The second day of CamundaCon started with a keynote by Camunda co-founder and chief technologist Bernd Ruecker and CTO Daniel Meyer. They started with the situation that plagues many organizations: point-to-point integrations between heterogeneous legacy systems and a lot of manual work, resulting in inefficiencies and fragile system architecture. News flash: your customers don’t care about your aging IT infrastructure, they just want to be served in a way that works for them.
You can swap all of this with a “big bang” approach that changes everything at once, but that’s usually pretty painful and doesn’t work that well. Instead, they advocate starting with a gradual modernization which looks more like the following.
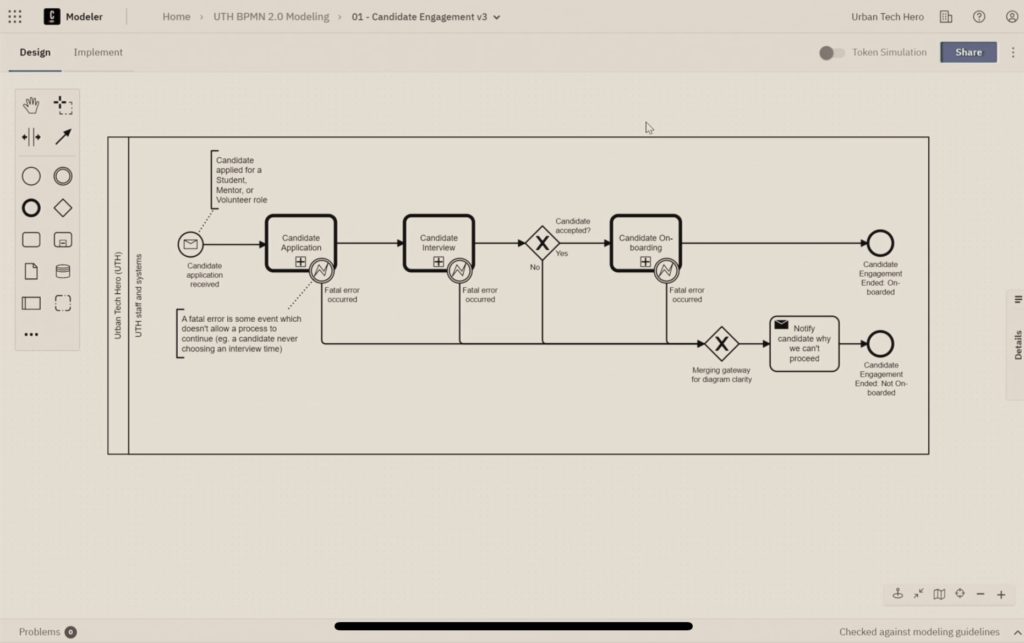
First, model your process and track the flow as it moves through different systems and steps. This allows you to understand how things work without making any changes, and identify the opportunities for change. You can actually run the modeled processes, with someone manually moving them through the steps as the work completes on other systems, and tracking the work as it passes through the model.
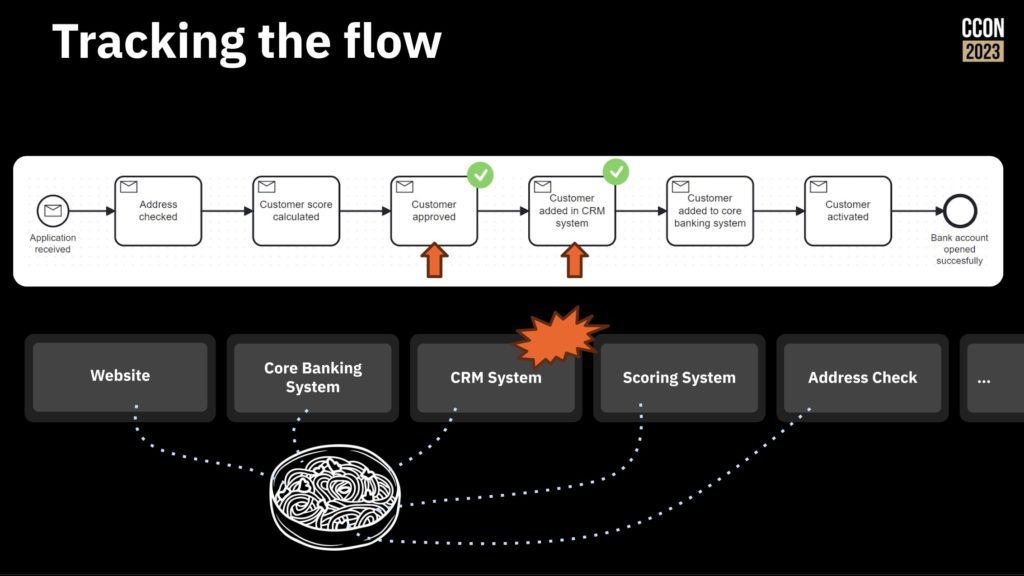
Next, start orchestrating the work by taking the flow that you have, identifying the first best point to integrate, and doing the integration to the system at that step. Once’s that’s working, continue integrating and automating until all the steps are done and the legacy systems are integrated into this simple flow.
