The first day of IBM’s online conference Think 2020 kicked off with a keynote by CEO Arvind Krishna on enterprise technology for digital transformation. He’s new to the position of CEO, but has decades of history at IBM, including heading IBM Research and, most recently, the Cloud and Cognitive Computing group. He sees hybrid cloud and AI as the key technologies for enterprises to move forward, and was joined by Rajeev Ronanki, Chief Digital Officer at Anthem, a US healthcare provider, discussing what they’re doing with AI to harness data and provide better insights. Anthem is using Red Hat OpenShift containerization that allows them to manage their AI “supply chain” effectively, working with technology partners to integrate capabilities.
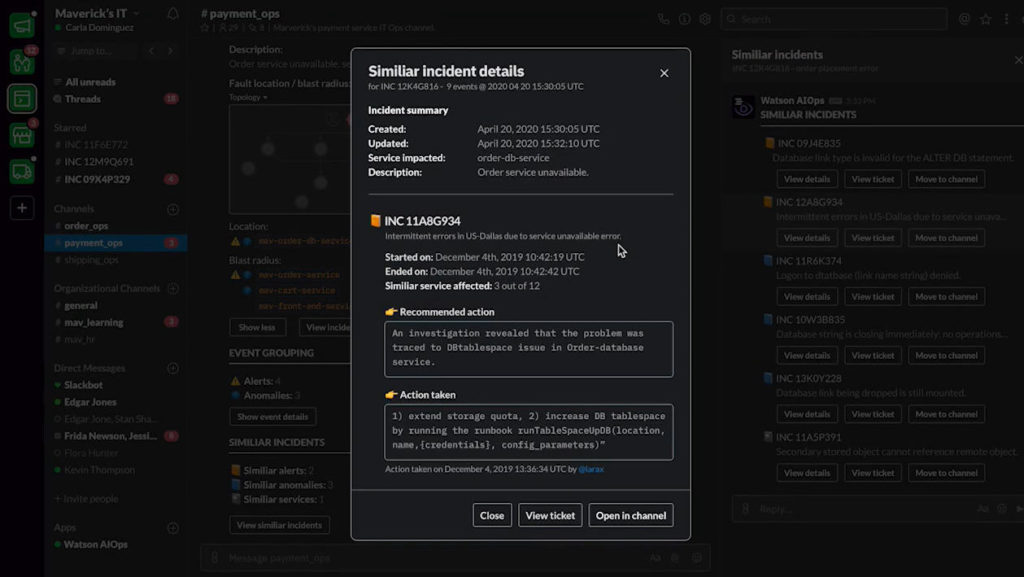
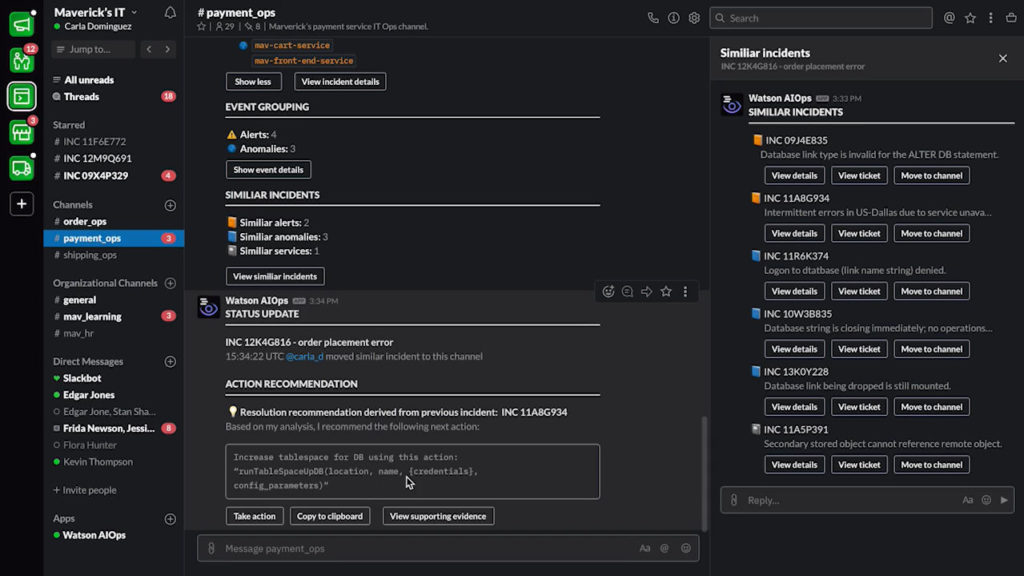
Krishna announced AIOps, which infuses Watson AI into mission-critical IT operations, providing predictions, recommendations and automation to allow IT to get ahead of problems, and resolve them quickly. We had a quick demo of this yesterday during the analyst preview, and it looks pretty interesting: integrating trouble notifications into a Slack channel, then providing recommendations on actions based on previous similar incidents:
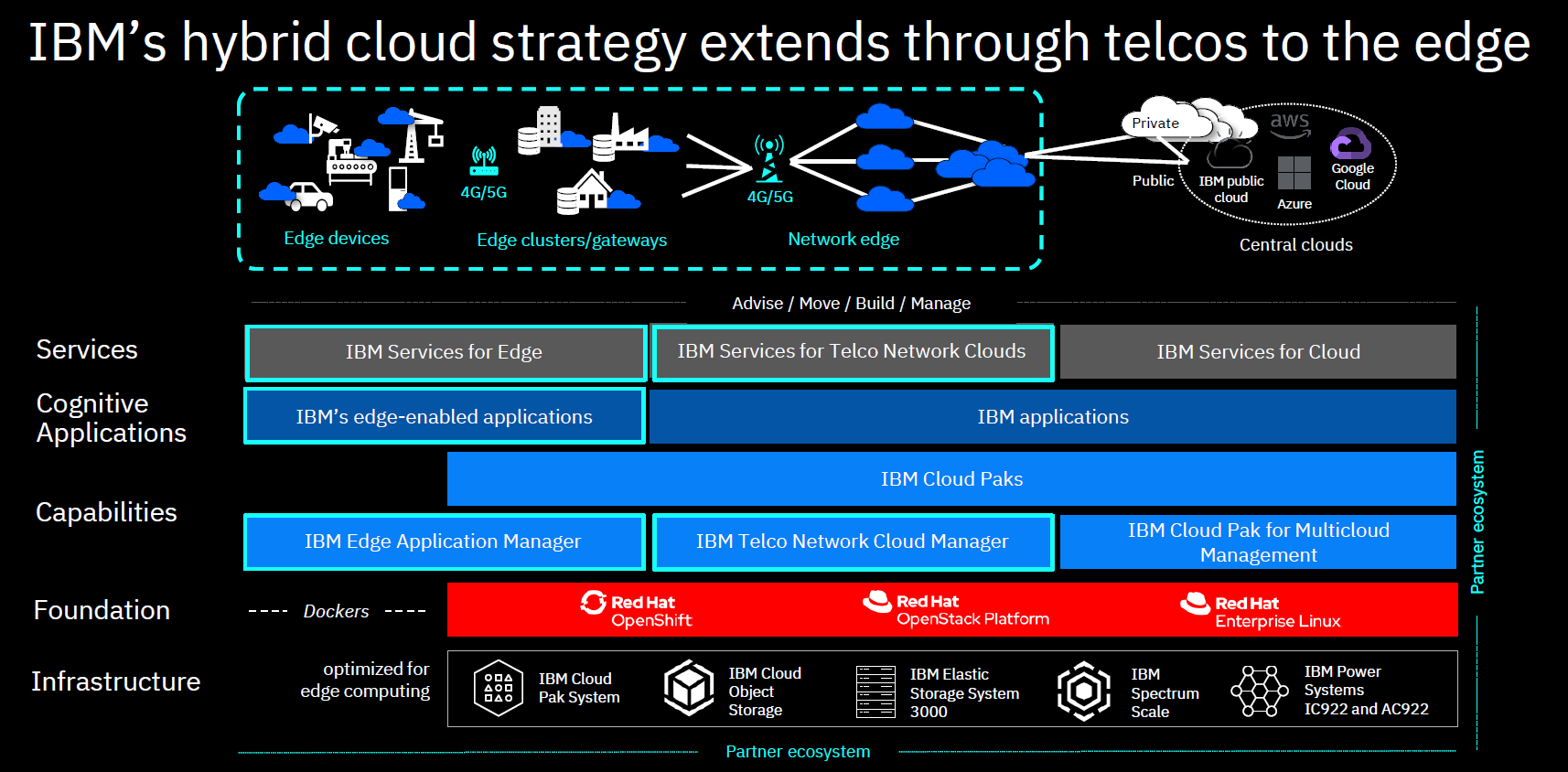
He finished up with an announcement about their new cloud satellite, and edge and telco solutions for cloud platforms. This enables development of future 5G/edge applications that will change how enterprises work internally and with their customers. As our last several weeks of work-from-home has taught us, better public cloud connectivity can make a huge difference in how well a company can continue to do business in times of disruption; in the future, we won’t require a disruption to push us to a distributed workforce.
There was a brief interview with Michelle Peluso, CMO, on how IBM has pivoted to focus on what their customers need: managing during the crisis, preparing for recovery, and enabling transformation along the way. Cloud and AI play a big part of this, with hybrid cloud providing supply chain resiliency, and AI to better adapt to changing circumstances and handle customer engagement. I completely agree with one of her key points: things are not just going back to normal after this crisis, but this is forcing a re-think of how we do business and how things work. Smart companies are accelerating their digital transformation right now, using this disruption as a trigger. I wrote a bit more about this on a guest post on the Trisotech blog recently, and included many of my comments in a webinar that I did for Signavio.
The next session was on scaling innovation at speed with hybrid cloud, featuring IBM President Jim Whitehurst, with a focus on how this can provide the level of agility and resiliency needed at any time, but especially now. Their OpenShift-based hybrid cloud platform will run across any of the major cloud providers, as well as on premise. He announced a technology preview of a cloud marketplace for Red Hat OpenShift-based applications, and had a discussion with Vishant Vora, CTO at Vodafone Idea, India’s largest telecom provider, on how they are building infrastructure for low-latency applications. The session finished up with Hillery Hunter, CTO of IBM Cloud, talking about their public cloud infrastructure: although their cloud platform will run on any vendor’s cloud infrastructure, they believe that their own cloud architecture has some advantages for mission-critical applications. She gave us a few more details about the IBM Cloud Satellite that Arvind Krishna had mentioned in his keynote: a distributed cloud that allows you to run workloads where it makes sense, with simplified and consolidated deployment and monitoring options. They have security and privacy controls built in for different industries, and currently have offerings such as a financial services-ready public cloud environment.
I tuned in briefly to an IDC analyst talking about the new CEO agenda, although targeted at IBM business partners; then a few minutes with the chat between IBM’s past CEO Ginny Rometty and will.i.am. I skipped Amal Clooney‘s talk — she’s brilliant, but there are hours of online video of other presentations that she has made that are likely very similar. If I had been in the audience at a live event, I wouldn’t have walked out of these, but they did not hold my interest enough to watch the virtual versions. Definitely virtual conferences need to be more engaging and offer more targeted content: I attend tech vendor conferences for information about their technology and how their customers are using it, not to hear philanthropic rap singers and international human rights lawyers.
The last session that I attended was on reducing operational cost and ensuring supply chain resiliency, introduced by Kareen Yusuf, General Manager of AI applications. He spoke about the importance of building intelligence into systems using AI, both for managing work in flight through end-to-end visibility, and providing insights on transactions and data. The remainder of the session was a panel hosted by Amber Armstrong, CMO of AI applications, featuring Jonathan Wright who heads up cognitive process re-engineering in supply chains for IBM Global Business Services, Jon Young of Telstra, and Joe Harvey of Southern Company. Telstra (a telecom company) and Southern Company (an energy company) have both seen supply chain disruptions due to the pandemic crisis, but have intelligent supply chain and asset management solutions in place that have allowed them to adapt quickly. IBM Maximo, a long-time asset management product, has been supercharged with IoT data and AI to help reduce downtime and increase asset utilization. This was an interesting panel, but really was just three five-minute interviews with no interaction between the panelists, and no audience questions. If you want to see an example of a much more engaging panel in a virtual conference, check out the one that I covered two weeks ago at CamundaCon Live.
The sessions ran from 11am-3pm in my time zone, with replays starting at 7pm (well, they’re all technically replays because everything was pre-recorded). That’s a much smaller number of sessions than I expected, with many IBM products not really covered, such as the automation products that I normally focus on. I even took a lengthy break in the middle when I didn’t see any sessions that interested me, so only watched about 90 minutes of content. Today was really all cloud and AI, interspersed with some IBM promotional videos, although a few of the sessions tomorrow look more promising.
As I’ve mentioned over the past few weeks of virtual conferences, I don’t like pre-recorded sessions: they just don’t have the same feel as live presentations. To IBM’s credit, they used the fact that they were all pre-recorded to add captions in five or six different languages, making the sessions (which were all presented in English) more accessible to those who speak other languages or who have hearing impairments. The platform is pretty glitchy on mobile: I was trying to watch the video on my tablet while using my computer for blogging and looking up references, but there were a number of problems with changing streams that forced me to move back to desktop video for periods of time. The single-threaded chat stream was completely unusable, with 4,500 people simultaneously typing “Hi from Tulsa” or “you are amazing” (directed to the speaker, presumably).
