Today is Ada Lovelace Day — marking the contributions of the world’s first “programmer” — and the perfect day for Bizagi to launch their Ask Ada generative AI that helps knowledge workers find answers to questions about their organization’s data. Check out the short video clip on the AI product page to see how it looks to a user; basically, this is conversational analytics out of the box without having to predefine the analytics.
I had a sneak peak a few days ago with the always-informative Rachel Brennan, Bizagi’s VP of Product and Solutions Marketing, and she pointed out some of the important governance and privacy safeguards that they have put in place:
Ada uses Azure Private OpenAI GPT Service, rather than the public service
Ada is trained on Bizagi’s data structure and does not share any private data
Ada filters information to present only what is authorized and relevant to the user’s role and context
This focus on governance and privacy is something that a lot of companies are struggling with, but Bizagi seems to be moving in the right direction.
Many companies are choosing to focus on genAI for “co-pilot” developer tasks, including creating process models, or for replacing human steps in processes; having Ada as a trusted advisor for knowledge workers is a different angle to how AI can be used in the context of business processes. I’m imagining many other types of “user assist” tasks where AI can be applied, such as summarizing a long-running customer transaction so that the worker don’t have to read through every piece of content associated with that customer.
Ask Ada will be released this month, and is free to Bizagi customers until June 30, 2024. Looking forward to see how they expand these capabilities in the months to come.
Bennet Krause of Holisticon, an IT consultancy, presented some of the integrations that they’ve created between Camunda and GPT, which could be applied to other Large Language Models (LLMs). Camunda provides an OpenAI connector, but there are many other LLMs that may provide better functionality depending on the situation. Holisticon has created an open source GPT connector, which Bennet demonstrated in a scenario for understanding an inbound customer email and constructing an outbound response after the issue has been resolved by a customer service representative.
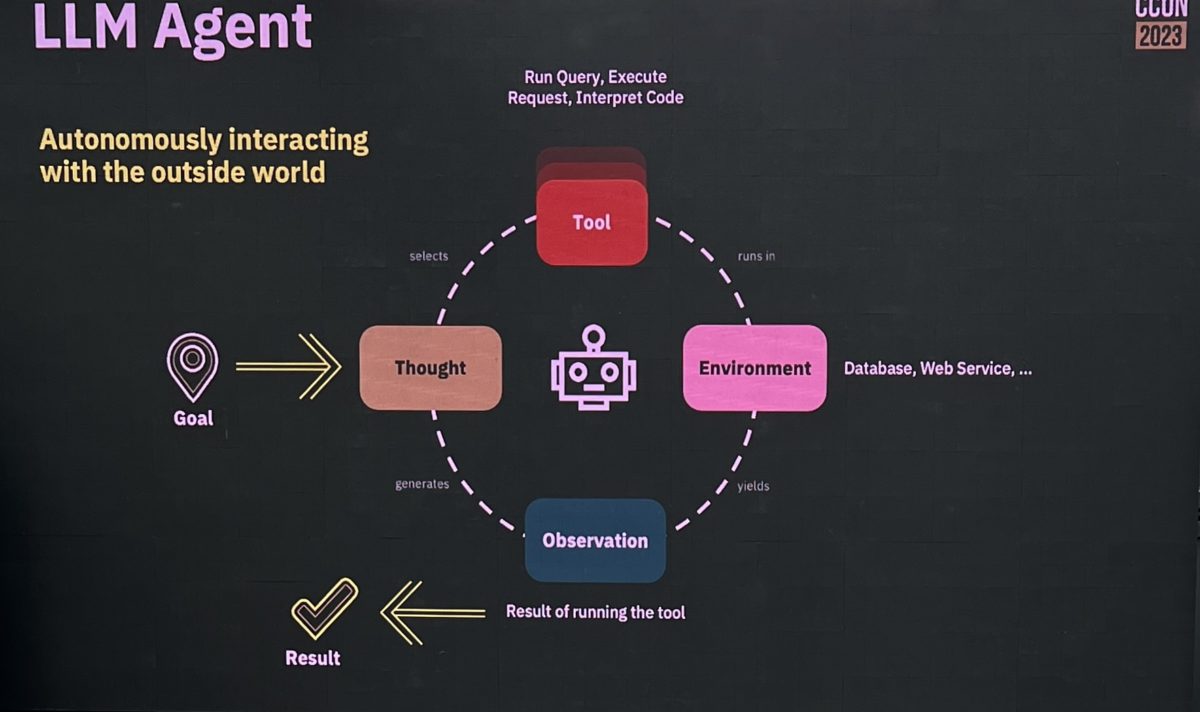
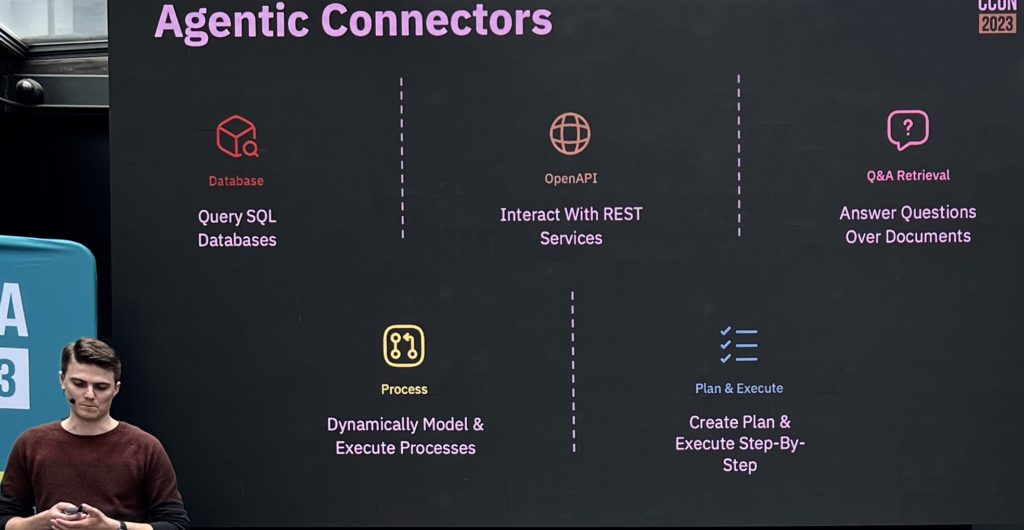
They have a number of foundational connectors — extract structured data from unstructured data, make decisions or classifications, compose text from instructions and templates, and natural language translation — as well as what he calls agentic connectors, which are automated agents interacting with the outside world.
