“Is there any point to which you would wish to draw my attention?” “To the curious incident of the dog in the night-time.” “The dog did nothing in the night-time.” “That was the curious incident,” remarked Sherlock Holmes.
Silver Blaze, Sir Arthur Conan Doyle
And so the fact of me (and others) not yet blogging about the IBM BPM release has itself become a point of discussion. 😉
To recount the history, I was briefed on the new IBM BPM strategy and product offerings a few weeks before the Impact conference, with a strict embargo until the first day of the conference when the announcements would be made. Then, the week before Impact, IBM updated their online product pages and the sharp-eyed Scott Francis noticed this and jumped to the obvious – and correct – conclusion: IBM was about to integrate their WebSphere BPM offerings. That prerelease of information certainly diffused the urgency about writing about the release at the moment of announcement, and gave many of us the chance to sit back and think about it a bit more. I only had a brief day and a half at Impact before making my way back east for another conference where I was giving a workshop, and here I am a week later finally finishing up my thoughts on IBM BPM.
There’s been some written about it already by others who were there: Clay Richardson and his now-infamous “fresh coat of paint” post, which I’m sure did not make him any friends in some IBM circles, Neil Ward-Dutton with his counterpoint to Clay’s opinion, some quick notes from Scott Francis in the context of his keynote blogging (which also links to the video of Phil Gilbert making the announcement), and Tony Baer as part of his post on a week of BPM announcements.
It’s important to look at how the IBM organization has realigned to allow for the new product release: Phil Gilbert, former president and CTO of Lombardi, now has overall responsibility for all of WebSphere BPM – including both the former Lombardi and WebSphere BPM products – plus ILOG rules management. Neil Ward-Dutton referred to this as the reverse takeover of IBM by Lombardi; when I had a chance for a 1:1 with Phil at Impact, I told him that we’d all bet that he would be gone from IBM after a year. He admitted that he originally thought so too, until they gave him the opportunity to do exactly what he knew needed to be done: bring together all of the IBM BPM offerings into a unified offering. This new product announcement is the beginning of that unification, but they still have a ways to go.
Let’s take a look at the product offering, then. They’ve take pretty much everything in the WebSphere BPM portfolio (Lombardi Edition, Dynamic Process Edition, Process Server, Integration Developer, Business Modeler, Business Compass, Business Fabric) and mostly rolled it into IBM BPM or replaced its functionality with something similar; there are a few exceptions, such as Business Compass, that have just disappeared. This reduces the entire IBM BPM portfolio to the following:
- IBM Business Process Manager (which I’m covering here)
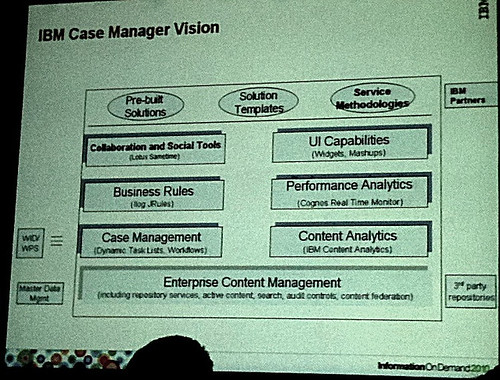
- IBM Case Manager (the rebranding of some specialized functionality built on the IBM FileNet BPM platform, which is separate from the above IBM BPM offering)
- IBM Blueworks Live
- IBM Business Monitor
- IBM BPM Industry Packs
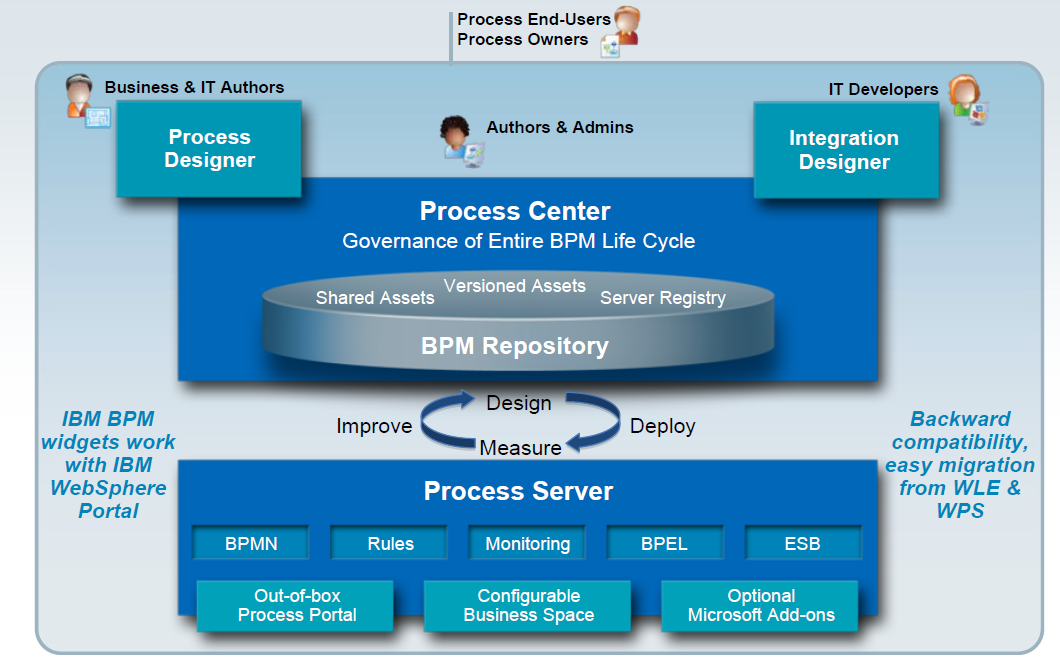
