Wow, it’s been over two months since my last post. I took a long break over the end of the year since there wasn’t a lot going on that inspired me to write, and we were in conference hiatus. Now that (virtual) conferences are ramping up again for 2021, I wanted to share some of the best practices that I gathered from attending — and in one case, organizing — virtual conferences over 2020. Having sent this information by email to multiple people who were organizing their own conferences, I decided to just put it here where everyone could enjoy it. Obviously, these are all conferences about intelligent automation platforms, but the best practices are applicable to any technical conference, and likely to many non-technical conferences.
In summary, I saw three key things that make a virtual conference work well:
- Live presentations, not pre-recorded. This is essential for the amount of energy in the presentation, and makes the difference between a cohesive conference and a just a bunch of webinars. Screwups happen when you’re live, but they do at in-person conferences, too.
- Separate and persistent discussion platform, such as Slack (or Pega’s community in the case of their conference). Do NOT use the broadcast vendor’s chat/discussion platform, since a) it will disappear once your conference is over, and b) it probably sucks.
- Replays of the video posted as soon as possible, so that people who missed a live session can watch it and jump into the discussion later the same day while others are still talking about it. Extra points for also publishing the presentation slides at the same time.
A conference is not a one-way broadcast, it’s a big messy collaborative conversation
Let’s start with the list of the virtual conferences that I wrote about, with links to the posts:
- Camunda: https://column2.com/tag/camundacon/
- Alfresco: https://column2.com/2020/04/alfresco-modernize-2020/
- Celonis: https://column2.com/tag/celospherelive/
- IBM: https://column2.com/tag/think2020/
- Appian: https://column2.com/tag/appianworld/
- Signavio: https://column2.com/tag/signaviolive2020/
- Pega: https://column2.com/tag/pegaworld/
- Process Mining Camp (Fluxicon): https://column2.com/tag/pmcamp/
- OpenText: https://column2.com/tag/opentextworld/
- Bizagi: https://column2.com/tag/bizagicatalyst/ where I also gave a keynote and apparently broke the internet
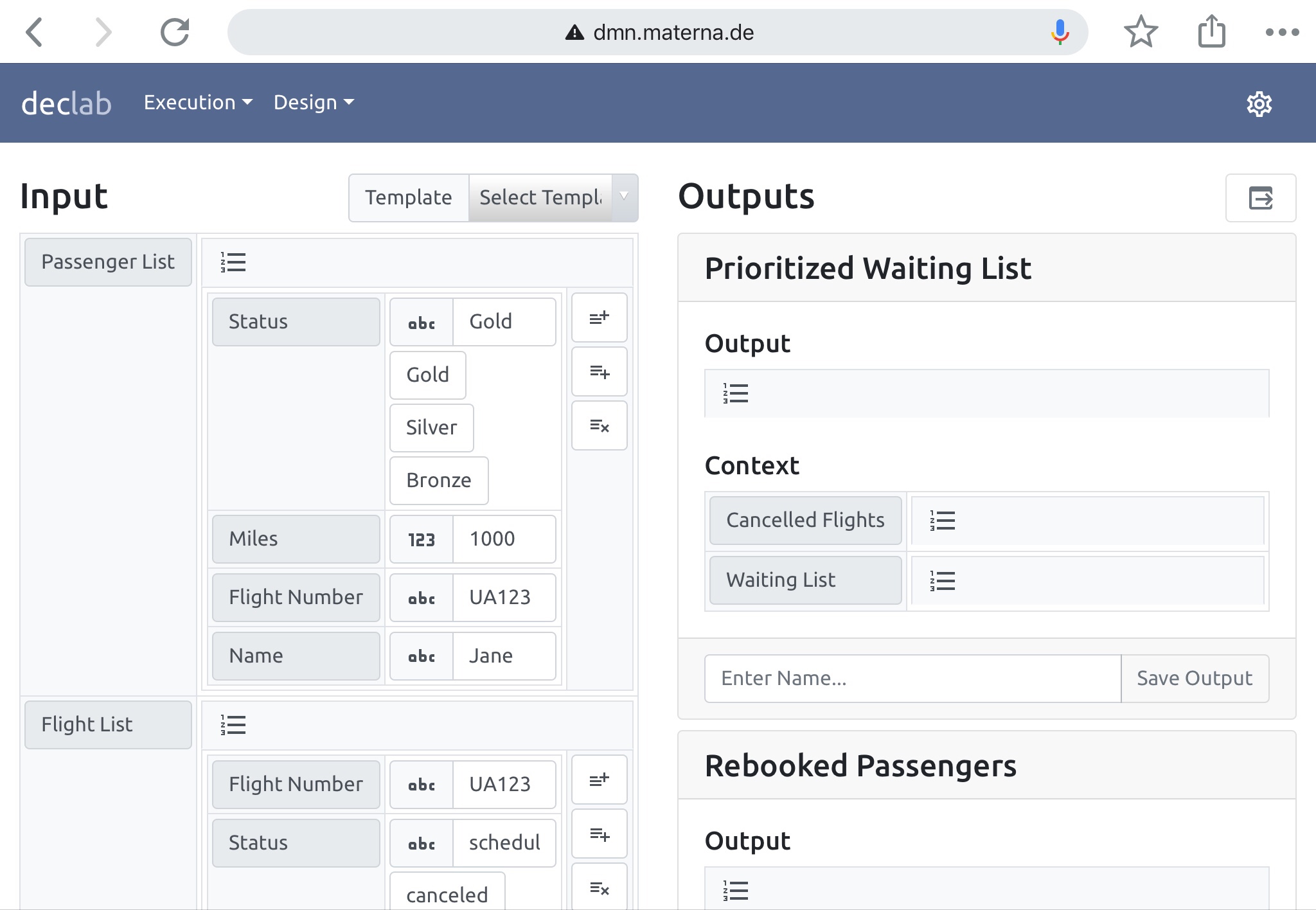
