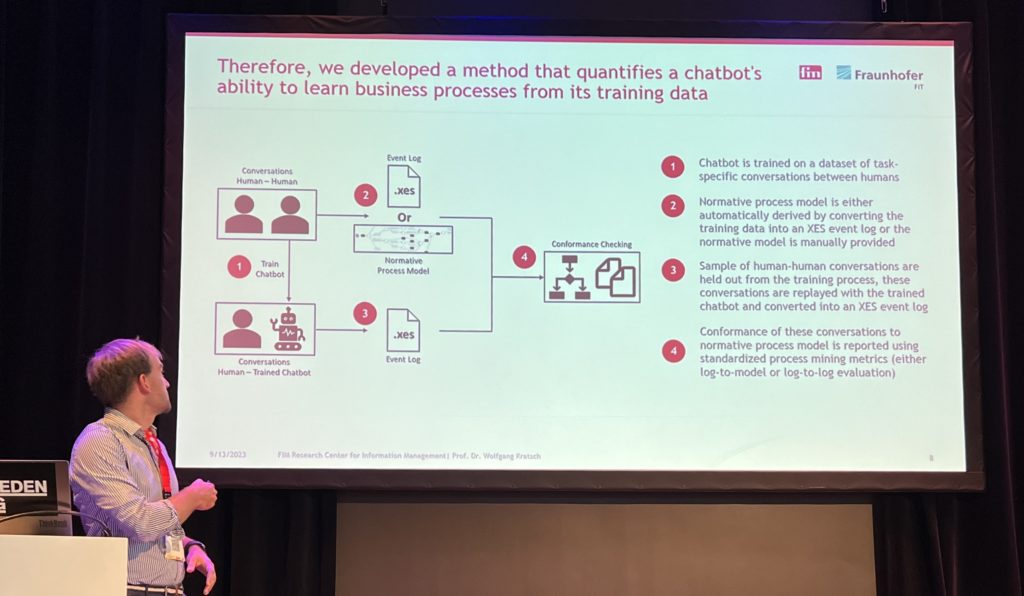
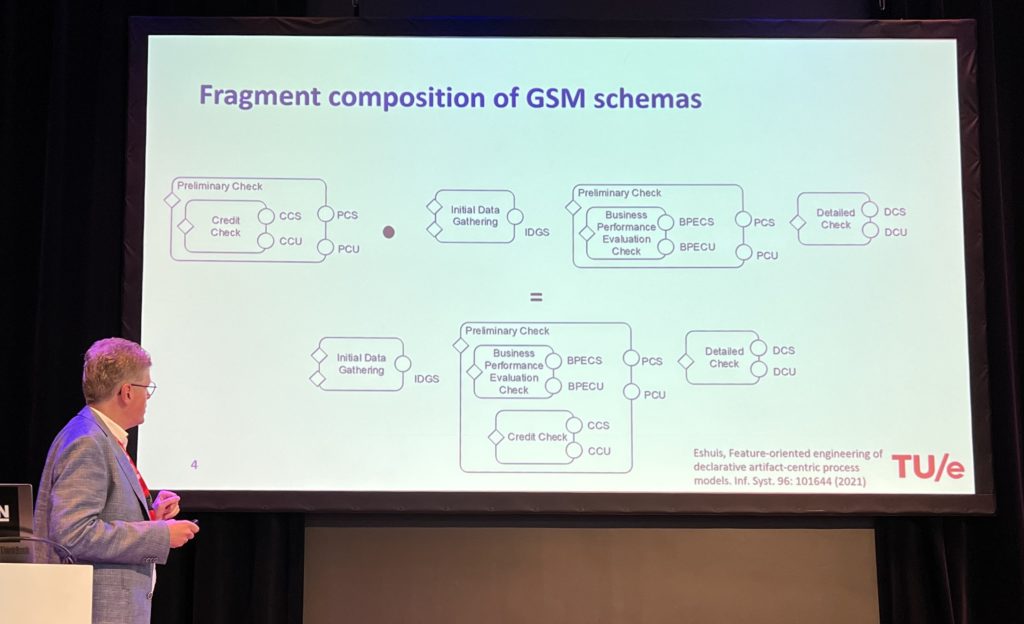
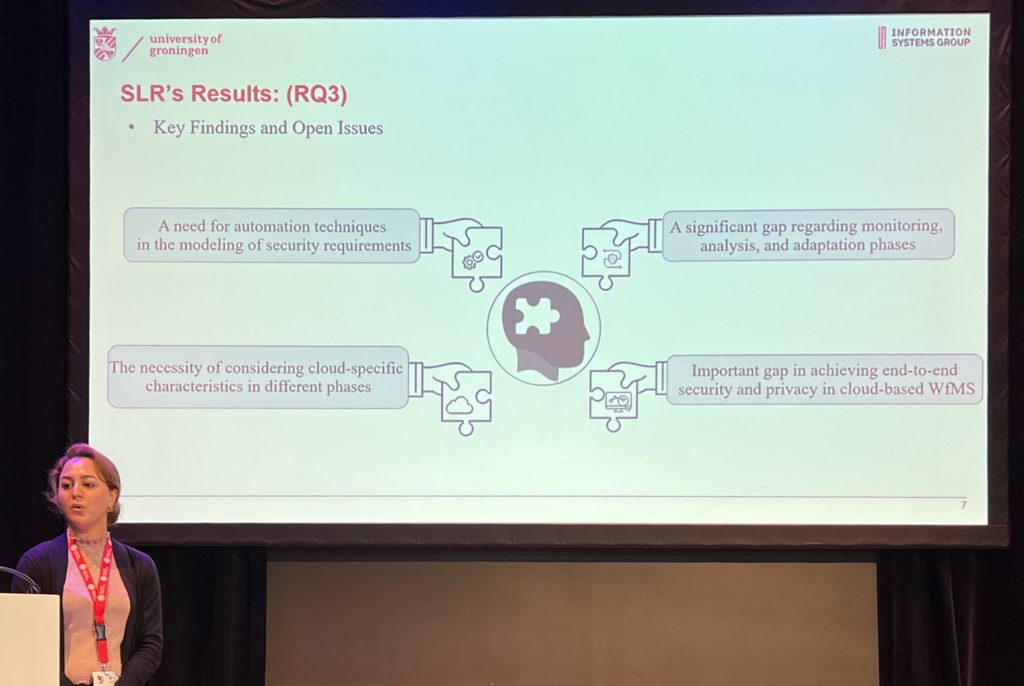
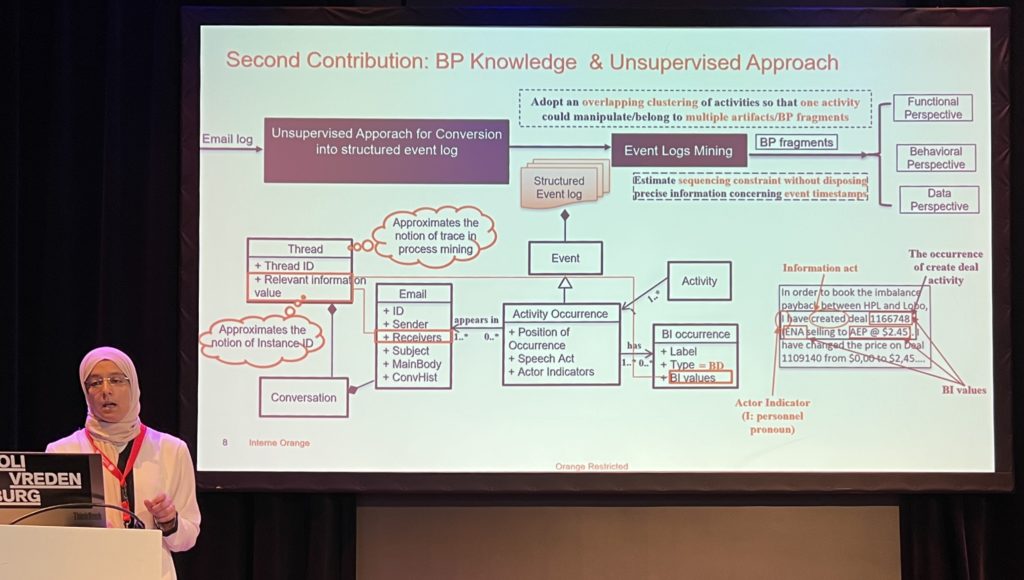
After the keynote, I attended the Journal First session, which was a collection of eight 15-minute presentations of papers that have been accepted by relevant journals (in contrast to the regular research papers seen in other presentations). It was like the speed-dating of presentations and I didn’t take any specific notes, but did snap a few photos and linked to the papers where I could find them. Lots of interesting ideas, in small snippets.
The second day of the main conference kicked off with a keynote by Marta Kwiatkowska, Professor of Computer Science at Oxford, on AI and machine learning in BPM. She started with some background on AI and deep learning, and linked this to automated process model discovery (process mining), simulation, what-if analysis, predictions and automated decisions. She posed the question of whether we should be worried about the safety of AI decisions, or at least advance the formal methods for provable guarantees in machine learning, and the more challenging topic of formal verification for neural networks.
She has done significant research on robustness for neural networks and the development of provable guarantees, and offered some recent directions of these applications in BPM. She showed the basics of calculating and applying robustness guarantees for image and video classification, and also for text classification/replacement. In the BPM world, she discussed using language-type prediction models for event logs, evaluating the robustness of decision functions to causal interventions, and the concept of reinforcement learning for teaching agents how to choose an action.
As expected, much of the application of AI to process execution is to the decisions within processes – automating decisions, or providing “next best action” recommendations to human actors at a particular process activity. Safety assurances and accountability/explainability are particularly important in these scenarios.
Given the popularity of AI in general, a very timely look at how it can be applied to BPM in ways that maintain robustness and correctness.
I’ve been remiss with blogging the past couple of months, mostly because I’ve been involved in several pretty cool projects that have been keeping me busy. As I mentioned in yesterday’s post, I recently wrote a paper for Flowable about end-to-end automation and the business model transformation that it enabled.
I’ve been working on a video series for a process mining startup, Futuroot, which specializes in process intelligence for SAP systems. We’re doing these as conversational videos between me and a couple of the Futuroot team, each video about 20 minutes of free-ranging conversation. In the first episode, I talk with Rajee Bhattacharyya, Futuroot’s Chief Innovation Officer, and Anand Argade, their Director of Product Development. Here’s a short teaser from the video:
You can sign up here to watch the entire video and be notified of the future ones as they are published. We’ve just recorded the second one, so watch for that coming out soon.
I recently created a paper for Flowable on end-to-end automation, including a look at how the Gartner “hyperautomation” term fits into the picture. End-to-end automation is really about enabling business model transformation, not just making the same widgets a little bit faster, and I walk through some of the steps and technologies that are required.
Check it out on the Flowable site at the link above (registration required).
I have a long history working with insurance companies on their digitization and process automation initiatives, and there’s a lot of interesting things happening in insurance as a result of the pandemic and associated lockdown: more automation of underwriting and claims, increased use of digital documents instead of paper, and trying to discover the “new normal” in insurance processes as we move to a world that will remain, at least in part, with a distributed workforce for some time in the future. At the same time, there is an increase in some types of insurance business activity, and decreases in other areas, requiring reallocation of resources.
On June 17, I’ll be presenting a webinar for ABBYY on some of the ways that insurance companies can navigate this perfect storm of business and societal disruption using digital intelligence technologies including smarter content capture and process intelligence. Here’s what we plan to cover:
Helping you understand how to transform processes, instead of falling into the trap of just automating existing, often broken processes
Getting your organization one step further of your competition with the latest content intelligence capabilities that help transform your customer experience and operational effectiveness
Completely automating your handling of essential documents used in onboarding, policy underwriting, claims, adjudication, and compliance
Having direct overview of your processes as living in real time to discover where bottlenecks and repetitions occur, where content needs to be processed, and where automation can be most effective
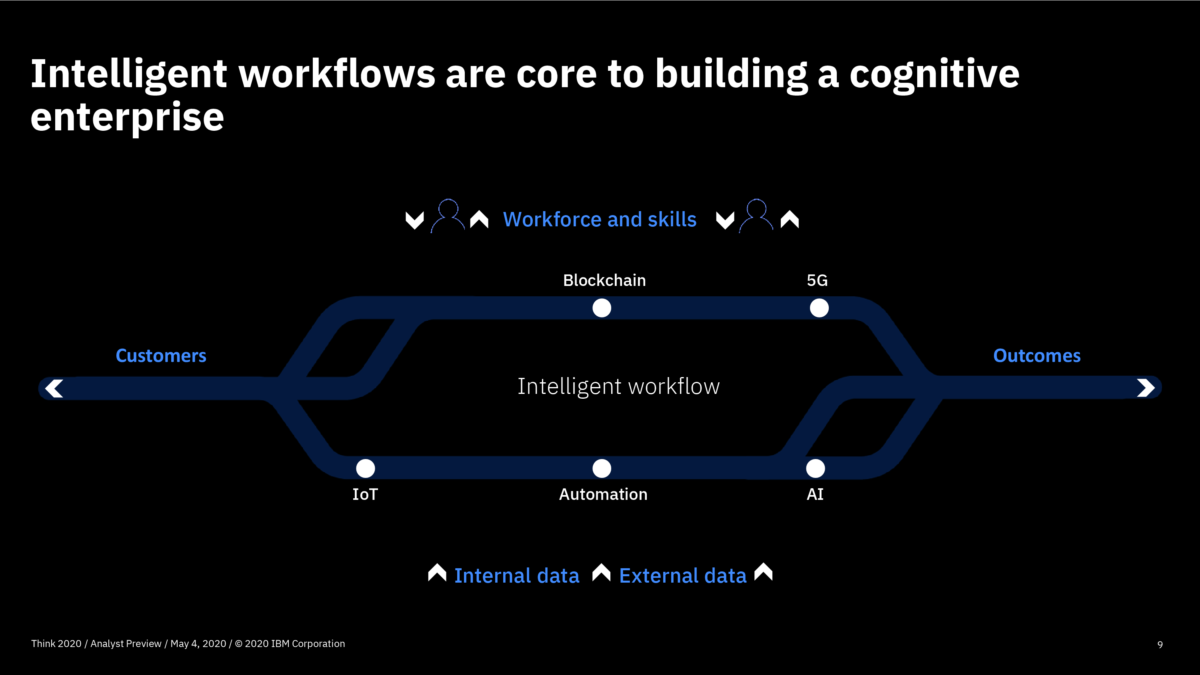
This is now my third day attending IBM’s online Think 2020 conference: I attended the analyst preview on Monday, then the first day of the conference yesterday. We started the day with Mark Foster, SVP of IBM Services, giving a keynote on building resilient and smarter businesses. He pointed out that we are in uncertain times, and many companies are still figuring out whether to freeze new initiatives, or take advantage of this disruption to build smarter businesses that will be more competitive as we emerge from the pandemic. This message coming from a large software/services vendor is a bit self-serving, since they are probably seeing this quarter’s sales swirling down the drain, but I happen to agree with him: this is the time to be bold with digital transformation. He referred to what can be done with new technologies as “business process re-engineering on steroids”, and said that it’s more important than ever to build more intelligent processes to run our organizations. Resistance to change is at a particular low point, except (in my experience) at the executive level: workers and managers are embracing the new ways of doing things, from virtual experiences to bots, although they may be hampered somewhat by skittish executives that think that change at a time of disruption is too risky, while holding the purse strings of that change.
He had a discussion with Svein Tore Holsether, CEO of Yara, a chemical company with a primary business in nitrogen crop fertilizers. They also building informational platforms for sustainable farming, and providing apps such as a hyper-local farm weather app in India, since factors such as temperature and rainfall can vary greatly due to microclimates. The current pandemic means that they can no longer have their usual meetings with farmers — apparently a million visits per year — but they are moving to virtual meetings to ensure that the farmers still have what the need to maximize their crop yields.
