Urban Tech Hero is a non-profit organization with the mission to connect underserved youth to the superpower of tech by achieving IT certification and employment. Danny DeJesus, Adriel Henderson and Jonathan Patridge took the stage to talk to us about what they do, and their longer term vision of transforming underserved communities from economically disadvantaged to technologically empowered. Danny, the founder of Urban Tech Hero, had his own life personally transformed during his teens when he learned to read, broke out of his societal and economic constraints, and eventually discovered the power of technology. Adriel, their program manager, saw technology as a way to let her do more for Urban Tech Hero and her life in general. And Jono is the process engineer who learned Camunda and brought it to life within Urban Tech Hero.
Their onboarding process, like that of many much larger organizations, was a bit of a mess: someone handling student onboarding had a lot of manual work across multiple applications, and there was insufficient feedback to the potential students about what was happening in the process.
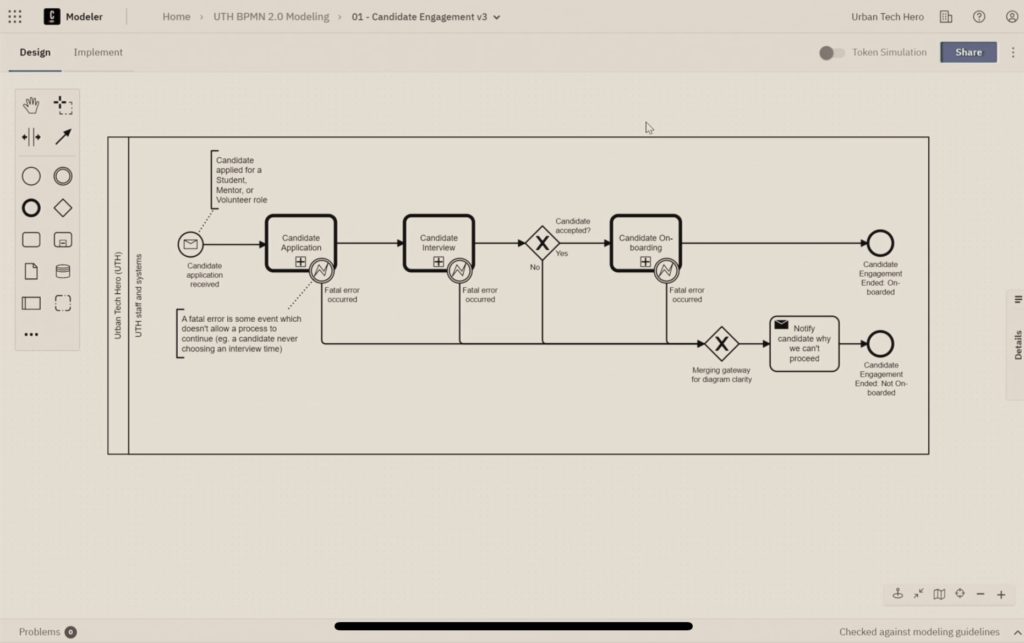
They took advantage of the Camunda for Common Good program for software, training and support, and built an onboarding process that was more efficient and provided better control over the process. We saw their actual process model with a simulation of how it works; like many onboarding processes, this is a matter of passing through a number of tasks that are gates to success, such as submitting an application, setting up and completing an interview, acceptance decisions, sending notification emails, and some lightweight integration with applications such as Google Forms.
They still have a lot to do in terms of automation, but they are driven to improve their efficiency because they have a small number of people to do a lot of tasks. There was a lot of interest and questions from the audience: not only is this an inspiring story of a small non-profit using technology to do something that really makes a difference, it’s a good demonstration of how to get started using process orchestration to tackle a messy manual onboarding problem. In spite of being relatively new to Camunda, they have an incredible amount of knowledge about how to use it within their context, and have a few ideas for projects in the works for future improvements.
Zurich has been working on their end-to-end processes for a long time, and found that the lead time for changes became a problem as they attempted to move to continuous improvement through continuously changing processes. Laurenz Harnischmacher and Stefan Post of Zurich presented their approach to improving this. They measured Change Lead Time, which is the time that the developer starts working on a change until it is released to production, and found that it was generally about 10 weeks. This was a problem not just for agile processes in general, but they also had a mismatch between what the developers were creating versus what the users actually needed, which meant that there were potentially multiple of those 10-week cycles to solve a single problem. In other words, like many other organizations, there was not an appropriate and complete method of communicating needs from business to the developer.
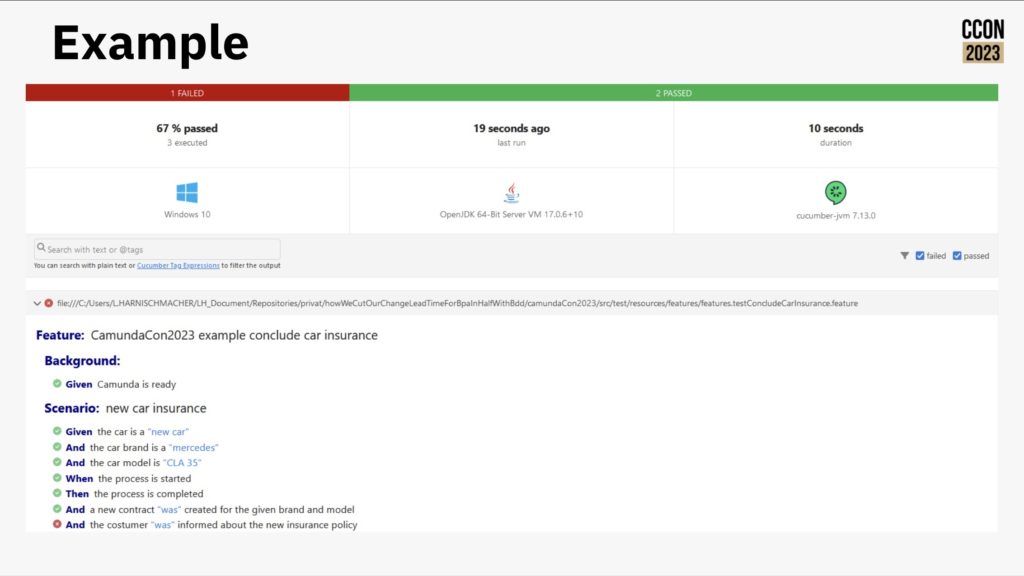
They adopted Behavior Driven Development, which provides a methodology for the business to define the desired system behavior using structured test scenarios, aided by the use of Cucumber. These scenarios are defined with given…when…then…and language to specify the context, constraints and expected behavior. This takes a bit longer up front, since the business unit has to write complete test cases, then the developers/testers create the automated testing scenarios and feedback to the business if they find inconsistencies or omissions, then development occurs, then the automated testing can be applied to the finished code. This is much more likely to result in code that works right for the business the first time rather than requiring multiple cycles of the full development cycle.