The addition of the agentic connector allowed some paths in his customer service example to become completely automated, replacing the customer service representative with an automated agent. These connectors include a database connector to query SQL databases, an OpenAI connector to interact with REST services, a Q&A retrieval connector to answer questions based on documentation, a process connector to dynamically model and execute processes, and a plan and execute connector.
He warned of some of the potential issues with replacing human decisions and actions with AI, including bias in the LLMs, then finished with their plans for new and experimental connectors. In spite of the challenges, LLMs can help to automate or assist many BPM tasks and you can expect to see much more interaction between AI and BPM in the future.
This is the last session I’ll be at on-site for this edition of CamundaCon: we have the afternoon break now, then I need to head for the airport shortly after. I’ll catch up on the last couple of sessions that I missed when the on-demand comes out next week, and will post a link to the slides and presentations in case you want to (re)view any of the sessions.
Falko Menge and Marco Lopes from Camunda gave a presentation on the involvement of Camunda with the development of OMG’s core process and decision standards, BPMN and DMN. Camunda (and Falko in particular) has been involved in OMG standards for a long time, and embrace these two standards in their products. Sadly, at least to me, they gave up support for the case management standard, CMMN, due to a lackluster market adoption; other vendors such as Flowable support all three of the standards in their products and have viable use cases for CMMN.
Falko and Marco gave a shout out to universities and the BPM academic research conference that I attended recently as promoters of both the concepts of standards and future research into the standards. Camunda has not only participated in the standards efforts, but the co-founders wrote a book on Real-Life BPMN as they discovered the ways that it can best be used.
They gave a good history of the development of the BPMN standard and also of Camunda’s implementation of it, from the early days of the Eclipse-based BPMN modeler to the modern web-based modelers. Camunda became involved in the BPMN Model Interchange Working Group (MIWG) to be able to exchange models between different modeling platforms, because they recognized that a lot of organizations do much broader business modeling in tools aimed at business analysts, then want to transfer the models to a process execution platform like Camunda. Different vendors choose to participate in the BPMN MWIG tests, and the results are published so that the level of interoperability is understood.
DMN is another critical standard, allowing modelers to create standardized decision models and also supports the Friendly-Enough Expression Language (FEEL) for scripting within the models. The DMN Technolgy Compatibility Kit (TCK) is a set of decision models and expected results that provides test results similar to that of the BPMN MIWG tests: information about the vendors’ products test coverage are published so that their implementation of DMN can be assessed by potential customers.
Although standards are sometimes decried as being too difficult for business people to understand and use (they’re really not), they create an environment where common executable models of processes and decisions can be created and exchanged across many different vendor platforms. Although there are many other parts of a technology stack that can create vendor lock-in, process and decision models don’t need to be part of that. Also, someone working at a company that uses BPMN and DMN modeling tools can easily move to a different organization that uses different tools without having to relearn a proprietary modeling language. From a model richness standpoint, many vendors and researchers working together towards a common goal can create a much better and more extensive standard (as long as they’re not squabbling over details).
