Usually I live-blog sessions at conferences, publishing my notes at the end of each, but here at OpenText Enterprise World 2017, I realized that I haven’t taken a look at OpenText Process Suite (formerly Cordys, from the 2013 acquisition) for a while, and needed to chew over a couple of sessions to get the whole picture. There’s some significant repositioning happening with Process Suite becoming rebranded as part of their low-code development environment AppWorks, or possibly it’s better to say that Process Suite is becoming the AppWorks developer platform: something that follows naturally from the Cordys history.
Cordys has been on my radar since 2006 when I linked to a post that Bruce Silver wrote about them, then a couple of months later I had a chance to get a more in-depth briefing. At that time, I commented on how they had a pretty complete process application development environment for creating what we were still calling mashups; now this just falls under low-code app dev. By 2008, Forrester had them classified as integration-centric BPM, although many saw that their strong human-centric capabilities defied this categorization. I had another look at Cordys in 2010 at a conference in Oslo, at which time it was positioned as a SaaS-only offering that was tightly integrated with the Google Apps Marketplace; this was possibly due to the injection of the Process Factory DNA when Jon Pyke (formerly of Staffware) joined Cordys after his time starting up Process Factory. By 2013, when OpenText acquired Cordys, it was positioned as a cloud-based platform for creating process-centric applications, although at the time I raised the issue (as did others) of having multiple competing BPM platforms within OpenText. It appears that OpenText would really like their customers to move off the old Metastorm and Global 360 implementations and onto Process Suite, but like most large enterprise vendors with a broad portfolio, they are not sunsetting any of these other products, just not spending a lot of time enhancing them.
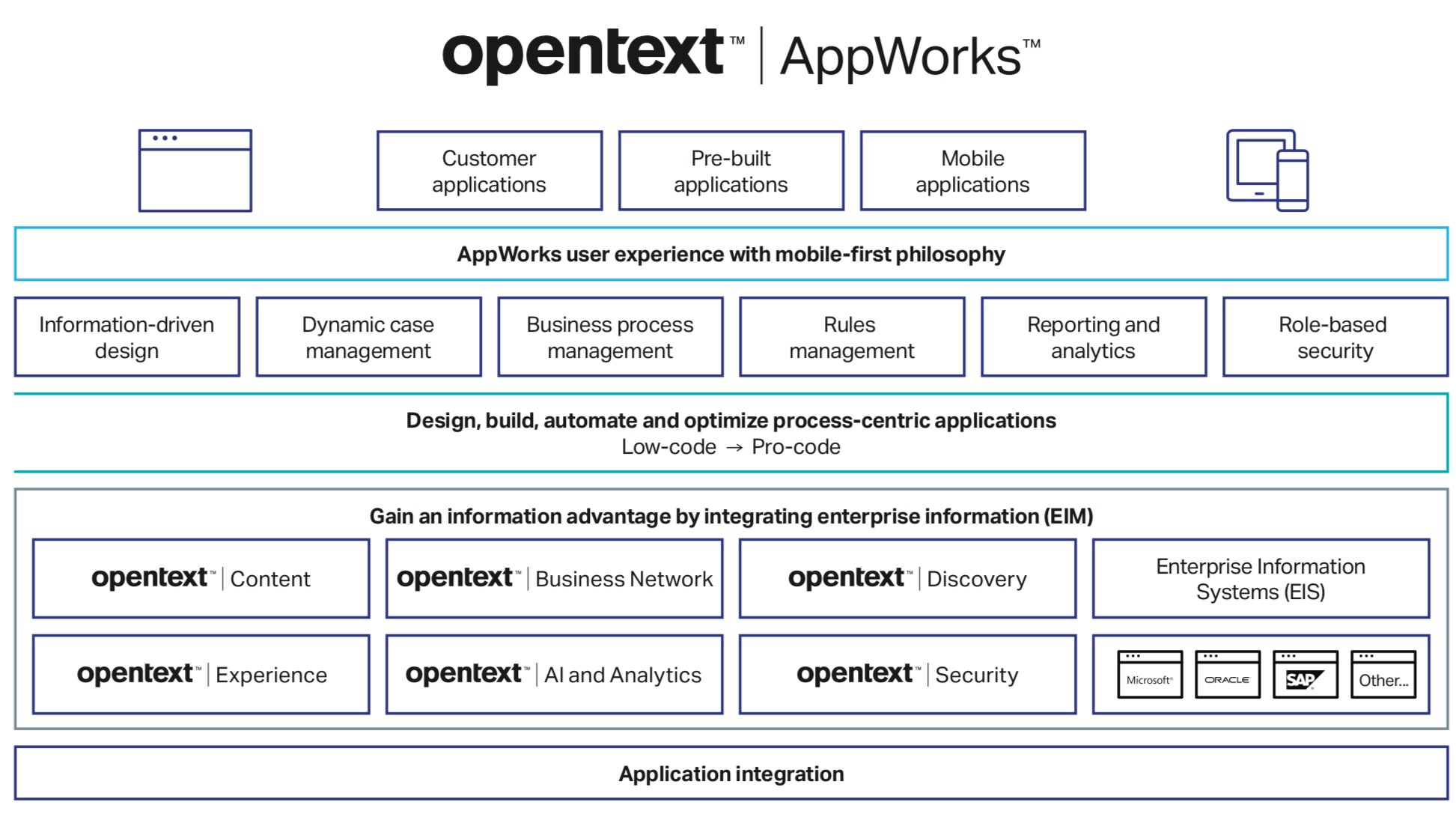
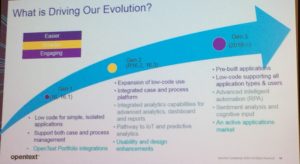 OpenText is now using the term Process Automation rather than BPM, with the message shifting to process innovation as part of digital transformation. Process automation needs to be easier (low/no-code, templates, reusability, pre-built apps), smarter (data-driven, IoT, social, sentiment, RPA, AI) and engaging (integrate as part of ecosystem, focus on customer experience). And, as I mentioned earlier, they are repositioning BPM as just part of the larger low-code application development platform, a move that we’ve been seeing from most other BPM vendors over the past few years. This is a move seen as essential for citizen developers and long-tail applications, but is often the bane of more technical developers who want to just write code that can call BPM functionality, not have a monolithic and opaque proprietary development environment. OpenText is providing both options, allowing citizen developers to use low-code methods, while technical developers can use more traditional coding techniques as required.