Although they’ve been able to have a huge improvement in lead time, I’m left with the thought that somewhere along the Agile journey, we lost the ability to properly create business requirements for software. Agile in the absence of written requirements works okay if your development cycle is super-short, but 10 weeks is not really that Agile. I’m definitely not advocating a return to waterfall development, where requirements are completely documented and signed off before any development begins, but we need to bake in some of the successful bits of waterfall with a more (lower-case A) agile iterative approach. This is independent of Camunda or any other platform, and more a comment on how application development needs to work in order to avoid excessive lengthy rework cycles. Also, the concepts of BDD borrow a lot from earlier test-driven development methods; in software development, like much else in life, everything old is new again.
Interesting to note from the comments at the end that the automated test cases are only for automated/service steps, and that the business people do not create process models directly. 樂
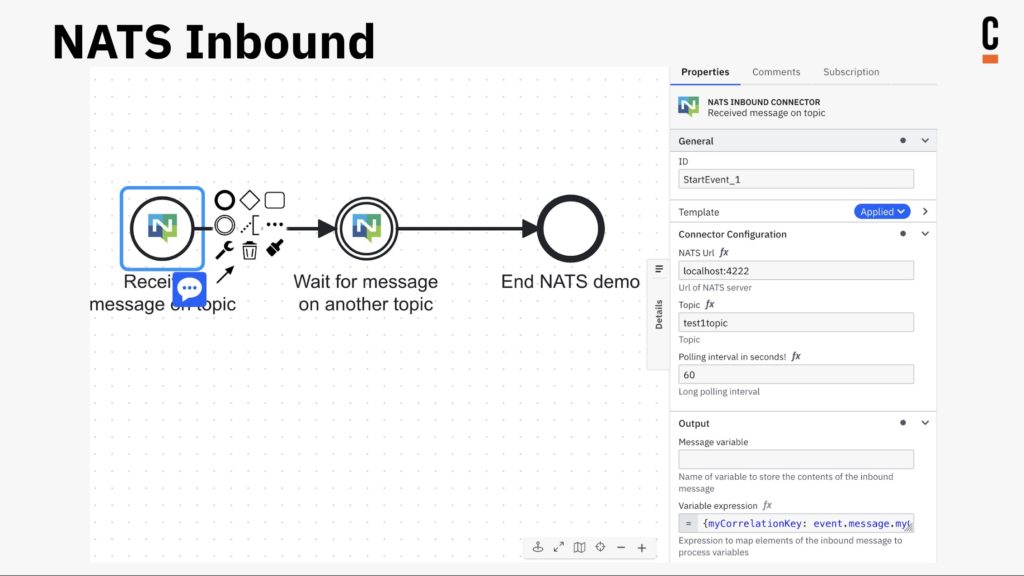
When a customer presenter was unable to attend at the last minute, Joe Pappas stepped in and gave an impromptu presentation and demo on building connectors. The Camunda Marketplace (formerly the Community Hub) is the place for some of the expanding shared resources that Jakob Freund spoke about in the keynote: there’s one section for Camunda-provided connectors, one for those provided by partners, and one for those from the community.
Joe walked through some of the connectors that he has built and published, showing the code and then demonstrating the functionality. You can find his connectors in the Community section of the Marketplace, including NATS inbound/outbound, email inbound, file watch inbound, and database inbound from Postgres or MongoDB. Not much to write about since it was mostly a code demo, but cool stuff!
I feel like I’m barely back from the academic research BPM conference in Utrecht, and I’m already at Camunda’s annual CamundaCon, being held in New York (Brooklyn, actually) — the first time for the main conference outside of Germany. The location change from Berlin is a bit of a tough call since they will lose some of the European customers who don’t have a budget for international travel, but the opportunity to see their North American customers will make up for it. They’re also running the conference virtually for those of you who can’t be here in person, and you can sign up for free to attend the presentations online.
Although I don’t blog about anything that happens after the bar is open, I did have a couple of interesting conversations at the networking event last night about my relationship with Camunda. I’m here this week as an independent analyst, and although they are covering my travel expenses, I’m not being paid for my time and (as usual) the opinions that I write here are my own. This is the same arrangement I have with any vendor whose conference I attend, although I have got a bit pickier about which locations I’m willing to travel to (hint: not Vegas). I’ve been covering Camunda a long time, starting 10 years ago with their fork from Activiti, back when they didn’t capitalize their name. They’ve been a client of mine in the past for creating white papers, webinars and speaking at their conference. I’ve also worked with some of their clients on technical strategy and architecture, which is the other side of my business.
