It’s now really the last day of BPM2023 in Utrecht, and we’re off at the Utrecht Science Park campus for the Industry Day. The goal of industry day is to have researchers and practitioners come together to discuss issues of overlap and integration. Jan vom Brocke gave the keynote “Generating Business Value with Business Process Management (BPM) – How to Engage with Universities to Continuously Develop BPM Capabilities”. I don’t think that I’ve seen Jan since we were both presenting at a series of seminars in Brazil ten years ago. His keynote was about how everything is a process (bad or good), but we need to consider how to leverage the opportunity to understand and improve processes with process management. This doesn’t mean that we want to draw a process model for everything and force it into a standardized way of running, but need to understand all types of processes and modes of operation. His work at ERCIS is encouraging the convergence of research and practice, which means (in part) bringing together the researchers and the practitioners in forums like today’s industry day, but also in more long-running initiatives.
He discussed the “BPM billboard” which shows how BPM can deliver significant value to organizations through real-world experience, academic discourse and in-depth case studies. Many businesses — particularly business executives — aren’t interested in process models or technical details of process improvement methodologies, but rather in strategy in their own business context: how can BPM be brought to bear on solving their strategic problems. This requires the identification or development process-centric capabilities within the organization, including alignment, governance, methods, technology, people and culture. Then the issues can lead to actionable projects, and the results of those projects.
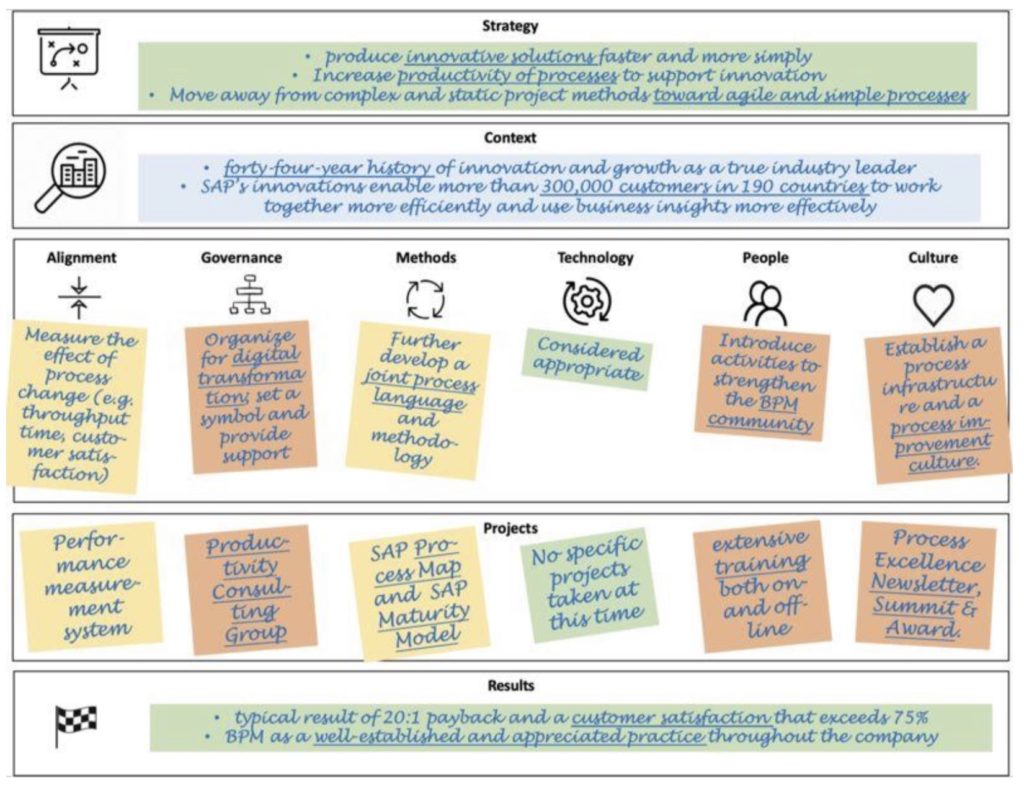
