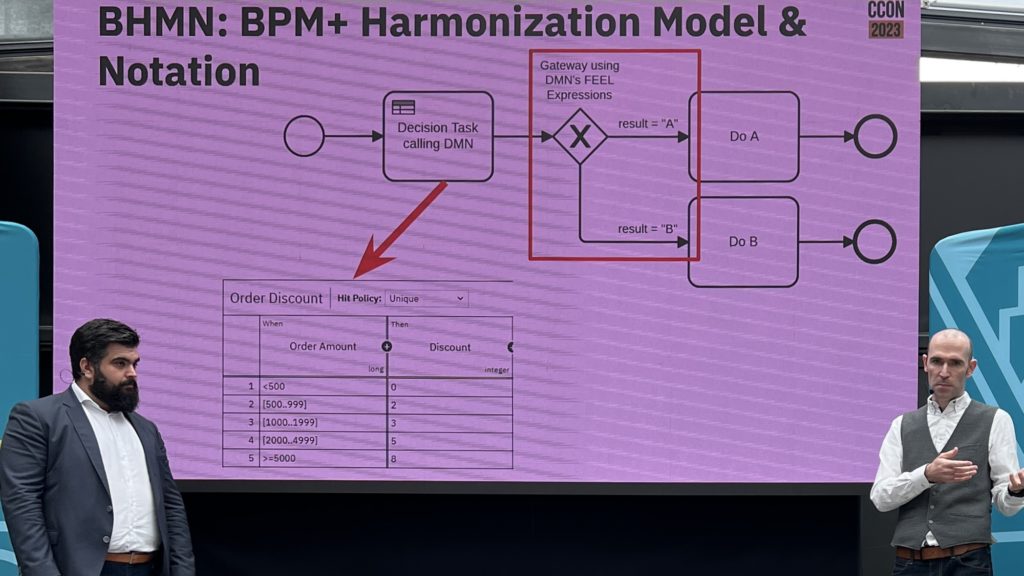
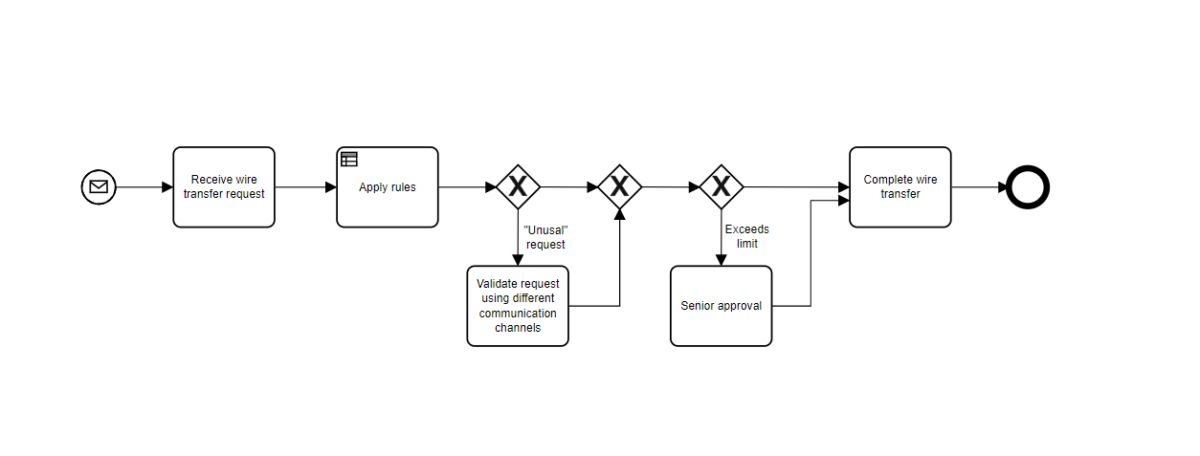
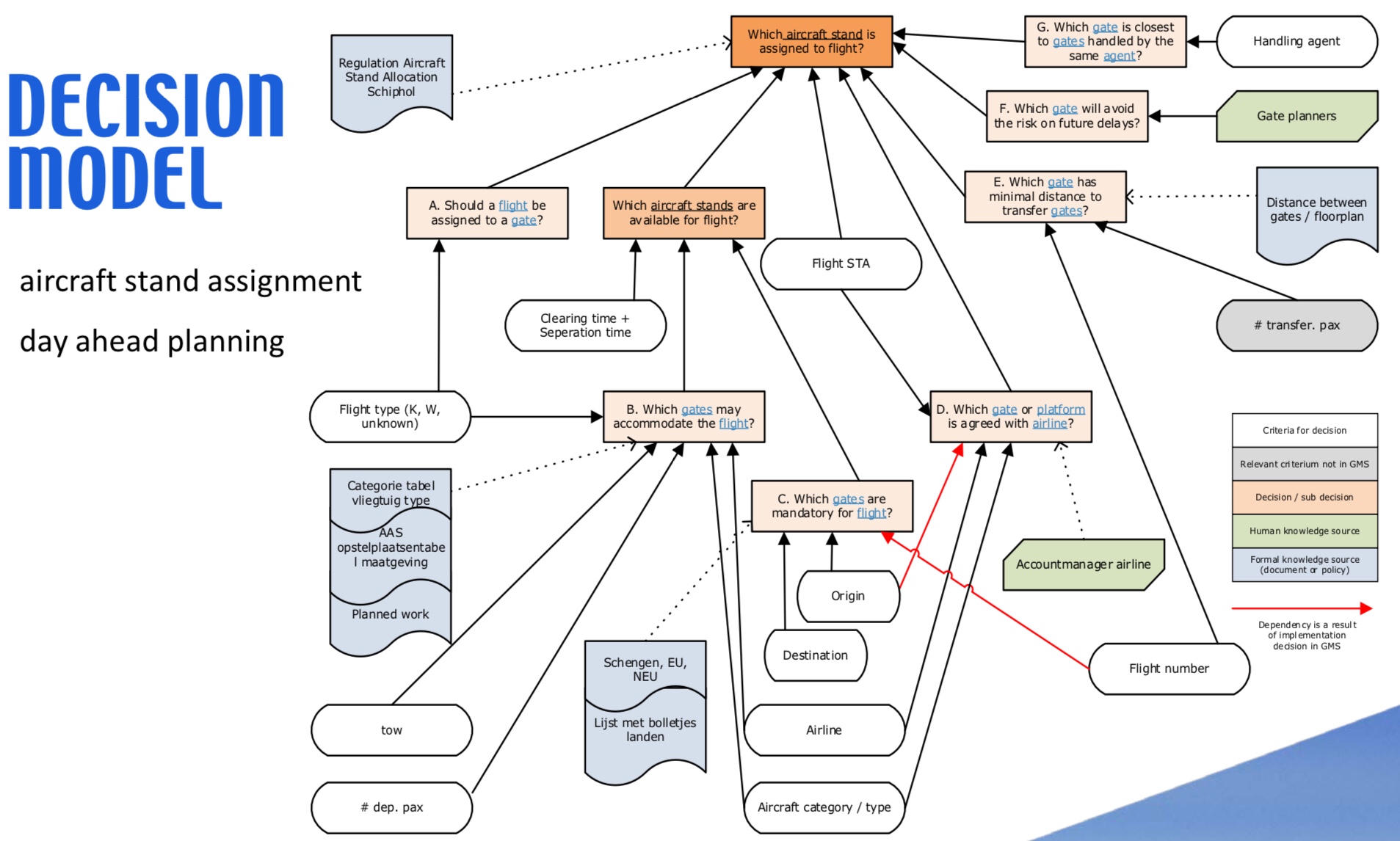
I attended an analyst briefing earlier today with Jakob Freund, CEO of Camunda, on the latest release of their product, Camunda BPM 7.5. This includes both the open source version available for free download, and the commercial version with the same code base plus a few additional features and professional support. Camunda won the “Best in Show” award at the recent bpmNEXT conference, where they demonstrated combining DMN with BPMN and CMMN; the addition of the DMN decision modeling standard to BPMN and CMMN modeling environments is starting to catch on, and Camunda has been at the front edge of the wave to push that beyond modeling into implementation.
They are managing to keep their semi-annual release schedule since they forked from Activiti in 2013: version 7.0 (September 2013) reworked the engine for scalability, redid the REST API and integrated their Cockpit administration module; 7.1 (March 2014) focused on completing the stack with performance improvements and more BPMN 2.0 support; 7.2 (November 2014) added CMMN execution support and a new tasklist; 7.3 (May 2015) added process instance modification, improved authorization models and tasklist plugins; and 7.4 (November 2015) debuted the free downloadable Camunda Modeler based on the bpmn.io web application, and added DMN modeling and execution. Pretty impressive progression of features for a small company with only 18 core developers, and they maintain their focus on providing developer-friendly BPM rather than a user-oriented low-code environment. They support their enterprise editions for 18 months; of their 85-90 enterprise customers, 25-30% are on 7.4 with most of the rest on 7.3. I suspect that a customer base of mostly developers means that customers are accustomed to the cycle of regression testing and upgrades, and far fewer lag behind on old versions than would be common with products aimed at a less technical market.
Today’s 7.5 release marches forward with improvements in CMMN and BPMN modeling, migration of process instances, performance and user interface.
