Retirement? A new chapter in life? Taking a break?
My regular readers and contacts have probably noticed that I’ve been posting a lot less in the past year or two. It seems like a good time to shift from my usual business of industry analyst and process consultant, and spend a bit more time enjoying myself with friends and family, and travelling for leisure rather than dashing from one vendor conference to another.
I’m still open to the occasional speaking engagement or small contract, but I’m considering myself mostly retired.
For any of you who find yourself in Toronto, drop me a note and I’m happy to meet up or at least provide some restaurant and sightseeing recommendations. I’m in Europe at least once each year and enjoy meeting up with friends there too!
This morning I travelled all the way north…to Yonge and Bloor (that’s a Toronto joke, since downtowners consider anything north of Bloor to be a suburban wasteland) for the Camunda Local in Toronto. I haven’t been to a lot of events lately, but when one pops up here at home, I take the opportunity to see some familiar faces and get an update on companies and products.
Frederic Meier, Senior VP of Sales, gave the opening keynote on Camunda’s views of industry trends and how they are responding to those to help organizations drive business transformation. He made it all the way to slide 2 before he mentioned AI (lol), and shared some stats that 83% of executive leaders are driving AI strategy within their company but most of them — 85-90% — are struggling to operationalize it and really make it work. A proper process architecture can help with this by providing a platform for transforming processes as a prelude to or in conjunction with implementing AI. In my experience, a lot of initial AI applications can be thought of as occurring at a specific activity within an orchestrated process, not standalone applications. RPA (robotic process automation) has been in this space for several years now, and many of the RPA vendors have shifted to more of an AI message, but they’re still fundamentally point solutions rather than end-to-end business processes.
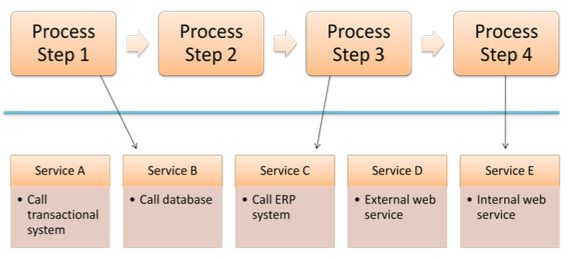
Throwing AI at an unmanaged process is just going to increase technical debt, not reduce complexity. Process orchestration, such as what Camunda provides, allow for integration across point solutions including AI, but also integrating line-of-business systems, CRM, ERP and other systems into an end-to-end process that maps to the customer journey. This provides visibility and the ability to govern the process, then switch out endpoints independently since the process orchestration platform is handling the integration and scalability, not the individual point business solutions.
Frederic discussed case studies with Halkbank (a Turkish bank), who used Camunda process orchestration with AI to improve their money transfer processes; and Deutsche Telekom, who evolved from manual to RPA bots to more fully orchestrated processes using Camunda that include RPA bots and AI endpoints. The Deutsche Telekom example is particularly interesting in that it shows that migration, where manual processes had RPA bots applied to them in a somewhat ad hoc fashion, then orchestrated into end-to-end processes, then the RPA bots eventually replaced with APIs or AI endpoints. Camunda has built-in connectors to several OpenAI platforms such as Azure OpenAI, or you can build a connection to your own internal LLM.
Many organizations haven’t even started on the journey to extract processes from their legacy systems, and he showed using Camunda Copilot that generates process models from text descriptions. I wrote about this in previous posts (both Camunda and other process vendors who use AI to help model processes), and it’s a bit of a party trick. In the simplest case, it produces a process model, but it’s usually pretty high level and could have been created by a BPMN-trained business analyst in a couple of minutes. Where it starts to be more useful is when there are longer more technical descriptions of processes available — he showed pasting in a long text description of a process, and a section of COBOL code, and each produced a process model. Okay for a starting point, but this is something that I think will get more use during a demo than in actual process analysis.
He finished with a discussion of agentic AI, which in the most extreme sense is turning over a business process/decision to a completely non-deterministic AI; however, he advocated for deterministic guardrails within which a non-deterministic AI. The model for this shows an ad hoc BPM subprocess boundary representing an agent, containing multiple activities/processes that could be selected depending on the information at hand. On the boundary of the ad hoc subprocess, there are deterministic guardrails in the form of escalation and timeouts. For those of you who have been around the BPMN standards for a while, this style of ad hoc/deterministic processes looks a lot like CMMN. (CMMN arguably should never have been spun off from the BPMN standard, and has not been broadly accepted in the industry.)
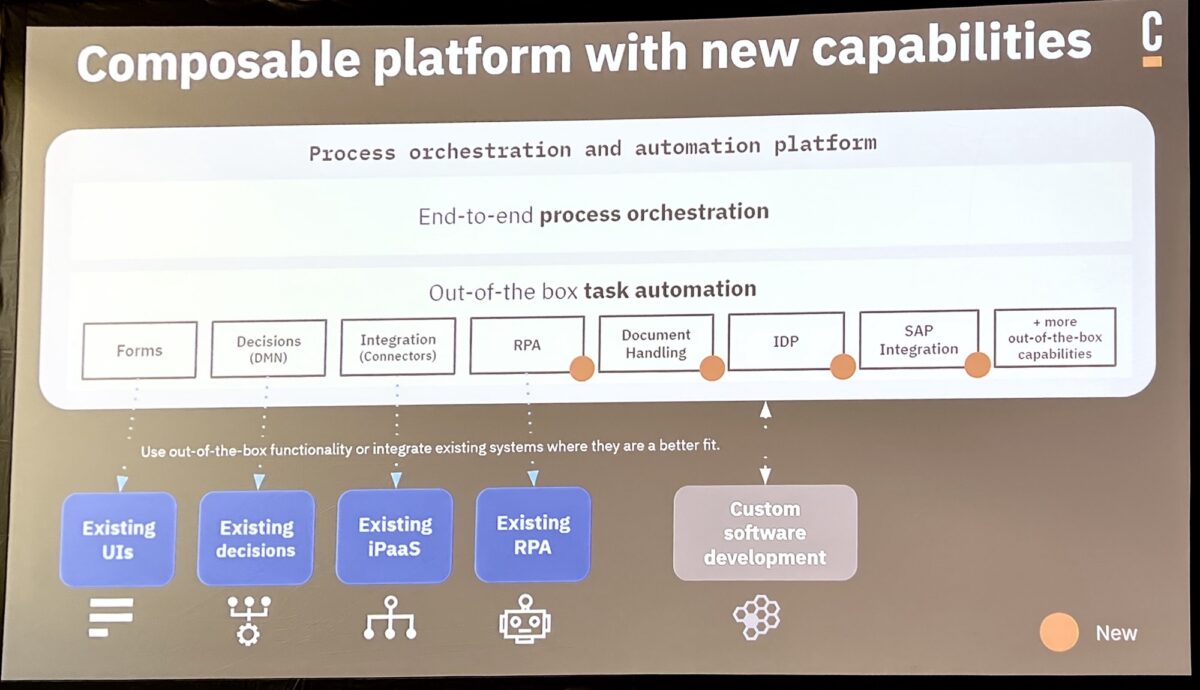
Daniel Meyer, CTO, took the stage to talk about the future of automation with Camunda from a product standpoint. Building on their end-to-end process orchestration platform (now really the Zeebe engine since they have made plans to sunset C7 and previous generations), you can include human tasks; automated decisions; integration via standard protocols and connectors of various types built by Camunda, partners and customers; RPA (to be released in their April release); and IDP (intelligent document processing, to be released in April).