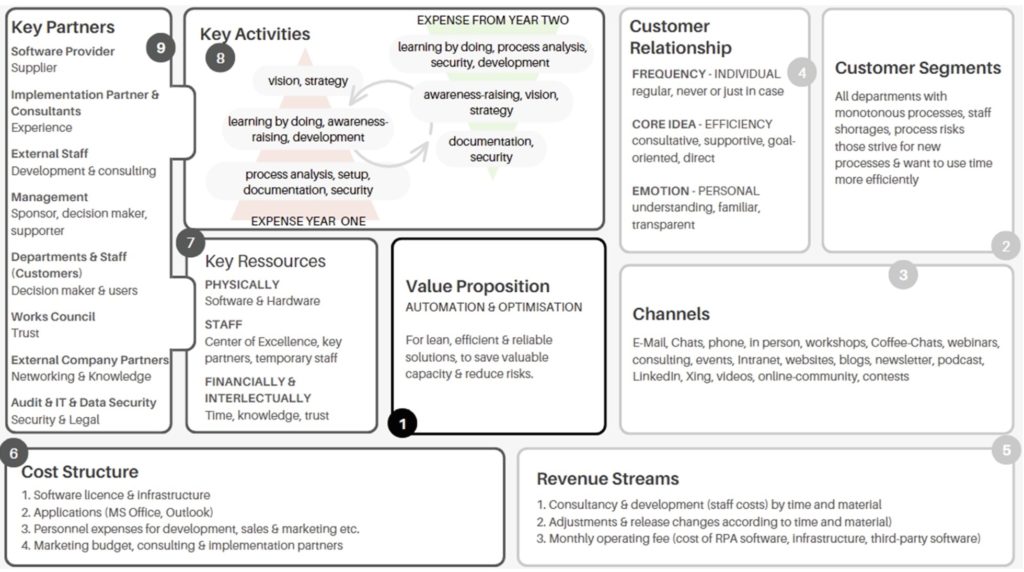
He moved on to talk about the BPM context matrix, with a focus on how to make people love the BPM initiative. This requires recognizing the diversity in processes and also diversity in methods and intentions that should be applied to processes. He showed a chart of two process dimensions — frequency and variability — creating four distinct clusters of process types. This was then mapped using the BPM billboard to map onto specific approaches for each cluster. Developing more appropriate approaches in the specific business context then allows the organizations involved to understand how BPM can bring value, and fully buy in to the initiates.
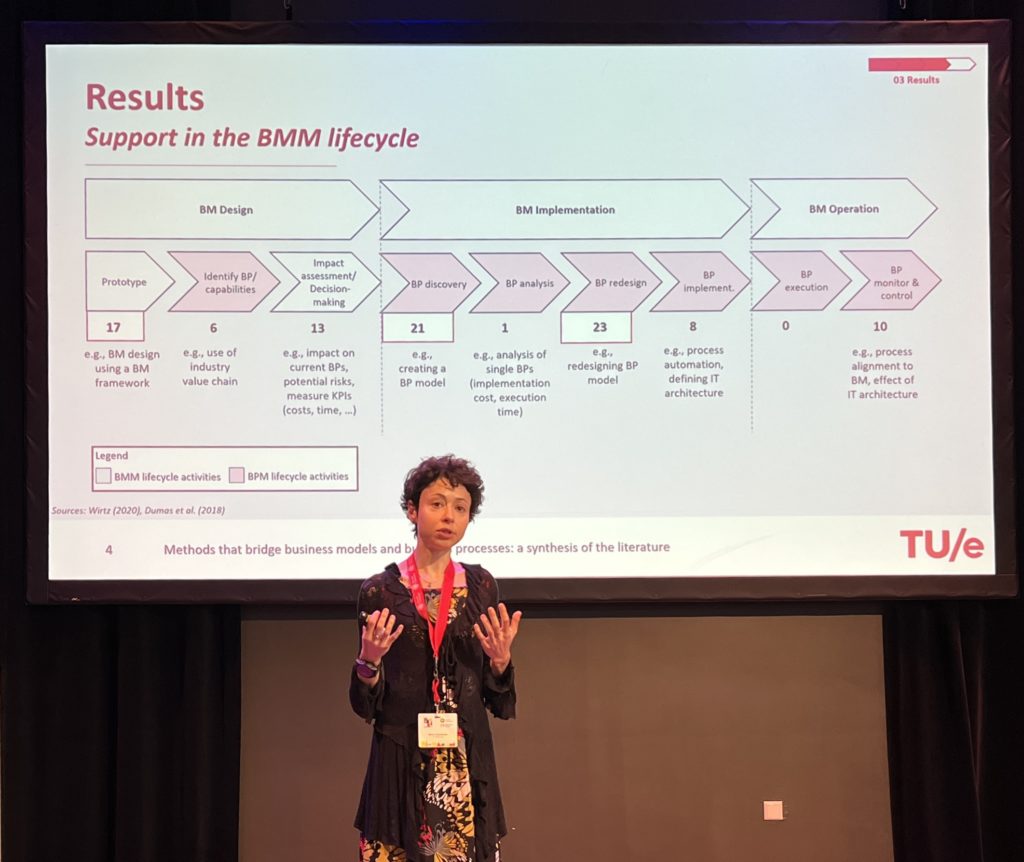
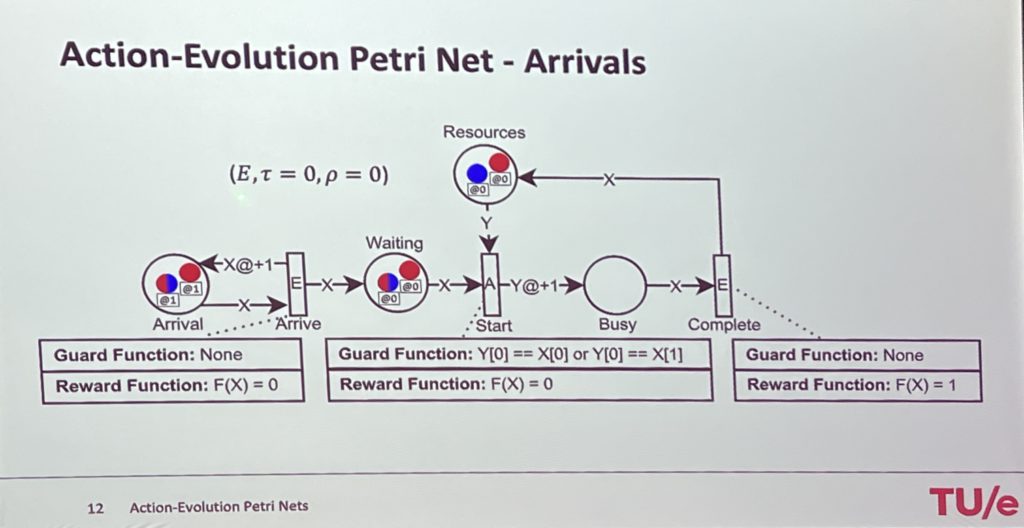
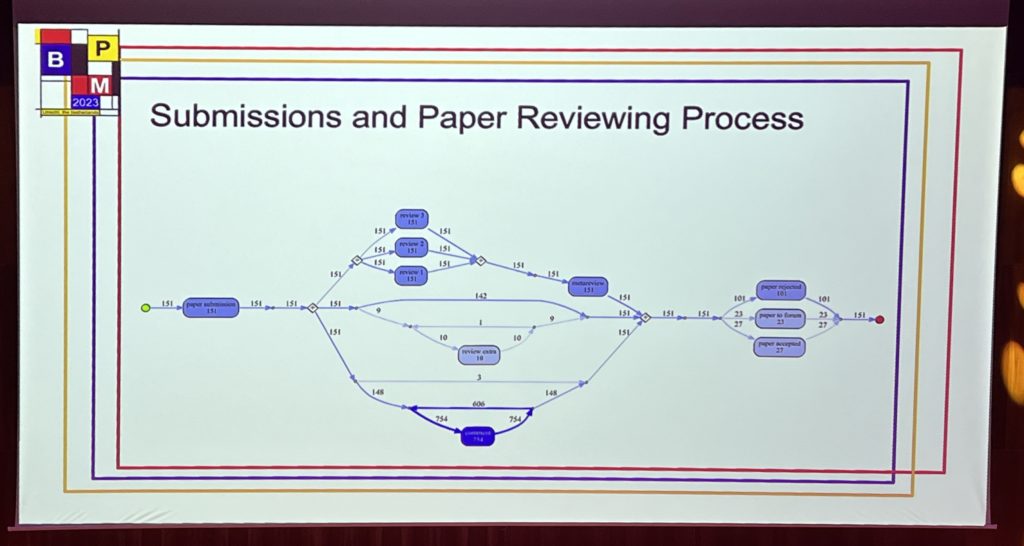
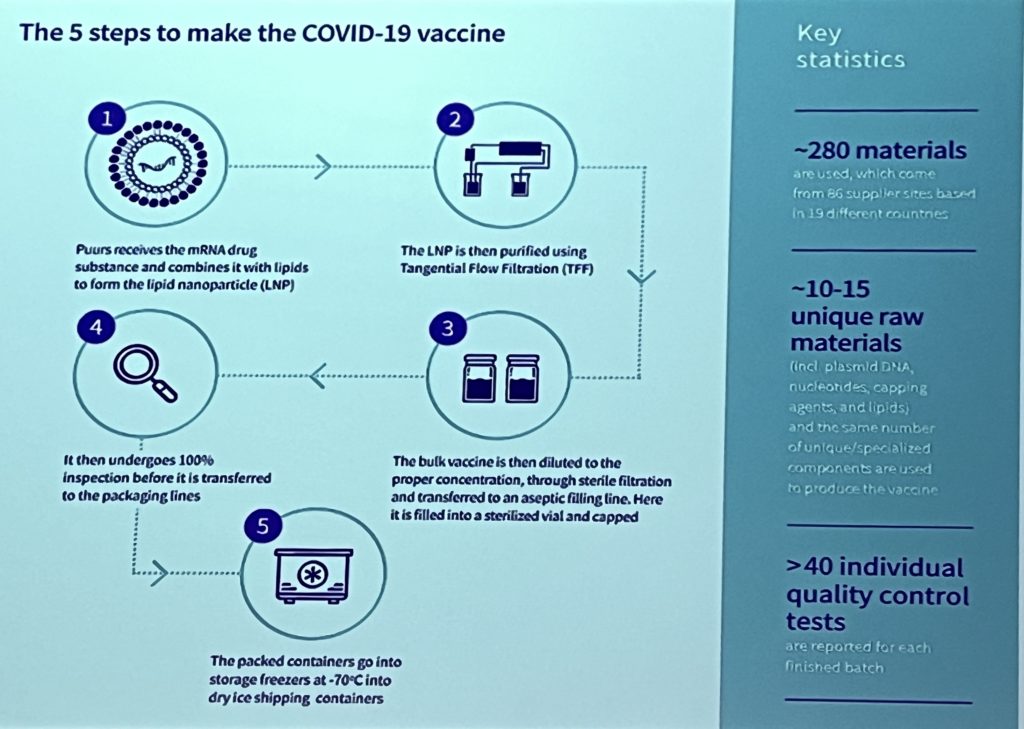
