
Business Rules — Focus on “Business”. Guilhem Molines, IBM
Guilhem Molines presented on what business analysts can do in the creation of automated decisions before developers need to get involved (or take over), and what the modeling tools can provide to help them get further in the process independently.
Clearly, business analysts can model business decisions at the level of a decision requirements diagram (e.g., DMN DRD) that shows the entities and information required to make a decision. Then, the data and decision models required for implementation can be created by the business analyst or co-authored together with a developer. IBM’s ODM tool has authoring assistance such as smart predictions to guide an analyst while they are modeling, plus suggestions to define terms in the model as they are used in a rule definition.
In authoring decision tables, assistance may include Excel-like functions for copy and paste or smart drag to extend a range; as a table is being defined, there can be guidance to check for gaps and overlaps in the parameter ranges. Being able to do instant validation for a decision table by entering data values and seeing the calculation result (without deploying the rule) builds confidence in the logic implementation.
A more comprehensive “unit testing” approach allows the analyst to provide a number of input parameter sets in a spreadsheet or similar tabular form and see the results. A further step in testing decisions is simulation based on a large quantity of production data; then integration testing in a full test environment before promotion to production.
Much of this presentation was based on IBM ODM capabilities, although some good ideas here for any modeling environment.
Combining Decision Models for Better Decision Management. Fernando Donati Jorge, FICO
Fernando Donati Jorge presented on whether we have the right decision model to solve mysteries in addition to puzzles — an interesting distinction, where puzzles can be solved given the right information, while mysteries may not have a well-defined answer and can depend on future interactions.
The challenges with mysteries is that there is too much data but no indication of the most relevant bits; they are full of uncertainties; and they depend on future known and unknown interactions. Decision models can properly contextualize data, but don’t measure relevance. Predictive analytics can quantify uncertainties, and decision models can contextualize the use of different types of knowledge models. An analytic decision model (a Gartner term, which does not include DMN decision models) can represent how different decision outcomes can lead to different future interactions.
Typically, there are two separate types of decision models: one that models the input data and business knowledge model that results in a decision (a DMN model), and the other that models how a decision impacts business performance. If you want to combine these into a single model, an extension to DMN is required to be able to model performance metrics, which in turn have models, decisions and data as inputs.
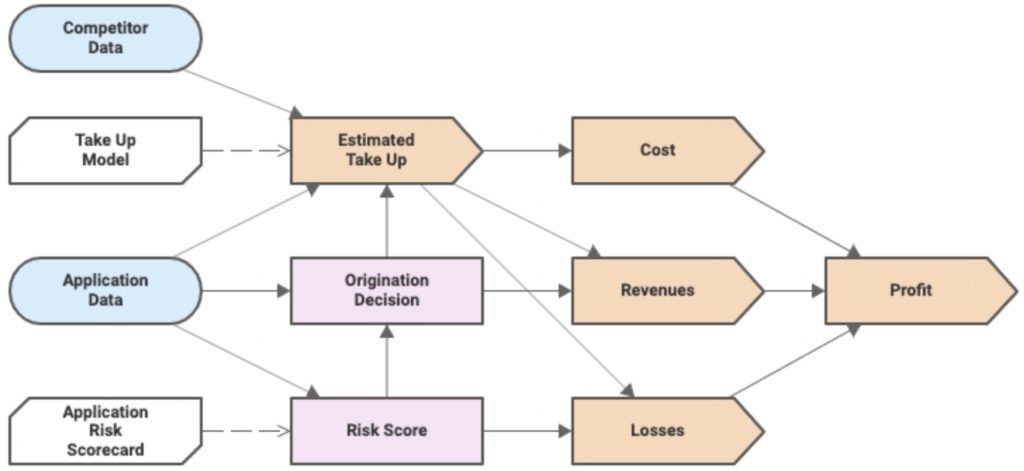
This DMN extension is available in the FICO Analytic Cloud for adding KPIs to decision-making. Good discussion about how they handle latency for calculating the performance metrics, and the issue of metrics aggregation over multiple decision instances. They don’t currently allow a performance metric to inform (provide input to) a decision, but that’s obviously open for future discussion.
