
DMN 2.0? Gary Hallmark, Oracle
Gary Hallmark presented on the next major version of DMN that’s in the works, starting with a timeline of what’s happened so far since the original RFP in 2011 up to the expected 1.3 release later this year. He added the question mark to his title because whether to issue a major (fix the mistakes of the past) or minor (patch and live with the mistakes of the past) release is still under consideration. He went through the top 10 requested features, half of which can be backward-compatible with DMN 1.x (i.e., DMN 1.x models can be ingested and executed in the new version) and half of which can’t.
He mentioned the issue of harmonization of DMN, BPMN and CMMN, a topic that I am especially interested in, and plan to ask the vendors about later this afternoon when I am moderating the panel. That can include a common item definition model that is used by all three notations, tighter integration of DMN with BPMN gateways and CMMN sentries, and easier reference and interchange between the model types. This could also include the use of FEEL and decision tables for expressions and logic in BPMN and CMMN, such as at gateways and in data associations. We already have the problem of keeping a collection of different model types sorted out, and there may need to be a “model of models” concept to tie these together.

Better model validation is another request for the next version of DMN; I don’t have a lot of experience with DMN, but judging by the comments here, the “null” returned for all types of errors is definitely a touchy issue. This could be improved with a “required” property in item definitions and model validation with respect to the item definitions. Additional datatypes would also be useful, such as integers and some types of ranges. There are suggestions for better ways to deal with iteration and recursion in a new version of DMN, some of which are already being done by vendors such as Oracle in their products to make it easier for business analysts to understand and model.
Something that seems simple but would break compatibility is moving to case insensitive names (indicating just how IT-centric the original, and possibly the current, committee was), and handling some things such as single-quoted strings unambiguously. Moving to Xpath-like sequences instead of the current lists also wouldn’t be compatible, nor are many types of recursion and cyclic information requirements.
As mentioned earlier, half of the top requested features could be done in 1.x because they don’t break compatibility; one option is to implement those in a 1.x version and leave the others for now. The alternative is to start the DMN 2.x RFP process, which is a much larger undertaking, which will delay the implementation of those features but will open the door (or Pandora’s box) for a completely new version of DMN. Lots of great discussion at the end of this presentation: many of the people in the room are active contributors to the standard and/or vendors who implement the standard, so they definitely have both knowledge and opinions on the subject.
Quality of Decision Models. Jan Vanthienen, KU Leuven
Jan Vanthienen presented on measuring quality of decision models, starting with notions of information quality, resulting in measures such as complexity and traceability. For example, you can look at complexity of a DRD based on number of decision, number of elements and cyclomatic comlexity; complexity of a decision table can be based on hit policy usage and total number of input variables.
Consistency and interpretability in decision tables can be measured by a unique hit table (no overlapping rules) and a natural order for easy visual reading of the rules — it is more important to be correct and consistent than compact.
There’s a contextual quality factor when we look at a decision model that is related to a process model, where the connections between the two models can be fairly complex. He presented a set of guidelines for integrating processes and decision, including avoiding embedding decisions in gateways: something that happens all the time, in my experience with process modeling.
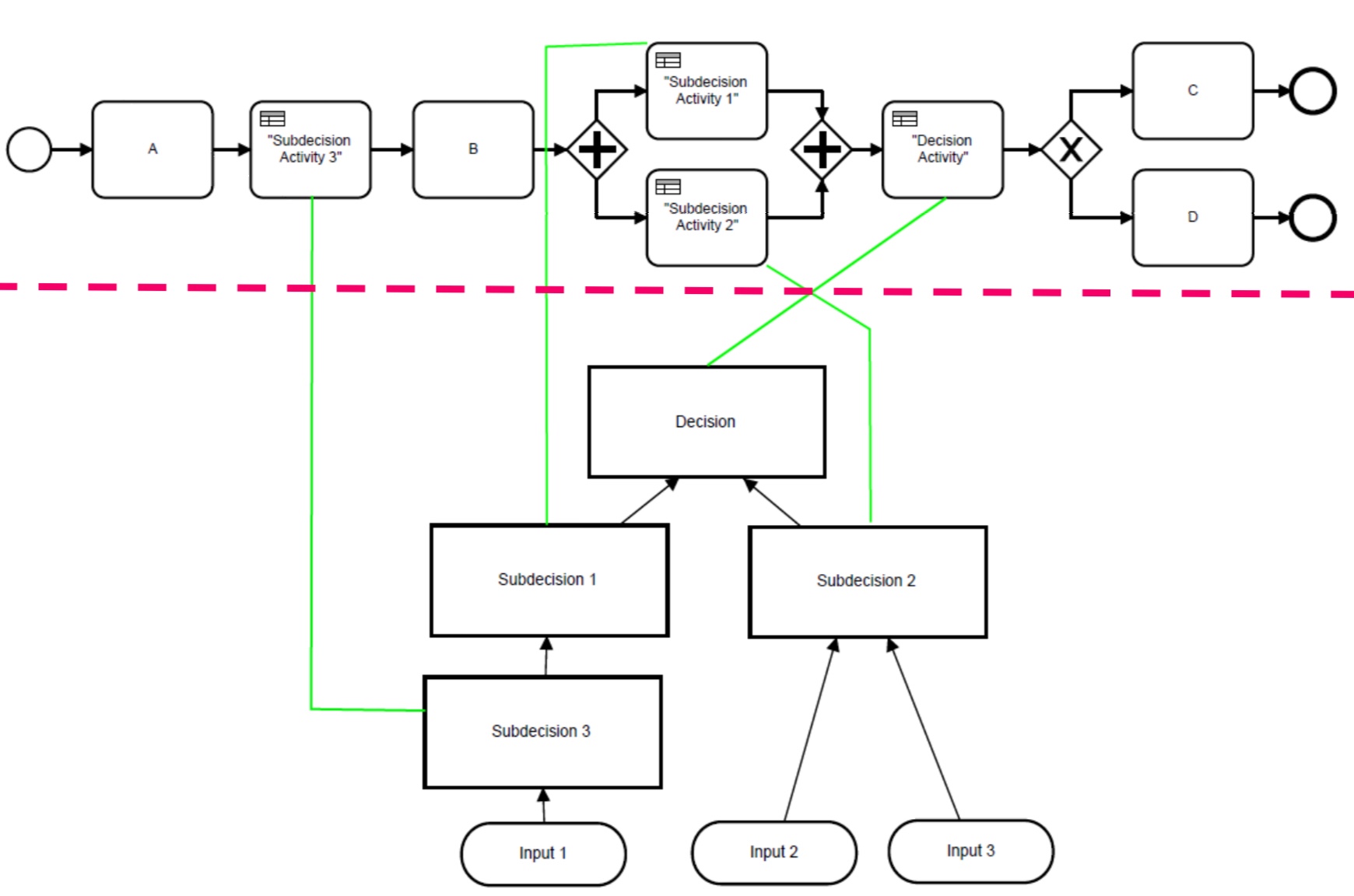
He covered some ideas on decision modeling methodology for creating the models of highest quality: usually this will involve working back and forth between the DRD and the decision tables, rather than trying to do a pure top-down or bottom-up approach. There’s a lot of past research that covers many of the issues of creating quality models, most of which predates BPMN and DMN but the same principles apply. The DMN and BPMN standards embody some of these principles, such as separating decision and process logic.