He walked us through the specific roadmap items, including what was released in October, and what is coming in April and October (Camunda runs on a strict 6-month release cycle). The core process orchestration roadmap is mostly about new developer features plus improved scalability and deployment capabilities. Questions from the audience included discussions of some of the differences from the Camunda 7 engine, and I’m guessing that Camunda is having a bit of a challenge with encouraging their customers to take on the platform migration. Their upcoming RPA offering is intended to be a “good enough” solution when an organization doesn’t need the full capabilities of a third party RPA tool, and possibly is using RPA as a temporary stopgap as they work towards API integration. They are also releasing their first version of IDP to allow for extracting data from documents, and move towards more robust document classification.
It’s important to note that RPA and IDP are necessary for Camunda to be included in Gartner’s newish BOAT categorization. In my opinion, these are a bit niche for Camunda’s product direction, but probably a case of an influential industry analyst firm forcing the market in a certain direction.
Also coming up is their SAP integration, which is very interesting for organizations that are migrating between older SAP and S/4HANA platforms, as well as providing deep integration between SAP processes and other activities within the business.
We heard from Sathya Sethuraman, Field CTO, on operational resilience in financial services. There are a lot of factors to this, but there’s definitely a focus is on being able to provide fast, automated, seamless transactions regardless of the size of the transaction. If you’re going to provide micro-lending and process millions of small transactions to replace cash, it has to be immediate and easy to use. At the other end, if you’re going to deal with a huge volume of mortgage renewals based on changing interest rates, you need to automate both the process and the decisions regarding what the customer is offered, or you’ll lose business. Customer service needs to improve and become more automated — using intelligent chatbots for straightforward inquiries, for example — since customers don’t have the same sense of loyalty to a financial institution that many banks used in the past to build their business.
He talked about the time required to transfer money between countries: in many situations, this takes 5+ days. Compare that to a platform like Wise, which acts as an intermediary and allows same-day transfers between banks in different countries. These disruptive fintechs are going to take a huge chunk of traditional banks’ business if the banks can’t innovate in response to the customers’ needs. In countries that have proper banking regulations, like Canada, this puts a lot of burden traditional banks to update their legacy technology, optimize their processes, and automate where possible. Processes and decisions need to be flexible and responsive in the face of changing markets and customer needs, and be able to scale up quickly without increasing costs.
Lots of financial services customers and prospects in the room, so this message likely hit home.
We finished with Gustavo Mendoza, Senior Sales Engineer, and Olivier Fiaty, Senior Customer Success Manager, with a presentation on building a business case for process orchestration. This was a fairly standard framework of identifying pain points; defining objectives and KPIs; mapping and analyzing current processes; co-developing and analyzing future-state business process model; conducting a cost-benefit analysis; and cultivating stakeholder support. As they went through these, they showed how each stage applied to a customer case study with an omnichannel financial services organization, and where Camunda products could be applied during the initial analysis and in the solution estimation. Camunda has an online guide for building a business case, and offers a half-day consultative workshop to help business and technical stakeholders work through this.
There’s a lot of buzz about how we’re all going to be replaced in our jobs by artifical intelligence. As a long-time pracitioner in business process automation, it seemed like this might just be another step in the trend of automating work to make it better, faster and cheaper, as we’ve been doing for centuries. From Jacquard looms to Ford’s assembly lines to automated business workflows, it’s a bit more of the same applied to different fields, although increasing more sophisticated. Most people who are in some sort of creative role — writing, graphics, innovation — assume that they’re immune from this type of automation. They may be wrong.
I was listening to a podcast by Tim Harford, who creates the excellent Cautionary Tales series, and in this episode he was talking with Jacob Goldstein, who has recently written a book called Money: The True Story of a Made Up Thing. Jacob described uploading a chapter of his book to Google’s Notebook LM and asking it to do an audio summary; Notebook LM generated a two-person converational podcast with entirely AI actors that summarized and discussed his book chapter. Whoa.
End of the last day at CamundaCon 2024 in New York, and I attended a last few sessions.
Bernd Ruecker and Leon Strauch led a panel to discuss their new book, Enterprise Process Orchestration, and talk about centres of excellence with guests Sanjay Sarpal from Atlassian and Prashant Appikatla from US Bank. Panels are pretty much impossible to live-blog; suffice it to say that it was an interesting discussion with an active Q&A. Although the book is not purely about CoEs, there’s definitely a move towards process orchestration maturity, CoE and other higher-level topics rather than just the technical mechanics of orchestration. We were given copies of the early access version of the book, and it will be generally available in the spring of 2025.
I went to a last technical session with Bastian Koerber and Calvin Robbins, who discussed and demonstrated the new capabilities that are coming in the 2025 releases: BPMN Copilot, FEEL Copilot, IDP, RPA and SAP integration. This was a bit more detailed than what we saw in the technical keynote, and gave a better sense of what the capabilities will look like to the developers and analysts. Some of these are available to play around with already, such as the FEEL Copilot alpha and the early release documentation.
Finally, I attended the fireside chat that co-founders Jakob Freund and Bernd Ruecker always have to wrap up CamundaCon. Both of them recommended that it’s a good next step to get your hands on the product and play around with it if you’re wanting to try out some functionality that you’re not already using. There were some funny recollections about how Jakob and Bernd first met and started working together: the days of startup culture and “no bullshit BPM”. Now, they’re introducing the same type of no-BS AI, RPA and IDP, with lighter weight capabilities that allow people to get started and address simpler needs. Hopefully they can keep that same philosophy for solving customer problems as they continue to grow.
Check Camunda’s socials next week for links to the recorded presentations from the conference — lots of great content.
There are a lot of interesting case studies being presented here in New York this week, and I’ll be checking back for the videos of ones that I missed when they’re published next week.
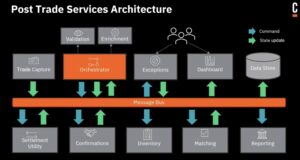
I attended the Barclay’s session on their post-trade processes, presented by Shakir Ahmed, Head of International securities Settlements Technology, and Larisa Kvetnoy, Managing Director of Markets Post Trade Technology. Although trading processes are not handled with a BPMN engine like Camunda, the post-trade processes are an important part of ensuring that trades settle correctly. Given the move to T+1 settlements, it’s critical that all of the exception handling and due diligence is completed in time to execute the settlement on time. There are a lot of complex activities that must be performed, often in a specific order, and many of these have relied on aging legacy systems and manual processes in the past.
