It’s been a quick two days at CamundaCon 2022 in Berlin, and as always I’ve enjoyed my time here. The second day finished with a quick fireside chat with Camunda co-founders Jakob Freund and Bernd Ruecker, who wrapped up some of the conference themes about process orchestration. I’ll post a link to the videos when they’re all available; not sure if Camunda is going to publish them on their YouTube channel or put them behind a registration page.
I mentioned previously about what a great example of a hybrid conference this has been, with both speakers and attendees either on-site or remote — my own panel included three of us on the stage and one person remotely, and it worked seamlessly. One part of this that I liked is that in the large break lounge area, there were screens set up with the video feed from each of the four stages, and wireless headsets that you could tune to any of the four channels. This let you be “remote” even when on site, which was necessary in some of the smaller rooms where it was standing room only. Or if you wanted to have a coffee while you were watching.
Thanks to Camunda for inviting me, and the exciting news is that next September’s CamundaCon will be in New York: a much shorter trip for me, as well as for many of Camunda’s North American customers and partners.
Michael Goldverg from BNY Mellon presented on their journey with automating processes within the bank across thousands of people in multiple business departments. They needed to deal with interdependencies between departments, variations due to account/customer types, SLAs at the departmental and individual level, and thousands of daily process instances.
They use the approach of a single base model with thousands of variations – the “super model” – where the base model appears to include smaller ad hoc models (mostly snippets surrounding a single task that were initially all manual operations) that are assembled dynamically for any specific type of process. Sort of an accidental case management model at first glance, although I’d love to get a closer look at their model. There was a question about the number of elements in their model, which Michael estimated as “three dozen or so” tasks and a similar number of gateways, but can’t share the actual model for confidentiality reasons.
They have a deployment architecture that allows for multiple clusters accessing a single operational database, where each cluster could have a unique version of the process model. Applications could then be configured to select the server cluster – and therefore the model version – at runtime, allowing for multiple models to be tested in a live environment. There’s also an automated process instance migration service that moves the live process instances if the old and new process models are not compatible. Their model changes constantly, and they update the production model at least once per week.
They’ve had to deal with optimistic locking exceptions (fairly common when you have a lot of parallel gateways and multiple instances of the engine) by introducing their own external locking mechanism, and by offloading some of this to the Camunda JobExecutor using asynchronous continuations although that can cause a hit on performance. The hope is that this will be resolved when they move to the V8 engine – V8 doesn’t rely on a single relational database and is also highly distributed by design.
They run 50-100k transactions per day, and have hundreds of millions of tasks in the history database. They manage this with aggressive cleaning of the history database – currently set to 60 days – by archiving the task history as PDFs in their content management system where it’s discoverable. They are also very careful about the types of queries that they allow directly on the Camunda database, since a single poorly-constructed search can bring the database to its knees: this is why Camunda, like other vendors, discourage the direct querying of their database.
There are a lot of trade offs to be understood when it comes to performance optimization at this scale. Also some good points about starting your deployment with a more complex configuration, e.g., two servers even if one is adequate, so that you’re not working out the details of how to run the more complex configuration when you’re also trying to scale up quickly. Lots of details in Michael’s presentation that I’m not able to capture here, definitely check out the recorded video later if you have large deployment requirements.
My little foldable keyboard isn’t playing nice, so I’m typing this directly on my iPad which is…not ideal. However, I will do my best and debug the keyboard later.
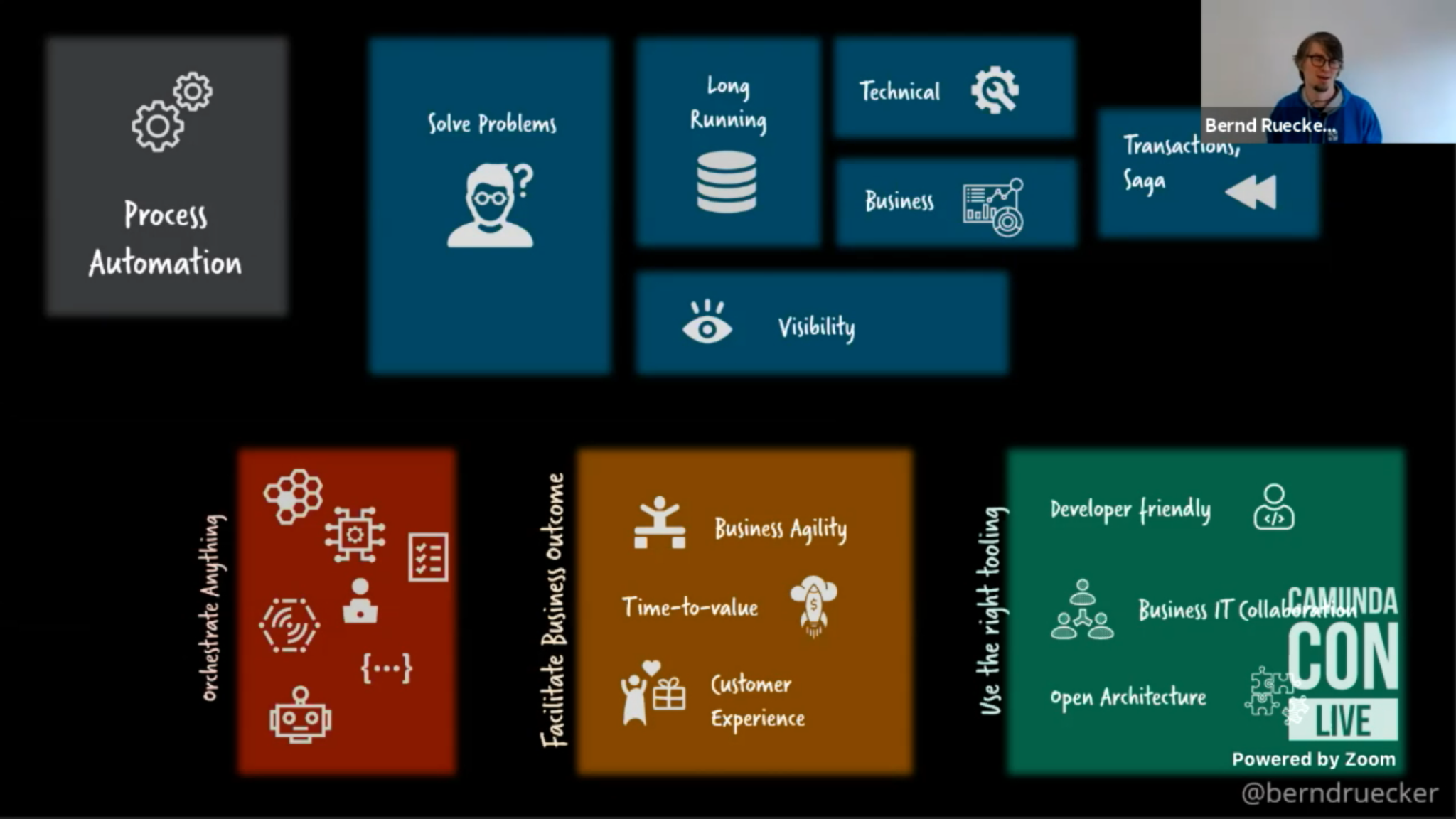
Day 2 of CamundaCon 2022 here in Berlin started off with a keynote from Bernd Ruecker, Camunda co-founder and chief technologist, and Daniel Meyer, CTO. Version 8.1 is coming up, and with it some new connectors as well as other core enhancements. Bernd started out with a reinforcement of some of Jakob Freund’s messages yesterday: the distinction between task (depth) and process (breadth) automation, and how process orchestration is characterized by endpoint diversity and process complexity. These are important points in understanding the scope of process orchestration, but also for companies like Camunda to distinguish themselves in an increasingly diverse and crowded “process automation” market.
Once Bernd had walked us through what an initial process orchestration could look like (for a bank account opening example), Daniel took over to take about moving from an initial project to a transformed, process-centric enterprise. Some of this requires tools that allow less technical developers to get involved, which means having more connectors available for these developers to create apps by assembling and configuring connectors, while more technical developers may be creating new connectors for what’s not offered out of the box by Camunda. Bernd, who loves his live demos, showed us how to create a new connector quickly in Java, then expose it graphically in the modeler using a connector template – this makes it appears as an activity type directly in the Camunda modeler. Once they are in the modeler, connectors can be used in any application, so that (for example) a connector to your bespoke mainframe monolith can be created and added to the modeler once, then used in a variety of applications.
The concept of connectors as a way for less technical developers to use a BPMN model as an application development framework isn’t new: many other BPMS vendors have been doing this for a long time. Camunda is obviously feeling the pressure to move from a purely developer-focused platform and address some level of low-code needs, and connectors is one if the main ways that they are doing this. The ease in creating new connectors is pretty cool – many products let you use their out of the box connectors but don’t make it that easy to make new ones. Camunda is positioning this capability (creating new connectors quickly) as core to automating the enterprise.
We heard about more of what they’ve been releasing this year, including the web modeler that allows new developers and business analysts to be onboarded quickly without having to install anything locally. The modeler includes BPMN validation so that correct process models are created and errors avoided before deploying to the server. They are also using FEEL (friendly enough expression language) – borrowed from the DMN specification – for scripting within tasks. This use of FEEL is also being done by other standards-focused vendors, such as Trisotech. We also saw some of the things that they’re working on, such as interactive debugging to step through processes, and an improved forms UI builder. Again, not completely new ideas in the BPM space, but nice productivity enhancements to their developer experience. Based on what they’ve seen within their own company, they’re integrating Slack and Microsoft Teams for human task orchestration to avoid the requirement for users to go to a separate app for their process task list.
Bernd addressed the issue of Camunda supporting low code, when they have been staunchly pro code only for most of their history. Fundamentally, the market (that is, their customers and prospective customers) need this capability, and it’s clear that you have to offer at least something low code (ish) to play in the process automation space these days. This is definitely a shift for them, and they are doing it fairly gracefully although are a bit behind the curve in much of the functionality because they stuck to their roots for so long. In their favour, they’re still a small and nimble company and can roll out this type of functionality in their product fairly quickly. They are mostly just dipping into the pro code end of the low code space, and it will be interesting to see how far they go in upcoming releases. Creating more low code tooling and more connectors obviously creates more long-term technical debt for Camunda: if they decide this isn’t the way forward after a while, or they change some of the underlying architecture, customers could end up with legacy versions of connectors and low code tooling that need to be updated. Definitely worth checking out for existing Camunda customers who want to accelerate adoption within their organizations.
By the way, I’ve had so much great feedback on our panel yesterday: happy to hear that we had some nuggets of wisdom in there. So many good conversations last night at the BBQ and continuing into today between sessions. I’ll post a link to the recorded session when it’s published.
I realize that I’m completely remiss for not posting about last week’s DecisionCAMP, but in my defense, I was co-hosting it and acting as “master of ceremonies”, so was a bit busy. This was the third year for a virtual DecisionCAMP, with a plan to be back in person next year, in Oslo. And speaking of in-person conferences, I’m in Berlin! Yay! I dipped my toe back into travel three weeks ago by speaking at Hyland’s CommunityLive conference in Nashville, and this week I’m on a panel at Camunda’s annual conference. I’ve been in Berlin for this conference several times in the past, from the days when they held the Community Day event in their office by just pushing back all the desks. Great to be back and hear about some of their successes since that time.
Day 1 started with an opening keynote by Jakob Freund, Camunda’s CEO. This is a live/online hybrid conference, and considering that Camunda did one of the first successful online conferences back in 2020 by keeping it live and real, this is shaping up to be a forerunner in the hybrid format, too. A lot of companies need to learn to do this, since many people aren’t getting back on a plane any time soon to go to a conference when it can be done online just as well.
Anyway, back to the keynote. Camunda just published the Process Orchestration Handbook, which is a marketing piece that distills some of the current messaging around process automation, and highlights some of the themes from Jakob’s keynote. He points out the problems with a lot of current process automation: there’s no end-to-end automation, no visibility into the overall process, and little flexibility to rework those processes as business conditions change. As a result, a lot of process automation breaks since it falls over whenever there’s a problem outside the scope of the automation of a specific set of tasks.
Jakob focused on a couple of things that make process orchestration powerful as a part of business automation: endpoint diversity (being able to connect a lot of different types of tasks into an integrated process) and process complexity (being able to include dynamic parallel execution, event-driven message correlation, and time-based escalation). These sound pretty straightforward, and for those of us who have been in process automation for a long time these are accepted characteristics of BPMN-based processes, but these are not the norm in a lot of process orchestration.
He also walked through the complexities that arise due to long-running processes, that is, anything that involves manual steps with knowledge workers: not the same as straight-through API-only process orchestration that doesn’t have to worry about state persistence. There are a few good customer stories here this week that bring all of these things together, and I plan to be attending some of those sessions.
He presented a view of the process automation market: BPMS, low-code platforms, process mining, iPaaS/integration, RPA, microservices orchestration, and process orchestration. Camunda doesn’t position itself in BPMS any more – mostly since the big analysts have abandoned this term – but in the process orchestration space. Looking at the intersection between the themes of endpoint diversity and process complexity that he talked about earlier, you can see where different tools end up. He even gives a nod to Gartner’s hyperautomation term and how process orchestration fits into the tech stack.
He finished up with a bit of Camunda’s product vision. They released V8 this year with the Zeebe engine, but much more than that is under development. More low-code especially around modeling and front-end human task technology, to enable less technical developers. Decision automation tied into process orchestration. And stronger coverage of AI, process mining and other parts of the hyperautomation tech stack through partnerships as well as their own product development.
Definitely some shift in the messaging going on here, and in some of Camunda’s direction. A big chunk of their development is going into supporting low-code and other “non-developer” personas, which they resisted for many years. They have a crossover point for pro-code developers to create connectors that are then used by low-code developers to assemble into process orchestrations – a collaboration that has been recognized by larger vendors for some time. Sensible plans and lots of cool new technology.
The rest of the day is pretty packed, and I’m having trouble deciding which sessions to attend since there are several concurrent that all sound interesting. Since most of them are also virtual for remote attendees, I assume the recordings will be available later and I can catch up on what I missed. It’s not too late to sign up to attend the rest of today and tomorrow virtually, or to see the recorded sessions after the fact.
Wow, it’s been over two months since my last post. I took a long break over the end of the year since there wasn’t a lot going on that inspired me to write, and we were in conference hiatus. Now that (virtual) conferences are ramping up again for 2021, I wanted to share some of the best practices that I gathered from attending — and in one case, organizing — virtual conferences over 2020. Having sent this information by email to multiple people who were organizing their own conferences, I decided to just put it here where everyone could enjoy it. Obviously, these are all conferences about intelligent automation platforms, but the best practices are applicable to any technical conference, and likely to many non-technical conferences.
In summary, I saw three key things that make a virtual conference work well:
Live presentations, not pre-recorded. This is essential for the amount of energy in the presentation, and makes the difference between a cohesive conference and a just a bunch of webinars. Screwups happen when you’re live, but they do at in-person conferences, too.
Separate and persistent discussion platform, such as Slack (or Pega’s community in the case of their conference). Do NOT use the broadcast vendor’s chat/discussion platform, since a) it will disappear once your conference is over, and b) it probably sucks.