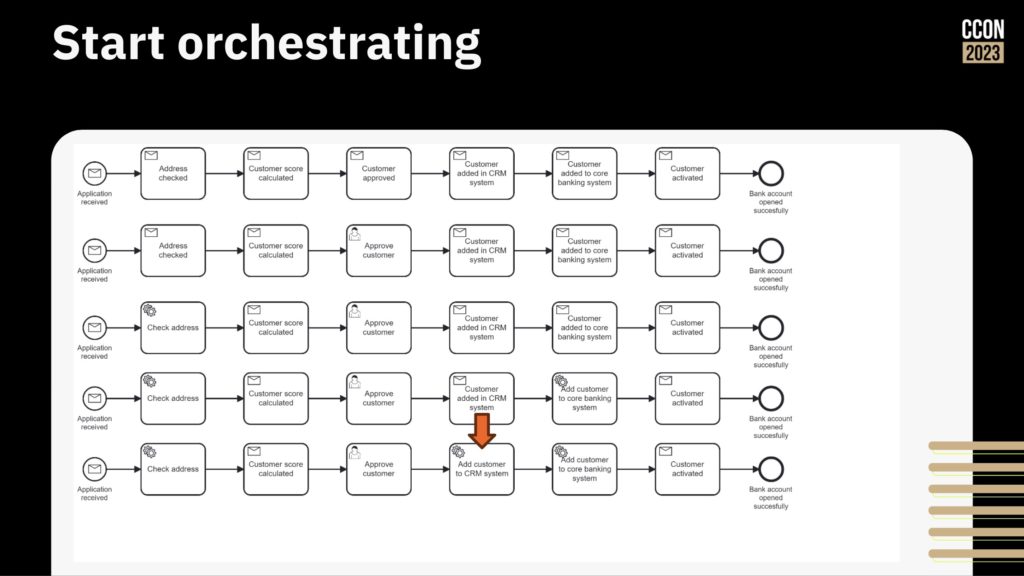
Then, start improving the process by adding more logic, rearranging the steps, and integrating/automating other systems that may be manually integrated.
