Beyond Decision Models – Using Technical and Business Standards to Transform Financial Services. Brian Stucky, Quicken Loans
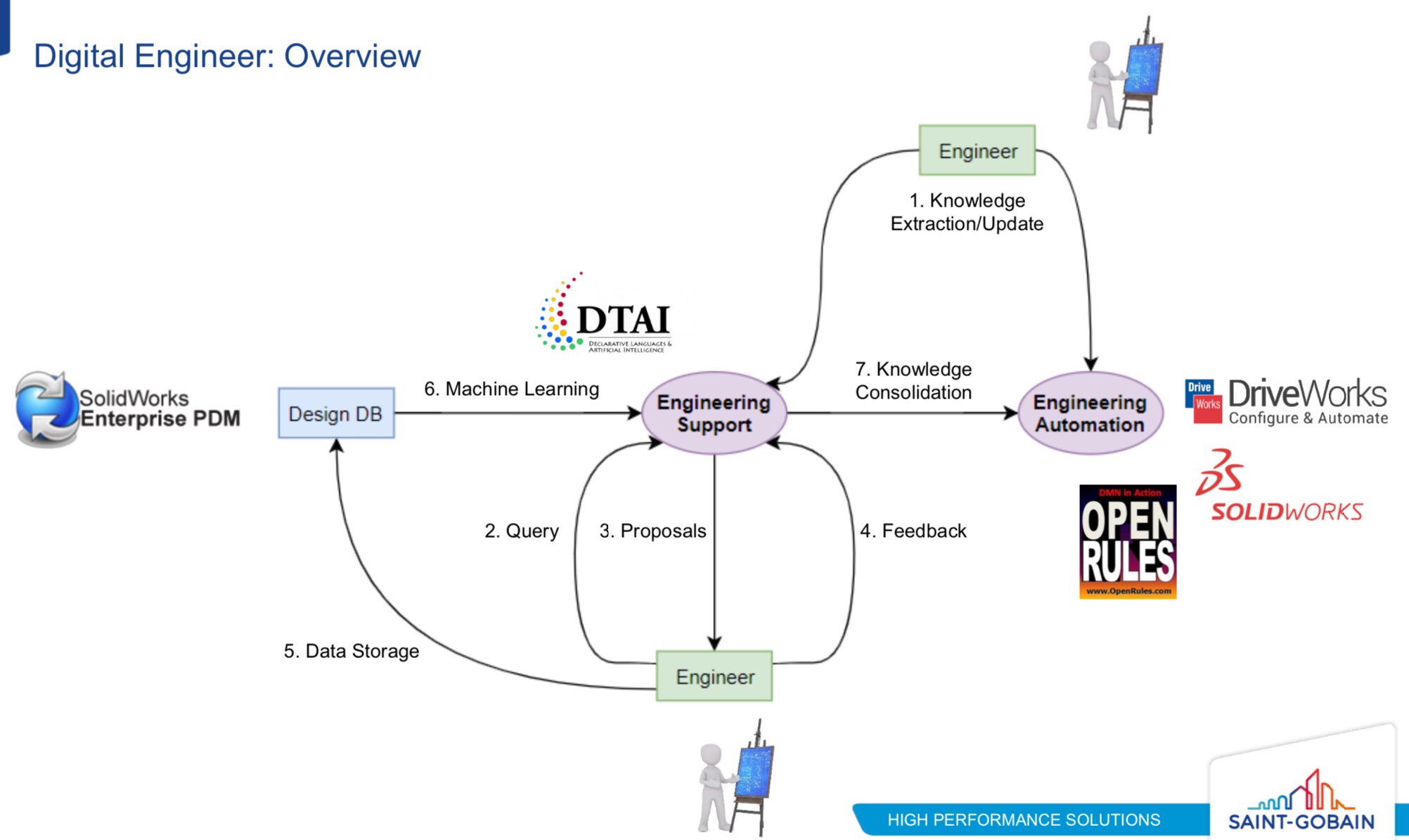
Although having recently joined Quicken Loans as a senior enterprise architect, Brian Stucky is also involved in the MISMO mortgage standards organization, which was the focus of his presentation. Earlier this year, MISMO recommended DMN as an official standard for documenting, implementing, exchanging and executing decision models in the mortgage industry; they are also working on officially recognizing BPMN too. The idea is to create a DMN data structure based on the existing MISMO XSD to allow these mortgage-related decision models to be shared, but the industry is still rife with paper-based processes and legacy systems that hinder adoption.
