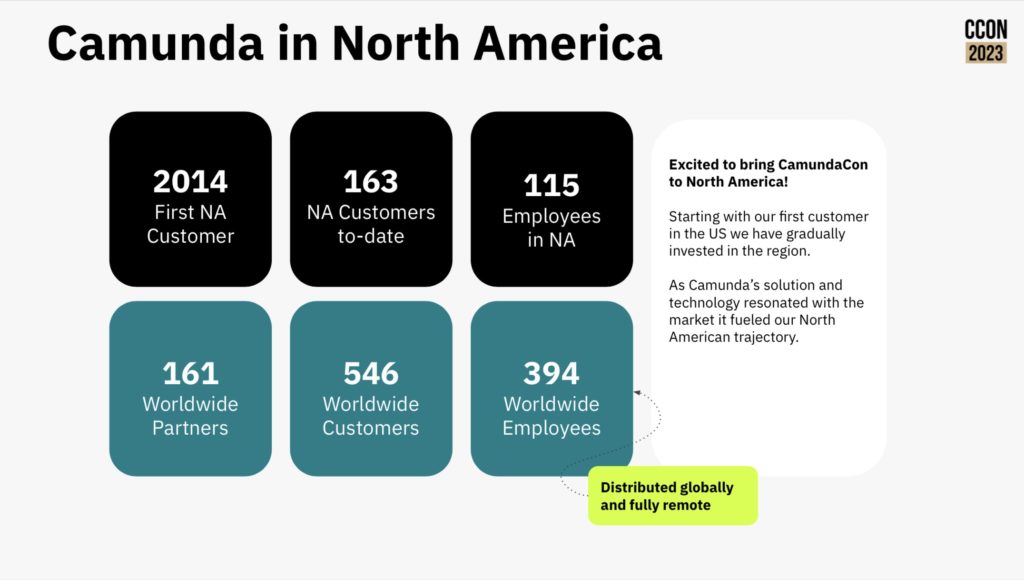
This morning I travelled all the way north…to Yonge and Bloor (that’s a Toronto joke, since downtowners consider anything north of Bloor to be a suburban wasteland) for the Camunda Local in Toronto. I haven’t been to a lot of events lately, but when one pops up here at home, I take the opportunity to see some familiar faces and get an update on companies and products.
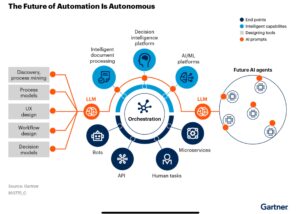
Frederic Meier, Senior VP of Sales, gave the opening keynote on Camunda’s views of industry trends and how they are responding to those to help organizations drive business transformation. He made it all the way to slide 2 before he mentioned AI (lol), and shared some stats that 83% of executive leaders are driving AI strategy within their company but most of them — 85-90% — are struggling to operationalize it and really make it work. A proper process architecture can help with this by providing a platform for transforming processes as a prelude