It’s been a minute! Last time that I attended the BPM academic research conference was in the “before times”, back in 2019 in Vienna. This week, I’m in Utrecht for this year’s version, and it’s lovely here – beautiful historic buildings and stroopwafels in the conference bag!
I’m starting with the workshop on BPM and social software. This was the first workshop that I attended at my first trip to the BPM conference in 2008 in Milan, also chaired by Rainer Schmidt.
All three of these presentations looked at different aspects of how traditional structured process modeling and orchestration fails at addressing end-to-end process management, and how social (including social media) constructs can help. In the first presentation, processes are too unstructured for (easy) automation; in the second, there’s a need for better ways to provide feedback from process participants to the design; and in the third, organizations can’t even figure out how to get started with BPM.
The first in the workshop was Joklan Imelda Camelia Goni, who was accompanied by her supervisor Amy van Looy, on “Towards a Measurement Instrument for Assessing Capabilities when Innovating Less-Structured Business Processes”. Some of the background research for this work was a Delphi study that I participated in during 2021-2022, so it was interesting to see how her research is advancing. There is a focus on capabilities within organizations: how capable are certain people or departments at determining the need for innovation and creating the innovation in (often manual) processes.
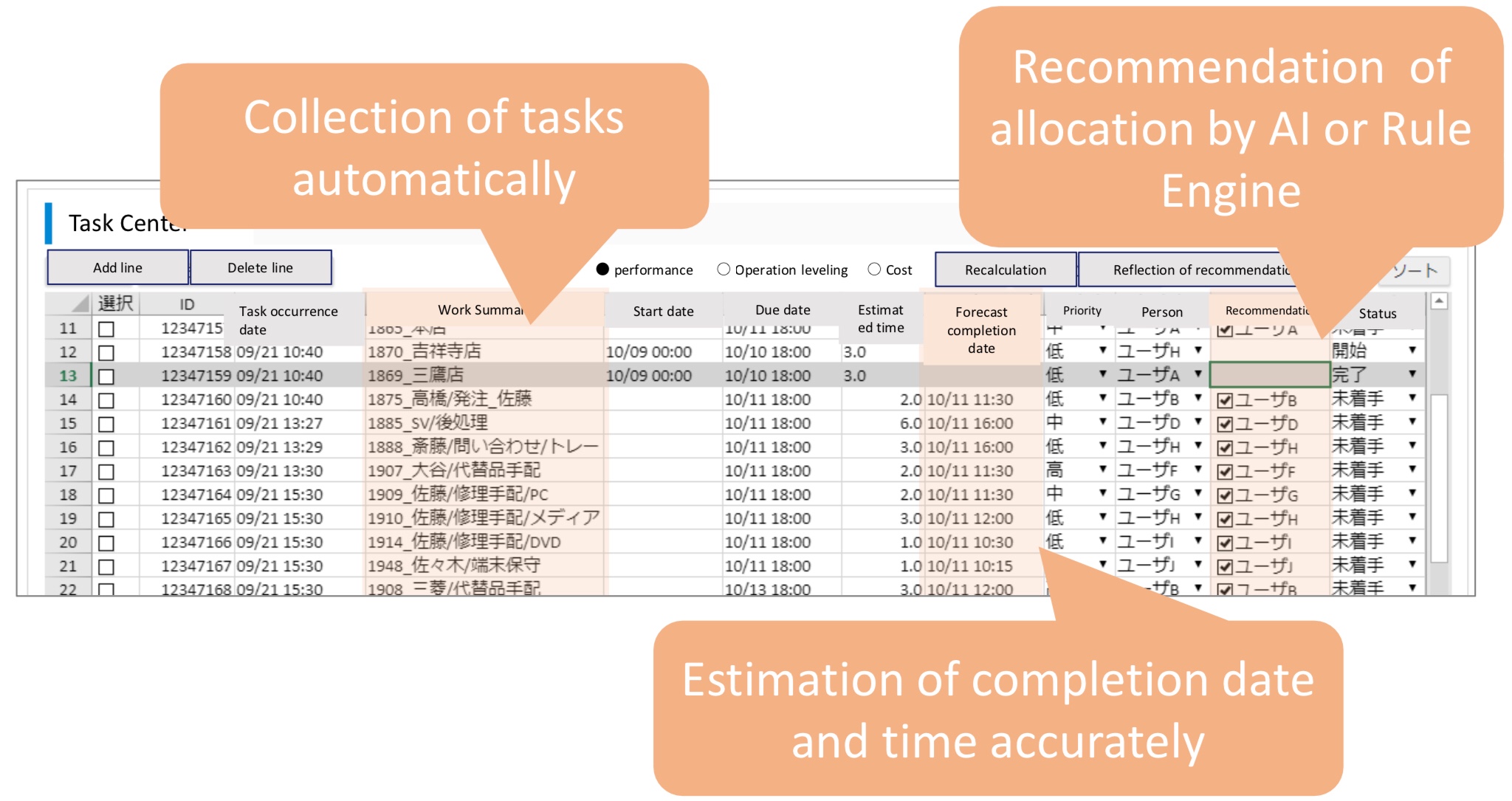
Next was Mehran Majidian Eidgahi on “Integrating Social Media and Business Process Management: Exploring the Role of AI Agents and the Benefits for Agility” (other paper contributors are Anne-Marie Barthe-Delanoë, Dominik Bork, Sina Namaki Araghi, Guillaume Mace-Ramete and Frédérick Bénaben). This looks at the problem of structured business process models that have been orchestrated/automated, but that need some