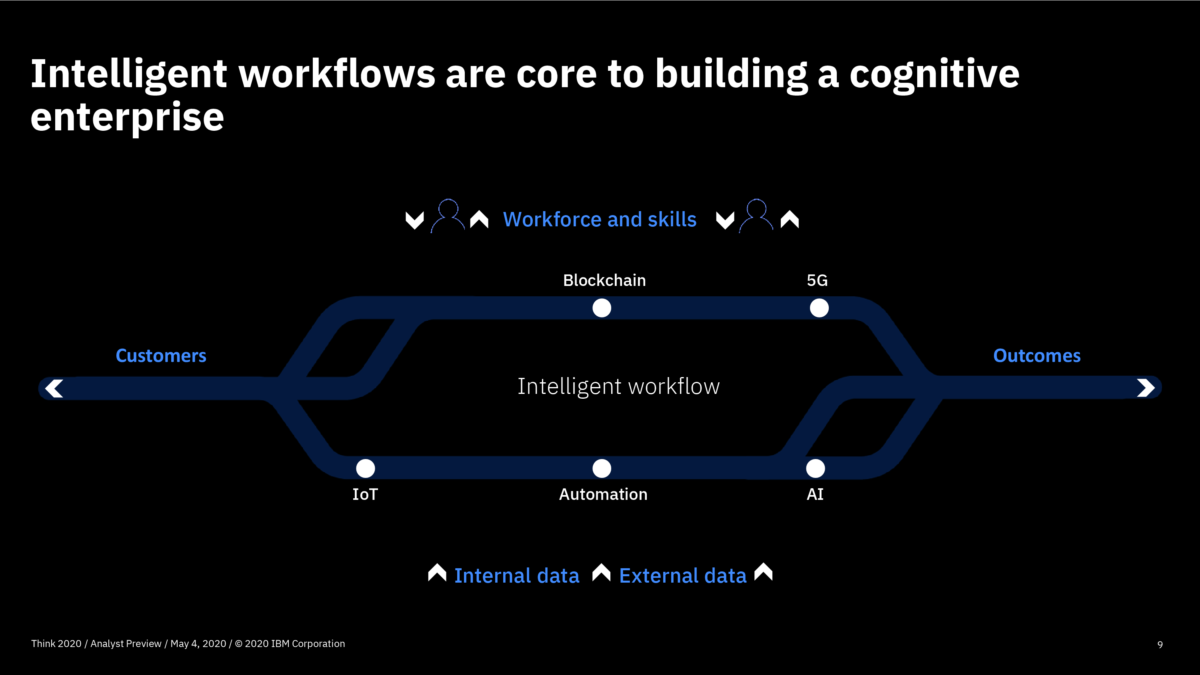
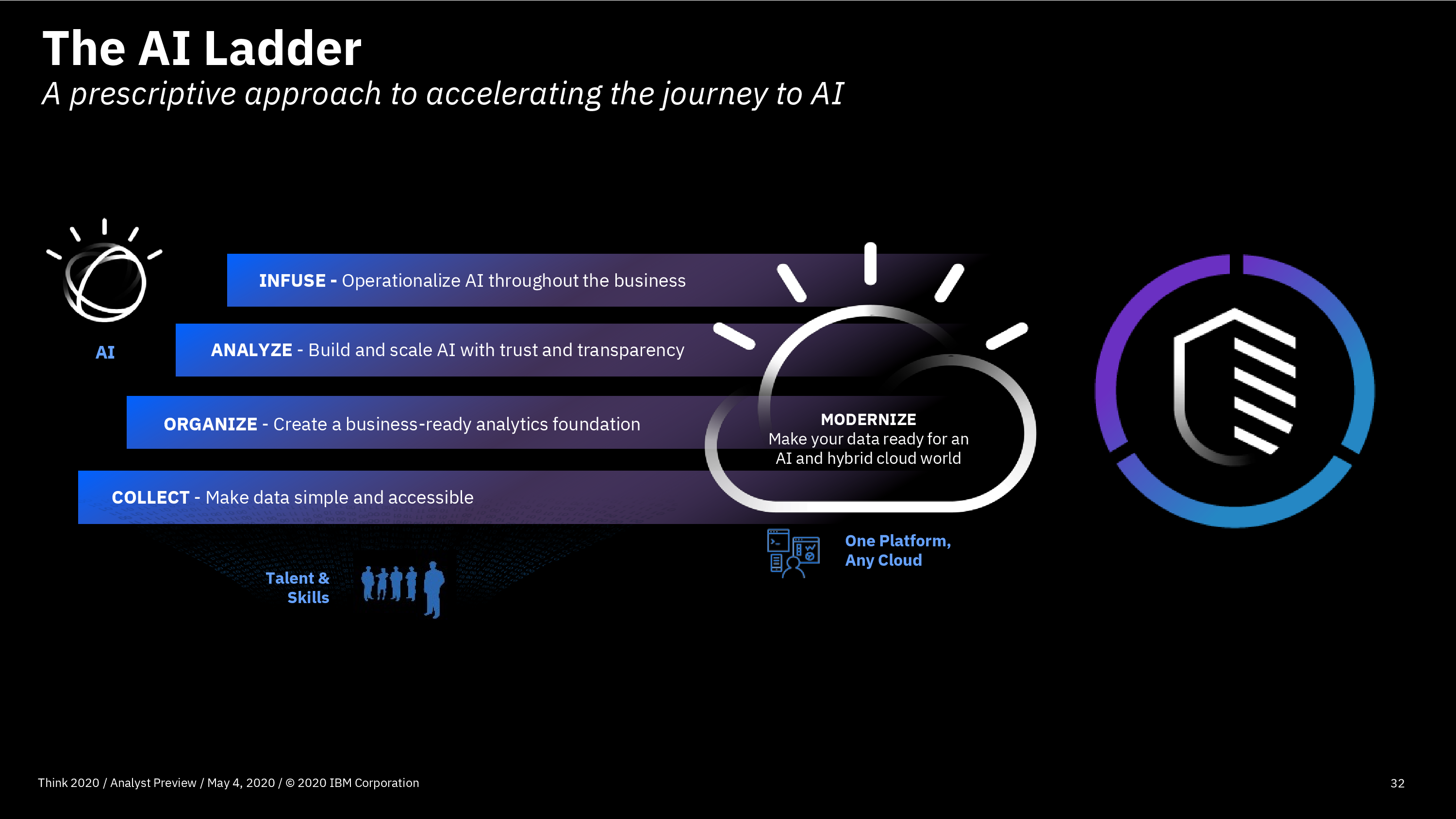
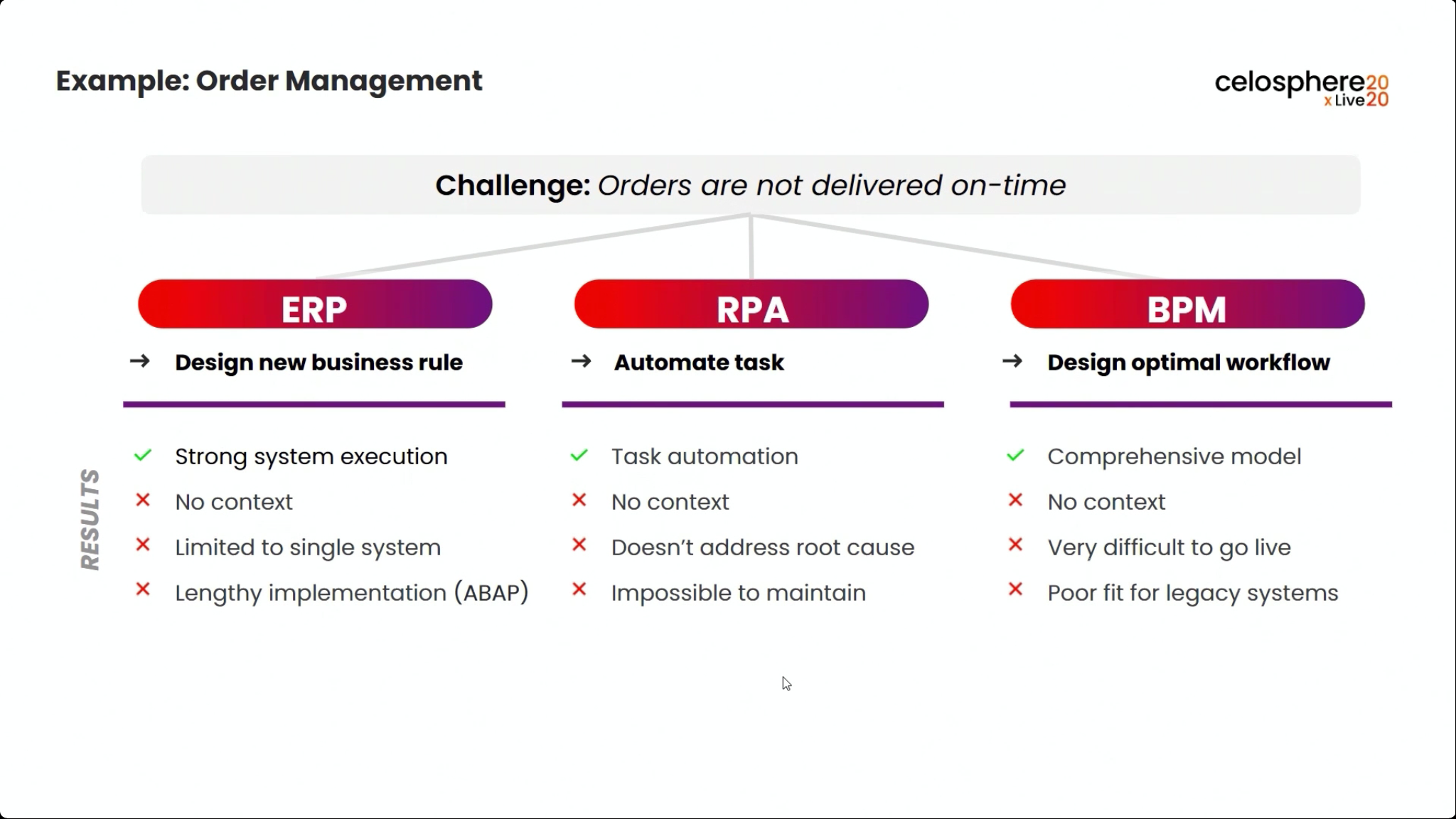
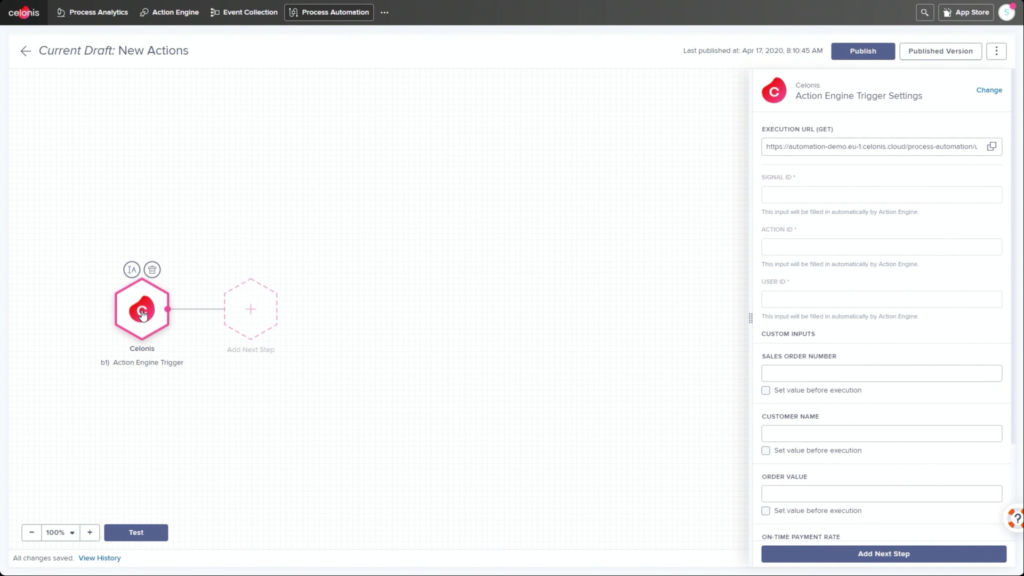
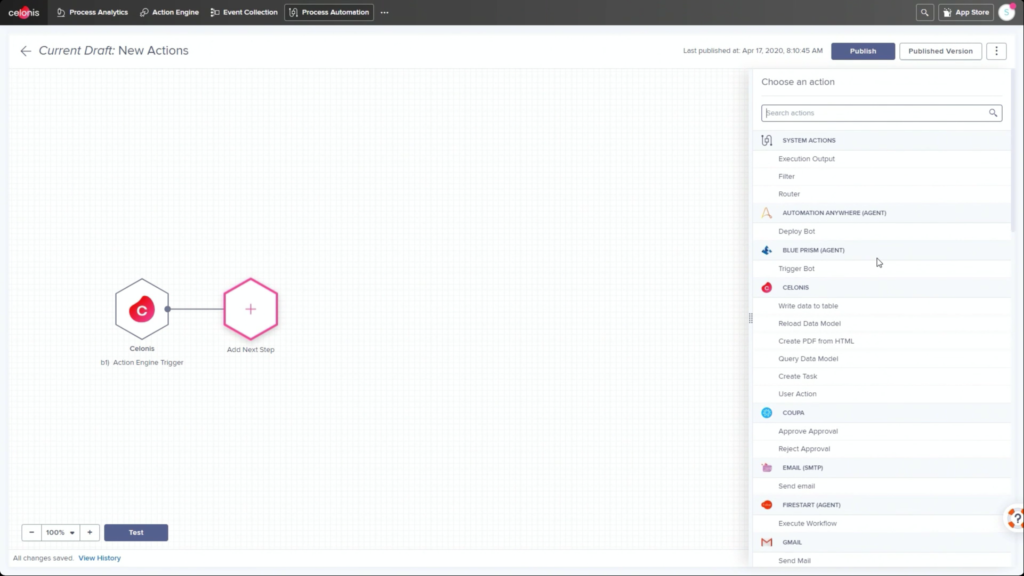
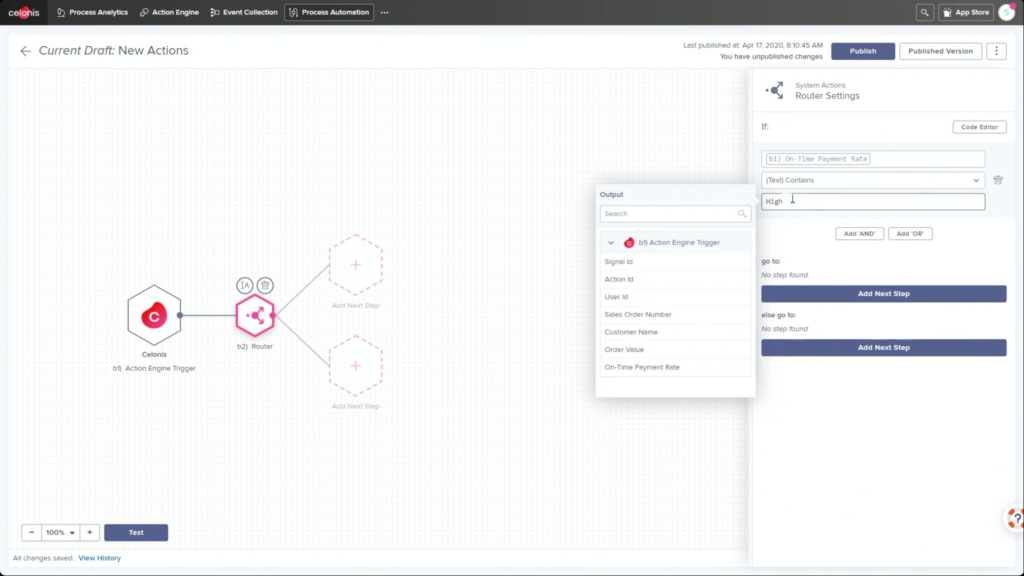