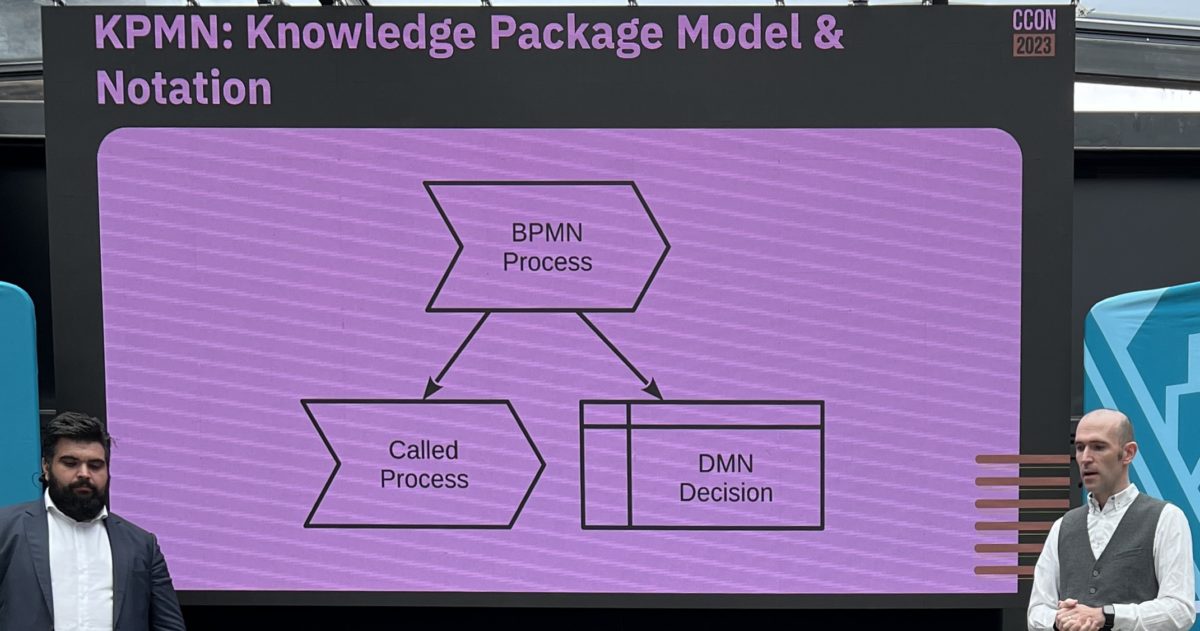
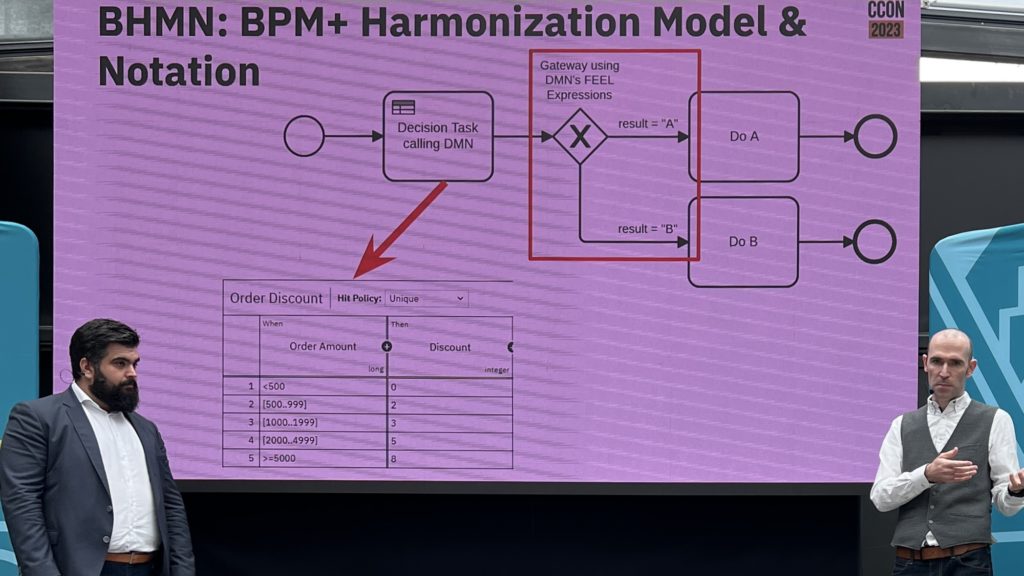
They went on to discuss some of the upcoming new standards: BPM+ Harmonization Model and Notation (BHMN), Shared Data Model and Notation (SDMN), and Knowledge Package Model and Notation (KPMN), all of which are in some way involved in integrating BPMN and DMN due to the high degree of overlap between these standards in many organizations. Since these standards aren’t close enough to release, they’re not planned for a near-future version of Camunda, but they’ll be added to the product management roadmap as the standards evolve and the customer requirements for the standards becomes clear.
Steven Gregory of Cardinal Health™ Sonexus™ Access and Patient Support, a healthcare technology provider, presented on some of the current US healthcare trends — including value-based care and telemedicine — and the technology trends that are changing healthcare, from IoT wearable devices to AI for clinical decisioning. Healthcare is a very process-driven industry, but many of the processes are manual, or embedded within forms, or within legacy systems: scheduling, admin/discharge, insurance, and health records management. As with many other industries, these “hidden” workflows are critical to patient outcomes but it’s not possible to see how the flows work at any level, much less end-to-end.
There’s some amount of history of clinical workflow automation; I worked with Siemens Medical Systems (now Cerner) on their implementation of TIBCO’s workflow more than 10 years ago, and even wrote a paper on the uses of BPM in healthcare back in 2014. What Steven is talking about is a much more modern version of that, using Camunda and a microservice architecture to automate processes and link legacy systems.
They implemented a number of patient journey workflows effectively: appointment creating, rescheduling and cancellation; benefits verification and authorization; digital enrollment; and some patient-facing chatbot flows. Many of these are simply automation of the existing manual processes, but there’s a lot of benefit to be gained as long as you recognize that’s not the final version of the flow, but a milestone on the journey to process improvement.
He discussed a really interesting use case of cell and gene therapy: although they haven’t rolled this out this yet, it’s a complex interaction of systems integration, data tracking across systems, unique manufacturing processes while providing personalized care to patients. He feels that Camunda is key for orchestrating complex processes like this. In the Q&A, he also spoke about the difference in ramp-up time for their developers, and how much faster it is to learn Camunda and individual microservices than a legacy system.
Great examples of moving beyond straightforward process orchestration for improving critical processes.
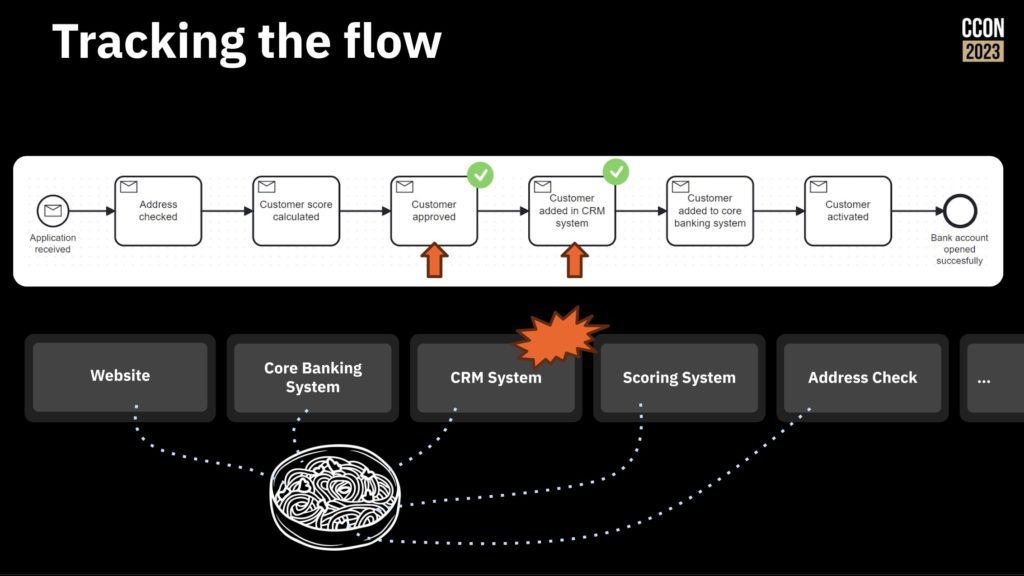
The second day of CamundaCon started with a keynote by Camunda co-founder and chief technologist Bernd Ruecker and CTO Daniel Meyer. They started with the situation that plagues many organizations: point-to-point integrations between heterogeneous legacy systems and a lot of manual work, resulting in inefficiencies and fragile system architecture. News flash: your customers don’t care about your aging IT infrastructure, they just want to be served in a way that works for them.