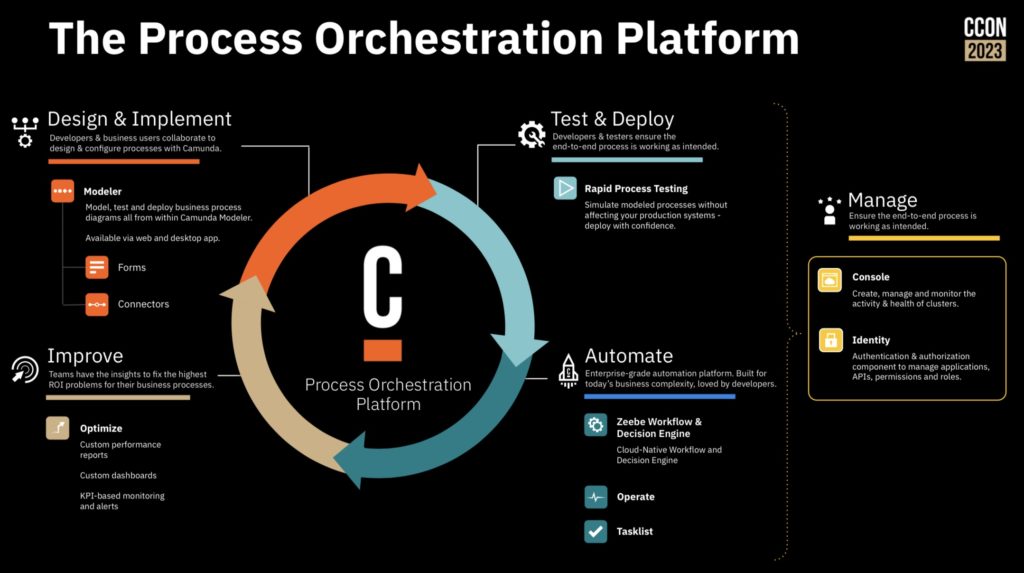
The first day opened with a keynote from Camunda CEO Jakob Freund giving a brief retrospective of the last 10 years of their growth and especially their current presence in North America. There’s over 200 people attending today in person at the 74Wythe event space, plus an online contingent of attendees. He started with a vision of the automated enterprise, and how this is made difficult by the complexity of mission-critical processes that cross multiple silos of systems and organizational departments. Process orchestration allows for automation of the end-to-end processes by acting a a controller that can invoke the right resource — whether a person or a system — at the right time while maintaining end-to-end visibility and management. If you’re not embracing process orchestration, you run the risk of having broken processes that have a significant impact on your customer satisfaction, efficiency and innovation.
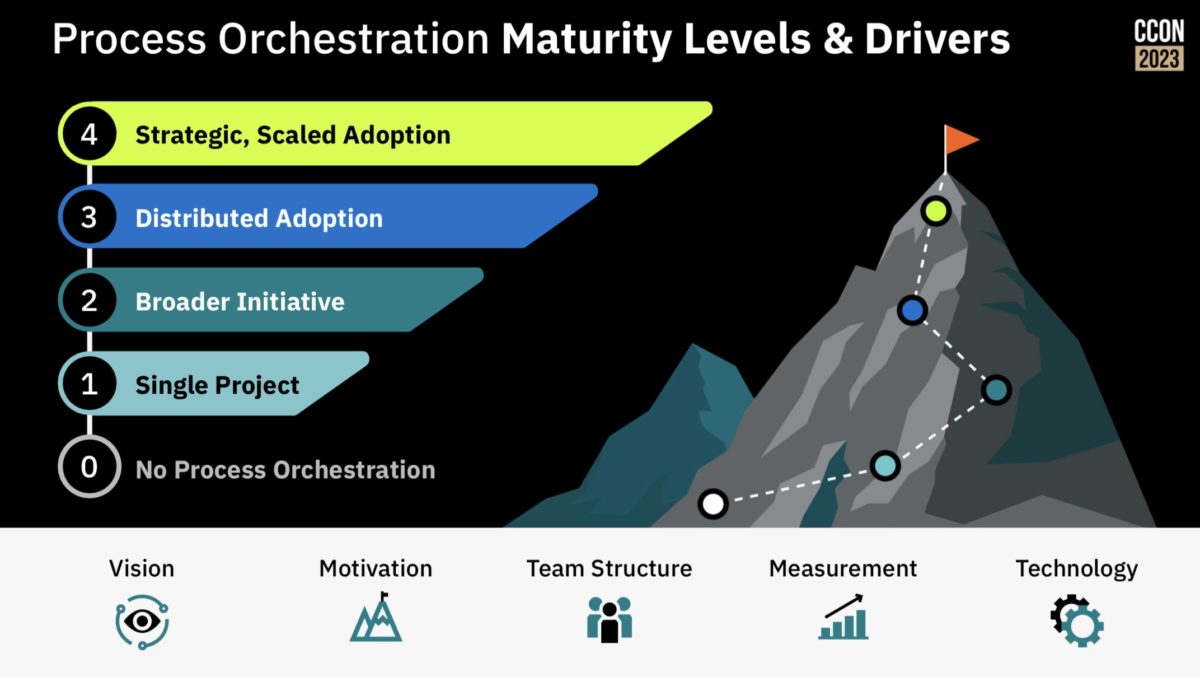
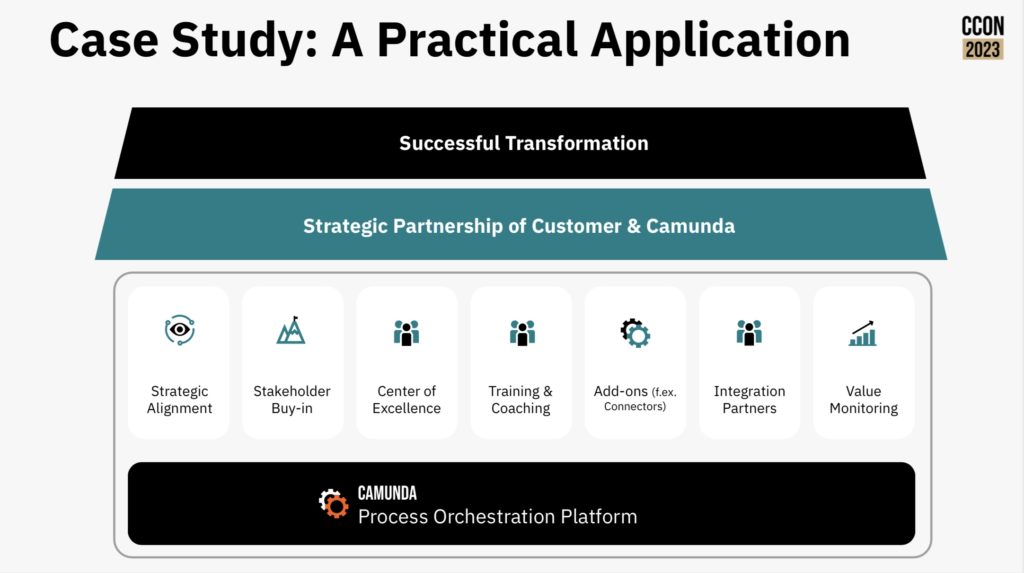
Camunda has more than 500 customers globally now, and has amassed over 5000 use cases for how those organizations are using Camunda’s software. This has allowed them to develop a process orchestration maturity model: from single projects, to broader initiatives, to distributed adoption, to a strategic scaled adoption of process orchestration. Although obviously Jakob sees the Camunda Process Orchestration Platform as a foundational platform, he looked at a number of other non-technical components such as stakeholder buy-in, plus technical add-ons and integration partners. I like that he started with strategic alignment and ended with value monitoring wrapping back to the alignment; this type of alignment between strategic goals and operational metrics is something that I strongly believe in and have written about quite a bit.