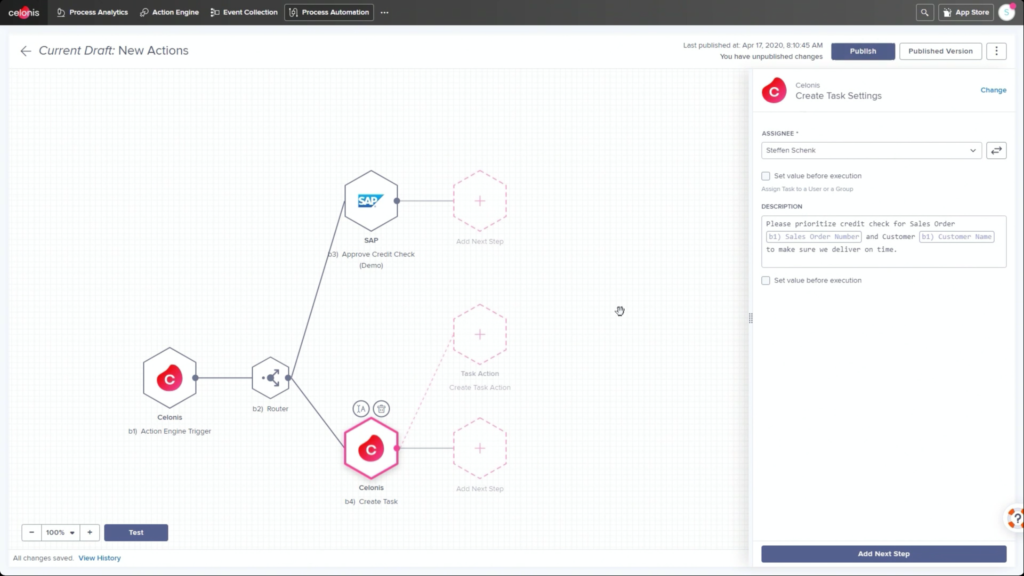
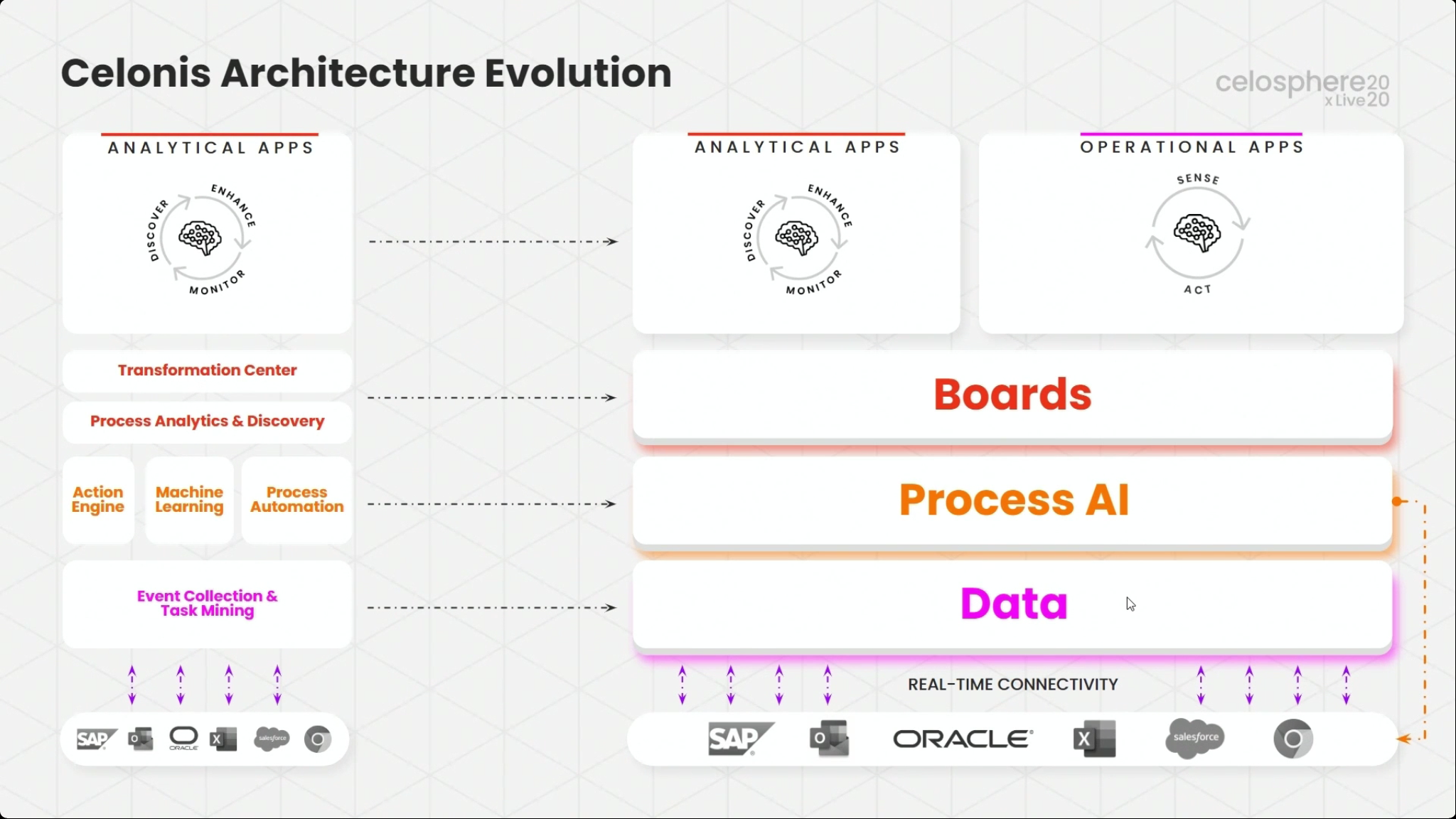
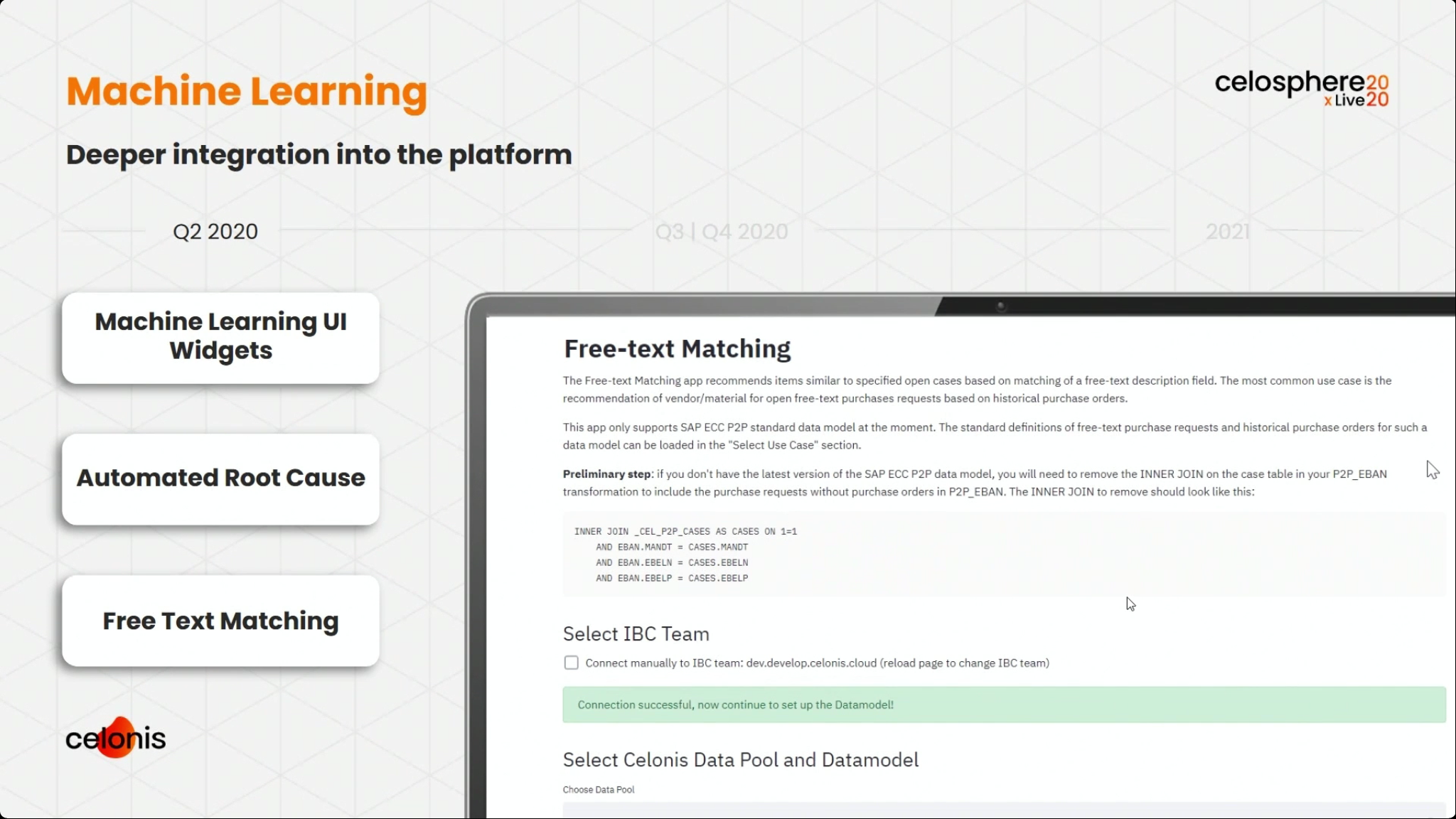
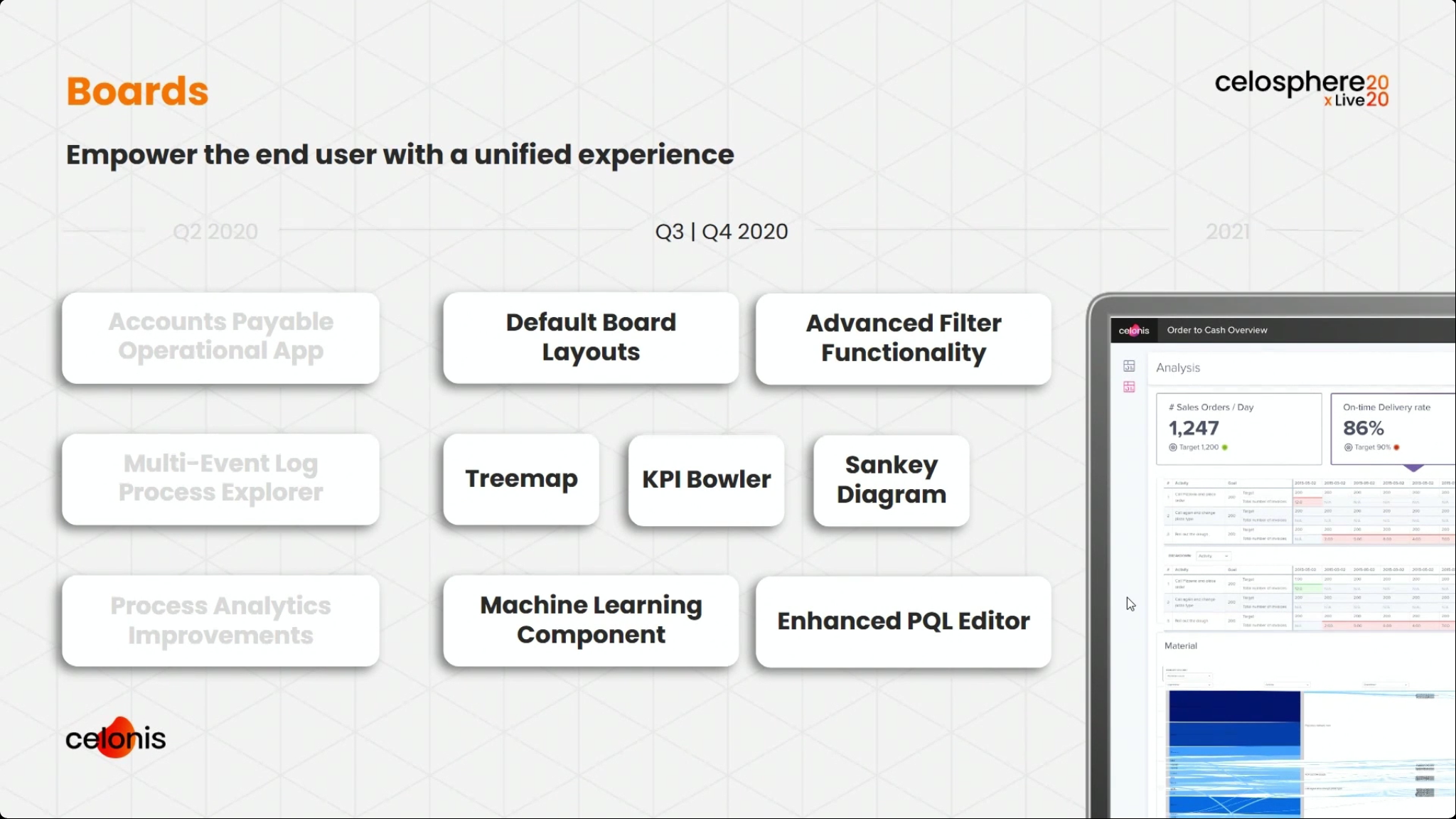
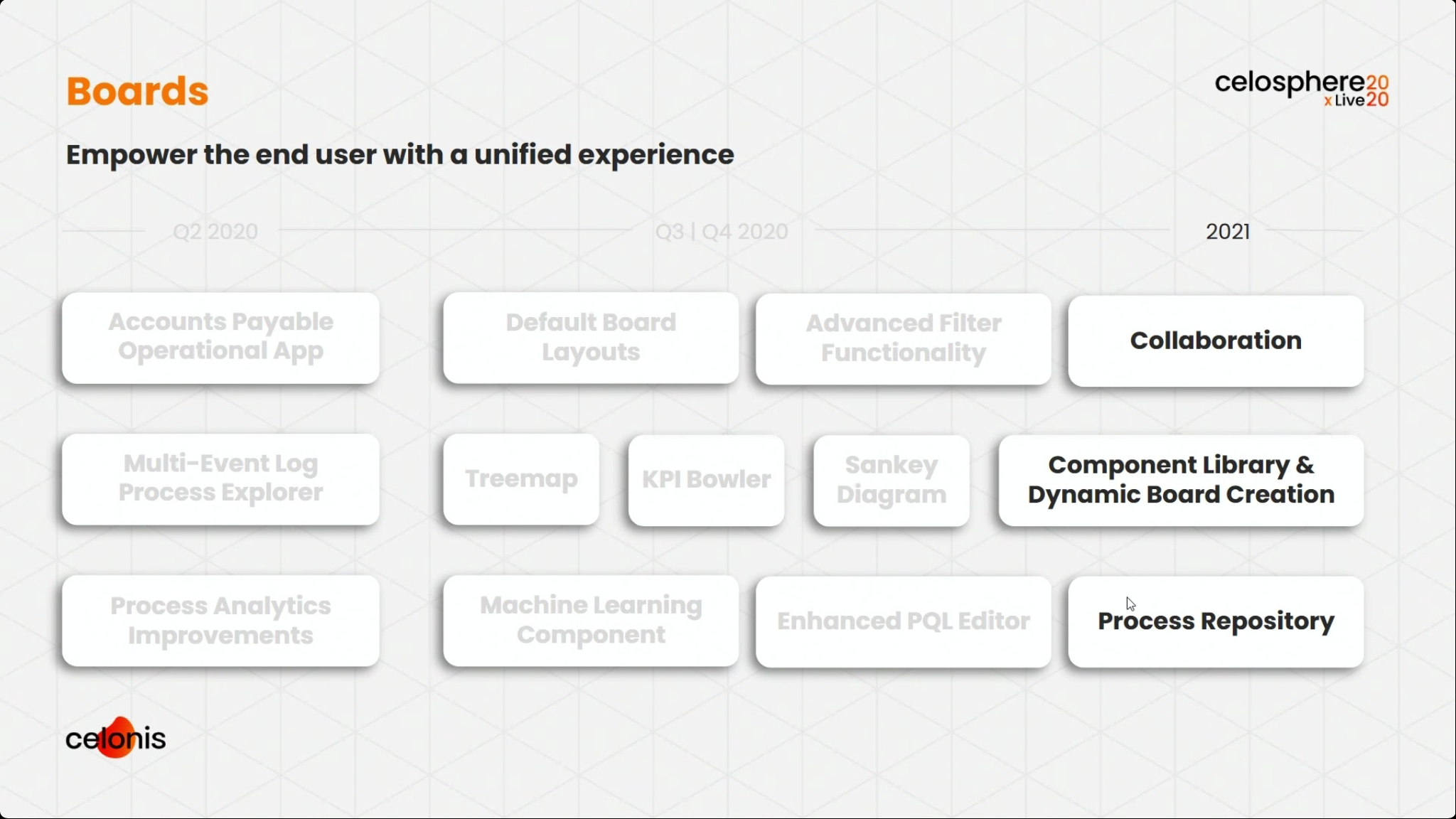
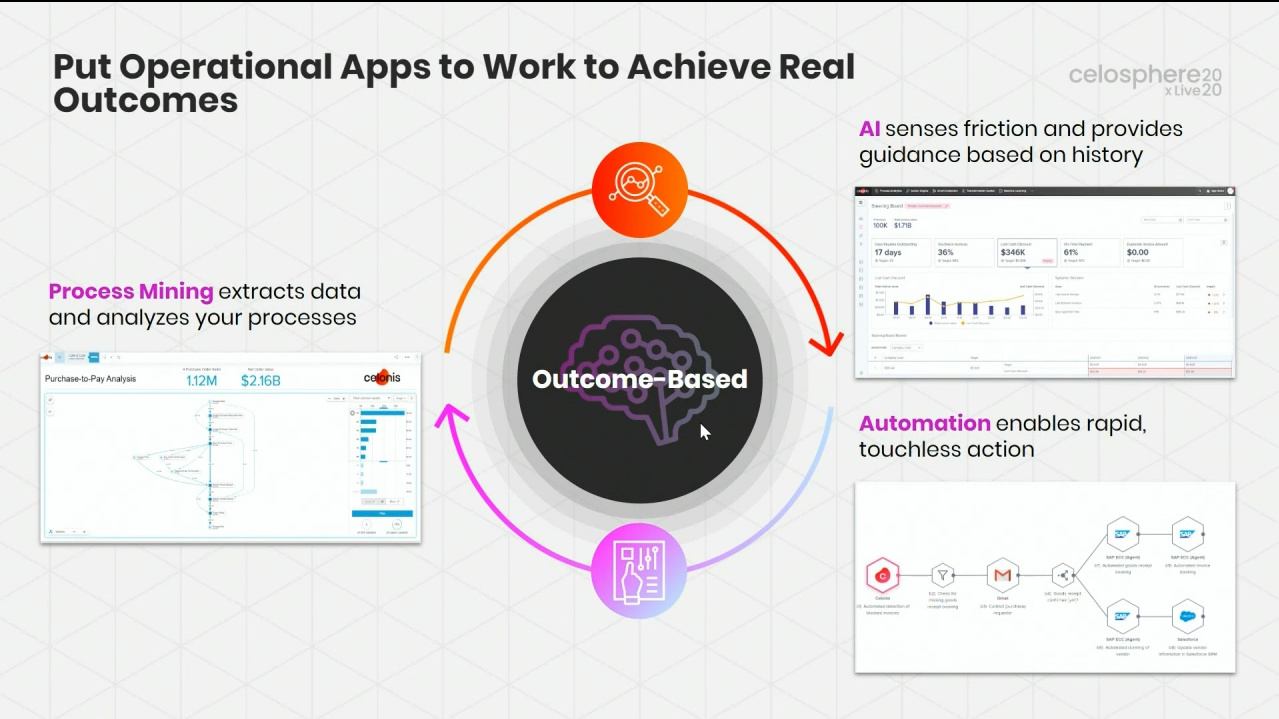
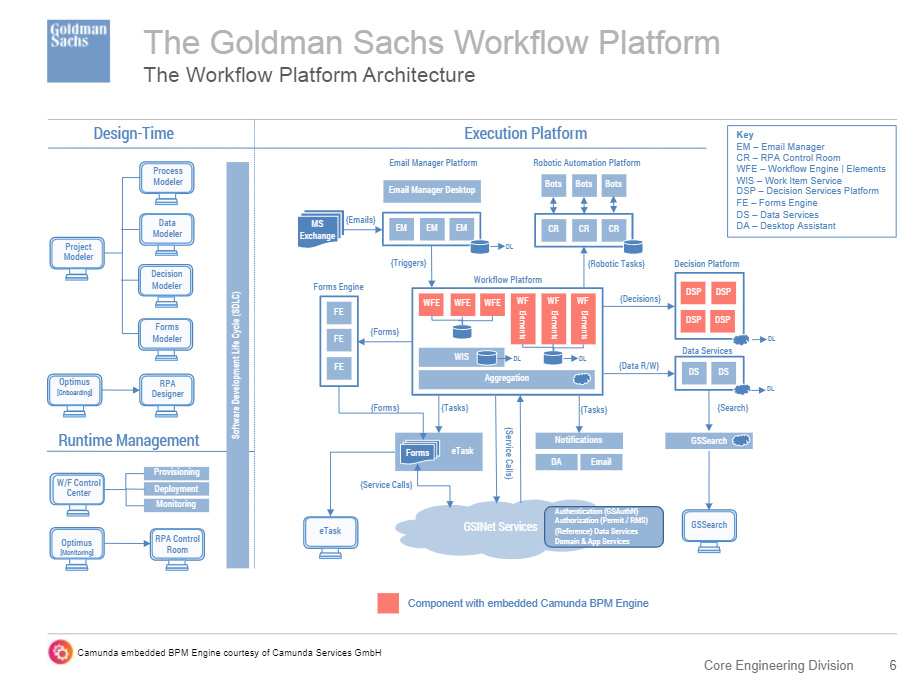
The first day of IBM’s online conference Think 2020 kicked off with a keynote by CEO Arvind Krishna on enterprise technology for digital transformation. He’s new to the position of CEO, but has decades of history at IBM, including heading IBM Research and, most recently, the Cloud and Cognitive Computing group. He sees hybrid cloud and AI as the key technologies for enterprises to move forward, and was joined by Rajeev Ronanki, Chief Digital Officer at Anthem, a US healthcare provider, discussing what they’re doing with AI to harness data and provide better insights. Anthem is using Red Hat OpenShift containerization that allows them to manage their AI “supply chain” effectively, working with technology partners to integrate capabilities.