to or in conjunction with implementing AI. In my experience, a lot of initial AI applications can be thought of as occurring at a specific activity within an orchestrated process, not standalone applications. RPA (robotic process automation) has been in this space for several years now, and many of the RPA vendors have shifted to more of an AI message, but they’re still fundamentally point solutions rather than end-to-end business processes.
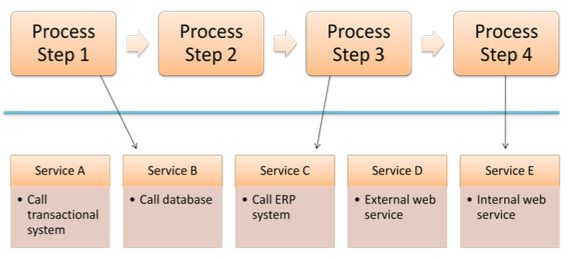
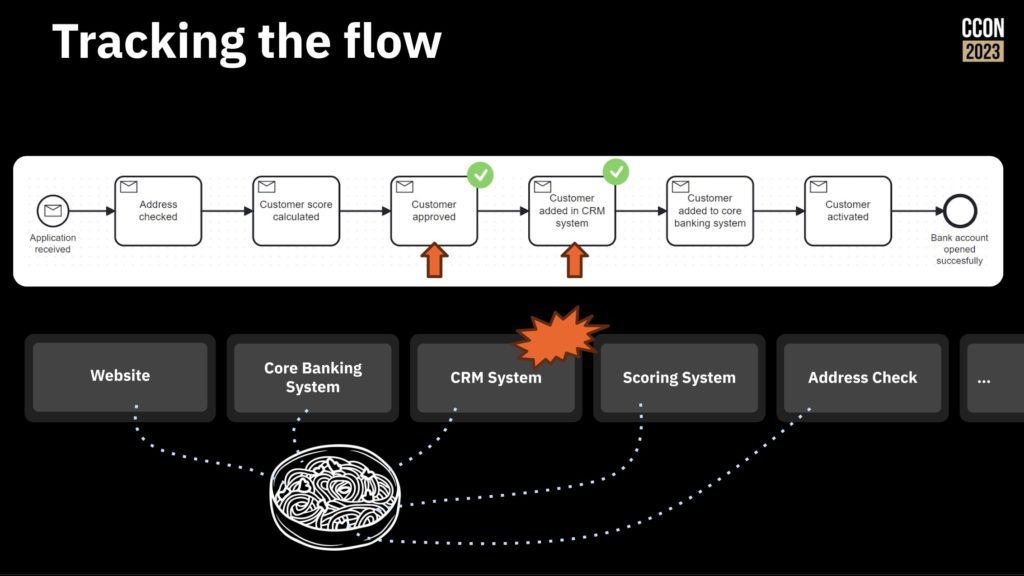
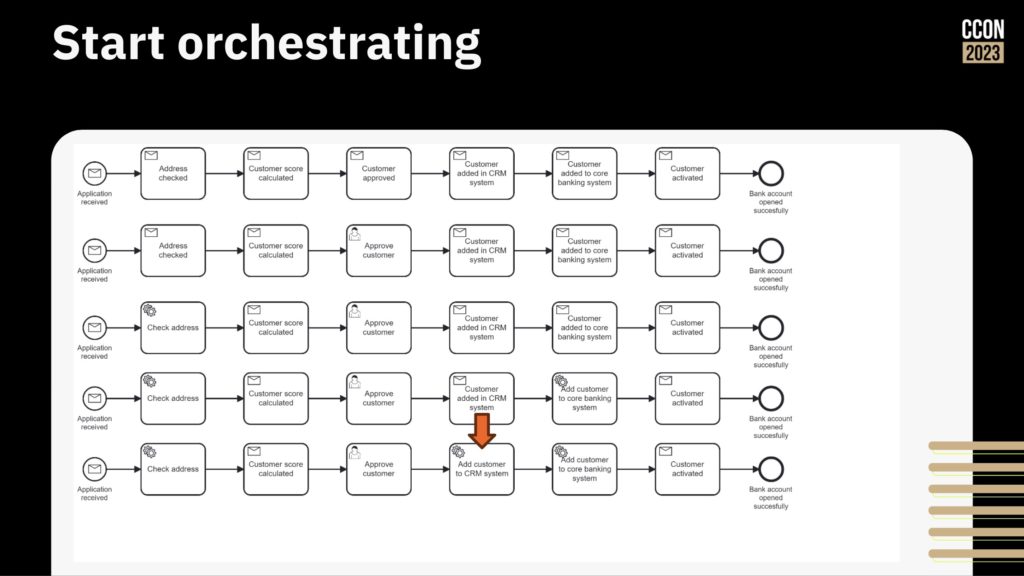
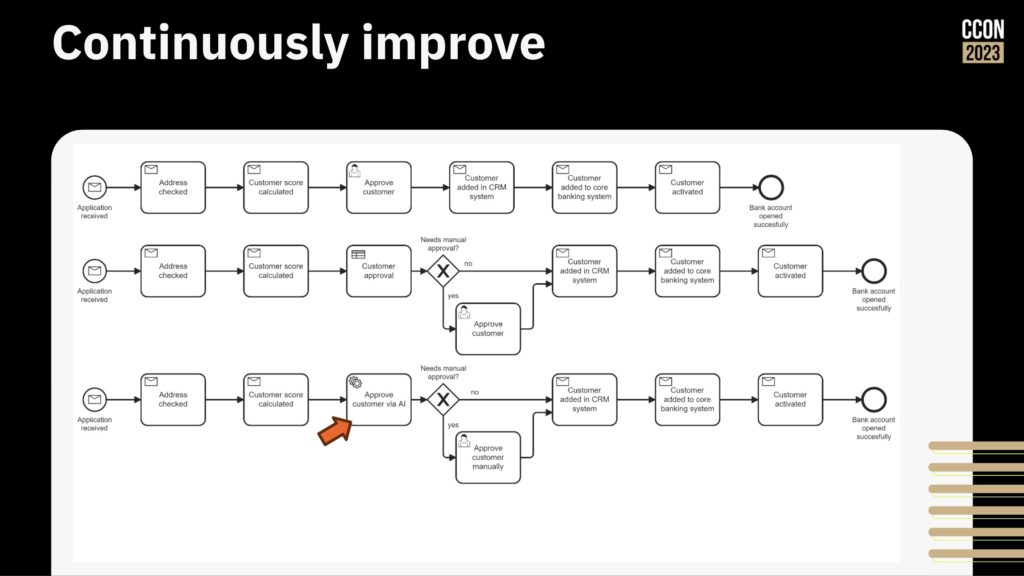
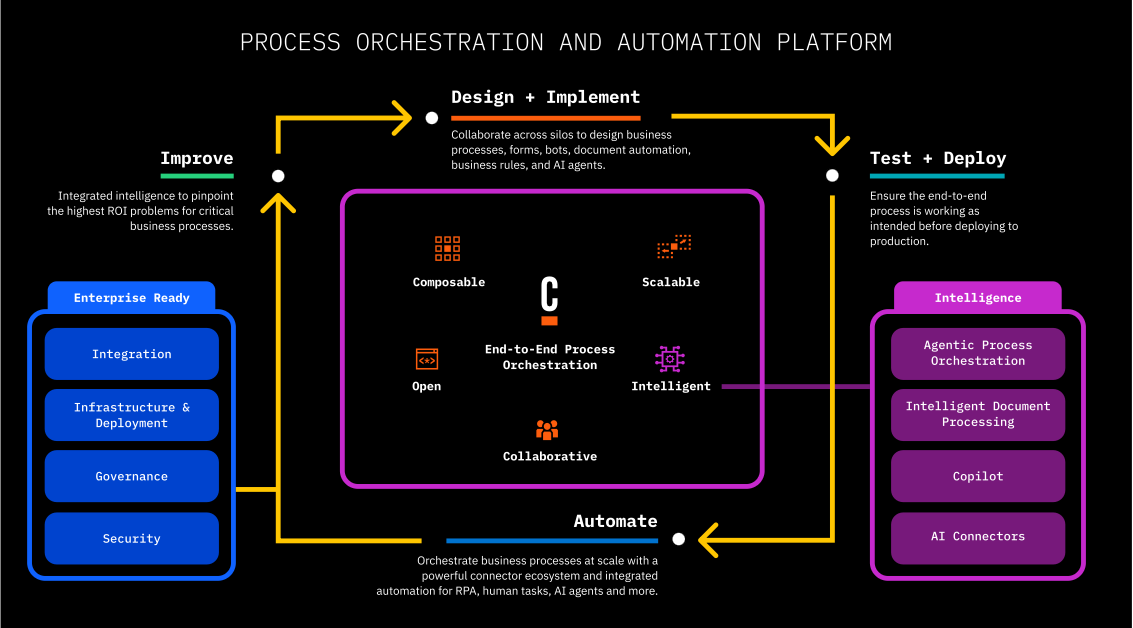
Throwing AI at an unmanaged process is just going to increase technical debt, not reduce complexity. Process orchestration, such as what Camunda provides, allow for integration across point solutions including AI, but also integrating line-of-business systems, CRM, ERP and other systems into an end-to-end process that maps to the customer