Since we’re in New York, his process orchestration in action part was focused on financial services, although with lessons for many other industries. I work a lot with my own financial services clients, and the challenges listed are very familiar. He walked through case studies of Desjardins (legacy BPMS replacement), Truist (merging systems from two merged banks), National Bank of Canada (automation CoE to radically reduce project development time), and NatWest (CoE to aid self-service projects).
He moved on to talk about the innovation that Camunda is introducing through their technology. They now address more of the BPM lifecycle than they started out with — which was purely as a developer tool — and now provide more tools for business and IT to collaborate on process improvement/automation projects. They are also addressing the accelerating of solutions through some low-code aspects; this was a necessary move for them in the face of the current market. Their challenge will be keeping the low code tooling from getting in the way of the developers, and keeping the technical details from getting in the way of the business people.
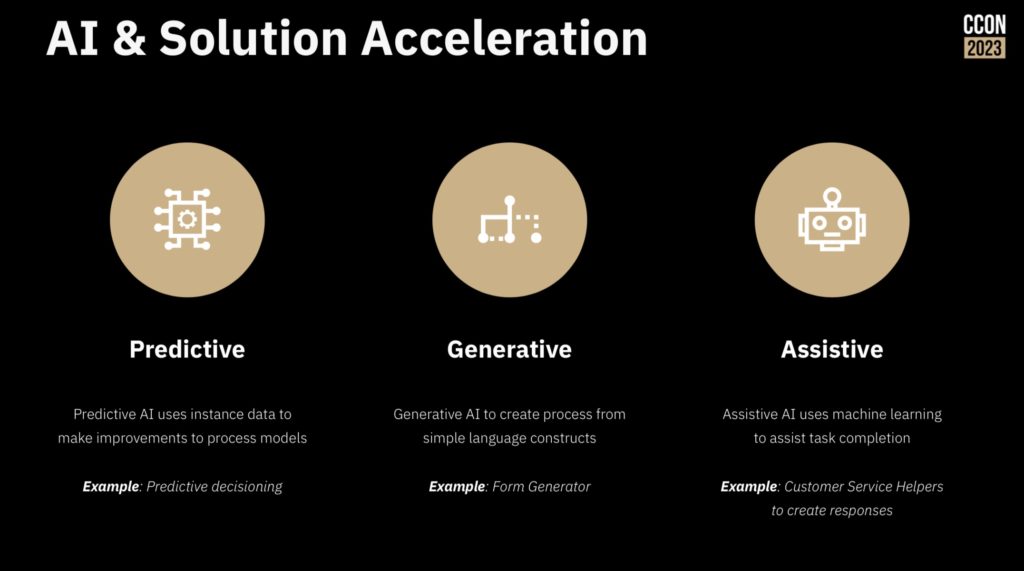
No technical conference today is complete without at least one slide on AI, and Jakob did not disappoint. He walked through how they see AI as it applies to process orchestration: predictive AI (e.g., process mining and decisioning), generative AI (e.g., form generator from simple language), and assistive AI (e.g., knowledge worker helper).