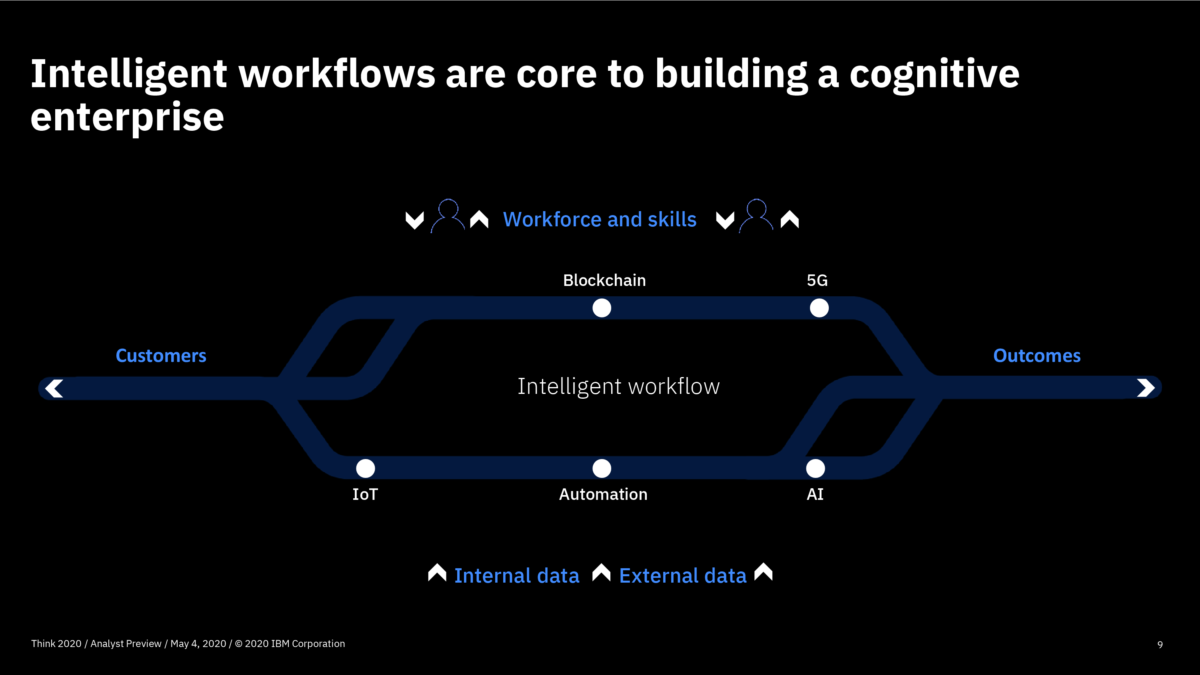
I had an early look at IBM’s virtual Think conference by attending the analyst preview today, although I will need to embargo the announcements until they are officially released at the main event tomorrow. The day kicked off with a welcome from Harriet Fryman, VP of Analyst Relations, followed by a welcome from IBM President Jim Whitehurst before the first presentation from Mark Foster, SVP of Services, on building resilient and smarter businesses. Foster led with the need for innovative and intelligent workflow automation, and a view of end-to-end processes, and how work patterns are changing and will continuing to change as we emerge from the current pandemic crisis.
Whitehurst returned to discuss their offerings in hybrid cloud environments, including both the platforms and the applications that run on those platforms. There’s no doubt that every company right now is laser-focused on the need for cloud environments, with many workforces being distributed to a work-from-home model. IBM offers Cloud Paks, containerized software solutions to get organizations up and running quickly. Red Hat OpenShift is a big part of their strategy for cloud.
Hillery Hunter, CTO and VP of Cloud Infrastructure, followed on with more details on the IBM cloud. She doubled down on their commitment to open source, and to how they have hardened open source cloud tools for enterprise readiness. If enterprises want to be flexible, scalable and resilient, they need to move their core business operations to the public cloud, and IBM hopes to provide the platform for them to do that. This should not just be lift-and-shift from on-premise systems, but this is an opportunity to modernize systems and operations. The impacts of COVID-19 have shown the cracks in many companies’ mission-critical capabilities and infrastructure, and the smart ones will already be finding ways to push towards more modern cloud platforms to allow them to weather business disruptions and gain a competitive edge in the future.
Rob Thomas, SVP of IBM Cloud and Data Platform, gave a presentation on AI and automation, and how they are changing the way that organizations work. By infusing AI into workflows, companies can outperform their competitors by 165% in terms of revenue growth and productivity, plus improve their ability to innovate and manage change. For example, in a very short time, they’ve deployed Watson Assistant to field questions about COVID-19 using information published by the CDC and other sources. Watson Anywhere combines with their Cloud Pak for Data to allow Watson AI to be applied to any of your data sources. He finished with a reminder of the “AI Ladder” which is basically a roadmap for adding operationalized AI.
The final session was with Dario Gil, Director of IBM Research. IBM has been an incredible source of computing research over 75 years, and employs 3,000 researchers in 19 locations. Some of this research is around the systems for high-performance computing, including their support for the open source Linux community. Other research is around AI, having moved from narrow AI to broader multi-domain AI, with more general AI with improved learning and autonomy in the future. They are also investing in quantum computing research, and he discussed this convergence of bits, neurons and qubits for things such as AI-assisted programming and accelerated discovery.
This was all pre-recorded presentations, which is not as compelling as live video, and there was no true discussion platform or even live Q&A; these are the two common complaints that I am having with many of the virtual conferences. I’m expecting that the next two days of the main IBM Think event will be more of the same format. I’ll be tuning in for some of the sessions of the main event, starting with CEO Arvind Krishna tomorrow morning.
I’ve been attending the online Celonis conference for the past couple of days, but taking a break for Alfresco‘s short event, Alfresco Modernize. We started with an insightful keynote from CTO John Newton on patterns of digital transformation. As we likely enter a recession triggered by the global pandemic, he pointed out that most companies fail to execute properly through a recession, and showed some Harvard Business Review research on what actually works. This includes investing in digital transformation, decentralizing decision making, and being sure to retain knowledge and experience. The responses of digital leaders to disruptions such as what we’re now seeing focus on improving business processes, modernizing infrastructure, and making it easier to connect with customers and suppliers.
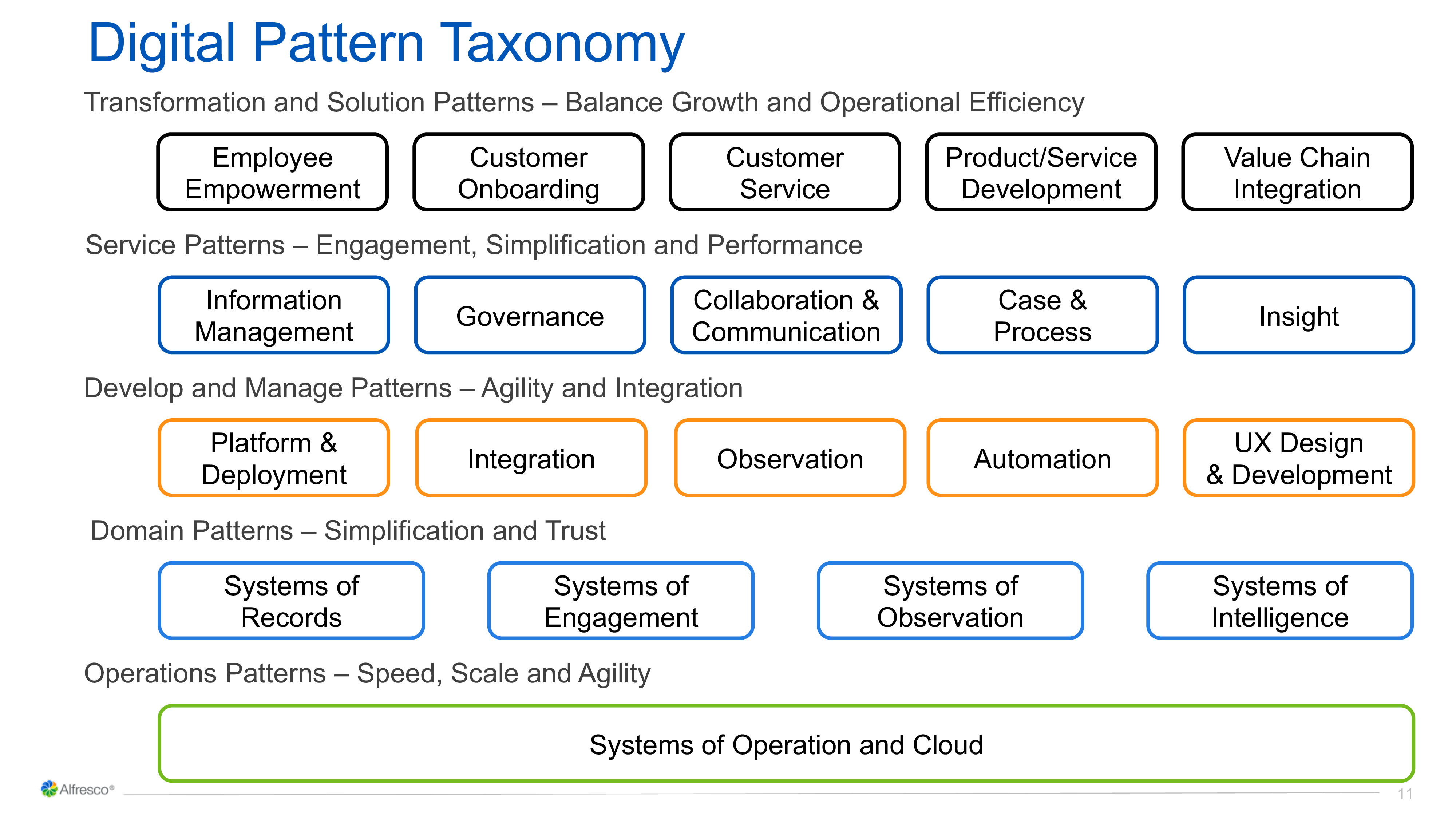
He discussed the concept of digital transformation patterns that can be derived from successful journeys, such as customer onboarding or improving manufacturing operations. He addressed the different layers of patterns shown in the chart at the left, and how they interact. We’ve used patterns in software development for a long time, and Newton shows us that it’s time to start documenting, understanding and applying digital transformation patterns. Alfresco wants to start documenting these in a very open source manner, and create solutions to address the common patterns.
Up next was a presentation by Dinesh Selvakumar, Global Head of Enterprise Content Management at Invesco, a global investment management firm. They are a relatively new Alfresco ECM customer, implementing in their own AWS instance during 2018-2019, and migrated content from other systems. They still have a lot of content silos, plus ad hoc routing and approval workflows, and have created an ECM CoE to improve standardization and governance. They want to integrate their systems to provide a unified user experience, and moved from an ECM mindset to that of Enterprise Content Services (ECS) that provides unified capabilities across the disparate platforms. They realize that there are some content and collaboration platforms that they’re never going to get rid of, but still need to have them integrated into the big picture connected by Alfresco. Eventually, enterprise content may be created in other applications, but then sent to Alfresco for enterprise-level management. They are quantifying the benefits of the move to an ECS, although some of the benefits are difficult to measure, such as decreased time searching for content. He shared some of the lessons that they learned and their key success factors, several of which are based on having a global focus and deployment.
Tony Grout, Alfresco Chief Product Officer, provided a product roadmap for their digital business platform. I found the slide on content and process interesting, in that it mentioned “processes relating to a document”: it seems like they have really trimmed off any of the pure process management messaging that they had previously, although Alfresco Process Server (Activiti) is still alive and well. Part of their core value proposition is the ability to start with open source and transition to the fully-supported (and more functional) enterprise version: this is true of any commercial open source vendor, but it’s front and center with Alfresco.
There are a number of new features on the roadmap: Federation Services (launching today) to federate different repositories, managing content in place instead of having to migrate everything to Alfresco; regulatory compliance in AWS; and the Enterprise Viewer that we saw demoed a bit later. Some of these capabilities likely came from their acquisition of Technology Services Group, a former Alfresco partner that built out a lot of value-added functionality.