What I saw by attending these helped me when I was asked to organize DecisionCAMP, which ran in late June: we did the sessions using Zoom with livestreaming to YouTube (participants could watch either way), used Slack as a discussion platform (which is still being used for ongoing discussions and to run monthly events), and YouTube for the on-demand videos. Fluxicon used a similar setup for their Process Mining Camp: Skype (I think) instead of Zoom to capture the speakers’ sessions with all participants watching through the YouTube livestream and discussions on Slack.
Some particular notes excerpted from my posts on the vendor conferences follow. If you want to see the full blog posts, use the tag links above or just search.
Camunda
- “Every conference organizer has had to deal with either cancelling their event or moving it to some type of online version as most of us work from home during the COVID-19 pandemic. Some of these have been pretty lacklustre, using only pre-recorded sessions and no live chat/Q&A, but I had expectations for Camunda being able to do this in a more “live” manner that doesn’t completely replace an in-person event, but has a similar feel to it. They did not disappoint: although a few of the CamundaCon presentations were pre-recorded, most were done live, and speakers were available for live Q&A. They also hosted a Slack workspace for live chat, which is much better than the Q&A/chat features on the webinar broadcast platform: it’s fundamentally more feature-rich, and also allows the conversations to continue after a particular presentation completes.”
- “As you probably gather from my posts today, I’m finding the CamundaCon online format to be very engaging. This is due to most of the presentations being performed live (not pre-recorded as is seen with most of the online conferences these days) and the use of Slack as a persistent chat platform, actively monitored by all Camunda participants from the CEO on down.”
- “I mentioned on Twitter today that CamundaCon is now the gold standard for online conferences: all you other vendors who have conferences coming up, take note. I believe that the key contributors to this success are live (not pre-recorded) presentations, use of a discussion platform like Slack or Discord alongside the broadcast platform, full engagement of a large number of company participants in the discussion platform before/during/after presentations, and fast upload of the videos for on-demand watching. Keep in mind that a successful conference, whether in-person or online, allows people to have unscripted interactions: it’s not a one-way broadcast, it’s a big messy collaborative conversation.”