Replays of the video posted as soon as possible, so that people who missed a live session can watch it and jump into the discussion later the same day while others are still talking about it. Extra points for also publishing the presentation slides at the same time.
A conference is not a one-way broadcast, it’s a big messy collaborative conversation
Let’s start with the list of the virtual conferences that I wrote about, with links to the posts:
What I saw by attending these helped me when I was asked to organize DecisionCAMP, which ran in late June: we did the sessions using Zoom with livestreaming to YouTube (participants could watch either way), used Slack as a discussion platform (which is still being used for ongoing discussions and to run monthly events), and YouTube for the on-demand videos. Fluxicon used a similar setup for their Process Mining Camp: Skype (I think) instead of Zoom to capture the speakers’ sessions with all participants watching through the YouTube livestream and discussions on Slack.
Some particular notes excerpted from my posts on the vendor conferences follow. If you want to see the full blog posts, use the tag links above or just search.
Camunda
“Every conference organizer has had to deal with either cancelling their event or moving it to some type of online version as most of us work from home during the COVID-19 pandemic. Some of these have been pretty lacklustre, using only pre-recorded sessions and no live chat/Q&A, but I had expectations for Camunda being able to do this in a more “live” manner that doesn’t completely replace an in-person event, but has a similar feel to it. They did not disappoint: although a few of the CamundaCon presentations were pre-recorded, most were done live, and speakers were available for live Q&A. They also hosted a Slack workspace for live chat, which is much better than the Q&A/chat features on the webinar broadcast platform: it’s fundamentally more feature-rich, and also allows the conversations to continue after a particular presentation completes.”
“As you probably gather from my posts today, I’m finding the CamundaCon online format to be very engaging. This is due to most of the presentations being performed live (not pre-recorded as is seen with most of the online conferences these days) and the use of Slack as a persistent chat platform, actively monitored by all Camunda participants from the CEO on down.”
“I mentioned on Twitter today that CamundaCon is now the gold standard for online conferences: all you other vendors who have conferences coming up, take note. I believe that the key contributors to this success are live (not pre-recorded) presentations, use of a discussion platform like Slack or Discord alongside the broadcast platform, full engagement of a large number of company participants in the discussion platform before/during/after presentations, and fast upload of the videos for on-demand watching. Keep in mind that a successful conference, whether in-person or online, allows people to have unscripted interactions: it’s not a one-way broadcast, it’s a big messy collaborative conversation.”
Note that things did go wrong occasionally — one presentation was cut off part way through when the presenter’s home internet died. However, the energy level of the presentations was really high, making me want to keep watching. Also hilarious when one speaker talked about improving their “shittiest process” which is probably only something that would come out spontaneously during a live presentation.
Alfresco
“Alfresco Modernize didn’t have much of a “live” feel to it: the sessions were all pre-recorded which, as I’ve mentioned in my coverage of other online conferences, just doesn’t have the same feel. Also, without a full attendee discussion capability, this was more like a broadcast of multiple webinars than an interactive event, with a short Q&A session at the end as the only point of interaction.”
Celonis
“A few notes on the virtual conference format. Last week’s CamundaCon Live had sessions broadcast directly from each speaker’s home plus a multi-channel Slack workspace for discussion: casual and engaging. Celonis has made it more like an in-person conference by live-broadcasting the “main stage” from a studio with multiple camera angles; this actually worked quite well, and the moderator was able to inject live audience questions. Some of the sessions appeared to be pre-recorded, and there’s definitely not the same level of audience engagement without a proper discussion channel like Slack — at an in-person event, we would have informal discussions in the hallways between sessions that just can’t happen in this environment. Unfortunately, the only live chat is via their own conference app, which is mobile-only and has a single chat channel, plus a separate Q&A channel (via in-app Slido) for speakers that is separated by session and is really more of a webinar-style Q&A than a discussion. I abandoned the mobile app early and took to Twitter. I think the Celosphere model is probably what we’re going to see from larger companies in their online conferences, where they want to (attempt to) tightly control the discussion and demonstrate the sort of high-end production quality that you’d have at a large in-person conference. However, I think there’s an opportunity to combine that level of production quality with an open discussion platform like Slack to really improve the audience experience.”
“Camunda and Celonis have both done a great job, but for very different reasons: Camunda had much better audience engagement and more of a “live” feel, while Celonis showed how to incorporate higher production quality and studio interviews to good effect.”
“Good work by Celonis on a marathon event: this ran for several hours per day over three days, although the individual presentations were pre-recorded then followed by live Q&A. Lots of logistics and good production quality, but it could have had better audience engagement through a more interactive platform such as Slack.”
IBM
“As I’ve mentioned over the past few weeks of virtual conferences, I don’t like pre-recorded sessions: they just don’t have the same feel as live presentations. To IBM’s credit, they used the fact that they were all pre-recorded to add captions in five or six different languages, making the sessions (which were all presented in English) more accessible to those who speak other languages or who have hearing impairments. The platform is pretty glitchy on mobile: I was trying to watch the video on my tablet while using my computer for blogging and looking up references, but there were a number of problems with changing streams that forced me to move back to desktop video for periods of time. The single-threaded chat stream was completely unusable, with 4,500 people simultaneously typing “Hi from Tulsa” or “you are amazing”.”
“IBM had to pivot to a virtual format relatively quickly since they already had a huge in-person conference scheduled for this time, but they could have done better both for content and format given the resources that they have available to pour into this event. Everyone is learning from this experience of being forced to move events online, and the smaller companies are (not surprisingly) much more agile in adapting to this new normal.”
Appian
“This was originally planned as an in-person conference, and Appian had to pivot on relatively short notice. They did a great job with the keynotes, including a few of the Appian speakers appearing (appropriately distanced) in their own auditorium. The breakout sessions didn’t really grab me: too many, all pre-recorded, and you’re basically an audience of one when you’re in any of them, with little or no interactivity. Better as a set of on-demand training/content videos rather than true breakout sessions, and I’m sure there’s a lot of good content here for Appian customers or prospects to dig deeper into product capabilities but these could be packaged as a permanent library of content rather than a “conference”. The key for virtual conferences seems to be keeping it a bit simpler, with more timely and live sessions from one or two tracks only.”
Signavio
“Signavio has a low-key format of live presentations that started at 11am Sydney time with a presentation by Property Exchange Australia: I tuned in from my timezone at 9pm last night, stayed for the Deloitte Australia presentation, then took a break until the last part of the Coca-Cola European Partners presentation that started at 8am my time. In the meantime, there were continuous presentations from APAC and Europe, with the speakers all presenting live in their own regular business hours.”
“The only thing missing is a proper discussion platform — I have mentioned this about several of the online conferences that I’ve attended, and liked what Camunda did with a Slack workspace that started before and continued after the conference — although you can ask questions via the GoToWebinar Question panel. To be fair, there is very little social media engagement (the Twitter hashtag for the conference is mostly me and Signavio people), so possibly the attendees wouldn’t get engaged in a full discussion platform either. Without audience engagement, a discussion platform can be a pretty lonely place. In summary, the GTW platform seems to behave well and is a streamlined experience if you don’t expect a lot of customer engagement, or you could use it with a separate discussion platform.”
Pega
“In general, I didn’t find the prerecorded sessions to be very compelling. Conference organizers may think that prerecording sessions reduces risk, but it also reduces spontaneity and energy from the presenters, which is a lot of what makes live presentations work so well. The live Q&A interspersed with the keynotes was okay, and the live demos in the middle breakout section as well as the live Tech Talk were really good. PegaWorld also benefited from Pega’s own online community, which provided a more comprehensive discussion platform than the broadcast platform chat or Q&A.”
Fluxicon
“The format is interesting, there is only one presentation each day, presented live using YouTube Live (no registration required), with some Q&A at the end. The next day starts with Process Mining Café, which is an extended Q&A with the previous day’s presenter based on the conversations in the related Slack workspace (which you do need to register to join), then a break before moving on to that day’s presentation. The presentations are available on YouTube almost as soon as they are finished.”
“The really great part was engaging in the Slack discussion while the keynote was going on. A few people were asking questions (including me), and Mieke Jans posted a link to a post that she wrote on a procedure for cleansing event logs for multi-case processes – not the same as what van der Aalst was talking about, but a related topic. Anne Rozinat posted a link to more reading on these types of many-to-many situations in the context of their process mining product from their “Process Mining in Practice” online book. Not surprisingly, there was almost no discussion on the Twitter hashtag, since the attendees had a proper discussion platform; contrast this with some of the other conferences where attendees had to resort to Twitter to have a conversation about the content. After the keynote, van der Aalst even joined in the discussion and answered a few questions, plus added the link for the IEEE task force on process mining that promotes research, development, education and understanding of process mining: definitely of interest if you want to get plugged into more of the research in the field. As a special treat, Ferry Timp created visual notes for each day and posted them to the related Slack channel.”
Bizagi
“The broadcast platform fell over completely…I’m not sure if Bizagi should be happy that they had so many attendees that they broke the platform, or furious with the platform vendor for offering something that they couldn’t deliver. The “all-singing, all-dancing” platforms look nice when you see the demo, but they may not be scalable enough.”
Final thoughts
Just to wrap things up, it’s fair to say that things aren’t going to go back to the way that they were any time soon. Part of this is due to organizations understanding that things can be done remotely just as effectively (or nearly so) as they can in person, if done right. Also, a lot of people are still reluctant to even think about travelling and spending days in poorly-ventilated rooms with a bunch of strangers from all over the world.
The vendors who ran really good virtual conferences 2020 are almost certain to continue to run at least some of their events virtually in the future, or find a way to have both in-person and remote attendees simultaneously. If you run a virtual conference that doesn’t get the attendee engagement that you expected, the problem may not be that “virtual conferences don’t work”: it could be that you just aren’t doing it right.
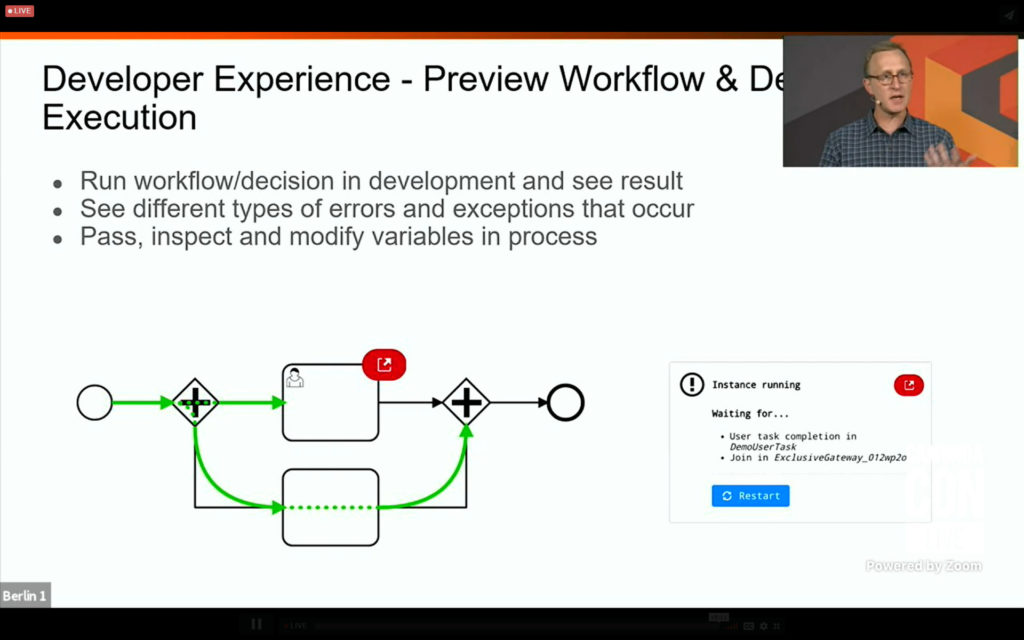
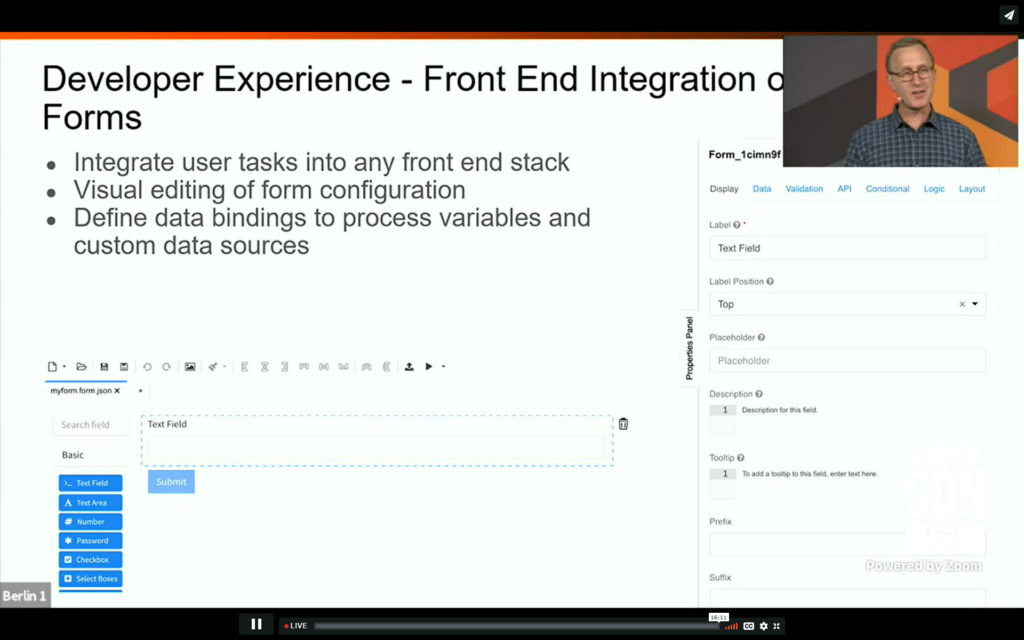
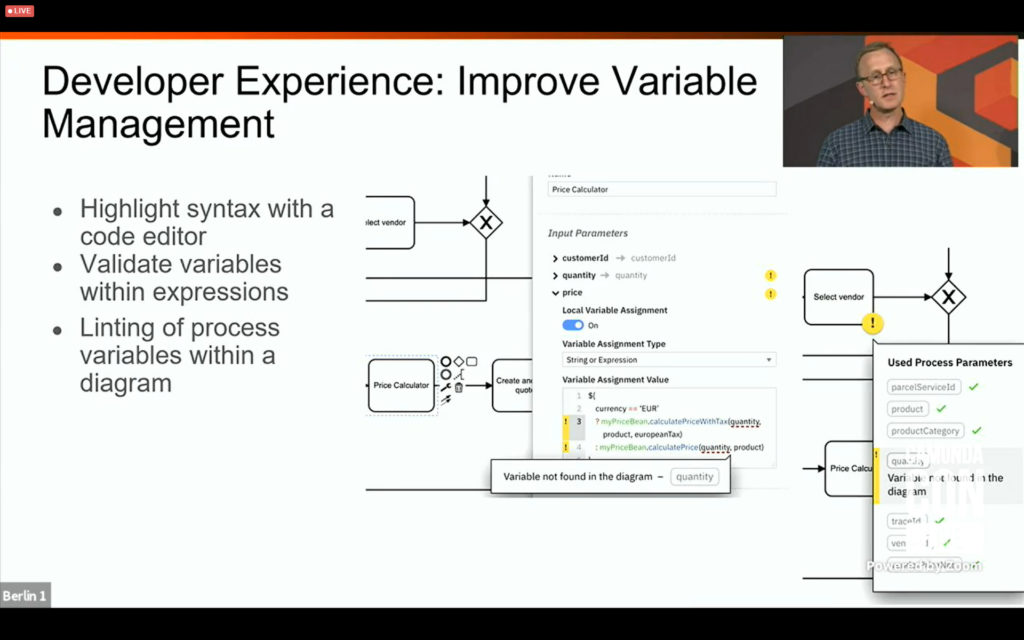
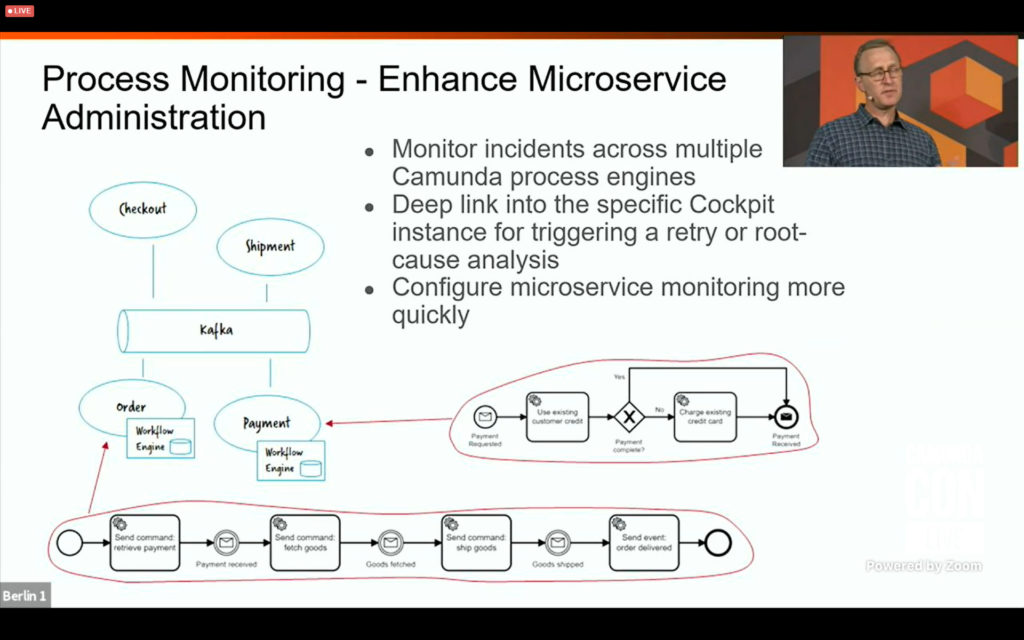
I split off the first part of CamundaCon day 2 since it was getting a bit long: I had a briefing with Daniel Meyer earlier in the week on the new RPA integration, and had a lot of thoughts on that already. I rejoined for Camunda VP of Product Management Rick Weinberg’s roadmap presentation, which covered what’s coming in 2021. If you’re a Camunda customer, or thinking about becoming one, you should check out the replay of his session if you missed it. Expect to see updates to decision automation, developer experience, process monitoring and interoperability.