Foster was then joined by Carol Chen, VP of Global Lubricants Marketing at Shell. She talked about the specific needs of the mining industry for one of their new initiatives, leveraging the ability to aggregate data from multiple sources — many of them IoT — to make better decisions, such as predictive maintenance on equipment fleets. This allows the decisions about a mining operation to be made from a digital twin in the home office, rather than just by on-site operators who may not have the broader context: this improves decision quality and local safety.
He then talked to Michael Lindsey, Chief Transformation and Strategy Officer at PepsiCo North America, with a focus on their Frito-Lay operations. This operation has a huge fleet, controlling the supply chain from the potato farms to the store. Competition has driven them to have a much broader range of products, in terms of content and flavors, to maintain their 90%+ penetration into the American household market. Previously, any change would have been driven from their head office, moving out to the fringes in a waterfall model. They now have several agile teams based on IBM’s Garage Methodology that are more distributed, taking input from field associates to know what it needed at each point in the supply chain, driving need from the store shelves back to the production chain. The pandemic crisis means that they have had to move their daily/weekly team meetings online, but that has actually made them more inclusive by not requiring everyone to be in the same place. They have also had to adjust the delivery end of their supply chains in order to keep up the need for their products: based on my Facebook feed, there are a lot of people out there eating snacks at home, fueling a Frito-Lay boom.
Rob Thomas, SVP of IBM Cloud & Data Platform, gave a keynote on how AI and automation is changing how companies work. Some of this was a repeat from what we saw in the analyst preview, plus some interviews with customers including Mirco Bharpalania, Head of Data & Analytics at Lufthansa, and Mallory Freeman, Director of Data Science and Machine Learning in the Advanced Analytics Group at UPS. In both cases, they are using the huge amount of data that they collect — about airplanes and packages, respectively — to provide better insights into their operations, and perform optimization to improve scheduling and logistics.
He was then joined by Melissa Molstad, Director of Common Platforms, Stata Strategy & Vendor Relations at PayPal. She spoke primarily about their AI-driven chatbots, with the virtual assistants handling 1.4M conversations per month. This relieves the load on customer service agents, especially for simple and common queries, which is especially helpful now that they have moved their customer service to distributed home-based work.
He discussed AIOps, which was already announced yesterday by Arvind Krishna; I posted a bit about that in yesterday’s post including some screenshots from a demo that we saw at the analyst preview on Monday. They inserted the video of Jessica Rockwood, VP of Development for Hybrid Multicloud Management, giving the same demo that we saw on Monday, worthwhile watching if you want to hear the entire narrative behind the screenshots.
Thomas’ last interview segment was with Aaron Levie, CEO of Box, and Stewart Butterfield, CEO of Slack, both ecosystem partners of IBM. Interesting that they chose to interview Slack rather than use it as an engagement channel for the conference attendees. ¯_(ツ)_/¯ They both had interesting things to add on how work is changing with the push to remote cloud-based work, and the pressures on their companies for helping a lot of customers to move to cloud-based collaboration all at once. There seems to be a general agreement (I also agree) that work is never going back to exactly how it was before, even when there is no longer a threat from the pandemic. We are learning new ways of working, and also learning that things that companies thought could not be done effectively — like work from home — actually work pretty well. Companies that embrace the changes and take advantage of the disruption can jump ahead on their digital transformation timeline by a couple of years. One of them quoted Roy Amara’s adage that “we tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run”; as distributed work methods, automation and the supporting technology get a foothold now, they will have profound changes on how work will be done in the future. This is not going to be about which organizations have the most money to spend: it will hinge on the ability and will to embrace AI and automation to remake intelligent end-to-end processes. Software vendors will need to accept the fact that customers want to do best-of-breed assembly of services from different vendors, meaning that the vendors that integrate into a standard fabric are going to do much better in the long run.
I switched over to the industry/customer channel to hear a conversation between Donovan Roos, VP of Enterprise Automation at US Bank, and Monique Ouellette, VP of Global Digital Workplace Solutions at IBM. She invited us at the beginning to submit questions, so this may have been one of the few sessions that has not been prerecorded, although they never seemed to take any audience questions so I’m not sure. Certainly much lower audio and video quality than most of the prerecorded sessions. US Bank has implemented Watson AI-driven chatbots for internal and external service requests, and has greatly reduced wait times for requests where a chatbot can assist with self-service rather than waiting for a live agent. Roos mentioned that they really make use of the IBM-curated content that comes as part of the Watson platform, and many of the issues are resolved without even hitting internal knowledge bases. Like many other banks during the current crisis, they have had to scale up their ability to process small business loans; although he had some interesting things to mention about how they scaled up their customer service operations using AI chatbots, I would also be interested to hear how they have scaled up the back-end processes. He did mention that you need to clean up your business processes first before starting to apply AI, but no specifics.
I stayed on the industry channel for a presentation on AI in insurance by Sandeep Bajaj, CIO of Everest Re Group. I do quite a bit of work with insurance companies as a technical strategist/architect so have some good insights into how their business works, and Bajaj started with the very accurate statement that insurance is an information-driven industry, both in the sense of standard business information, but also IoT and telematics especially for vehicle and P&C coverage. This provides great opportunities for better insights and decisions based on AI that leverages that data. He believes that AI is no longer optional in insurance because of the many factors and data sources involved in decisions. He did discuss the necessity to review and improve your business processes to find opportunities for AI: it’s not a silver bullet, but needs to have relatively clean processes to start with — same message that we heard from US Bank in the previous presentation. Everest reviewed some of their underwriting processes and split the automation opportunities between robotic process automation and AI, although I would have thought that using them together, as well as other automation technologies, could provide a better solution. They used an incremental approach, which let them see results sooner and feed back initial results into ongoing development. One side benefit is that they now capture much more of the unstructured information from each submission, whereas previously they would only capture the information entered for those submissions that led to business; this allows them to target their marketing and pricing accordingly. They’re starting to use AI-driven processes for claims first notice of loss (FNOL is a classic claims problem) in addition to underwriting, and are seeing operational efficiency improvements as well as better accuracy and time to market. Looking ahead, he sees that AI is here to stay in their organization since it’s providing proven value. Really good case study; worth watching if you’re in the insurance business and want to see how AI can be applied effectively.
IBM had to pivot to a virtual format relatively quickly since they already had a huge in-person conference scheduled for this time, but they could have done better both for content and format given the resources that they have available to pour into this event. Everyone is learning from this experience of being forced to move events online, and the smaller companies are (not surprisingly) much more agile in adapting to this new normal. I’ll be at the virtual Appian World next week, then will write an initial post on virtual conference best — and worst — practices that I’ve seen over the five events that I’ve attended recently. In the weeks following that, I’ll be attending Signavio Live, PegaWorld iNspire and DecisionCAMP, so will have a chance to add on any new things that I see in those events.
The first day of IBM’s online conference Think 2020 kicked off with a keynote by CEO Arvind Krishna on enterprise technology for digital transformation. He’s new to the position of CEO, but has decades of history at IBM, including heading IBM Research and, most recently, the Cloud and Cognitive Computing group. He sees hybrid cloud and AI as the key technologies for enterprises to move forward, and was joined by Rajeev Ronanki, Chief Digital Officer at Anthem, a US healthcare provider, discussing what they’re doing with AI to harness data and provide better insights. Anthem is using Red Hat OpenShift containerization that allows them to manage their AI “supply chain” effectively, working with technology partners to integrate capabilities.
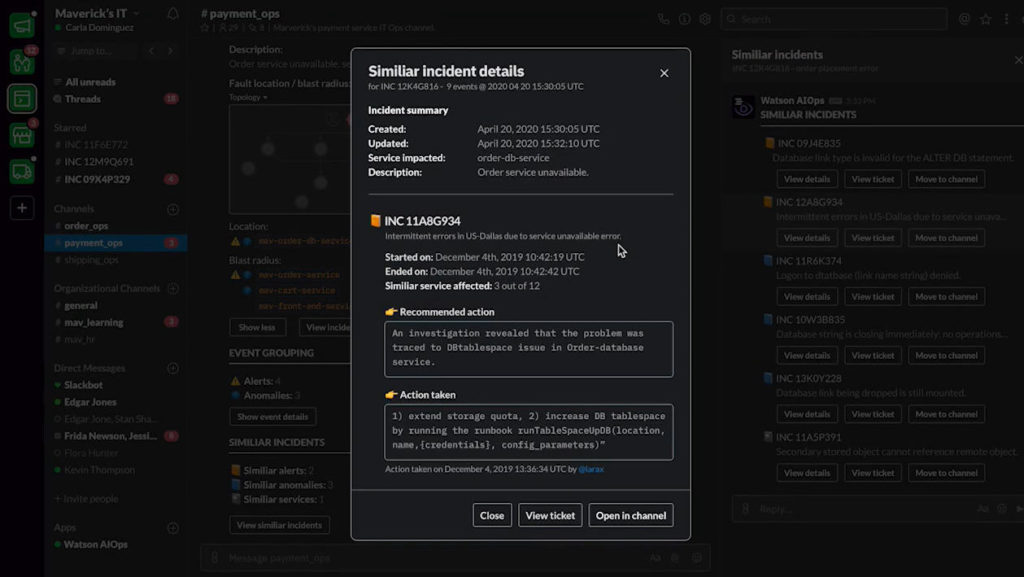
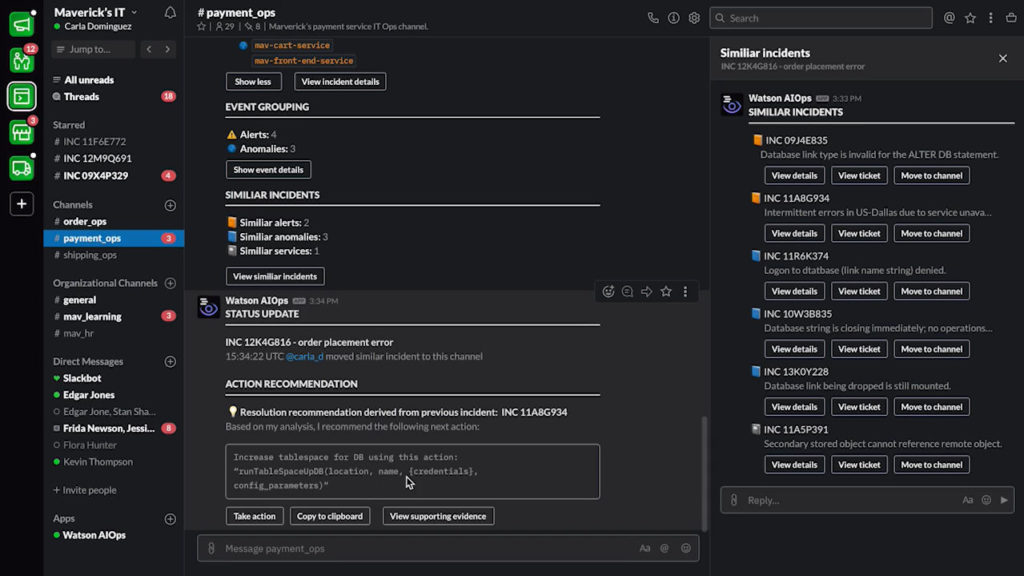
Krishna announced AIOps, which infuses Watson AI into mission-critical IT operations, providing predictions, recommendations and automation to allow IT to get ahead of problems, and resolve them quickly. We had a quick demo of this yesterday during the analyst preview, and it looks pretty interesting: integrating trouble notifications into a Slack channel, then providing recommendations on actions based on previous similar incidents:
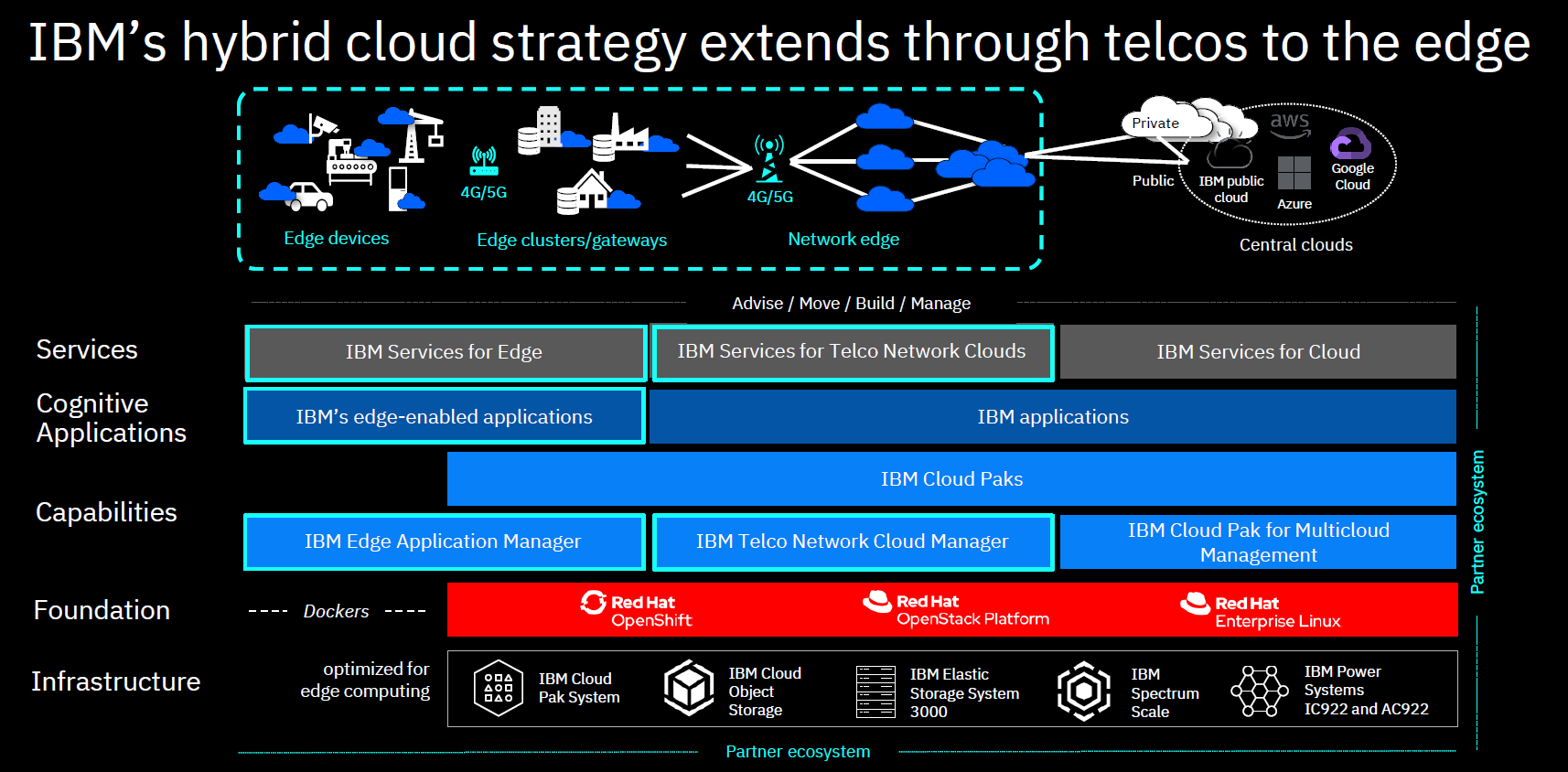
He finished up with an announcement about their new cloud satellite, and edge and telco solutions for cloud platforms. This enables development of future 5G/edge applications that will change how enterprises work internally and with their customers. As our last several weeks of work-from-home has taught us, better public cloud connectivity can make a huge difference in how well a company can continue to do business in times of disruption; in the future, we won’t require a disruption to push us to a distributed workforce.