You can swap all of this with a “big bang” approach that changes everything at once, but that’s usually pretty painful and doesn’t work that well. Instead, they advocate starting with a gradual modernization which looks more like the following.
First, model your process and track the flow as it moves through different systems and steps. This allows you to understand how things work without making any changes, and identify the opportunities for change. You can actually run the modeled processes, with someone manually moving them through the steps as the work completes on other systems, and tracking the work as it passes through the model.
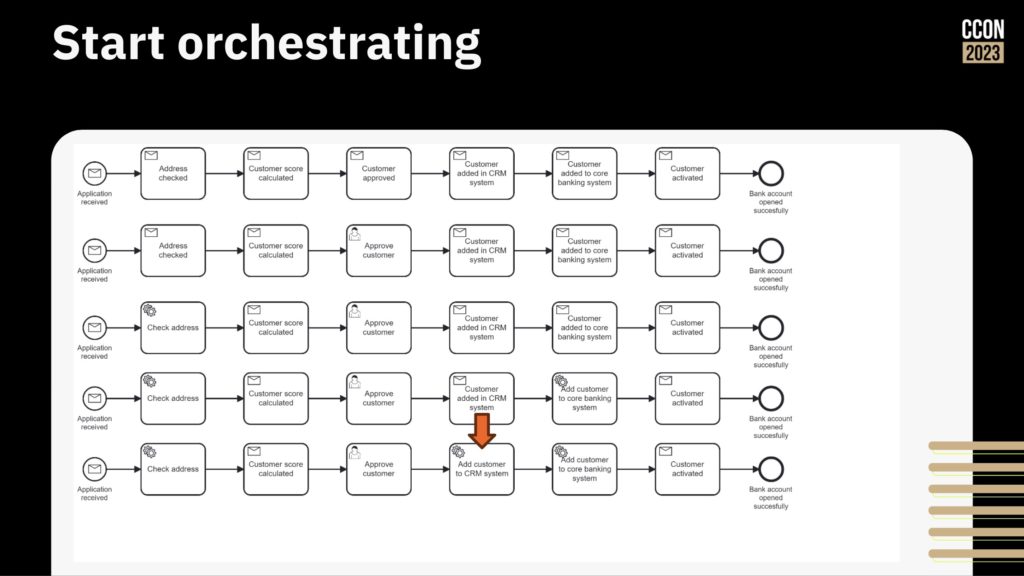
Next, start orchestrating the work by taking the flow that you have, identifying the first best point to integrate, and doing the integration to the system at that step. Once’s that’s working, continue integrating and automating until all the steps are done and the legacy systems are integrated into this simple flow.
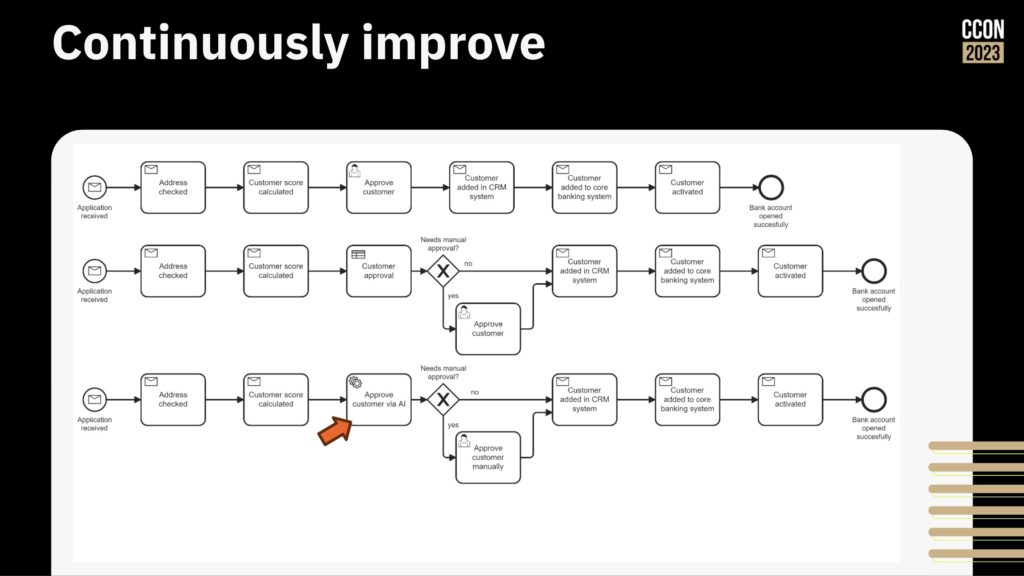
Then, start improving the process by adding more logic, rearranging the steps, and integrating/automating other systems that may be manually integrated.
