In the afternoon breakouts, I attended the RPA (robotic process automation) forum for three presentations.
The first presentation was “What Are You Gazing At? An Approach to Use Eye-tracking for Robotic Process Automation”, presented by Antonio Martínez-Rojas. RPA typically includes a training agent that captures what and where a human operator is typing based on UI logs, and uses that to create the script of actions that should be executed when that task is automated using the RPA “bot” without the person being involved – a type of process mining but based on UI event logs. In this presentation, we heard about using eye tracking — what the person is looking at and focusing on — during the training phase to understand where they are looking for information. This is especially interesting in less structured environments such as reading a letter or email, where the information may be buried in non-relevant text, and it’s difficult to filter out the relevant information. Unlike the UI event log methods, this can find what the user is focusing on while they are working, which may not be the same things in the screen that they are clicking on – an important distinction.
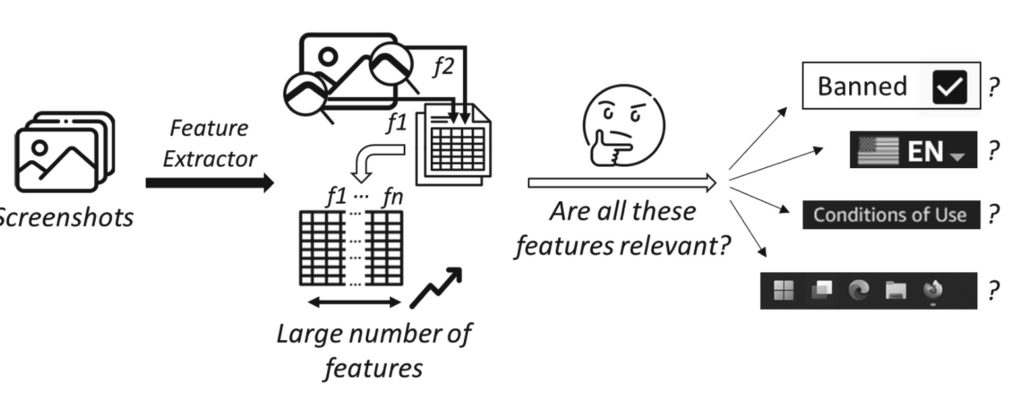
The second presentation was “Accelerating The Support of Conversational Interfaces For RPAs Through APIs”, presented by Yara Rizk. She presented the problem that many business people could be better supported through easier access to all types of APIs, including unattended RPA bots, and proposed a chatbot interface to APIs. This can be extracted by automatically interrogating the OpenAPI specifications, with some optional addition of phrases from people, to create natural language sentences: what is the intent of the action based on the API endpoint name and description plus sample sentences provided by the people. Then, the sentences are analyzed and filtered, and typically also with some involvement from human experts, and used to train the intent recognition models required to drive a chatbot interface.
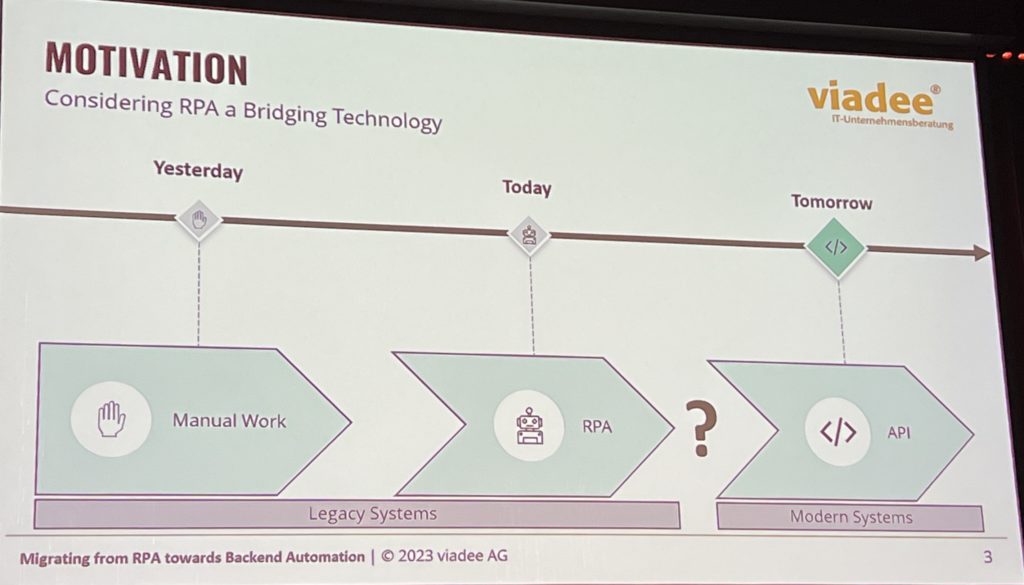
The last presentation in this session was “Migrating from RPA to Backend Automation: An Exploratory Study”, presented by Andre Strothmann. He discussed how RPA robots need to be designed and prioritized so that they can be easily replaceable, with the goal to move to back-end automation as soon as it is available. I’ve written and presented many times about how RPA is a bridging technology, and most of it will go away in the 5-10 year horizon, so I’m pretty happy to see this presented in a more rigorous way than my usual hand-waving. He discussed the analysis of their interview data that resulted in some fundamental design requirements for RPA bots, design guidelines for the processes that orchestrate those bots, and migration considerations when moving from RPA bots to APIs. If you’re developing RPA bots now and understand that they are only a stopgap solution, you should be following this research.