There was a brief interview with Michelle Peluso, CMO, on how IBM has pivoted to focus on what their customers need: managing during the crisis, preparing for recovery, and enabling transformation along the way. Cloud and AI play a big part of this, with hybrid cloud providing supply chain resiliency, and AI to better adapt to changing circumstances and handle customer engagement. I completely agree with one of her key points: things are not just going back to normal after this crisis, but this is forcing a re-think of how we do business and how things work. Smart companies are accelerating their digital transformation right now, using this disruption as a trigger. I wrote a bit more about this on a guest post on the Trisotech blog recently, and included many of my comments in a webinar that I did for Signavio.
The next session was on scaling innovation at speed with hybrid cloud, featuring IBM President Jim Whitehurst, with a focus on how this can provide the level of agility and resiliency needed at any time, but especially now. Their OpenShift-based hybrid cloud platform will run across any of the major cloud providers, as well as on premise. He announced a technology preview of a cloud marketplace for Red Hat OpenShift-based applications, and had a discussion with Vishant Vora, CTO at Vodafone Idea, India’s largest telecom provider, on how they are building infrastructure for low-latency applications. The session finished up with Hillery Hunter, CTO of IBM Cloud, talking about their public cloud infrastructure: although their cloud platform will run on any vendor’s cloud infrastructure, they believe that their own cloud architecture has some advantages for mission-critical applications. She gave us a few more details about the IBM Cloud Satellite that Arvind Krishna had mentioned in his keynote: a distributed cloud that allows you to run workloads where it makes sense, with simplified and consolidated deployment and monitoring options. They have security and privacy controls built in for different industries, and currently have offerings such as a financial services-ready public cloud environment.
I tuned in briefly to an IDC analyst talking about the new CEO agenda, although targeted at IBM business partners; then a few minutes with the chat between IBM’s past CEO Ginny Rometty and will.i.am. I skipped Amal Clooney‘s talk — she’s brilliant, but there are hours of online video of other presentations that she has made that are likely very similar. If I had been in the audience at a live event, I wouldn’t have walked out of these, but they did not hold my interest enough to watch the virtual versions. Definitely virtual conferences need to be more engaging and offer more targeted content: I attend tech vendor conferences for information about their technology and how their customers are using it, not to hear philanthropic rap singers and international human rights lawyers.
The last session that I attended was on reducing operational cost and ensuring supply chain resiliency, introduced by Kareen Yusuf, General Manager of AI applications. He spoke about the importance of building intelligence into systems using AI, both for managing work in flight through end-to-end visibility, and providing insights on transactions and data. The remainder of the session was a panel hosted by Amber Armstrong, CMO of AI applications, featuring Jonathan Wright who heads up cognitive process re-engineering in supply chains for IBM Global Business Services, Jon Young of Telstra, and Joe Harvey of Southern Company. Telstra (a telecom company) and Southern Company (an energy company) have both seen supply chain disruptions due to the pandemic crisis, but have intelligent supply chain and asset management solutions in place that have allowed them to adapt quickly. IBM Maximo, a long-time asset management product, has been supercharged with IoT data and AI to help reduce downtime and increase asset utilization. This was an interesting panel, but really was just three five-minute interviews with no interaction between the panelists, and no audience questions. If you want to see an example of a much more engaging panel in a virtual conference, check out the one that I covered two weeks ago at CamundaCon Live.
The sessions ran from 11am-3pm in my time zone, with replays starting at 7pm (well, they’re all technically replays because everything was pre-recorded). That’s a much smaller number of sessions than I expected, with many IBM products not really covered, such as the automation products that I normally focus on. I even took a lengthy break in the middle when I didn’t see any sessions that interested me, so only watched about 90 minutes of content. Today was really all cloud and AI, interspersed with some IBM promotional videos, although a few of the sessions tomorrow look more promising.
As I’ve mentioned over the past few weeks of virtual conferences, I don’t like pre-recorded sessions: they just don’t have the same feel as live presentations. To IBM’s credit, they used the fact that they were all pre-recorded to add captions in five or six different languages, making the sessions (which were all presented in English) more accessible to those who speak other languages or who have hearing impairments. The platform is pretty glitchy on mobile: I was trying to watch the video on my tablet while using my computer for blogging and looking up references, but there were a number of problems with changing streams that forced me to move back to desktop video for periods of time. The single-threaded chat stream was completely unusable, with 4,500 people simultaneously typing “Hi from Tulsa” or “you are amazing” (directed to the speaker, presumably).
I had an early look at IBM’s virtual Think conference by attending the analyst preview today, although I will need to embargo the announcements until they are officially released at the main event tomorrow. The day kicked off with a welcome from Harriet Fryman, VP of Analyst Relations, followed by a welcome from IBM President Jim Whitehurst before the first presentation from Mark Foster, SVP of Services, on building resilient and smarter businesses. Foster led with the need for innovative and intelligent workflow automation, and a view of end-to-end processes, and how work patterns are changing and will continuing to change as we emerge from the current pandemic crisis.
Whitehurst returned to discuss their offerings in hybrid cloud environments, including both the platforms and the applications that run on those platforms. There’s no doubt that every company right now is laser-focused on the need for cloud environments, with many workforces being distributed to a work-from-home model. IBM offers Cloud Paks, containerized software solutions to get organizations up and running quickly. Red Hat OpenShift is a big part of their strategy for cloud.
Hillery Hunter, CTO and VP of Cloud Infrastructure, followed on with more details on the IBM cloud. She doubled down on their commitment to open source, and to how they have hardened open source cloud tools for enterprise readiness. If enterprises want to be flexible, scalable and resilient, they need to move their core business operations to the public cloud, and IBM hopes to provide the platform for them to do that. This should not just be lift-and-shift from on-premise systems, but this is an opportunity to modernize systems and operations. The impacts of COVID-19 have shown the cracks in many companies’ mission-critical capabilities and infrastructure, and the smart ones will already be finding ways to push towards more modern cloud platforms to allow them to weather business disruptions and gain a competitive edge in the future.
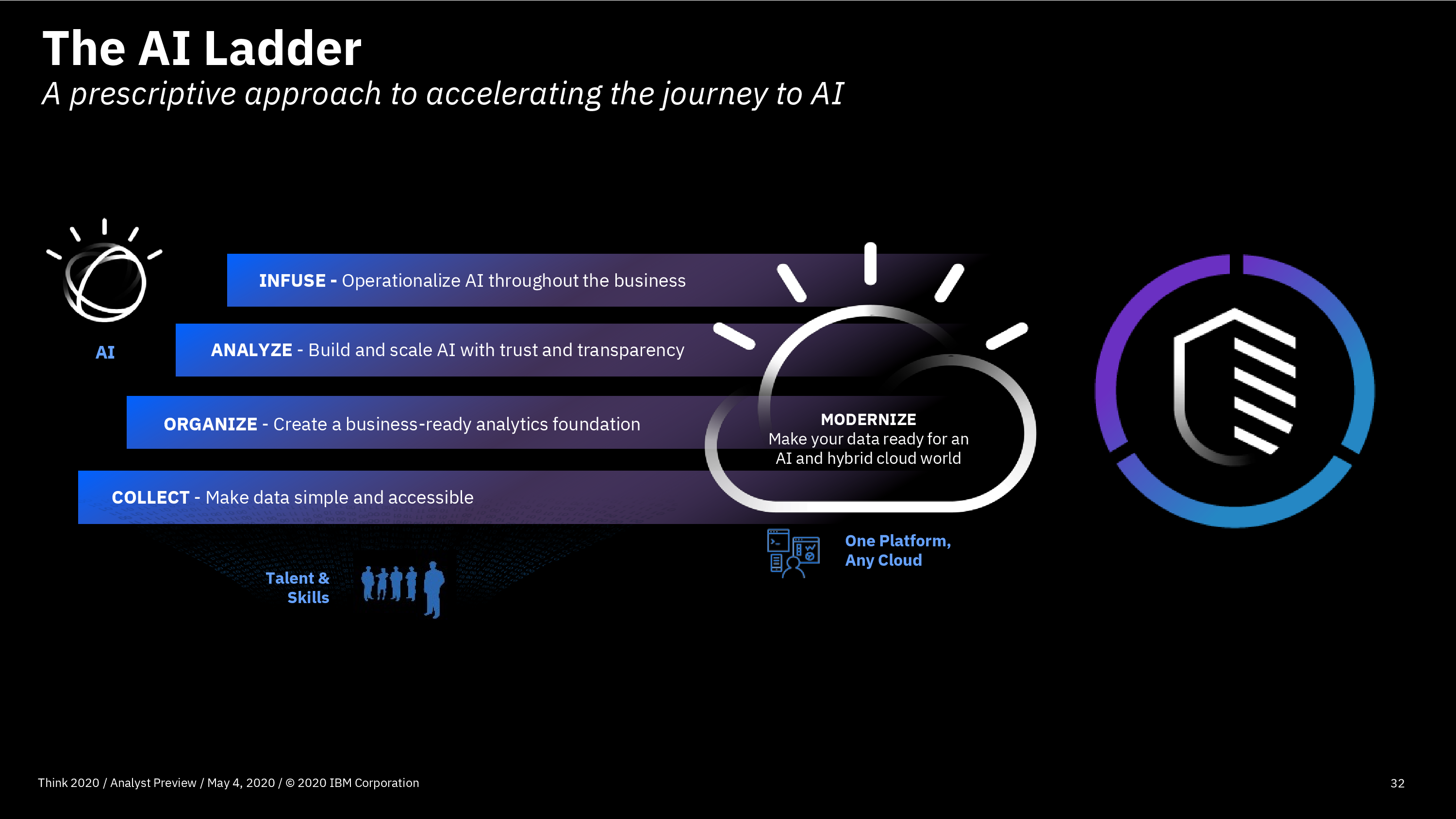
Rob Thomas, SVP of IBM Cloud and Data Platform, gave a presentation on AI and automation, and how they are changing the way that organizations work. By infusing AI into workflows, companies can outperform their competitors by 165% in terms of revenue growth and productivity, plus improve their ability to innovate and manage change. For example, in a very short time, they’ve deployed Watson Assistant to field questions about COVID-19 using information published by the CDC and other sources. Watson Anywhere combines with their Cloud Pak for Data to allow Watson AI to be applied to any of your data sources. He finished with a reminder of the “AI Ladder” which is basically a roadmap for adding operationalized AI.
The final session was with Dario Gil, Director of IBM Research. IBM has been an incredible source of computing research over 75 years, and employs 3,000 researchers in 19 locations. Some of this research is around the systems for high-performance computing, including their support for the open source Linux community. Other research is around AI, having moved from narrow AI to broader multi-domain AI, with more general AI with improved learning and autonomy in the future. They are also investing in quantum computing research, and he discussed this convergence of bits, neurons and qubits for things such as AI-assisted programming and accelerated discovery.
This was all pre-recorded presentations, which is not as compelling as live video, and there was no true discussion platform or even live Q&A; these are the two common complaints that I am having with many of the virtual conferences. I’m expecting that the next two days of the main IBM Think event will be more of the same format. I’ll be tuning in for some of the sessions of the main event, starting with CEO Arvind Krishna tomorrow morning.