journey. This provides visibility and the ability to govern the process, then switch out endpoints independently since the process orchestration platform is handling the integration and scalability, not the individual point business solutions.
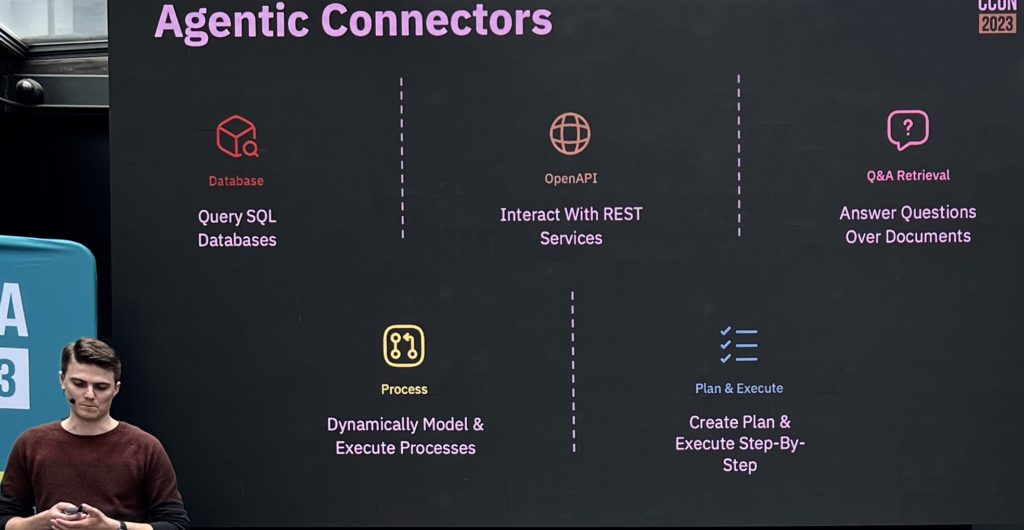
Frederic discussed case studies with Halkbank (a Turkish bank), who used Camunda process orchestration with AI to improve their money transfer processes; and Deutsche Telekom, who evolved from manual to RPA bots to more fully orchestrated processes using Camunda that include RPA bots and AI endpoints. The Deutsche Telekom example is particularly interesting in that it shows that migration, where manual processes had RPA bots applied to them in a somewhat ad hoc fashion, then orchestrated into end-to-end processes, then the RPA bots eventually replaced with APIs or AI endpoints. Camunda has built-in connectors to several OpenAI platforms such as Azure OpenAI, or you can build a connection to your own internal LLM.