Now, they use Camunda to orchestrate services, and have created separate services for each function that must be performed in the post-trade processes. They also created a centralized exception handling service — which relies heavily on human work — to bring together all of the exceptions regardless of the system or step where they occur.
They are definitely seeing improvements in agility and time to market, but also in operational oversight: making sure that transactions don’t “fall through the cracks” and fail to settle on time. This reduces their financial risk as well as their overall costs.
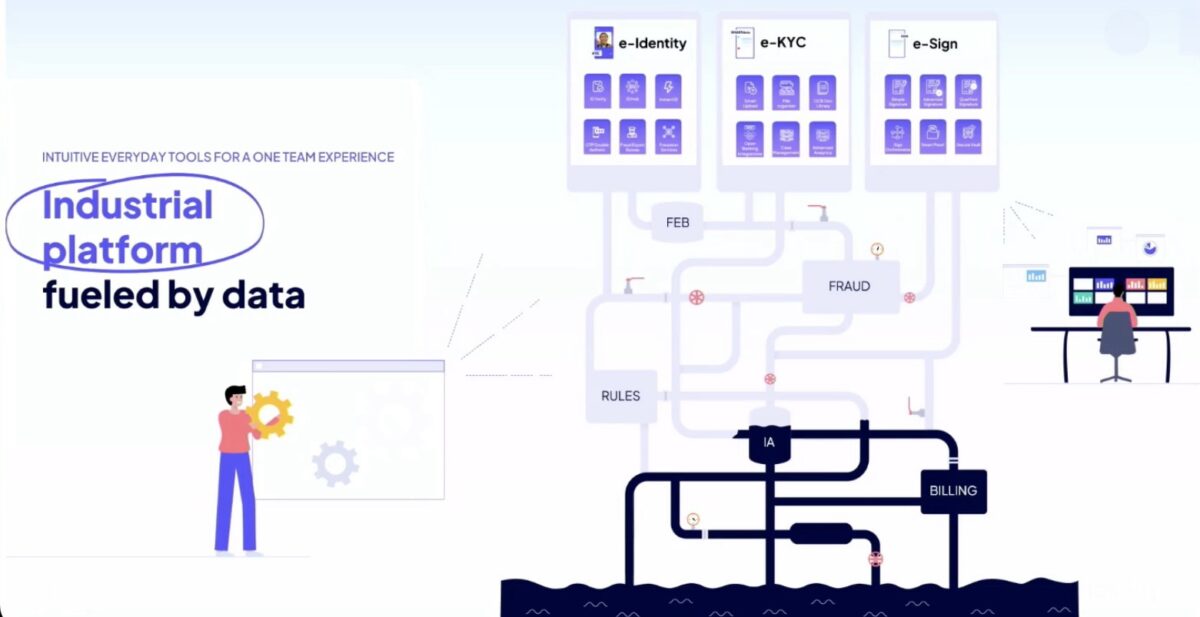
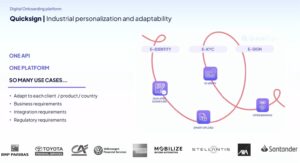
Next was QuickSign, a European digital onboarding provider, presented by founder Thibaut Ravise and CMO Charlotte Stril. They provide services to large financial institutions such as BNP Paribas, allowing these FIs to outsource the onboarding of customers almost instantly. This is essential for being able to provide credit solutions in the course of a retail transaction, where the customer is offered the option to use a credit option during online checkout when they are buying (for example) the latest iPhone. This is also used for fast bank account opening, immediate expense payments for insurance claims, and other situations where an onboarding experience needs to be much faster than could be offered by the FIs directly with their legacy processes. Since they’re based in France, they provide services that adhere to the strict EU standards and regulations, and are expanding into the US with some of their products.
Part of their solution is an orchestration layer that is based on Camunda, which brings together the digital identification, KYC (know your client) and signing services. This in turn helps their FI clients to win new retail clients such as Apple and Amazon, where near-instant credit account opening and onboarding is a necessary part of online purchasing. When Camunda 8 was released in 2020, they made the move from their own internal workflow to the Camunda BPMN engine on premise. The use of BPMN has allowed them to rework and release customer workflows quickly, and Camunda Optimize allows them to gather information and optimize processes. For them, scalability and resiliency of the platform is critical: workloads can increase by several times on heavy shopping days such as Black Friday.
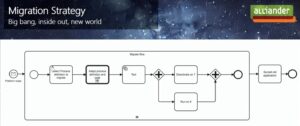
The last customer case study session that I attended today was with Dutch energy infrastructure company Alliander on their migration from Camunda 7 to 8, presented by Floris van der Meulen, Business Analyst System Operations, and Eric Hendriks, Senior Software Engineer. They were one of the first companies to migrate a production process from 7 to 8, and likely have the scars to prove it.
From a business standpoint, they operate large energy distribution grids throughout the Netherlands, with one component of that being their autonomous grid manager that includes Camunda. They were originally using open source Camunda 7 to respond to Kafka messages and manage security and load changes required to the grid as load and supply conditions fluctuate.
Factors driving their decision to move off the open source Camunda 7 included lack of operational insights, transactional locking, no commercial support, and scalability, all ofwhich had them decide to move to Camunda 8. They were in production with Camunda 7 but hadn’t scaled up so did not consider the processes mission critical; in order to move to the next stage, they felt it necessary to shift platforms before investing more in the older platform. They did an evaluation of what would change as a result of the migration: at the time, some BPMN features were not (yet) in Camunda 8, such as execution listeners, but they would have the benefit of scalability as well as being able to use Optimize for operational insights.
They used a gradual “new world” approach to migration, and even created a BPMN diagram to illustrate their migration process. They ended up having to do a manual conversion of their BPMN models because of the execution listeners: this required them to rethink and completely redesign their processes.
Once they redesigned the BPMN processes and reconnected them to their UI, they needed to overhaul their testing procedures. They started with “black box” tests on their old processes, and ran them against the new processes to ensure that the same inputs resulted in the same outputs. Following the confirmation that the new processes behaved the same as the old processes, they could migrate in the new V8 processes and decommission the V7 processes. Their process instances are all short-running, so there was no requirement to migrate work in progress, which made the migration more straightforward. Also, they only had about a dozen process models to migrate.
They were pretty open about some of the problems that they had with the migration: it’s not automated by any stretch of the the imagination, and it’s a non-trivial project that will almost certainly include process redesign and retooling. However, they now have cleaner models and code, and a much more robust and scalable environment.