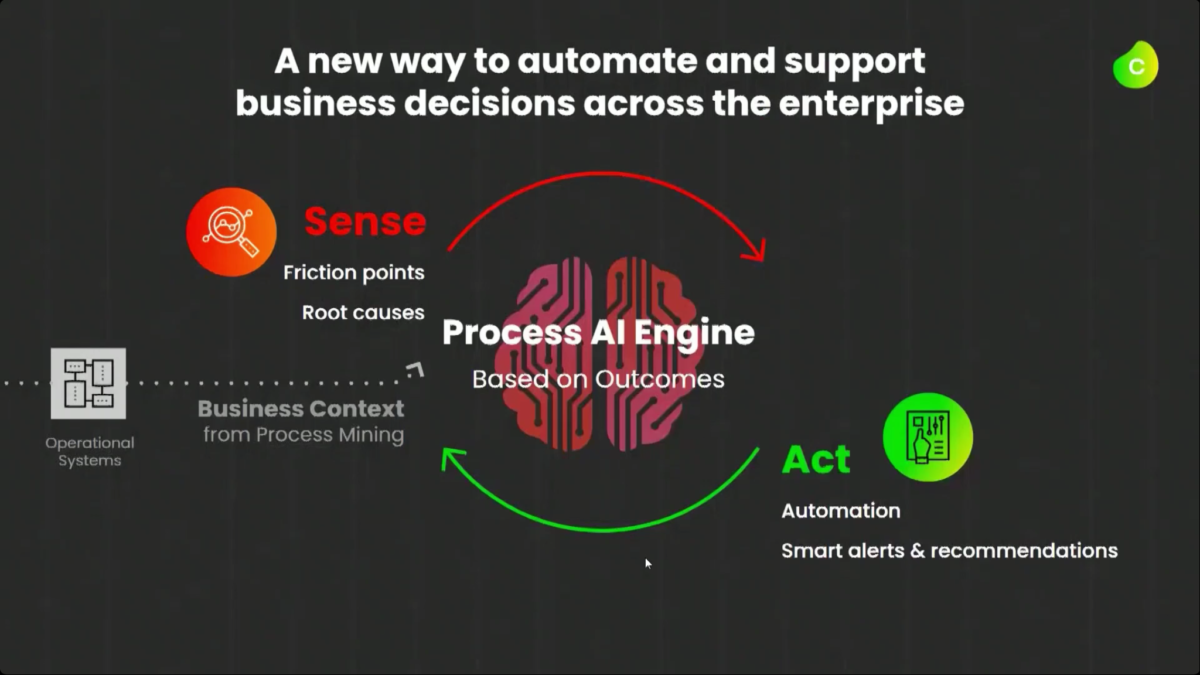
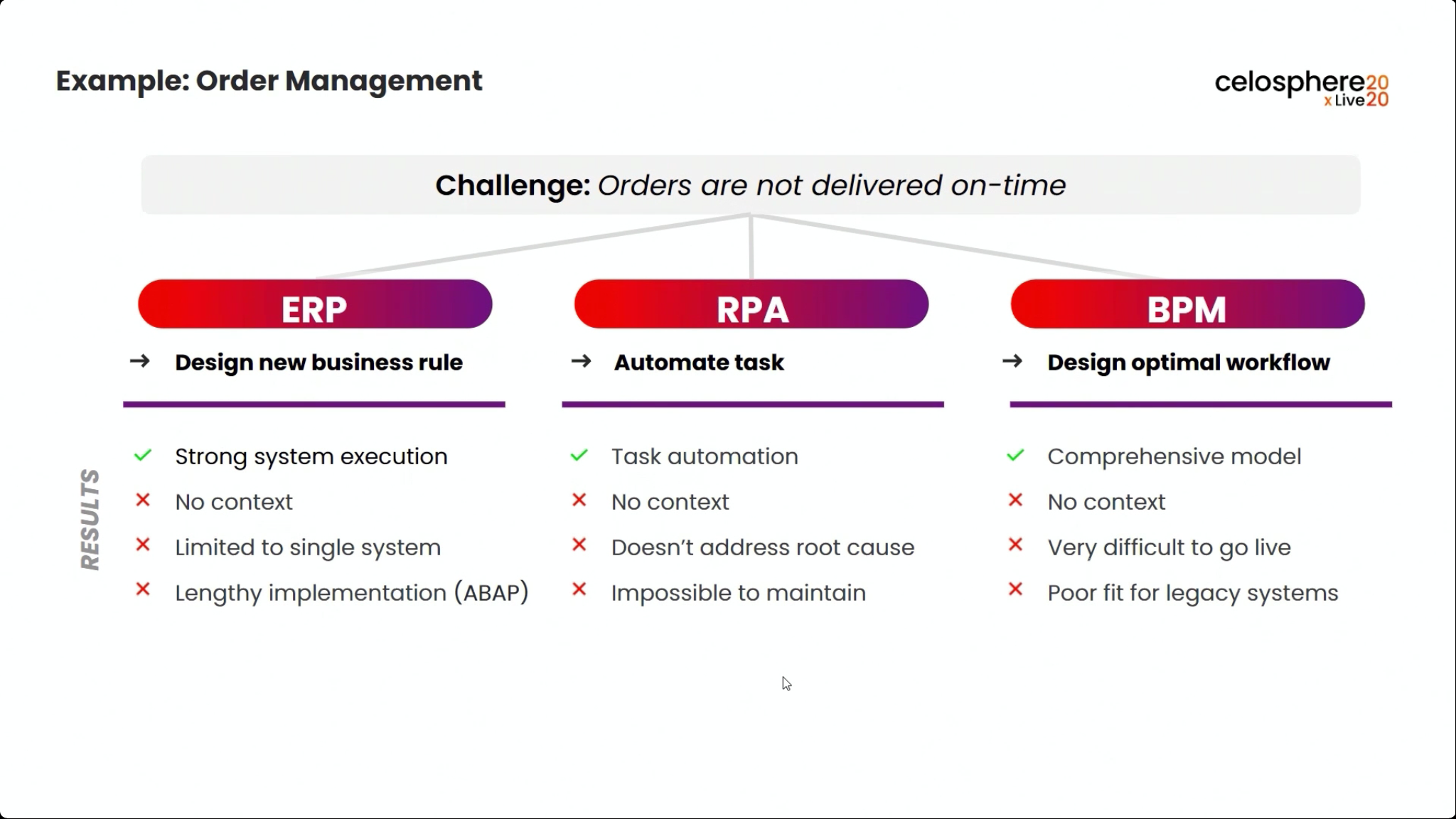
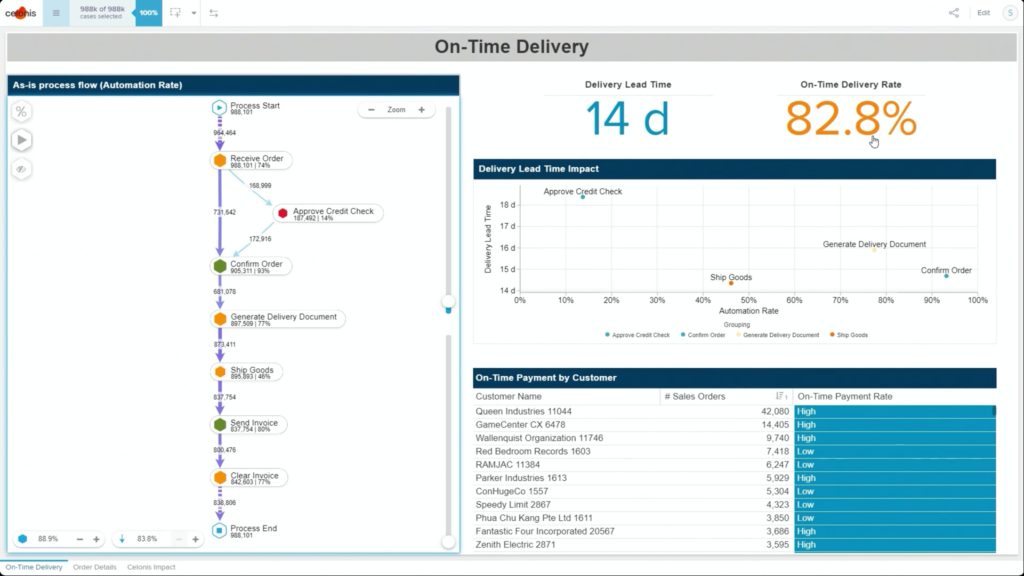
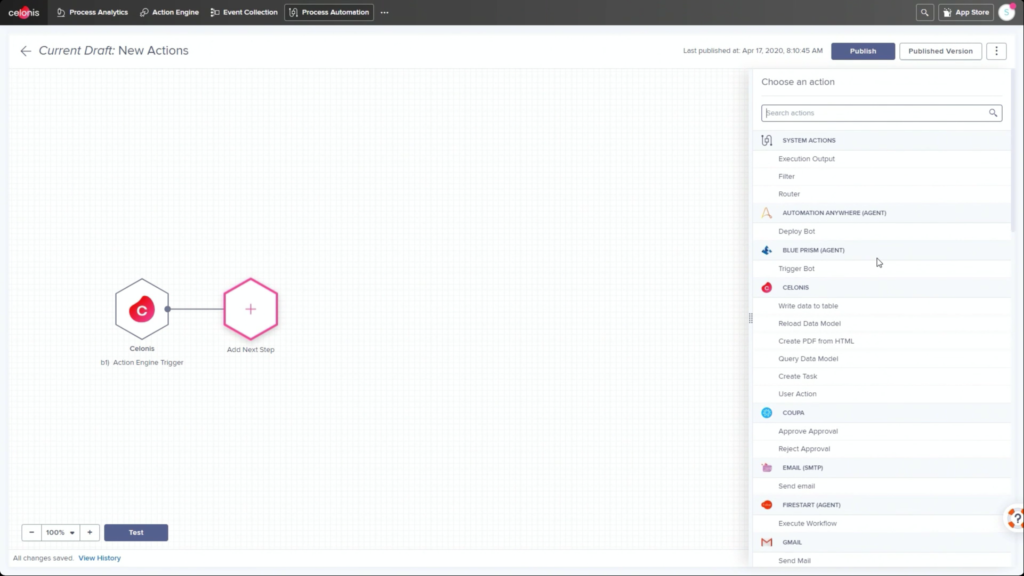
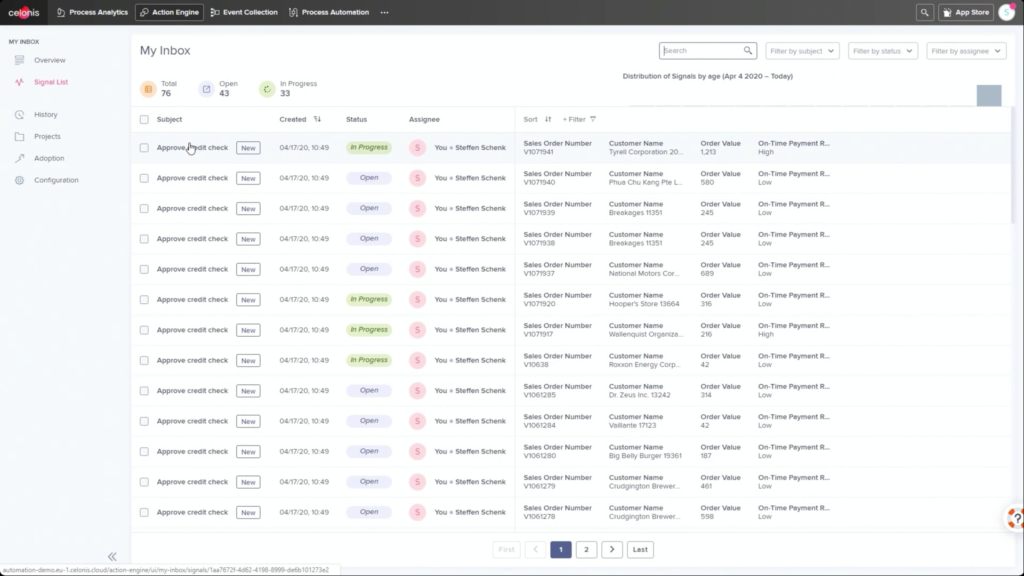
I started my day early to see Dr.Steffen Schenk, Celonis Head of Product Management, talk about the Celonis Action Engine and process automation. In short, they are seeing that because they integrate directly with core systems (especially ERP systems, that have their own processes built in), they can do things that RPA and BPM systems can’t do: namely, data-driven sense and act capabilities. However, these processes are only as timely as the data connection from the core systems into Celonis, so there can be latency.
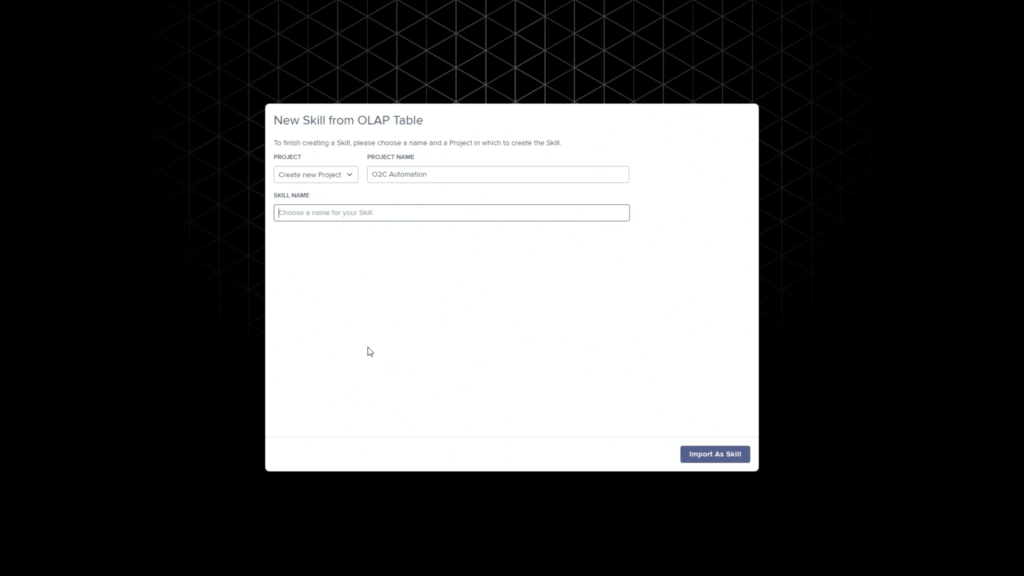
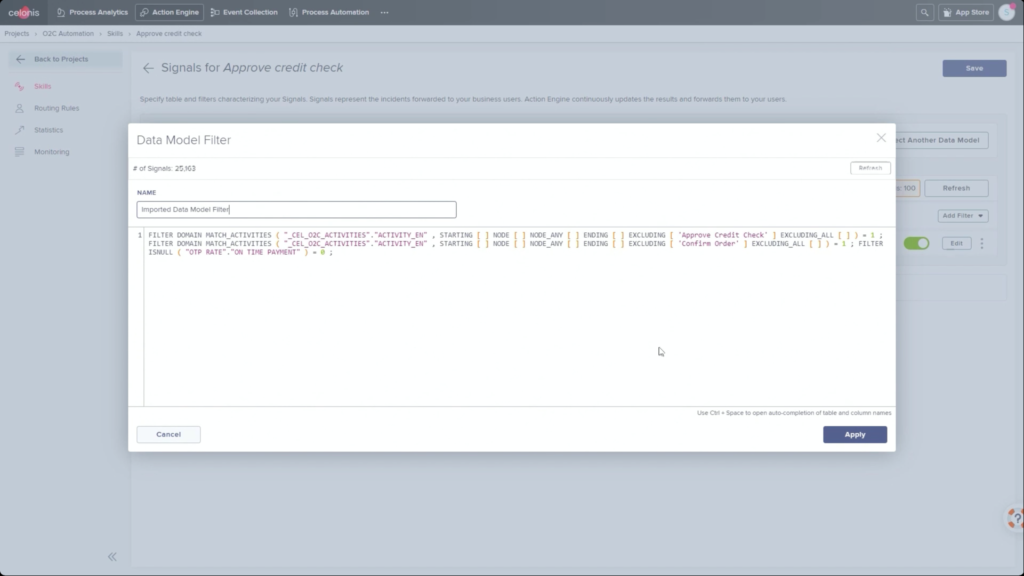
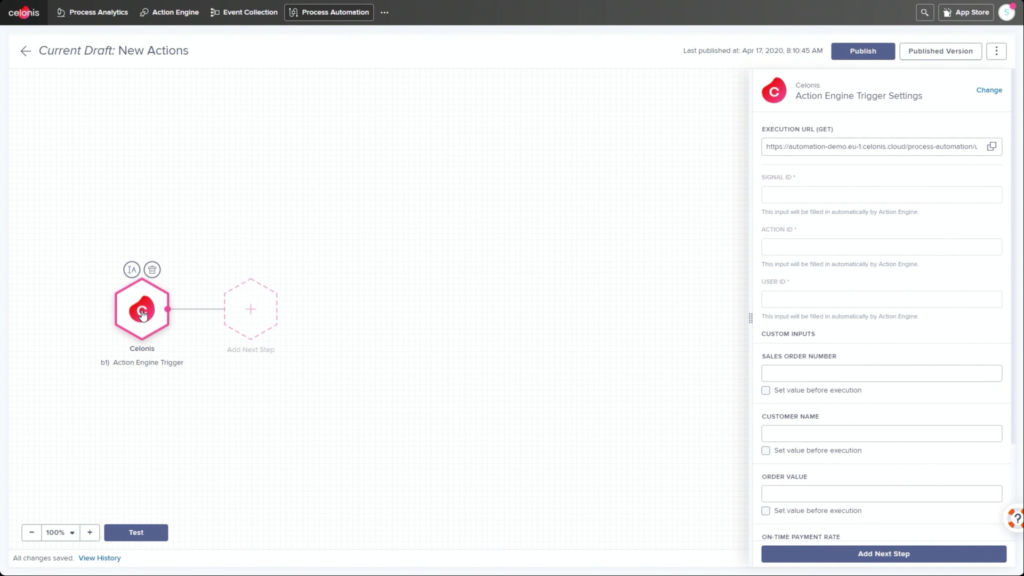
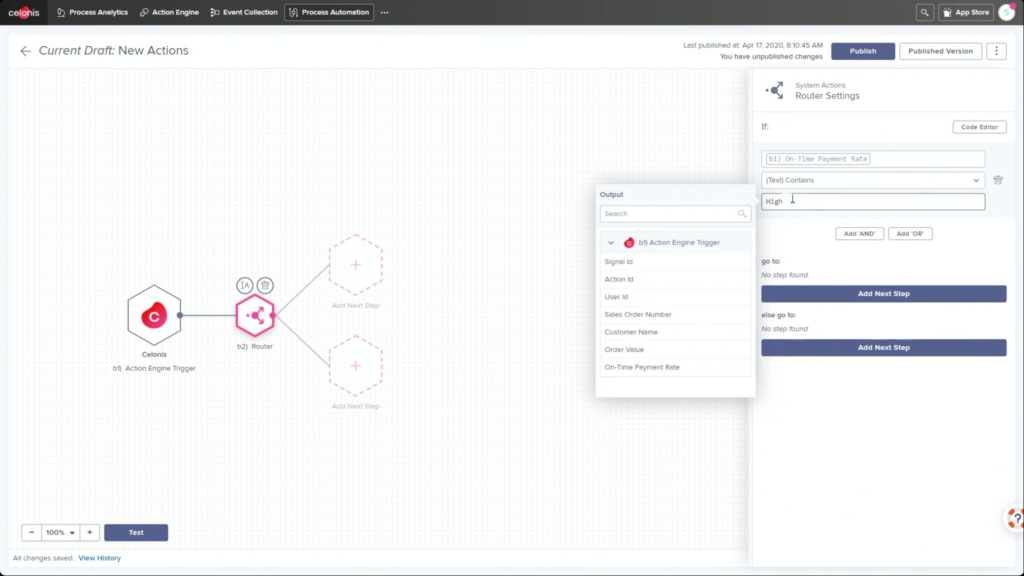
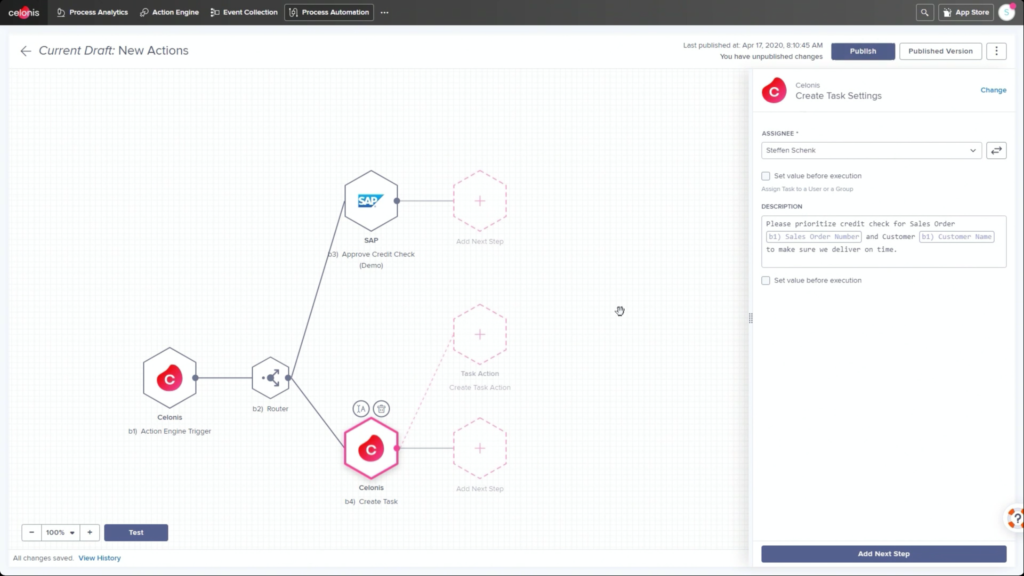
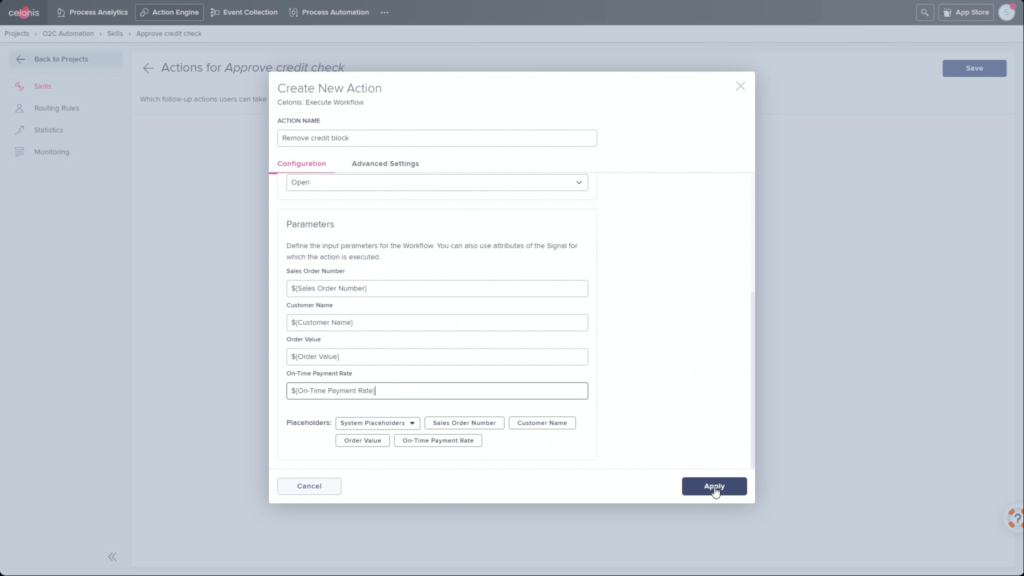
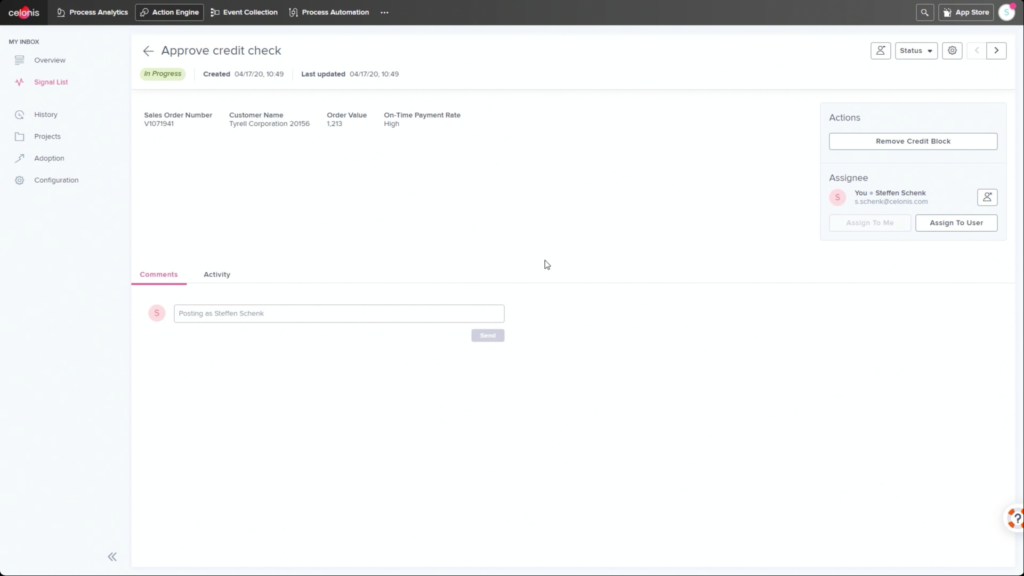
He walked through an example of an order management process where he filtered SAP order data to show those with on-time delivery problems, due to order approval or credit check required, and created a query to detect those conditions in the future. Then, he created a process automation made up of system connectors that would be triggered based on a signal from that query in the future. In addition to system connectors (including webhooks), the automation can also directly call Celonis actions that might prompts a user to take an action. The automation can do branching based on data values: in his example, a customer credit block was automatically removed if they have a history of on-time payment, and that data was pushed back to SAP. That, in turn, would cause SAP to move the invoice along: it’s effectively a collaborative process automation between SAP and Celonis. The non-automated path sends a task to an order manager to approve or deny the credit, which in turn will trigger other automated actions. This process automation is now a “Skill” in Celonis, and can be set to execute for all future SAP order data that flows through Celonis.
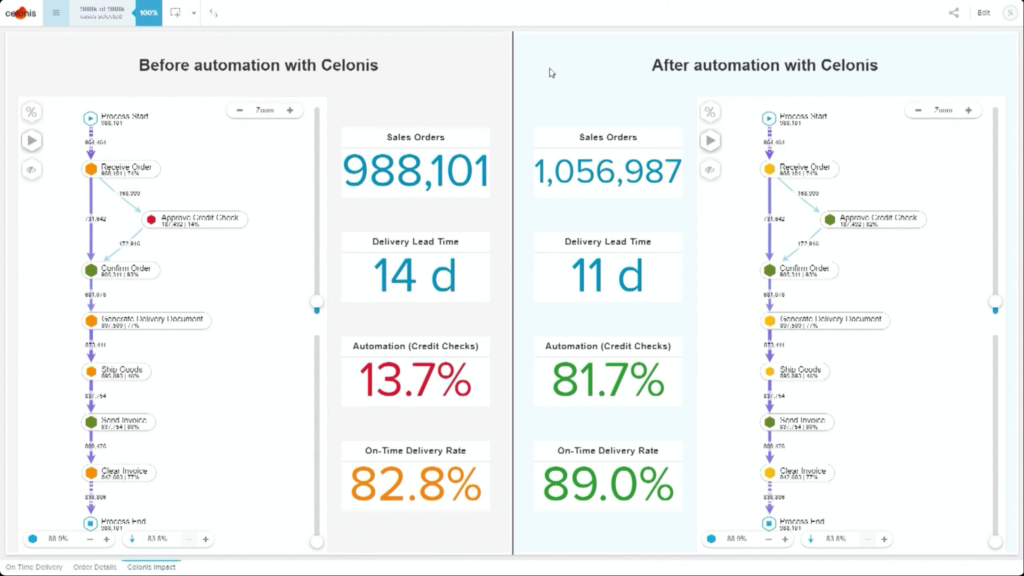
Once this automation has been set up, the before and after processes can be compared: we see a higher degree of automation that has led to improving the on-time delivery KPI without increasing risk. It’s data-driven, so that only customers that continue to have an on-time payment record will be automatically approved for credit on a specific order. This is an interesting approach to automation that provides more comprehensive task automation than RPA, and a better fit than BPM when processes primarily exist in a line-of-business or legacy system. If you have an end-to-end process to orchestrate and need a comprehensive model, then BPM may be a better choice, but there’s a lot of interesting applications for the Celonis model of automating the parts of an existing process that the core system would have “delegated” to human action. I can definitely see applications for this in insurance claims, where most of the claim process lives in a third-party claims management system, but there are many decisions and ancillary processes that need to happen around that system.