There’s a history of business rules in the mortgage industry, but it didn’t really allow for business control of the rules, didn’t have the agility required, and was expensive. DMN is changing that game — especially with decisions as a service instead of on-premise systems — and allowing mortgage companies to better meet some of the new regulations such as Ability-To-Repay, where the written government regulation can be translated into a standard DMN model to ensure that all parties are using the same evaluation criteria. They’ve proven that time required to change the DMN model for a specific rule can take as little as a couple of hours to analyze and modify the model, which is a huge push for moving from MISMO XSD to the DMN model.
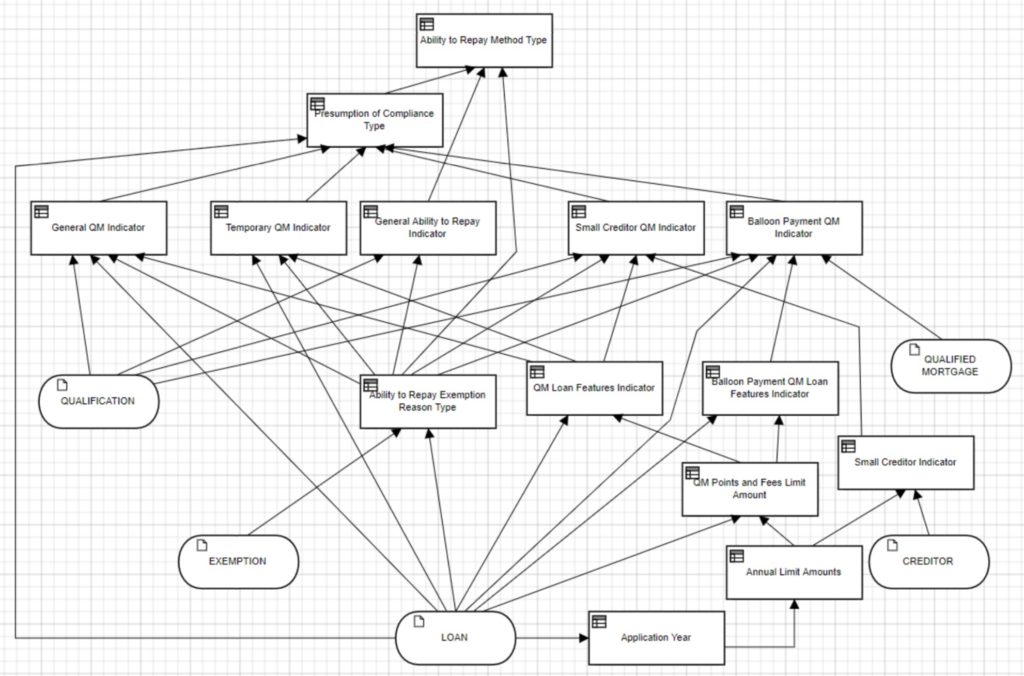
In the future, this could mean that DMN plus the MISMO data model could be used directly to disseminate a regulatory rule change, rather than the 800-page text document used now. That brings up other issues, such as versioning of the model or even of DMN, and engine compliance in executing the DMN models as distributed. A better way to do it may be to roll out the model as a service with an open API, where every mortgage provide uses the same decision service; this guarantees that it will be evaluated identically everywhere. The ultimate goal may be a digital mortgage, potentially using blockchain to ensure the chain of events in this smart contract.
Meeting the Expectations with DMN and Constraint Solving: The Notary Case. Marjolein Deryck, KU Leuven
Marjolein Deryck presented on research in decision modeling and knowledge representation, and how she applied it to property registration taxes in Belgium, which is typically calculated by a notary. The use case was to support a notary when performing these calculations, using DMN for collaborative analysis with the notary and an executable prototype; then IDP to go beyond DMN capabilities in a constraint approach.
An interesting requirement was that the support application be non-intrusive: the notary felt that if he was spending too much time typing on a computer while figuring this out with a client, he would be seen as less of an expert. A tablet-based app with minimal requirement for data entry, plus interactive in terms of presenting the next best question rather than following a fixed script were seen as essential.
In her initial evaluation, DMN was seen as lacking script interactivity/adaptability (although I saw a really interesting way to use DMN and BPMN to resolve this last week at CamundaCon), and she instead considered IDP as a more powerful implementation. This provides a better solution, although the models are less understandable by the notaries, and required enhancements to be able to provide an explanation of a specific calculation.
