

It’s the last day of the main BPM2023 conference in Utrecht; tomorrow is the Industry Day where I will be speaking on a panel (although I would really like to talk to next year’s organizers about having a concurrent industry track rather than a separate day after many of the researchers and academics have departed). This morning, I attended the keynote by Matthias Weidlich of Humboldt-Universität zu Berlin on database systems and BPM.
He covered some of the history of database systems and process software, then the last 20 years of iBPMS where workflow software was expanded to include many other integrated technologies. At some point, some researchers and industry practitioners started to realize that data and process are really two sides of the same coin: you can’t do process analytics or mining without a deep understanding of the data, for example, nor can you execute decisions without processes without data. Processes have both metadata (e.g., state) and business data (process instance payload), and also link to other sources of data during execution. This data is particularly important as processes become more complex, where there may be multiple interacting processes within a single transaction.

He highlighted some of the opportunities for a tighter integration of process and data during execution, including the potential to use a database for event-based processing rather than the equivalent functionality within a process management system. One interesting development is the creation of query languages specifically for processes, both for mining and execution. Examining how existing query models can be used may allow some of the query work to be pushed down to a database system that is optimized for that functionality.
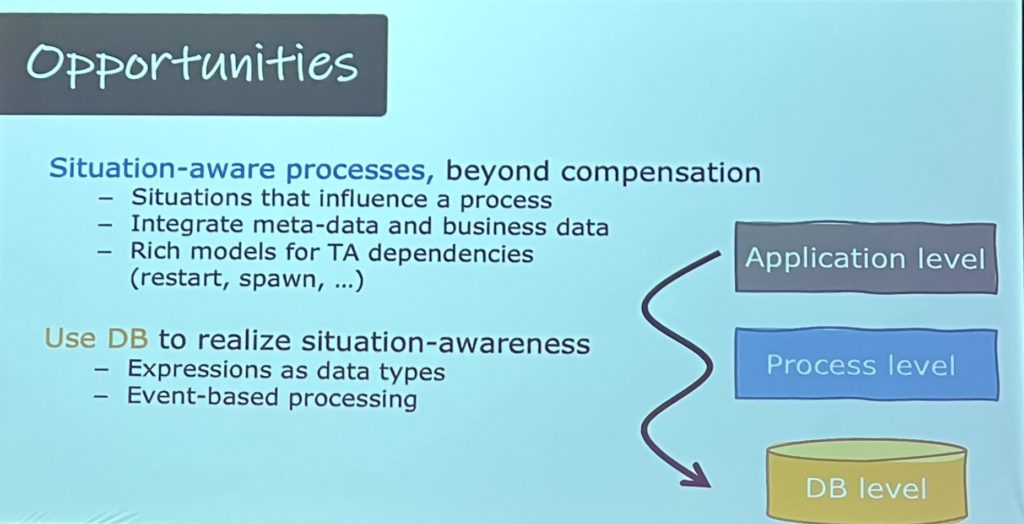
He finished by stating that data is everywhere in process management, and we should embrace database technology in process analysis and implementation. I’m of two minds about this: we don’t want to be spending a lot of time making one type of system perform an activity that is easier/better done in a different type, but we also don’t want to go down the rathole of just building our own process management system in a database engine. And yes, I’ve seen this done in practice, and it is always a terrible mistake. However, using a database to recognize and trigger events that are then managed in a process management system, or using a standardized query engine for process queries fall into the sweet spot of using both types of systems for what they do best in an integrated fashion.
Lots to think about, and good opportunities to see how database and process researchers and practitioners can work together towards “best of both worlds” solutions.