This level of automation can be set up by a trained Celonis analyst: if you’re already creating analysis and dashboards, then you have the level of skill required to create these automations. This is also available both for cloud and on-premise deployments. There was an interesting discussion in the Q&A about credentials for updating the connected systems: this could be done with the credentials of the person who approves a task to execute (attended automation) or with generic system credentials for fully-automated tasks.
This was a really fascinating talk and a vision of the future for this type of process automation, where the core process lives within an off-the-shelf or legacy system, and there’s a need to do additional automation (or recommendations) of supporting decisions and actions. Very glad that I got up early for the 7:15am start.
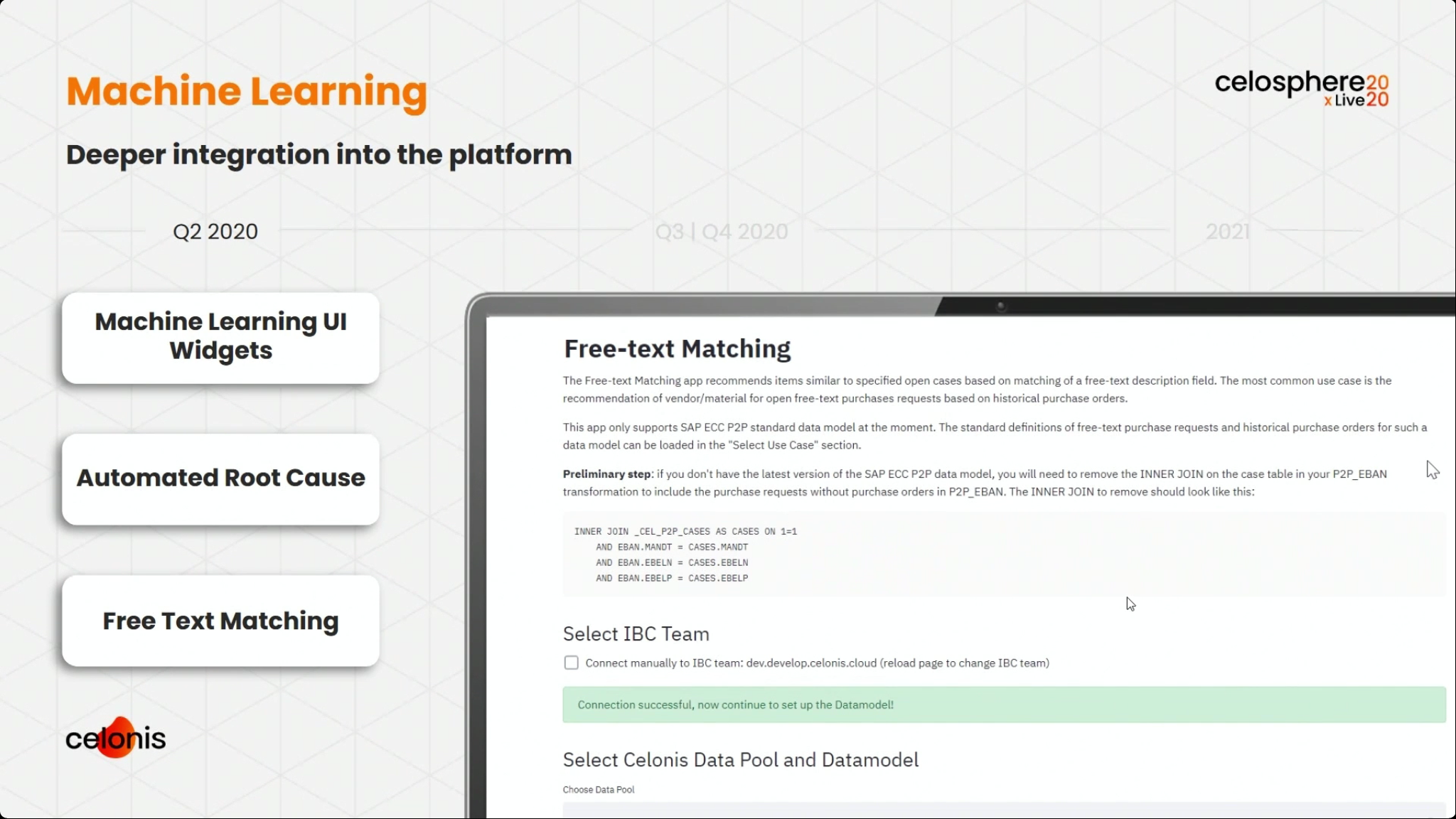
I listened in on the following talk on machine learning and intelligent automation by Nicolas Ilmberger, Celonis Senior Product Manager of Platform and Technology, where he showed some of their pre-built ML tools such as duplicate checkers (for duplicate invoices, for example), root cause analysis and intelligent audit sampling. These are used to detect specific scenarios in the data that is flowing into Celonis, then either raising an action to a user, or automating an action in the background. They have a number of pre-configured connectors and filters, for example, to find a duplicate vendor invoice in an SAP system; these will usually need some customization since many organizations have modified their SAP systems.
He showed a demonstration of using some of these tools, and also discussed a case study of a manufacturing customer that had significant cost savings due to duplicate invoice checking: their ERP system only found exact matches, but slight differences in spelling or other typographical errors could result in true duplicates that needed more intelligent comparison. A second case study was for on-time delivery by an automotive supplier, where customer orders at risk were detected and signals sent to customer service with recommendations for the agent for resolution.
It’s important to note that both for these ML tools and the process automation that we saw in the previous session, these are only as timely as the data connection from the core processing system to Celonis: if you’re only doing daily data feeds from SAP to Celonis, for example, that’s how often these decisions and automations will be triggered. For orders of physical goods that may take several days to fulfill, this is not a problem, but this is not a truly real-time process due to that latency. If an order has already moved on to the next stage in SAP before Celonis can act, for example, there will need to be checks to ensure that any updates pushed back to SAP will not negatively impact the order status.
There was a studio discussion following with Hala Zeine and Sebastian Walter. Zeine said that customers are saying “we’re done with discovery, what’s next?”, and have the desire to leverage machine learning and automation for day-to-day operations. This drove home the point that Celonis is repositioning from being an analysis tool to an operational tool, which gives them a much broader potential in terms of number of users and applications. Procure-to-pay and order-to-cash processes are a focus for them, and every mid-sized and large enterprise has problems with these processes.