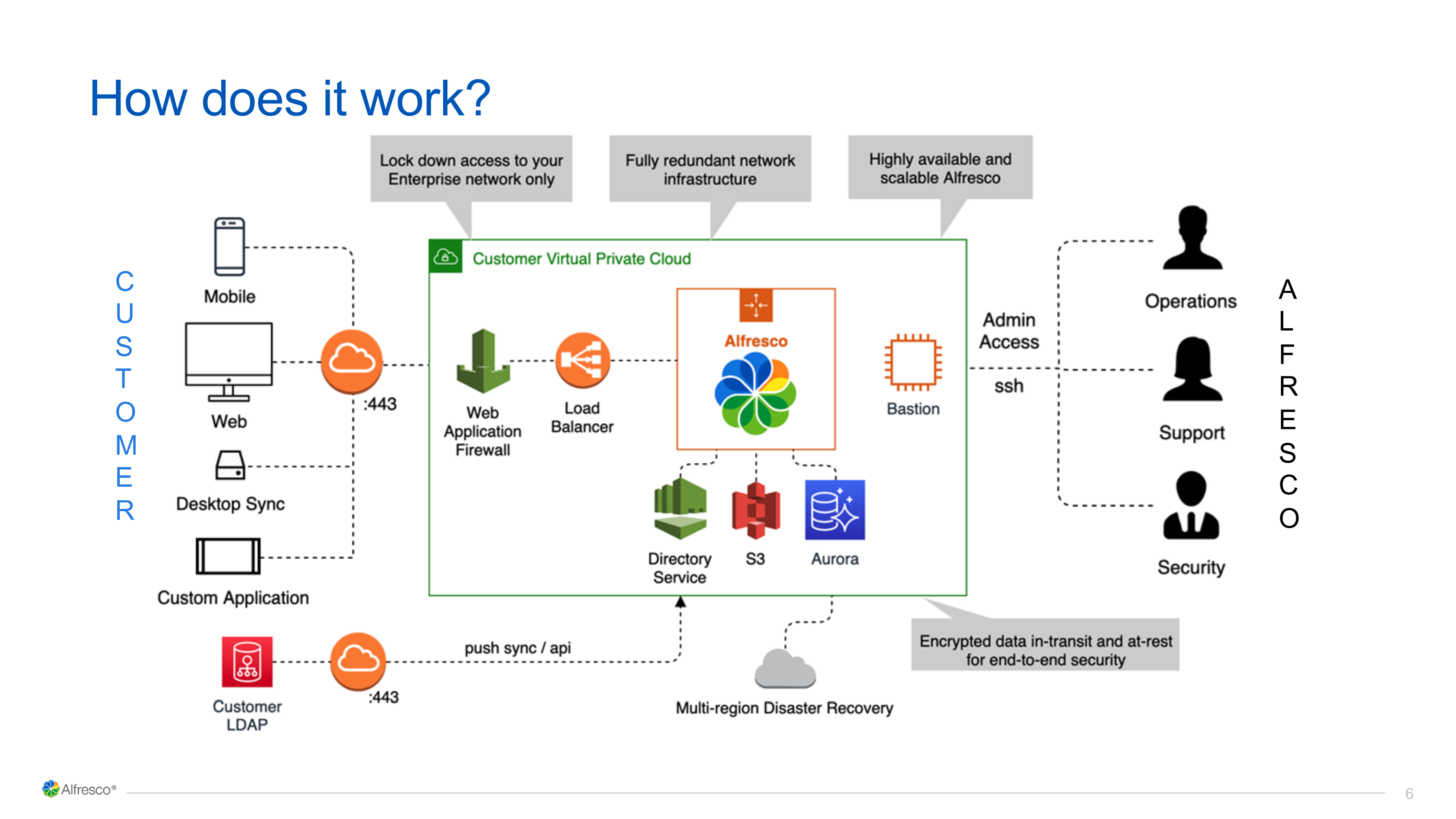
Mark Stevens, General Manager for the Alfresco Cloud, introduced how they are rolling out the Alfresco Digital Business Platform as a service, and why cloud provides such great benefits for content management: resiliency, availability, and lower costs. Their platform is cloud-native, not just a containerized version of an on-premised platform, which provides better scalability and extensibility. Removing most of the overhead from managing an ECM platform means that you have more time (and money) for more innovation and digital transformation. He walked us through their overall architecture, and what a typical implementation would look like, in terms of what’s managed by the customer and what’s managed by Alfresco. They’ve had some pretty high-profile wins over other ECM vendors, such as OpenText Documentum and IBM FileNet, with transitioned customers seeing a lot of hard benefits from Alfresco Cloud.
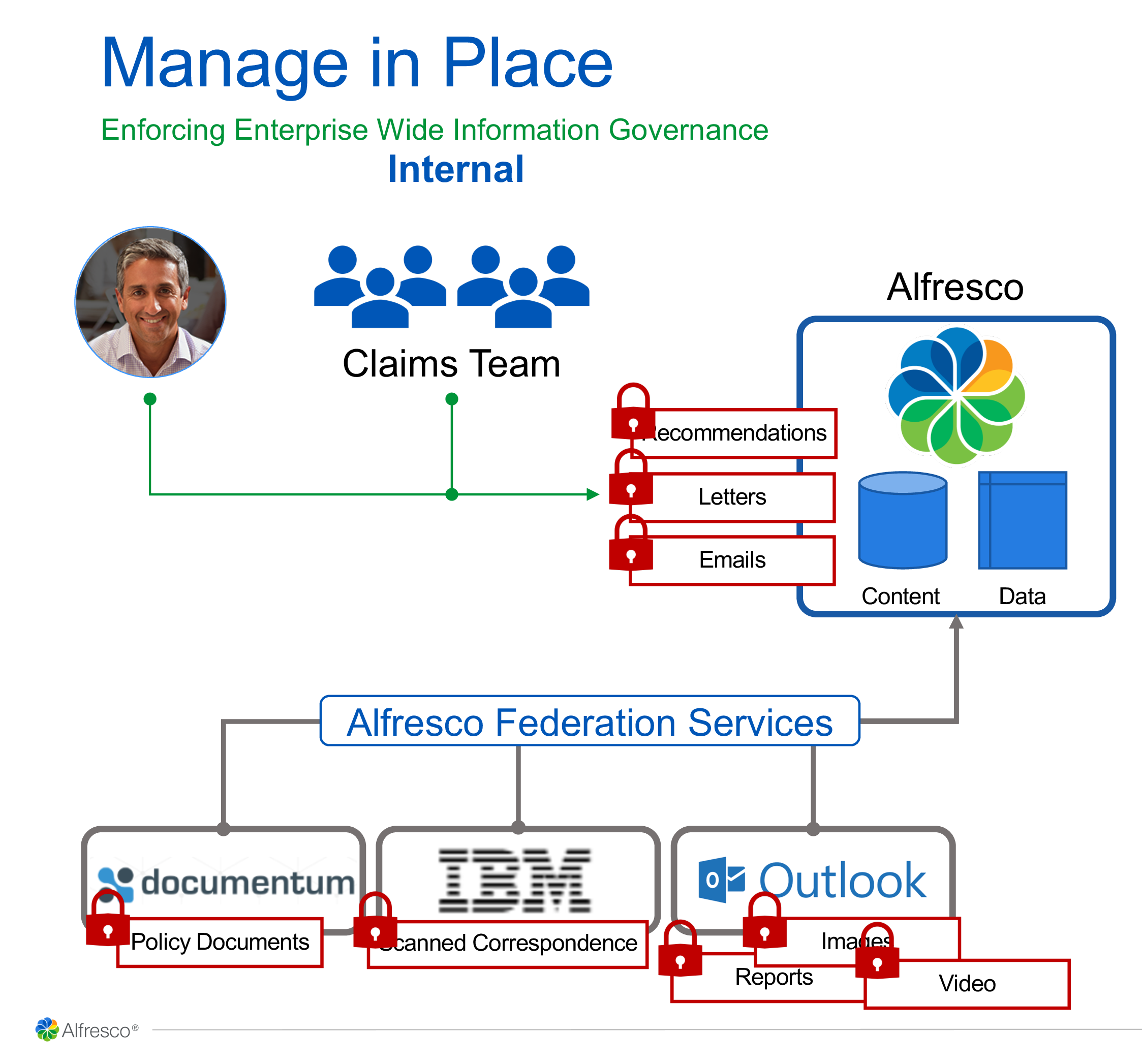
Last up in this short event were Paul Hampton, Senior Director of Product Marketing, and Ben Allen, Technical Architect, talking about the new Federation Services and Enterprise Viewer products that were announced earlier by Tony Grout. These are both pretty significant new capabilities: Federation Services allows all content repositories to be federated through Alfresco, so that users have a single user experience, and all of the sources can be managed directly by policies set in Alfresco. Content is managed in place rather than all migrated into Alfresco, although in some cases this will likely be a first step on the way to a migration.
We saw a demo of the Enterprise Viewer, which has a lot of interesting capabilities for both internal and external participants. It’s fast to browse and load large document sets, and to individual large documents since they’re caching across the network by page. Documents can be redacted for external participants, for example, removing personal information from an insurance claim when sending to an external party for a repair quote. Video can be annotated to add comments at specific points to highlight certain things in the video, with the ability to jump directly to the point of the comment. Annotations are collaborative, so that a user can reply to an existing annotation.
I didn’t stick around for the live Q&A since I wanted to get back to CelosphereLive for a session starting at the same time. Alfresco Modernize didn’t have much of a “live” feel to it: the sessions were all pre-recorded which, as I’ve mentioned in my coverage of other online conferences, just doesn’t have the same feel. Also, without a full attendee discussion capability, this was more like a broadcast of multiple webinars than an interactive event, with a short Q&A session at the end as the only point of interaction. To their credit, each speaker was in their own home, practicing social distancing; although I liked the Celonis studio environment, I did feel that it’s a bit too early to have people in the same location for an event, no matter how controlled.
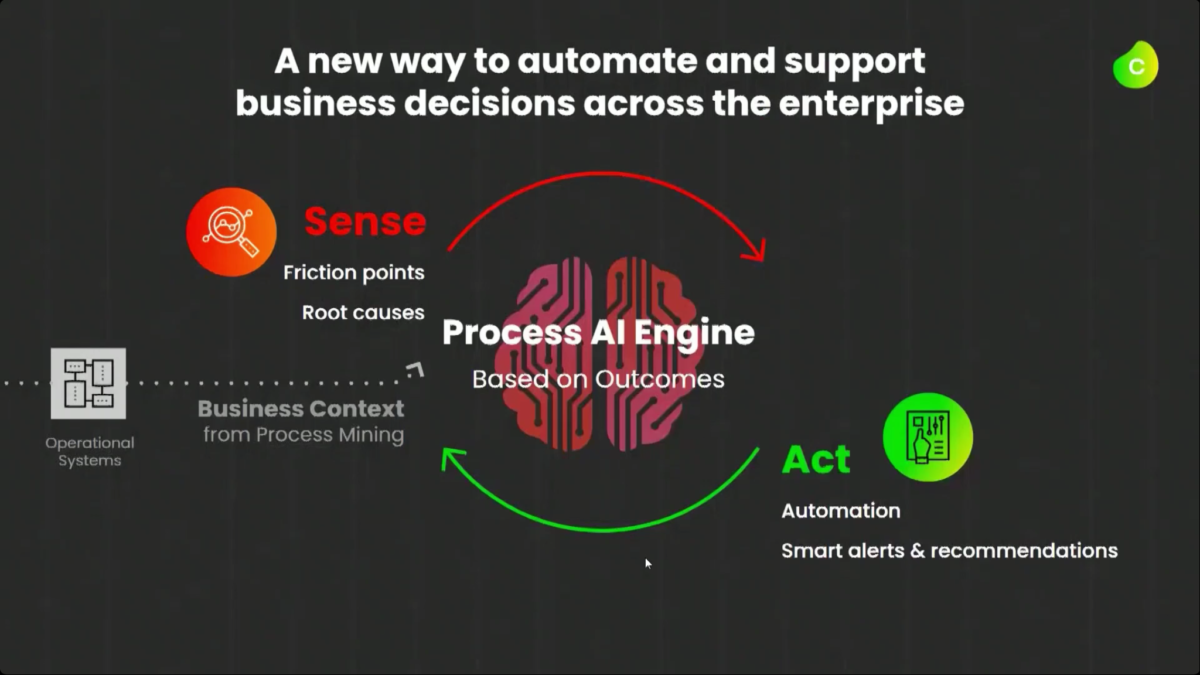
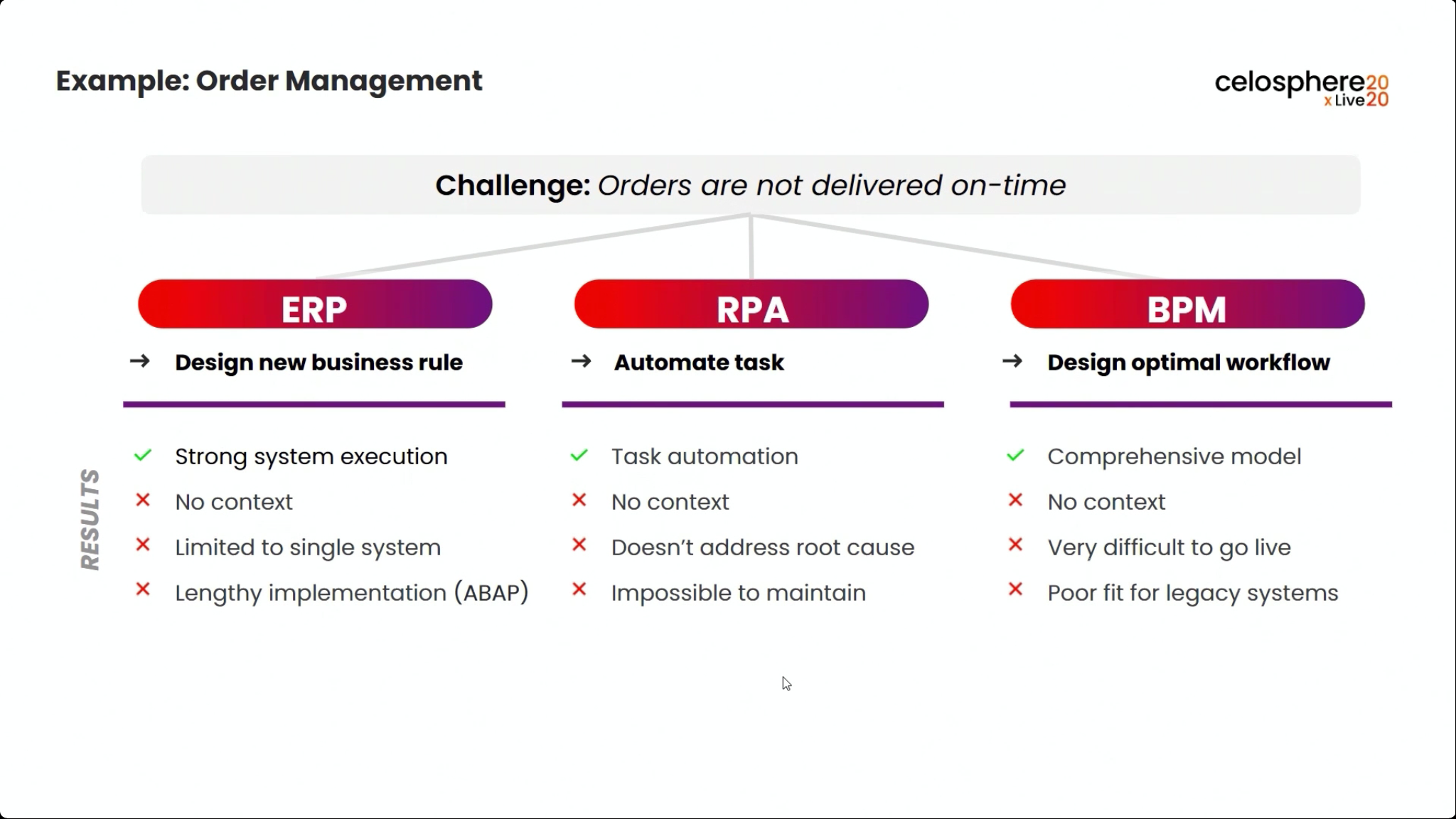
I started my day early to see Dr.Steffen Schenk, Celonis Head of Product Management, talk about the Celonis Action Engine and process automation. In short, they are seeing that because they integrate directly with core systems (especially ERP systems, that have their own processes built in), they can do things that RPA and BPM systems can’t do: namely, data-driven sense and act capabilities. However, these processes are only as timely as the data connection from the core systems into Celonis, so there can be latency.
