Flowable is holding their half-day online FlowFest today, and in spite of the eye-wateringly early start here in North America, I’ve tuned in to watch some of the sessions. All of these will be available on demand after the conference, so you can watch the sessions even if you miss them live.
There are three tracks — technical, architecture and business — and I started the day in the tech stream watching co-founder Tijs Rademakers‘ presentation on what’s new in Flowable. He spent quite a bit of the hour on a technical backgrounder, but did cover some of the new features: deprecation of Angular, new React Flow replacing the Oryx modelers, a new form editor, improved deployment options and cloud support, a managed service solution, and a quick-start migration path that includes an automatic migration of Camunda 7 process instance database to Flowable (for those companies that don’t want to make the jump to Camunda 8 and are concerned about the long-term future of V7).

For the second session, I switched over to the architect stream for Roman Saratz’ presentation on low-code integration with data objects. He showed some cool stuff where changes to the data in an external data object would update a case, in the example tied to a Microsoft Dynamics instance. The presentation was relatively short and there was an extended Q&A, obviously a lot of people interested in this form of integration. At the end, I checked in on the business track and realized that the sessions there were not time-aligned with the two technical tracks: they were already well into the Bosch session that was third on the agenda – not sure why the organizers thought that people couldn’t be interested in technology AND business.

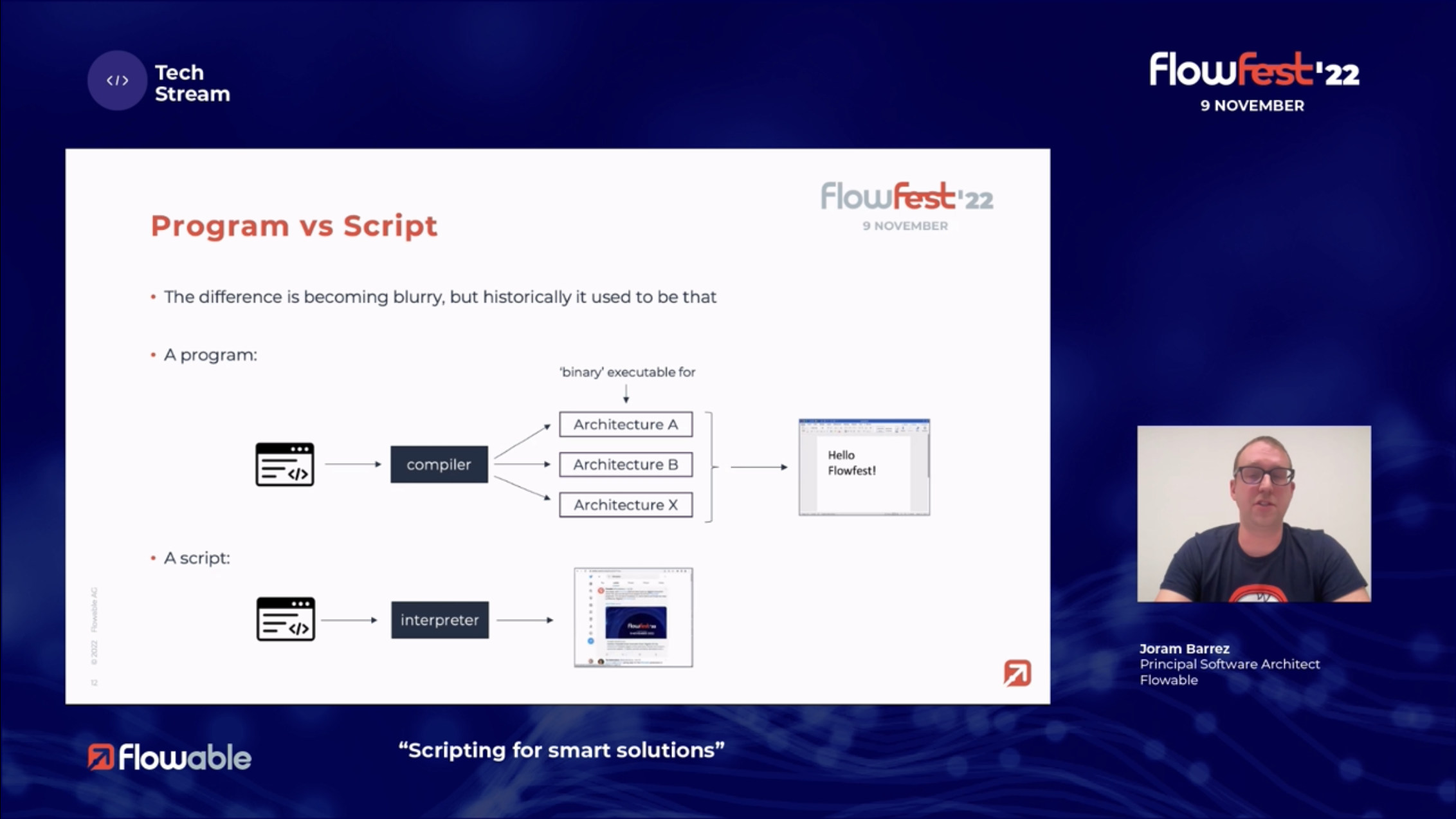
In the third session, I went back to the tech stream and attended Joram Barrez‘ presentation on scripting. Like a few of the other Flowable team, Joram came from Alfresco’s Activiti core development team (and jBPM before that), and is now Principal Software Architect. He looked at the historical difference between programs and scripts, which is that programs are compiled and scripts are interpreted, and the current place of pre-compiled [Java] delegates in service tasks versus script tasks that are interpreted at runtime. In short, the creation, compilation and deployment of Java delegates are definitely the responsibility of technical developers, while scripts can be created and maintained by less-technical low code developers. Flowable now allows for the creation a “service registry” task that is actually a Javascript or Groovy script rather than a REST call, which allows scripts to be reusable across models as if they were external service tasks rather than embedded within one specific process or case model. There are, of course, tradeoffs. Pre-compiled delegates typically have higher performance, and provide more of a structured development experience such as unit testing, and backwards-compatible API agreements. Scripts open up more development capability to the model developer who may not be Java-savvy. Flowable has created some API constructs that make scripts more capable and less brittle, including REST service request/response processing and BPMN error handling. It appears that they are shifting the threshold for what’s being done by a low code developer directly in their modeling environment, versus what requires a more technical Java developer, an external IDE and a more complex deployment path: making scripts first-class citizens in Flowable applications. In fat, Joram talked about ideas (not yet in the product) such as having a more robust scripting IDE embedded directly in their product. I am reminded of companies like Trisotech that are using FEEL as their scripting language in BPMN-CMMN-DMN applications, on the assumption that if you’re already using FEEL in DMN then using it throughout your application is a good idea; I asked if Flowable is considering this, and Joram said that it’s not currently supported but it would not be that difficult to add if there was demand for it.
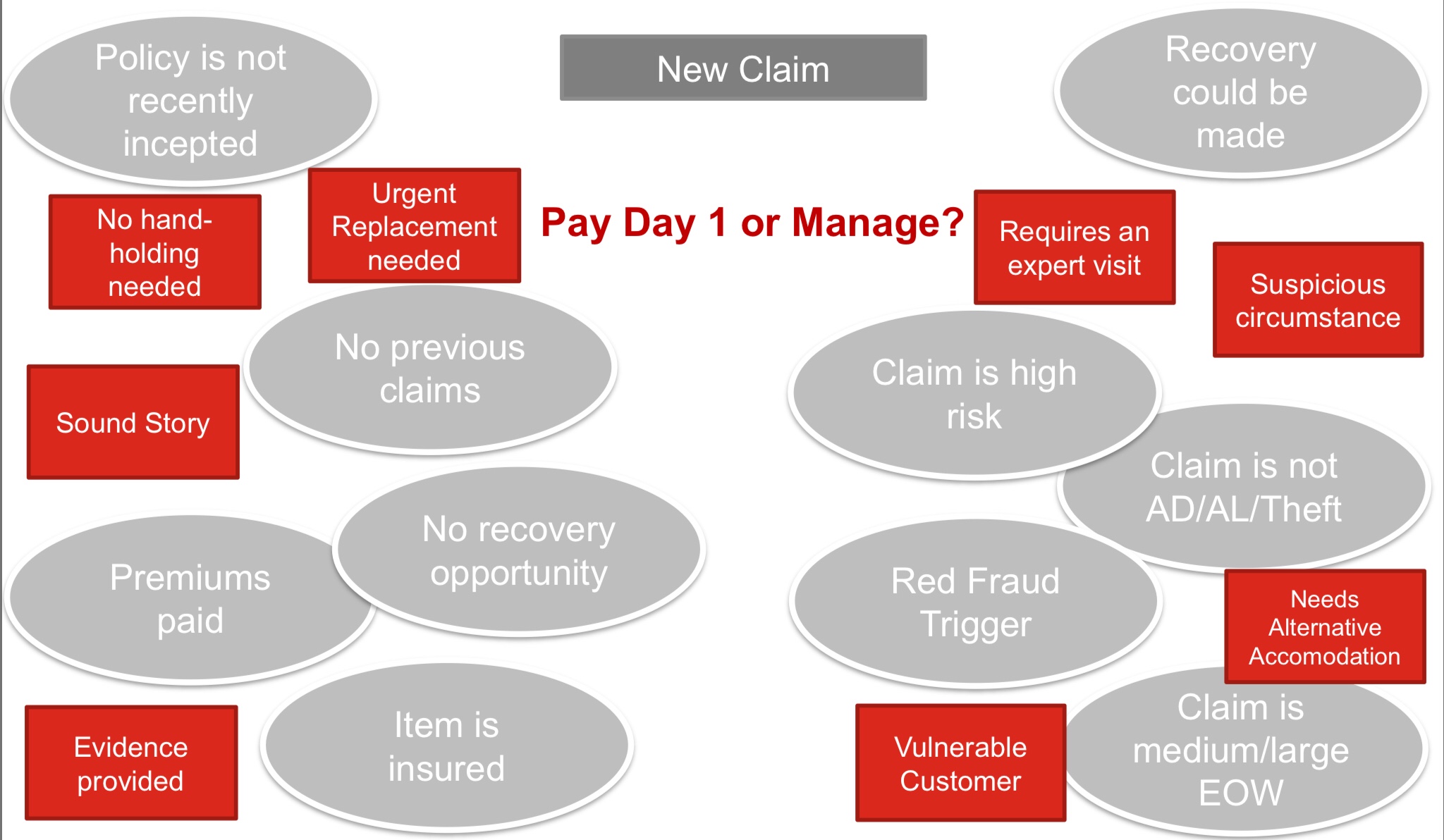