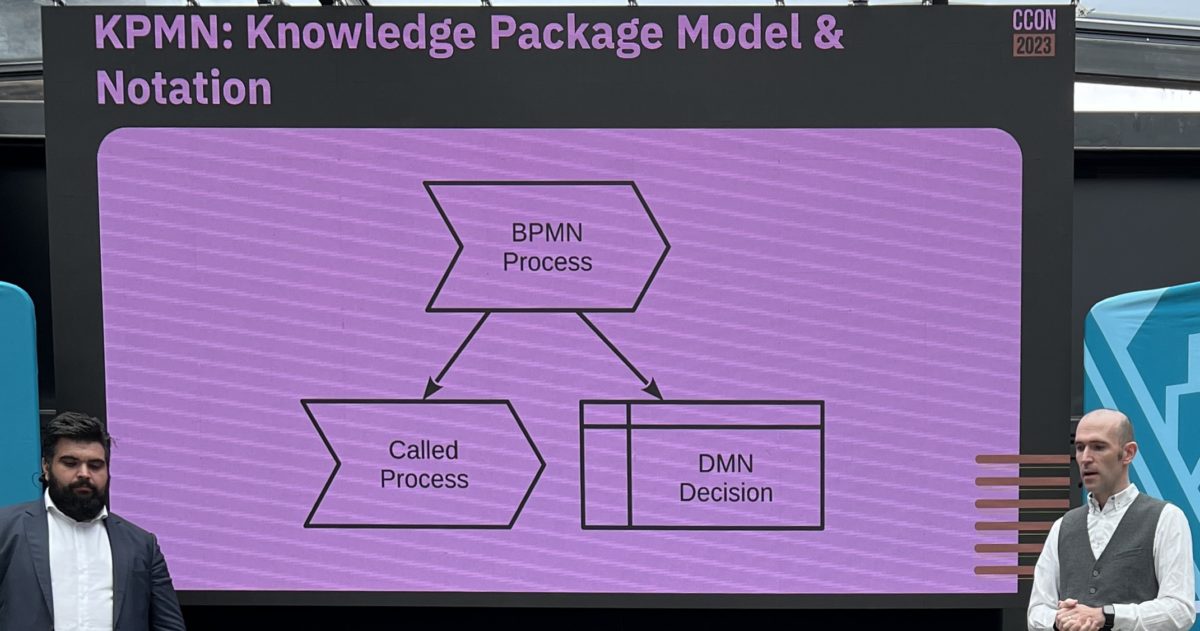
Oddly (to some), Camunda has included Case Management Model & Notation (CMMN) execution in their engine since version 7.2, but has only just added CMMN modeling in 7.5: previously, you would have used another CMMN-compliant modeler such as Trisotech’s then imported the model into Camunda. Of course, that’s how modeling standards are supposed to work, but a bit awkward. Their implementation of the CMMN modeler isn’t fully complete; they are still missing certain connector types and some of the properties required to link to the execution engine, so you might want to wait for the next version if you’re modeling executable CMMN. They’re seeing a pretty modest adoption rate for CMMN amongst their customers; the messaging from BPMS vendors in general is causing a lot of confusion, since some claim that CMMN isn’t necessary (“just use ad hoc tasks in BPMN”), others claim it’s required but have incomplete implementations, and some think that CMMN and BPMN should just be merged.
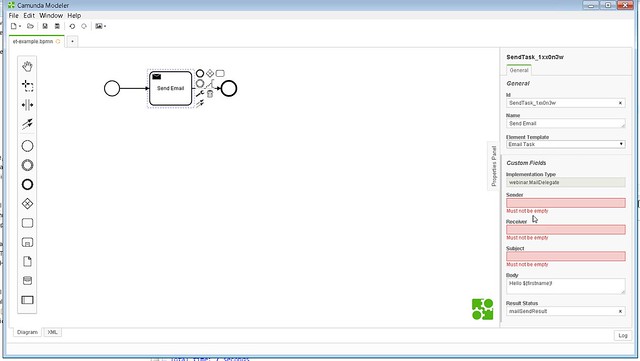
 On the BPMN modeling side, Camunda BPM 7.5 includes “element templates”, which are configurable BPMN elements to create additional functionality such as a “send email” activity. Although it looks like Camunda will only create a few of these as samples, this is really a framework for their customers who want to enable low-code development or encapsulate certain process-based functionality: a more technical developer creates a JSON file that acts as an extension to the modeler, plus a Java class to be invoked when it is executed; a less technical developer/analyst can then add an element of that type in the modeler and configure it using the properties without writing code. The examples I saw were for sending email and tweets from an activity; the JSON hooked the modeler so that if a standard BPMN Send Task was created, there was an option to make it an Email Task or Tweet Task, then specify the payload in the additional properties that appeared in the modeler (including passed variables). Although many vendors provide a similar functionality by offering things such as Send Email tasks directly in their modeling palettes, this appears to be a more standards-based approach that also allows developers to create their own extensions to standard activities. A telco customer is using Camunda BPM to create their own customized environments for in-house citizen developers, and element templates can significantly add to that functionality.