OpenText is now using the term Process Automation rather than BPM, with the message shifting to process innovation as part of digital transformation. Process automation needs to be easier (low/no-code, templates, reusability, pre-built apps), smarter (data-driven, IoT, social, sentiment, RPA, AI) and engaging (integrate as part of ecosystem, focus on customer experience). And, as I mentioned earlier, they are repositioning BPM as just part of the larger low-code application development platform, a move that we’ve been seeing from most other BPM vendors over the past few years. This is a move seen as essential for citizen developers and long-tail applications, but is often the bane of more technical developers who want to just write code that can call BPM functionality, not have a monolithic and opaque proprietary development environment. OpenText is providing both options, allowing citizen developers to use low-code methods, while technical developers can use more traditional coding techniques as required.
This week at Enterprise Week, I had the chance to sit in on a few sessions, including the BPM roadmap, low-code application development, the process automation customer market landscape, and integrating analytics with process; I also had the chance to get a couple of excellent demos on People Center (an HR app built on Process Suite) as well as using Process Suite to create other case management applications.
 The release later in 2017 will expand the use cases of AppWorks from simple, isolated applications to more comprehensive apps that take advantage of the newly-integrated case and process platform. More advanced analytics will be integrated, with better dashboards and reports, and the foundations laid for IoT and predicitive analytics. By next year, there will be more pre-built applications (similar to People Center) and an applications marketplace, plus more intelligence such as sentiment analysis, cognitive input and RPA. They will also have rolled out support for the complete set of developer personas, from novice citizen developer to technical ninja. Content services are already integrated using Extended ECM for Process Server, the same type of connector that they used to add content to external applications such as SAP.
The release later in 2017 will expand the use cases of AppWorks from simple, isolated applications to more comprehensive apps that take advantage of the newly-integrated case and process platform. More advanced analytics will be integrated, with better dashboards and reports, and the foundations laid for IoT and predicitive analytics. By next year, there will be more pre-built applications (similar to People Center) and an applications marketplace, plus more intelligence such as sentiment analysis, cognitive input and RPA. They will also have rolled out support for the complete set of developer personas, from novice citizen developer to technical ninja. Content services are already integrated using Extended ECM for Process Server, the same type of connector that they used to add content to external applications such as SAP.
