Lately, I’ve been thinking about cake. Not (just) because I’m headed to Vienna, home of the incomparable Sacher Torte, nor because I’ll be celebrating my birthday while attending the BPM2019 academic research conference while there. No, I’ve been thinking about technical architectural layer cake models.
In 2014, an impossibly long time ago in computer-years, I wrote a paper about what one of the analyst firms was then calling Smart Process Applications (SPA). The idea is that a vendor would provide a SPA platform, then the vendor, customer or third parties would create applications using this platform — not necessarily using low-code tooling, but at least using an integrated set of tools layered on top of the customer’s infrastructure and core business systems. Instances of these applications — the actual SPAs — could then be deployed by semi-technical analysts who just needed to configure the SPA with the specifics of the business function. The paper that I wrote was sponsored by Kofax, but many other vendors provided (and still provide) similar functionality.
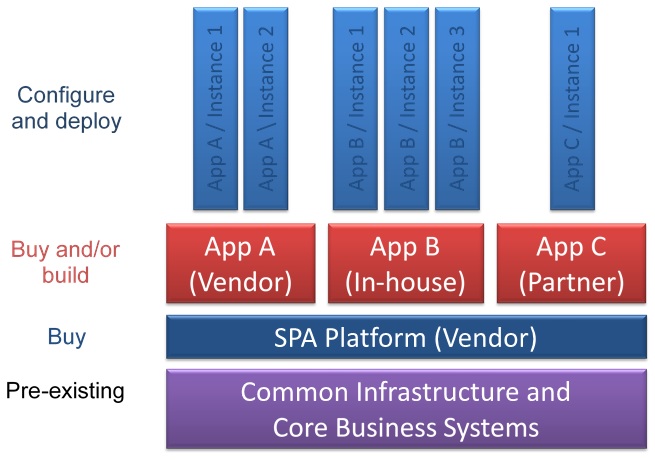
The SPA platforms included a number of integrated components to be used when creating applications: process management (BPM), content capture and management (ECM), event handling, decision management (DM), collaboration, analytics, and user experience.
The concept (or at least the name) of SPA platforms has now morphed into a “digital transformation”, “digital automation” or “digital business” platforms, but the premise is the same: you buy a monolithic platform from a vendor that sits on top of your core business systems, then you build applications on top of that to deploy to your business units. The tooling offered by the platform is now more likely to include a low-code development environment, which means that the applications built on the platform may not need a separate “configure and deploy” layer above them as in the SPA diagram here. Or this same model could be used, with non-low-code applications developed in the layer above the platform, then low-code configuration and deployment of those just as in the SPA model. Due to pressure suggestions from analysts, many BPMS platforms became these all-in-one platforms under the guise of iBPMS, but some ended up with a set of tools with uneven capabilities: great functionality for their core strengths (BPM, etc.) but weaker in functionality that they had to partner to include or hastily build in order to be included in the analyst ranking.
The monolithic vendor platform model is great for a lot of businesses that are not in the business of software development, but some very large organizations (or small software companies) want to create their own platform layer out of best-of-breed components. For example, they may want to pick BPM and DM from one vendor, ECM from multiple others, collaboration and user experience from still another, plus event handling and analytics using open source tools. In the SPA diagram above, that turns the dark blue platform layer into “Build” rather than “Buy”, although the impact is much the same for the developers who are building the applications on top of the platform. This is the core of what I’m going to be presenting at CamundaCon next month in Berlin, with some ideas on how the market divides between monolithic and best-of-breed platforms, and how to make a best-of-breed approach work (since that’s the focus of this particular audience).
And yes, there will be cake, or at least some updated technical architectural layer cake models.