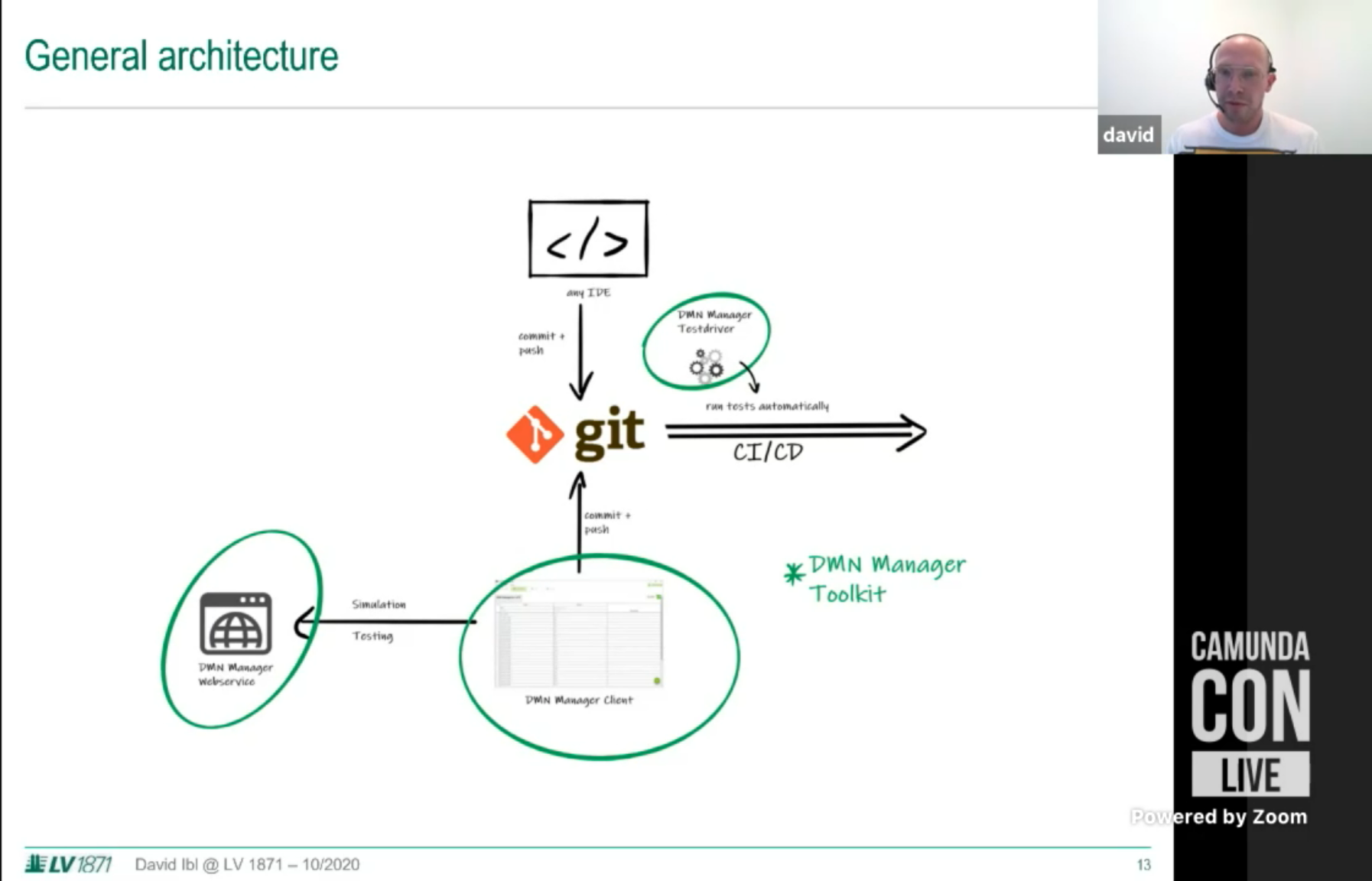
I tuned in to the business architecture track for a presentation by David Ibl, Enterprise Architect at LV 1871 (a German insurance company) on how they enabled their business specialists to perform decision model simulation and test case definition using their own DMN Manager based on the Camunda modeler toolkit. Their business people were already using BPMN for modeling processes, but were modeling business decisions as part of the process, and needed to use externalize the rules from the processes in order to simplify the processes. This was initially done by moving the decisions to code, then calling that from within the process, but that made the decisions much less transparent to the business. Now, the business specialists model both BPMN and DMN in Signavio, which are then committed to git; these models are then pulled from git both for deployment and for testing and simulation directly by the business people. You can read a much better description of it written by David a few months ago. A good example (and demo) on how business people can model, test and simulate their own decisions as well as processes. And, since they’re committed to open source, you can find the code for it on github.
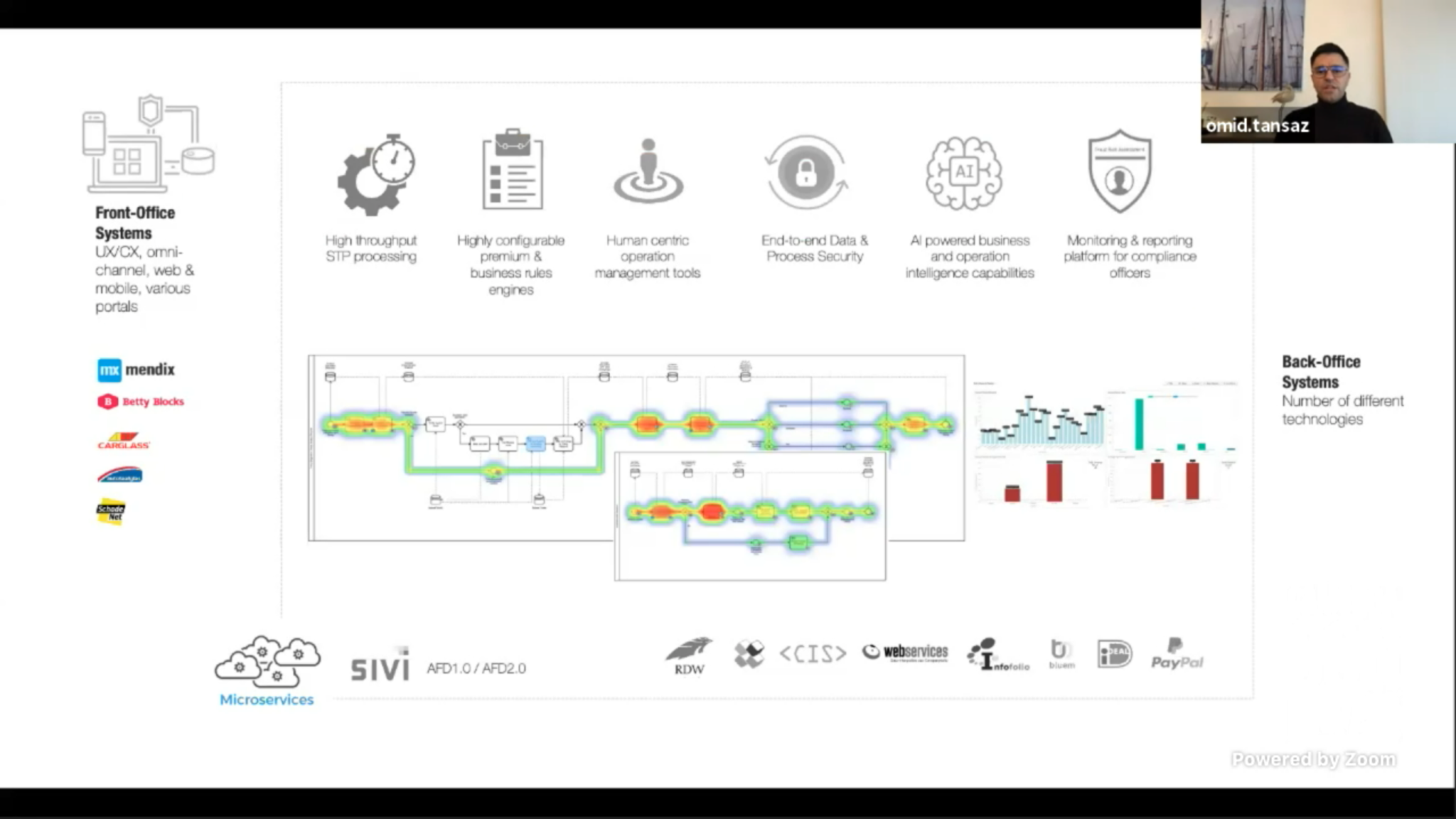
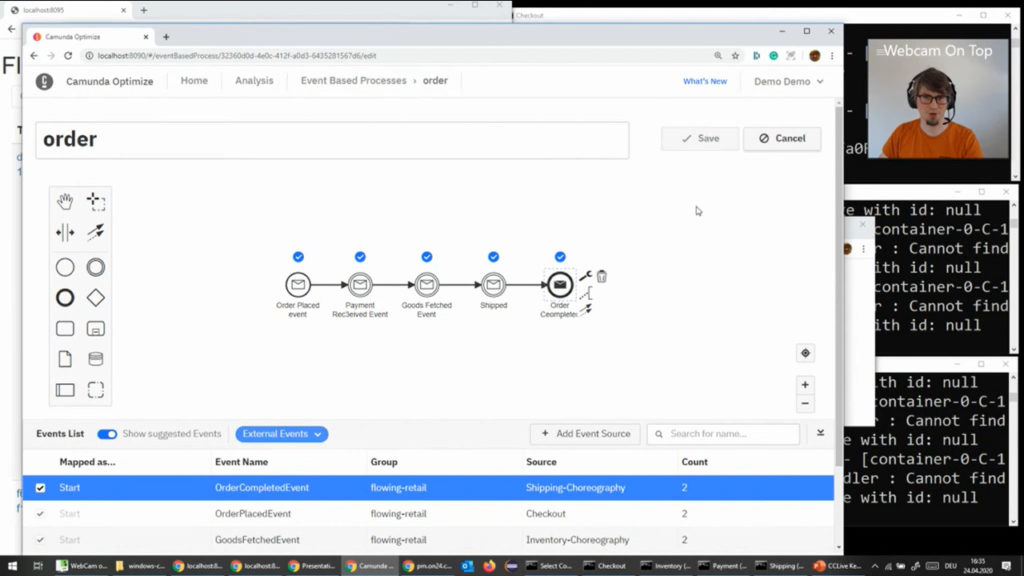
I also attended a session by Omid Tansaz of Nexxbiz, a Camunda consulting services partner, on their insurance process monitoring capability that allows systems across the entire end-to-end chain of insurance processes to be monitored in a consolidated fashion. This includes broker systems, front- and back-off systems within the insurer, as well as microservices. They were already using Camunda’s BPM engine, and started using Optimize for process visualization since Optimize 3.0 can include external event sources (from all of the other systems in the end-to-end process) as well as the Camunda BPM processes. This is one of the first case studies of the external event capability in Optimize, since that was only released in April, and show the potential for having a consolidated view across multiple systems: not just visibility, but compliance auditing, bottleneck analysis, and real-time issue prevention.
The conference closed with a keynote by Michael Kearns from the University of Pennsylvania on the science of socially-aware algorithm design. Ethical algorithms (the topic of his recent book written with Aaron Roth) are not just an abstract concept, but impact businesses from risk mitigation through to implementation patterns. There are many cases of how algorithmic decision-making shows definite biases, and instead of punting to legal and regulatory controls, their research looks at technical solutions to the problem in the form of better algorithms. This is a non-trivial issue, since algorithms often have outcomes that are difficult to predict, especially when machine learning is involved. This is exactly why software testing is often so bad (just to inject my own opinion): developers can’t or don’t consider the entire envelope of possible outcomes, and often just test the “happy path” and a few variants.