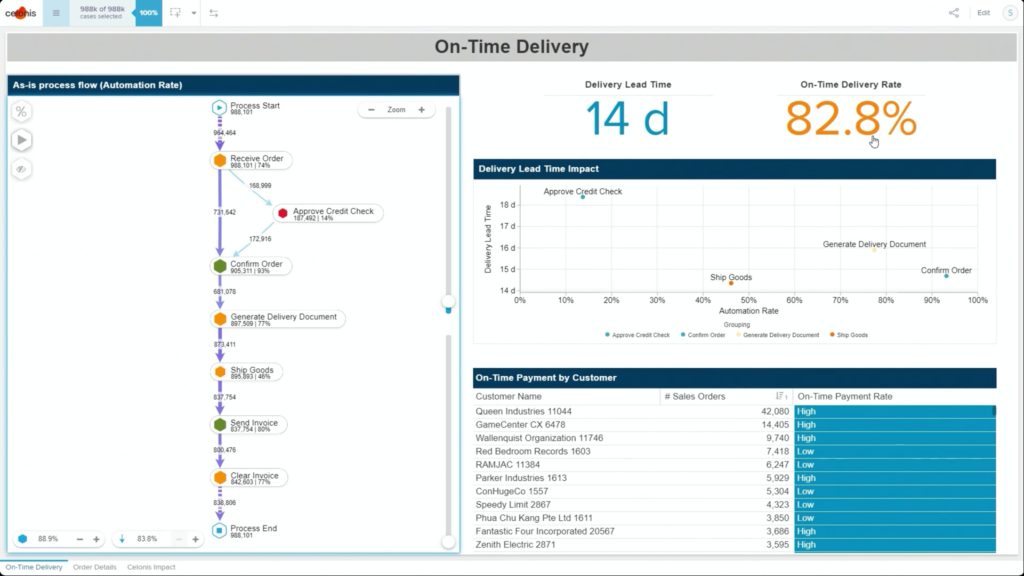
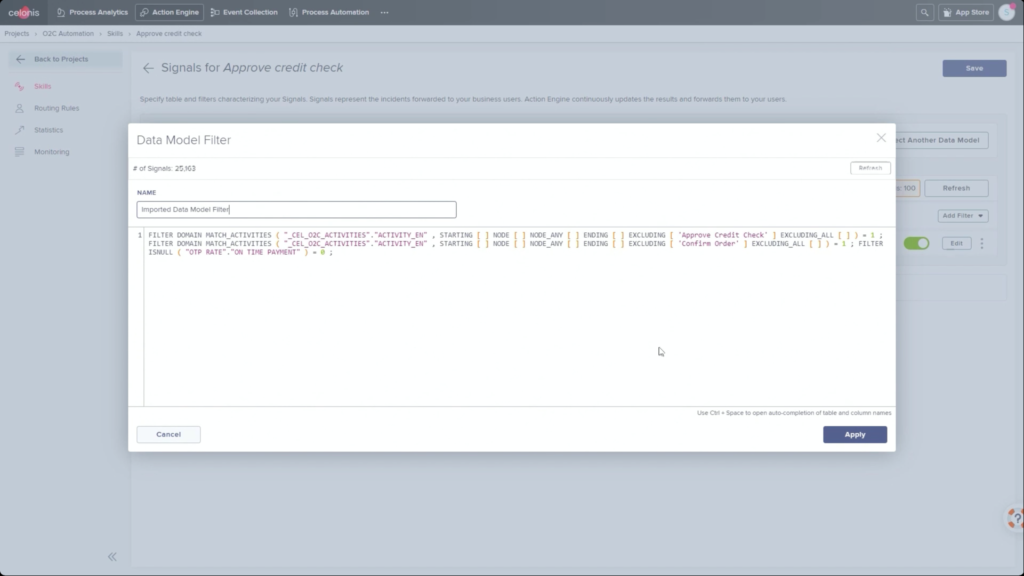
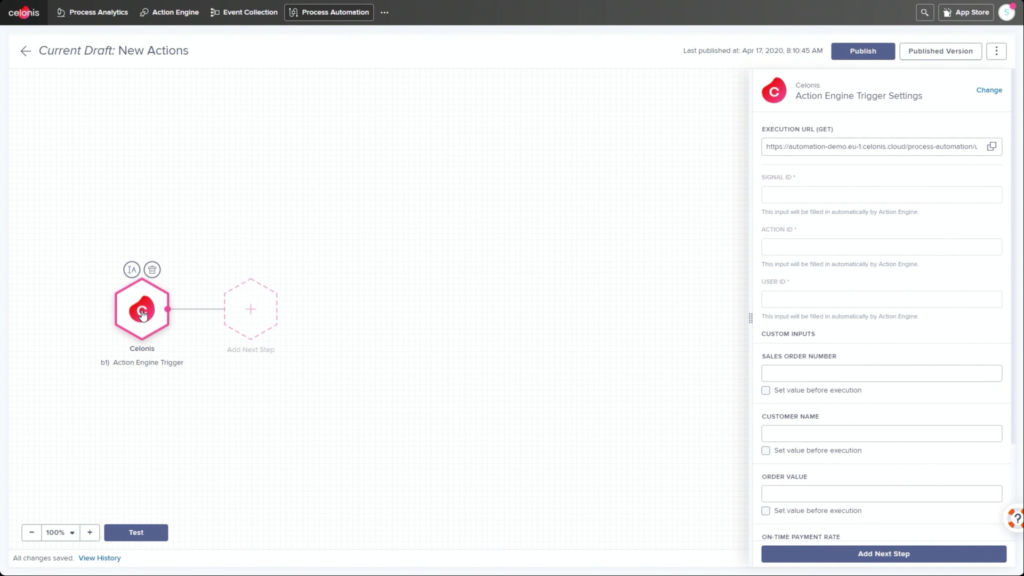
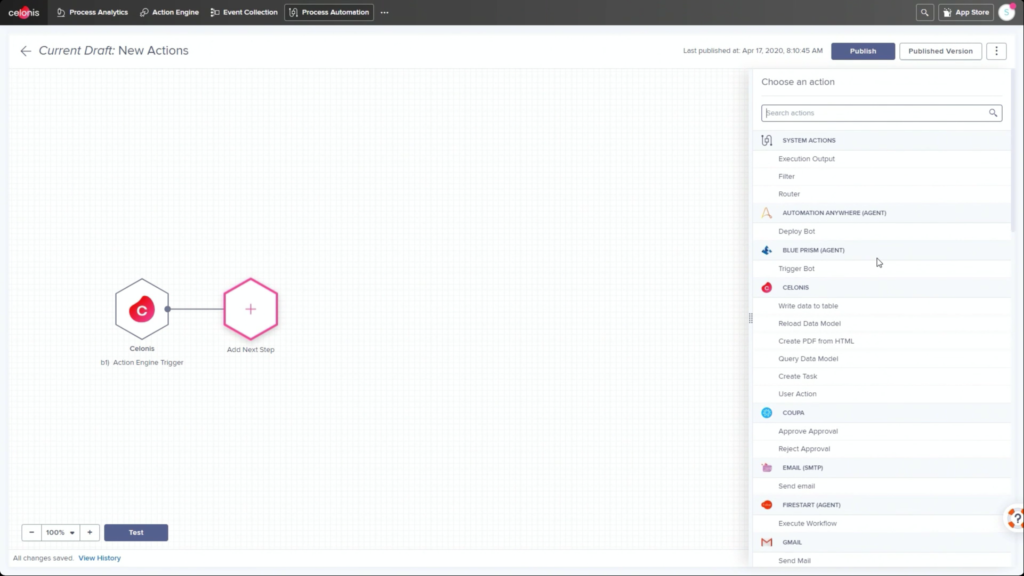
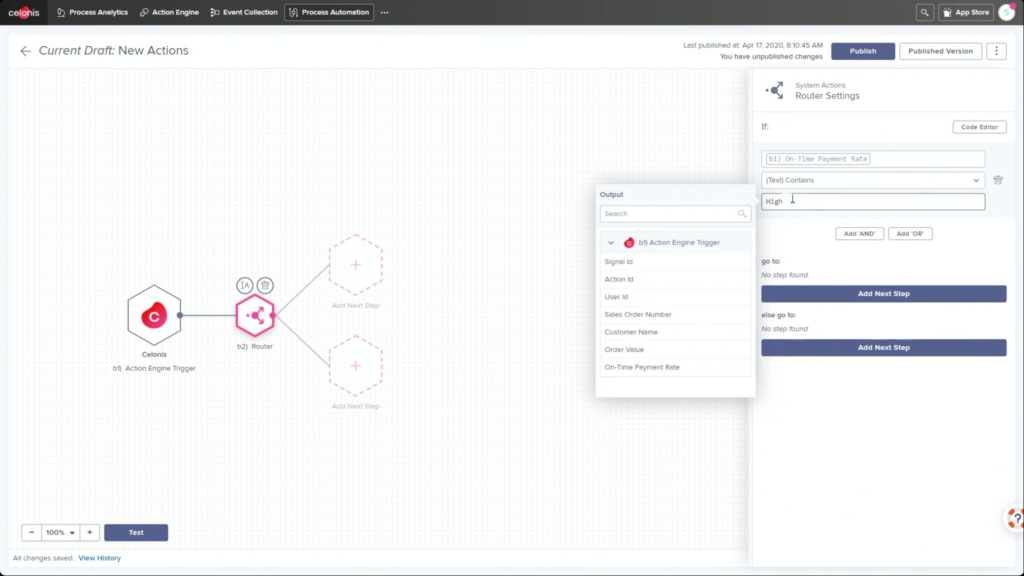
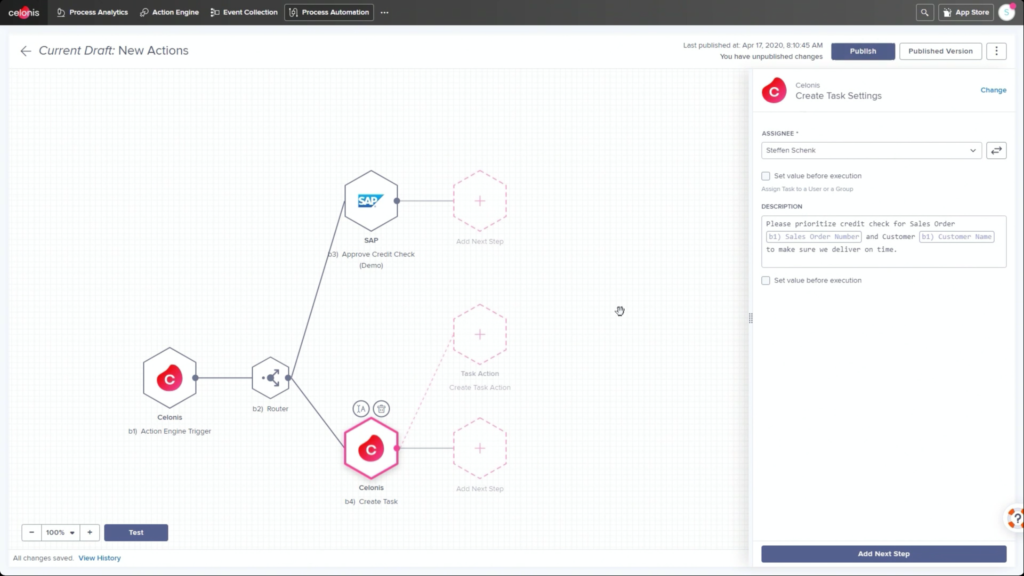
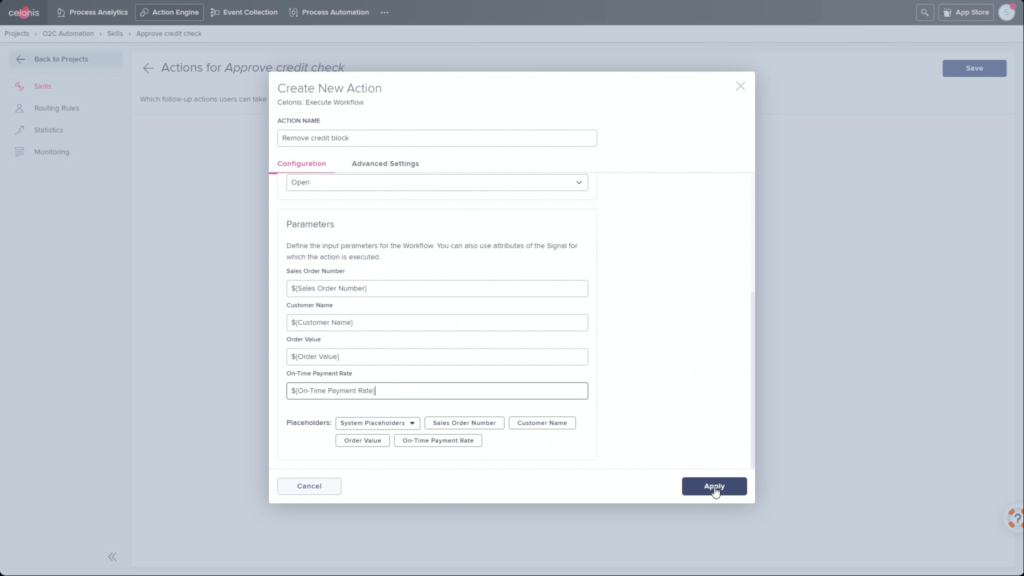
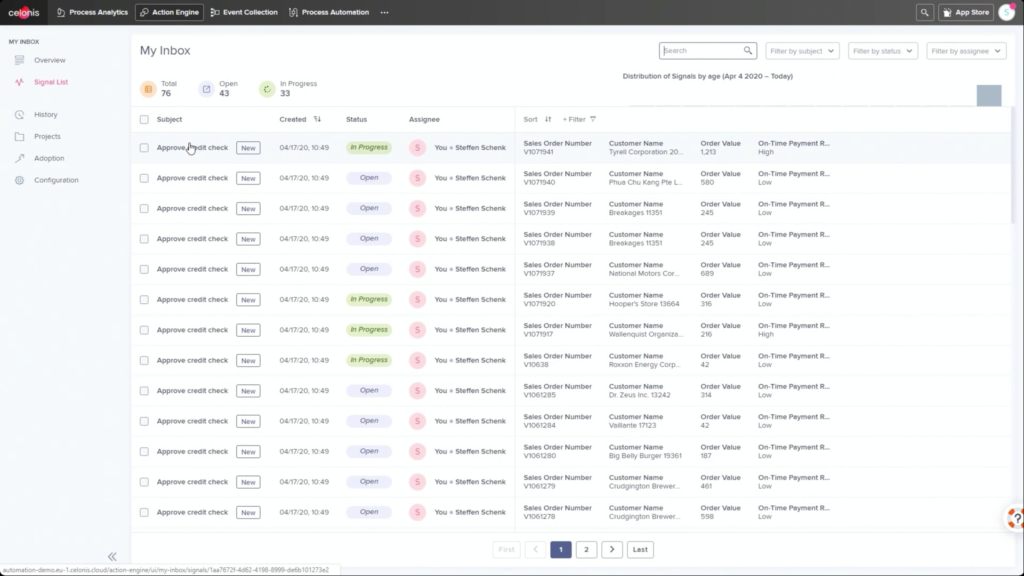
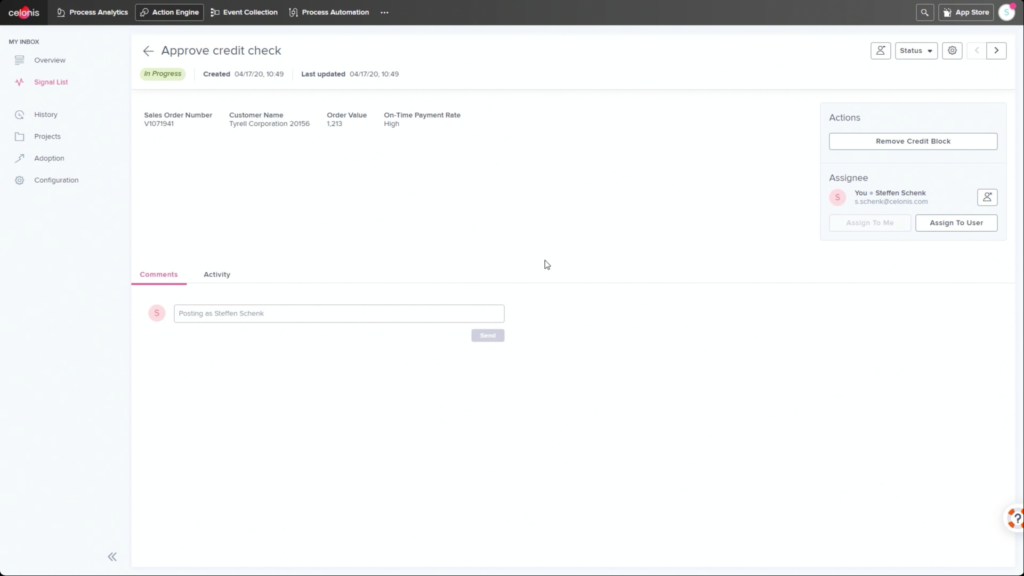
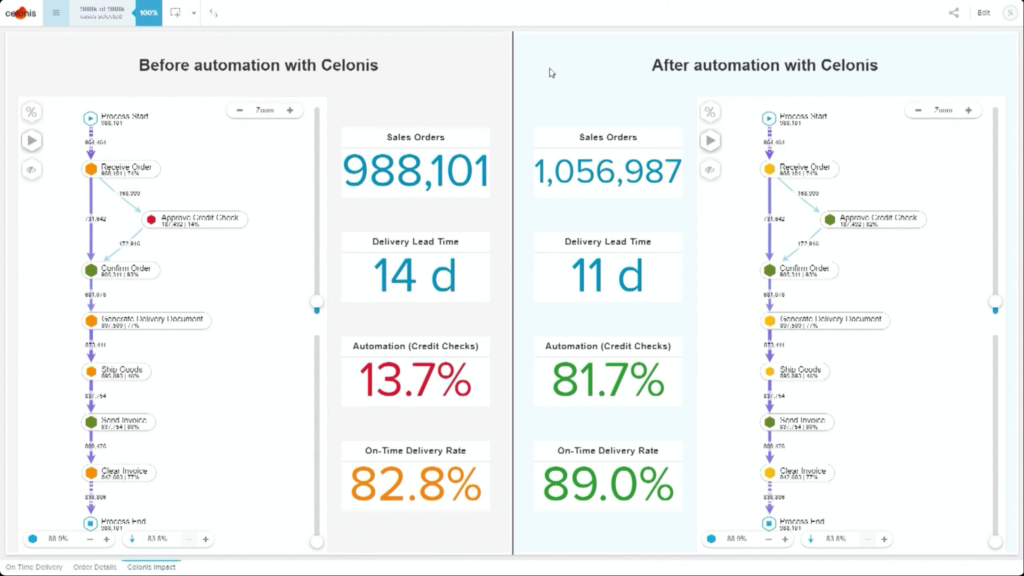
He walked through an example of an order management process where he filtered SAP order data to show those with on-time delivery problems, due to order approval or credit check required, and created a query to detect those conditions in the future. Then, he created a process automation made up of system connectors that would be triggered based on a signal from that query in the future. In addition to system connectors (including webhooks), the automation can also directly call Celonis actions that might prompts a user to take an action. The automation can do branching based on data values: in his example, a customer credit block was automatically removed if they have a history of on-time payment, and that data was pushed back to SAP. That, in turn, would cause SAP to move the invoice along: it’s effectively a collaborative process automation between SAP and Celonis. The non-automated path sends a task to an order manager to approve or deny the credit, which in turn will trigger other automated actions. This process automation is now a “Skill” in Celonis, and can be set to execute for all future SAP order data that flows through Celonis.
Once this automation has been set up, the before and after processes can be compared: we see a higher degree of automation that has led to improving the on-time delivery KPI without increasing risk. It’s data-driven, so that only customers that continue to have an on-time payment record will be automatically approved for credit on a specific order. This is an interesting approach to automation that provides more comprehensive task automation than RPA, and a better fit than BPM when processes primarily exist in a line-of-business or legacy system. If you have an end-to-end process to orchestrate and need a comprehensive model, then BPM may be a better choice, but there’s a lot of interesting applications for the Celonis model of automating the parts of an existing process that the core system would have “delegated” to human action. I can definitely see applications for this in insurance claims, where most of the claim process lives in a third-party claims management system, but there are many decisions and ancillary processes that need to happen around that system.
This level of automation can be set up by a trained Celonis analyst: if you’re already creating analysis and dashboards, then you have the level of skill required to create these automations. This is also available both for cloud and on-premise deployments. There was an interesting discussion in the Q&A about credentials for updating the connected systems: this could be done with the credentials of the person who approves a task to execute (attended automation) or with generic system credentials for fully-automated tasks.
This was a really fascinating talk and a vision of the future for this type of process automation, where the core process lives within an off-the-shelf or legacy system, and there’s a need to do additional automation (or recommendations) of supporting decisions and actions. Very glad that I got up early for the 7:15am start.