As as aside, I’m attuned to the challenges of migrating customers between product versions when it’s a complete replatforming exercise, and interested to see how well Camunda handles this over the next few years as they sunset Camunda 7 support. A lot of companies don’t do this very well — see the history of TIBCO with migrating Staffware customers to ActiveMatrix BPM, for example, or the IBM BPM “three engines under the covers” fiasco — and it’s no longer enough to just tell customers to build their new processes on the new platform while sticking their heads in the sand over the existing processes. Given that Camunda has really focused on being the orchestration engine in the past, the shift from 7 to 8 should be a bit less painful than replatforming with some other vendor products: no UI to redevelop, and some ability to export/import BPMN processes directly as long as all of the BPMN elements are supported. Maybe they can use AI for this? 😉
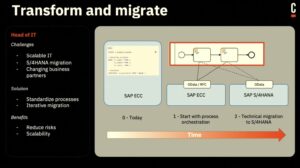
We’re kicking off day 2 of CamundaCon in New York with the technical keynote, featuring Bernd Rücker, Co-Founder and Chief Technologist; Daniel Meyer, CTO; and Bastian Körber, Principal Product Manager. Bernd opened the session talking about organizations’ conflicting goals to continue innovating their business while also transforming and modernizing their technical architecture. This was an interesting although possibly unintentional tie-in with the SAP integration session that I attended at the end of the day yesterday, where the migration example from SAP ECC to S/4HANA falls into the latter category, but the business leaders are pushing for the business innovation and don’t want to “waste” time on technology modernization. Adding RPA/AI bots and moving to an orchestrated architecture allows for gradual architecture modernization while making the business processes much more agile by externalizing the processes from the legacy systems.
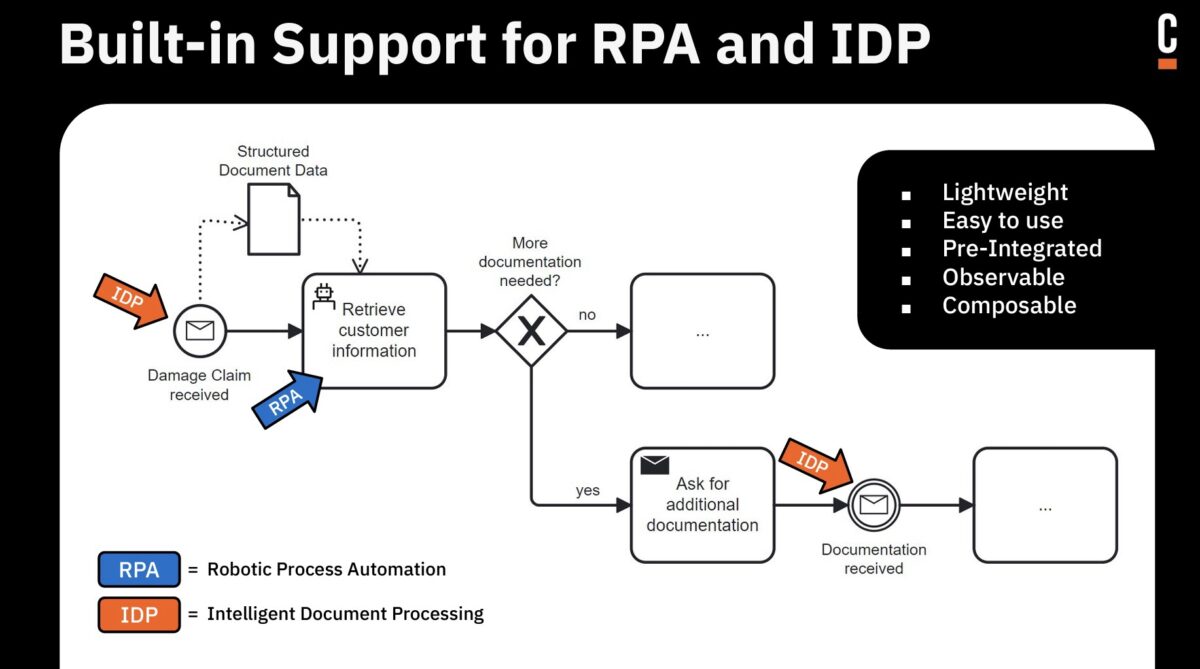
We saw a demonstration of claims handling showing their upcoming IDP (Intelligent Document Processing) capability, which calls AI to extract information from receiving documents then figures out what to do with the information. The goal is to map that information onto the data elements in the process model, which then allows documents to be automatically integrated into processes with little or no human intervention.
We also saw some of their upcoming lightweight RPA capabilities built on the open source Robot framework. The addition of IDP and RPA — necessary if Camunda wants to work their way into the new Gartner BOAT category — are intended to be relatively lightweight, and not replace the need for more robust IDP and RPA products if an organization is already using third-party products, which can just be treated as external services to be orchestrated as part of a Camunda process.. Hopefully these will actually be “good enough” to be generally used, rather than being toy versions that are just there to chase the analyst categorization that we’ve seen from many other vendors in the past.
The demo also includes other AI calls and SAP integration, highlighting their new/upcoming features. Worth watching the replay of the demo when the sessions are released next week to see Bernd walk through it all (with a bit of help from Daniel).
Daniel took over to discuss the next generation of automation platform, which expands their orchestration environment through the addition of AI at a number of different points. This is exposed in the modeler as IDP, RPA and AI connectors and services.
Bastian described the AI offerings in more detail, starting with the BPMN Copilot, which can be used to create BPMN diagrams based on text descriptions. There have been natural language processing interfaces to BPMN model generation around for quite a while, both in research and as some released products, but this adds LLMs behind the text processing for better results — the more text that is provided, the less AI hallucination. Output is not (necessarily) intended to be the final version, but a fairly advanced starting point for a human modeler to then continue modifying and completing. The LLM is using publicly available information to provide best practices for process models. The BPMN Copilot demos well but feels like a bit of a party trick. A cool party trick, but maybe not something that’s going to be mainstream for a while. Some of the underlying technology can definitely be used, however, for automated process optimization or at least optimization recommendations, by bringing process mining data and some natural language to bear.
Daniel referred to Forrester’s definitions of AI Agents (task automation) and Agentic AI systems (orchestration of multiple types of tasks including AI agents). AI agents may be descendants of RPA bots, where some level of AI is already in use, while Agentic AI is focused on autonomous systems that optimize themselves without human intervention.
We also saw a demo of a travel booking process that uses AI agents to organize, research and present options based on a general description of a desired trip booking. These agents are orchestrated into a process with some human touch points, where the AI options are shown as recommendations: calls to third-party AI/LLMs as part of an orchestrated process, demonstrating AI agents and agentic AI in the context of E2E business orchestration
There was another example of a claims process with an ad hoc subprocess, blending deterministic and ad hoc in the same process where AI can be used to decide which activities are executed in which order within the ad hoc subprocess. The ad hoc subprocess has been in BPMN for a long time, but usually used to represent case management with human decisions or standard decision management on which activity to perform next; now, an LLM acts as the Next Best Action selector.
Daniel finished up with release dates: all of the features discussed will be released in 8.7 or 8.8 within the 2025 calendar year.
As we kick off the second day with an informative keynote, I also want to give a shout out to the Camunda events team, who keep everything running smoothly when I’m sure there are mini disasters happening behind the scenes every minute. Kudos!