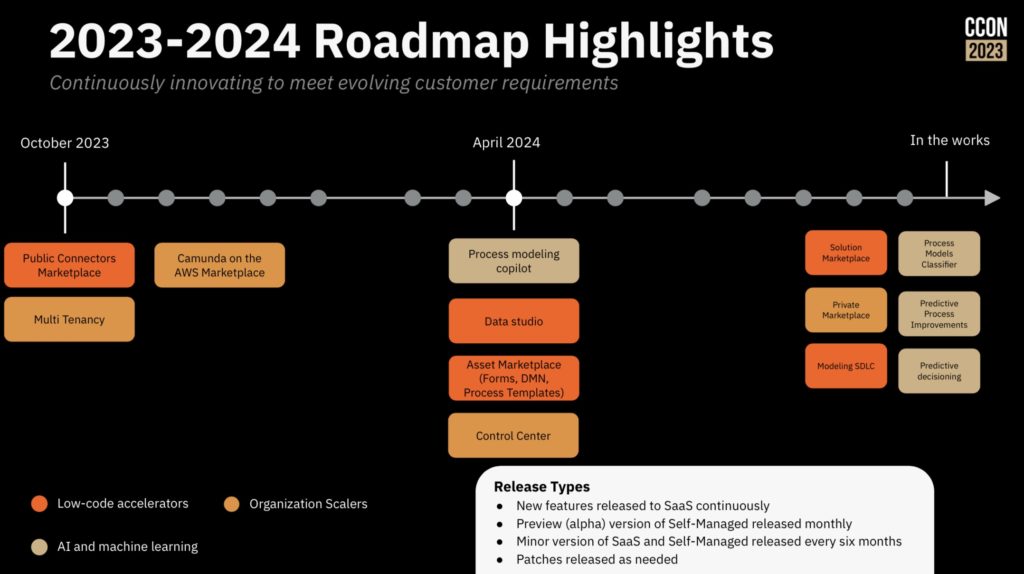
He described their connectors marketplace, which includes connectors created by them but also curated from their partners. Connectors are essential for integration, but their roadmap also includes process templates, internal marketplaces within an organization, and entire industry solutions and applications. This is an ambitious undertaking that a lot of vendors have done badly, and I’ll be very interested in seeing how this develops.
He finished up with some larger architecture issues: cloud support, security and compliance, multi-tenancy and how this allows them to support organizations both big and small. Their roadmap shows a lot of components that are targeted at broadening their reach while still supporting their long-term technical customers.
It’s now really the last day of BPM2023 in Utrecht, and we’re off at the Utrecht Science Park campus for the Industry Day. The goal of industry day is to have researchers and practitioners come together to discuss issues of overlap and integration. Jan vom Brocke gave the keynote “Generating Business Value with Business Process Management (BPM) – How to Engage with Universities to Continuously Develop BPM Capabilities”. I don’t think that I’ve seen Jan since we were both presenting at a series of seminars in Brazil ten years ago. His keynote was about how everything is a process (bad or good), but we need to consider how to leverage the opportunity to understand and improve processes with process management. This doesn’t mean that we want to draw a process model for everything and force it into a standardized way of running, but need to understand all types of processes and modes of operation. His work at ERCIS is encouraging the convergence of research and practice, which means (in part) bringing together the researchers and the practitioners in forums like today’s industry day, but also in more long-running initiatives.
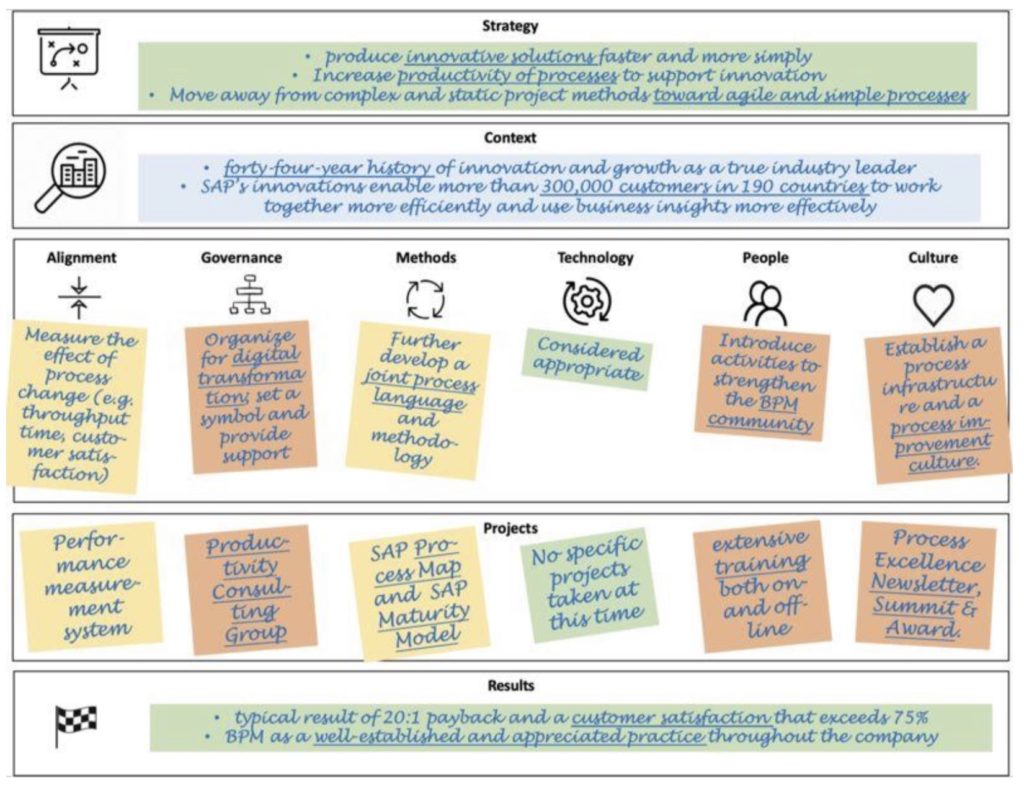
He discussed the “BPM billboard” which shows how BPM can deliver significant value to organizations through real-world experience, academic discourse and in-depth case studies. Many businesses — particularly business executives — aren’t interested in process models or technical details of process improvement methodologies, but rather in strategy in their own business context: how can BPM be brought to bear on solving their strategic problems. This requires the identification or development process-centric capabilities within the organization, including alignment, governance, methods, technology, people and culture. Then the issues can lead to actionable projects, and the results of those projects.