Kearns’ research proposes embedding social values in algorithms: privacy, fairness, accountability, interpretability and morality. This requires a definition of what these social values mean in a precise mathematical. There’s already been some amount of work on privacy by design, spearheaded by the former Ontario Information and Privacy Commissioner Ann Cavoukian, since privacy is one of the better-understood algorithmic concepts.
Kearns walked us through issues around algorithmic privacy, including the idea that “anonymized” data often isn’t actually anonymized, since the techniques used for this assume that there is only a single source of data. For example, redacting data within a data set can make it anonymous if that’s the only data set that you have; as soon as other data sets exist that contain one or more of the same unredacted data values, you can start to correlate the data sets and de-anonymize the data. In short, anonymization doesn’t work, in general.
He then looked at “differential privacy”, which compares the results of an algorithm with and without a specific person’s data: if an observer can’t tell the discern between the outcomes, then the algorithm is preserving the privacy of that person’s data. Differential privacy can be implemented by adding a small amount of random noise to each data point, which makes is impossible to figure out the contribution of any specific data point., and the noise contributions will cancel out of the results when a large number of data points are analyzed. Problems can occur, however, with data points that have very small values, which may be swamped by the size of the noise.
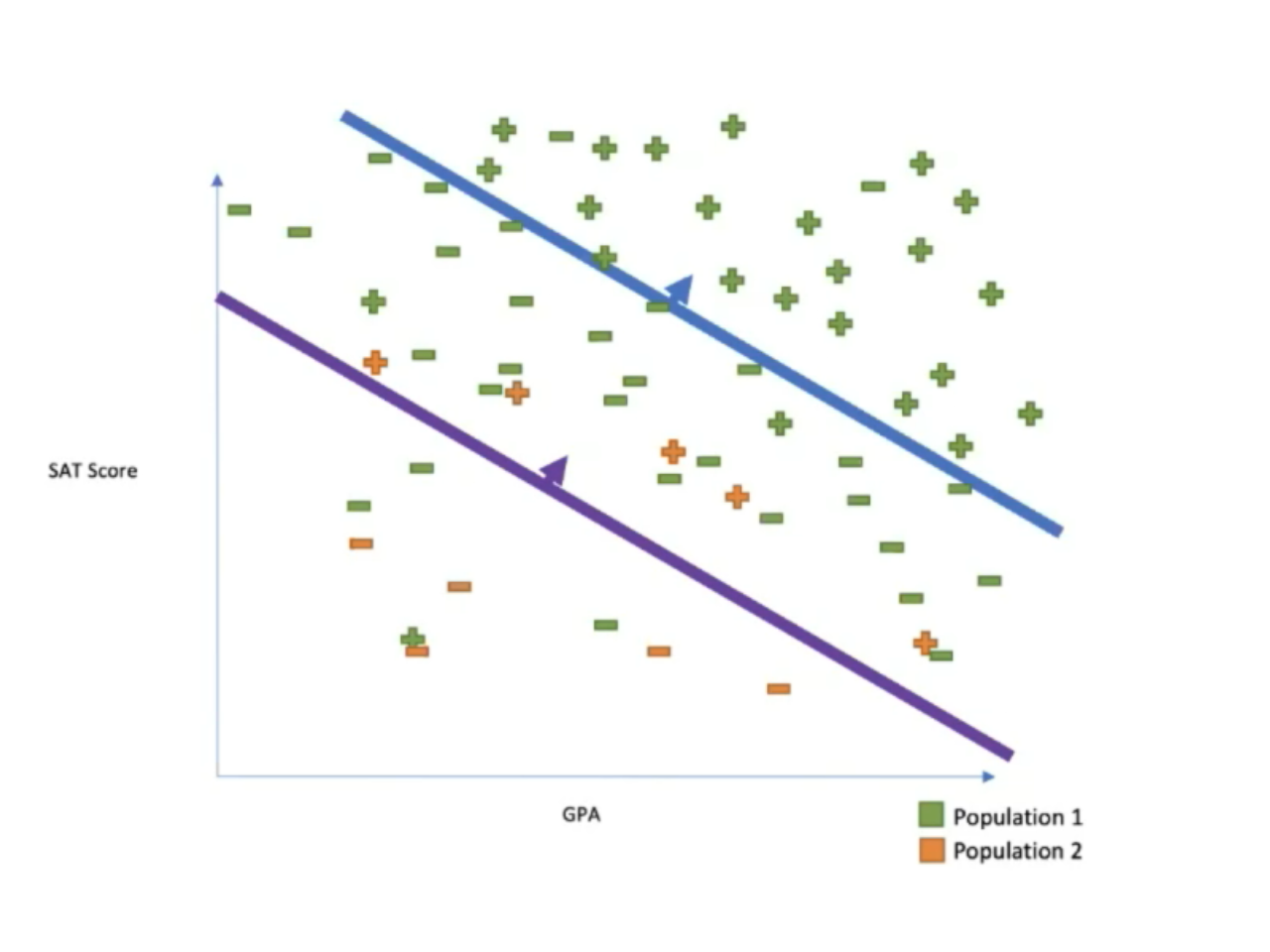
He moved on to look at algorithmic fairness, which is trickier: there’s no agreed-upon definition of fairness, and we’re only just beginning to understand tradeoffs, e.g., between race and gender fairness, or between fairness and accuracy. He had a great example of college admissions based on SAT and GPA scores, with two different data sets: one for more financially-advantaged students, and the other for students from modest financial situations. The important thing to note is that the family financial background of a student has a strong correlation with race, and in the US, as in other countries, using race as an explicit differentiator is not allowed in many decisions due to “fairness”. However, it’s not really fair if there are inherent advantages to being in one data set over the other, since those data points are artificially elevated.
There was a question at the end about the role of open source in these algorithms: Kearns mentioned OpenDP, an open source toolset for implementing differential privacy, and AI Fairness 360, an open source toolkit for finding and mitigating discrimination and bias in machine learning models. He also discussed some techniques for determining if your algorithms adhere to both privacy and fairness requirements, and the importance of auditing algorithmic results on an ongoing basis.
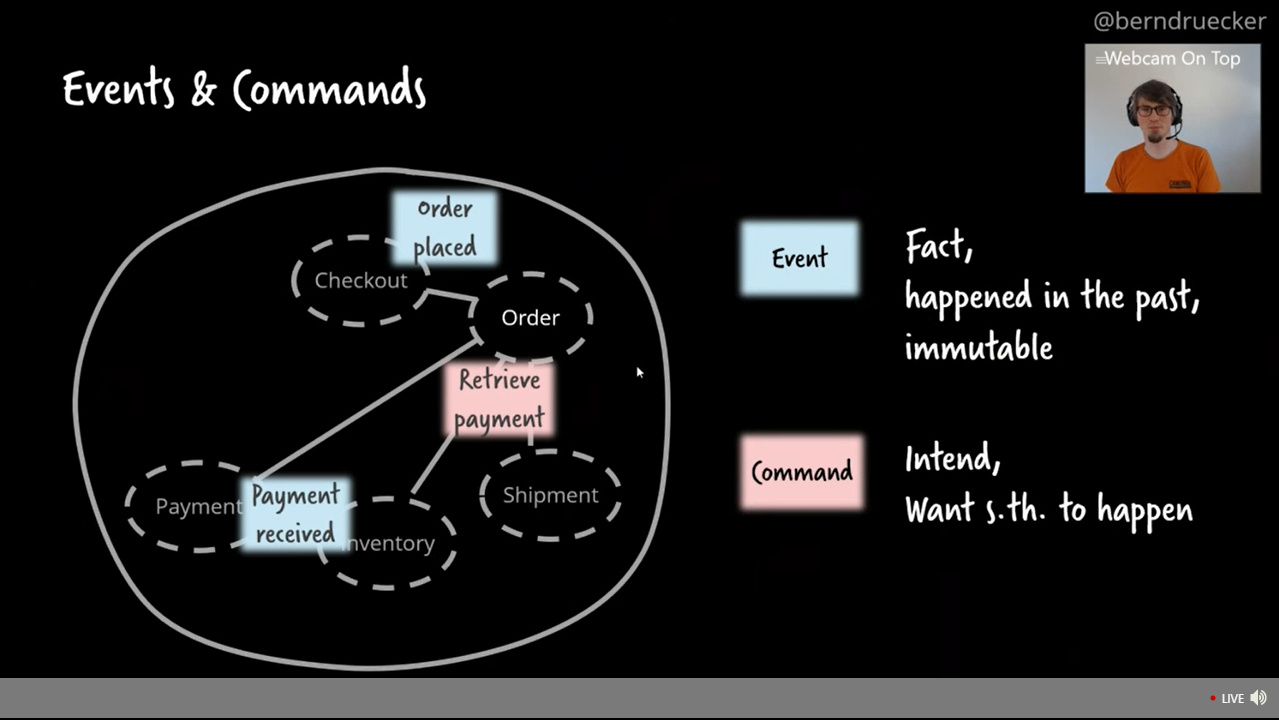
I’m back at CamundaCon 2020.2 for day 2, which kicked off with a keynote by Camunda co-founder and developer advocate Bernd Rücker. He’s a big fan of BPM and graphical models (obviously), but not of low-code: his view is that the best way to build robust process-based applications is with a stateful workflow engine, a graphical process modeler, and code. In my opinion, he’s not wrong for complex core applications, although I believe there are a lot of use cases for low code, too. He covered a number of different implementation architectures and patterns with their strengths and weaknesses, especially different types of event-driven architectures and how they are best combined with workflow systems. You can see the same concepts covered in some of his previous presentations, although every time I hear him give a presentation, there are some interesting new ideas. He’s currently writing a book call Practical Process Automation, which appears to be gathering many of these ideas together.
CTO Daniel Meyer was up next with details of the upcoming 7.14 release, particularly the RPA integration that they are releasing. He positions Camunda as having the ability to orchestrate any type of process, which may include endpoints (i.e., non-Camunda components for task execution) ranging from human work to microservices to RPA bots. Daniel and I have had a number of conversations about the future of different technologies, and although we have some disagreements, we are in agreement that RPA is an interim technology: it’s a stop-gap for integrating systems that don’t have APIs. RPA tends to be brittle, as pointed out by Camunda customer Goldman Sachs at the CamundaCon Live earlier this year, with a tendency to fail when anything in the environment changes, and no proper state maintained when failures occur. Daniel included a quote from a Forrester report that claims that 45% of organizations using RPA deal with breakage on at least a weekly basis.
As legacy systems are replaced, or APIs created for them, RPA bots will gradually be replaced as the IT infrastructure is modernized. In the meantime, however, we need to deal with RPA bots and limit the technical debt of converting the bots in the future when APIs are available. Camunda’s solution is to orchestrate the bots as external tasks; my advice would also be to refactor the bots to push as much process and decision logic as possible into the Camunda engine, leaving only the integration/screen scraping capabilities in the bots, which would further reduce the future effort required to replace them with APIs. This would require that RPA low-code developers learn some of the Camunda process and decision modeling, but this is done in the graphical modelers and would be a reasonable fit with their skills.
The new release includes task templates for adding RPA bots to processes in the modeler, plus an RPA bridge service that connects to the UiPath orchestrator, which in turn manages UiPath bots. Camunda will (I assume) extend their bridge to integrate with other RPA vendors’ orchestrators in the future, such as Automation Anywhere and Blue Prism. What’s interesting, however, is that the current architecture of this is that the RPA task in a process is an external task — a task that relies on an external agent to poll for work, rather than invoking a service call directly — then the Camunda RPA bridge invokes the RPA vendor’s orchestrator, then the RPA bots poll their own orchestrator. If you are using a different RPA platform, especially one that doesn’t have an orchestrator, you could configure the bots to poll Camunda directly at the external task endpoint. In short, although the 7.14 release will add some capabilities that make this easier (for enterprise customers only), especially if you’re using UiPath, you should be able to do this already with any RPA product and external tasks in Camunda.
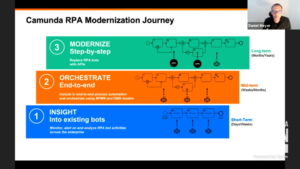
Daniel laid out a modernization journey for companies with an existing army of bots: first, add in monitoring of the bot activities using Camunda Optimize, which now has the capability to monitor external events, in order to gain insights into the existing bot activities across the organization. Then, orchestrate the bots using the Camunda workflow engine (both BPMN and DMN models) using the tools and techniques described above. Lastly, as API replacements become available for bots, switch them out, which could require some refactoring of the Camunda models. There will likely be some bots left hanging around for legacy systems that are never going to have APIs, but that number should dwindle over the years.
Daniel also teased some of the “smart low-code” capabilities that are on the Camunda roadmap, which will covered in more detail later by Rick Weinberg, since support for RPA low-code developers is going to push them further into this territory. They’re probably never going to be a low-code platform, but are becoming more inclusive for low-code developers to perform certain tasks within a Camunda implementation, while professional developers are still there for most of the application development.
This is getting a bit long, so I’m going to publish this and start a new post for later sessions. On a technical note, the conference platform is a bit wonky on a mobile browser (Chrome on iPad); although it’s “powered by Zoom”, it appears in the browser as an embedded Vimeo window that sometimes just doesn’t load. Also, the screen resolution appears to be much lower than at the previous CamundaCon, with the embedded video settings maxing out at 720p: if you compare some of my screen shots from the two different conferences, the earlier ones are higher resolution, making them much more readable for smaller text and demos. In both cases, I was mostly watching and screen capping on iPad.
I listened to Camunda CEO Jakob Freund‘s opening keynote from the virtual CamundaCon 2020.2 (the October edition), and he really hit it out of the park. I’ve known Jakob a long time and many of our ideas are aligned, and there was so much in particular in his keynote that resonated with me. He used the phrase “reinvent [your business] or die”, whereas I’ve been using “modernize or perish”, with a focus not just on legacy systems and infrastructure, but also legacy organizational culture. Not to hijack this post with a plug for another company, but I’m doing a keynote at the virtual Bizagi Catalyst next week on aligning intelligent automation with incentives and business outcomes, which looks at issues of legacy organizational culture as well as the technology around automation. Processes are, as he pointed out, the algorithms of an organization: they touch everything and are everywhere (even if you haven’t automated them), and a lot of digital-native companies are successful precisely because they have optimized those algorithms.