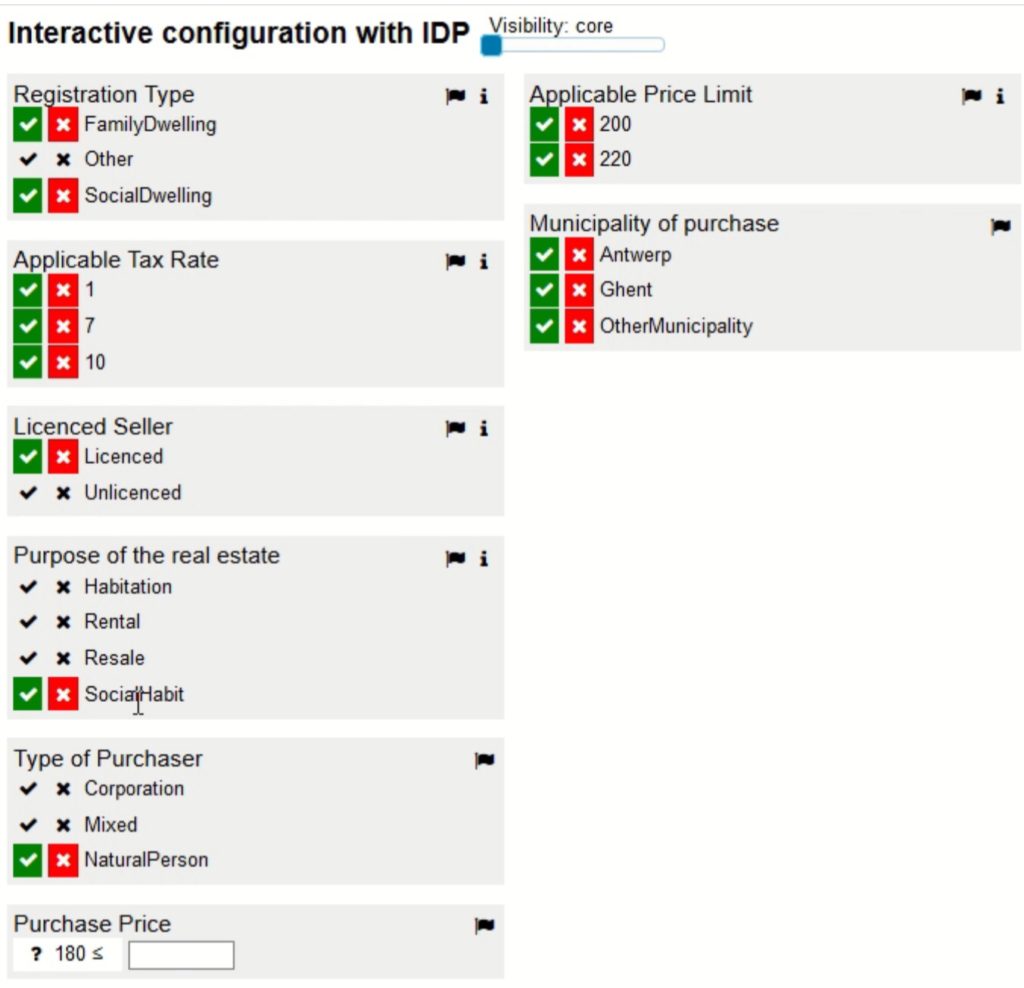
The lessons learned included the use of DMN as an intermediate model — for gathering and analyzing requirements together with the business user — as well as how to combine DMN and IDP in a project.
Panel: DMN and Beyond
We closed off day 1 of DecisionCAMP 2019 with a panel that included Mike Gualtieri, Alan Fish, Jan Vanthienen, Jan Purchase, Gary Hallmark and Brian Stucky, moderated by Jacob Feldman.
A few points that came up during the panel (unattributed to the specific speaker):
- Many buyers of decision management systems don’t known enough about DMN to evaluate it or even ask for it.
- DMN still falls short in complex representations, although works well to represent static hierarchical information from decision tables. It has the potential to include other representations and other models such as machine learning. Making it more powerful could, however, have DMN lose the simplicity that makes it more likely to be adopted.
- DMN is difficult to debug, making it hard to figure out logic flaws.
- The diagram/graph level of DMN is very understandable to business users/analysts, but by the time you’re doing more complex nested expression logic at the FEEL execution level, you’ve lost most of them.
- Highly-regulated industries such as lending, where rules are already documented in spreadsheets, are a good target for DMN implementation.
- Being able to follow the execution path is not the same as an explanation of the decision logic. The DMN standard includes support for remarks/annotations to improve explainability but that may not be sufficient.
- Knowledge sources in DMN models have no programmatic representation, putting the onus on the modeler to ensure explainability and traceability.
- Ethics are important to decision management in terms of decision fairness and consistency. DMN model-based decision making can improve that as long as the models are based on the right rules and data.
- There’s a need to be able to integrate DMN and machine learning while still providing decision explainability.
- Models are always fit for purpose: there is no all-encompassing model that is suitable for everything. As an aside, that’s definitely true in the BPMN realm too.
That’s it for day 1; I’m off to find a gelato and an Aperol Spritz on this warm evening in Bolzano.