It’s the last session of the last morning at OpenText Enterprise World 2017 — so might be my last post from here if I skip out on the one session that I have bookmarked for late this afternoon — and I’m sitting in on Mike Kremer of OpenText and Kiran Thakrar of SoluSoft showing SoluSoft’s Active Client Management for Insurance, built on OpenText’s Process Suite and case management. SoluSoft originally built this capability on earlier OpenText products (Global 360) but have moved to the new low-code platform. Their app can be used out of the box, or can be configured to suit a particular environment.
The goal of Active Client Management for Insurance is to provide a 360 view of the client, including data from a variety of sources (typically systems of record for policy administration or claims), content from any repository, open tasks and pending actions, checklists and ad hoc notes. It includes the entire customer lifecycle, from onboarding and underwriting, through policy administration and claims; basically, it’s user work management and CRM in one.
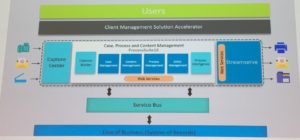 The solution is built on the core of Process Suite, using the full entity modeling AppWorks-style low-code development. It also includes process intelligence for analytics, Capture Center for document capture, and Streamserve for customer communication management. Above all of these OpenText building blocks, SoluSoft has built a client management solution accelerator that (I believe) they can use for a variety of vertical applications; below the OpenText layer is a service bus integration to line of business systems. For insurance, they’ve created a number of business processes and request types corresponding to different parts of the business, such as processing a new application, amending a policy, or initiating a claim; each of these can be configured for the specific customer’s terminology, or disabled if they don’t require specific functions. It’s not completely clear, however, how much of the functionality of other insurance systems might be replaced by this rather than augmented: clearly, the core policy administration system stays as the system of record, but an underwriting or claims system workflow might be replaced by this functionality. Having done this a few times with clients that use systems such as Guidewire, I have to say that this is a non-trivial architectural exercise to decide what parts of the flow happen where, and how to properly interact with other systems.
