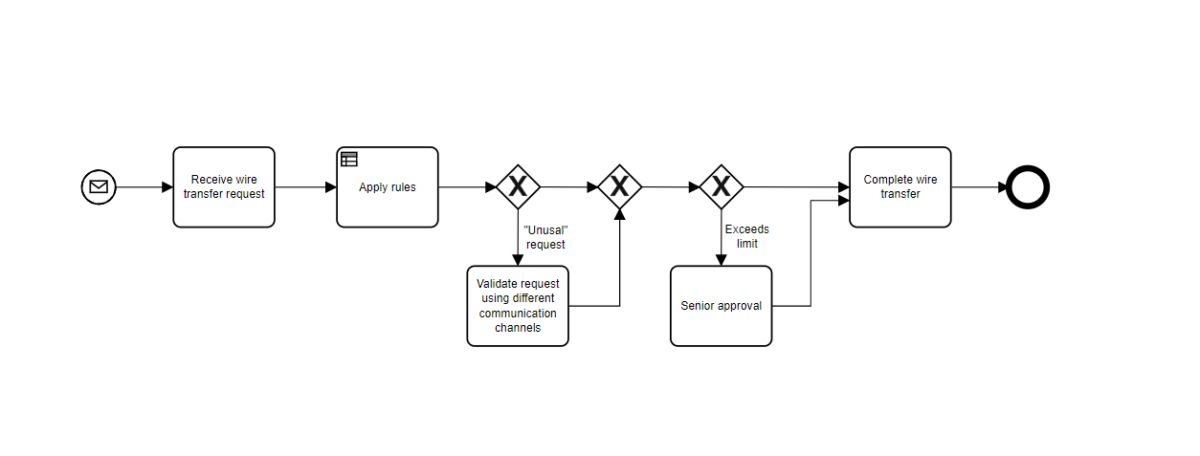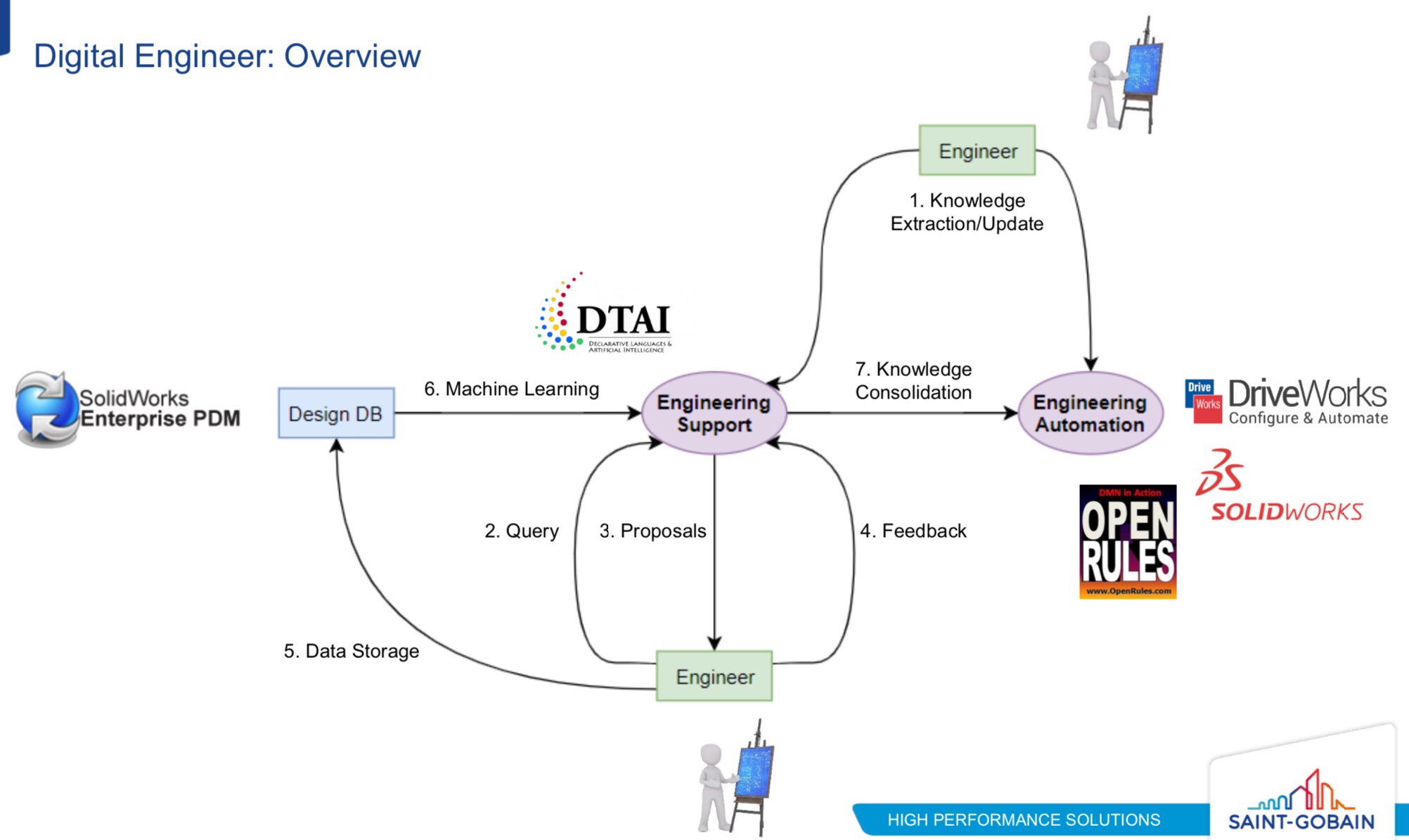
Falko Menge and Marco Lopes from Camunda gave a presentation on the involvement of Camunda with the development of OMG’s core process and decision standards, BPMN and DMN. Camunda (and Falko in particular) has been involved in OMG standards for a long time, and embrace these two standards in their products. Sadly, at least to me, they gave up support for the case management standard, CMMN, due to a lackluster market adoption; other vendors such as Flowable support all three of the standards in their products and have viable use cases for CMMN.