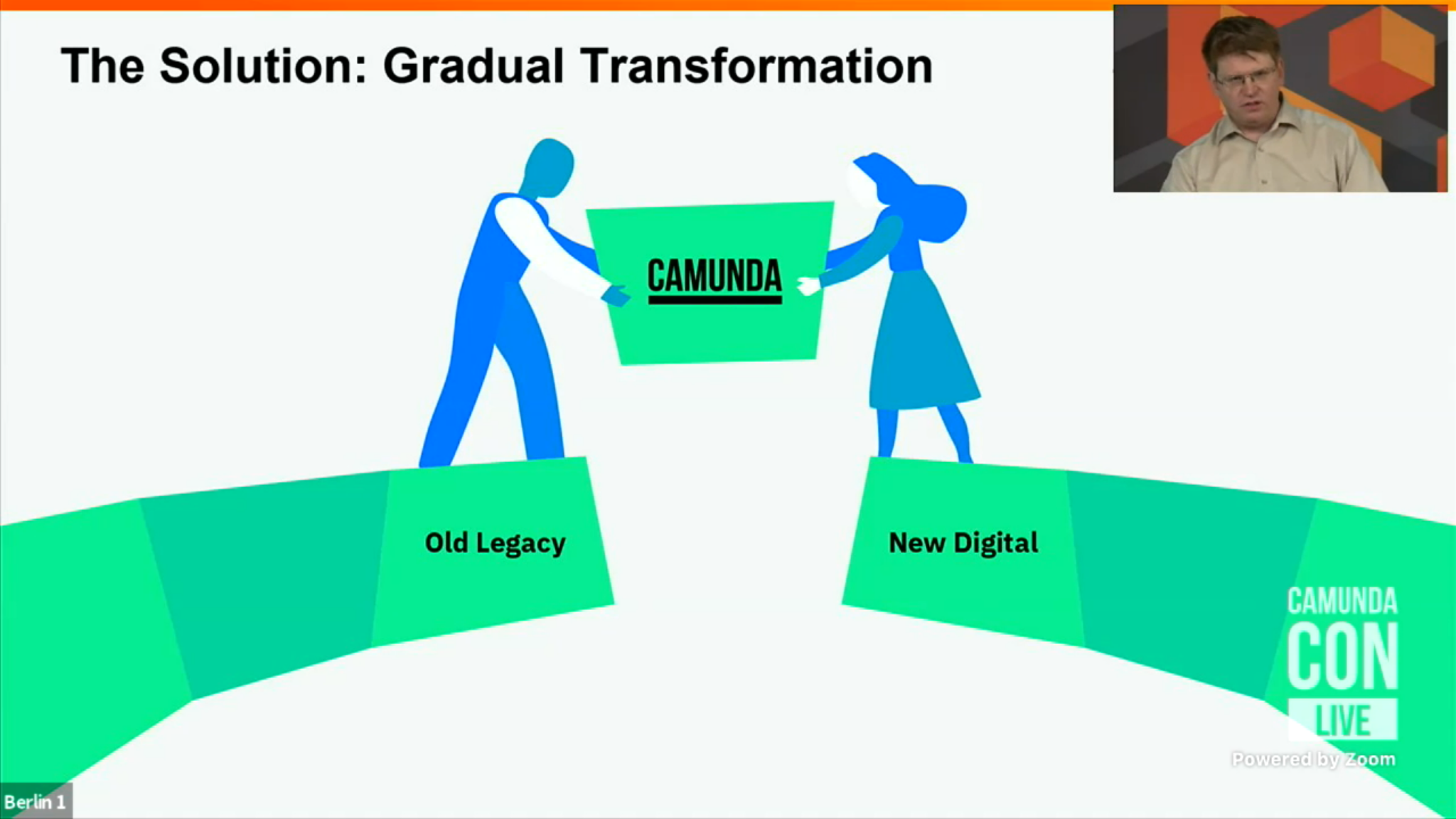
Jakob’s advice in achieving reinvention/modernization is to do a gradual transformation, not try to do a big bang approach that fails more often than it succeeds, and positions Camunda (of course) as the bridge between the worlds of legacy and new technology. In my years of technology consulting on BPM implementations, I also recommend using a gradual approach by building bridges between new and old technology, then swapping out the legacy bits as you develop or buy replacements. This is where, for example, you can use RPA to create stop-gap task automation with your existing legacy systems, then gradually replace the underlying legacy or at least create APIs to replace the RPA bots.
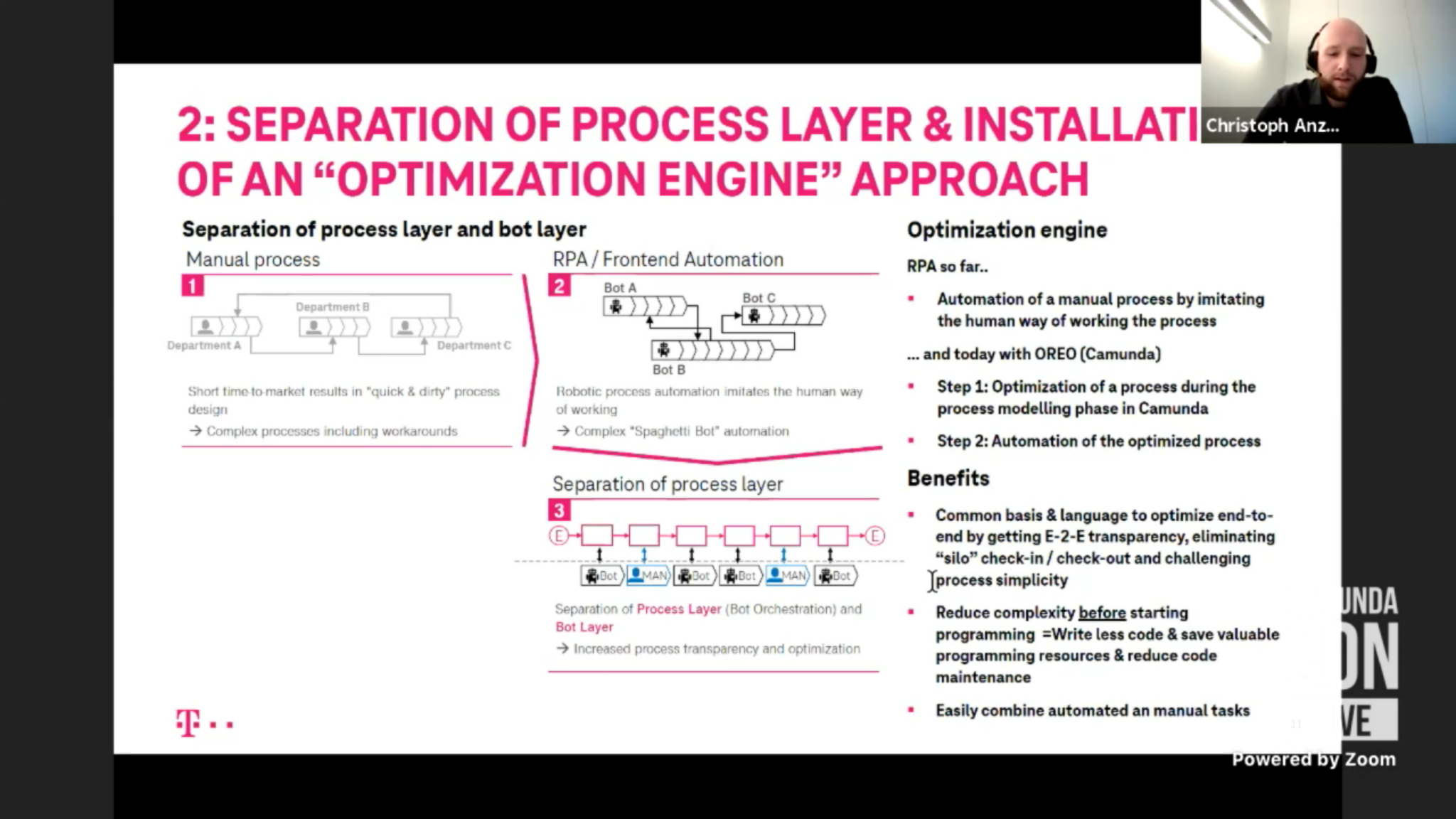
The second opening keynote was with Marco Einacker and Christoph Anzer of Deutsche Telekom, discussing how they are using process and task automation by combining Camunda for the process layer and RPA at the task layer. They started out with using RPA for automating tasks and processes, ending up with more than 3,000 bots and an estimated €93 million in savings. It was a very decentralized approach, with initially being created by business areas without IT involvement, but as they scaled up, they started to look for ways to centralize some of the ideas and technology. First was to identify the most important tasks to start with, namely those that were true pain points in the business (Einacker used the phrase ” look for the shittiest, most painful process and start there”) not just the easy copy-paste applications. They also looked at how other smart technologies, such as OCR and AI, could be integrated to create completely unattended bots that add significant value.
The decentralized approach resulted in seven different RPA platforms and too much process automation happening in the RPA layer, which increased the amount of technical debt, so they adapted their strategy to consolidate RPA platforms and separate the process layer from the bot layer. In short, they are now using Camunda for process orchestration, and the RPA bots have become tasks that are orchestrated by the process engine. Gradually, they are (or will be) replacing the RPA bots with APIs, which moves the integration from front-end to back-end, making it more robust with less maintenance.
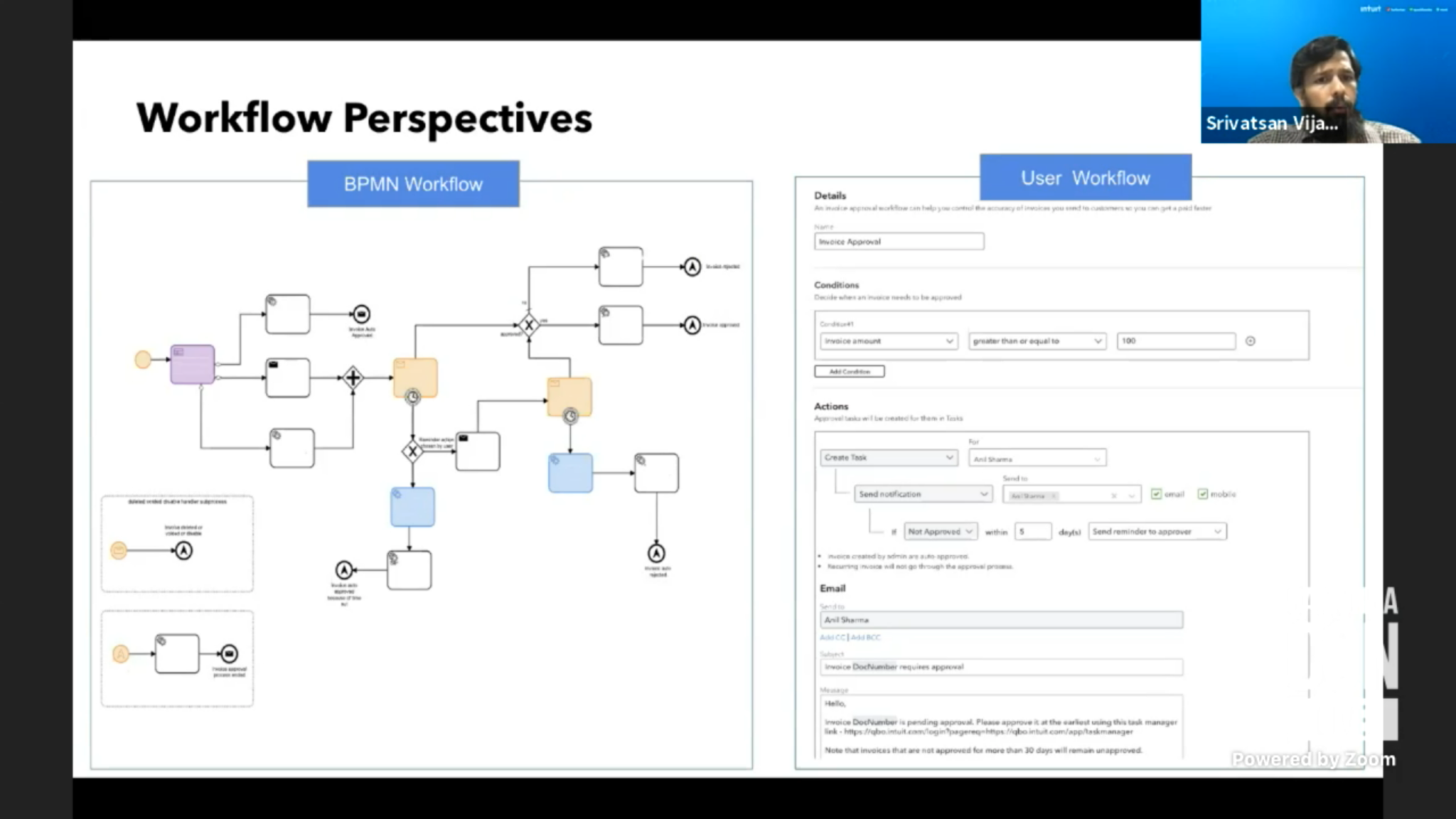
I moved off to the business architecture track for a presentation by Srivatsan Vijayaraghavan of Intuit, where they are using Camunda for three different use cases: their own internal processes, some customer-facing processes for interacting with Intuit, and — most interesting to me — enabling their customers to create their own workflows across different applications. Their QuickBooks customers are primarily small and mid-sized business that don’t have the skills to set up their own BPM system (although arguably they could use one of the many low-code process automation platforms to do at least part of this), which opened the opportunity for Intuit to offer a workflow solution based on Camunda but customizable by the individual customer organizations. Invoice approvals was an obvious place to start, since Accounts Payable is a problem area in many companies, then they expanded to other approval types and integration with non-Intuit apps such as e-signature and CRM. Customers can even build their own workflows: a true workflow as a service model, with pre-built templates for common workflows, integration with all Intuit services, and a simplified workflow designer.
Intuit customers don’t interact directly with Camunda services; Camunda is a separately hosted and abstracted service, and they’ve used Kafka messages and external task patterns to create the cut-out layer. They’ve created a wrapper around the modeling tools, so that customers use a simplified workflow designer instead of the BPMN designer to configure the process templates. There is an issue with a proliferation of process definitions as each customer creates their own version of, for example, an invoice approval workflow — he mentioned 70,000 process definitions — and they will likely need to do some sort of automated cleanup as the platform matures. Really interesting use case, and one that could be used by large companies that want their internal customers to be able to create/customize their own workflows.
The next presentation was by Stephen Donovan of Fidelity Investments and James Watson of Doculabs. I worked with Fidelity in 2018-19 to help create the architecture for their digital automation platform (in my other life, I’m a technical architecture/strategy consultant); it appears that they’re not up and running with anything yet, but they have been engaging the business units on thinking about digital transformation and how the features of the new Camunda-based platform can be leveraged when the time comes to migrate applications from their legacy workflow platform. This doesn’t seem to have advanced much since they talked about it at the April CamundaCon, although Donovan had more detailed insights into how they are doing this.