- Note that things did go wrong occasionally — one presentation was cut off part way through when the presenter’s home internet died. However, the energy level of the presentations was really high, making me want to keep watching. Also hilarious when one speaker talked about improving their “shittiest process” which is probably only something that would come out spontaneously during a live presentation.
Alfresco
- “Alfresco Modernize didn’t have much of a “live” feel to it: the sessions were all pre-recorded which, as I’ve mentioned in my coverage of other online conferences, just doesn’t have the same feel. Also, without a full attendee discussion capability, this was more like a broadcast of multiple webinars than an interactive event, with a short Q&A session at the end as the only point of interaction.”
Celonis
- “A few notes on the virtual conference format. Last week’s CamundaCon Live had sessions broadcast directly from each speaker’s home plus a multi-channel Slack workspace for discussion: casual and engaging. Celonis has made it more like an in-person conference by live-broadcasting the “main stage” from a studio with multiple camera angles; this actually worked quite well, and the moderator was able to inject live audience questions. Some of the sessions appeared to be pre-recorded, and there’s definitely not the same level of audience engagement without a proper discussion channel like Slack — at an in-person event, we would have informal discussions in the hallways between sessions that just can’t happen in this environment. Unfortunately, the only live chat is via their own conference app, which is mobile-only and has a single chat channel, plus a separate Q&A channel (via in-app Slido) for speakers that is separated by session and is really more of a webinar-style Q&A than a discussion. I abandoned the mobile app early and took to Twitter. I think the Celosphere model is probably what we’re going to see from larger companies in their online conferences, where they want to (attempt to) tightly control the discussion and demonstrate the sort of high-end production quality that you’d have at a large in-person conference. However, I think there’s an opportunity to combine that level of production quality with an open discussion platform like Slack to really improve the audience experience.”
- “Camunda and Celonis have both done a great job, but for very different reasons: Camunda had much better audience engagement and more of a “live” feel, while Celonis showed how to incorporate higher production quality and studio interviews to good effect.”
- “Good work by Celonis on a marathon event: this ran for several hours per day over three days, although the individual presentations were pre-recorded then followed by live Q&A. Lots of logistics and good production quality, but it could have had better audience engagement through a more interactive platform such as Slack.”
IBM
- “As I’ve mentioned over the past few weeks of virtual conferences, I don’t like pre-recorded sessions: they just don’t have the same feel as live presentations. To IBM’s credit, they used the fact that they were all pre-recorded to add captions in five or six different languages, making the sessions (which were all presented in English) more accessible to those who speak other languages or who have hearing impairments. The platform is pretty glitchy on mobile: I was trying to watch the video on my tablet while using my computer for blogging and looking up references, but there were a number of problems with changing streams that forced me to move back to desktop video for periods of time. The single-threaded chat stream was completely unusable, with 4,500 people simultaneously typing “Hi from Tulsa” or “you are amazing”.”
- “IBM had to pivot to a virtual format relatively quickly since they already had a huge in-person conference scheduled for this time, but they could have done better both for content and format given the resources that they have available to pour into this event. Everyone is learning from this experience of being forced to move events online, and the smaller companies are (not surprisingly) much more agile in adapting to this new normal.”
Appian
- “This was originally planned as an in-person conference, and Appian had to pivot on relatively short notice. They did a great job with the keynotes, including a few of the Appian speakers appearing (appropriately distanced) in their own auditorium. The breakout sessions didn’t really grab me: too many, all pre-recorded, and you’re basically an audience of one when you’re in any of them, with little or no interactivity. Better as a set of on-demand training/content videos rather than true breakout sessions, and I’m sure there’s a lot of good content here for Appian customers or prospects to dig deeper into product capabilities but these could be packaged as a permanent library of content rather than a “conference”. The key for virtual conferences seems to be keeping it a bit simpler, with more timely and live sessions from one or two tracks only.”