Falko and Marco gave a shout out to universities and the BPM academic research conference that I attended recently as promoters of both the concepts of standards and future research into the standards. Camunda has not only participated in the standards efforts, but the co-founders wrote a book on Real-Life BPMN as they discovered the ways that it can best be used.

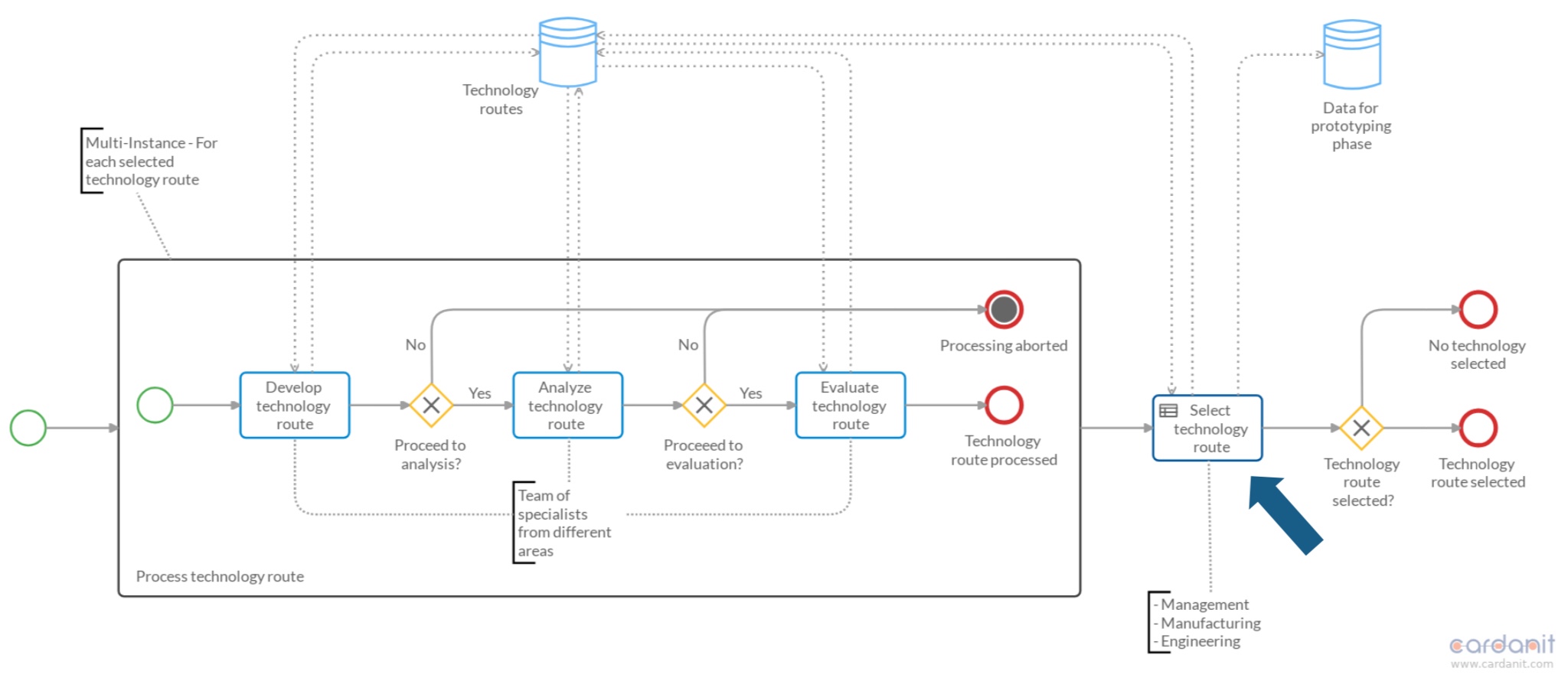
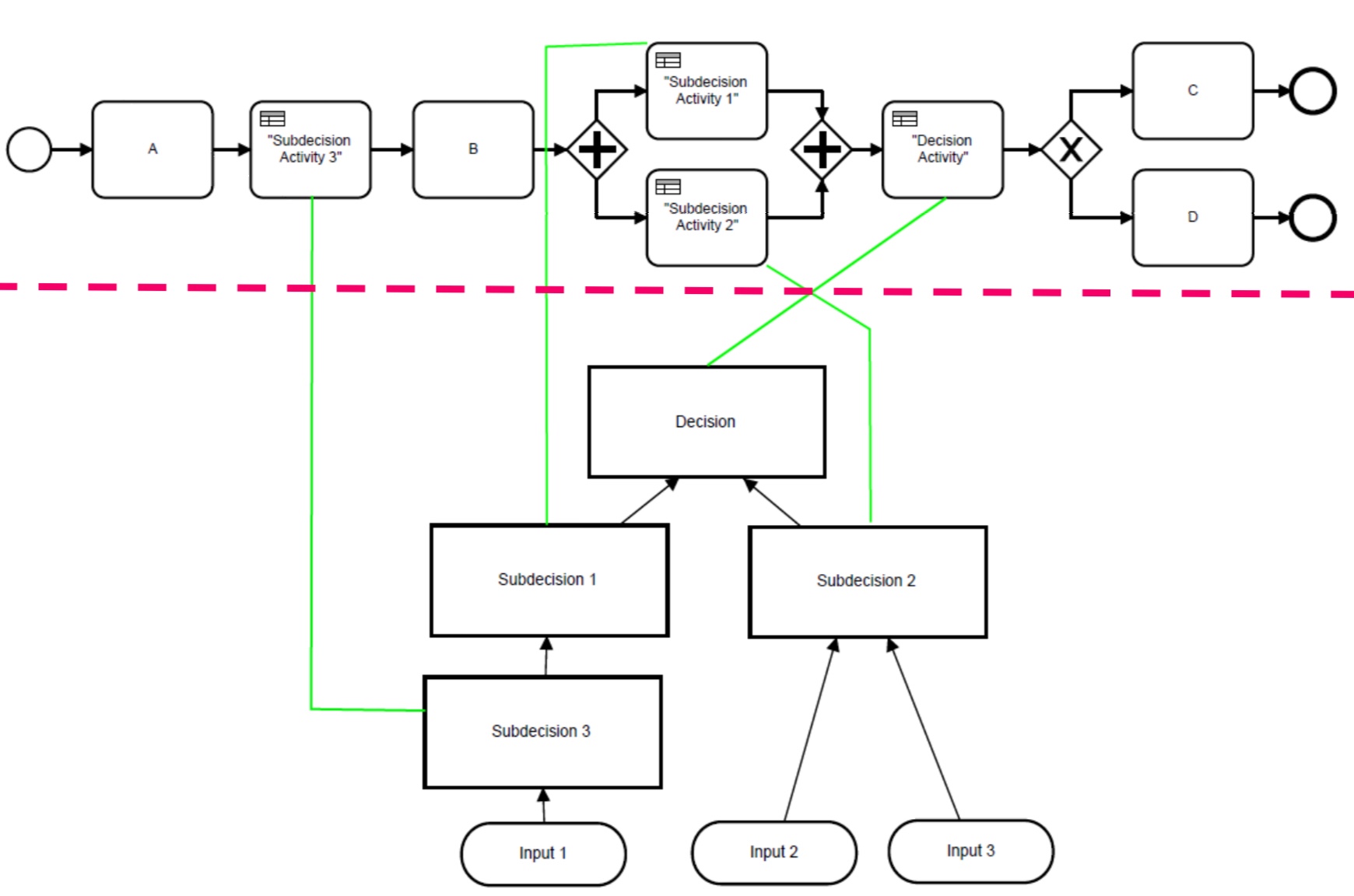
They gave a good history of the development of the BPMN standard and also of Camunda’s implementation of it, from the early days of the Eclipse-based BPMN modeler to the modern web-based modelers. Camunda became involved in the BPMN Model Interchange Working Group (MIWG) to be able to exchange models between different modeling platforms, because they recognized that a lot of organizations do much broader business modeling in tools aimed at business analysts, then want to transfer the models to a process execution platform like Camunda. Different vendors choose to participate in the BPMN MWIG tests, and the results are published so that the level of interoperability is understood.