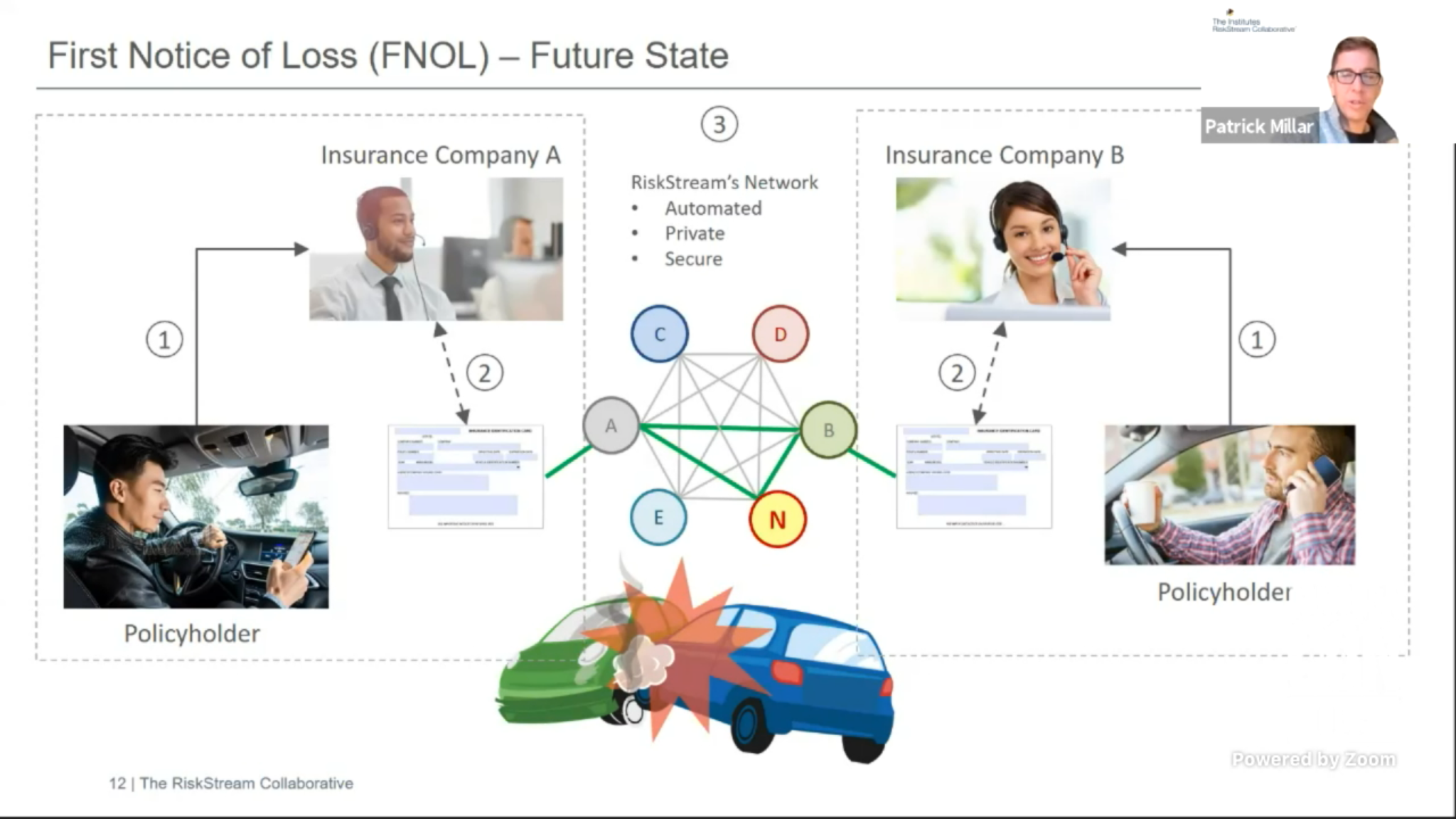
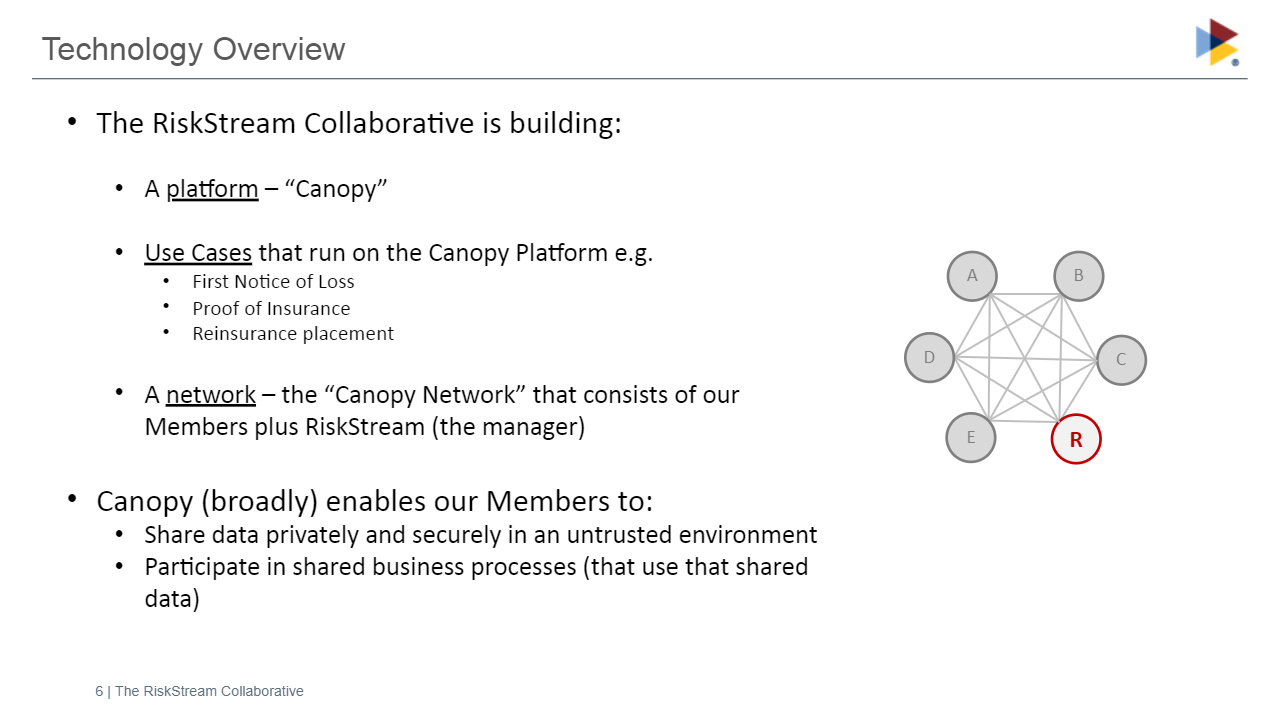
At the April CamundaCon, I watched Patrick Millar’s presentation on using Camunda for blockchain ledger automation, or rather I watched part of it: his internet died partway through and I missed the part about how they are using Camunda, so I’m back to see it now. The RiskStream Collaborative is a not-for-profit consortium collaborating on the use of blockchain in the insurance industry; their parent organization, The Institutes, provides risk management and insurance education and is guided by senior executives from the property and casualty industry. To copy from my original post, RiskStream is creating a distributed network platform, called Canopy, that allows their insurance company members to share data privately and securely, and participate in shared business processes. Whenever you have multiple insurance companies in an insurance process, like a claim for a multi-vehicle accident, having shared business processes — such as first notice of loss and proof of insurance — between the multiple insurers means that claims can be settled quicker and at a much lower cost.
I do a lot of work with insurance companies, as well as with BPM vendors to help them understand insurance operations, and this really resonates: the FNOL (first notice of loss) process for multi-party claims continues to be a problem in almost every company, and using enterprise blockchain to facilitate interactions between the multiple insurers makes a lot of sense. Note that they are not creating or replacing claims systems in any way; rather, they are connecting the multiple insurance companies, who would then integrate Canopy to their internal claims systems such as Guidewire.
Camunda is used in the control framework layer of Canopy to manage the flows within the applications, such as the FNOL application. The control framework is just one slice of the platform: there’s the core distributed ledger layer below that, where the blockchain data is persisted, and an integration layer above it to integrate with insurers’ claims systems as well as the identity and authorization registry.
There was a Gartner keynote, which gave me an opportunity to tidy up the writing and images for the rest of this post, then I tuned back in for Niall Deehan’s session on Camunda Hackdays over on the community tech track, and some of the interesting creations that come out of the recent virtual version. This drives home the point that Camunda is, at its heart, open source software that relies on a community of developer both within and outside Camunda to extend and enhance the core product. The examples presented here were all done by Camunda employees, although many of them are not part of the development team, but come from areas such as customer-facing consulting. These were pretty quick demos so I won’t go into detail, but here are the projects on Github:
DMN testing plugin, for testing DRD diagrams, by Stefan Wiese, Max Trumpf and Maciej Barelkowski
Deployment descriptor editor, for getting/setting running server configuration settings, by Chris Allen and Andreas Remdt
CamundaCloud Twitter raffle, to demonstrate 3rd party API integration and microservices, by Leonhardt Wille, Lars Lange and Sebastian Bathke
If you’re a Camunda customer (open source or commercial) and you like one of these ideas, head on over to the related github page and star it to show your interest.
There was a closing keynote by Capgemini; like the Gartner keynote, I felt that it wasn’t a great fit for the audience, but those are my only real criticisms of the conference so far.
Jakob Freund came back for a conversation with Mary Thengvall to recap the day. If you want to see the recorded videos of the live sessions, head over to the agenda page and click on Watch Now for any session.
It was a tough choice with the first post-break session at CamundaCon Live: I wanted to listen in on Rick Weinberg, Camunda VP of Products, as he talked about their product direction roadmap, but I decided on the presentation by Muthukumar Vaidhianathan and Tandeep Sidhu from Capital One instead, focused on their process automation modernization with Camunda. I’ll catch the recorded version of Weinberg’s session later, along with a few others that I want to see.
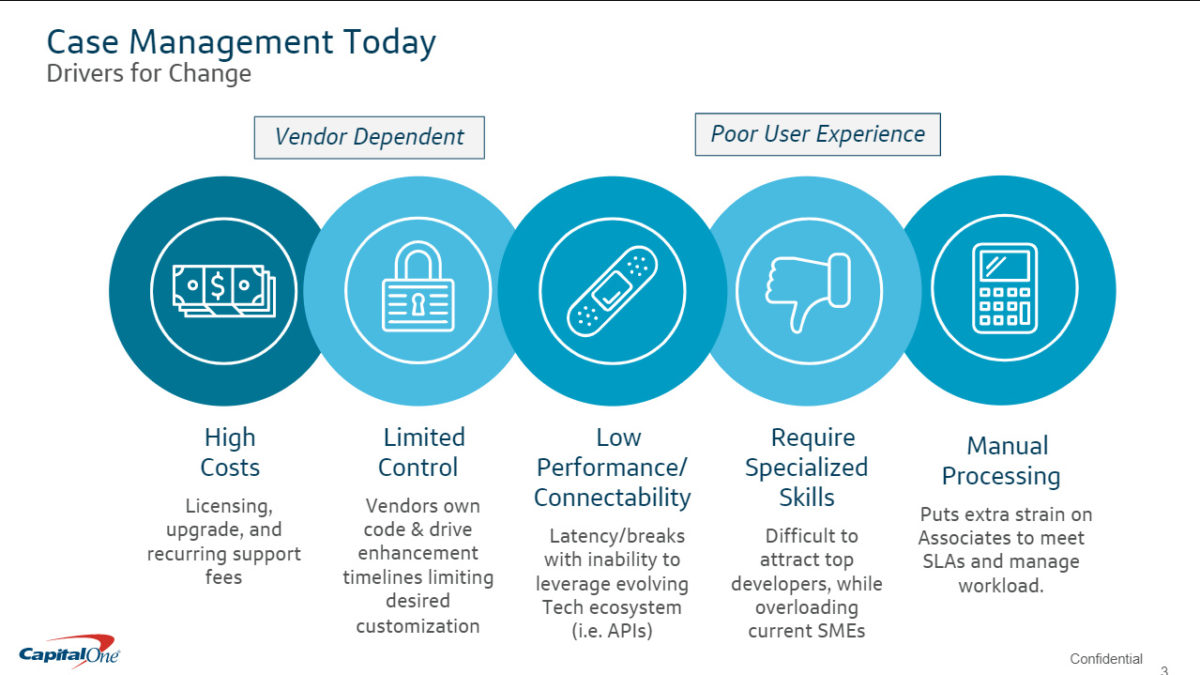
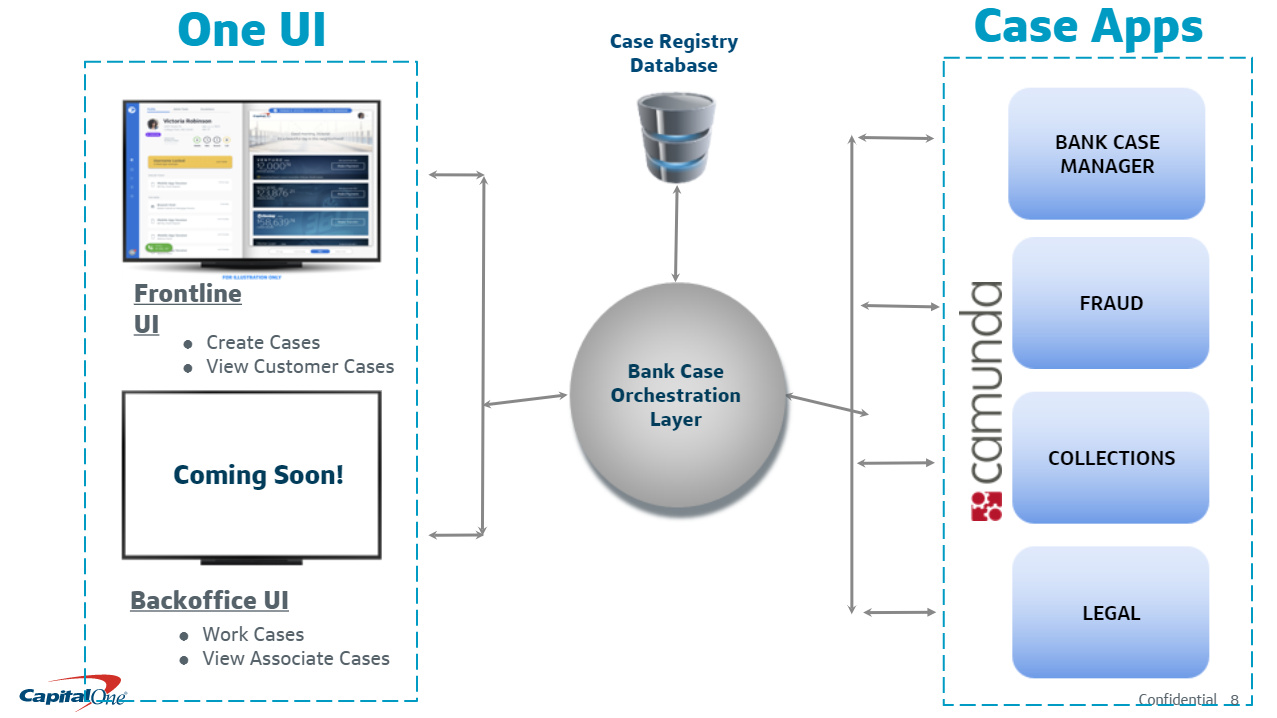
Vaidhianathan and Sidhu talked about some of the problems that they were having with case management using their legacy infrastructure, and how they selected and deployed Camunda. Sidhu talked quite a bit about getting the technical teams up and running with Camunda, and some of the team and DevOps scalability issues. They use a single consolidated UI (actually, one each for front office and back office workers), then a case orchestration layer that connects to the multiple Camunda-based applications: Bank Case Manager, Fraud, Collections, and Legal.