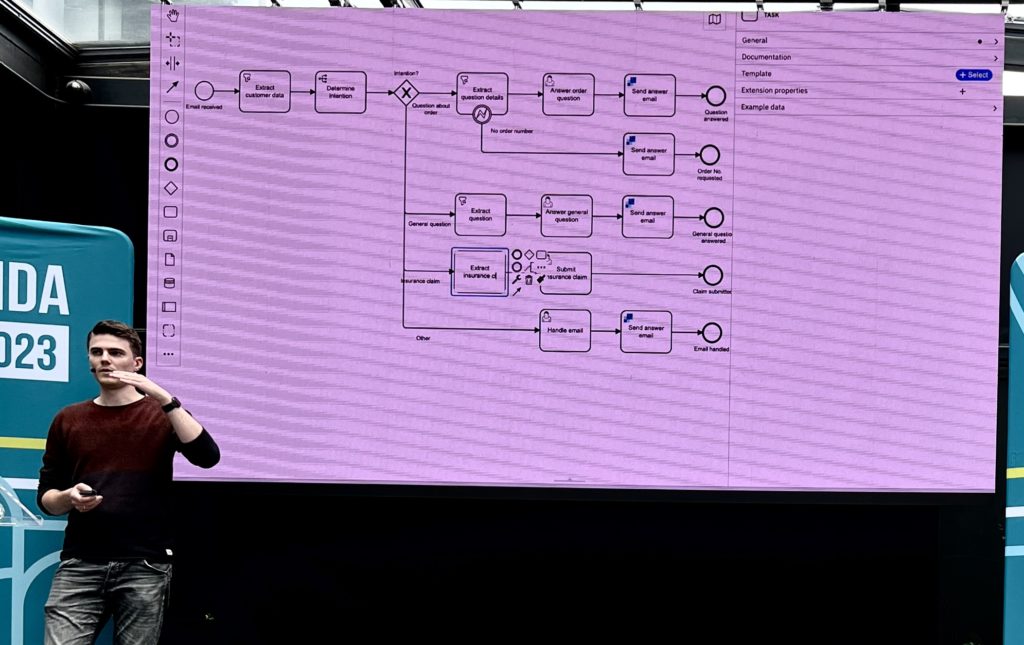
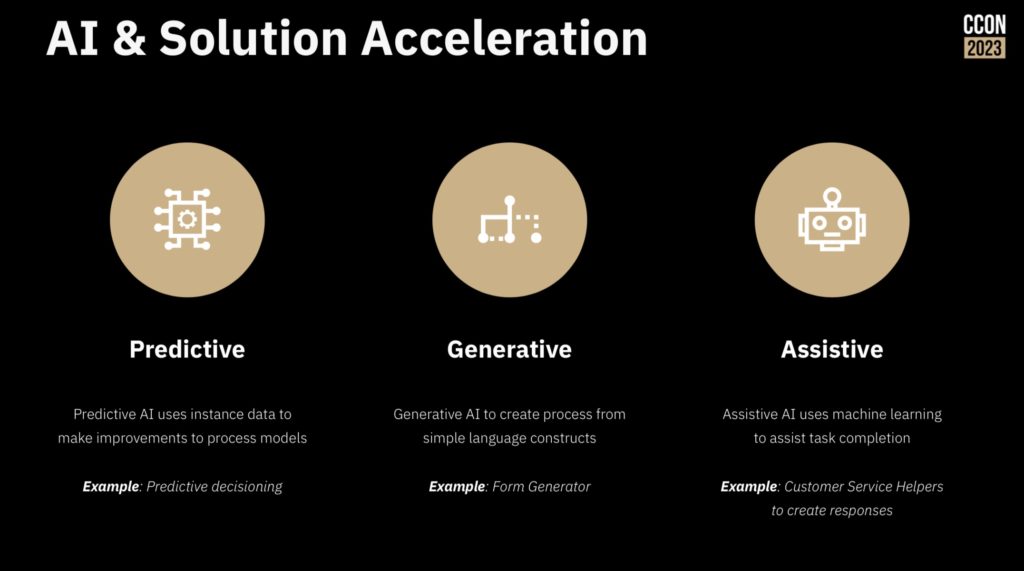
Many organizations haven’t even started on the journey to extract processes from their legacy systems, and he showed using Camunda Copilot that generates process models from text descriptions. I wrote about this in previous posts (both Camunda and other process vendors who use AI to help model processes), and it’s a bit of a party trick. In the simplest case, it produces a process model, but it’s usually pretty high level and could have been created by a BPMN-trained business analyst in a couple of minutes. Where it starts to be more useful is when there are longer more technical descriptions of processes available — he showed pasting in a long text description of a process, and a section of COBOL code, and each produced a process model. Okay for a starting point, but this is something that I think will get more use during a demo than in actual process analysis.