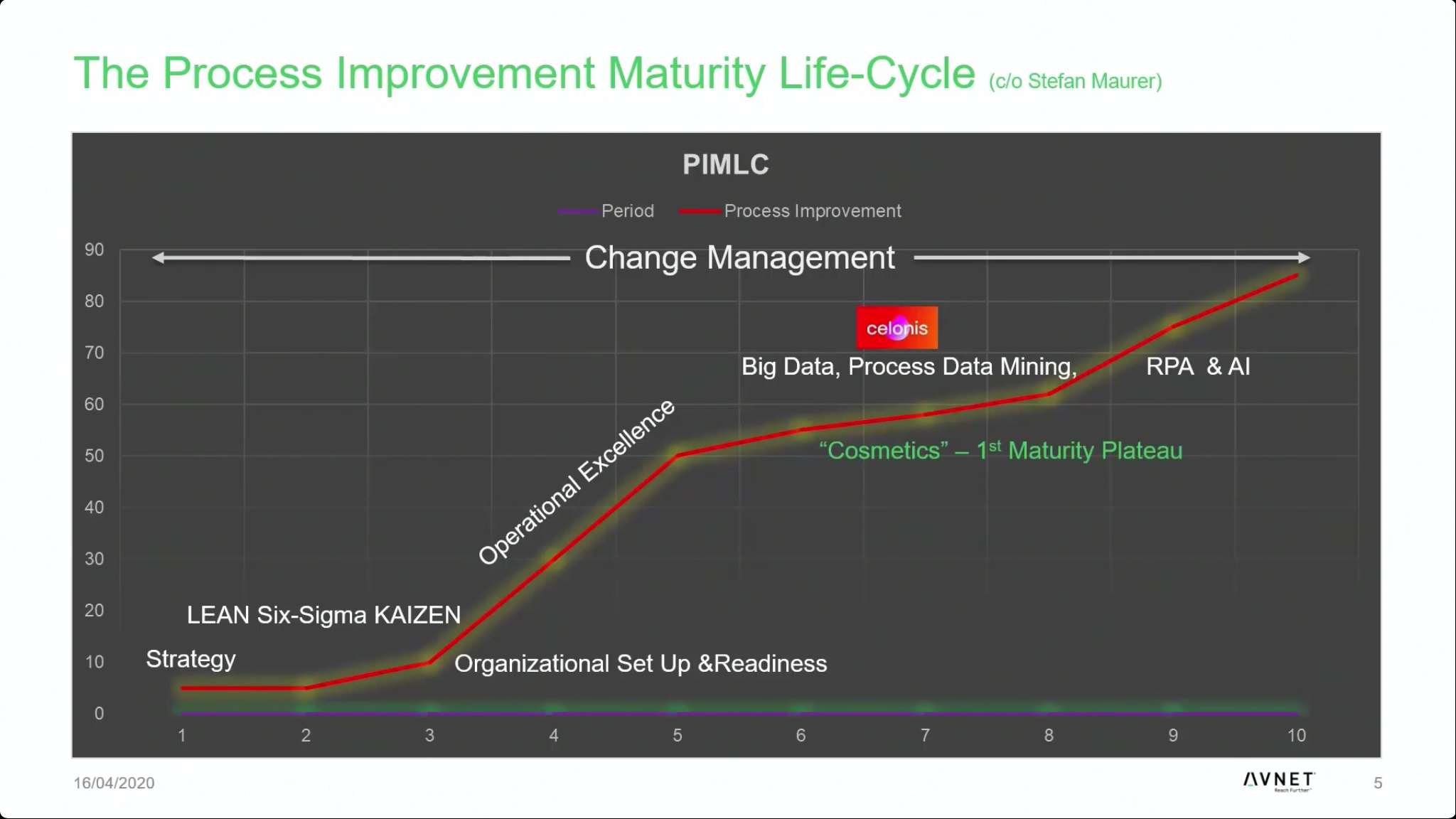
The next session was with Stefan Maurer, Vice President of Enterprise Effectiveness for AVNET, a distributor of electronic components. He spoke about how they are using Celonis in their procure-to-pay process to react to supplier delivery date changes due to the impact of COVID-19 on global supply chains. He started with a number of good points on organizational readiness and how to take on process mining and transformation projects. He walked us through their process improvement maturity lifecycle, showing what they achieved with fundamental efforts such as LEAN Six Sigma, then where they started adding Celonis to the mix to boost the maturity level. He said that they could have benefited from adding Celonis a bit earlier in their journey, but feels that people need a basic understanding of process improvement before adding new tools and methodologies. In response to an audience question later, he clarified that this could be done earlier in an organization that is ready for process improvement, but the results of process mining could be overwhelming if you’re not already in that mindset.
Their enterprise effectiveness efforts focus on the activities of a different team members in a cycle of success that get the business ideas and needs through analysis stages and into implementation within tools and procedures. At several points in that cycle, Celonis is used for process mining but not automation; they are using Kofax and UIPath for RPA as their general task automation strategy.
Maurer showed a case study for early supplier deliveries: although early deliveries might seem like a good thing, if you don’t have an immediate use for the goods and the supplier invoices on delivery, this can have a working capital impact. They used Celonis to investigate details of the deliveries to determine the impact, and identify the target suppliers to work with on resolving the discrepancies. They also use Celonis to monitor procure-to-pay process effectiveness, using a throughput time KPI based over time windows a year apart: in this case, they are using the analytical capabilities to show the impact of their overall process improvement efforts. By studying the process variants, they can see what factors are impacting their effectiveness. They are starting to use the Celonis Action Engine for some delivery alerts, and hope to use more Celonis alerts and recommendations in the future.
Almost accidentally, Celonis also provided an early warning to the changes in the supply chain due to COVID-19. Using the same type of data set as they used for their early delivery analysis, they were able to find which suppliers and materials had a significant delay to their expected deliveries. They could then prioritize the needs of their medical and healthcare customers, manually interfering in their system logic to shift their supply chain to guarantee those customers while delaying others. He thinks that additional insights into materials acquisition supply chains will help them through the crisis.
I’m taking a break from Celosphere to attend the online Alfresco Modernize event, but I plan to return for a couple of the afternoon sessions.
I’m back for the Celonis online conference, CelosphereLive, for a second day. They started much earlier since they using a European time zone, but I started in time to catch the Q&A portion of Ritu Nibber’s presentation (VP of Global Process and Controls at Reckitt Benckiser) and may go back to watch the rest of it since there were a lot of interesting questions that came up.
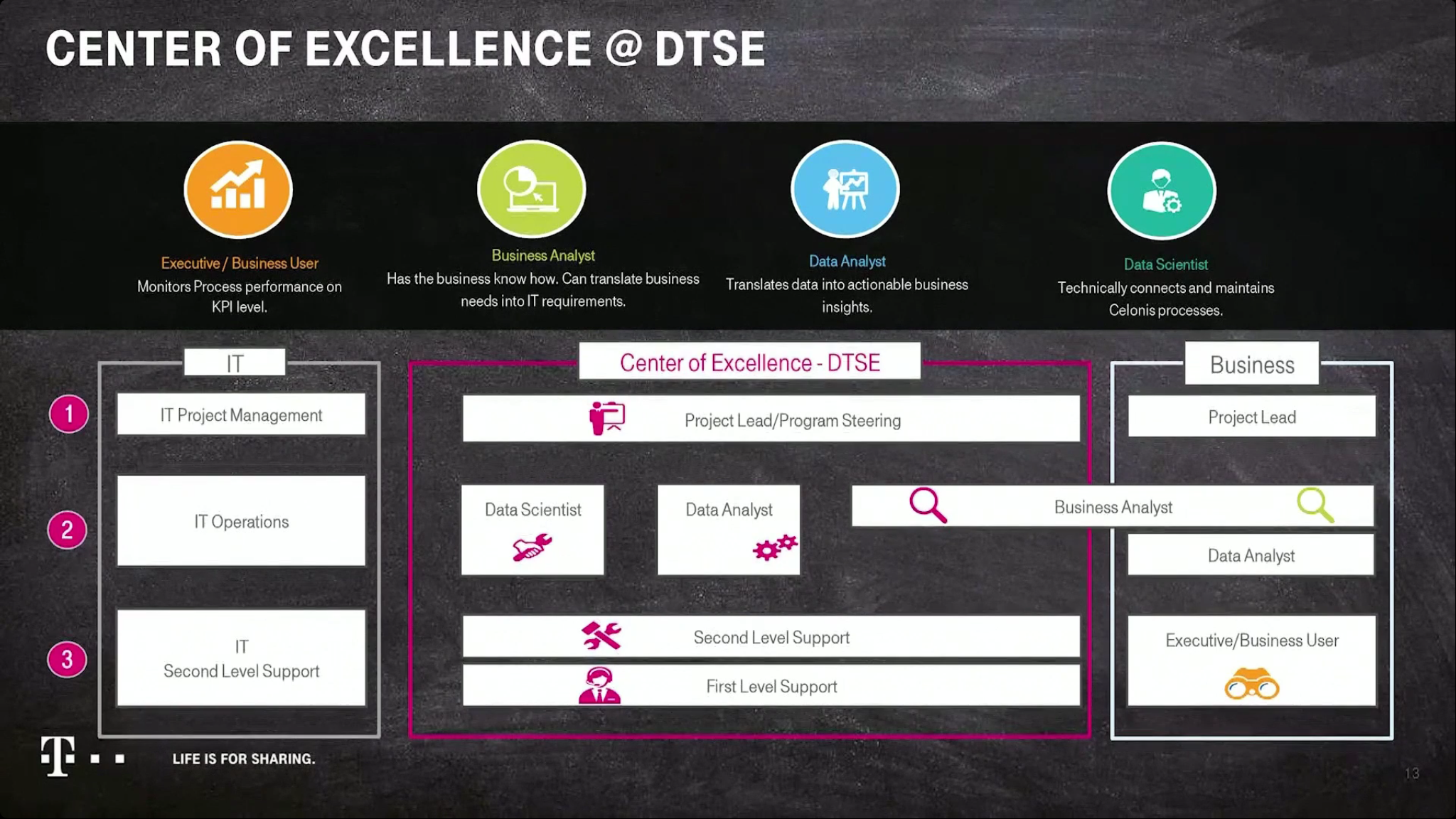
There was a 15-minute session back in their studio with Celonis co-CEO Bastian Nominacher and VP of Professional Services Sebastian Walter, then on to a presentation by Peter Tasev, SVP of Procure to Pay at Deutsche Telekom Services Europe. DTSE is a shared services organization providing process and service automation across many of their regional organizations, and they are now using Celonis to provide three key capabilities to their “process bionics”:
Monitor the end-to-end operation and efficiency of their large, heterogeneous processes such as procure-to-pay. They went through the process of identifying the end-to-end KPIs to include into an operational monitoring view, then use the dashboard and reports to support data-driven decisions.
Use of process mining to “x-ray” their actual processes, allowing for process discovery, conformance checking and process enhancement.
Track real-time breaches of rules in the process, and alert the appropriate people or trigger automated activities.
Interesting to see their architecture and roadmap, but also how they have structured their center of excellence with business analysts being the key “translator” between business needs and the data analysts/scientists, crossing the boundary between the business areas and the CoE.
He went through their financial savings, which were significant, and also mentioned the ability of process mining to identify activities that were not necessary or could be automated, thereby freeing up the workforce to do more value-added activities such as negotiating prices. Definitely worth watch the replay of this presentation to understand the journey from process mining to real-time operational monitoring and alerting.
It’s clear that Celonis is repositioning from just process mining — a tool for a small number of business analysts in an organization — into operational process intelligence that would be a daily dashboard tool for a much large portion of the workforce. Many other process mining products are attempting an equivalent pivot, although Celonis seems to be a bit farther along than most.