degree of agility for process changes. He characterizes BPM agility at three stages: discovering, deciding and implementing, and sees that much of the work has focused on discovery (process mining) and implementing, but not as much on deciding (that is, analysis or design). Socializing BPM with the participants can bring their ideas and feedback into the process design, and they propose a social BPM platform for providing reactions, feedback and suggestions on processes. I’ve seen structures similar to this in some commercial BPM products, but one of the main issues is that the actual executing model is not how the participants envision it: it may be much more event-driven rather than a more traditional flow model. He presented some of their other research on bringing AI to the platform and framework, which provides a good overview of the different areas in which AI may be applied.
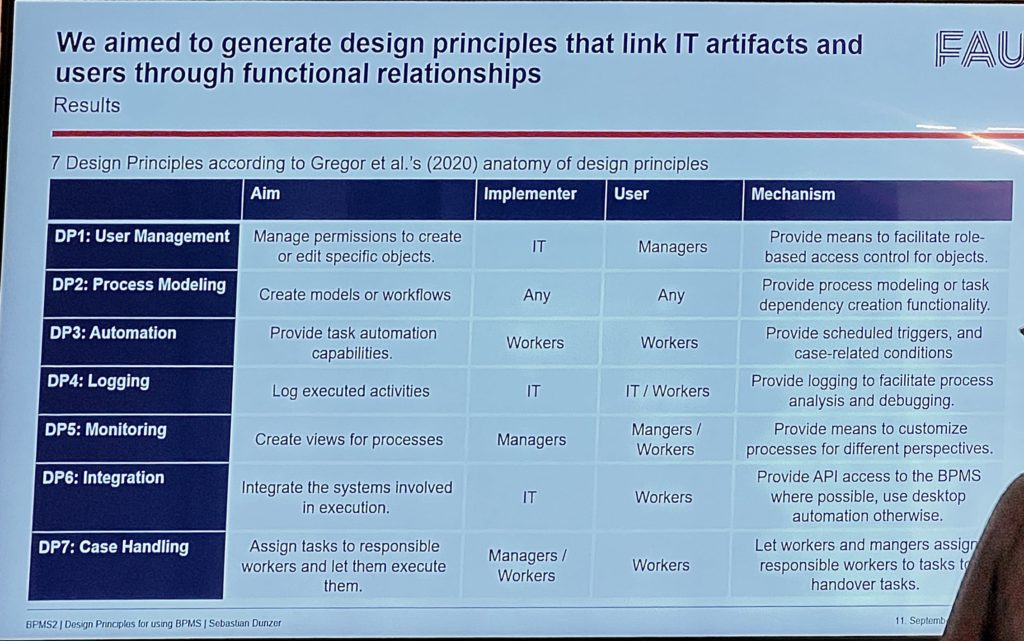
The last presentation in the workshop was by Sebastian Dunzer on “Design Principles for Using Business Process Management Systems” (other paper contributors Willi Tang, Nico Höchstädter, Sandra Zilker and Martin Matzner). He looks at the “pre-BPM” problem of how to have organizations understand how they could use BPM to improve their operations: in his words, “practice knows of BPM, but it remains unclear how to get started”. This resonates with me, since much of my consulting over the years has included some aspect of explaining that link between operational business problems and the available technologies. They did an issue-tracking project with a medium-sized company that allowed them to use practical applications and simultaneously provide research insights. Their research outcome was to generate design principles that link IT artifacts and users through functional relationships.
Many thanks to the conference chair, Hajo Reijers, for extending an invitation to me for the conference. I’ll be at more workshops later today, and the rest of the conference throughout the week.