I’ve been following Camunda a long time, and I’m pleased to see that they’ve “grown up” enough to have a separate analyst session at the conference, which I attended this afternoon. Because it was an open discussion of the roadmap and other topics, it was all under NDA. Sorry!
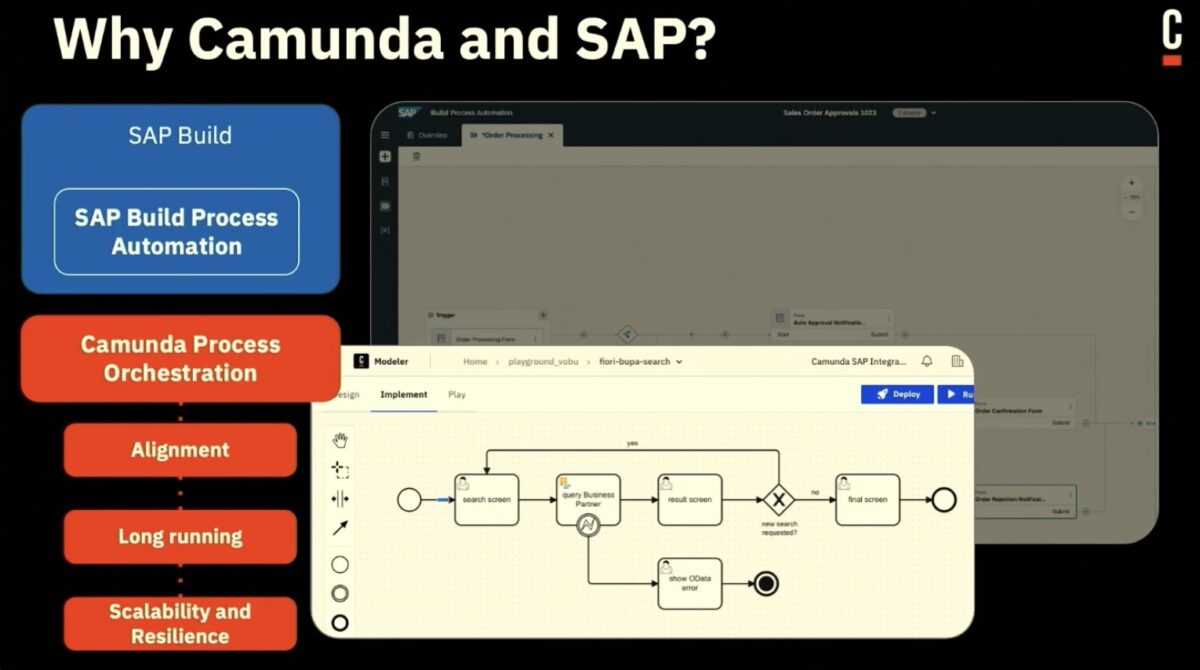
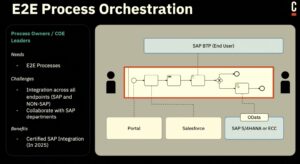
However, after we finished the analyst session, I ended the day listening to Camundi (Camundis?) Tobias Conx and Volker Burke talk about their upcoming SAP integration. This was only publicly announced a few weeks ago, but they seem to have hit the ground running and have quite a bit done already. Volker is a recent hire and is an SAP mentor, which means that he’s well-respected in the industry in addition to having a certain level of proficiency. He previously worked at a company that did quite a bit of Camunda-SAP integration, and showed some of the benefits of adding Camunda as a process orchestrator to SAP.
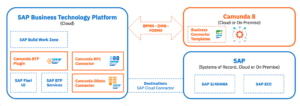
In this type of integration, Camunda orchestrates SAP automations in a similar ways as if the SAP modules and functions are any type of services. However, the connectors have been more tightly coupled so that they run in the SAP infrastructure. These connectors are set up as applications within the SAP BTP (Business Technology Platform), then the Camunda view of the connector is a technical OData connector allowing for those applications to be executed to read/write data between Camunda and SAP. Camunda forms can even be rendered within SAP Fiori.
There are some important use cases for this, including transforming and migrating from SAP ECC to S/4HANA, which allows multiple ECC systems to be migrated to S/4HANA over a period of time — something that many SAP customers are still struggling with. There’s also a number of different industry solutions that use the OData interface to SAP together with Camunda and other components, such as Cognizant’s Accounts Payable solution. SAP customers can also use this for their own internally-created process orchestrations that tie SAP together with Salesforce and other platforms in use.
In many of the use cases, SAP Fiori or BTP provides the user interface which connects to a Camunda process task, then other OData tasks within the process execute SAP functions to read/write data.
This will be released by Camunda in January 2025, and will be part of the 8.7 release without any extra licensing fee. Assuming you’re already using SAP BTP, it will not impact SAP licensing either.
That’s it for day 1 of CamundaCon 2024 here in New York. I’m off to the evening reception — where everything is off the record once the bar opens — and I’ll be back here blogging about day 2 in the morning.
I attended a number of customer case studies, starting with Pascal van Puijvelde, Business Analyst at Rabobank, and his colleague Louwris Wernink, IT Lead Payments, showing how they shifted $5.6M in sales processes (new accounts) to Camunda 8 SaaS, while adhering to regulatory standards. They worked closely with their Camunda Technical Account Manager on designs and modeling, and to set up a Centre of Excellence. They started looking at Camunda in late 2022 when they realized that they required a process orchestrator for their more complex case-mangement style processes. Their old technical stack was being deprecated, and they were looking for an architecture that separated the process orchestration from the front end UI and allowed each to be changed more rapidly, as well as a product that would integrate well with their tech stack. Their first implementation was earlier this year, and they onboarded directly to Camunda 8 SaaS.
They had to learn not just about using Camunda, but also about how BPMN can be used as a link between business requirements and IT implementation.There was some amount of trial and error as they went through their early designs, with both the business and IT having to learn about the new architecture and methods. Banking is highly regulated, so they had a lot of security and privacy concerns that needed to be addressed; this has resulted in them not putting any private data on the SaaS platform, but keeping that on their internal systems and using a reference key. Interestingly, their regulators consider a reference key to be pseudonymous rather than anonymous, so they’re still working through the privacy considerations. DORA (Digital Operations Resiliency Act) comes into effect in 2025 in the EU, and financial institutions such as Rabobank will be subject to stringent guidelines for safeguarding against data breaches and other privacy and security concerns.
They were the first Camunda customer to have a Technical Account Manager, who acts as their conduit to solving Camunda-related problems. They also created a CoE to help standardize their use of Camunda and process orchestration projects. This has really changed the way that they work both in the use of Camunda-focused development sprints, and how this rolls out to the business. Their single biggest benefit from moving to this type of platform is time to market: they signed the contract with Camunda at the end of 2023 and rolled out their first applications earlier this year. Going forward, changes to the UI or the process are much more agile, and new applications can be developed more quickly.