I listened in on the following talk on machine learning and intelligent automation by Nicolas Ilmberger, Celonis Senior Product Manager of Platform and Technology, where he showed some of their pre-built ML tools such as duplicate checkers (for duplicate invoices, for example), root cause analysis and intelligent audit sampling. These are used to detect specific scenarios in the data that is flowing into Celonis, then either raising an action to a user, or automating an action in the background. They have a number of pre-configured connectors and filters, for example, to find a duplicate vendor invoice in an SAP system; these will usually need some customization since many organizations have modified their SAP systems.
He showed a demonstration of using some of these tools, and also discussed a case study of a manufacturing customer that had significant cost savings due to duplicate invoice checking: their ERP system only found exact matches, but slight differences in spelling or other typographical errors could result in true duplicates that needed more intelligent comparison. A second case study was for on-time delivery by an automotive supplier, where customer orders at risk were detected and signals sent to customer service with recommendations for the agent for resolution.
It’s important to note that both for these ML tools and the process automation that we saw in the previous session, these are only as timely as the data connection from the core processing system to Celonis: if you’re only doing daily data feeds from SAP to Celonis, for example, that’s how often these decisions and automations will be triggered. For orders of physical goods that may take several days to fulfill, this is not a problem, but this is not a truly real-time process due to that latency. If an order has already moved on to the next stage in SAP before Celonis can act, for example, there will need to be checks to ensure that any updates pushed back to SAP will not negatively impact the order status.
There was a studio discussion following with Hala Zeine and Sebastian Walter. Zeine said that customers are saying “we’re done with discovery, what’s next?”, and have the desire to leverage machine learning and automation for day-to-day operations. This drove home the point that Celonis is repositioning from being an analysis tool to an operational tool, which gives them a much broader potential in terms of number of users and applications. Procure-to-pay and order-to-cash processes are a focus for them, and every mid-sized and large enterprise has problems with these processes.
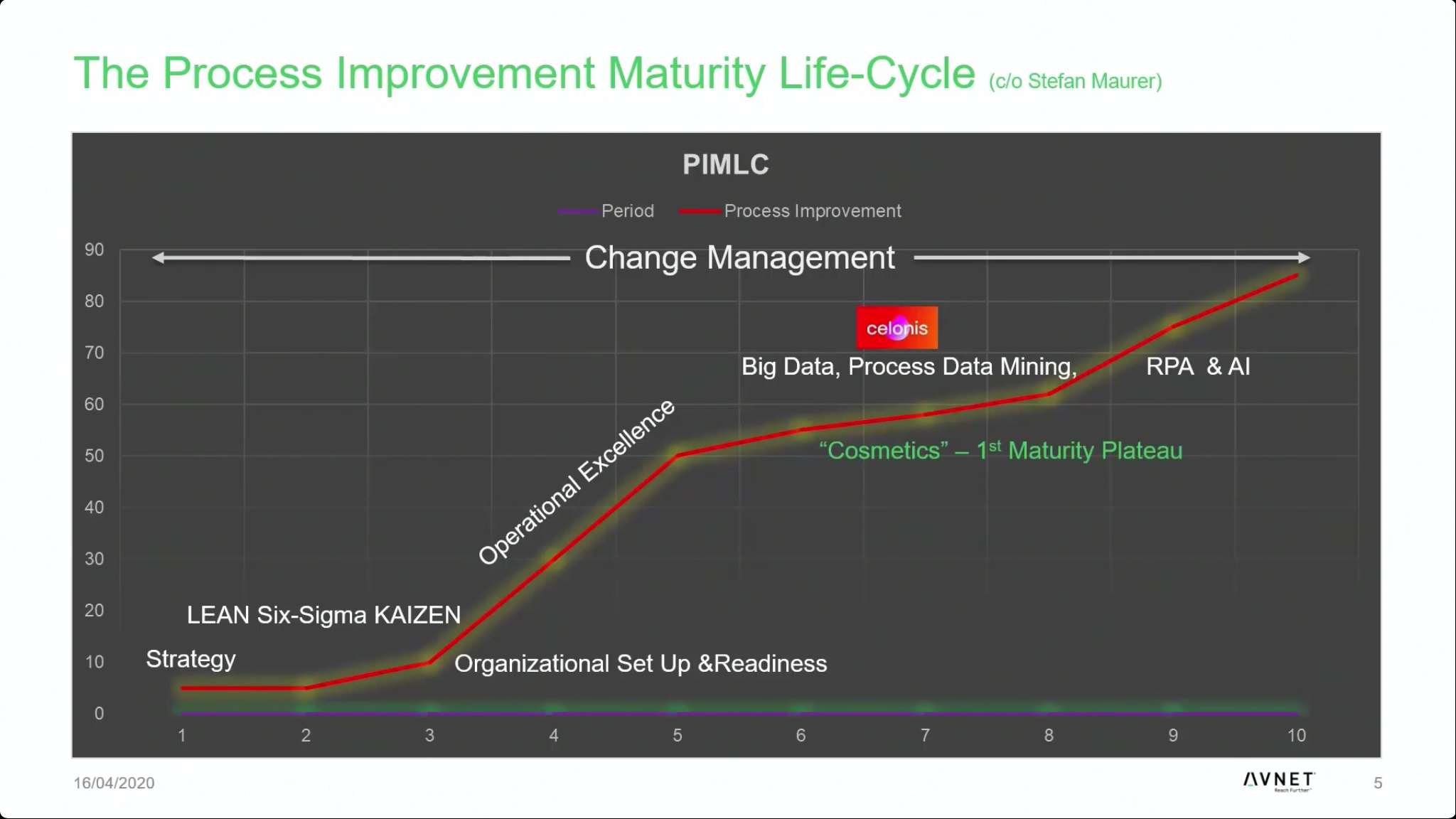
The next session was with Stefan Maurer, Vice President of Enterprise Effectiveness for AVNET, a distributor of electronic components. He spoke about how they are using Celonis in their procure-to-pay process to react to supplier delivery date changes due to the impact of COVID-19 on global supply chains. He started with a number of good points on organizational readiness and how to take on process mining and transformation projects. He walked us through their process improvement maturity lifecycle, showing what they achieved with fundamental efforts such as LEAN Six Sigma, then where they started adding Celonis to the mix to boost the maturity level. He said that they could have benefited from adding Celonis a bit earlier in their journey, but feels that people need a basic understanding of process improvement before adding new tools and methodologies. In response to an audience question later, he clarified that this could be done earlier in an organization that is ready for process improvement, but the results of process mining could be overwhelming if you’re not already in that mindset.