He moved on to talk about the BPM context matrix, with a focus on how to make people love the BPM initiative. This requires recognizing the diversity in processes and also diversity in methods and intentions that should be applied to processes. He showed a chart of two process dimensions — frequency and variability — creating four distinct clusters of process types. This was then mapped using the BPM billboard to map onto specific approaches for each cluster. Developing more appropriate approaches in the specific business context then allows the organizations involved to understand how BPM can bring value, and fully buy in to the initiates.
His third topic was on establishing the value of process mining, or how to turn data into value. Many companies are interested in process mining, and may have started to work on some projects in their innovation areas, it’s a challenge for many of them to actually demonstrate the value. Process mining research tends to focus on the technical aspects, but there needs to be expansion of the other aspects: how it impacts individuals, groups and high level value chains.
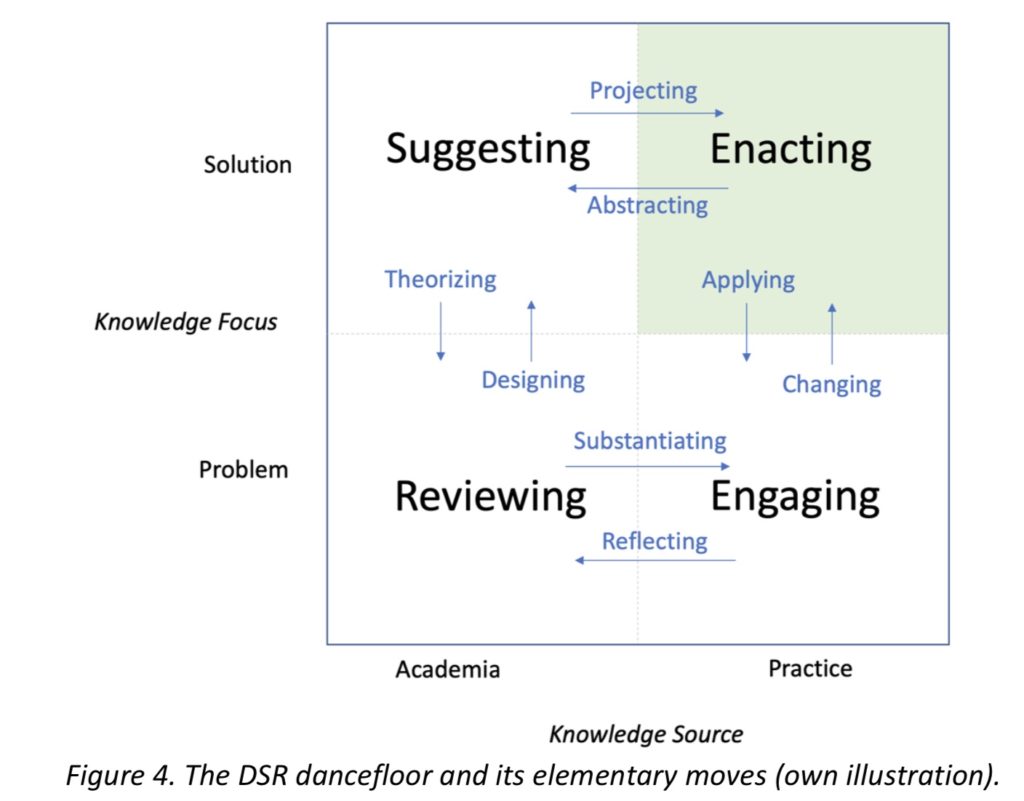
His conclusion, which I completely agree with, is that we need to have both research and practice involved in order to move BPM forward. Practice informs research, and research supports practice: a dance that involves both equally.
Following the keynote, I was on a panel with Jan in addition to Jasper van Hattem from Apolix and Jason Dietz of Tesco. Lots of good conversation about BPM in practice, some of the challenges, and how research can better support practice.
The rest of the day was dedicated to breakouts to work on industry challenges. Representatives from four different organizations (Air France KLM Martinair Cargo, Tesco, GEMMA, and Dutch Railways) presented their existing challenges in process management, then the attendees joined into groups to brainstorm solutions and directions before a closing session to present the findings.
I didn’t stick around for the breakouts, it’s been a long week and my brain was full. Instead, I visited Rietveld Schröderhuis with its amazing architectural design and had a lovely long walk through Utrecht.
I did have a few people ask me throughout the week how many of these conferences that I’ve been to (probably because they were too polite to ask WHY I’m here), and I just did a count of seven: 2008 in Milan, 2009 in Ulm, 2010 in Hoboken, 2011 in Clermont-Ferrand (where I gave a keynote in the industry track), 2012 in Tallinn, then a long break until 2019 in Vienna, then this year in Utrecht.
I moved to the BPM Forum session for another rapid-fire succession of 15-minute presentations, a similar format to yesterday’s Journal First session. No detailed notes in such short presentations but I captured a few photos as things progressed. So many great research ideas!
Conversational Process Modelling: State of the Art, Applications, and Implications in Practice (Nataliia Klievtsova, Janik-Vasily Benzin, Timotheus Kampik, Juergen Mangler and Stefanie Rinderle-Ma), presented by Nataliia Klievtsova.
Large Language Models for Business Process Management: Opportunities and Challenges (Maxim Vidgof, Stefan Bachhofner and Jan Mendling), presented by Maxim Vidgof.
Towards a Theory on Process Automation Effects (Hoang Vu, Jennifer Haase, Henrik Leopold and Jan Mendling), presented by Hoang Vu.
Process Mining and the Transformation of Management Accounting: A Maturity Model for a Holistic Process Performance Measurement System, presented by Simon Wahrstoetter.
Business Process Management Maturity and Process Performance – A Longitudinal Study (Arjen Maris, Guido Ongena and Pascal Ravesteijn), presented by Arjen Maris.