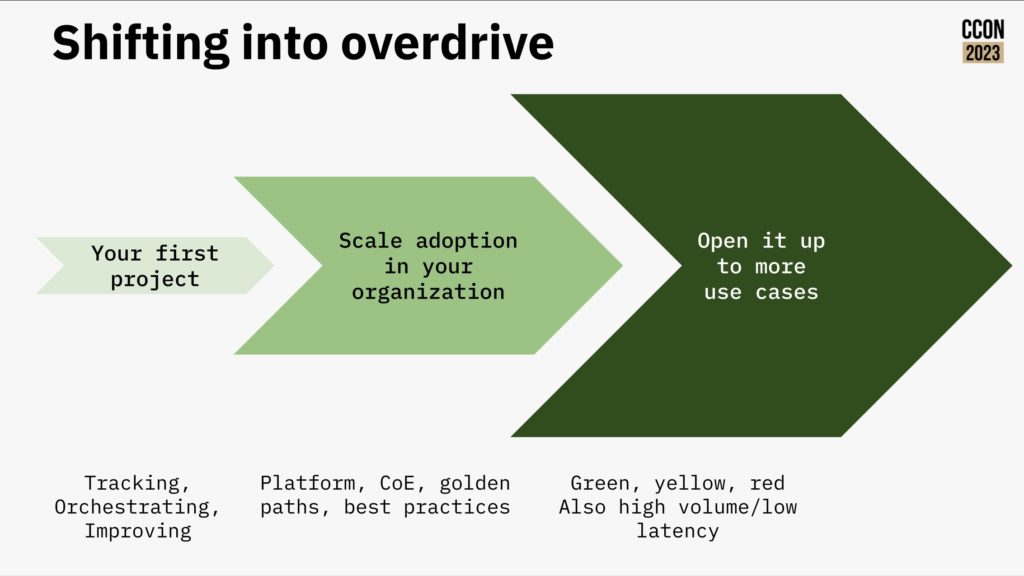
That’s a great approach for a first project, or when you’re just focused on automating a couple of processes, but you also need to consider the broader transformation goals and how to drive it across your entire organization. There are a number of different components of this: establishing a link between value chains, orchestrations and down through to business and technical capabilities; driving reuse within your organization using the newly-launched Camunda Marketplace; and providing self-service deployment of Camunda to remove any barriers to getting started.
An important part of your modernization journey will be the use of connectors, while allow you to expose integrations into a wide variety of system types directly into a process model without the modeler needed to understand the technical intricacies of the system being called. This, and the use of microservices to provide additional plug-in functionality, makes it easier for developers and technical analysts to build and update process-centric applications quickly. Underpinning that is how you structure development teams within your organization (autonomy versus centralization) and support them with a CoE, smoothing the path to successful implementations.
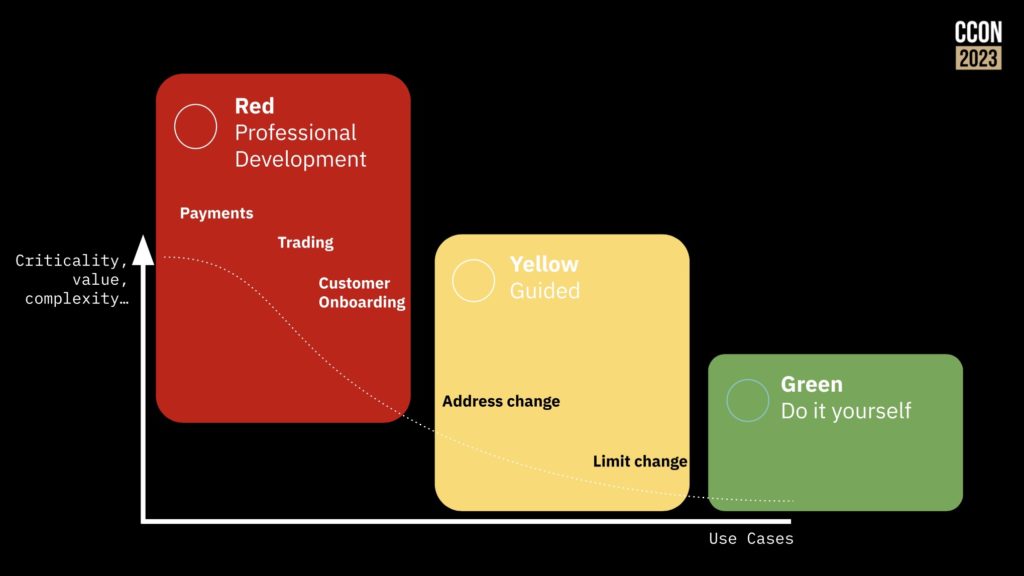
In short, the easier you make it for teams to build new applications that fit into corporate standards and meet business goals, the less likely you are to have business teams be forced go out and try to solve the problem themselves when they really need a more technical approach, or just suffer with a manual approach. You’ll be able to categorize your use cases to understand when a business-driven low-code solution will work, and what you need the technical developers to focus on.
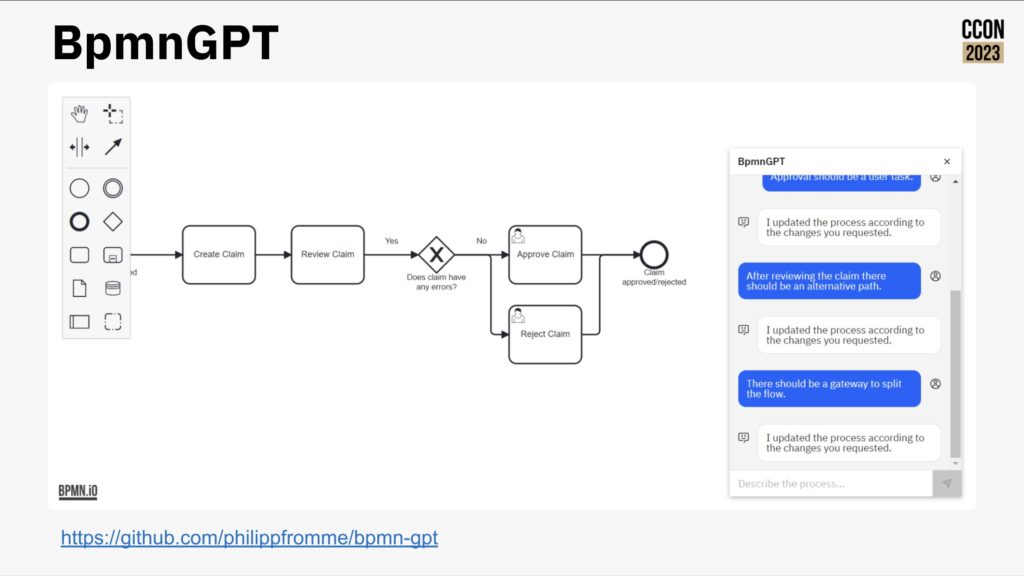
Camunda now includes a much friendlier out of the box user interface, rich(er) forms support and testing directly in the process modeler; this allows more of the “yellow” areas in the diagram above to be implemented by less-technical developers and analysts. They are also looking at how AI can be used for generating simple process models or provide help to a person who is building a model, as well as the more common use of predictive decisioning. They’ve even had a developer in the community create BpmnGPT to demonstrate how an AI helper can assist with model development.