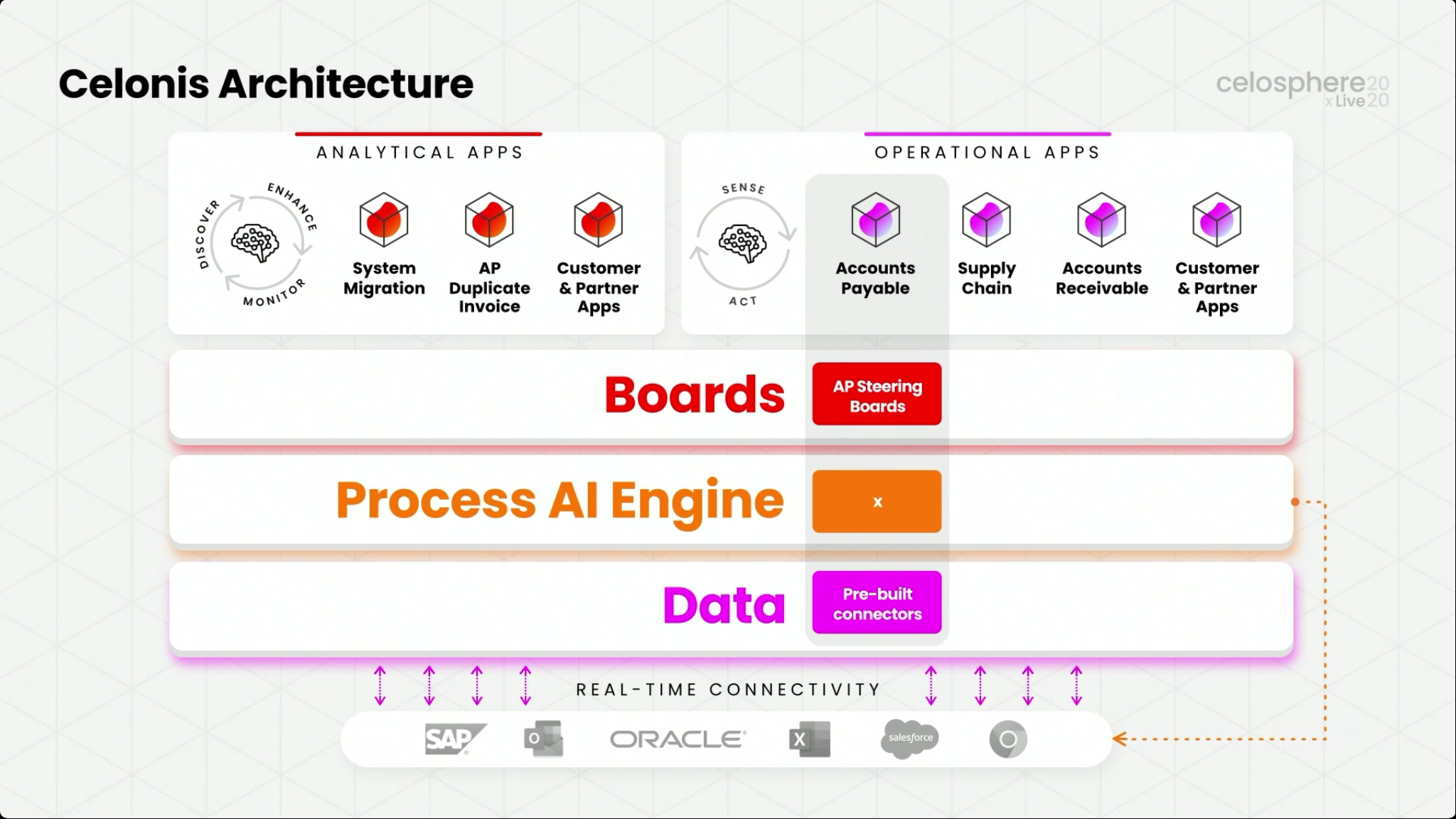
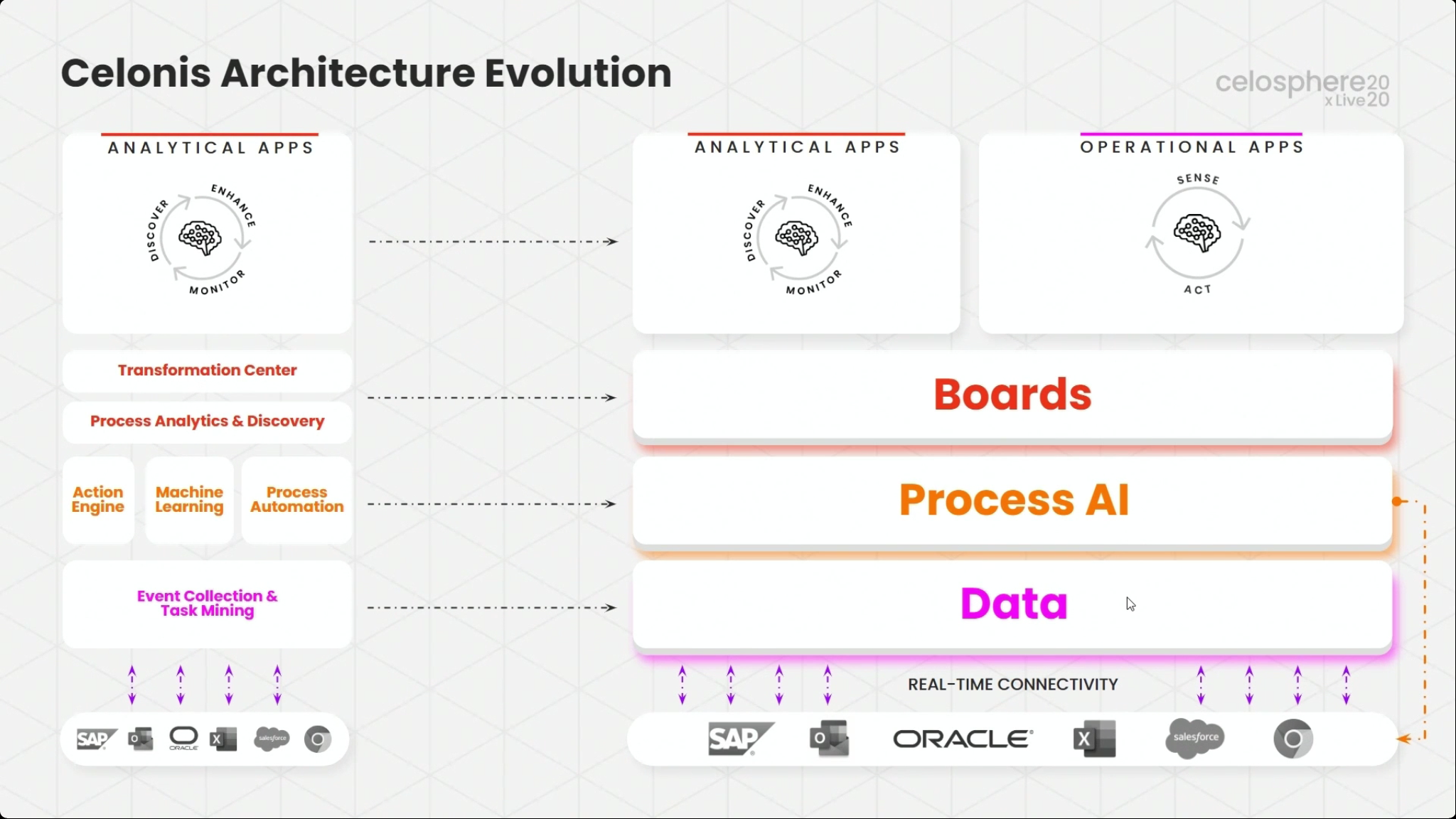
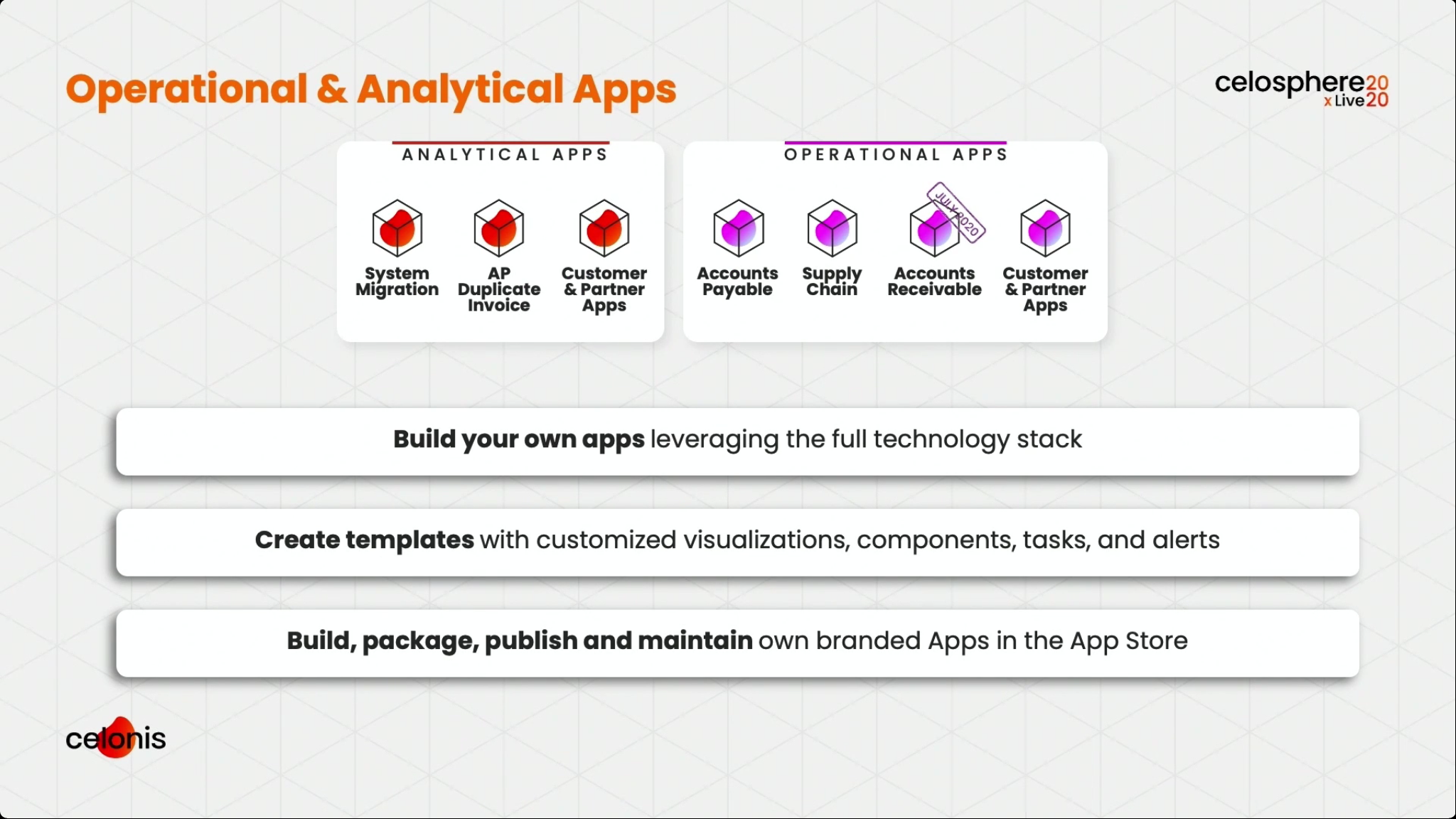
Martin Klenk, Celonis CTO, gave an update on their technology strategy, with an initial focus on how the Celonis architecture enables the creation of these real-time operational apps: real-time connectors feed into a data layer, which is analyzed by the Process AI Engine, and then exposed through Boards that integrate data and other capabilities for visualization. Operational and analytical apps are then created based on Boards. Although Celonis has just released two initial Accounts Payable and Supply Chain operational apps, this is something that customers and partners can build in order to address their particular needs.
He showed how a custom operational app can be created for a CFO to show how this works, using a real-time connectors to Salesforce for order data and Jira for support tickets. He showed their multi-event log analytical capability, which makes it much easier to bring together data sources from different systems and automatically correlate them without a lot of manual data cleansing — the links between processes in different systems are identified without human intervention. This allows detection of anomalies that occur on boundaries between systems, rather than just within systems.
Signals can be created based on pre-defined patterns or from scratch, allowing a real-time data-driven alert to be issued when required, or an automation push to another system be triggered. This automation capability is a critical differentiator, allowing for a simple workflow based on connector steps, and can replace the need for some amount of other process automation technologies such as RPA in cases where those are not a good fit.
He was joined by Martin Rowlson, Global Head of Process Excellence at Uber; they are consolidating data from all of their operational arms (drive, eats, etc.) to analyze their end-to-end processes, and using process mining and task mining to identify areas for process improvement. They are analyzing some critical processes, such as driver onboarding and customer support, to reduce friction and improve the process for both Uber and the driver or customer.
Klenk’s next guest as Philipp Grindemann, head of Business Development at Lufthansa CityLine, discussing how they are using Celonis to optimize their core operations. They track maintenance events on their aircraft, plus all ground operations activities. Ground operations are particularly complex due to the high degree of parallelism: an aircraft may be refueled at the same time that cargo is being loaded. I have to guess that their operations are changing radically right now and they are having to re-structure their processes, although that wasn’t discussed.
His last guest was Dr. Lars Reinkemeyer, author of Process Mining in Action — his book has collected and documented many real-world use cases for process mining — to discuss some of the expected directions of process mining beyond just analytics.
They then returned to a studio session for a bit more interactive Q&A; the previous technology roadmap keynote was pre-recorded and didn’t allow for any audience questions, although I think that the customers that he interviewed will have full presentations later in the conference.
#CelosphereLive lunch break
As we saw in at CamundaCon Live last week, there is no break time in the schedule: if you want to catch all of the presentations and discussions in real time, be prepared to carry your laptop with you everywhere during the day. The “Live from the Studio” sessions in between presentations are actually really interesting, and I don’t want to miss those. Today, I’m using their mobile app on my tablet just for the streaming video, which lets me take screenshots as well as carry it around with me, then using my computer for blogging, Twitter, screen snap editing and general research. This means that I can’t use their chat or Q&A functions since the app does not let you stream the video and use the chat at the same time, and the chat wasn’t very interesting yesterday anyway.
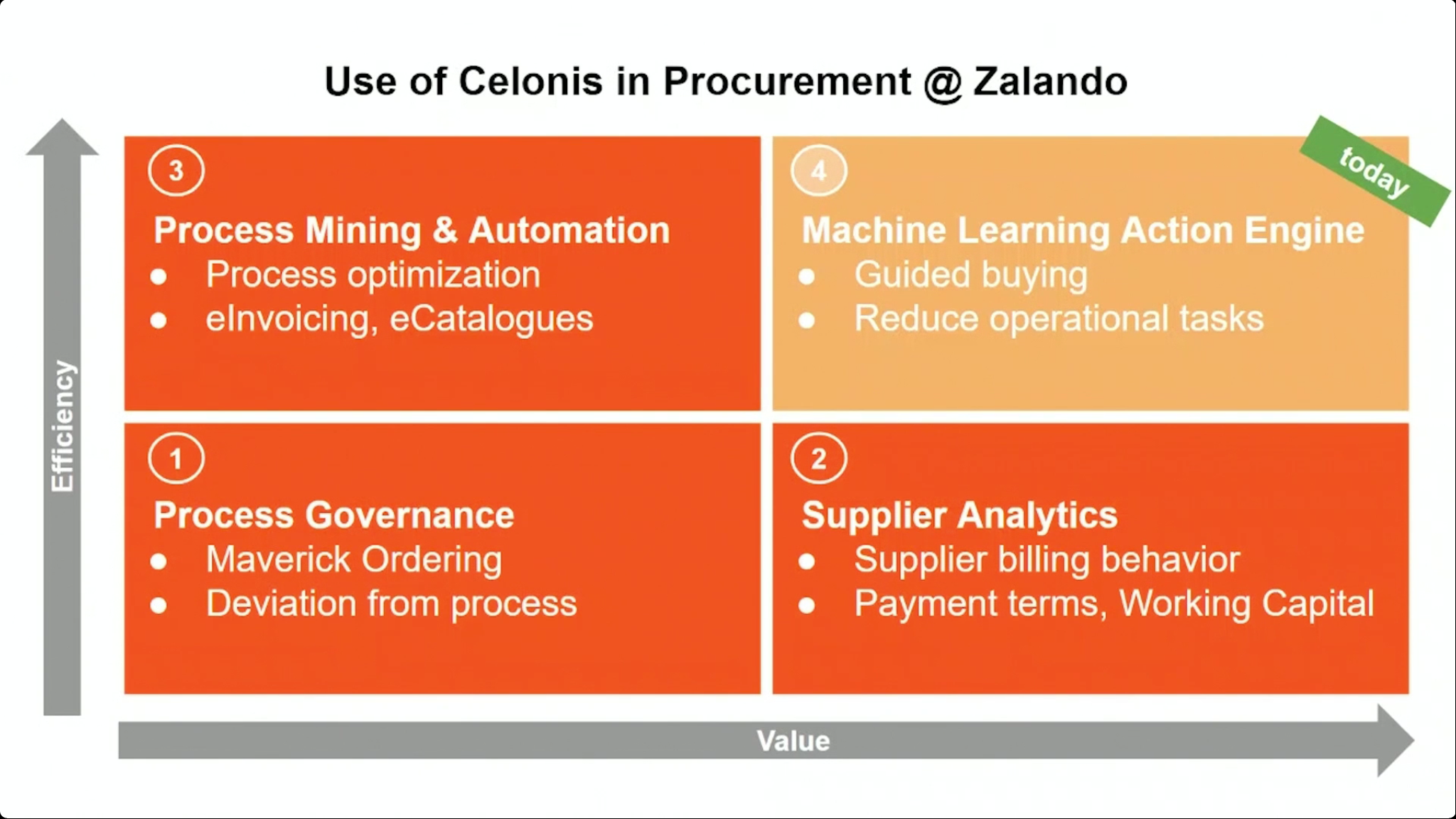
The next presentation was by Zalando, a European online fashion retailer, with Laura Henkel, their Process Mining Lead, and Alejandro Basterrechea, Head of Procurement Operations. They have moved beyond just process mining, and are using Celonis to create machine learning recommendations to optimize procurement workflows: the example that we saw provided Amazon-like recommendations for internal buyers. They also use the process automation capabilities to write information back to the source systems, showing how Celonis can be used for automating multi-system integration where you don’t already have process automation technology in place to handle this. Their key benefits in adding Celonis to their procurement processes have been efficiency, quality and value creation. Good interactive audience Q&A at the end where they discuss their journey and what they have planned next with the ML/AI capabilities. It worked well with two co-presenters, since one could be identifying a question for their area while the other was responding to a different question, leaving few gaps in the conversation.