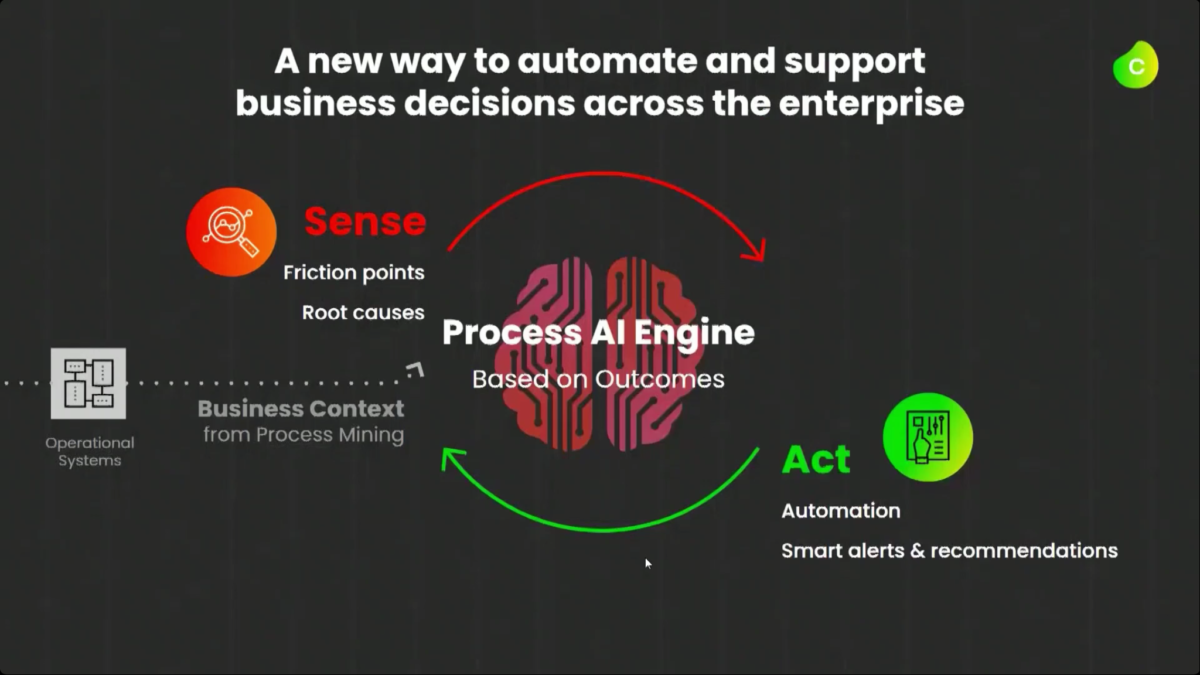
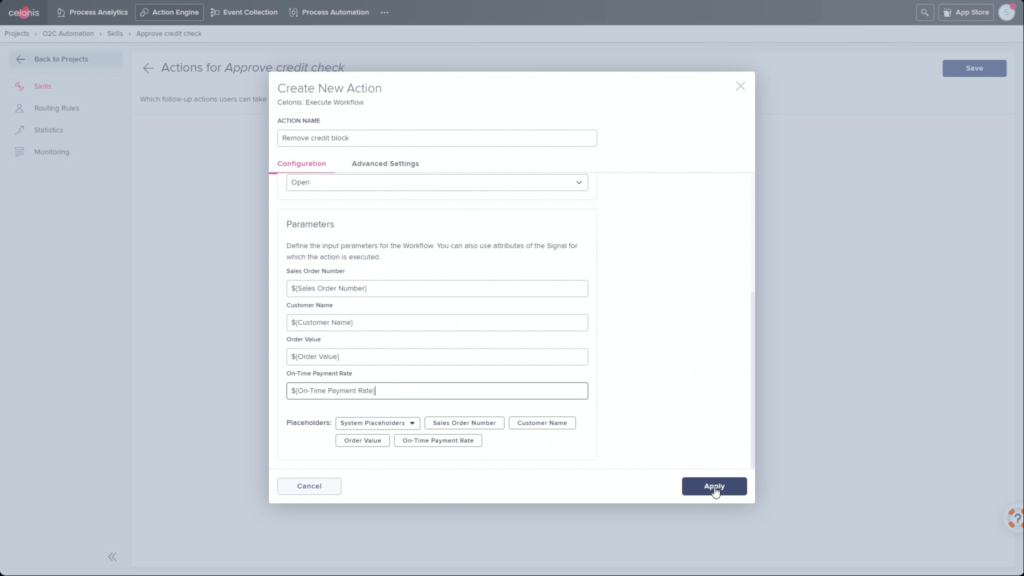
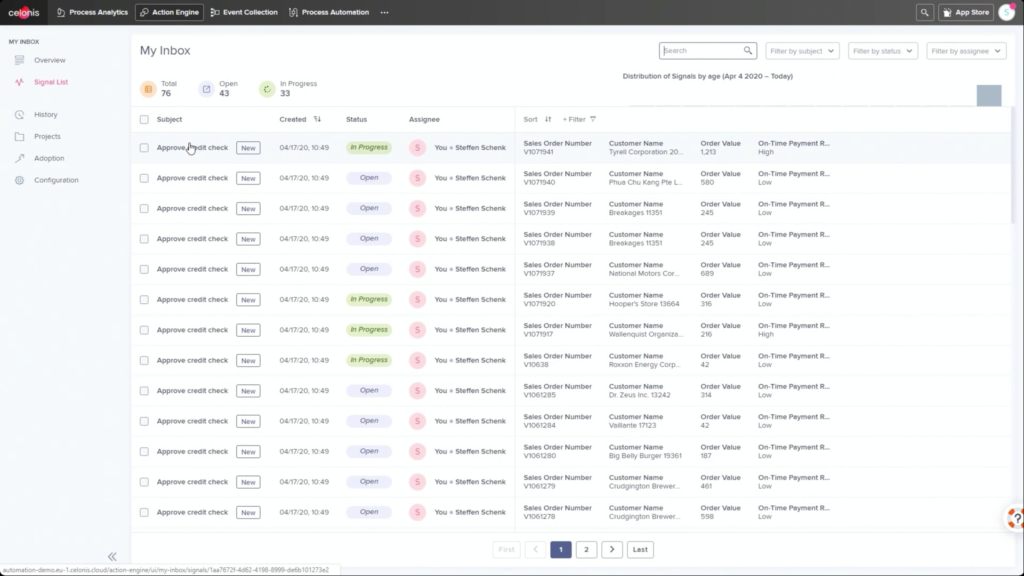
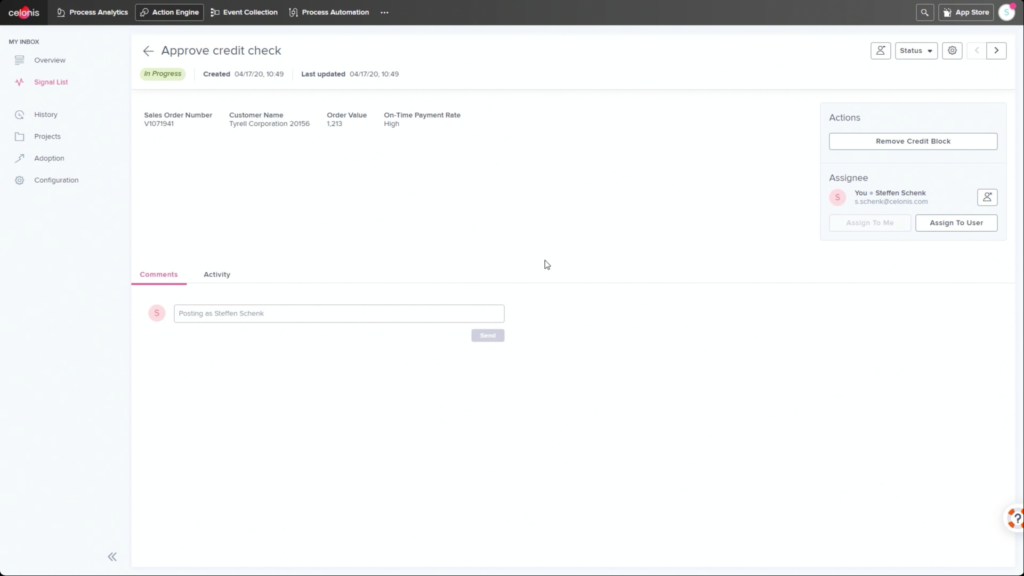
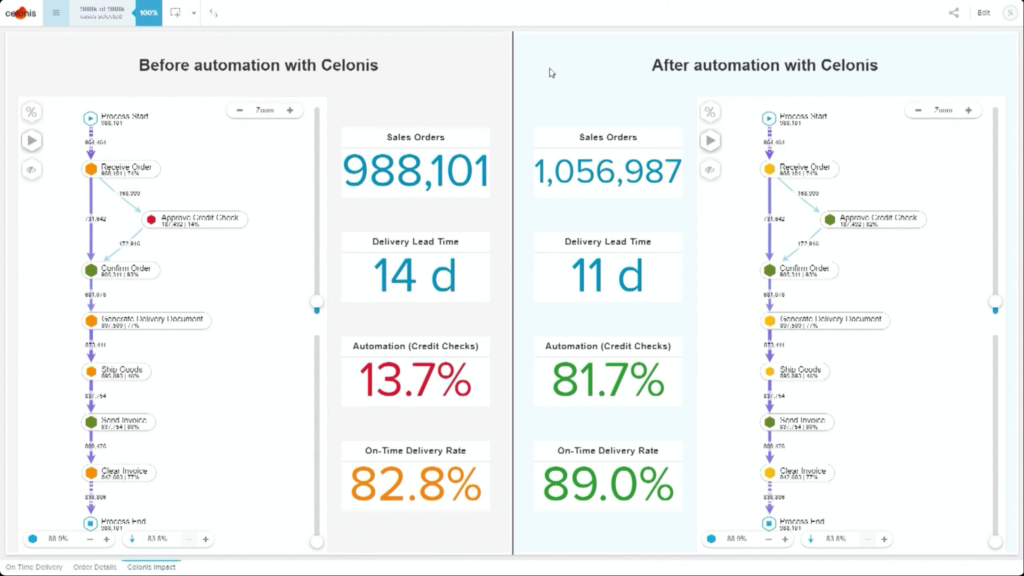
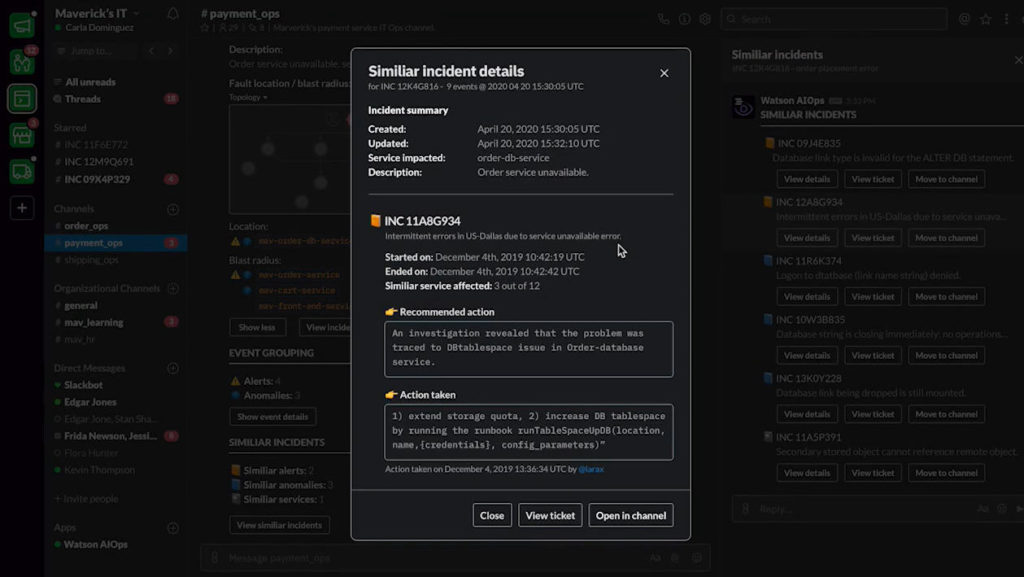
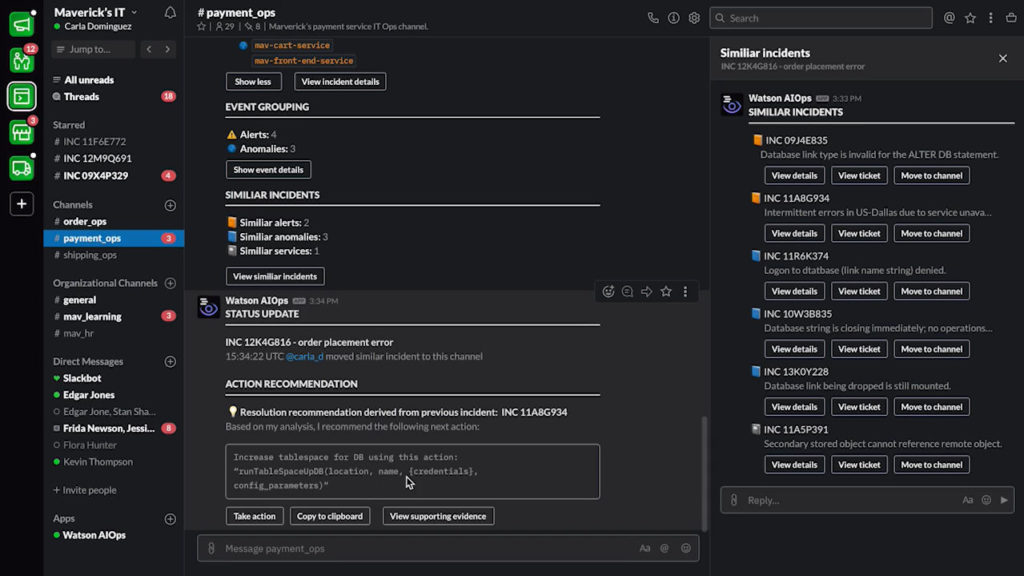
Krishna announced AIOps, which infuses Watson AI into mission-critical IT operations, providing predictions, recommendations and automation to allow IT to get ahead of problems, and resolve them quickly. We had a quick demo of this yesterday during the analyst preview, and it looks pretty interesting: integrating trouble notifications into a Slack channel, then providing recommendations on actions based on previous similar incidents:







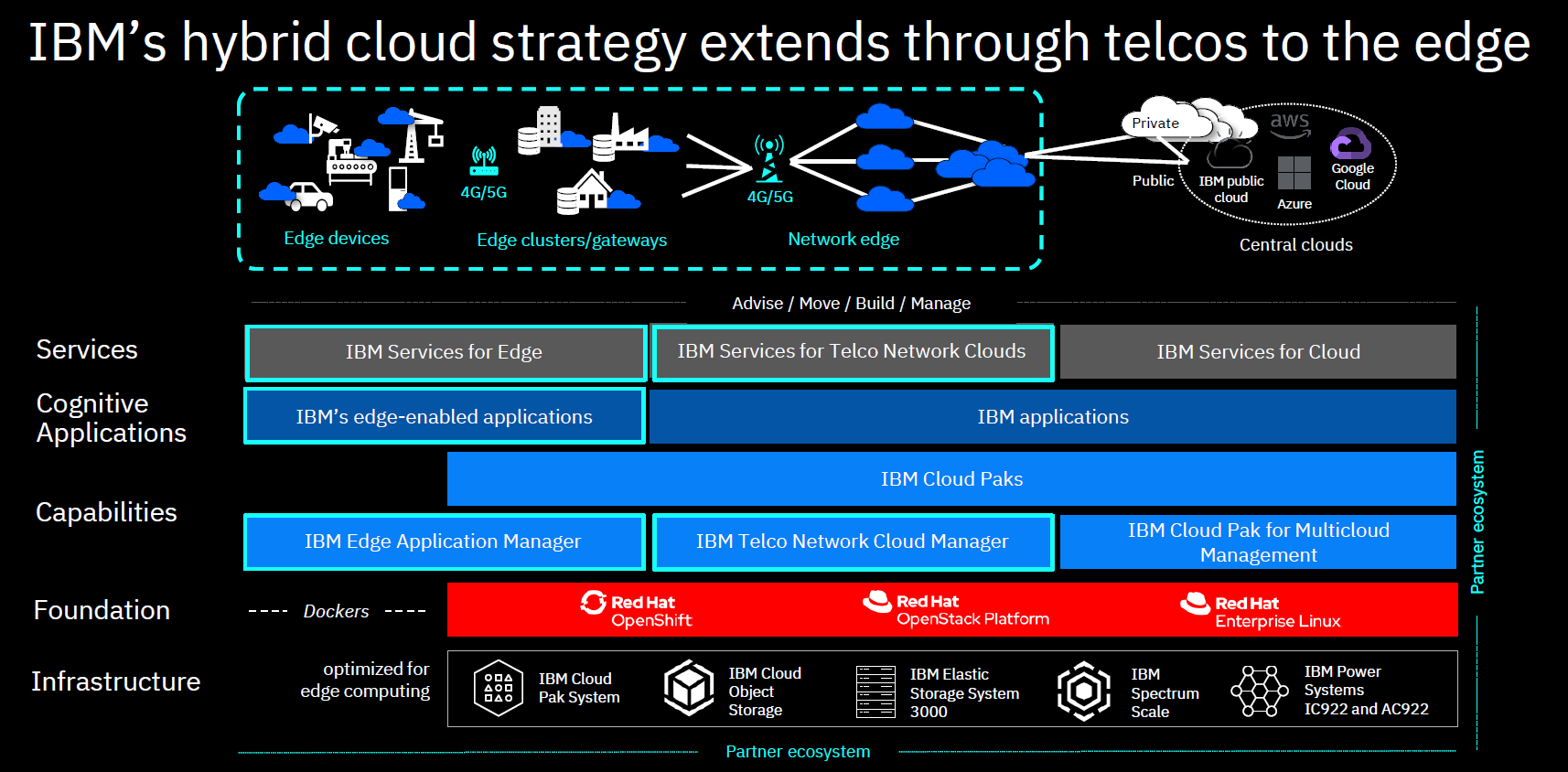
He finished up with an announcement about their new cloud satellite, and edge and telco solutions for cloud platforms. This enables development of future 5G/edge applications that will change how enterprises work internally and with their customers. As our last several weeks of work-from-home has taught us, better public cloud connectivity can make a huge difference in how well a company can continue to do business in times of disruption; in the future, we won’t require a disruption to push us to a distributed workforce.

There was a brief interview with Michelle Peluso, CMO, on how IBM has pivoted to focus on what their customers need: managing during the crisis, preparing for recovery, and enabling transformation along the way. Cloud and AI play a big part of this, with hybrid cloud providing supply chain resiliency, and AI to better adapt to changing circumstances and handle customer engagement. I completely agree with one of her key points: things are not just going back to normal after this crisis, but this is forcing a re-think of how we do business and how things work. Smart companies are accelerating their digital transformation right now, using this disruption as a trigger. I wrote a bit more about this on a guest post on the Trisotech blog recently, and included many of my comments in a webinar that I did for Signavio.