Their enterprise effectiveness efforts focus on the activities of a different team members in a cycle of success that get the business ideas and needs through analysis stages and into implementation within tools and procedures. At several points in that cycle, Celonis is used for process mining but not automation; they are using Kofax and UIPath for RPA as their general task automation strategy.
Maurer showed a case study for early supplier deliveries: although early deliveries might seem like a good thing, if you don’t have an immediate use for the goods and the supplier invoices on delivery, this can have a working capital impact. They used Celonis to investigate details of the deliveries to determine the impact, and identify the target suppliers to work with on resolving the discrepancies. They also use Celonis to monitor procure-to-pay process effectiveness, using a throughput time KPI based over time windows a year apart: in this case, they are using the analytical capabilities to show the impact of their overall process improvement efforts. By studying the process variants, they can see what factors are impacting their effectiveness. They are starting to use the Celonis Action Engine for some delivery alerts, and hope to use more Celonis alerts and recommendations in the future.
Almost accidentally, Celonis also provided an early warning to the changes in the supply chain due to COVID-19. Using the same type of data set as they used for their early delivery analysis, they were able to find which suppliers and materials had a significant delay to their expected deliveries. They could then prioritize the needs of their medical and healthcare customers, manually interfering in their system logic to shift their supply chain to guarantee those customers while delaying others. He thinks that additional insights into materials acquisition supply chains will help them through the crisis.
I’m taking a break from Celosphere to attend the online Alfresco Modernize event, but I plan to return for a couple of the afternoon sessions.
I’m calling this a DIY Mask for Techies because the basic materials are something that every techie has in their drawer: a t-shirt, a couple of conference lanyards, and a paperclip. Of course, you don’t have to be a techie to make one. 🙂
I realize that this is way, way off topic for this blog, and for me in general, but unusual times lead to unusual solutions. This is a long, DIY instructional post, and if you prefer to watch it instead of read it, I’ve recorded the same information as a video. Click on any of the photos in this post to see it at full resolution.
There’s a variety of recommendations on whether or not to wear a mask if you are not exhibiting any symptoms of illness. In some countries that have had success in reducing infection rates, they have a general policy of wearing a mask in public regardless of symptoms, since carriers can be asymptomatic.
I’m choosing to wear a mask when I leave home, or when I greet people who come to the door. Since it’s very difficult to buy medical-grade masks now, I’ve opted to make my own. I’ve also made a few for friends, especially those who have to walk their dogs, or work in an essential service that requires them to leave home.
I’m going to take you through the method that I used, with photos of each step, so that you can make your own. Although I use a sewing machine here, you can sew these by hand, or you could even use fabric glue or staples if you don’t have a needle and thread, or are in a hurry.
Design considerations
I did a lot of research before I started making masks, but my final design was based on these two references.
I went through several iterations to try and make the materials something that a lot of people would already have, since it’s hard to get out shopping these days. Based on the suggested materials, I started with a large t-shirt from my husband’s collection of the many that I have brought home to him from conferences. To all of you vendors who provided me with t-shirts in the past, we thank you!
Next, I needed something to make ties, since these work better than elastic, and I didn’t have a lot of elastic on hand. Remember all of those conferences I went to? Yup, I still had a lot of the conference lanyards hanging in a closet. I provide a hack at the end of these instructions to use the bottom hem of the t-shirt if you don’t have conference lanyards, or you can use other types of ties such as shoelaces.
The paperclip was added in the third-to-last design iteration after I went out for a walk and found that my glasses steamed up due to a gap between the mask and the sides of my nose. It’s sewn into the top edge of the mask to create a bendable nose clip that can be adjusted for each wearer.
Caveats
Just a few caveats, since these are NOT medical-grade masks and I make no specific claims about their effectiveness:
They do not form a tight seal with your face, although they hug pretty closely.
They do not use medical-grade materials, and are not going to be as effective at filtering out the bad stuff.
In general, these masks may not provide complete protection. If you have medical-grade or N95 masks at home, you could use those and they would be better than these, but I recommend that you donate the medical-grade and N95 masks to your local healthcare organization so that front-line doctors and nurses are protected.
All in all, not perfect, but I believe that wearing a DIY fabric mask is better than wearing no mask at all.
Getting started and installing the nose clip
Let’s get started with the basic measuring and installing the nose clip.
Here’s the fabric pattern: it’s a 20cm by 37cm square cut from a t-shirt. Depending on your t-shirt size, you may get four or five of these out of a single shirt.
If you are using a double-knit material like a t-shirt, then you don’t need to hem the edges because it doesn’t ravel at the edges very much. If you are using a different fabric that will ravel, then cut slightly larger and hem the edges. I like to optimize the process so opted for the t-shirt with no hemming.
Next is our basic standard-sized paperclip. I don’t have a lot to say about this, expect that the first paperclip version used a larger paperclip and the wire was too stiff to easily bend while adjusting.
Next thing is to straighten the paperclip. Mine ended up about 10cm long, but plus or minus a centimetre isn’t going to matter.
Putting the paperclip aside for a moment, here’s how to fold the fabric to prepare for sewing. The 20cm length is the width of the mask from side to side on your face, and the 37cm length allows you to fold it so that the two ends overlap by about 1cm. In this case, I’ve overlapped by about 1.5cm, which means that the total height of the mask is 17cm, or 37/2 – 1.5.
I used these measurements because they fit both myself and my husband, so likely work for most adults. If you’re making a mask for a child, measure across their face from cheekbone to cheekbone to replace the 20cm measurement, then measure from the top of their nose to well under their chin, double it and add a centimeter to replace the 37cm measurement.
This next part is a bit tricky, and hard to see in the photos.
This is where we sew the paperclip into the top fold of the mask to create a bendable nose clip. What you’re seeing on the right is the fold at the top of the mask with the straightened paperclip rolled right up into the fold.
To prepare for sewing, I pinned the fabric below the paperclip, pushing the paperclip right into the inside of the fold. In the photo on the left, the paperclip is inside the folded material above the pins.
Now we move to the sewing machine, although this could be done by hand-stitching through the edge of the fabric and around the paperclip. In fact, after having done this a few times, I think that hand-sewing may be easier, since the feed mechanism on most home machines don’t work well when you have something stiff like a paperclip inside your fabric.
If you’re using a sewing machine, put on the zigzag foot and set the width of the stitch to as wide as it will go, so that the two sides of the zigzag stitches will go on either side of the paperclip. Start sewing and guide it through so that the fabric-covered paperclip tucked into the fold is in the centre, and the zigzag stitches go to either side of it: first to the left on the main part of the fabric, and then to the right where there is no fabric but the stitch will close around it.
That may not have been the best explanation, but here’s what you end up with. The straightened paperclip is inside the fold at the top of the fabric, and the zigzag stitches go to either side of it, which completely encloses the paperclip with fabric.
If you have fabric glue, you could definitely try that to hold the paperclip in place instead, although I haven’t tried that. You could also, as I mentioned before, hand-sew it into place.
And here’s why we went to all that work: a bendable nose clip. This is looking from the top of the mask, so you can see that the paperclip is completely sewn into the fold of the fabric, and when you bend the paperclip, it’s going to let you mold it to fit your own nose.
Now here’s what you have, and the hard part is over. You have the folded fabric like we saw earlier, with a straightened paperclip sewn inside the top fold. Lay out your fabric like this again for the next steps.
Adding ties and stitching sides
We’re now going to add ties and stitch the sides to create the mask. I used a sewing machine, but you could do all of this with hand sewing, or you could some type of craft adhesive such as a hot glue gun or fabric glue. You could even staple it together, although if you opt for that, make sure that the smooth (top) side of the staples are facing inwards so that they don’t scratch your face.
Here’s where the conference lanyards come in: who doesn’t have a couple of these hanging around? You’ll need two of them, and I’ve selected two from past vendor clients of mine where I’ve also attended their conferences: Camunda and ABBYY. Thanks guys!
Cut off all that cool stuff at the end of the lanyard and throw it away. Cut each lanyard in half. These will be the four ties that attach to each corner of the mask, and tie behind your head. If one set is slightly longer than the other, use it at the top of the mask since it’s a bit further around the back of your head than around your neck where the other one ties.
To prepare for sewing the edges I’ve started with the right side, and you’re looking at it from the back side, that is, the side that will touch your face. Slide about 1 or 1.5cm of the tie into the fold of the fabric (that is, between the layers) at the top and bottom, and pin in place. I made mine so that the logos on the ties are facing out and right-side up when the mask is on, but the choice is yours.
Also put a pin where the fabric overlaps in the middle of that edge to hold it in place while sewing.
Now, it’s just a straight shot of sewing from top to bottom. I went back and forth over the ties a couple of times to make sure that they’re secure, then just stitched the rest of the way.
Once it’s sewn, if you flip it over, it will look like the photo on the right. This is the outside of the mask, now with the ties sewn in place and the entire edge stitched closed.
Now, pin the ties in place on the second edge, and pin the fabric overlap at the centre to prepare for sewing, just like you did with the first edge.
Sew that one just like you did the other, and you know have an almost completed mask. The photo to the right shows the side of the mask that faces outwards, with the nose clip in the edge at the top.
Some of the fabric designs that I’ve seen online stop with a simple version like this, but I find it leaves large gaps at the sides, so I wanted to tighten it up like what the Taiwanese doctor did by adding tucks to his.
Adding side tucks
There are other ways to do this rather than the tucks that I’m going to show you. I did a couple of masks using elastic, but I don’t have a lot of elastic on hand and thought that most people wouldn’t unless they do a lot of sewing or crafts. If you have a shirring foot on your sewing machine, you can definitely use that. If you don’t know what a shirring foot is, then you probably don’t have one. I recall a hand-shirring technique that I learned in Home Economics class in junior high, but that part of my memory was overwritten when I learned my 4th programming language.
Basically, I wanted to reduce the 17cm height of the mask that is required to stretch from nose to chin down to about 10cm at the edges. I added two large-ish tucks/pleats, angling them slightly in, and pinned them in place. This is shown from the inside of the mask, since I want the tucks to push out.
You’ll see what I mean when we flip the mask over, still just pinned, and you can see that the two tucks will cause the mask to pleat it out away from your face towards the centre.
Sew across the two tucks to hold them in place. There’s not going to be a lot of strain on these, so hand-sew them if that’s easier. The photo on the right shows what it looks like on the inside of the mask after stitching the tucks.
And when we flip it over, the photo on the left is what it looks like from the outside after stitching.
Do the same on the other side, and the mask is essentially done. This is the completed mask with ties at each corner, and a bendable nose clip at the top:
Filter insert
We’re not quite done. Remember that open fold at the back of the mask? We’re going to insert an extra layer of filter material inside the mask, between the two layers of t-shirt fabric.
The mask would work just fine as it is, but will work better with an additional layer of a non-woven material inside to stop transmission of aerosolized particles. The doctor from the original design said that you could use a few layers of tissue that had been wet and then dried, so that it melded together. I was also talking with a friend about using a paper coffee filter. Use your imagination here, as long as it isn’t embedded with any chemicals and air can pass through it sufficiently for breathing.
I found a great suggestion online, however…a piece of a Swiffer Sweeper cloth, cut to fit. It’s unscented and likely contains little in the way of harmful chemicals, although I might try out a few other things here.
With the inside of the mask facing up, open the pocket formed by the overlapping edges of the fabric that we left across the middle of the mask. This is where the filter is going to go, and then the fabric will close around it.
Push the filter into the opening, flattening it out so that you’re only breathing through a single layer of it. It’s going to be a bit harder than usual to breathe through the mask anyway, so you don’t want to make it worse.
Now the filter is all the way inside the mask. Flatten it out and push it up into the corners for best coverage. If it’s too big, take it out and trim it rather than having rolls of extra filter material inside the mask.
If you just tug gently at the sides of the mask, the opening closes over the filter, and you’re ready to go. I did one model that put a snap in the middle so that the opening was held closed, but it’s not necessary and the snap pressed up against my nose in an annoying fashion.
Adjusting and wearing
Time to finally put the mask on. Before tying it on the first time, put the nose clip up to the top of your nose and mold it to fit over your nose. Once you’ve done this once, you probably only need to make minor adjustments, if any, when you put it on again.
On the left, you can see how I’ve bent the nose clip down the sides of my nose, then flattened the ends of it to follow the edge of my cheek. This closes most of the gap between the mask and my face at the top edge, which reduces the opportunity for aerosol particles to get in, and also means that my glasses don’t fog up every time I exhale.