On the BPMN modeling side, Camunda BPM 7.5 includes “element templates”, which are configurable BPMN elements to create additional functionality such as a “send email” activity. Although it looks like Camunda will only create a few of these as samples, this is really a framework for their customers who want to enable low-code development or encapsulate certain process-based functionality: a more technical developer creates a JSON file that acts as an extension to the modeler, plus a Java class to be invoked when it is executed; a less technical developer/analyst can then add an element of that type in the modeler and configure it using the properties without writing code. The examples I saw were for sending email and tweets from an activity; the JSON hooked the modeler so that if a standard BPMN Send Task was created, there was an option to make it an Email Task or Tweet Task, then specify the payload in the additional properties that appeared in the modeler (including passed variables). Although many vendors provide a similar functionality by offering things such as Send Email tasks directly in their modeling palettes, this appears to be a more standards-based approach that also allows developers to create their own extensions to standard activities. A telco customer is using Camunda BPM to create their own customized environments for in-house citizen developers, and element templates can significantly add to that functionality.
 The process instance migration feature, which is a plugin to the enterprise Cockpit administration module but also available to open source customers via the underlying RESET and Java APIs, helps to solve the problem of what to do with long-running processes when the process model changes. A number of vendors have solutions for this, some semi-automated and some completely manual. Camunda’s take on it is to compare the existing process model (with live instances) against the new model, attempt to match current steps to new steps automatically, then allow any step to be manually remapped onto a different step in the new model. Once that migration plan is defined, all running instances can be migrated at once, or only a filtered (or hand-selected) subset. Assuming that the models are fairly similar, such as the addition or deletion of a few steps, this should work well; if there are a lot of topology changes, it might be more of a challenge since there could need to roll back instance property values if instances are migrated to an earlier step in the process.
The process instance migration feature, which is a plugin to the enterprise Cockpit administration module but also available to open source customers via the underlying RESET and Java APIs, helps to solve the problem of what to do with long-running processes when the process model changes. A number of vendors have solutions for this, some semi-automated and some completely manual. Camunda’s take on it is to compare the existing process model (with live instances) against the new model, attempt to match current steps to new steps automatically, then allow any step to be manually remapped onto a different step in the new model. Once that migration plan is defined, all running instances can be migrated at once, or only a filtered (or hand-selected) subset. Assuming that the models are fairly similar, such as the addition or deletion of a few steps, this should work well; if there are a lot of topology changes, it might be more of a challenge since there could need to roll back instance property values if instances are migrated to an earlier step in the process.
They have also improved multi-tenancy capabilities for customers who use Camunda BPM as a component within a SaaS platform, primarily by adding tenant identifier fields to their database tables. If those customers’ customers – the SaaS users – log in to Cockpit or a similar admin UI, they will only see their own instances and related objects, without the developers having to create a custom restricted view of the database.
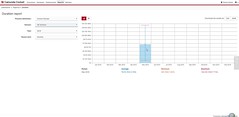 They’ve released a simple process instance duration report that provides a visual interface as well a downloadable data. There’s not a lot here, but I assume this means that they are starting to build out a more robust and accessible reporting platform to play catch-up with other vendors.
They’ve released a simple process instance duration report that provides a visual interface as well a downloadable data. There’s not a lot here, but I assume this means that they are starting to build out a more robust and accessible reporting platform to play catch-up with other vendors.
Lastly, I saw their implementation of external task handling, another improvement based on customer requests. You can see more of the technical details here and here: instead of a system task calling an 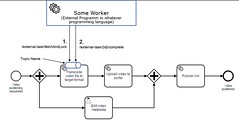 external task asynchronously then wait for a response, this creates a queue that an external service can poll for work. There are some advantages to this method of external task handling, including easier support for different environments: for example, it’s easier to call a Camunda REST API from a .NET client than to put a REST API on top of .NET; or to call a cloud-based Camunda server from behind a firewall than to let Camunda call through your firewall. It also provides isolation from any scaling issues of the external task handlers, and avoids service call timeouts.
external task asynchronously then wait for a response, this creates a queue that an external service can poll for work. There are some advantages to this method of external task handling, including easier support for different environments: for example, it’s easier to call a Camunda REST API from a .NET client than to put a REST API on top of .NET; or to call a cloud-based Camunda server from behind a firewall than to let Camunda call through your firewall. It also provides isolation from any scaling issues of the external task handlers, and avoids service call timeouts.
There’s a public webinar tomorrow (June 1) covering this release, you can register for the English one here (11am Eastern time) and the German one here (10am Central European time).