The next session was on scaling innovation at speed with hybrid cloud, featuring IBM President Jim Whitehurst, with a focus on how this can provide the level of agility and resiliency needed at any time, but especially now. Their OpenShift-based hybrid cloud platform will run across any of the major cloud providers, as well as on premise. He announced a technology preview of a cloud marketplace for Red Hat OpenShift-based applications, and had a discussion with Vishant Vora, CTO at Vodafone Idea, India’s largest telecom provider, on how they are building infrastructure for low-latency applications. The session finished up with Hillery Hunter, CTO of IBM Cloud, talking about their public cloud infrastructure: although their cloud platform will run on any vendor’s cloud infrastructure, they believe that their own cloud architecture has some advantages for mission-critical applications. She gave us a few more details about the IBM Cloud Satellite that Arvind Krishna had mentioned in his keynote: a distributed cloud that allows you to run workloads where it makes sense, with simplified and consolidated deployment and monitoring options. They have security and privacy controls built in for different industries, and currently have offerings such as a financial services-ready public cloud environment.
I tuned in briefly to an IDC analyst talking about the new CEO agenda, although targeted at IBM business partners; then a few minutes with the chat between IBM’s past CEO Ginny Rometty and will.i.am. I skipped Amal Clooney‘s talk — she’s brilliant, but there are hours of online video of other presentations that she has made that are likely very similar. If I had been in the audience at a live event, I wouldn’t have walked out of these, but they did not hold my interest enough to watch the virtual versions. Definitely virtual conferences need to be more engaging and offer more targeted content: I attend tech vendor conferences for information about their technology and how their customers are using it, not to hear philanthropic rap singers and international human rights lawyers.

The last session that I attended was on reducing operational cost and ensuring supply chain resiliency, introduced by Kareen Yusuf, General Manager of AI applications. He spoke about the importance of building intelligence into systems using AI, both for managing work in flight through end-to-end visibility, and providing insights on transactions and data. The remainder of the session was a panel hosted by Amber Armstrong, CMO of AI applications, featuring