Signavio
- “Signavio has a low-key format of live presentations that started at 11am Sydney time with a presentation by Property Exchange Australia: I tuned in from my timezone at 9pm last night, stayed for the Deloitte Australia presentation, then took a break until the last part of the Coca-Cola European Partners presentation that started at 8am my time. In the meantime, there were continuous presentations from APAC and Europe, with the speakers all presenting live in their own regular business hours.”
- “The only thing missing is a proper discussion platform — I have mentioned this about several of the online conferences that I’ve attended, and liked what Camunda did with a Slack workspace that started before and continued after the conference — although you can ask questions via the GoToWebinar Question panel. To be fair, there is very little social media engagement (the Twitter hashtag for the conference is mostly me and Signavio people), so possibly the attendees wouldn’t get engaged in a full discussion platform either. Without audience engagement, a discussion platform can be a pretty lonely place. In summary, the GTW platform seems to behave well and is a streamlined experience if you don’t expect a lot of customer engagement, or you could use it with a separate discussion platform.”
Pega
- “In general, I didn’t find the prerecorded sessions to be very compelling. Conference organizers may think that prerecording sessions reduces risk, but it also reduces spontaneity and energy from the presenters, which is a lot of what makes live presentations work so well. The live Q&A interspersed with the keynotes was okay, and the live demos in the middle breakout section as well as the live Tech Talk were really good. PegaWorld also benefited from Pega’s own online community, which provided a more comprehensive discussion platform than the broadcast platform chat or Q&A.”
Fluxicon
- “The format is interesting, there is only one presentation each day, presented live using YouTube Live (no registration required), with some Q&A at the end. The next day starts with Process Mining Café, which is an extended Q&A with the previous day’s presenter based on the conversations in the related Slack workspace (which you do need to register to join), then a break before moving on to that day’s presentation. The presentations are available on YouTube almost as soon as they are finished.”
- “The really great part was engaging in the Slack discussion while the keynote was going on. A few people were asking questions (including me), and Mieke Jans posted a link to a post that she wrote on a procedure for cleansing event logs for multi-case processes – not the same as what van der Aalst was talking about, but a related topic. Anne Rozinat posted a link to more reading on these types of many-to-many situations in the context of their process mining product from their “Process Mining in Practice” online book. Not surprisingly, there was almost no discussion on the Twitter hashtag, since the attendees had a proper discussion platform; contrast this with some of the other conferences where attendees had to resort to Twitter to have a conversation about the content. After the keynote, van der Aalst even joined in the discussion and answered a few questions, plus added the link for the IEEE task force on process mining that promotes research, development, education and understanding of process mining: definitely of interest if you want to get plugged into more of the research in the field. As a special treat, Ferry Timp created visual notes for each day and posted them to the related Slack channel.”
Bizagi
- “The broadcast platform fell over completely…I’m not sure if Bizagi should be happy that they had so many attendees that they broke the platform, or furious with the platform vendor for offering something that they couldn’t deliver. The “all-singing, all-dancing” platforms look nice when you see the demo, but they may not be scalable enough.”
Final thoughts
Just to wrap things up, it’s fair to say that things aren’t going to go back to the way that they were any time soon. Part of this is due to organizations understanding that things can be done remotely just as effectively (or nearly so) as they can in person, if done right. Also, a lot of people are still reluctant to even think about travelling and spending days in poorly-ventilated rooms with a bunch of strangers from all over the world.
The vendors who ran really good virtual conferences 2020 are almost certain to continue to run at least some of their events virtually in the future, or find a way to have both in-person and remote attendees simultaneously. If you run a virtual conference that doesn’t get the attendee engagement that you expected, the problem may not be that “virtual conferences don’t work”: it could be that you just aren’t doing it right.

 Note that the last day of the conference, Wednesday July 1, is
Note that the last day of the conference, Wednesday July 1, is