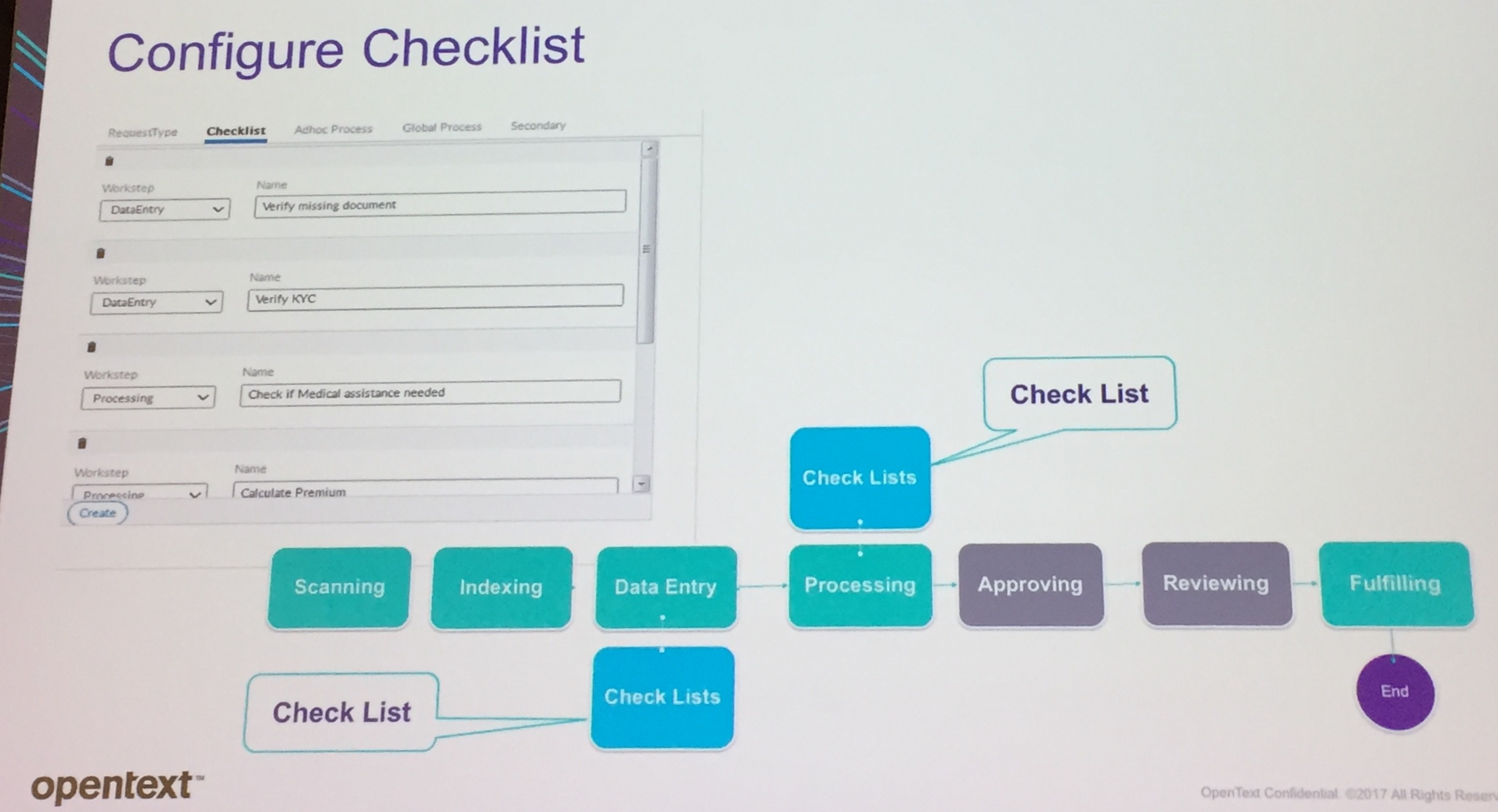
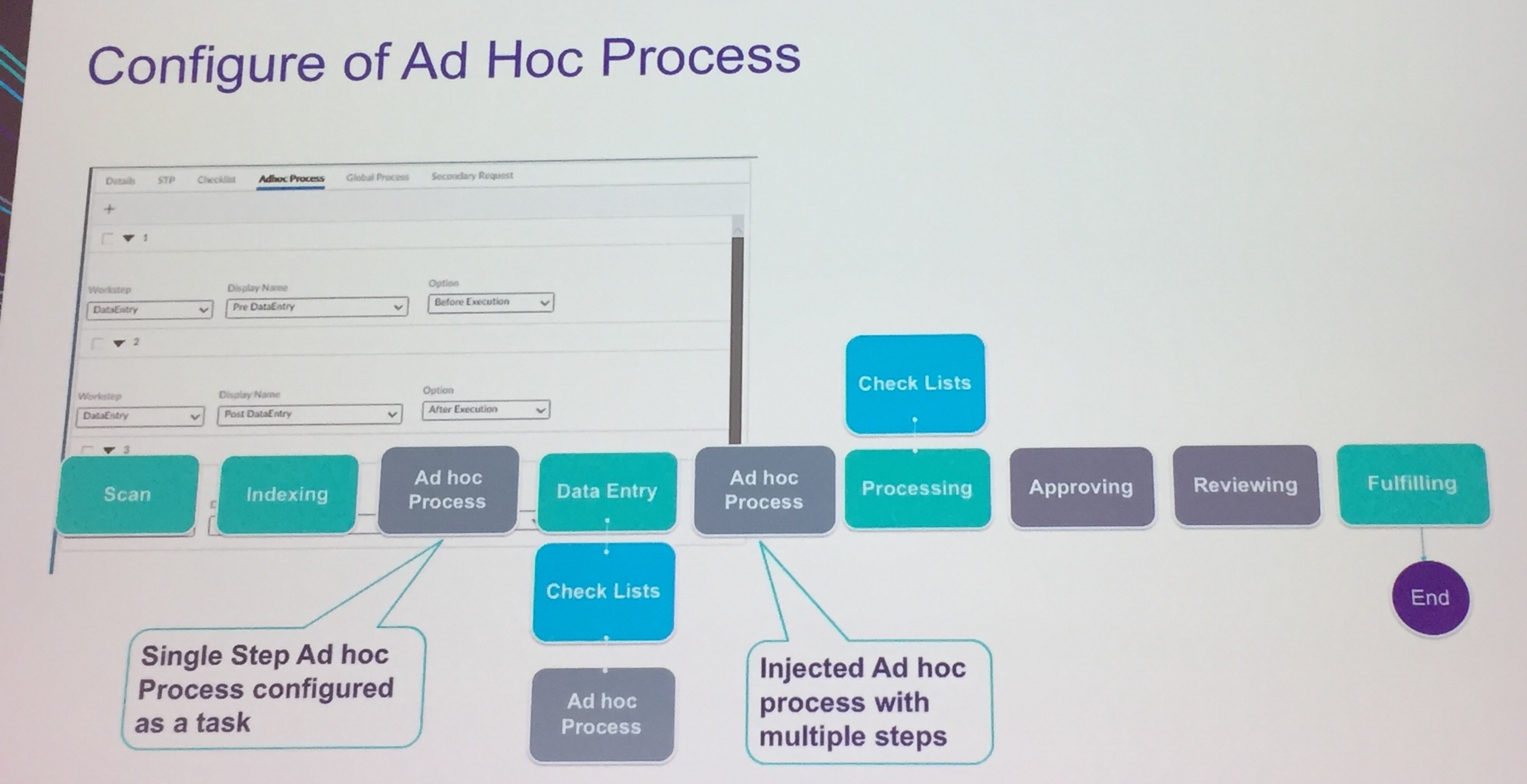
They’re working at a development style that allows for pre-built applications to be configured and extended by customers while maintaining upgradability; this is pretty critical for applications such as People Center, where you want the customers to create their own checklists and integrate to their own HRIS, but still be able to install the latest version of People Center without breaking that, and requires that guardrails be established and followed. They are also creating templates such as the current dynamic case management, which is really just sample/starter code that can be used by a partner or developer as a starting point but is not intended to be maintained by OpenText.