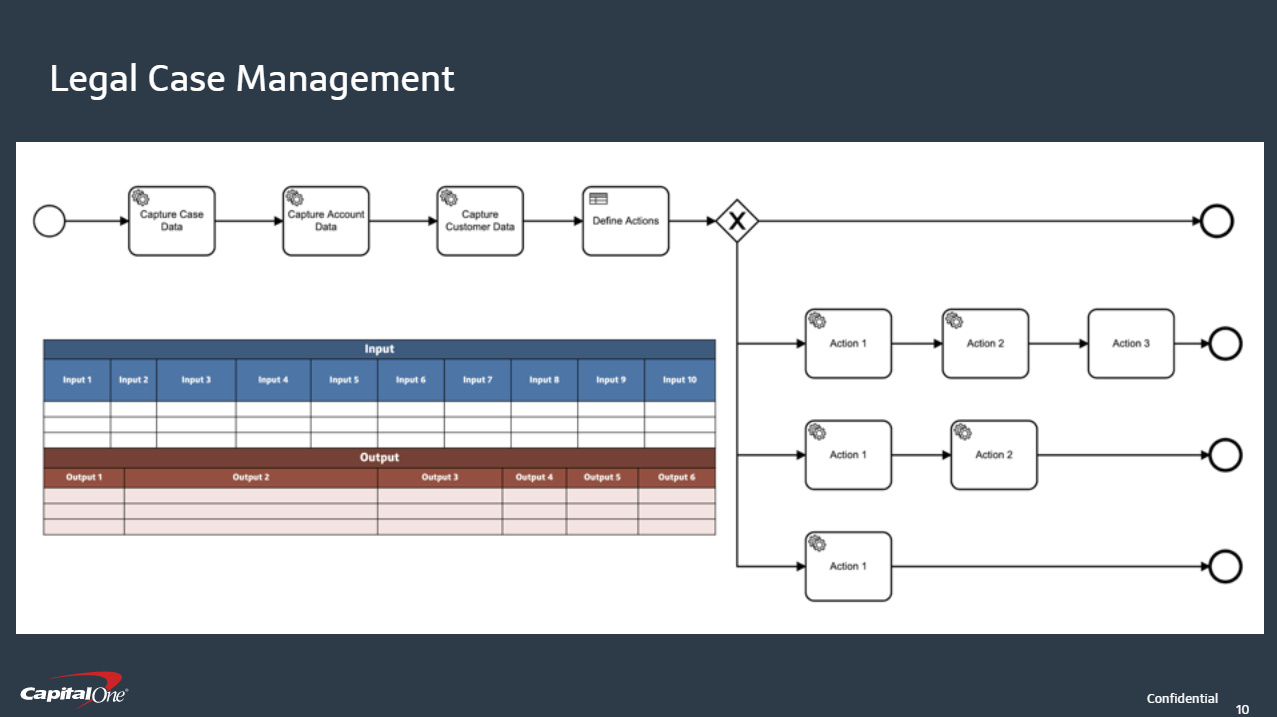
Vaidhianathan then took us through their Legal Case Management application, and how they use BPMN and DMN for automating with complex business rules. Decision tables are used to decide, for example, on the course of action for a particular case based on the data about the case. They feel that it’s important for product owners to own their BPMN and DMN models, while building the strong relationships between developers and the product owners on the business side. Some good lessons learned from their journey at the end.
Captial One also presented at the Camunda Day in NYC last summer, but talked about how they organized a Camunda hackathon rather than the business applications — I think they were much earlier in their journey then, and weren’t ready to talk about business applications yet.
I’ve been interested in blockchain and BPM for a while now, and listened in on Patrick Millar of the non-profit consortium RiskStream Collaborative as he presented on ledger automation using Camunda. Their parent organization is The Institutes, which provides risk management and insurance education, and is guided by senior executives from the property and casualty industry. RiskStream is creating a distributed network platform, called Canopy, that allows their insurance company members to share data privately and securely, and participate in shared business processes. Whenever you have multiple insurance companies in an insurance process, like a claim for a multi-vehicle accident, having shared business processes — such as first notice of loss and proof of insurance — between the multiple insurers means that claims can be settled quicker and at a much lower cost.
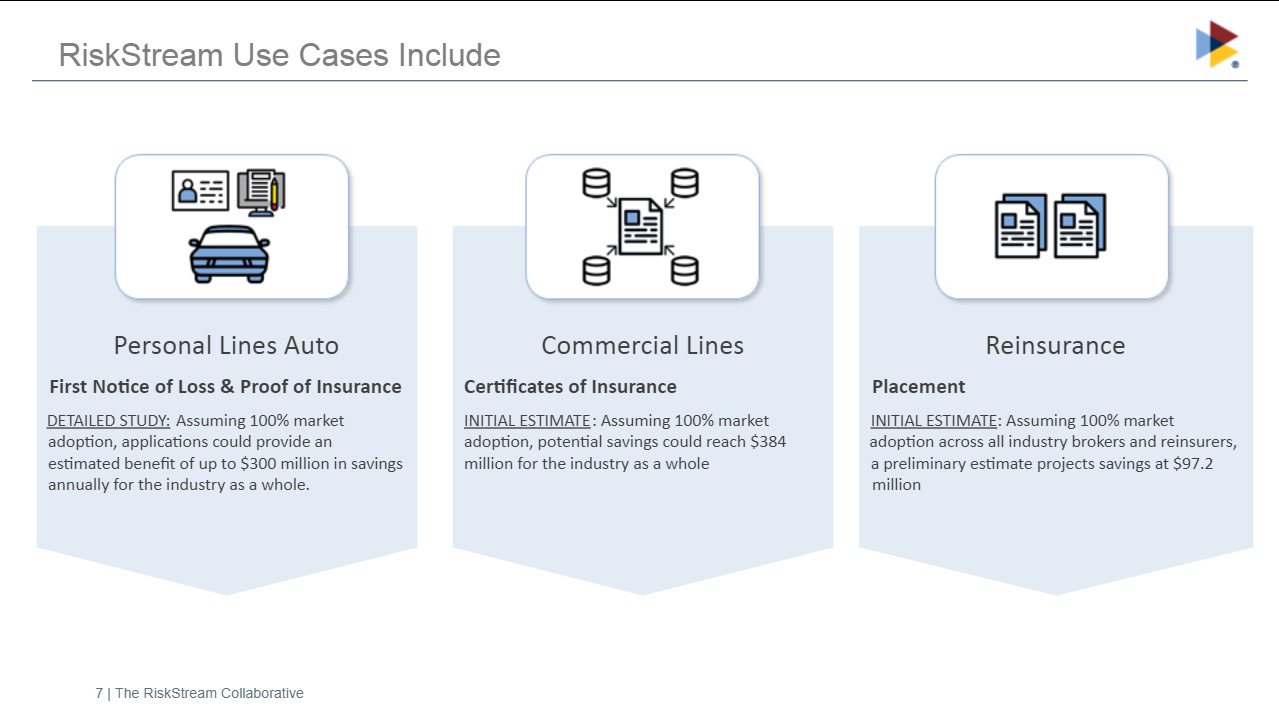
In addition to private lines of insurance, they are also looking at applications in commercial lines and reinsurance. There are pretty significant savings if they get 100% market adoption (not an unrealistic goal since the market is made up of their members): $300M in personal lines auto for FNOL and proof of insurance, $384 in commercial lines for certificates of insurance, and $97M in reinsurance for placement.
Unfortunately, we lost the audio/video connection to the presenter in the middle of the session (yes, this really is happening live, and shit happens) and they had to close the session, just as I was really getting into the topic. Also, he never got to the part about how they’re using Camunda. We’ve already heard from Camunda that they will have him record his presentation and have it added to the on-demand videos.
The next session brought both tracks back together for a panel on digital transformation, featuring Mike Ryan, VP Software Engineering at JP Morgan Chase; Christine Yen, CEO of Honeycomb; and Camunda’s Bernd Rücker. Mary Thengvall, Camunda’s Director of Developer Relations, moderated the panel. Here’s some of the points that came up:
We’ve built up these massive monolithic systems over the last few decades, but now need to break up these legacy pieces while still supporting them, all while adding new functionality in a more agile manner. This is making it difficult for many of the established companies to compete with the new competitors, such as older financial services companies competing with fintechs. (By the way, I talked about this on a recent webinar, and see it with my own enterprise customers)
There’s a need to protect — and improve — the customer experience while the monolith is being replaced piece by piece. In my opinion, “big bang” as a deployment model is dead: gradual migrations without disrupting the user experience should be the general method.
There has been a lot of change in roles and communication within organizations. DevOps is part of that, which changes what people are responsible for, and also the concept of process owners being responsible for the end-to-end metrics. Microservices (and service-oriented architecture in general) means that systems can be more targeted since they’re assembled from shared services for a unique purpose.
There are a lot of great tools and methodologies now, but many companies are not yet ready to implement them. Microservices, serverless architectures, etc. are changing how we design systems for future state.
The current pandemic crisis is driving some amount of digital transformation, and companies are having to decide what is critical for survival now versus what can wait. Ryan said that JP Morgan sent 300,000 employees home to work, and they are rethinking how productive that people can be in distributed environments, and how teams can still work collaboratively. As a financial company, they need to keep serving customers who need access to financial transactions, and are probably having to scale up their online customer experiences to accommodate. Yen believes there is as much of a focus on how people work together remotely to build applications, as there is on the technology itself.
The panel felt a bit unfocused, and wasn’t as engaging as yesterday’s panel. Possibly I’m not quite as fresh after live-blogging 6,000 words over two days.
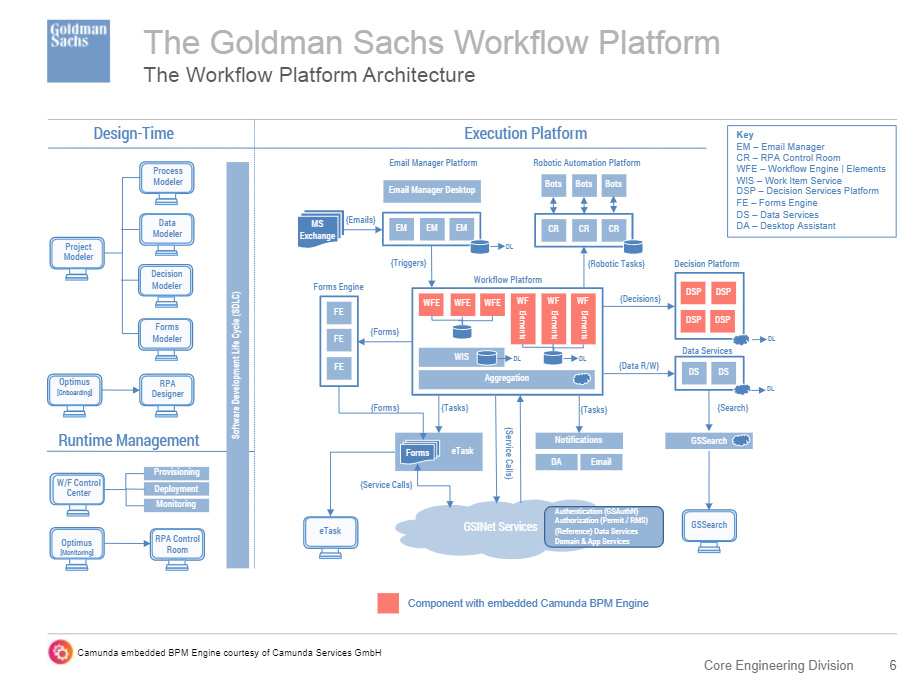
The last presentation of the day, and of CamundaCon Live 2020, was Richard Tarling, co-head of Workflow Engineering at Goldman Sachs, on the process automation platform that they built with Camunda at its core. He is focused on workflow at enterprise scale: they have 60,000 users (the entire firm) with 8,000 daily users, participating in 10M new activities and 250M decisions per day spread over 650 compute servers. This includes 3,000 process models, 1,000 decision models, 6,000 forms models and 125 RPA bot automations, all created and supported by 1,500 platform developers. Yowsa.
Their goal with creating their digital automation platform was to accelerate developers, but also support non-technical/citizen developers. This means that they embraced model-driven development by creating six key design tools:
Workflow Control Centre
Workflow Application Project Modeler
Workflow Designer, based on bpmn.io
Data Modeler
Decision Designer, based on dmn.io
Forms Designer
They built some engine extensions for their implementation, specifically around the using a stripped-down embedded BPM engine to implement decision flows with high-performance, plus the creation of an open-source jDMN execution engine.
He walked through their overall design-time and execution platform architecture, and some of the things that they did to maximize performance while maximizing (developer) usability. Decision services is a big part of their platform, and he discussed their enterprise-wide decision services execution platform. Their architecture wasn’t born in the cloud, but he feels that their use of microservices design principles means that they could move into the cloud in a straightforward manner.
They have a number of different UI personas that they’ve developed for, resulting in a “zero inbox” persona versus a “power user”. They’ve recently redesigned these UIs with a mobile-first focus. They’re also supporting citizen developers for creating their own case management applications through a combination of model-driven design and pre-built components, plus a governed software development lifecycle built on GitLab. They’ve also built their own provisioning, runtime management and monitoring tools — they even use a BPMN-based process for provisioning.
If you’re building your own large-scale digital process/decision automation platform, definitely go and watch the replay of this presentation — Tarling has been in the trenches and has a ton of great advice. Lots of great Q&A at the end, too.
@phoebe_cat
Jakob Freund came back briefly to chat with Mary Thengvall and wrap the conference: thanks for giving a shout out to this blog (and my cat, who made a brief appearance on the Slack channel). And congrats to all for a great virtual conference that was much, much more than a long series of webinars.
I mentioned on Twitter today that CamundaCon is now the gold standard for online conferences: all you other vendors who have conferences coming up, take note. I believe that the key contributers to this success are live (not pre-recorded) presentations, use of a discussion platform like Slack or Discord alongside the broadcast platform, full engagement of a large number of company participants in the discussion platform before/during/after presentations, and fast upload of the videos for on-demand watching. Keep in mind that a successful conference, whether in-person or online, allows people to have unscripted interactions: it’s not a one-way broadcast, it’s a big messy collaborative conversation.
Day 2 of CamundaCon Live kicked off with Camunda co-founder Bernd Rücker talking about microservices orchestration and integation using workflow automation. This is a common theme for him, and I’ve seen earlier versions of this presentation, but he always brings something fresh to the discussion. He discussed reactive applications that are responsive, resilient, elastic and message-driven, then covered different styles of event-driven architecture.