I had a bit of a view of the Norfolk & Dedham insurance case study at the Camunda Day in Toronto earlier this year, and wanted to check back to see how they are progressing with their P&C claims processes. Shashi Ayachitam, IT Director, updated us on how Camunda has become the heart of their new technical architecture, replacing an obsolete workflow tool. When I heard about their projects in March, things were still in the testing phase, although they were nearly ready to deploy claims and were considering other business areas such as underwriting.
N&D customized the Camunda modeler to allow them to include their own business roles (e.g., claims adjuster) and other business data to make modeling faster and more accurate. They made use of the data-rich analytics to provide real-time dashboards and insights that can help to manage operations as well as feed back into process improvement.
In the six months since they deployed claims into production, they’ve cut the time to process claims by 35%, and reduced costs by 30%. Given that they are early in their journey and can likely still do a lot of fine-tuning, these are fairly significant improvements.
They are interested in Camunda’s new roadmap that includes RPA and AI, since they can make use of both of those technologies to improve their operations. They’re on Camunda 7 on premise, and haven’t started planning for migration to Camunda 8 although Camunda has announced end of life for V7 by 2030 with a gradual phase-out.
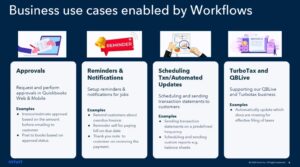
The last customer breakout that I attended was with Yash Agarwal and Rishabh Surana of Intuit, describing how they incorporate Camunda into their QuickBooks mid-market accounting product. In addition to my work consulting in financial services, I’m also a former QuickBooks user for my own business, and I was interested to see how they are using it for actions such as approvals, reminders, notifications, and triggers within the product.
They went from simple forms-based workflows triggered by a single condition, to visual process models that allow for branching with multiple conditions and actions. An example that they showed was reminders to customers for near/overdue invoices, which allows Quickbooks clients to receive their payments earlier and potentially with a greater success rate. They still provide a template-based design for ease of use by non-developers, but dynamically generate BPMN process models at runtime.
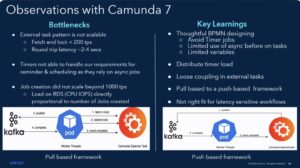
They found some key bottlenecks with their Camunda 7 implementation: the external task pattern is not particularly scalable, and large numbers of timers are problematic due to their reliance on asynchronous jobs.
This led them to implement the equivalent functionality outside Camunda to achieve the performance required. They started experimenting with Camunda 8 to see if they could bypass some of these bottlenecks, and found out that tweaking the configuration allowed them to reach the low latency levels that they required for the external task pattern, as well as support the large numbers of timers that they required.
They showed a list of the issues such as these latency problems that they have resolved by working together with the Camunda team, as well as some of the issues still being resolved. A realistic look at the technical issues around an implementation, and the performance improvements that can be experienced when migrating from Camunda 7 to 8. They evaluated other options when they started their v8 experiments, but found that the options that had equivalent performance didn’t have the same level of functional sophistication.
Interesting set of customer case studies. I’m off to the industry analyst session for most of the rest of the day, although may be back for the SAP integration session at the end of the afternoon. You’ll be able to see the recordings of all of these sessions by some time next week.
It seems that a lot of my posts are about Camunda lately, mostly because these are the events that I’m attending in person. Like a lot of people, I’m a bit over online conferences since too many of them are pre-recorded and the speaking is uninspired – as a long-time conference presenter, there’s just something about presenting to a live audience that livens up a presentation. This week, I’m in New York for CamundaCon 2024, which is also being streamed live if you want to participate remotely. The livestream really is live, and they use Slido to field questions from audience members regardless of location.
Day 1 opened with a keynote by CEO Jakob Freund. It’s been a while since I’ve had a Camunda briefing, and several people hinted in advance that there would some interesting updates. He opened with their growth stats: Camunda now has more than $100M in revenue and 500 employees, which is a pretty stellar path from its humble origins. He then went on to discuss waves of change, primarily waves of AI opportunities such as the current agentic AI.The goal is to drive the right process architecture, which doesn’t mean just throwing AI at a spaghetti architecture, although many organizations will be unable to resist that path since it gives the illusion of progress. The same has happened with many new technologies in the past: think of how RPA (robotic process automation) has been added to existing overly-complicated architectures and just serves to make them more complex and rigid.
Process orchestration is a potential path to taming the complexity by providing a layer above the complicated and disparate legacy and “helper” technologies, loosely binding and coordinating them. Instead of the “spaghetti bot” architecture that results from many RPA implementations, process orchestration allows the bots to be separated from the process orchestration layer. Then, the underlying bots can gradually be replaced with APIs while maintaining the same process layer focused on customer journeys. This is not really new — in fact, I think I wrote a paper or two on exactly this method of continuous improvement rather than a big bang approach.
How is Camunda responding to this new reality? They’ve come from a core vision of process automation through microservice orchestration as a developer tool, to adding out of the box connectors, low-code capabilities, human-facing tooling, and lightweight decision management with DMN. Their next steps are the addition of RPA and IDP (intelligent document processing) to their core stack. Their RPA, in particular, isn’t a competitive independent RPA product, but a built-in capability to integrate legacy applications without having to expose an API. You can still integrate bots from other RPA vendors to Camunda processes, but they are providing a lightweight capability for customers who need a small amount of RPA without having to work with a second product. This is not — or at least should not be — particularly heavy lifting for a capable process orchestration product company, since it’s just process on a different level.
Another big announcement was about Camunda’s move further into the business solution space. Their marketplace has allowed partners to provide templates and solutions for some time, but now Camunda is taking a bigger role in providing solutions themselves. As part of this, they are providing a “process orchestration for SAP” solution. There’s another session on this later today that I plan to attend.
Jakob wrapped up his keynote with an overview of their expansion in AI, which we will be hearing more about over the next two days. This includes chatbot-supported process modeling as well as process orchestration runtime capabilities from lightweight helpers to full agentic AI: the operationalization of AI.
Some exciting announcements, and we’ll see more detail and demos at the technical keynote tomorrow.
This was followed by a keynote from Gartner on their latest move to rebrand the market under a new acronym: BOAT, or Business Orchestration and Automation Technologies.
Not completely surprisingly, Camunda’s new product announcements seem to be aligned with BOAT, and Gartner’s presence here may be an indicator that Camunda is going down the path of chasing the analysts and aiming for a good Magic Quadrant placement.
When conferences end up in my back yard, I usually find a way to attend. Today, I’m at CamundaLocal Toronto, a one-day conference and workshop for Camunda customers, prospects and partners. Toronto is the hot spot for Canadian finance, and we can see the major bank towers from our perch at the top of the Bisha Hotel. I’ve worked for a long time as a process automation consultant in this region and there is really an overwhelming number of investment firms, bank, insurance and other related financial organizations within a short distance. Lots of representation from the big banks and other financials in attendance today.