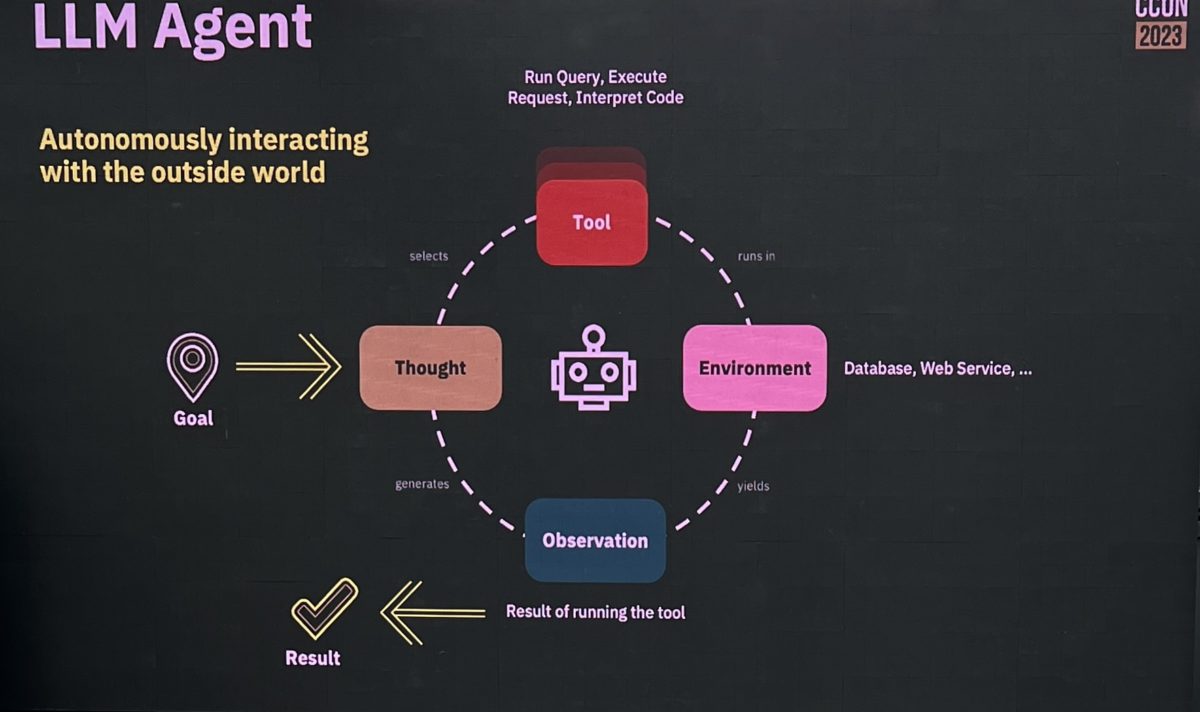
He finished with a discussion of agentic AI, which in the most extreme sense is turning over a business process/decision to a completely non-deterministic AI; however, he advocated for deterministic guardrails within which a non-deterministic AI. The model for this shows an ad hoc BPM subprocess boundary representing an agent, containing multiple activities/processes that could be selected depending on the information at hand. On the boundary of the ad hoc subprocess, there are deterministic guardrails in the form of escalation and timeouts. For those of you who have been around the BPMN standards for a while, this style of ad hoc/deterministic processes looks a lot like CMMN. (CMMN arguably should never have been spun off from the BPMN standard, and has not been broadly accepted in the industry.)