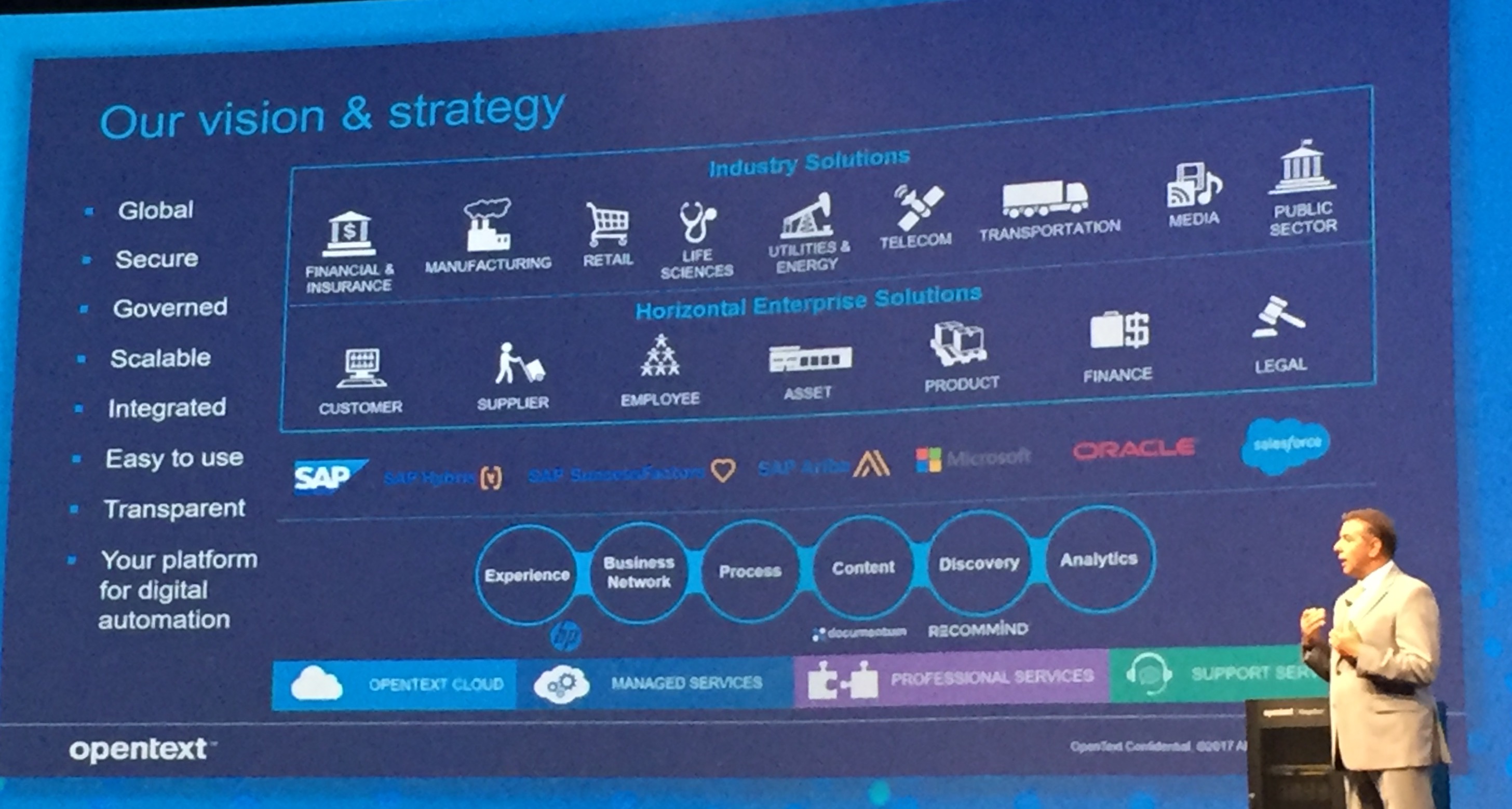
I ended Wednesday at a session on connecting analytics to process, which rounds out the capabilities. The OpenText Analytics Suite (from the Actuate acquisition, and including the new Magellan offering/branding) is separate from the Process Suite, but there are obvious connections between analytics and process in general: extracting insights from process data, and automating processes based on the results of analytics. The Analytics Suite includes business intelligence services (iHub) that provide enterprise-level analytics and visualization, with the optional addition of data discovery (Big Data Analytics) and text analysis (InfoFusion). The robust API capabilities in iHub allow analytics to be tied in directly to Process Suite or any other application; like process, analytics are ubiquitous and need to be easily integrated across other products and applications. Magellan, as we heard, is a pre-wired set of capabilities from the Analytics Suite that is focused around machine learning, combining data discovery, reporting and dashboarding, text analysis, large-scale data processing, and predictive analytics. This is built on Apache Spark, leveraging Hadoop, and is packaged and supported by OpenText.
We saw a demo of the general capabilities of the Analytics Suite — looked pretty nice, although I’m not the analytics geek in the family — then saw some examples of how process can be integrated with analytics. In one scenario, a low rating provided by a customer on a taxi app causes a customer service process to be kicked off to follow up on the problem with the customer, which is amazingly similar (although much more automated) as a Zipcar experience that I still talk about as an example of customer experience.
I’ll be back at Enterprise World for the last day tomorrow to see a few of the remaining BPM sessions. There’s still a lot that isn’t completely clear about high-level strategy for the complete portfolio of OpenText process-related products — such as how the document-centric workflow in Documentum are going to fit into the mix — but at least I feel like I’m starting to scratch the surface.