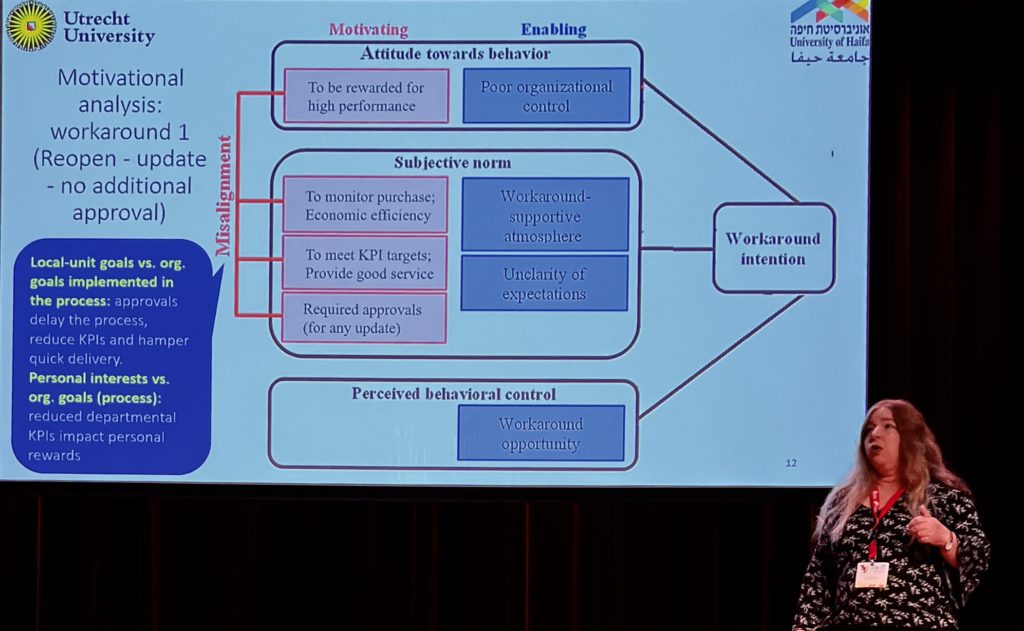
From Automatic Workaround Detection to Process Improvement: A Case Study (Nesi Outmazgin, Wouter van der Waal, Iris Beerepoot, Irit Hadar, Inge van de Weerd and Pnina Soffer), presented by Pnina Soffer.
Detecting Weasels at Work: A Theory-driven Behavioural Process Mining Approach (Michael Leyer, Arthur H. M. ter Hofstede and Rehan Syed), presented by Michael Leyer.
It’s the last day of the main BPM2023 conference in Utrecht; tomorrow is the Industry Day where I will be speaking on a panel (although I would really like to talk to next year’s organizers about having a concurrent industry track rather than a separate day after many of the researchers and academics have departed). This morning, I attended the keynote by Matthias Weidlich of Humboldt-Universität zu Berlin on database systems and BPM.
He covered some of the history of database systems and process software, then the last 20 years of iBPMS where workflow software was expanded to include many other integrated technologies. At some point, some researchers and industry practitioners started to realize that data and process are really two sides of the same coin: you can’t do process analytics or mining without a deep understanding of the data, for example, nor can you execute decisions without processes without data. Processes have both metadata (e.g., state) and business data (process instance payload), and also link to other sources of data during execution. This data is particularly important as processes become more complex, where there may be multiple interacting processes within a single transaction.
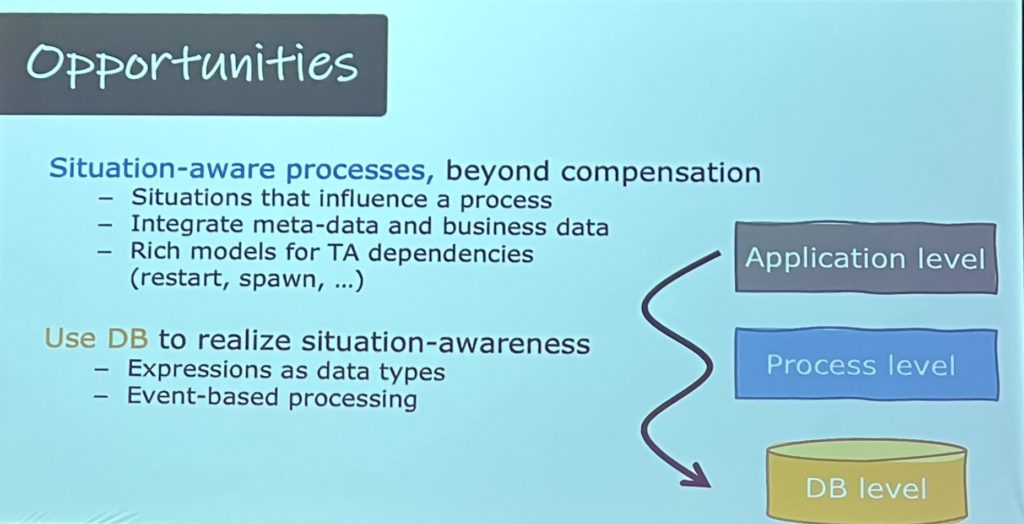
He highlighted some of the opportunities for a tighter integration of process and data during execution, including the potential to use a database for event-based processing rather than the equivalent functionality within a process management system. One interesting development is the creation of query languages specifically for processes, both for mining and execution. Examining how existing query models can be used may allow some of the query work to be pushed down to a database system that is optimized for that functionality.
He finished by stating that data is everywhere in process management, and we should embrace database technology in process analysis and implementation. I’m of two minds about this: we don’t want to be spending a lot of time making one type of system perform an activity that is easier/better done in a different type, but we also don’t want to go down the rathole of just building our own process management system in a database engine. And yes, I’ve seen this done in practice, and it is always a terrible mistake. However, using a database to recognize and trigger events that are then managed in a process management system, or using a standardized query engine for process queries fall into the sweet spot of using both types of systems for what they do best in an integrated fashion.