His third topic was on establishing the value of process mining, or how to turn data into value. Many companies are interested in process mining, and may have started to work on some projects in their innovation areas, it’s a challenge for many of them to actually demonstrate the value. Process mining research tends to focus on the technical aspects, but there needs to be expansion of the other aspects: how it impacts individuals, groups and high level value chains.
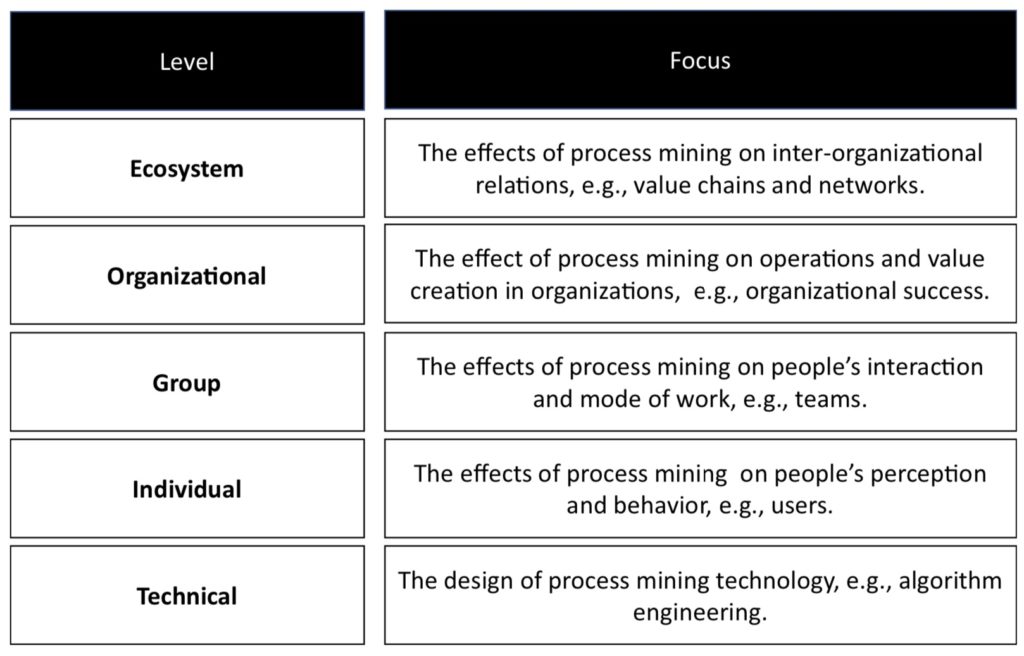
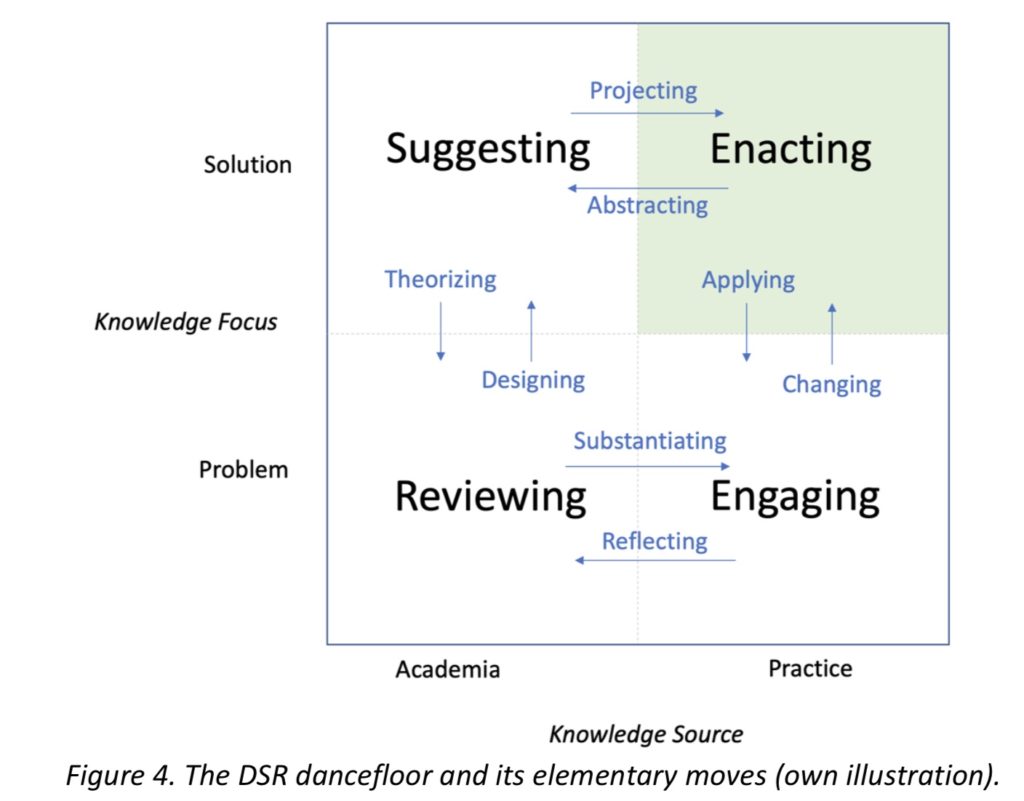
His conclusion, which I completely agree with, is that we need to have both research and practice involved in order to move BPM forward. Practice informs research, and research supports practice: a dance that involves both equally.
Following the keynote, I was on a panel with Jan in addition to Jasper van Hattem from Apolix and Jason Dietz of Tesco. Lots of good conversation about BPM in practice, some of the challenges, and how research can better support practice.
The rest of the day was dedicated to breakouts to work on industry challenges. Representatives from four different organizations (Air France KLM Martinair Cargo, Tesco, GEMMA, and Dutch Railways) presented their existing challenges in process management, then the attendees joined into groups to brainstorm solutions and directions before a closing session to present the findings.
I didn’t stick around for the breakouts, it’s been a long week and my brain was full. Instead, I visited Rietveld Schröderhuis with its amazing architectural design and had a lovely long walk through Utrecht.

I did have a few people ask me throughout the week how many of these conferences that I’ve been to (probably because they were too polite to ask WHY I’m here), and I just did a count of seven: 2008 in Milan, 2009 in Ulm, 2010 in Hoboken, 2011 in Clermont-Ferrand (where I gave a keynote in the industry track), 2012 in Tallinn, then a long break until 2019 in Vienna, then this year in Utrecht.