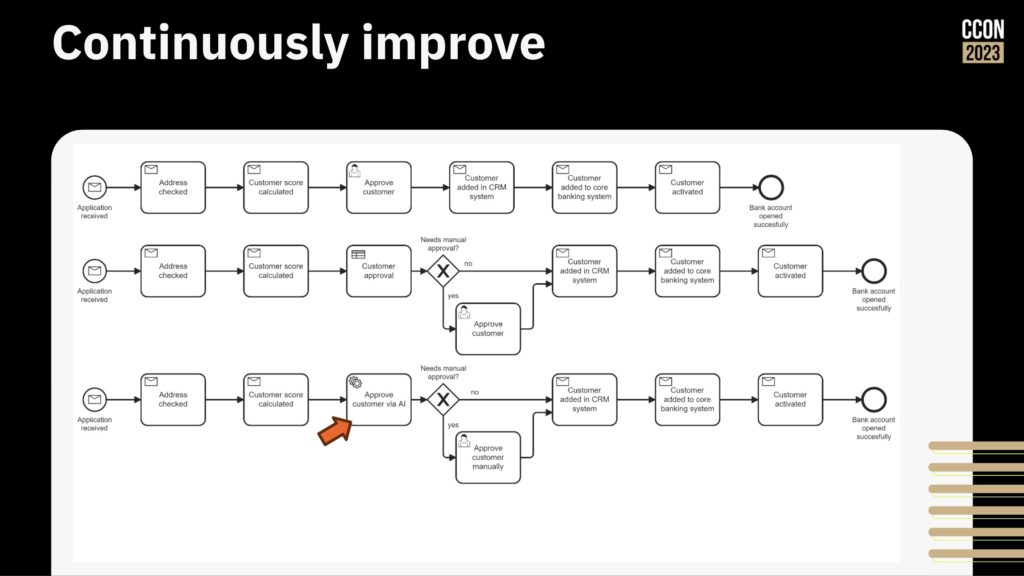
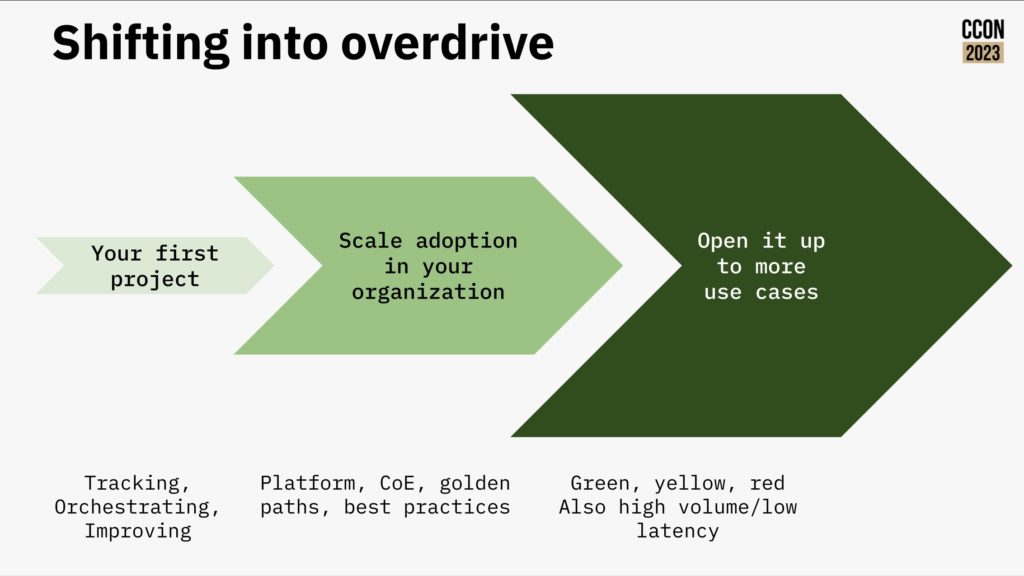
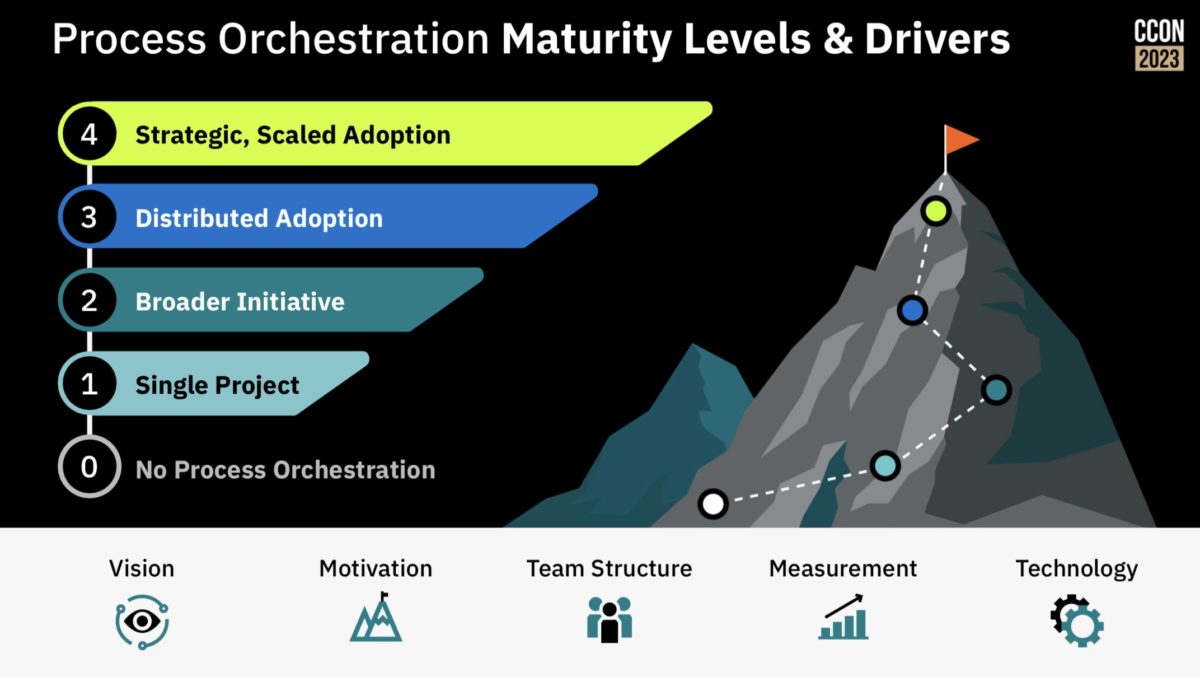
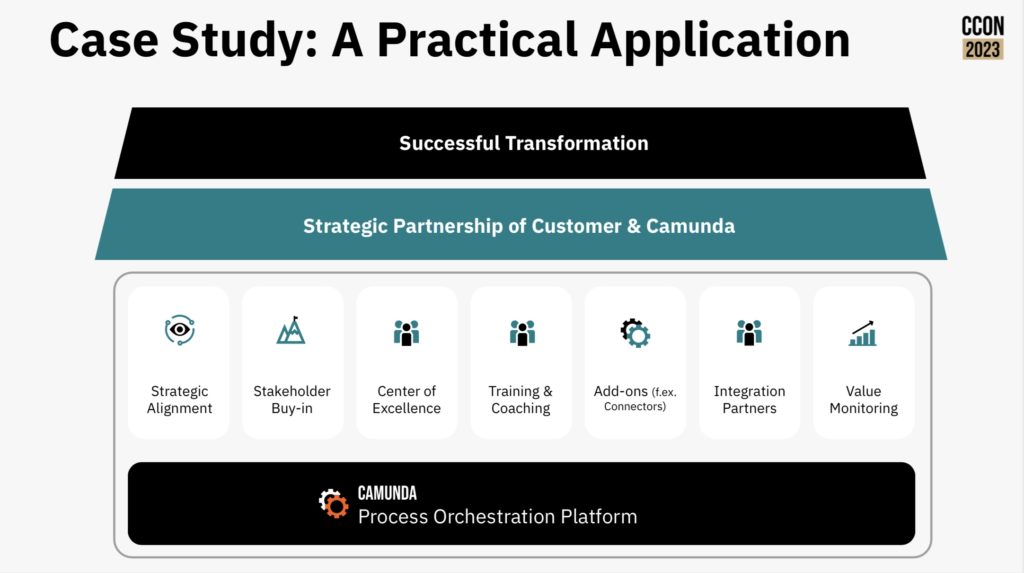
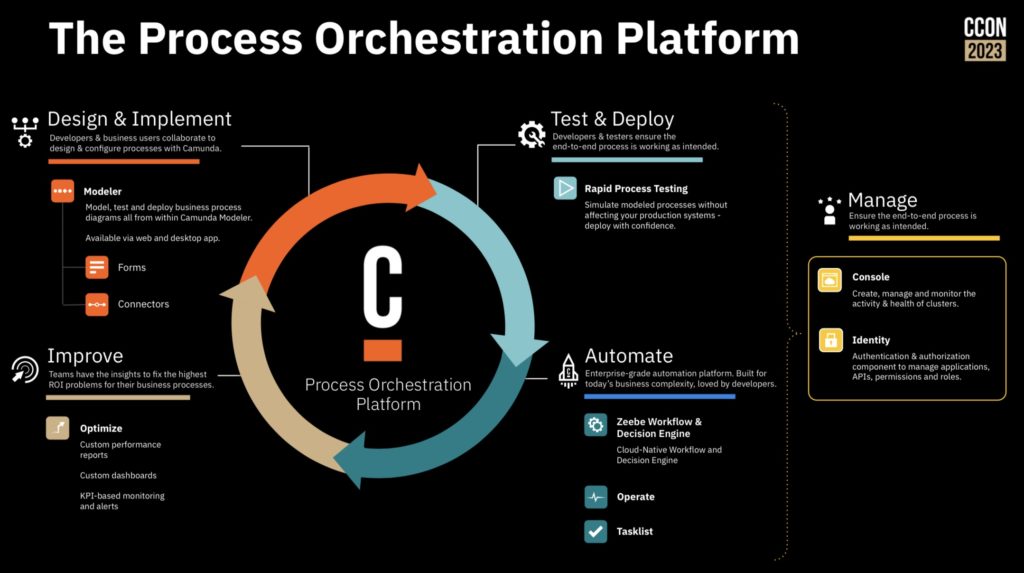
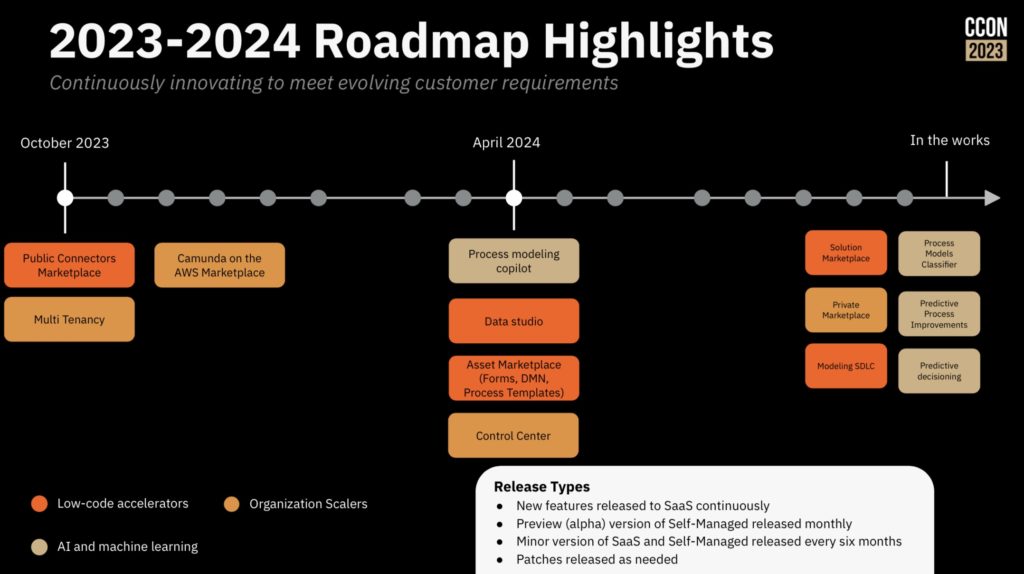
That’s a great approach for a first project, or when you’re just focused on automating a couple of processes, but you also need to consider the broader transformation goals and how to drive it across your entire organization. There are a number of different components of this: establishing a link between value chains, orchestrations and down through to business and technical capabilities; driving reuse within your organization using the newly-launched Camunda Marketplace; and providing self-service deployment of Camunda to remove any barriers to getting started.