Next, tie the top tie around your head. Make it nice and high so that it won’t slip down. This should be fairly snug but not uncomfortably so. Readjust the nose clip, since tying the top tie will usually pull it up a bit.
The bottom tie goes around and ties at the back of your neck, and can be fairly loose. Notice how the tucks conform to the side of my face so that the mask fits closely there. I’m thinking in the next version to add a tuck right in the middle of bottom edge to have it hug the chin closer, but this is pretty good.
General wearing instructions
A few tips about wearing, then I’ll show you a final hack in case you don’t have a conference lanyard.
Always put a clean mask on with clean hands.
Try not to adjust the mask once your hands may no longer be clean. In general, put the mask on before you leave home, and take it off when you come back.
Since the outside of the mask may have picked up something, be sure to wash your hands after you take it off. If you have to take it off while outside, you can untie the top tie and let the mask hang forward over your chest while it’s still tied around your neck, then wash your hands or use hand sanitizer before touching your face. To put it back on, just pull up and tie.
There are a few different ways to clean the mask.
If it’s not dirty but may have contacted the virus, you can just leave it for 24 hours. I’m basing that recommendation on the time that it takes for the virus to deteriorate on a porous material such as cardboard.
You can wash it in warm soapy water while you’re washing your hands. Rinse in clear water, squeeze out and hang to try.
You can also do the equivalent of a medical autoclave, and steam it over boiling water for 10 minutes. Obviously, don’t put it in the microwave because of the metal paperclip.
Here’s the final hack. If you don’t have a conference lanyard, or a pair of bootlaces or the drawstring from your pajamas, you can create ties by trimming the bottom (hemmed) edge off the t-shirt and cutting it to the right length. If you trim it a little bit away from the stitching, as you can see at the bottom, it won’t even need to be hemmed.
You can also fold and sew strips into ties, but probably you can find something already made to use instead.
That’s it for my DIY mask for techies, made from a t-shirt, 2 conference lanyards and a paperclip. I don’t plan to start any series of DIY coronavirus supplies, but if you’re interested in business process automation and how our world of work is changing in these changing times, check out some of my other work.
The ability to build apps quickly is a cornerstone in our industry of model-driven development and low-code, and it’s encouraging to see some good offerings on the table already in response to our current situation.
Appian was first out of the blocks with a COVID-19 Response Management application for collecting and managing employee health status, travel history and more in a HIPAA-compliant cloud. You can read about it on their blog, and sign up for it online. Their blog post says that it’s free to any enterprise or government agency, although the signup page says that it’s free to organizations with over 1,000 employees — not sure which is accurate, since the latter seems to exclude non-customers under 1,000 employees. It’s free only for six months at this point.
Pegasystems followed closely behind with a COVID-19 Employee Safety and Business Continuity Tracker, which seems to have similar functionality to the Appian application. It’s an accelerator, so you download it and configure it for your own needs, a familiar process if you’re an existing Pega customer — which you will have to be, because it’s only available for Pega customers. The page linked above has a link get the app from the Pega Marketplace, where it will be free through December 31, 2020.
As a founding member of OMG’s BPM+ Health community, Trisotech has been involved in developing shareable clinical pathways for other medical conditions (using visual models in BPMN, CMMN and/or DMN), and I imagine that these new tools might be the first bits of new shareable clinical pathways targeted at COVID-19, possibly packaged as consumable microservices. You can click on the tools and try them out without any type of registration or preparation: they ask a series of questions and provide an assessment based on the underlying business rules, and you can also upload files containing data and download the results.
My personal view is that making these apps available to non-customers is sure to be a benefit, since they will get a chance to work with your company’s platform and you’ll gain some goodwill all around.
There’s a very real possibility that a lot of people will be “on the bench” in the near future: either their work requires travel, or their company has to make tough decisions about staffing. This is a great time to consider skilling up, and The Master Channel has courses on process and decision modeling, business analysis, analytics and more. I have never taken one of their courses so can’t vouch for the quality, and I am not being compensated in any way for writing this post, but probably worth checking out what they have to offer.
Their current offer is only until April 5th, although it’s clear to most people that our period of confinement is going to last much longer than that. Get them while you can.
If you know of other e-learning companies making similar offers, please add them in the comments of this post (including a link if you have one). I know of several universities that offer free online courses for related topics although they tend to be longer and much more detailed — I had to dedicate four weeks and relearn a lot of forgotten graph theory to get through the Eindhoven University of Technology’s course in process mining, which is more than a lot of people have time (or patience) for.
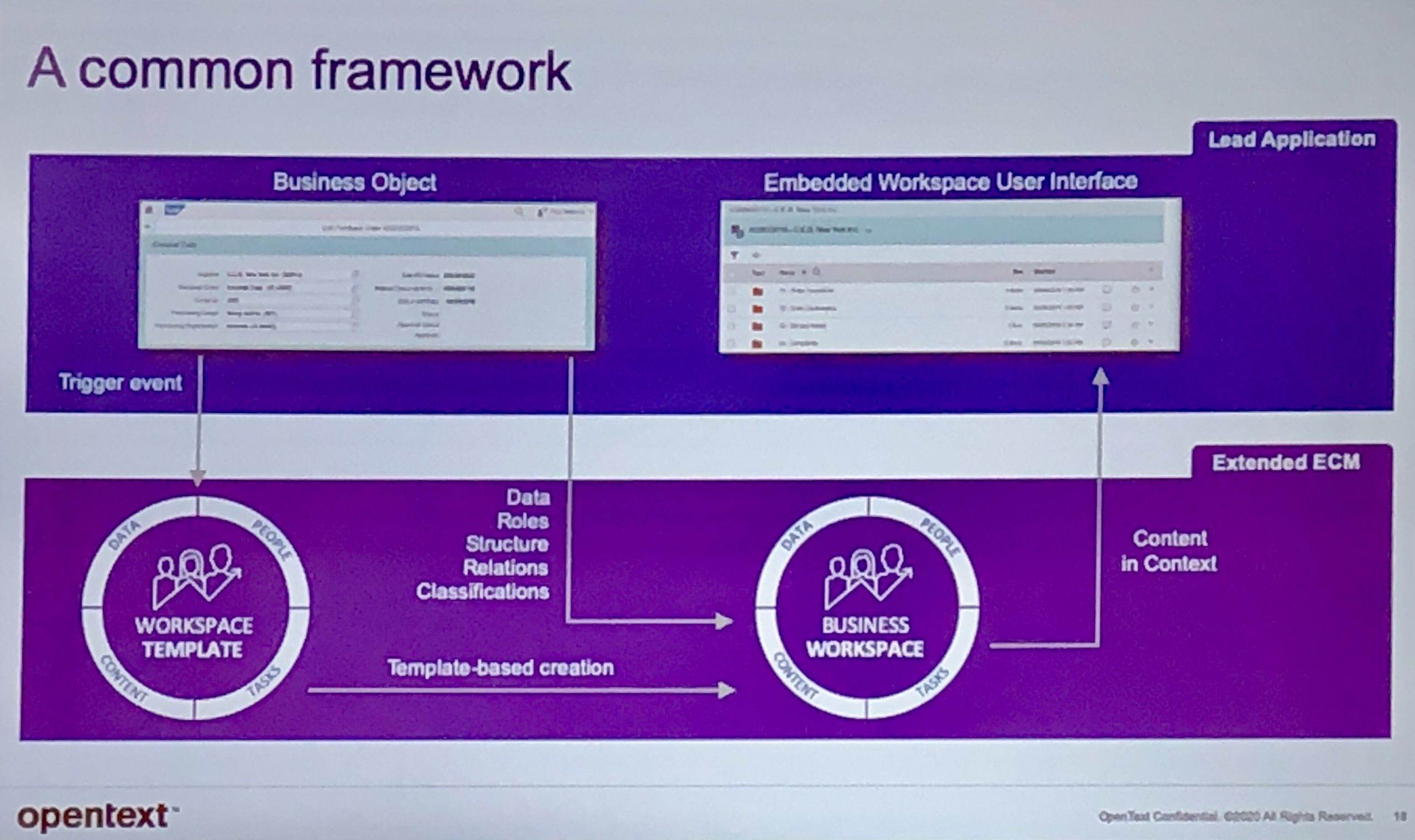
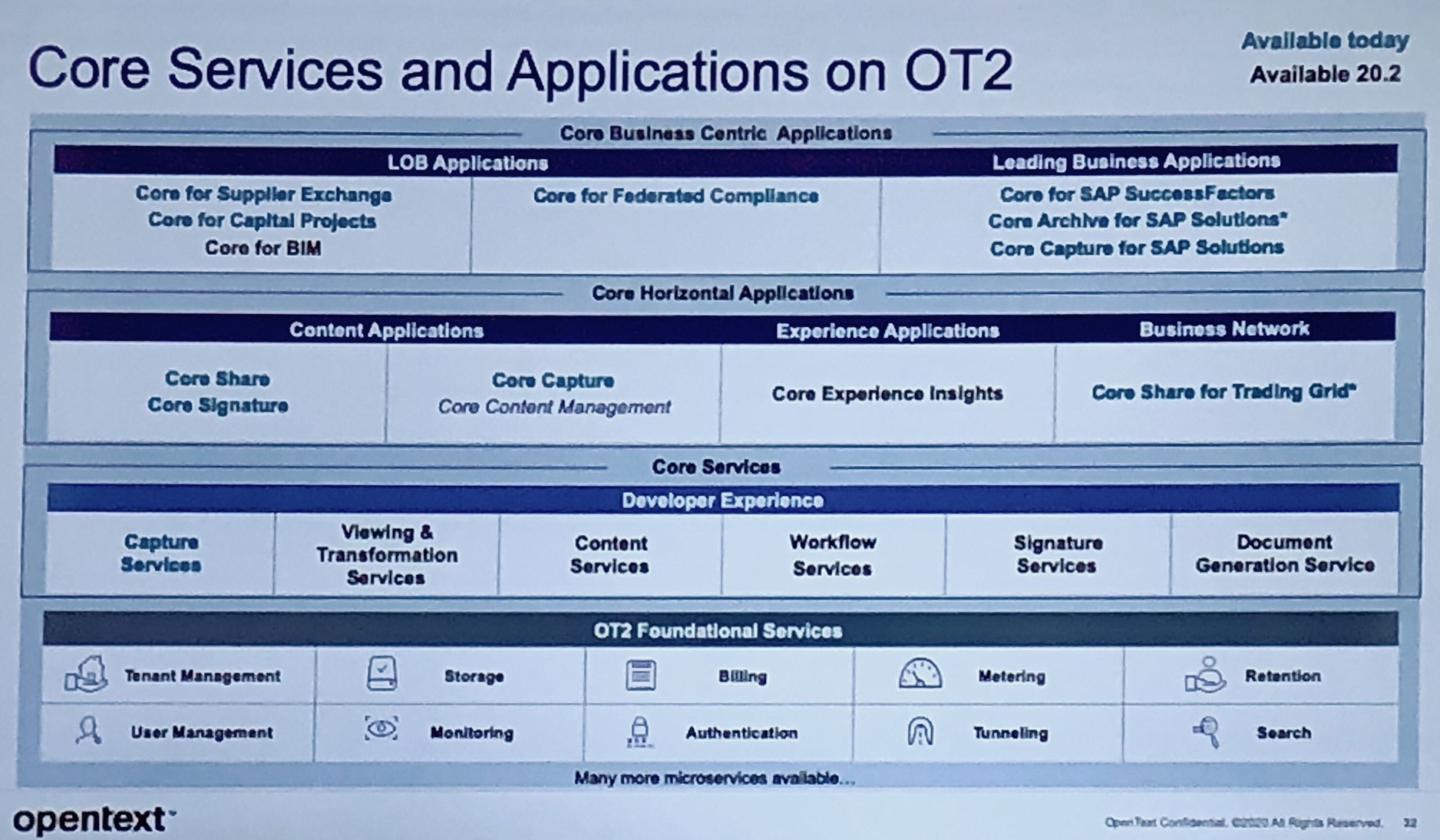
Fred Sass, Marc Diefenbruch and Michael Cybala presented a breakout session on the content services portfolio. OpenText has two main content services platforms: their original Content Suite and the 2016 acquisition of Documentum, both of which appear to be under active development. They also list Extended ECM as a “content services platform”, although my understanding is that it’s a layer that abstracts and links Content Suite (and to a lesser extent, Documentum) to exist within other business workplaces. I’m definitely not the best source of information on OpenText content services platform architecture.
In many cases, their Content Suite is not accessed via an OpenText UI, but is served up as part of some other digital workplace — e.g., SAP, Salesforce or Microsoft Teams — with deep integration into that environment rather than just a simple link to a piece of content. This is done via their Extended ECM product line, which includes connectors for SAP, Microsoft and other environments. They are starting to build out Extended ECM Documentum to allow the same type of access via other business environments, but to Documentum D2 rather than Content Suite. They are integrating Core Share in the same way with Salesforce, allowing for secure sharing of content with external participants.
They discussed the various cloud options for OpenText content (off cloud, public cloud, managed services on OpenText private cloud, managed services on public cloud, SaaS cloud), as well as some general benefits of containerization. They use Docker containers on Kubernetes, which means that they can deploy on any cloud platform as well as an on-premise environment. They also have a number of content-related services available in the OT2 SaaS microservices environment, including Core Share and Core Capture applications and the underlying capture and content services. Core has been integrated with a number of different SaaS applications (e.g., SAP SuccessFactors) for document capture, storage and generation.