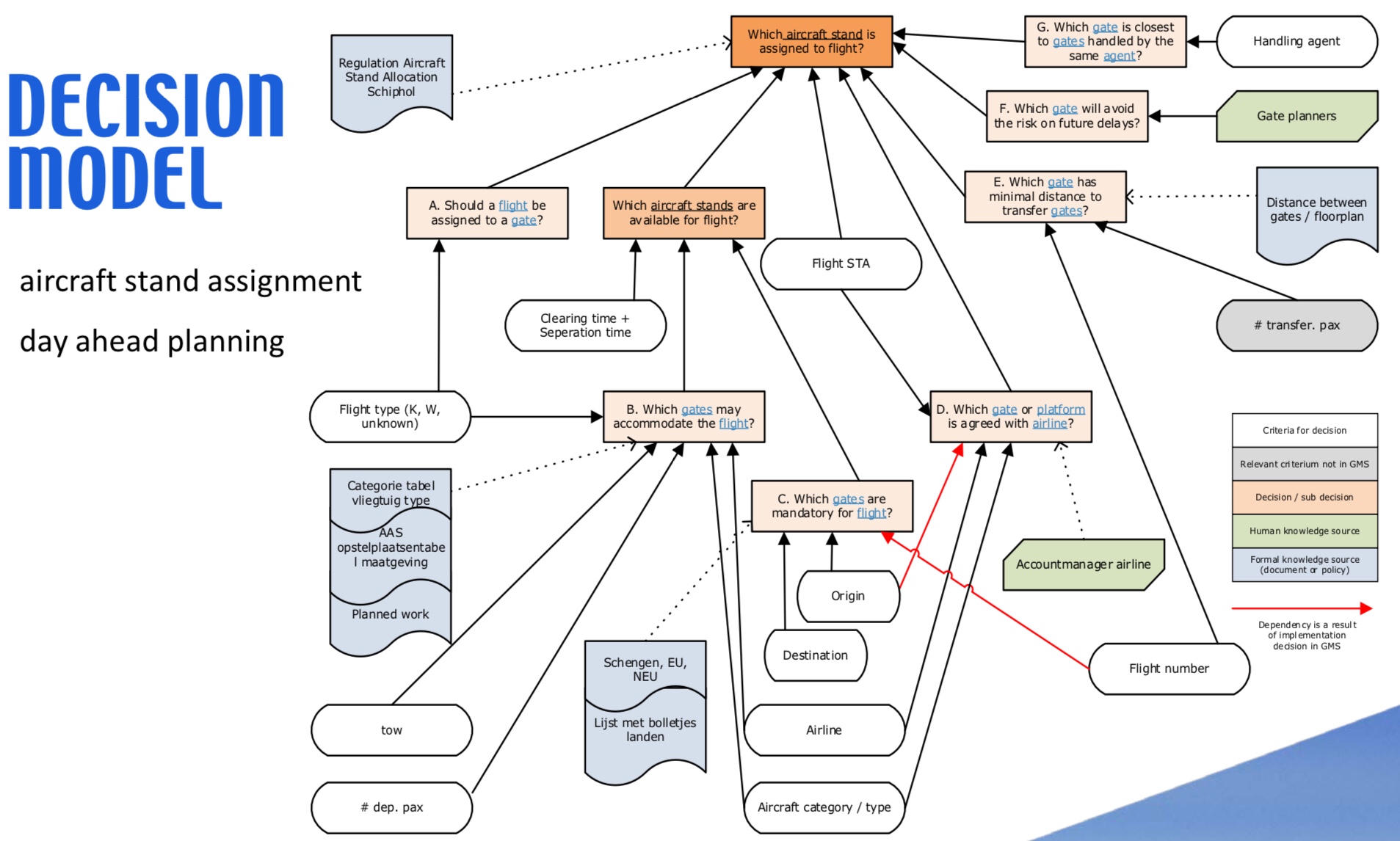
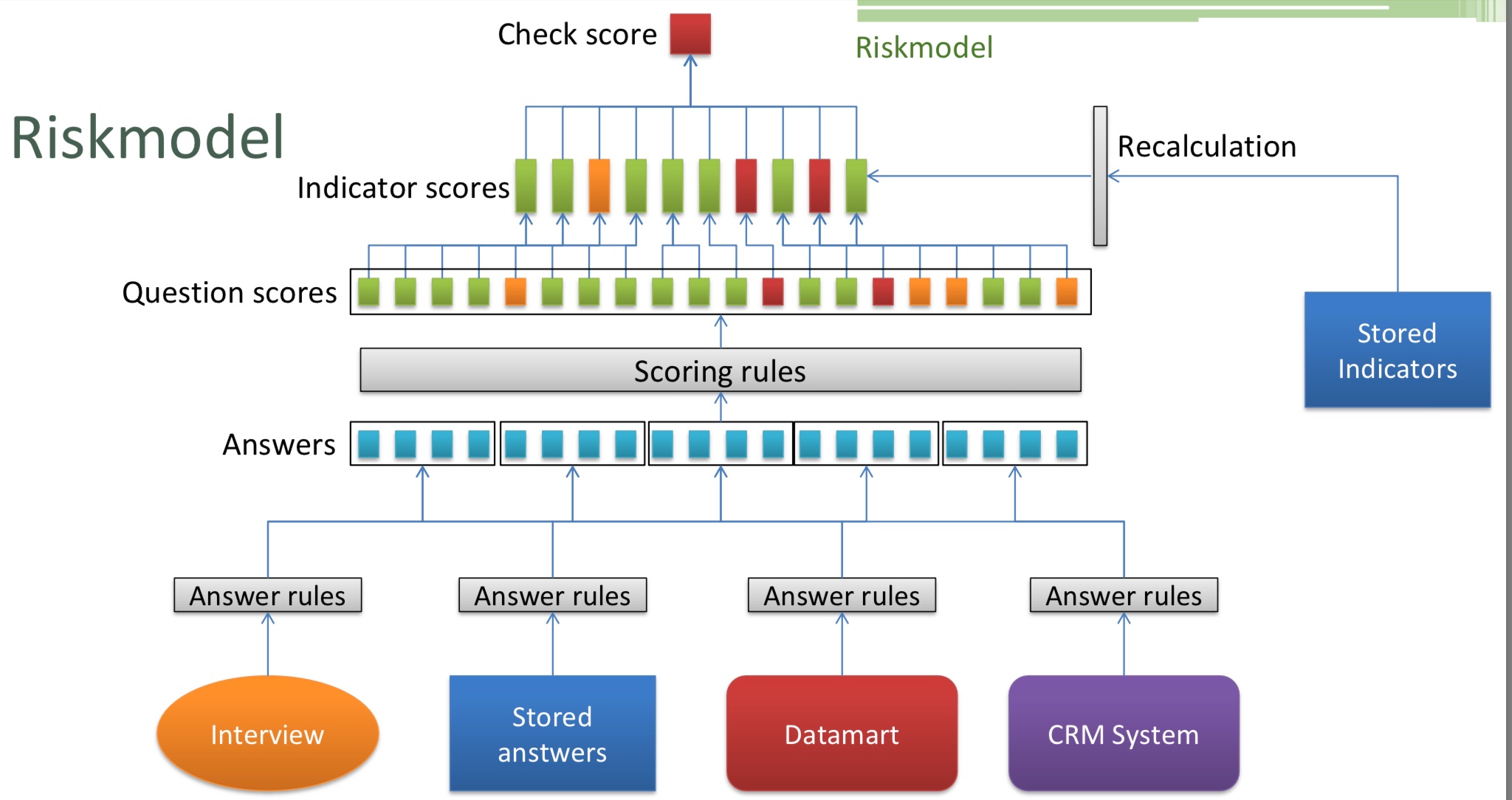
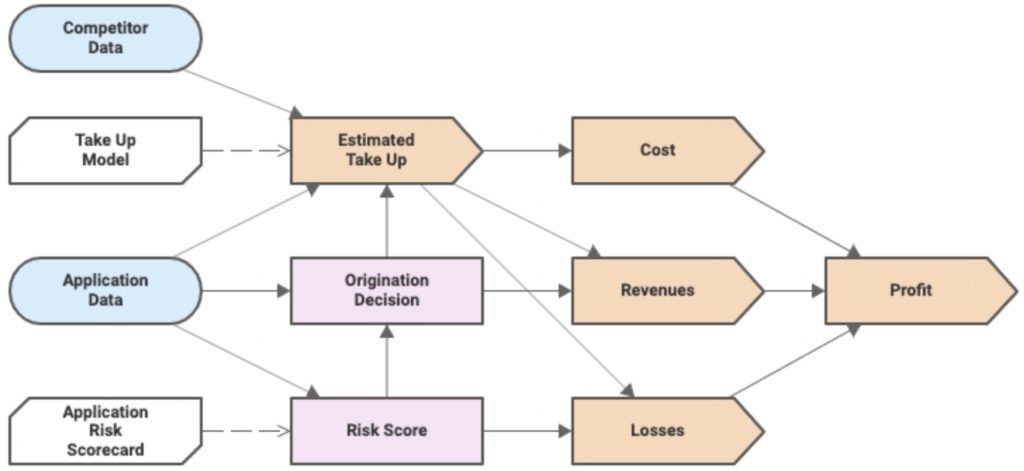
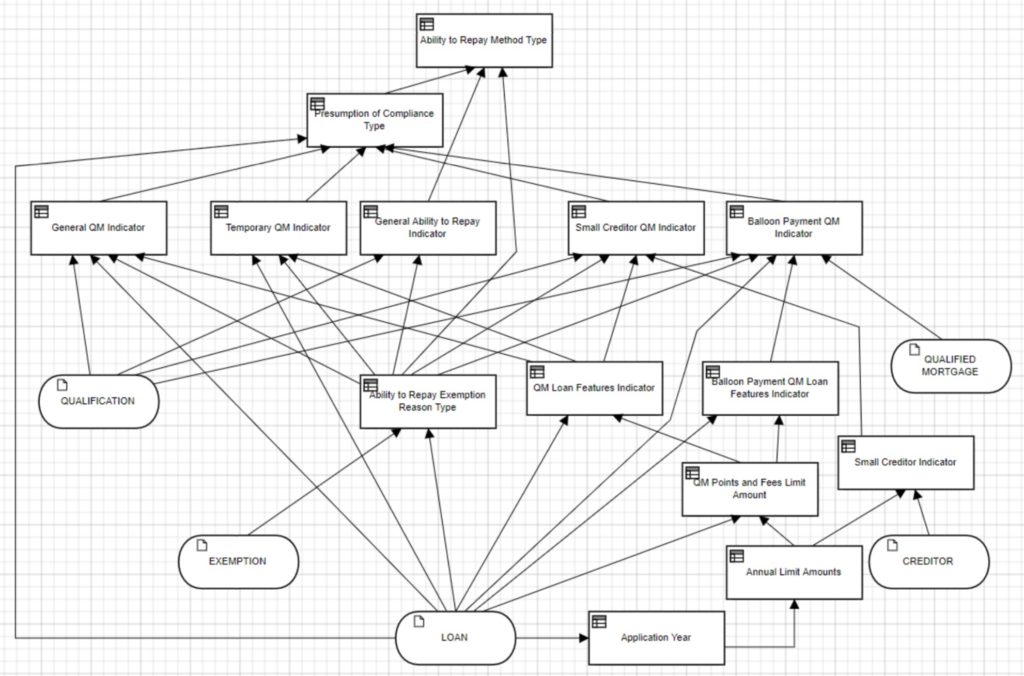
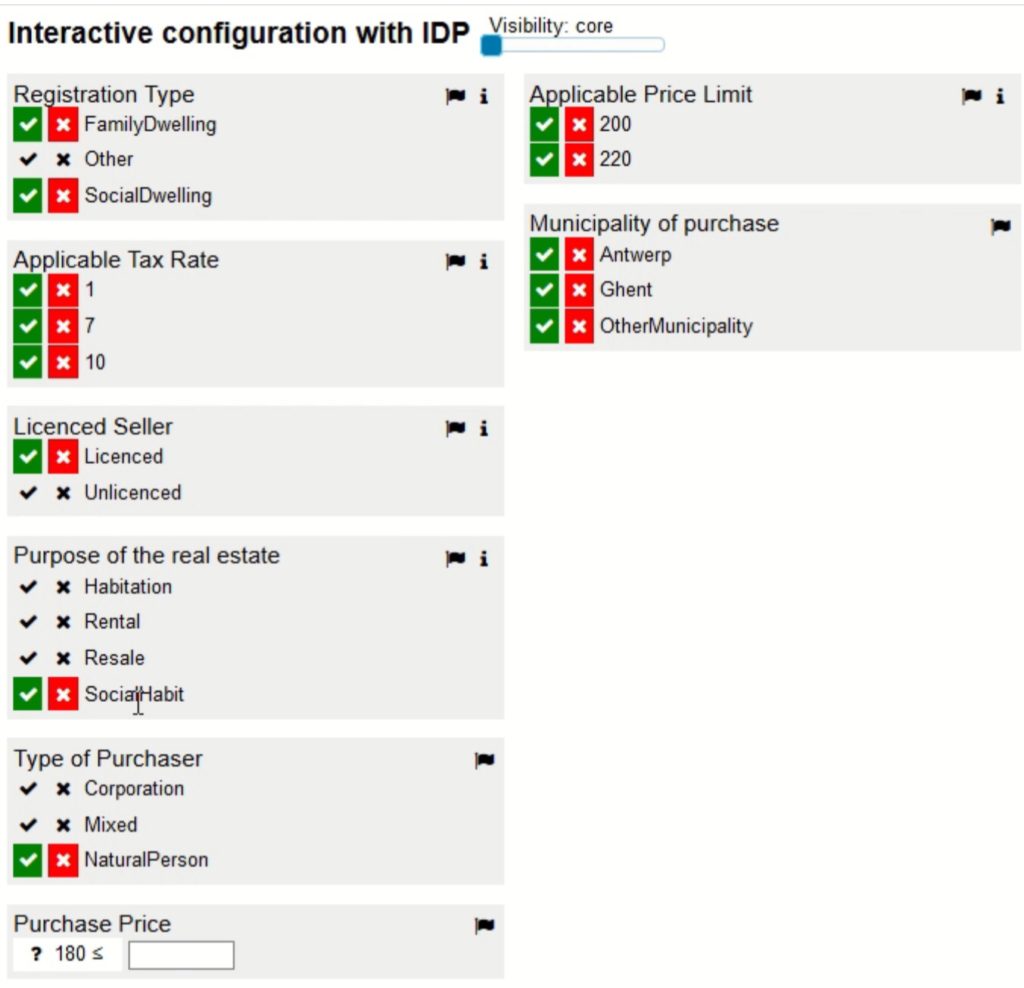
DMN is another critical standard, allowing modelers to create standardized decision models and also supports the Friendly-Enough Expression Language (FEEL) for scripting within the models. The DMN Technolgy Compatibility Kit (TCK) is a set of decision models and expected results that provides test results similar to that of the BPMN MIWG tests: information about the vendors’ products test coverage are published so that their implementation of DMN can be assessed by potential customers.
Although standards are sometimes decried as being too difficult for business people to understand and use (they’re really not), they create an environment where common executable models of processes and decisions can be created and exchanged across many different vendor platforms. Although there are many other parts of a technology stack that can create vendor lock-in, process and decision models don’t need to be part of that. Also, someone working at a company that uses BPMN and DMN modeling tools can easily move to a different organization that uses different tools without having to relearn a proprietary modeling language. From a model richness standpoint, many vendors and researchers working together towards a common goal can create a much better and more extensive standard (as long as they’re not squabbling over details).