The solution is built on the core of Process Suite, using the full entity modeling AppWorks-style low-code development. It also includes process intelligence for analytics, Capture Center for document capture, and Streamserve for customer communication management. Above all of these OpenText building blocks, SoluSoft has built a client management solution accelerator that (I believe) they can use for a variety of vertical applications; below the OpenText layer is a service bus integration to line of business systems. For insurance, they’ve created a number of business processes and request types corresponding to different parts of the business, such as processing a new application, amending a policy, or initiating a claim; each of these can be configured for the specific customer’s terminology, or disabled if they don’t require specific functions. It’s not completely clear, however, how much of the functionality of other insurance systems might be replaced by this rather than augmented: clearly, the core policy administration system stays as the system of record, but an underwriting or claims system workflow might be replaced by this functionality. Having done this a few times with clients that use systems such as Guidewire, I have to say that this is a non-trivial architectural exercise to decide what parts of the flow happen where, and how to properly interact with other systems.
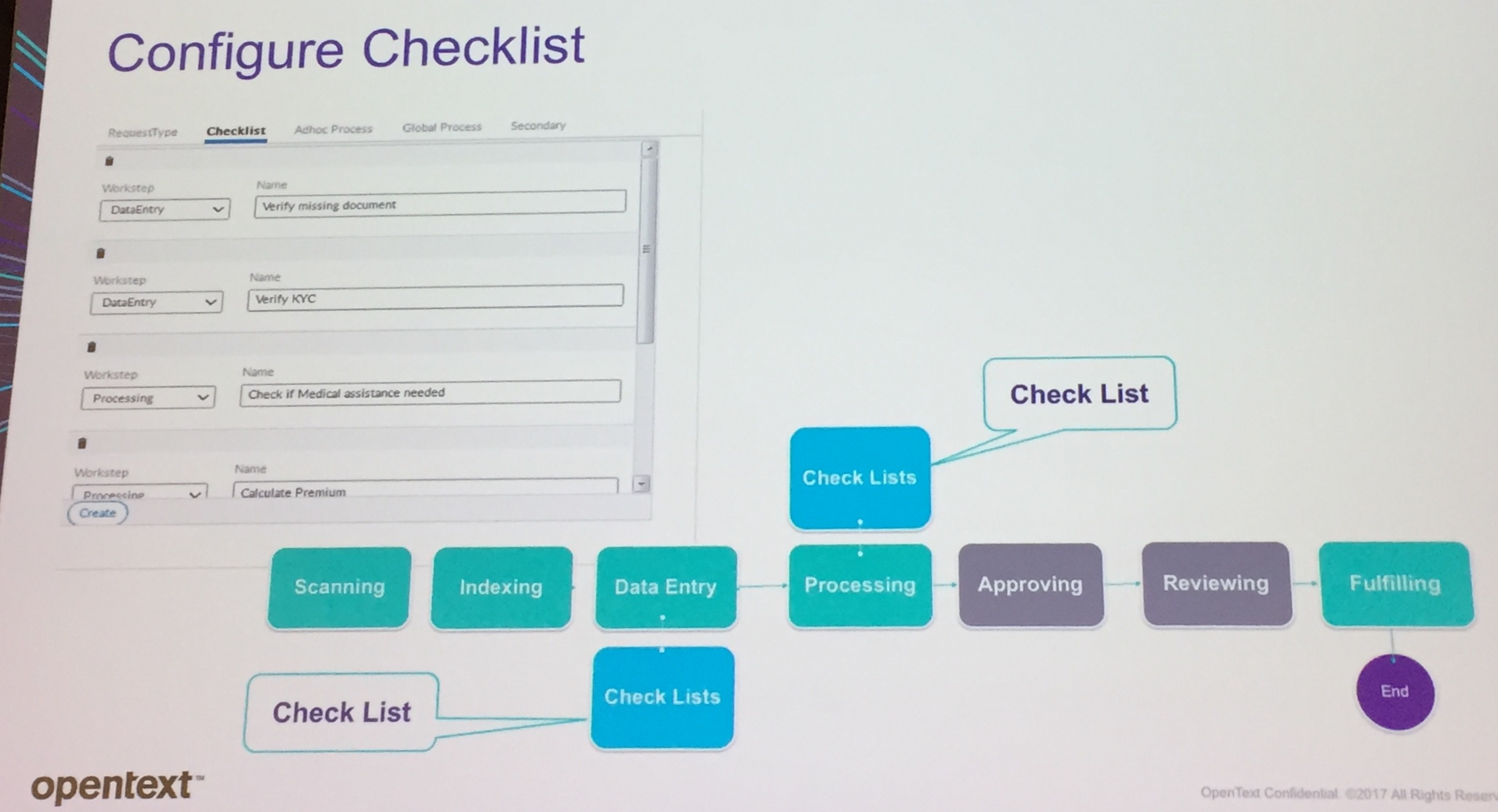
 At the heart is a generic capture-driven workflow: scan, capture, index, data entry, process, approve, review, fulfill. The names of these can be aliased for different vertical applications — their example is that “processing” becomes “underwriting” — and steps can be skipped for a specific request type. Actions that can be performed at any of these work steps are configured using checklists.
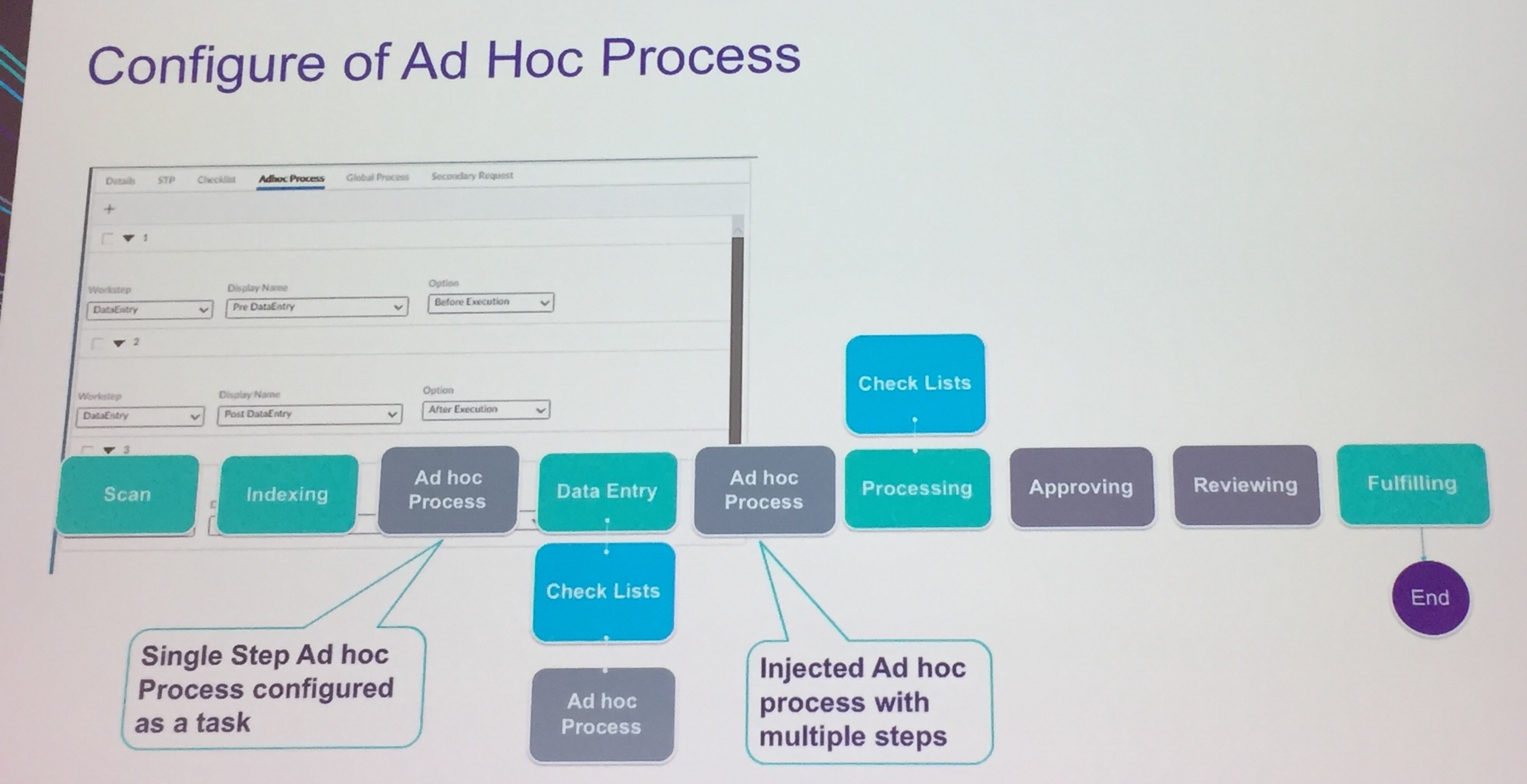
At the heart is a generic capture-driven workflow: scan, capture, index, data entry, process, approve, review, fulfill. The names of these can be aliased for different vertical applications — their example is that “processing” becomes “underwriting” — and steps can be skipped for a specific request type. Actions that can be performed at any of these work steps are configured using checklists.  