The third topic covered in the session was intelligent automation, including the type of AI-powered intelligent categorization and filing of documents with Magellan. We saw a demo of Core Capture with machine learning, where document classification and field recognition on the first pass of a document type were corrected manually, then the system performed correct recognition on a subsequent similar document. A second demo showed a government use case, where a captured document created a case management scenario on Extended ECM that is essentially a template-based document approval workflow with a few case management features including the ability to dynamically add steps and participants. As we get a bit deeper into the workflow, it’s revealed to be OpenText Process Suite, as part of AppWorks.
Lastly we looked at information governance, with a renewed interest due to privacy concerns and compliance-related legislation. They have a new solution, Core for Federated Compliance, that provides centralized records oversight and policy management over multiple platforms and repositories. It’s currently only linking to their own content repositories, but have some plans to extend this to other content sources such as file shares.
There’s another breakout plus a wrap-up Q&A with the executive leadership team, but this is the end of my coverage of the 2020 OpenText Analyst Summit. If something extraordinary happens in either of those sessions, I’ll tweet about it.
We started the second day of the OpenText analyst summit with EVP of sales Ted Harrison outlining their sales value proposition, both through their direct sales force and their partner channel. Customers tend to start with one OpenText product, but often expand to additional product lines to create more of a strategic partnership. OpenText is a prolific user of their own technology, providing a good template for some of their large customers in how their products can be used throughout an organization. With the growth in their cloud platform, they expect cloud to be their largest business in FY21. Harrison finished his presentation with a couple of customer case studies: Pacific Life doing a huge migration to OpenText Cloud, and JPMorgan Chase using AI for automated redaction, and Google using TeamSite for their partner portal.
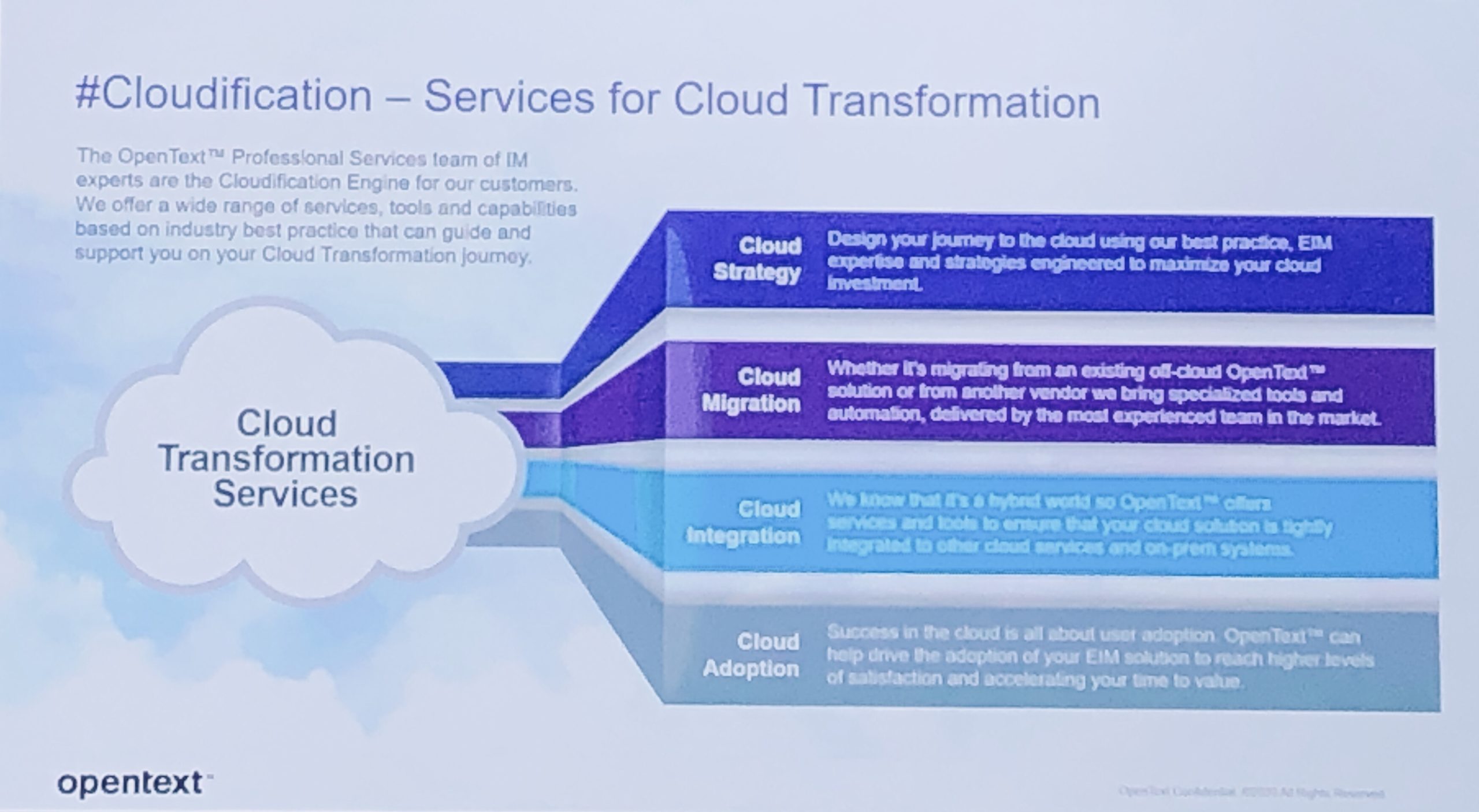
James McGourlay, EVP of customer operations, covered their support, professional services and customer experience teams. They’ve done more than 40,000 engagements, which has created a depth of knowledge in successful deployment of their products. To fuel the move to the OpenText Cloud, professional services is helping customers with “Cloudification” strategy, migration, integration and adoption. McGourlay spoke about their commitment to data sovereignty, especially for European customers that have strict location regulations for certain data types. They perform customer satisfaction surveys for both professional services and technical support, with the goal to constantly improve their approval rating — currently at 96.4% for their technical support, for example, which he considers “not good enough”.
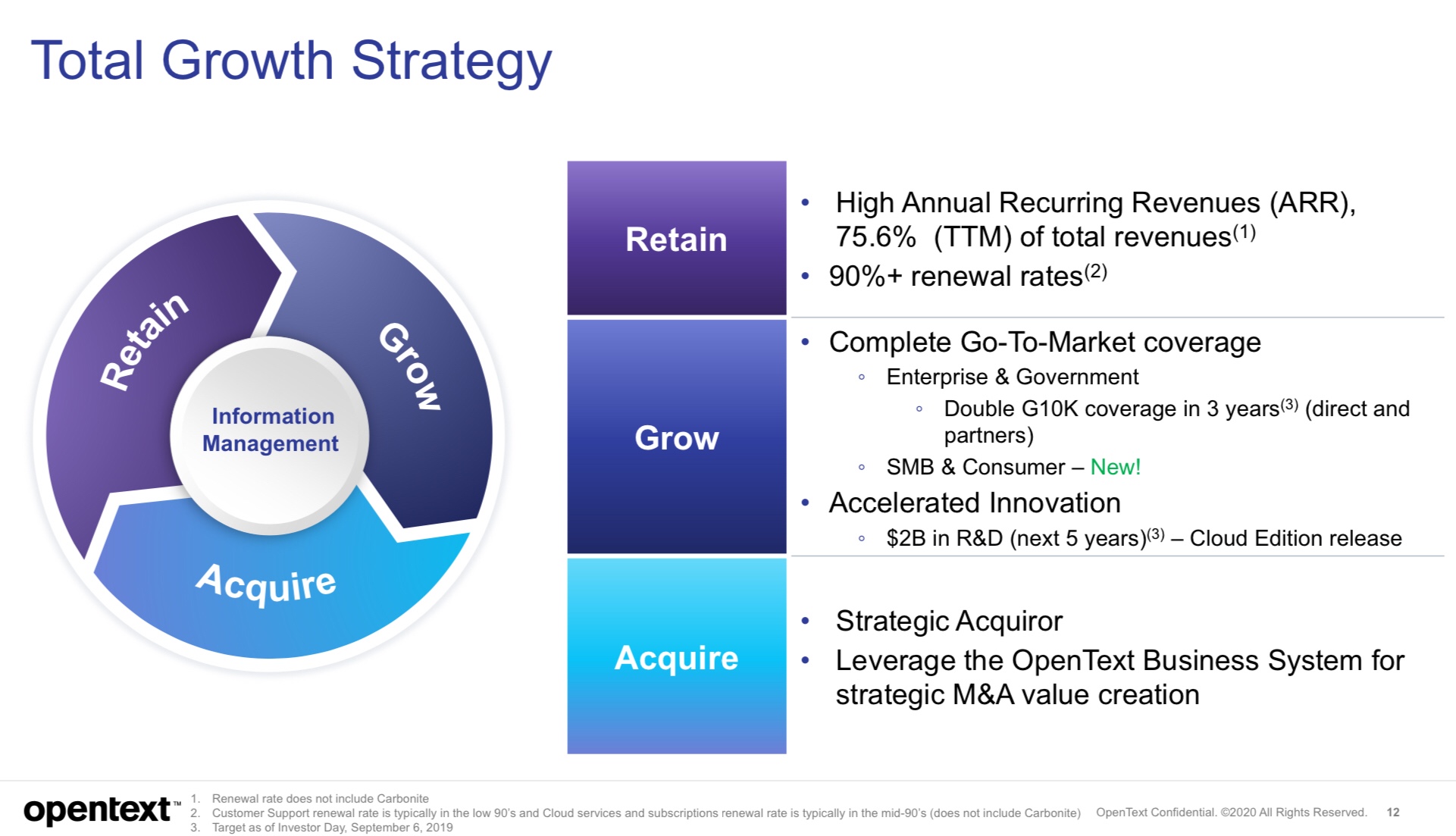
The last presentation in this session was CFO Madhu Ranganathan with a business and financial update. You can get more of the investor and financial details on their website (or read something written by one of the many blue-suited financial analysts in the audience), and she provided a summary of that publicly-available information: profitable and cash flow-positive, 25+ years of solid performance, and a proven M&A track record which is their dominant growth strategy. They have specific criteria for acquisitions: market leadership, value for OpenText’s customers, mission-critical capabilities, financially compelling, larger customer base, and longer operating history. Ranganathan showed a timeline of successful acquisitions; interestingly, none of the three BPM/workflow buys (Global360 and Metastorm in 2011, Cordys in 2013) were mentioned. It’s probably fair to say that workflow is not a primary product category for OpenText; it’s really just functionality within their AppWorks application development platform, most often used content-centric applications such as document lifecycle and case management. In summary, OpenText is solid financially, and has cash in the bank to leverage more acquisitions as part of their growth strategy.
I’m in Boston for the next two days for OpenText’s annual analyst summit; Patty Nagle, CMO, kicked things off in the first session, then we had a keynote from CEO/CTO Mark Barrenechea. They’re coming up on 30 years in existence, which is definitely a milestone for any technology company, and they’ve grown to 15,000 employees in over 30 countries, in part through their pattern of growth through acquisition. They sell through a large direct salesforce, as well as through their 27,000 partners and directly from their website.
The latest acquisition is Carbonite, which seems a pretty good fit with their cloud/edge content strategy, and Barrenchea discussed where Carbonite fits into their strategy some detail: decentralized computing, small/medium business and consumer audience, and cyber-resilience. OpenText has promoted the term enterprise information management (EIM) in the past, and now are dropping the “E” to be just information management as they enter the smaller end of the market.
They are following the lead of smaller (arguably more nimble) vendors with a move to quarterly product releases for their core content management, and their product versioning will reflect that with a YY.Q version number (e.g., 20.2). Their release 16 will become Cloud Edition 20.2 with the April release, with OT2 and Business Network following the same version numbering. The push to the cloud continues, and if you go to their website now, you’ll see a link to their cloud logins. I’m not sure that having quite so many different logins is a good thing, but I get that there are different audiences for this.
He also covered their business network and cyber resilience offerings, which are a bit peripheral to my interests; then on to their digital accelerants, which is a mixed bag of capabilities including low-code development, AI, IoT, process automation and analytics. They showed a demo of Magellan analytics visualizing World Health Organization data on COVID-19 — a timely example — showing the trends of the disease spread in human healthcare terms, but also the impact on business and markets.
Their key corporate priorities include maintaining market leadership in information management, with expansion to all size of customers; continued move to the cloud; and becoming more of an applications company. I’ve seen a few horizontal technology vendors fail spectacularly on building applications, so it will be interesting to see what they can accomplish there.
We heard briefly about BrightCloud Threat Intelligence, part of the Carbonite acquisition, and saw a demonstration of the Webroot BrightCloud Threat Investigator. Webroot was only acquired by Carbonite less than a year ago, and the branding didn’t even have time to change to Carbonite before becoming part of OpenText. OpenText plans to integrate this into their other offerings to provide better security for content and access to third-party sites and services.
Barrenechea ended with a call to arms to address climate change, ethical supply chains, overuse of plastics and other issues threatening society at large. Not what you usually hear from a technology CEO, but they are pushing a brand of “technology for the good”.
Ted Harrison, EVP of sales, finished the session by hosting a customer panel featuring Peter Chen of Stericycle, Shyam Pitchaimuthu of Chevron, and Gurreet Sidhu of BMO Financial Group. Stericycle and Chevron are both OpenText content management customers, with broad usage across their organizations and deep integration into other systems and processes. BMO is using the OpenText Trading Grid for B2B payment solutions, and appreciate the elastic scalability of the platform as business sectors expand and contract. Stericycle and Chevron both moved to cloud content management as part of their cloud-first strategy, with Chevron doing a conversion from on-premise Documentum to Azure. BMO went with OpenText’s managed services to allow them greater customization and security without running the core infrastructure themselves. Good discussion of how they’re using OpenText products, and the transition to their current state.