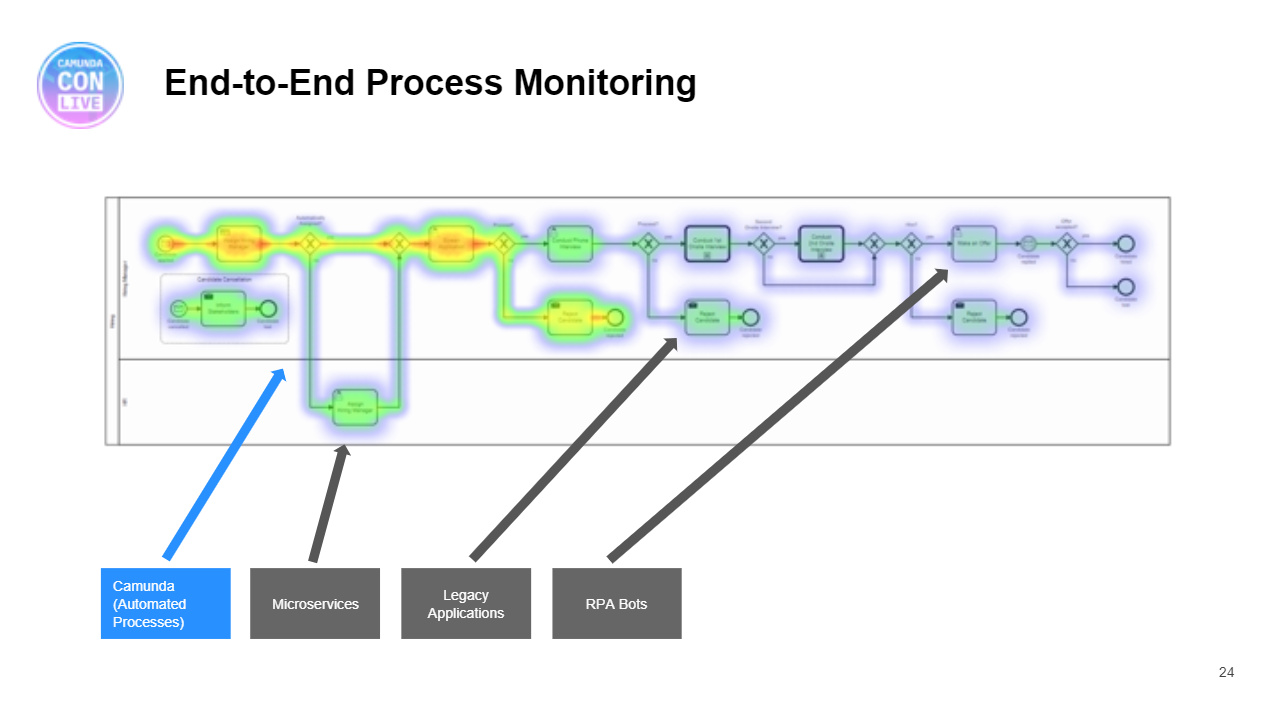
That’s it for me at IBM Think 2020, and I’ve really noticed a laser focus on AI and cloud at this event. I was hoping to see more of the automation portfolio, such as process modeling, process management, robotic process automation, decision management and even content management, but it’s as if they don’t exist.
IBM had to pivot to a virtual format relatively quickly since they already had a huge in-person conference scheduled for this time, but they could have done better both for content and format given the resources that they have available to pour into this event. Everyone is learning from this experience of being forced to move events online, and the smaller companies are (not surprisingly) much more agile in adapting to this new normal. I’ll be at the virtual Appian World next week, then will write an initial post on virtual conference best — and worst — practices that I’ve seen over the five events that I’ve attended recently. In the weeks following that, I’ll be attending Signavio Live, PegaWorld iNspire and DecisionCAMP, so will have a chance to add on any new things that I see in those events.