Jonathan Wright who heads up cognitive process re-engineering in supply chains for IBM Global Business Services, Jon Young of Telstra, and Joe Harvey of Southern Company. Telstra (a telecom company) and Southern Company (an energy company) have both seen supply chain disruptions due to the pandemic crisis, but have intelligent supply chain and asset management solutions in place that have allowed them to adapt quickly. IBM Maximo, a long-time asset management product, has been supercharged with IoT data and AI to help reduce downtime and increase asset utilization. This was an interesting panel, but really was just three five-minute interviews with no interaction between the panelists, and no audience questions. If you want to see an example of a much more engaging panel in a virtual conference, check out the one that I covered two weeks ago at CamundaCon Live.
The sessions ran from 11am-3pm in my time zone, with replays starting at 7pm (well, they’re all technically replays because everything was pre-recorded). That’s a much smaller number of sessions than I expected, with many IBM products not really covered, such as the automation products that I normally focus on. I even took a lengthy break in the middle when I didn’t see any sessions that interested me, so only watched about 90 minutes of content. Today was really all cloud and AI, interspersed with some IBM promotional videos, although a few of the sessions tomorrow look more promising.

As I’ve mentioned over the past few weeks of virtual conferences, I don’t like pre-recorded sessions: they just don’t have the same feel as live presentations. To IBM’s credit, they used the fact that they were all pre-recorded to add captions in five or six different languages, making the sessions (which were all presented in English) more accessible to those who speak other languages or who have hearing impairments. The platform is pretty glitchy on mobile: I was trying to watch the video on my tablet while using my computer for blogging and looking up references, but there were a number of problems with changing streams that forced me to move back to desktop video for periods of time. The single-threaded chat stream was completely unusable, with 4,500 people simultaneously typing “Hi from Tulsa” or “you are amazing” (directed to the speaker, presumably).