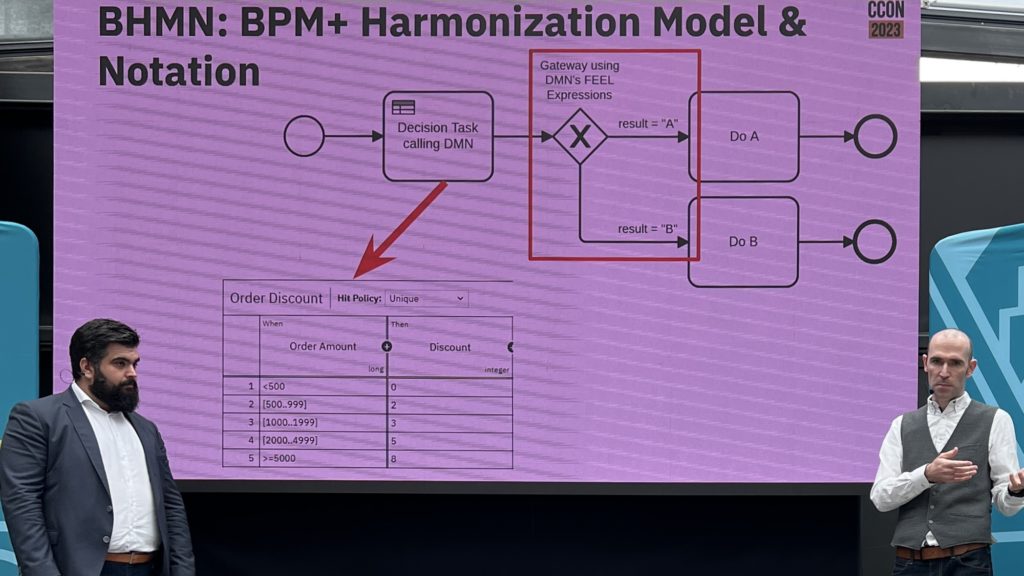
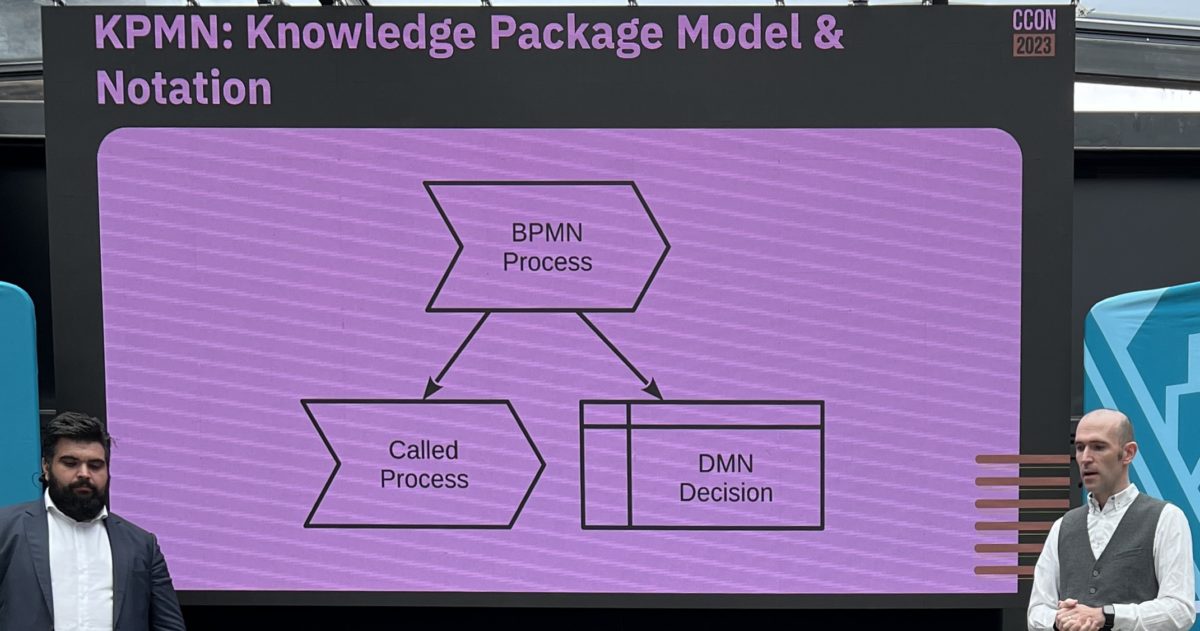
They went on to discuss some of the upcoming new standards: BPM+ Harmonization Model and Notation (BHMN), Shared Data Model and Notation (SDMN), and Knowledge Package Model and Notation (KPMN), all of which are in some way involved in integrating BPMN and DMN due to the high degree of overlap between these standards in many organizations. Since these standards aren’t close enough to release, they’re not planned for a near-future version of Camunda, but they’ll be added to the product management roadmap as the standards evolve and the customer requirements for the standards becomes clear.