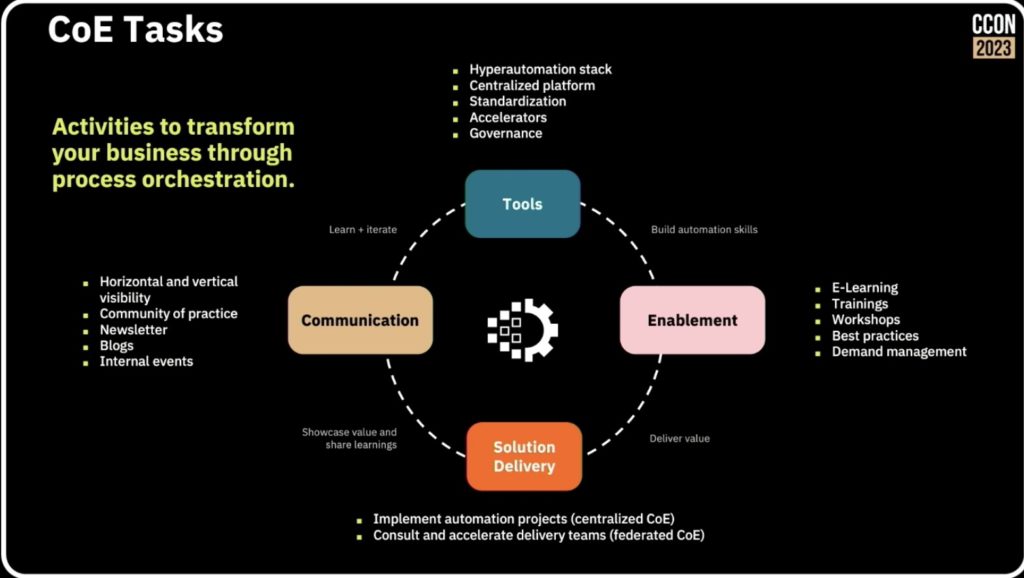
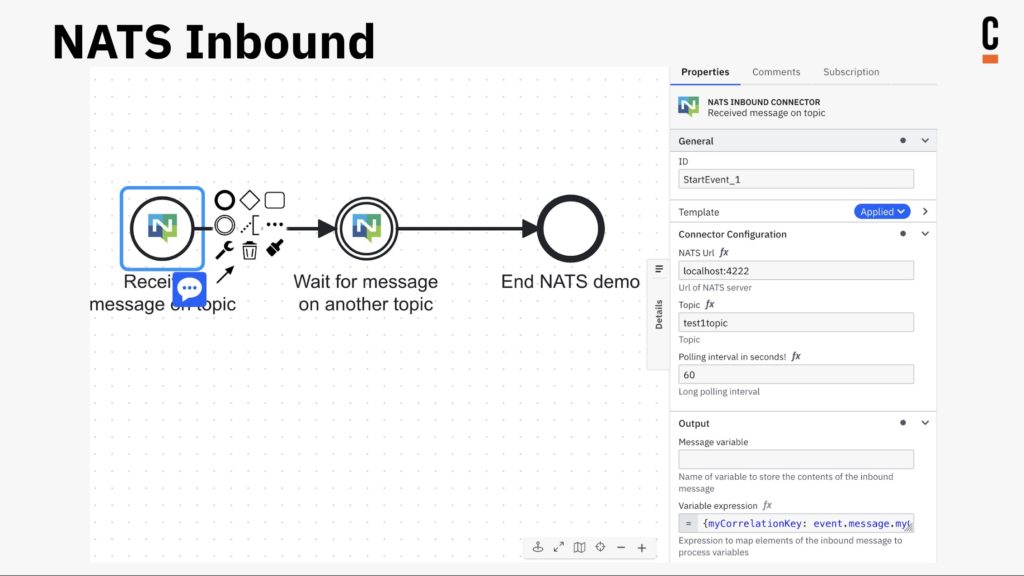
An important part of your modernization journey will be the use of connectors, while allow you to expose integrations into a wide variety of system types directly into a process model without the modeler needed to understand the technical intricacies of the system being called. This, and the use of microservices to provide additional plug-in functionality, makes it easier for developers and technical analysts to build and update process-centric applications quickly. Underpinning that is how you structure development teams within your organization (autonomy versus centralization) and support them with a CoE, smoothing the path to successful implementations.
In short, the easier you make it for teams to build new applications that fit into corporate standards and meet business goals, the less likely you are to have business teams be forced go out and try to solve the problem themselves when they really need a more technical approach, or just suffer with a manual approach. You’ll be able to categorize your use cases to understand when a business-driven low-code solution will work, and what you need the technical developers to focus on.