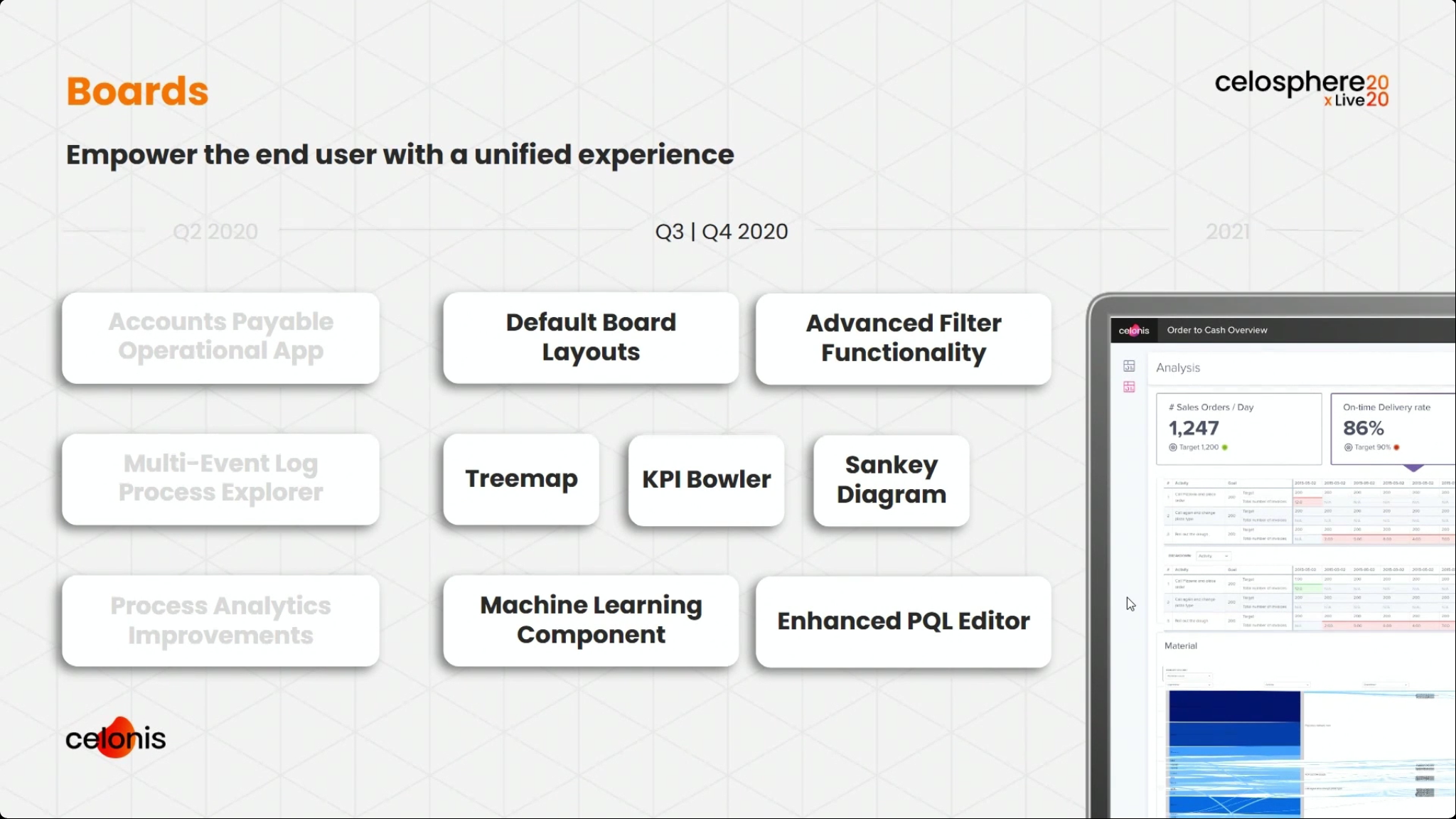
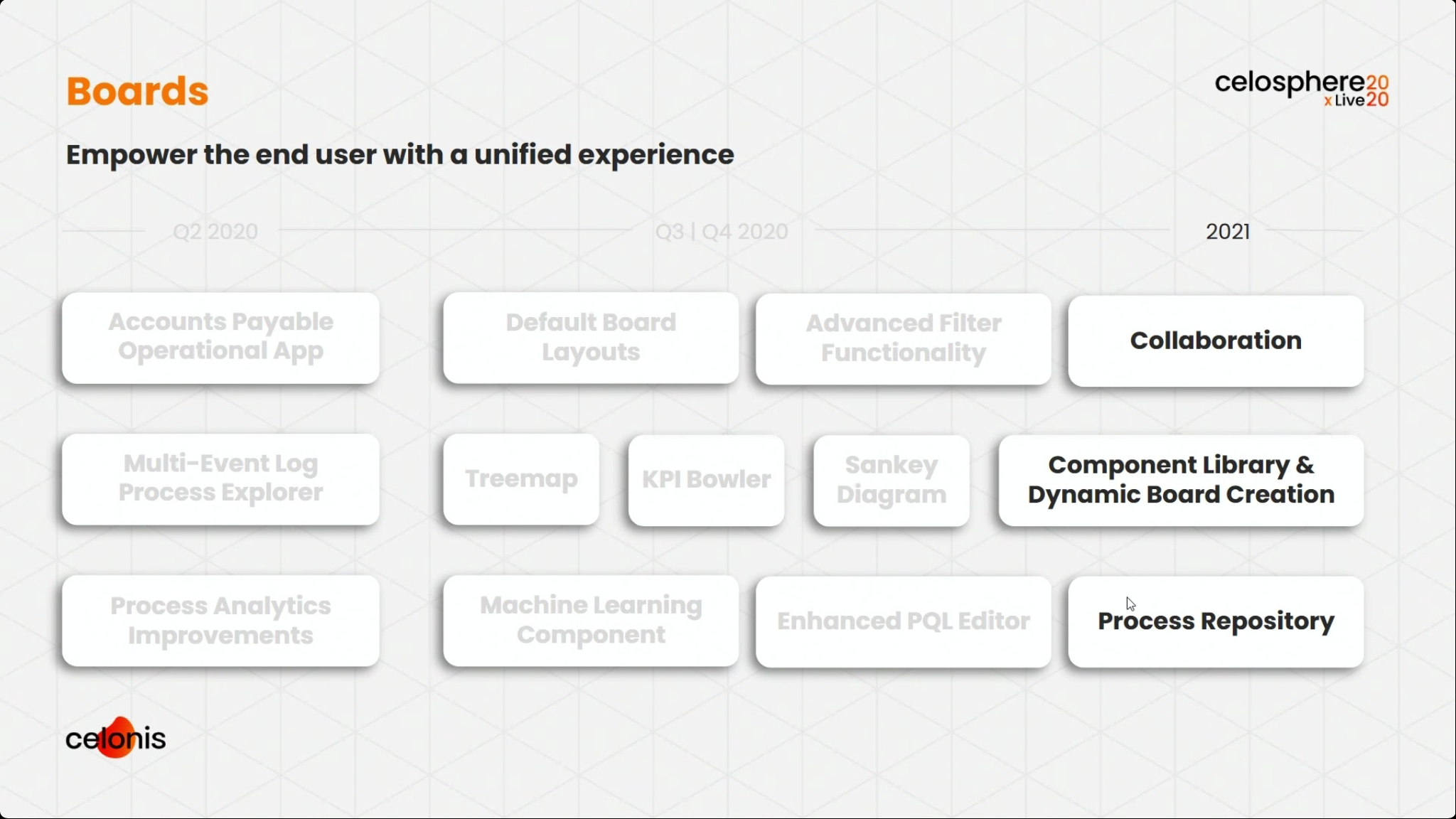
We broke into two tracks, and I attended the session with Michael Götz, Engineering Operations Officer at Celonis, providing a product roadmap. He highlighted their new operational apps, and how they collaborated with customers to create them from real use cases. There is a strong theme of moving from just analytical apps to operational apps that sense and act. He walked through a broad set of the new and upcoming features, starting with data and connectivity, through the process AI engine, and on to boards and the operational apps. I’ve shown some of his slides that I captured below, but if you’re a Celonis customer, you’ll want to watch this presentation and hear what he has to say about specific features. Pretty exciting stuff.
I skipped the full-length Uber customer presentation to see the strategies for how to leverage Celonis when migrating legacy systems such as CRM or ERP, presented by Celonis Data Scientist Christoph Hakes. As he pointed out, moving between systems isn’t just about migrating the data, but it also requires changing (and improving) processes . One of the biggest areas of risk in these large-scale migrations is around understanding and documenting the existing and future-state processes: if you’re not sure what you’re doing now, then likely anything that you design for the new system is going to be wrong. 60% of migrations fail to meet the needs of the business, in part due to that lack of understanding, and 70% fail to achieve their goals due to resistance from employees and management. Using process mining to explore the actual current process and — more importantly — understand the variants means that at least you’re starting from an accurate view of the current state. They’ve created a Process Repository for storing process models, including additional data and attachments
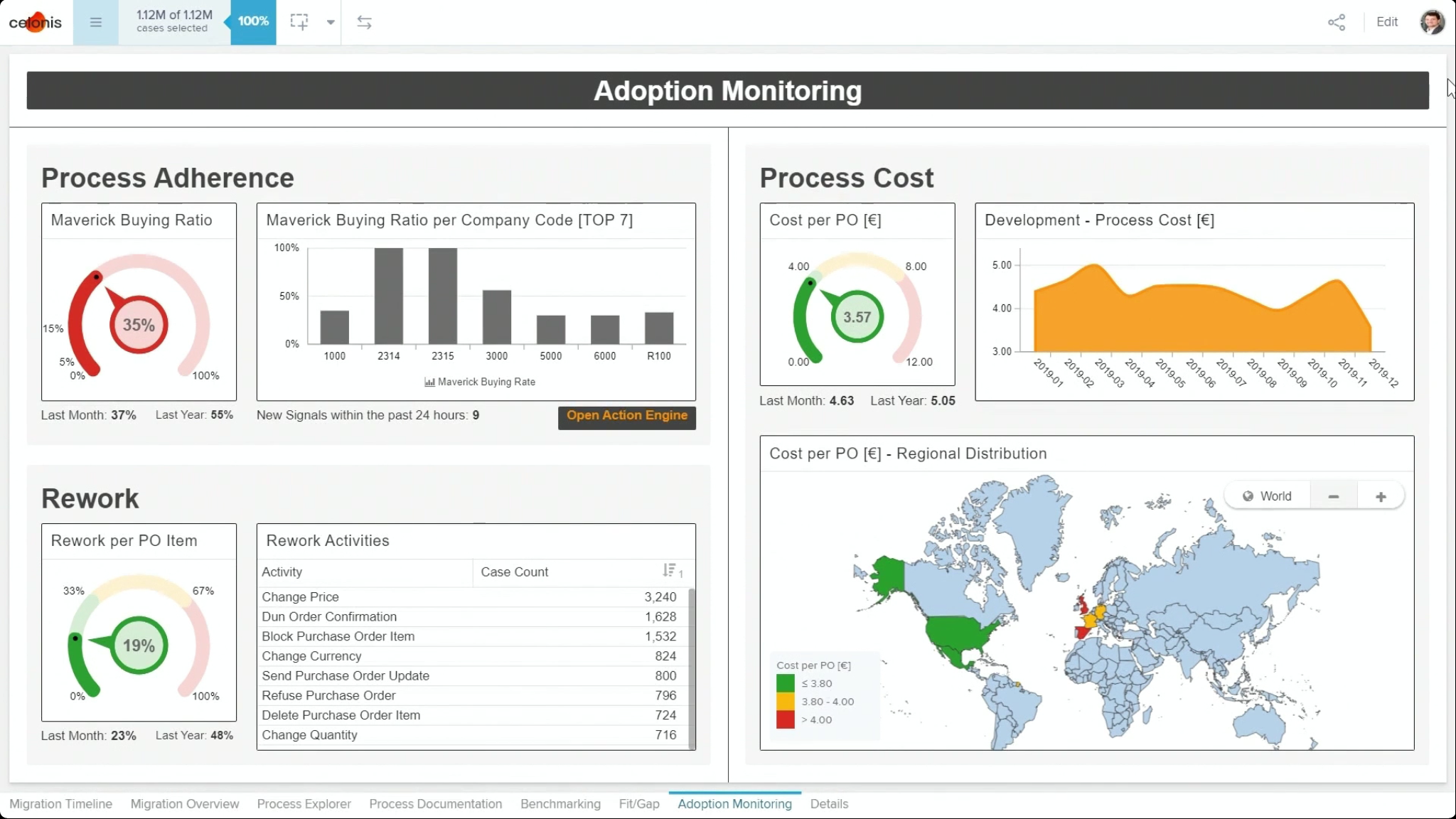
Hakes moved on to talk about their redesign tools, such as process conformance checking to align the existing processes to the designed future state. After rollout, their real-time dashboards can monitor adoption to locate the trouble spots, and send out alerts to attempt remediation. All in all, they’ve put together a good set of tools and best practices: their customer Schlumberger saved $40M in migration costs by controlling the migration costs, driving user adoption and performing ongoing optimization using Celonis. Large-scale ERP system migration is a great use case for process mining in the pre-migration and redesign areas, and Celonis’ monitoring capabilities also make it valuable for post-migration conformance monitoring.
The last session of the day was also a dual track, and I selected the best practices presentation on how to get your organization ready for process mining, featuring Celonis Director of Customer Success Ankur Patel. The concurrent session was Erin Ndrio on getting started with Celonis Snap, and I covered that based on a webinar last month. Patel’s session was mostly for existing customers, although he had some good general points on creating a center of excellence, and how to foster adoption and governance for process mining practices throughout the organization. Some of this was about how a customer can work with Celonis, including professional services, training courses, the partner network and their app store, to move their initiatives along. He finished with a message about internal promotion: you need to make people want to use Celonis because they see benefits to their own part of the business. This is no different than the internal evangelism that needs to be done for any new product and methodology, but Patel actually laid out methods for how some of their customers are doing this, such as road shows, hackathons and discussion groups, and how the Celonis customer marketing team can help.
He wrapped up with thoughts on a Celonis CoE. I’m not a big fan of product-specific CoEs, instead believing that there should be a more general “business automation” or “process optimization” CoE that covers a range of process improvement and automation tools. Otherwise, you tend to end up with pockets of overlapping technologies cropping up all over a large organization, and no guidance on how best to combine them. I wrote about this in a guest post on the Trisotech blog last month. I do think that Patel had some good thoughts on a centralized CoE in general to support governance and adoption for a range of personas.
I will check back in for a few sessions tomorrow, but have a previous commitment to attend Alfresco Modernize for a couple of hours. Next week is IBM Think Digital, the following week is Appian World, then Signavio Live near the end of May, so it’s going to be a busy few weeks. This would normally be the time when I am flying all over to attend these events in person, and it’s nice to be able to do it from home although some of the events are more engaging than others. I’m gathering a list of best practices for online conferences, including the things that work and those that don’t, and I’ll publish that after this round of virtual events. So far, I think that Camunda and Celonis have both done a great job, but for very different reasons: Camunda had much better audience engagement and more of a “live” feel, while Celonis showed how to incorporate higher production quality and studio interviews to good effect, even though I think it’s a bit early to be having in-person interviews.











 He had a discussion with Svein Tore Holsether, CEO of
He had a discussion with Svein Tore Holsether, CEO of  He then talked to Michael Lindsey, Chief Transformation and Strategy Officer at PepsiCo North America, with a focus on their Frito-Lay operations. This operation has a huge fleet, controlling the supply chain from the potato farms to the store. Competition has driven them to have a much broader range of products, in terms of content and flavors, to maintain their 90%+ penetration into the American household market. Previously, any change would have been driven from their head office, moving out to the fringes in a waterfall model. They now have several agile teams based on
He then talked to Michael Lindsey, Chief Transformation and Strategy Officer at PepsiCo North America, with a focus on their Frito-Lay operations. This operation has a huge fleet, controlling the supply chain from the potato farms to the store. Competition has driven them to have a much broader range of products, in terms of content and flavors, to maintain their 90%+ penetration into the American household market. Previously, any change would have been driven from their head office, moving out to the fringes in a waterfall model. They now have several agile teams based on 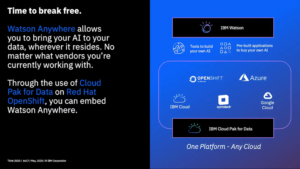 SVP of IBM Cloud & Data Platform, gave a keynote on how AI and automation is changing how companies work. Some of this was a repeat from what we saw in the analyst preview, plus some interviews with customers including Mirco Bharpalania, Head of Data & Analytics at Lufthansa, and Mallory Freeman, Director of Data Science and Machine Learning in the Advanced Analytics Group at
SVP of IBM Cloud & Data Platform, gave a keynote on how AI and automation is changing how companies work. Some of this was a repeat from what we saw in the analyst preview, plus some interviews with customers including Mirco Bharpalania, Head of Data & Analytics at Lufthansa, and Mallory Freeman, Director of Data Science and Machine Learning in the Advanced Analytics Group at