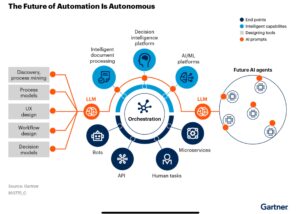
Our host for the day is Lisa-Marie Fernandes, Camunda Strategic Account Executive, and after she introduced the day and gave some background on Camunda, we heard from Sathya Sethuraman, Field CTO, on the problems with siloed automation versus Camunda’s vision of universal process orchestration. Every technology company and CIO have been talking about the necessity of business transformation for years, and Sathya pointed out that process automation is a fundamental part of any sort of digital transformation. The problem arises with siloed automation: local automation within departments or even sub-departments, with no automated interaction between parts of the process. Although people in that department are convinced of the value of their local automation, customers deal with a much broader end-to-end process in order to do business with an organization. With siloed automation, that customer journey is fragmented and difficult, with the customer having to fill in the gaps of the process themselves through multiple phone calls, forms and emails, while re-entering their information and explaining their issues at each step. Contrast that with an organization that has end-to-end orchestration using a product such as Camunda to bind together these departmental processes into a full customer journey. The customer no longer has to deal with multiple processes (while trying to figure out what those processes are from the outside), and people inside the organization no longer have to make heroic efforts just to meet the customer’s needs.
Sathya pointed out the risks of broken (or missing) end-to-end automation, including the increased complexity caused by multiple isolated processes, and the disconnect between business and IT due to lack of a common language for process automation. From an organization’s standpoint, there are issues with efficiency and quality of internal processes, but the bigger issue is that of customer satisfaction: if a competitor has a fully-automated end-to-end process that makes it easier for the customer, then many customers will choose that path of least resistance when they are choosing who to give their business to. This, of course, is not new. However, with the changes that we’ve seen in the past four years due to the pandemic, work from home and shifting supply chains, more streamlined and automated processes have become a true competitive differentiator. He had an interesting slide showing a heatmap of the many process orchestration opportunities just in the consumer banking value chain: probably 50-60 distinct processes across customer management, retail, lending, cards, payment, risk, finance and accounting, and corporate management where many financial organizations have room for improvement.
Daniel Meyer, Camunda CTO, then gave us a product roadmap update. He kicked off with a view of the common reality of most large organizations, echoing Sathya’s points about islands of automation without end-to-end process orchestration. Many companies focus on improving the local automation — making their core banking systems better, for example — without considering how this is making the customer journey worse because there’s no integration or linkage between these disparate systems. Opening a bank account as a new customer? There are likely different systems and processes for know-your-client checks, credit checks, customer onboarding and account opening; when one isn’t connected to the others, the customer experiences delays and an increasingly negative view of the organization as they struggle to get the new account open. The missing link is end-to-end process orchestration, and this is the focus that Camunda has defined for their product over the past few years.
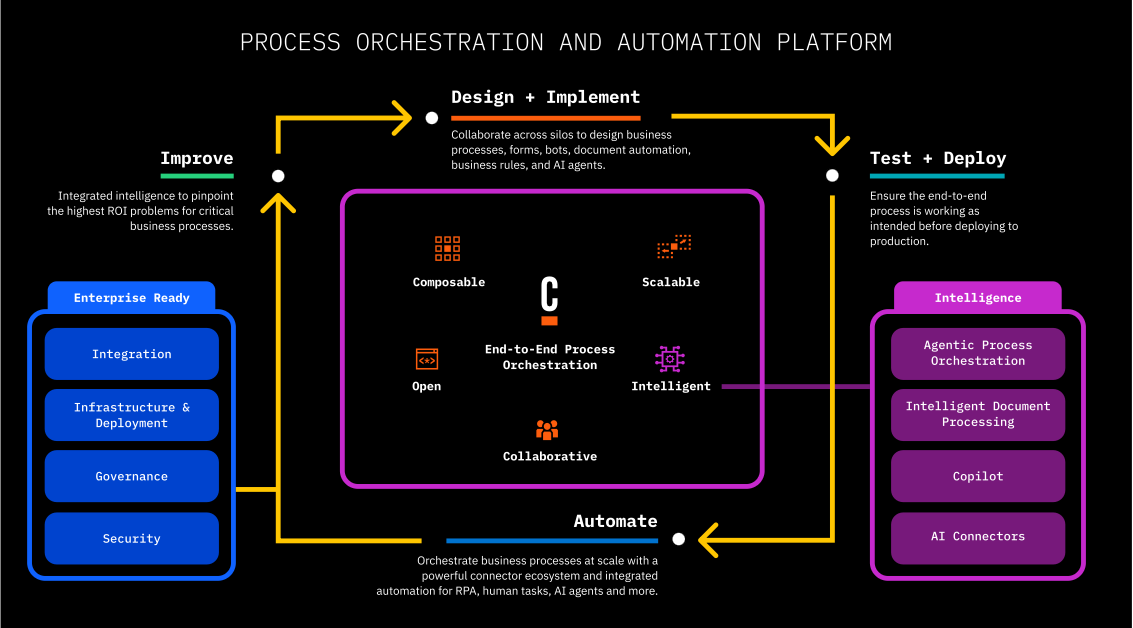
The challenges of end-to-end orchestration include endpoint diversity — it’s more difficult to integrate a heterogeneous set of endpoints since they have different interfaces and may be at different levels — and process complexity that goes beyond a simple sequence of steps. He showed where some of the customer use cases live on the endpoint diversity versus process complexity graph, and the sweet spot for Camunda in the top right quarter of that graph, where processes and the system integrations are both complex. Of course, those are also the mission-critical processes that are controlled by IT, even though business people may be involved in the design and requirements. In this context, their vision is Camunda as the universal process orchestrator: providing the capability of complex process flows as well as being able to integrate in human work, AI, business rules, microservices, RPA, IoT and APIs of all types. That being said, they still have quite a developer-centric bias.
Daniel spent a bit of time on some of the terminology and usage: process orchestration versus business process management (essentially the same when you’re talking about the automation side of BPM, and Camunda also uses the term “workflow engine” as the core of process automation), and who within an organization creates BPMN diagrams. This was a pretty technical audience, and there was a bit of discussion on the value of BPMN once you got down to the level of details that a non-technical process owner isn’t going to be looking at. I believe it’s still incredibly valuable as a graphical process-oriented development language even for those models that are not directly viewed by the business people: it provides a level of functionality as well as development guardrails (e.g., model validation) that can accelerate development and increase reusability while making it more accessible to less experienced developers.
Camunda, of course, is only one piece of the entire process improvement cycle, albeit a critical core piece of the automation. Most customers are also using some combination of process mining, more advanced business modeling, and business intelligence; these essential activities of discovery, design and analysis/improvement fit around Camunda’s process automation and low-code integration offerings. Some automation technologies, including AI, RPA and an event bus, are not part of the core Camunda platform but easily integrated to allow the best of breed components to be added. And although Camunda has recently provided a some front-end UI capabilities, it’s pretty rudimentary forms and most companies will be integrating Camunda into their existing application/UI development environment.