Both of the presentations in this section have looked at how vendors are adding value to their DMN-based modeler: IBM in terms of interactive to assist the modelers in creating better models, and FICO in extending DMN to include performance metrics directly in a decision model.
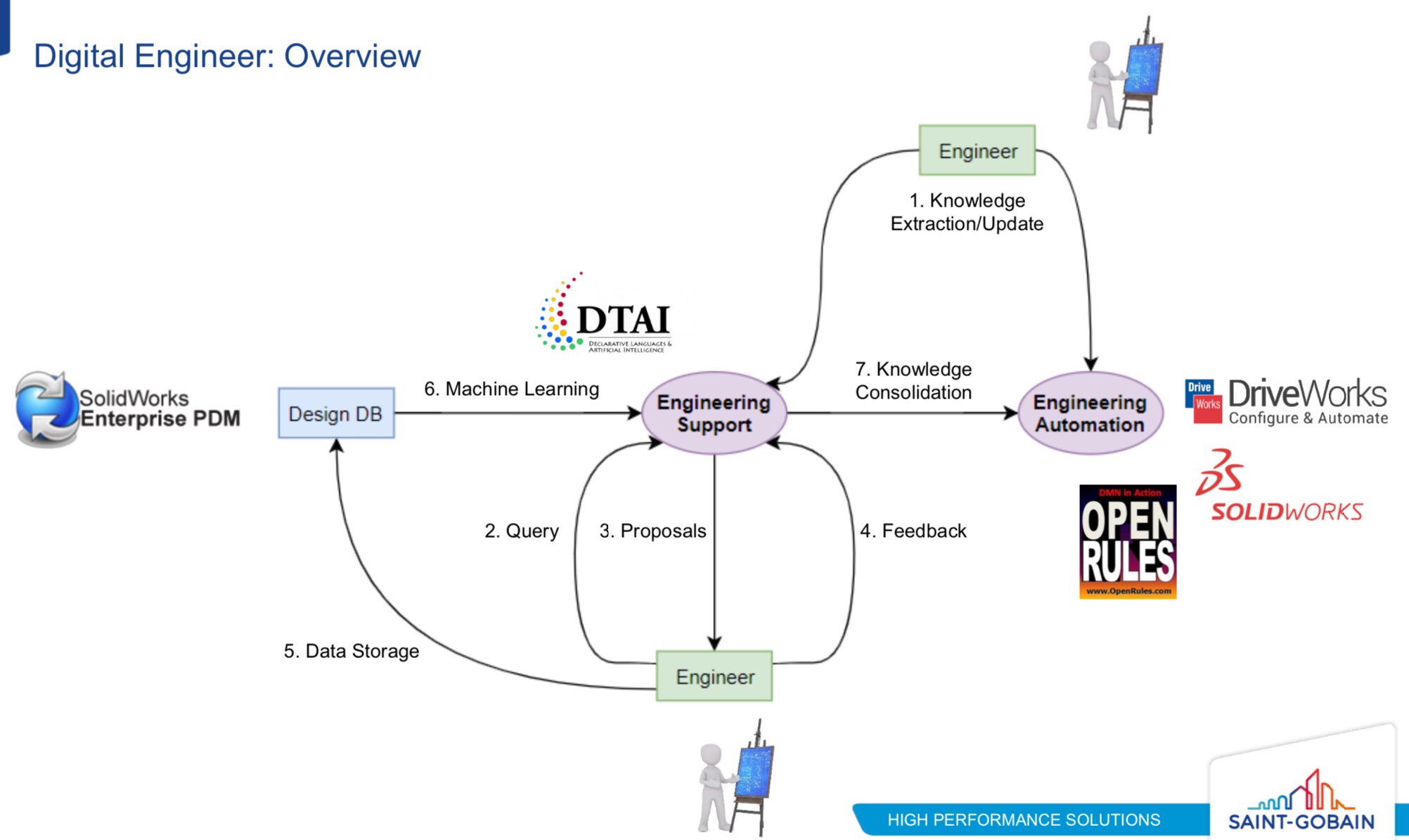

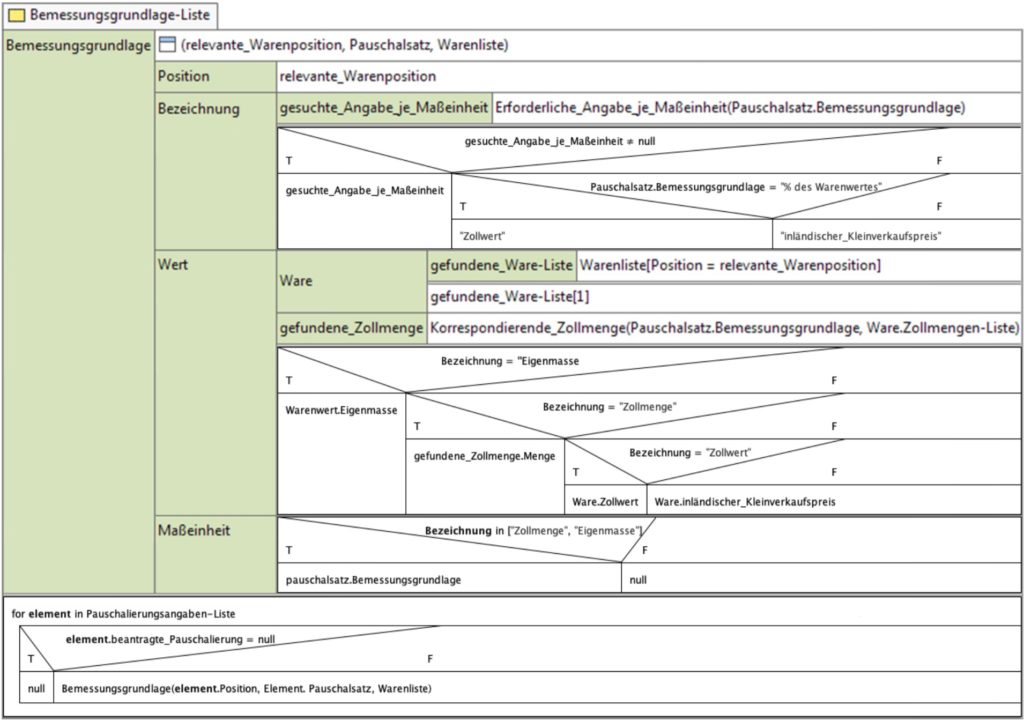
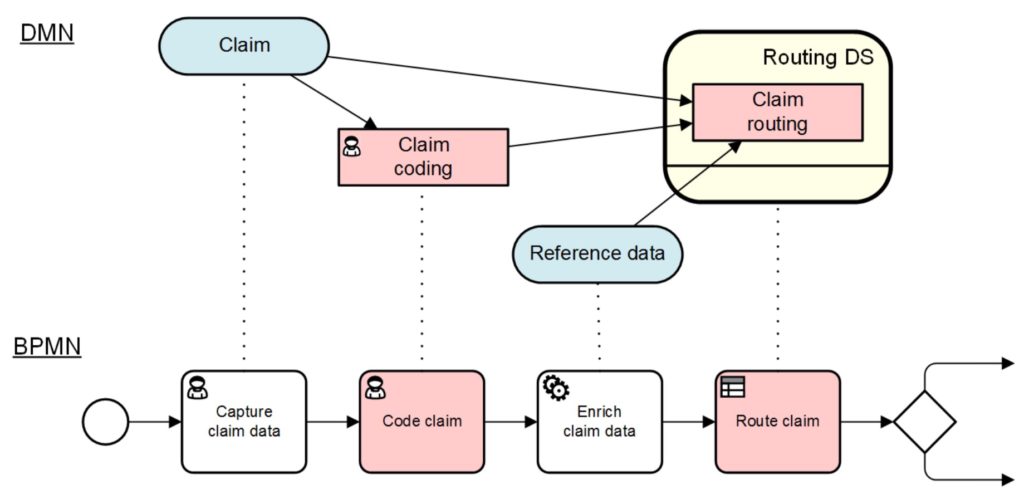
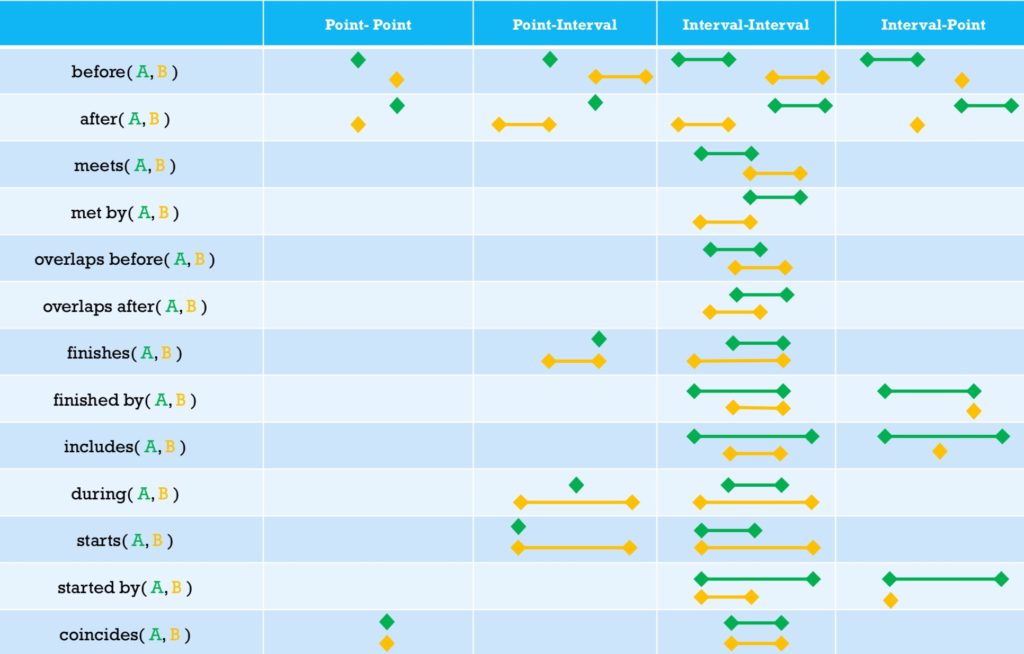
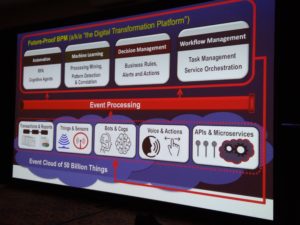 His Future-Proof BPM architecture — what others are calling a digital transformation platform — brings together a variety of capabilities that can be provided by many vendors or other organizations, and fed by events. In fact, the core capabilities (automation, machine learning, decision management, workflow management) also generate events that feed back into the data flooding into these processes. BPM platforms have the ability to become the orchestrating platforms for this, which is possibly why many of the BPMS vendors are rebranding as low-code application development environments, but be aware of fundamental differences in the underlying architecture: do they support modularity and microservices, or are they just lifting and shifting to monolithic containers in the cloud?
His Future-Proof BPM architecture — what others are calling a digital transformation platform — brings together a variety of capabilities that can be provided by many vendors or other organizations, and fed by events. In fact, the core capabilities (automation, machine learning, decision management, workflow management) also generate events that feed back into the data flooding into these processes. BPM platforms have the ability to become the orchestrating platforms for this, which is possibly why many of the BPMS vendors are rebranding as low-code application development environments, but be aware of fundamental differences in the underlying architecture: do they support modularity and microservices, or are they just lifting and shifting to monolithic containers in the cloud?