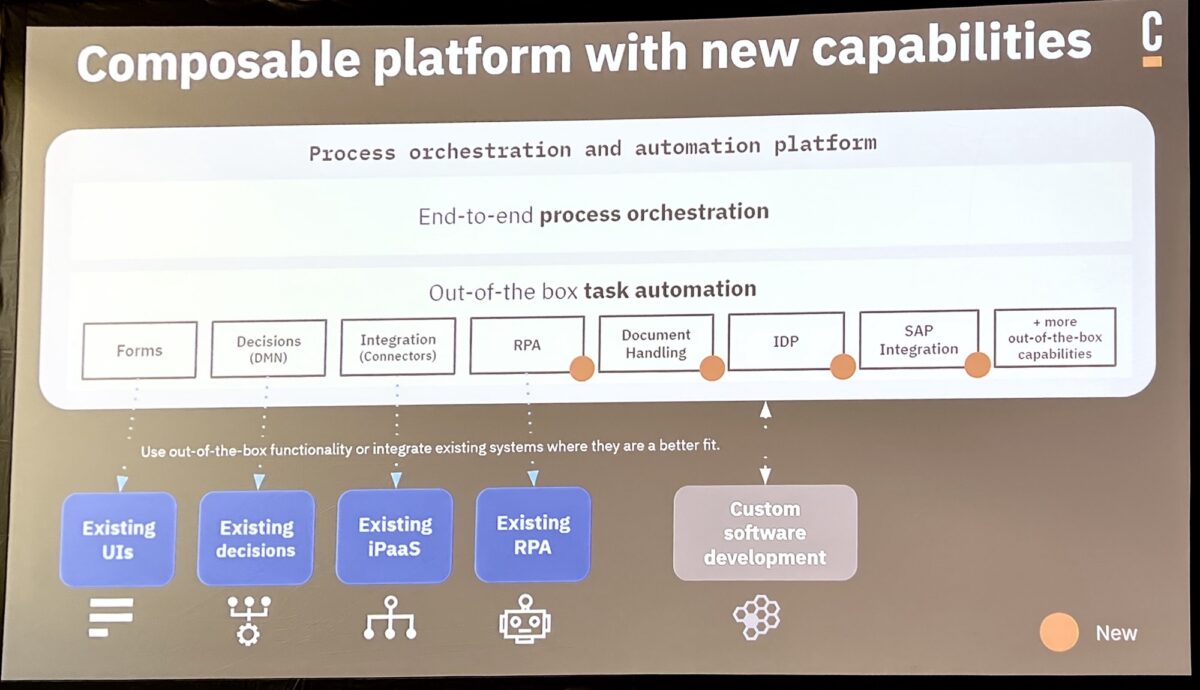
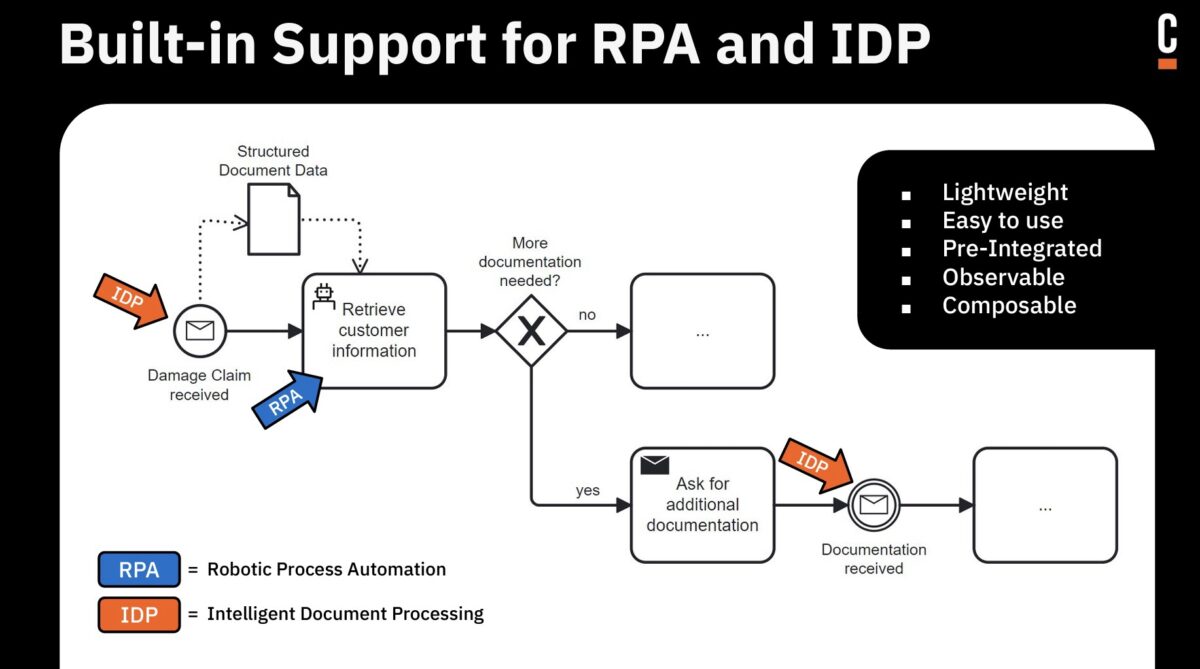
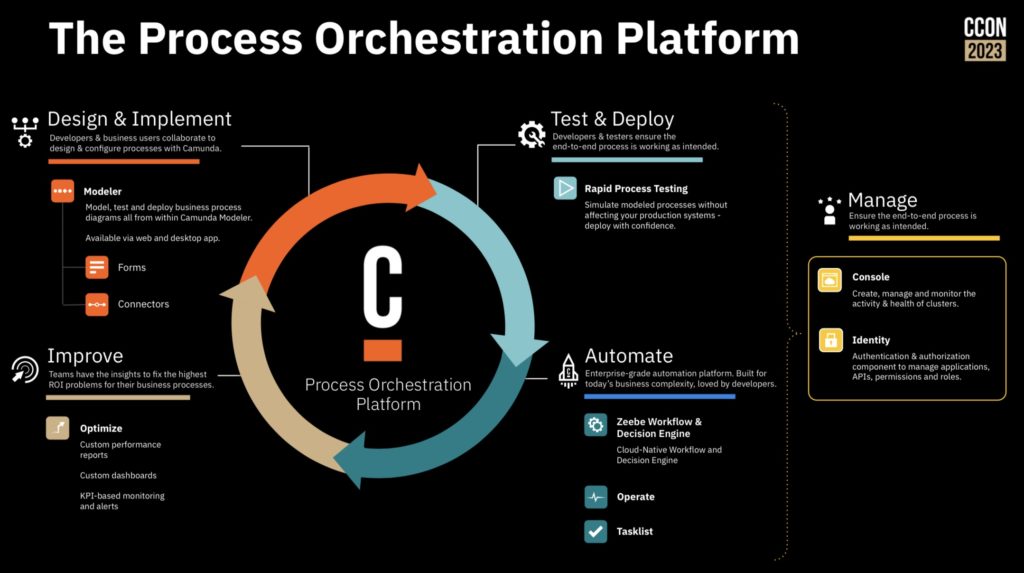
Daniel Meyer, CTO, took the stage to talk about the future of automation with Camunda from a product standpoint. Building on their end-to-end process orchestration platform (now really the Zeebe engine since they have made plans to sunset C7 and previous generations), you can include human tasks; automated decisions; integration via standard protocols and connectors of various types built by Camunda, partners and customers; RPA (to be released in their April release); and IDP (intelligent document processing, to be released in April).