Ad hoc processes can be attached to steps in this master flow, either a single-step task or a more complex flow, and be executed before, after or in parallel to the pre-defined work step. Ad hoc processes can be created at runtime, and secondary request processes created for certain case types. The ability to make any of these configuration changes is restricted by role security. Relationships between clients, policies, brokers, claims, etc. are managed using folders for customers, policies and advisers, driven by entity modeling in Process Suite (AppWorks Low Code); this ability to establish relationships between all of these types of entities is critical for providing the complete view of the customer. They also have integrated iHub analytics for showing case statistics and workload analysis, as well as more complex analysis of risk or profitability for specific customer groups or policy types.
Ad hoc processes can be attached to steps in this master flow, either a single-step task or a more complex flow, and be executed before, after or in parallel to the pre-defined work step. Ad hoc processes can be created at runtime, and secondary request processes created for certain case types. The ability to make any of these configuration changes is restricted by role security. Relationships between clients, policies, brokers, claims, etc. are managed using folders for customers, policies and advisers, driven by entity modeling in Process Suite (AppWorks Low Code); this ability to establish relationships between all of these types of entities is critical for providing the complete view of the customer. They also have integrated iHub analytics for showing case statistics and workload analysis, as well as more complex analysis of risk or profitability for specific customer groups or policy types.


Although SoluSoft built some of this in custom code. a lot of the application is built directly in the OpenText low code development environment provided by Process Suite. This means that it’s fast to configure or even do some basic customizations, with the caveats that I mentioned earlier about deciding on where some parts of the workflow might happen when you have existing LOB systems that already do that. It also provides them with native mobile support through AppWorks, rather than having to build a separate mobile application.
We saw the version focused on insurance, but they also have flavors for pensions, financial services, government, healthcare and education. However, it appears that there is an existing legacy of the Global 360-based application, and it’s not clear how long it will take for this new AppWorks version to make its way into the market.