Lots to think about, and good opportunities to see how database and process researchers and practitioners can work together towards “best of both worlds” solutions.
In the last session of the day, I attended another part of the RPA Forum, with two presentations.
The first presentation was “Is RPA Causing Process Knowledge Loss? Insights from RPA Experts” (Ishadi Mirispelakotuwa, Rehan Syed, Moe T. Wynn), presented by Moe Wynn. RPA has a lot of measurable benefits – efficiency, compliance, quality – but what about the “dark side” of RPA? Can it make organizations lose knowledge and control over their processes because people have been taken out of the loop? RPA is often quite brittle, and when (not if) it stops working, it’s possible that organizational amnesia has set in: no one remembers how the process works well enough to do it manually. The resulting process knowledge loss (PKL) can have a number of negative organizational impacts.
The study created a conceptual model for RPA-related PKL, and she walked us through the sets of human, organizational and process factors that may contribute. In layman’s terms, use it or lose it.
In my opinion, this is different from back-end or more technical automation (e.g., deploying a BPMS or creating APIs into enterprise system functionality) in that back-end automation is usually fully specified, rigorously coded and tested, and maintained as a part of the organization’s enterprise systems. Conversely, RPA is often created by the business areas directly and can be inherently brittle due to changes in the systems with which it interfaces. If an automated process goes down, there are likely service level agreements in place and IT steps in to get the system back online. If an RPA bot goes down, a person is expected to do the tasks manually that had been done by the bot, and there is less likely to be a robust SLA for getting the bot fixed and back online. Interesting discussion around this in the Q&A, although not part of the area of study for the paper as presented.
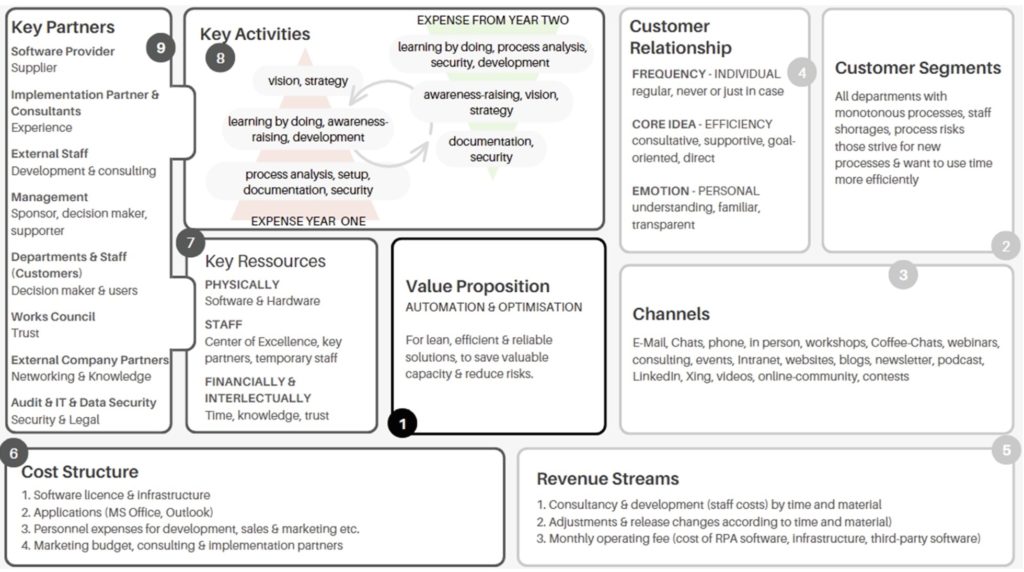
The second presentation was “A Business Model of Robotic Process Automation” (Helbig & Braun), presented by Eva Katarina Helbig of BurdaSolutions, an internal IT service provider for an international media group. Their work was based on a case study within their own organization, looking at establishing RPA as a driver of digitization and automation within a company based on an iterative, holistic view of business models with the Business Model Canvas as analysis tool.
They interviewed several people across the organization, mostly in operational areas, to develop a more structured model for how to approach, develop and deploy RPA projects, starting with the value proposition and expanding out to identify the customers, resources and key activities.
That’s it for day two of the main BPM2023 conference, and we’re off later to the Spoorwegmuseum for the conference dinner and a tour of the railway museum.
After the keynote, I attended the Journal First session, which was a collection of eight 15-minute presentations of papers that have been accepted by relevant journals (in contrast to the regular research papers seen in other presentations). It was like the speed-dating of presentations and I didn’t take any specific notes, but did snap a few photos and linked to the papers where I could find them. Lots of interesting ideas, in small snippets.
The second day of the main conference kicked off with a keynote by Marta Kwiatkowska, Professor of Computer Science at Oxford, on AI and machine learning in BPM. She started with some background on AI and deep learning, and linked this to automated process model discovery (process mining), simulation, what-if analysis, predictions and automated decisions. She posed the question of whether we should be worried about the safety of AI decisions, or at least advance the formal methods for provable guarantees in machine learning, and the more challenging topic of formal verification for neural networks.
She has done significant research on robustness for neural networks and the development of provable guarantees, and offered some recent directions of these applications in BPM. She showed the basics of calculating and applying robustness guarantees for image and video classification, and also for text classification/replacement. In the BPM world, she discussed using language-type prediction models for event logs, evaluating the robustness of decision functions to causal interventions, and the concept of reinforcement learning for teaching agents how to choose an action.
As expected, much of the application of AI to process execution is to the decisions within processes – automating decisions, or providing “next best action” recommendations to human actors at a particular process activity. Safety assurances and accountability/explainability are particularly important in these scenarios.
Given the popularity of AI in general, a very timely look at how it can be applied to BPM in ways that maintain robustness and correctness.