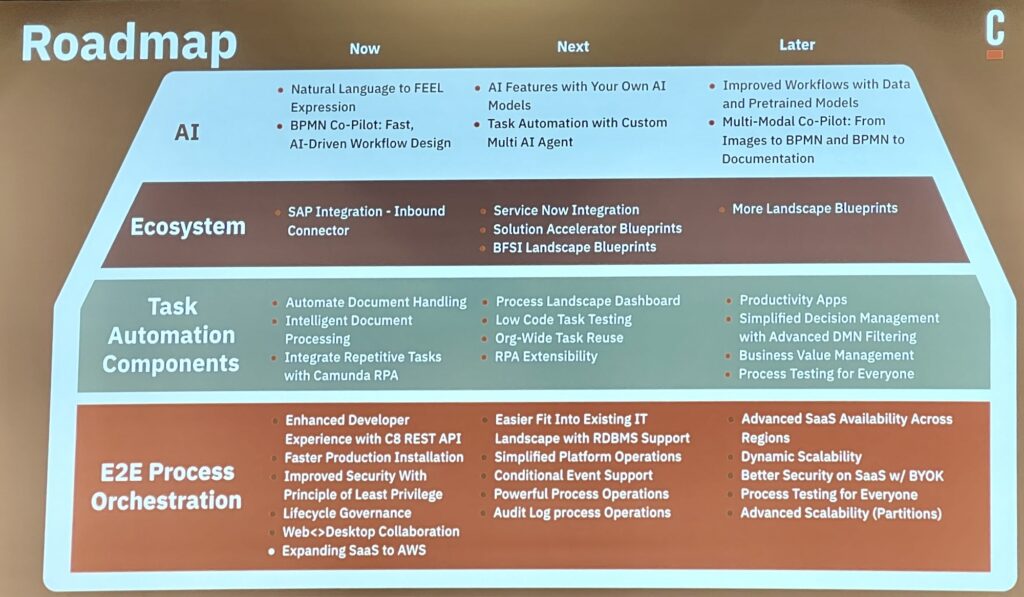
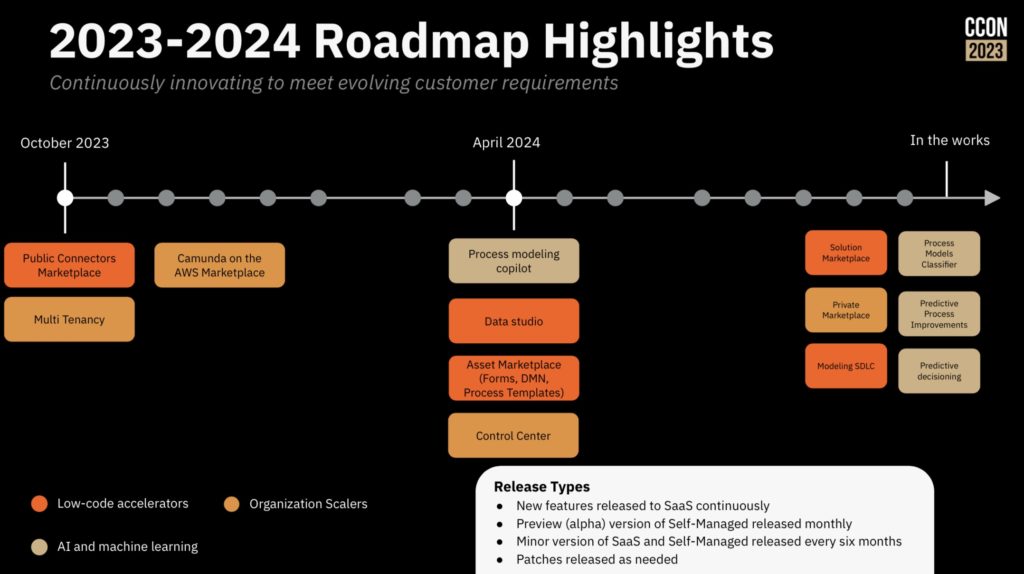
He walked us through the specific roadmap items, including what was released in October, and what is coming in April and October (Camunda runs on a strict 6-month release cycle). The core process orchestration roadmap is mostly about new developer features plus improved scalability and deployment capabilities. Questions from the audience included discussions of some of the differences from the Camunda 7 engine, and I’m guessing that Camunda is having a bit of a challenge with encouraging their customers to take on the platform migration. Their upcoming RPA offering is intended to be a “good enough” solution when an organization doesn’t need the full capabilities of a third party RPA tool, and possibly is using RPA as a temporary stopgap as they work towards API integration. They are also releasing their first version of IDP to allow for extracting data from documents, and move towards more robust document classification.