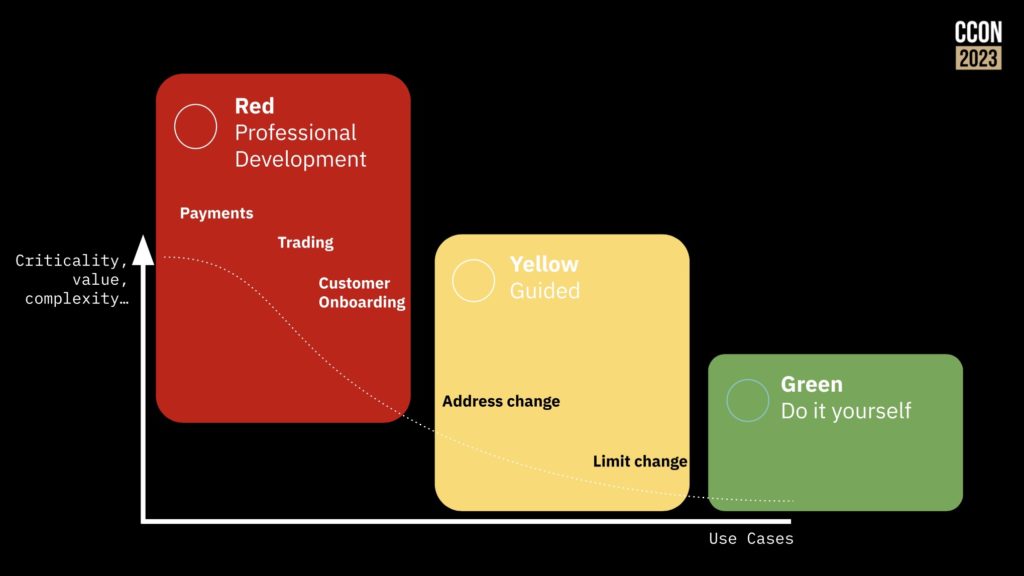
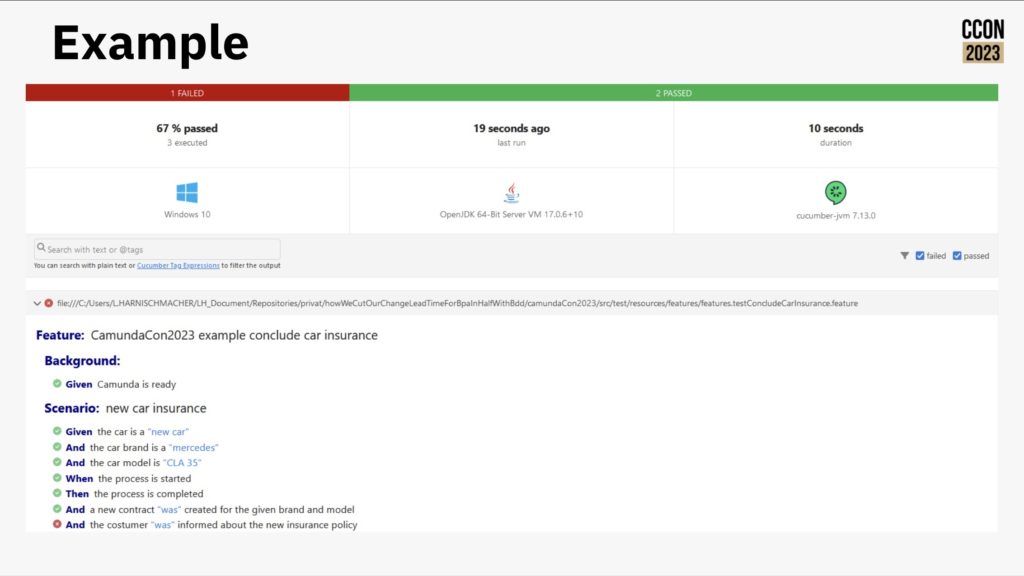
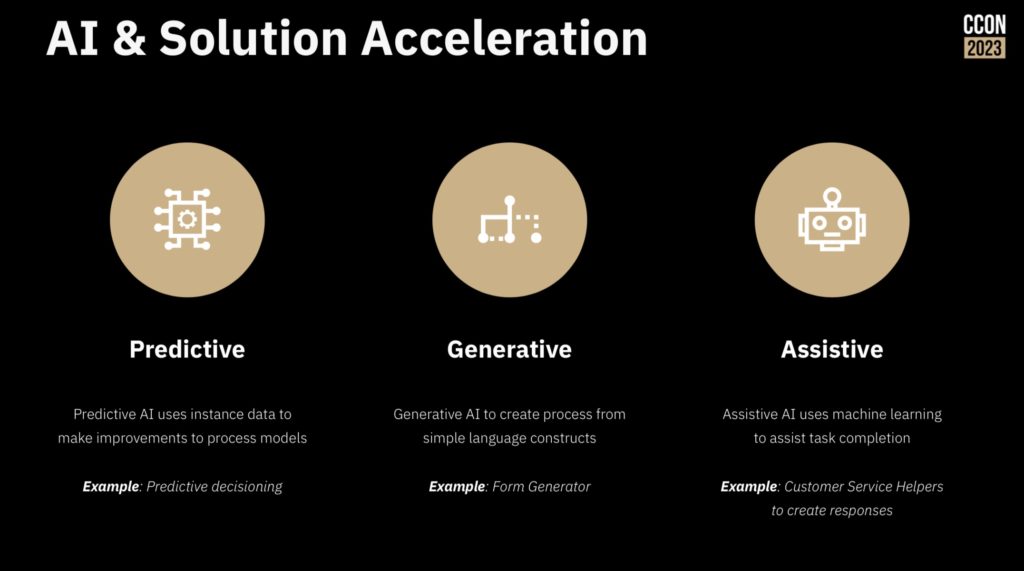
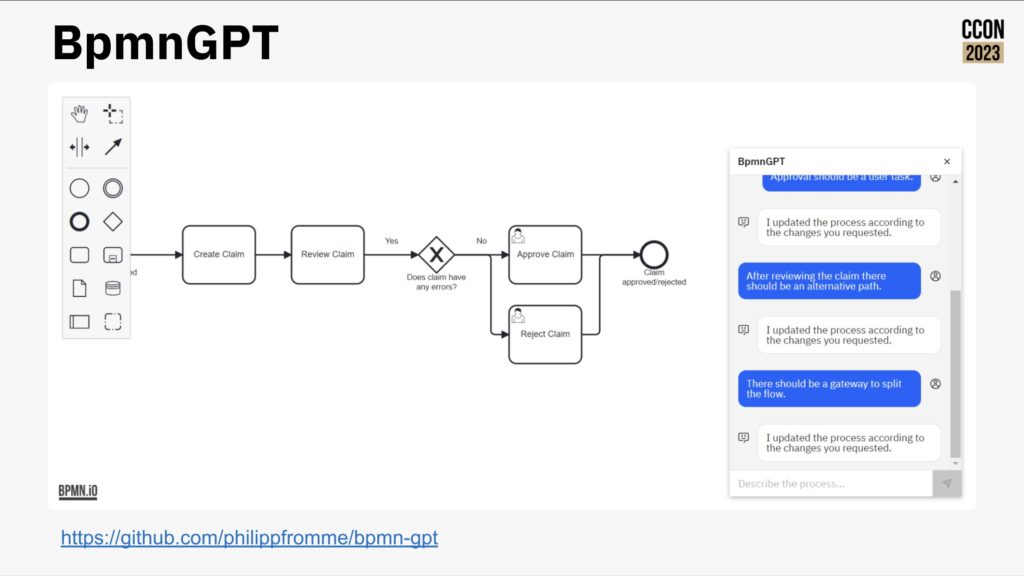
Camunda now includes a much friendlier out of the box user interface, rich(er) forms support and testing directly in the process modeler; this allows more of the “yellow” areas in the diagram above to be implemented by less-technical developers and analysts. They are also looking at how AI can be used for generating simple process models or provide help to a person who is building a model, as well as the more common use of predictive decisioning. They’ve even had a developer in the community create BpmnGPT to demonstrate how an AI helper can assist with model development.
They wrapped up with a summary of the journey from your first project to scaling adoption to a much broader transformation framework. Definitely some good goals for those on any process automation journey.