To wrap up the conference, I attend Paul Holmes-Higgin‘s architecture talk on Flowable future plans. Paul is co-founder of Flowable and Chief Product Officer. He started with a discussion of what they’re doing in Flowable Design, which is the modeling and design environment. Tijs spoke about some of this earlier, but Paul dug into more detail of what they’ve done in the completely rebuilt Design tool that will be released in early 2023. Both the technical underpinnings and the visuals have changed, to update to newer technology and to support a broader range of developer types from pro code to low code. He also spoke about longer term (2-3 year) innovation plans, starting with a statement of the reality that end-to-end processes don’t all happen within a centralized monolithic orchestrated system. Instead, they are made up of what he refers to as “process chains”, which is more of a choreography of different systems, services and organizations. He used a great example of a vehicle insurance claim that uses multiple technology platforms and crosses several organizational boundaries: Flowable Work may only handle a portion of those, with micro-engines on mobile devices and serverless cloud services for some capabilities. They’re working on Flowable Jet, a pared-down BPMN-CMMN-DMN micro-engine for edge automation that will run natively on mobile, desktop or cloud. This would change the previous insurance use case to put Flowable Jet on the mobile and cloud platforms to integrate directly with Flowable Work inside organizations. With the new desktop RPA capabilities in Windows 11, Flowable Jet could also integrate with that as a bridge to Flowable Work. This is pretty significant, since currently end-to-end automation has a lot of variability around the edges; allowing for their own tooling in the edge as well as central automation could provide better visibility and security throughout.

Tijs, Jorram and Paul are all open source advocates in spite of Flowable’s current more prominent commercial side; I’m hoping to see them shifting some of their online conversations over to the Fosstodon (or some other Mastodon instance), where I have started posting.
That’s it for FlowFest: a good set of informational sessions, and some that I missed due to multiple concurrent tracks that I’ll go back and watch later.

 Note that the last day of the conference, Wednesday July 1, is
Note that the last day of the conference, Wednesday July 1, is