It’s important to note that RPA and IDP are necessary for Camunda to be included in Gartner’s newish BOAT categorization. In my opinion, these are a bit niche for Camunda’s product direction, but probably a case of an influential industry analyst firm forcing the market in a certain direction.
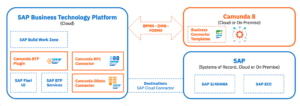
Also coming up is their SAP integration, which is very interesting for organizations that are migrating between older SAP and S/4HANA platforms, as well as providing deep integration between SAP processes and other activities within the business.
We heard from Sathya Sethuraman, Field CTO, on operational resilience in financial services. There are a lot of factors to this, but there’s definitely a focus is on being able to provide fast, automated, seamless transactions regardless of the size of the transaction. If you’re going to provide micro-lending and process millions of small transactions to replace cash, it has to be immediate and easy to use. At the other end, if you’re going to deal with a huge volume of mortgage renewals based on changing interest rates, you need to automate both the process and the decisions regarding what the customer is offered, or you’ll lose business. Customer service needs to improve and become more automated — using intelligent chatbots for straightforward inquiries, for example — since customers don’t have the same sense of loyalty to a financial institution that many banks used in the past to build their business.
He talked about the time required to transfer money between countries: in many situations, this takes 5+ days. Compare that to a platform like Wise, which acts as an intermediary and allows same-day transfers between banks in different countries. These disruptive fintechs are going to take a huge chunk of traditional banks’ business if the banks can’t innovate in response to the customers’ needs. In countries that have proper banking regulations, like Canada, this puts a lot of burden traditional banks to update their legacy technology, optimize their processes, and automate where possible. Processes and decisions need to be flexible and responsive in the face of changing markets and customer needs, and be able to scale up quickly without increasing costs.
Lots of financial services customers and prospects in the room, so this message likely hit home.
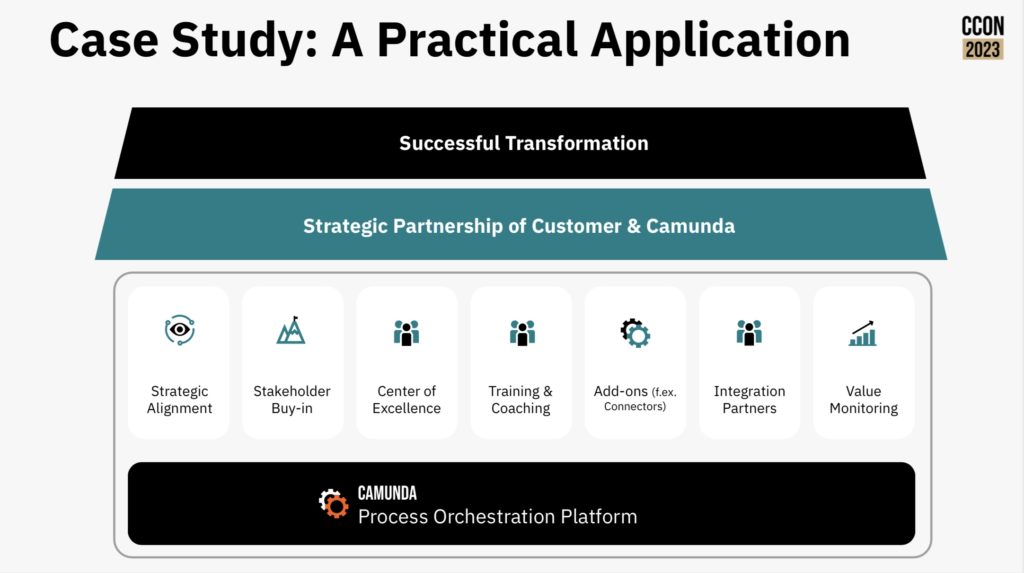
We finished with Gustavo Mendoza, Senior Sales Engineer, and Olivier Fiaty, Senior Customer Success Manager, with a presentation on building a business case for process orchestration. This was a fairly standard framework of identifying pain points; defining objectives and KPIs; mapping and analyzing current processes; co-developing and analyzing future-state business process model; conducting a cost-benefit analysis; and cultivating stakeholder support. As they went through these, they showed how each stage applied to a customer case study with an omnichannel financial services organization, and where Camunda products could be applied during the initial analysis and in the solution estimation. Camunda has an online guide for building a business case, and offers a half-day consultative workshop to help business and technical stakeholders work through this.