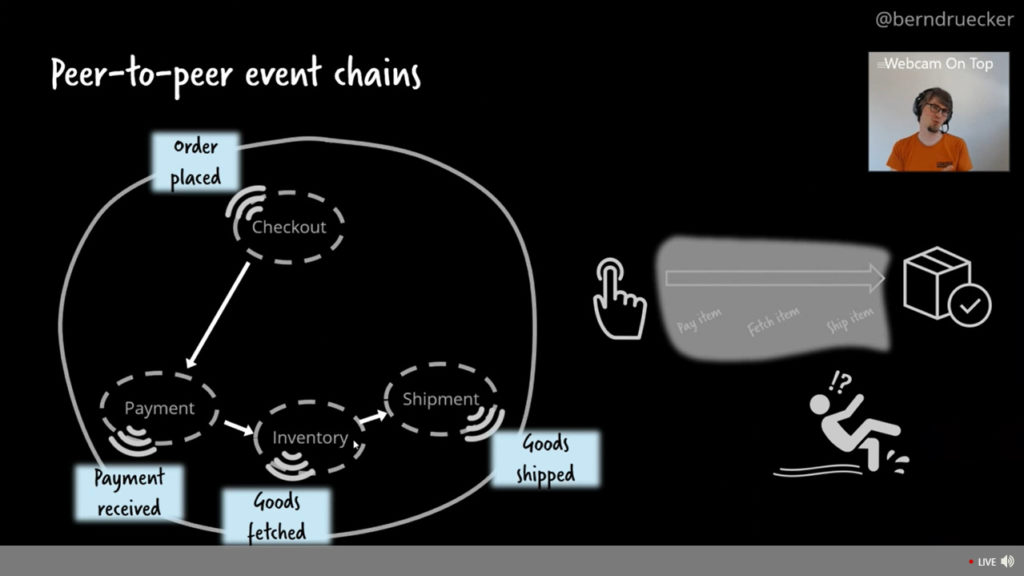
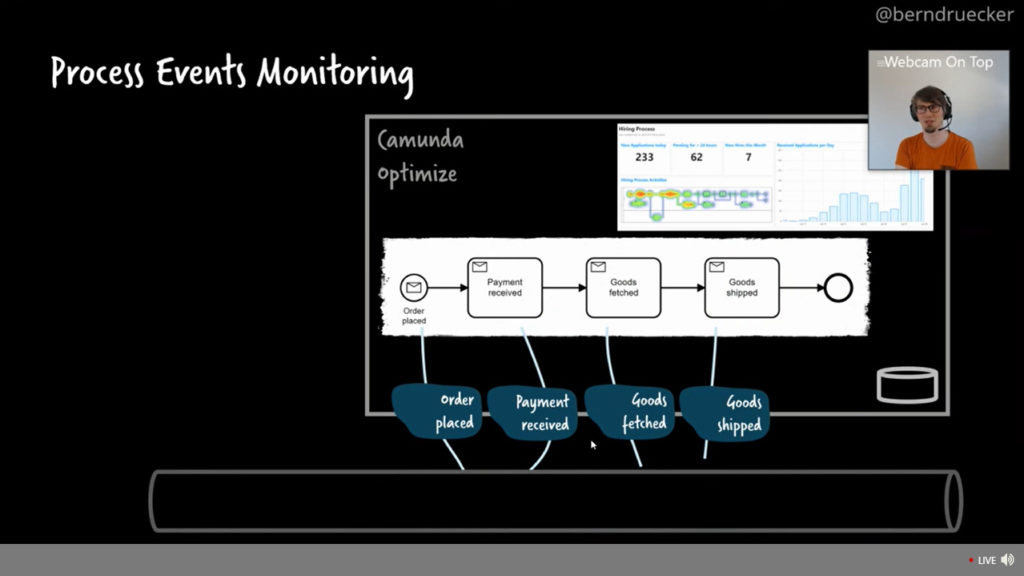
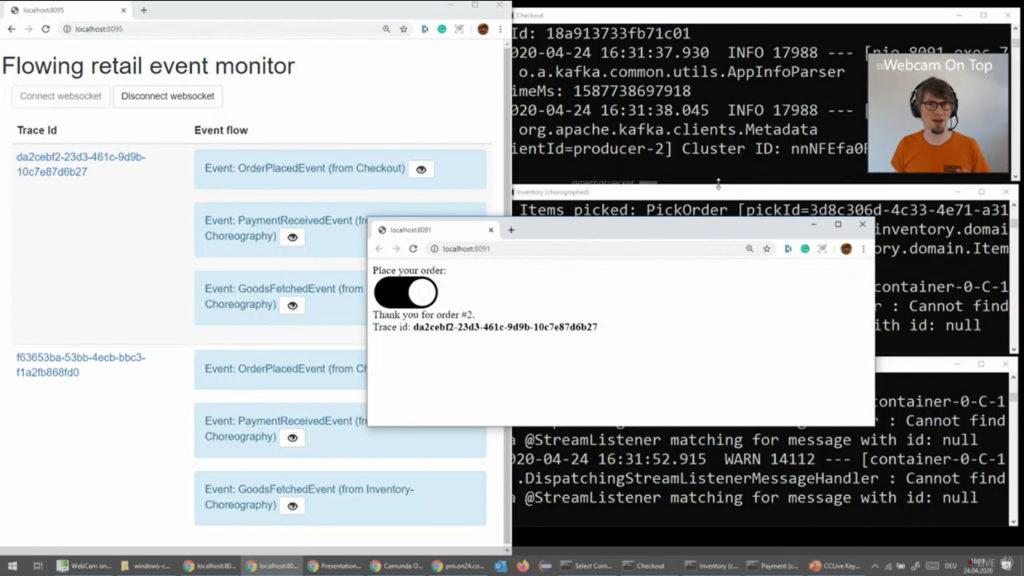
He gave a (live) demo of autonomous services communicating using Kafka, and showed the issue with peer-to-peer choreography: there is no sense of the end-to-end orchestration to ensure that all services that should have run did actually run. He created an event-based process in Camunda Optimize that modeled the expected end-to-end process, and now by connecting that to the Kafka messages, he had a visualization of the workflow that he defined that showed what happens when one service isn’t running: effectively, the virtual workflow is stuck at the previous service since it does not receive a message that the (stopped) service has picked up the messages.
One solution is to extract the end-to-end responsibility into its own service: really, this implies some level of orchestration via commands rather than purely reacting to events, even if it’s not a completely tightly-coupled workflow. If you use an engine like Camunda to do that top-level orchestration, then you can move the monitoring of the process within that engine (Cockpit rather than Optimize) although it’s likely that anyone using an event-based architecture is going to be looking at an event monitoring system like Optimize as well. You can see his slides below, and the video will be available on the CamundaCon Live hub probably by the time that I publish this post.
The morning session continued with CTO Daniel Meyer on some of the new product capabilities. Camunda’s goal has moved from just being a BPM engine for Java developers to a much broader orchestration platform that can integrate any technology stack and any endpoints.
He introduced a new distribution called Camunda Run (or Lil’ Camboot, as Niall Deehan calls it) provides a lightweight package (50MB) that includes the BPMN and DMN workflow and decision engines, Cockpit, Tasklist and the REST API. It can even be run in headless mode, which disables the web apps, if you just want the engines. It’s Open API enabled, CORS enabled, and SSL enabled out of the box. He gave a quick demo of downloading, starting and running Camunda Run: it’s pretty familiar if you’ve spent any time with Camunda, and it starts fast. From the blog post announcement, the target audience for Run is if at least one of the following is true:
You need a standalone process engine accessible via REST API
You don’t have extensive Java knowledge (or none at all) but still want to use Camunda BPM
You don’t want to configure an application server yourself
You want to configure everything in one place
You just want to Run Camunda BPM
Meyer also talked about Camunda Optimize, specifically the event-based process monitoring. We saw a bit of that yesterday in Felix Müller’s presentation, and I had a more complete view of the event-based features of Optimize a few weeks ago on the 3.0 release webinar. Basically, you add the event source to Optimize (such as Kafka), and Optimize exposes messages and allows them to be attached to the entry/exit points of elements on a BPMN diagram that represents the event-driven process. They are offering a 30-day free trial for Optimize now if you want to try it out.
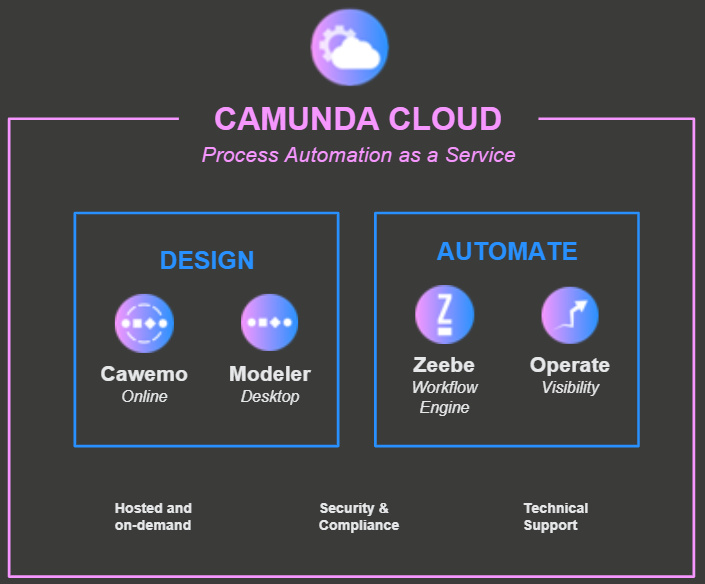
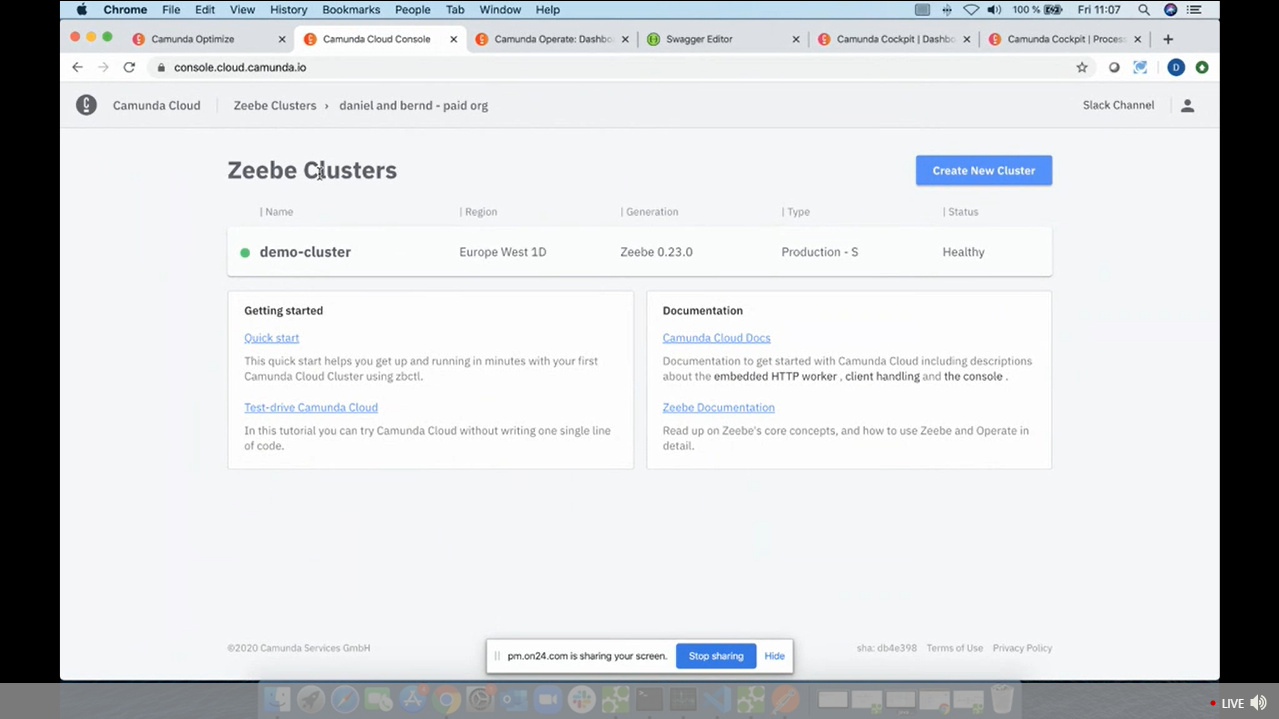
Meyer’s third topic was about process automation as a service via Camunda Cloud, which is powered by Zeebe (rather than Camunda BPM). Having cloud-native Zeebe behind the scenes means that it’s highly scalable and fault-tolerant, and uses pub-sub orchestration to let you include endpoints from anywhere. He demonstrated how to spin up a new Zeebe cluster, then deploy a BPMN model that was created in the Zeebe Modeler and start instances of the process using the zbctl command line. These instances were then visible in Camunda Operate (the Zeebe process monitoring tool), and he ran JavaScript workers and published messages to complete tasks in the process and show the instance progressing through the process model. There’s a free trial for Camunda Cloud, and an early access version for $699/month that includes access to larger clusters and technical support.
He fielded some questions that came up on the Slack workspace during his talk. Moving from an existing Camunda BPM implementation to Camunda Run is apparently as easy as just redirecting to the new application server. You can’t use Java delegates, but will have to switch those out for external tasks. There was a question about BPM versus Zeebe, which I think is a question that a lot of Camunda customers have: although most are likely familiar with the technical and functional differences, there is an open question of whether Camunda will continue to support two workflow engines in the future, and if they are going to shift focus more towards Zeebe use cases.
The morning finished by breaking out into two tracks; I stayed with the customer presentations rather than the technical breakout to hear some of the case studies. The one that I was most interested in was Fareed Saeed, head of Product and Tools for Advanced Process Solutions at Fidelity Investments, talking about migrating their monolithic legacy BPM to Camunda, in part because I did some early technical architecture consulting with them on their digital process automation platform over a year ago, although I’m not involved at this time. For those of you who know me mostly through this blog and as an independent industry analyst, you may not be aware that the other half of my business is as a consultant to large enterprises, mostly financial services and insurance, on technical architecture and strategy, or anything else to help make their process-centric implementation projects a success.
James Watson of Doculabs, who advised Fidelity on migration strategies, joined him on the discussion. Saeed talked about their current home-built workflow system, which runs thousands of different processes for most of their back office operations, and the need to move away from monolithic architecture and fragile, non-agile systems to a more flexible platform. This talk was not about the architecture or platform, but about the migration planning and execution: a key subject for any large enterprise moving off a legacy platform, but one that is often not fully considered during new digital automation platform implementation.
There are a few different strategies for migrating process-based applications, and it’s not the same story for each process. Watson shared his thoughts on this (see the slide at right), but this is my take on it:
High-volume processes, that usually represent a smaller number of process models but most of the transaction volume, are usually rewritten from scratch while incorporating some degree of re-engineering and process improvement along the way. These are the core business processes that need to be done right, and will most benefit from the more agile and scalable new platform.
Lower volume processes can be reviewed to see if they’re still required, may possible be combined into similar processes, then a straightforward “lift and shift” rewrite done to just duplicate the functionality as is. In short, these aren’t worth the time to do the re-engineering unless there are obvious wins, since the volume is relatively low. These are also candidates for low-code business-led development if that’s available on the automation platform, rather than the professional development teams required for the high-volume transactional processes.
Very low volume processes can be retired, especially if their functionality can be rolled into processes in one of the first two categories.
Although they are looking at a “factory model” for some level of automation around the migration, Saeed believes that this is an opportunity to re-engineer the processes rather than just rewriting the same (broken) process on a new platform. They want to have smaller, distributed groups for developing and delivering new applications, which means that they need to have the right governance and standards in place to support a distributed model. He sees the need for early pilots and successes to allow everyone to see how this can work, and learn how to make it successful. A strong diverse team of business leaders is also a plus, since there will be some degree of pain in the business units as the migration happens.
That’s it for the morning of Day 2, they must have read my comments yesterday and actually made sure that we finished on time so that we get our 15 minute lunch break. 🙂 I’ll be back for the afternoon to finish off CamundaCon Live 2020.