Daniel took us through the investment focus that Camunda has for product development in the areas of developer productivity, AI/ML, collaboration, business intelligence, low-code and universal connectivity. He also highlighted the availability of connectors in the Camunda Marketplace that can be pulled in and used in any model for additional connectivity beyond what is included in the out of the box product.
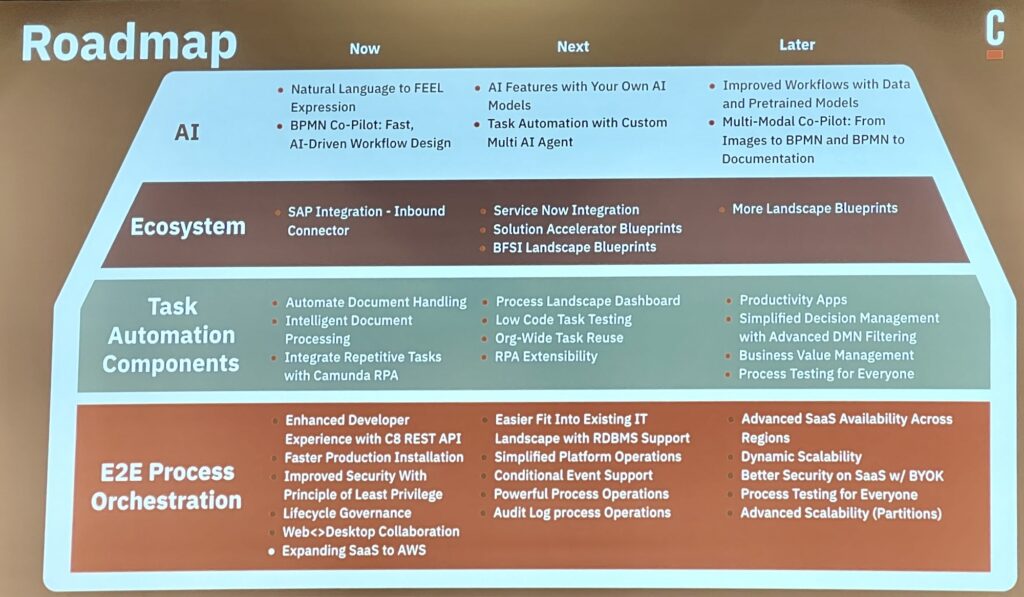
Camunda has a regular cycle of releases every six months, and he gave us a quick overview of what’s coming up in 8.5 in April, 8.6 in October, as well as future plans for 8.7 and beyond. This is all for systems based on the Zeebe architecture (V8+); not clear from this presentation what, if anything, they are doing for customers still on V7 aside from encouraging and assisting with migration to V8. As with many vendors that completely replatform, migrations to the new platform are likely much slower than they anticipated, although with the added complication that they are leaving behind their open source legacy with the shift to their modern Zeebe engine.
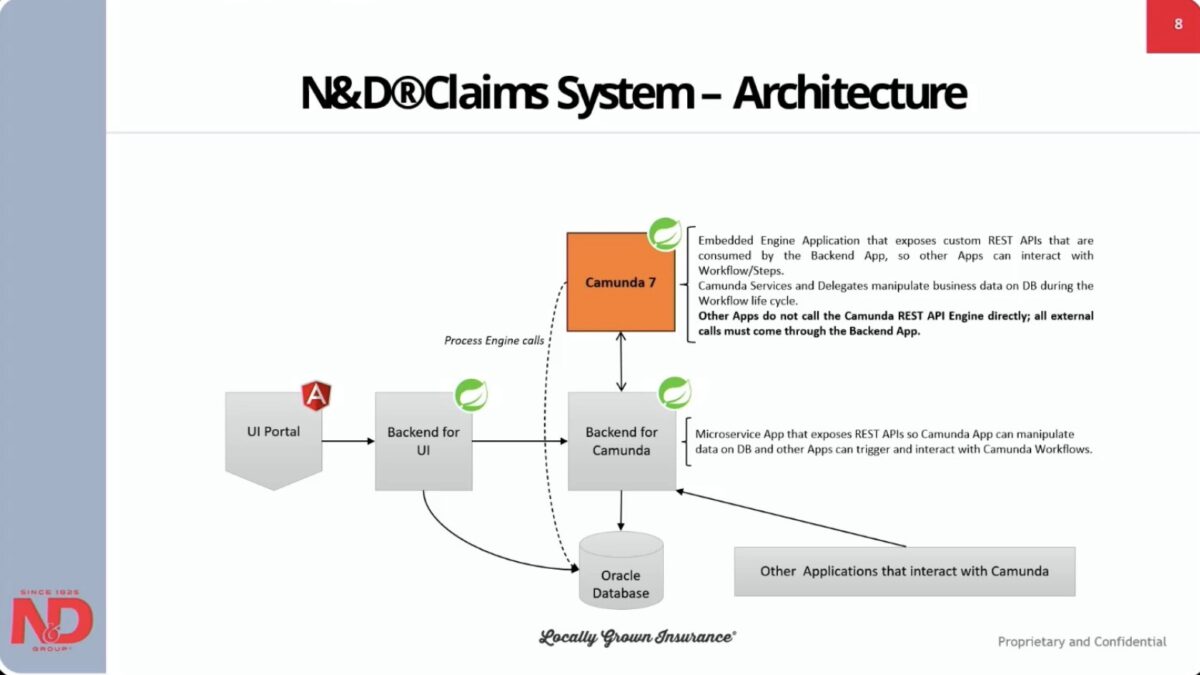
After lunch, there was a short customer presentation by Norfolk & Dedham insurance, who are using Camunda 7 and Spring Boot as an embedded engine invoked from their own UI portal for managing claims. They customized the Camunda Modeler to integrate their own applications and data sources, in order to accelerate development. In addition to the usual benefits from process automation and integration, the data generated by process instances is hugely valuable to them when looking at how to translate activities to more strategic actions when planning future improvements to their business operations. Now that their claims applications are in advanced testing stages, they are expanding the same technical stack to their underwriting applications, and are seeing a significant benefit from the reusability of components that they created during the claims project. They aren’t yet planning a V8 migration, although are very cognizant that this is likely in their future.
Following the customer presentation, Gustavo Mendoza, a Camunda senior sales engineer, gave us a technical demo of the V8 product stack to expand on some of the points that Daniel Meyer went through in his presentation earlier. We saw demos of the process and decision modelers, including the collaboration features, the UI forms builder for task handling, then the execution environment to see the user interaction with a running process as well as the Operate monitoring portal and integration with Slack.
The remainder of the afternoon was split into a hands-on live coding workshop for customers, and a partner workshop. A full and worthwhile day if you’re in the Camunda ecosystem.
Camunda has a couple of other CamundaLocal events coming up soon in Chicago and San Francisco, plus their main European conference in Berlin in May and their North American conference later in the year (September in New York, I think).