They wrapped up with a summary of the journey from your first project to scaling adoption to a much broader transformation framework. Definitely some good goals for those on any process automation journey.
Our first day at CanundaCon in New York wrapped up with a conversation between Camunda CTO Daniel Meyer and Ernst and Young’s Deepak Tiwari, operated by Amy Johnston. The focus was on implementing best of breed automation in financial services — definitely a topic that I can get behind, as you might have known from my Rolling Your Own Digital Automation Platform presentation at bpmNEXT in 2019 that ended up with me delivering a similar keynote later that same year at CamundaCon 2019 in Berlin. Although there is a technical challenge with selecting the right products to mix into your hyperautomation platform, the bigger issue can be managing multiple vendors, especially when something goes wrong. You also need to create and enforce the best practices for how to use the different products together through a CoE, so that you don’t end up with someone using a process model as a decision tree or other design atrocities.
They covered a variety of topics: how FIs are now considering themselves to be software companies in their own right (which can be okay, or can go horribly horribly wrong); the impact of low code platforms; legacy home-grown platforms versus best of breed based on commercial components; using a process-first approach; IT modernization via cloud replatforming which then triggers application modernization; generative AI (because you can’t have a tech conversation these days without mentioning it at least once); and the interaction of personal devices with financial services. Much of what they discussed was not specific to financial services, and some of the audience questions were specific to Camunda directions.
We finished with a brief fireside chat (sans fire) between Amy and Jakob Freund, touching on CoE, process-first orientation, AI for solution acceleration, and how Camunda has changed and grown as a company.
Having spent the day perched on a hard wooden chair, balancing my folding keyboard and tablet on my lap, I’m ready to go off the record. Back with day 2 coverage tomorrow.
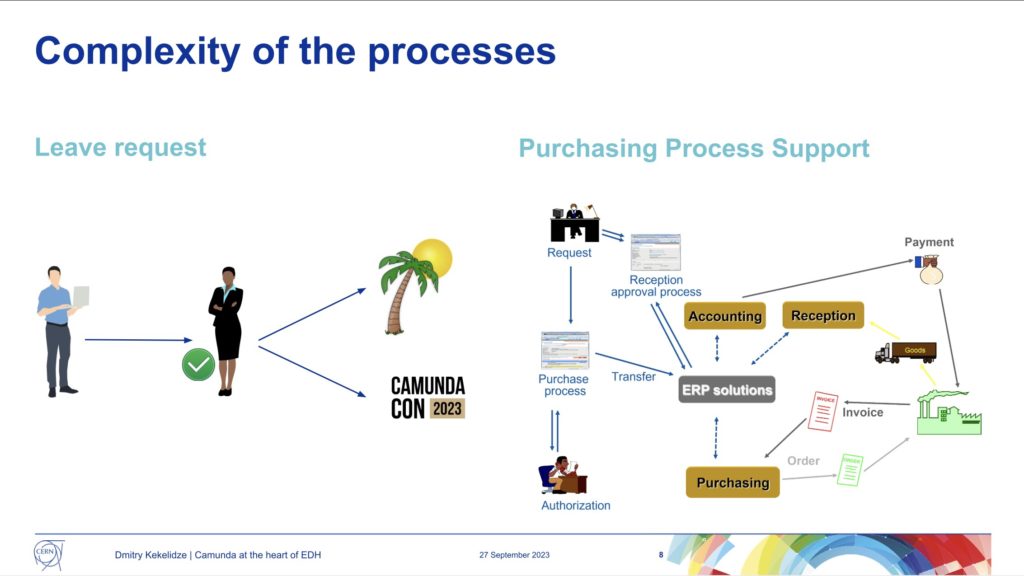
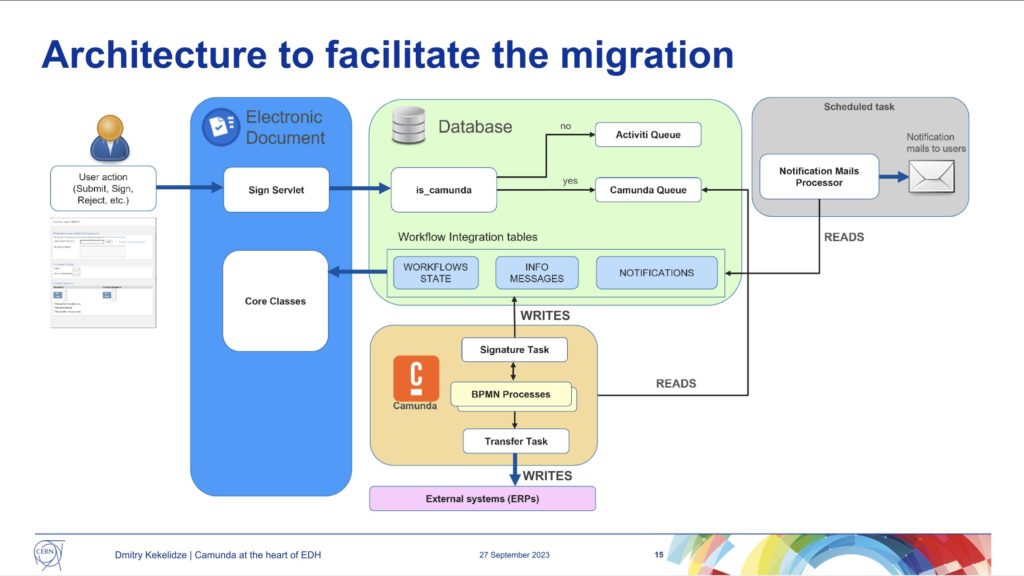
As we reached the end of the first day of CamundaCon 2023 in NYC, Dimitri Kekelidze of Conseil Européen pour la Recherche Nucléaire (CERN, or what we in English would call the European Council for Nuclear Research) presented on their use of Camunda for handling electronic documents. Although an “administrative” sort of workflow, it’s pretty critical: they started in the early 1990s to move from paper to electronic forms and documents, and those are used for everything from access requests to specific buildings to all types of HR forms to training requests to purchasing.
