I popped down to a steamy New York today for the half-day local Camunda Day, which was a good opportunity to see an update on their customer-facing messaging and also hear from some of their customers. It was a packed agenda, starting with Robert Gimbel (Chief Revenue Officer) on best practices for successful Camunda projects. Since he’s in charge of sales, some amount of this was about why to choose the enterprise edition over the community edition, but lots of good insights for all type of customers and even applicable to other BPM products. Although he characterized the community edition for lower complexity and business criticality, I know there are Camunda customers using the open source version on mission-critical processes; however, these organizations have made a larger developer commitment to have in-house experts who can diagnose and fix problems as required.
I popped down to a steamy New York today for the half-day local Camunda Day, which was a good opportunity to see an update on their customer-facing messaging and also hear from some of their customers. It was a packed agenda, starting with Robert Gimbel (Chief Revenue Officer) on best practices for successful Camunda projects. Since he’s in charge of sales, some amount of this was about why to choose the enterprise edition over the community edition, but lots of good insights for all type of customers and even applicable to other BPM products. Although he characterized the community edition for lower complexity and business criticality, I know there are Camunda customers using the open source version on mission-critical processes; however, these organizations have made a larger developer commitment to have in-house experts who can diagnose and fix problems as required.
Gimbel outlined the four major types of projects, which are similar to those that I’ve seen with most enterprise clients:
- Automation of manual work
- Migrate processes from other systems, whether legacy BPMS, an embedded workflow within another system, or a homegrown workflow system
- Add process management to a software product that has no (or inflexible) workflows, such as an accounts payable system
- Provide a centralized workflow infrastructure as part of a digital automation platform, which is what I talked about in my bpmNEXT keynote
They are seeing a typical project timeline of 3-9 months from initiation to go-live, with the understanding that the initial deployment will continue to be analyzed and improved in an agile manner. He walked through the typical critical success factors for projects, which includes “BPMN and DMN proficiency for all participants”: something that is not universally accepted by many BPM vendors and practitioners. I happen to agree that there is a lot of benefit in everyone involved learning some subset of BPMN and DMN; it’s a matter of what that subset is and how it’s used.
We had a demo by Joe Pappas, a New York-based senior technical consultant, which walked us through using Cawemo (now free!) for collaborative modeling by the business, then importing, augmenting, deploying and managing an application that included both a BPMN and a DMN model. He showed how to detect and resolve problems in operational systems, and finished with building new reports and dashboards to display process analytics.
 The first half of the morning finished with a presentation from John Fontaine, Master Software Engineer at Capital One (a Camunda customer) on organizing a Camunda hackathon. As an aside, this is a great topic for getting a customer involved who can’t talk directly about their BPM implementation due to privacy or intellectual property concerns. They had a 2-day event with 42 developers in 6 teams, plus product and process owners/managers — the latter of which are a bit less common as hackathon participants, but everyone was expected to work collaboratively and have fun.
The first half of the morning finished with a presentation from John Fontaine, Master Software Engineer at Capital One (a Camunda customer) on organizing a Camunda hackathon. As an aside, this is a great topic for getting a customer involved who can’t talk directly about their BPM implementation due to privacy or intellectual property concerns. They had a 2-day event with 42 developers in 6 teams, plus product and process owners/managers — the latter of which are a bit less common as hackathon participants, but everyone was expected to work collaboratively and have fun.
Capital One started with a problem brief in terms of the business case and required technical elements, and a specific judging rubric for evaluating the projects. Since many of the participants were relatively new to Camunda and BPMN, they included some playful uses of BPMN such as the agenda. The first morning was spent on ideation and solution selection, with the afternoon spent creating the BPMN models and creating application wireframes. On the second day, the morning was spent on completing the coding and preparing their demo, with the afternoon for the team demos.
Fontaine finished up with lessons learned across all aspects of the hackathon, from logistics and staffing to attendee recruiting and organization, agenda pacing and milestones, judging, and resource materials such as code samples. Their goal was not to create applications ready for deployment, but a couple of the teams created applications that have become a trigger for ongoing projects.
After the break, we heard from Bernd Ruecker, co-founder of Camunda and now in the role of developer evangelist, on workflow automation in a microservices architecture. He has been writing and speaking on this topic for a while now, including some key points that run counter to many BPM vendors’ views of microservices, and even counter to some of Camunda’s previous views:
- Every workflow must be owned by one microservice, and workflow live inside service boundaries. This means no monolithic (end-to-end) BPMN models for execution, although the business likely creates higher-level non-executable models that shown an end-to-end view.
- Event-driven architecture for passing information between services in a decoupled manner, although it’s necessary to keep a vision of an overall flow to avoid unexpected emergent behaviors. This can still be accomplished with messaging, but you need to think about some degree of coupling by emitting commands rather than just events: a balance of orchestration and choreography.
- Microservices are, by their nature, distributed systems; however, there is usually a need for some amount of stateful orchestration, such as is provided by a BPM engine.
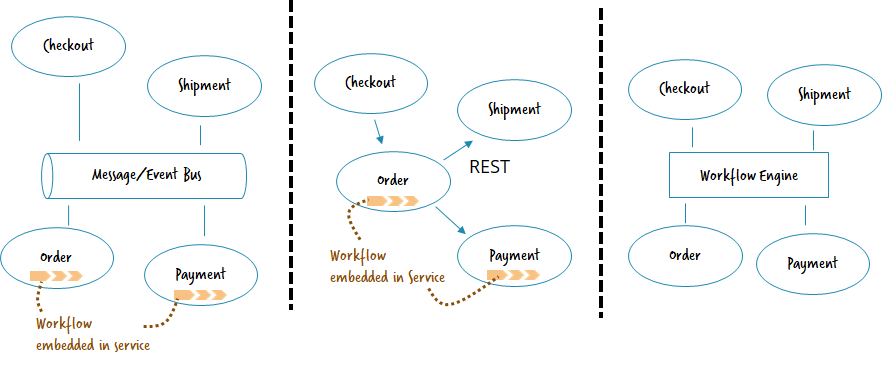
Ruecker talked about the different ways of communication — message/event bus versus REST-ish command-type events between services versus using a BPM engine as a work distributor for external services — with the note that it’s possible to do good microservices architecture with any of these methods. He notes that in the last scenario (using a BPM engine as the overall service orchestrator) is not necessarily best practice; he is looking more at the use of the engine at a lower granularity, where there is a BPM engine encapsulated in each service that requires it. Check out his blog post on microservices workflow automation for more details.
The (half) day finished with Frederic Meier, Camunda’s head of sales for North America, in conversation with Michael Kirven, VP of IT Business Solutions at People’s United Bank about their Camunda implementation in lending, insurance, wealth management and other business applications. They opened it up to the audience of mostly financial services customers to talk about their use cases, which included esoteric scenarios such as video processing (passing a video through transcoding and other services), and more mainstream examples such as a multi-account closure. This gave an opportunity for prospects and less-experienced customers to ask questions of the battle-hardened veterans who have deployed multiple Camunda applications.
Great content, and definitely worthwhile for the 40-50 people in attendance.