The volume is pretty significant: there have been 2 million leave requests alone since the system was started in 1992, and this is not just about filling out a form online, it’s the entire process of handling the request that is kicked off by the form. In short, document-driven processes where the document is an electronic form filled out on their employee portal.
CERN started their electronic document handling in 1992 (long before Camunda) with a home-built workflow solution, then moved to Oracle workflow in 1998, then to ActiveVOS (a name I haven’t heard in years!) in 2006, Activiti in 2013, and Camunda in 2021. Making the move from Activiti to Camunda meant that they could migrate quite a bit of the BPMN and code, although there were specific functions that he discussed that required a bit of work for migration. Since then, they’ve migrated 65 processes, and have 9 still to migrate; this has necessitated an architecture that supports both Activiti and Camunda, depending on the type of workflow.
Because of the business criticality, volume and complexity of these processes, there is a significant amount of testing prior to migration. They had a number of bugs/glitches during the migration: some because they had some legacy code that was no longer required (such as marking workflow instances busy/free in an external database), and some due to overly complex BPMN diagrams that could be redrawn in a simpler fashion to remove manual escalations and error handling.
In the upcoming months, they plan to complete the migrate of the remaining 9 processes so that they can decommission Activiti. They will also be upgrading to Camunda 8, and adding some custom plugins to Cockpit for monitoring and managing the flows.
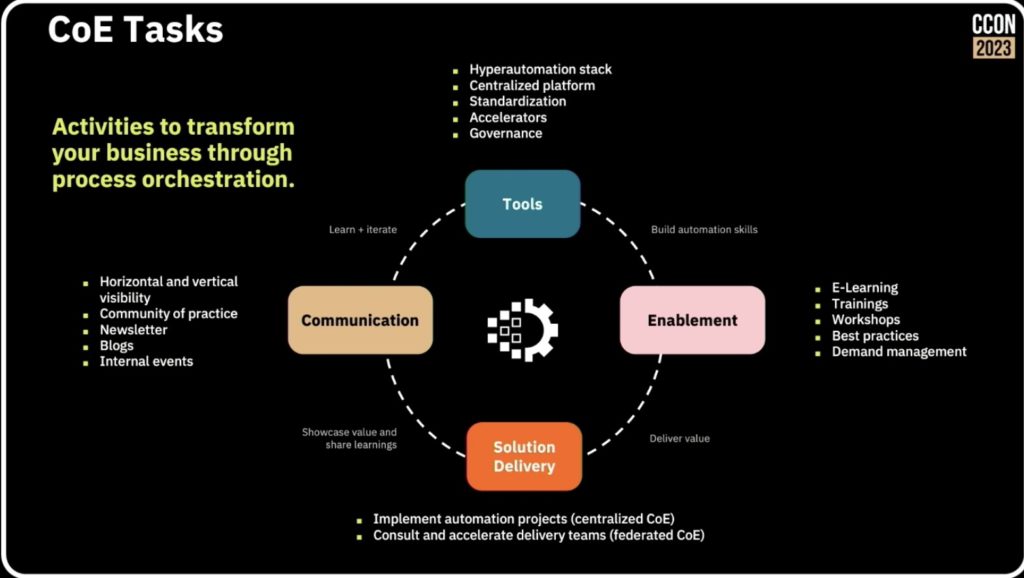
We’ve heard a few things already today on the value of centres of excellence (CoE): achieving the strategic scaled adoption of process orchestration maturity is going to require a CoE. André Wickenhöfer and Björn Brinkmann of Provinzial, a large Germany insurance company, were joined by Leon Strauch of Camunda to discuss CoE in general and how they are used at Provinzial.
CoEs can be centralized or more distributed — often they start out centralized but end up decentralized and federated within large organizations — but have some common activities and areas of expertise.
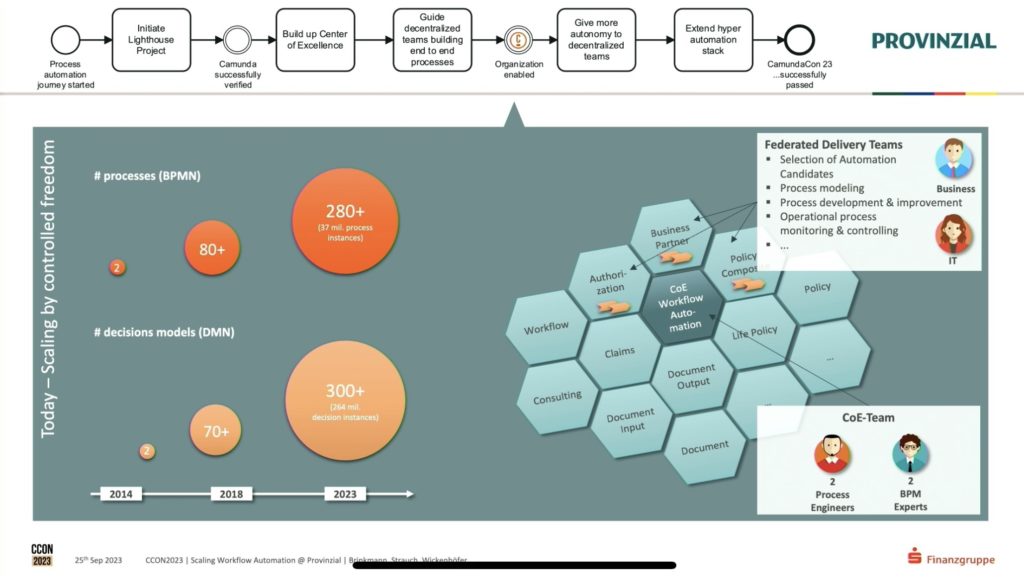
Provinzial started developing their CoE in conjunction with some successful implementation projects over the last 10 years; they spent quite a bit of time discussing the complexity of their projects, and how having some shared knowledge, methodologies and tools via their CoE has made it possible to do projects of this scope so successfully. The CoE supports the hyperautomation tech stack that is then used by the projects, allowing for common areas of discovery, design, automation and improvement. One of their primary conclusions was that this type of scaling is only possible through the use of a CoE and federated delivery teams.
Although the presentation was supposed to be about their CoE, we heard a lot of great information on the automation projects that they’ve been developing, and how each project can push new tools and methods back to the CoE for more widespread acceptance — worth watching the replay when it’s available to better understand what they learned along this journey.
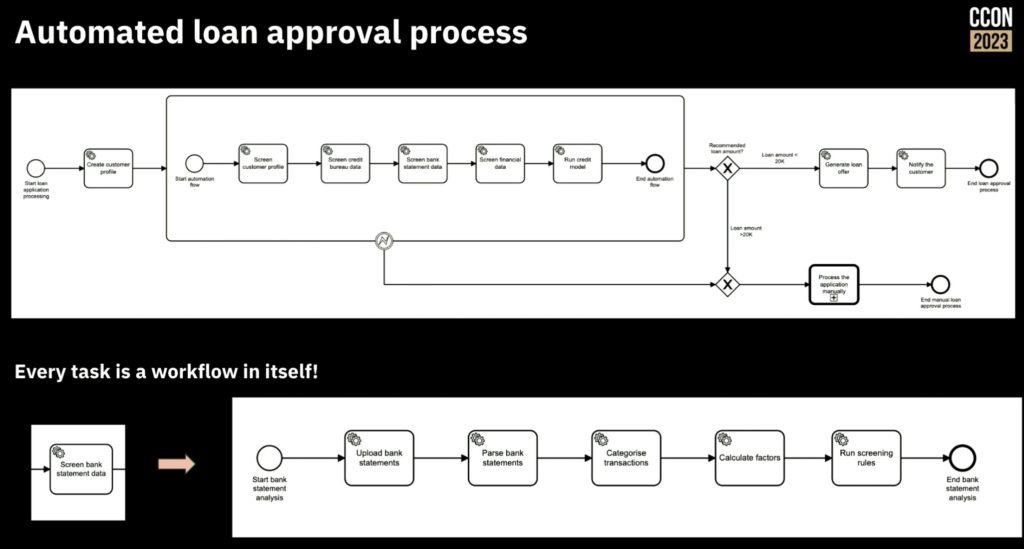
Rajesh Kumar Dharmalingam of Funding Societies Pte Ltd, a Singapore-based fintech startup, shared the story of their automated processes for instant loan approval. They provide (typically unsecured) financing to small and medium enterprises in Southeast Asia, from micro loans to much larger term loans, a total of about $1B USD per year. One key to their success is near-instant loan approval with manual intervention only for exceptions, while still successfully managing loan risk.
Loan approval processes are pretty much the same everywhere: collect information about the client, gather and assess financial information and risk, determine the allowable loan amount, and provide funding to the client. Funding Societies has a relatively straightforward loan approval process, but it includes a number of more complex tasks and decisions to assess risk.
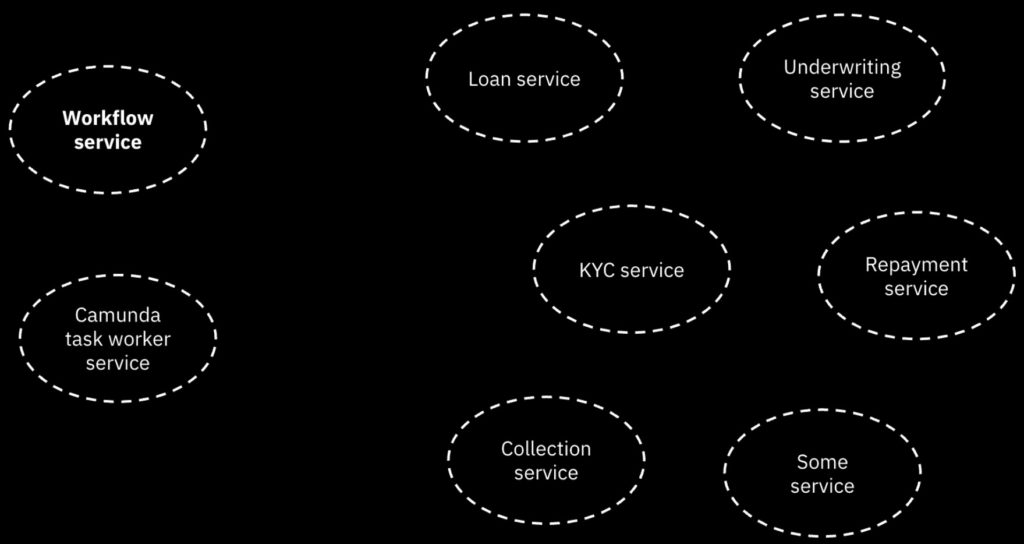
They have deployed Camunda as a microservice (in AWS cloud) as a peer to many other microservices that they use, which gives them quite a bit of flexibility and scalability.
Rajesh credits Camunda with helping him understand the value of rules/decision management, which they ended up relying on quite a bit: there are different sets rules for different countries and loan types, and rules are used for many of the decisions with the process flow. They design their processes with subprocesses for reusability in order to avoid monolithic processes, although that has been a journey for them; he advises just getting started first, then refactor the processes later. They don’t use the Camunda tasklist, but build all of their UI in Angular — this is a common approach for more technical development shops that are integrating Camunda into a much broader platform. Lots of interest from the audience in questions, since “instant” and “automated” are what everyone wants to see in their loan processes.