Combining most of the WebSphere BPM components into IBM BPM V7.5, the new product offering has both a BPMN Process Designer and a BPEL Integration Designer, a common repository, and a process server that includes both the BPMN and BPEL engines. Now you can see where Clay Richardson is coming from with the “new coat of paint” characterization: the issue of one versus two process “servers” seemed to occupy an inordinate amount of time in discussions with IBM representatives, who stoically recited the party line that it’s one server. For those of us who actually used to write code like this for a living, it’s clear that it’s two engines: one BPMN and one BPEL. However, from the customer/user standpoint, it’s wrapped into a single Process Server, so if IBM ever gets around to refactoring into a single engine, that could be made fairly transparent to their customers, but would likely have the benefit of reducing IBM’s internal engineering costs around maintaining one versus two engines. Personally, I believe that there is enough commonality between process design and service orchestration that both the designers and the engines could be combined into something that offers the full spectrum of functionality while reducing the underlying product complexity.
In addition to the core process functionality, the ILOG rules engine is also present, plus monitoring tools and user interface options with both the process portal and the Business Space composite application environment.
I don’t want to understate their achievements in this product offering: the (Lombardi-flavored) Process Center with its shared repository and process governance is significant, allowing users to reuse artifacts from the two different sides of the BPM house: you can add a BPEL process orchestration created in Integration Designer to your BPMN process created in Process Designer, or you can include a business object created in Process Designer as a data definition in your BPEL service orchestration in Integration Designer, or call a BPMN process for human task handling. The fact remains, however, that this is still a slightly uneasy combination of the two major BPM platforms, and it will likely take another version or two to work out the bumps.
Since this is IBM, they can’t just have one product configuration, but offer three:
- The Express edition, offered at a price point that is probably less than your last car, is for starter BPM projects: full functionality of the Process Designer to build and run BPMN processes, but only one server with no clustering, so unlikely to be used for any mission-critical applications. If you’re just getting started and are doing human-centric BPM, then this is for you.
- The Standard edition, which is pretty much the same human BPM and lightweight integration functionality as the former Lombardi Edition BPMS. Existing Lombardi Edition customers will be able to upgrade to this version seamlessly.
- The Advanced edition, which adds the Integration Designer and its ability to create a SOA layer of BPEL service/process orchestrations that can then be called from the BPMN processes or run independently.
In the product architecture diagram above, the Advanced edition is the whole thing, whereas the Standard and Express editions are missing the Integration Designer; to complicate that further, current WebSphere Process Server/Integration Designer customers will be transitioned to the Advanced edition but with the Process Designer disabled, a fourth shadow configuration that will not be available for new customers but is offered only as an upgrade. Both engines are still there in all editions, but it appears that without both designers, you can’t actually design anything that will run in one of the engines. For current customers, IBM has published information on migrating your existing configuration to the new BPM; there is a license migration path for all customers who currently have BPM products, but for some coming from the traditional WebSphere products, the actual migration of their applications may be a bit rocky.
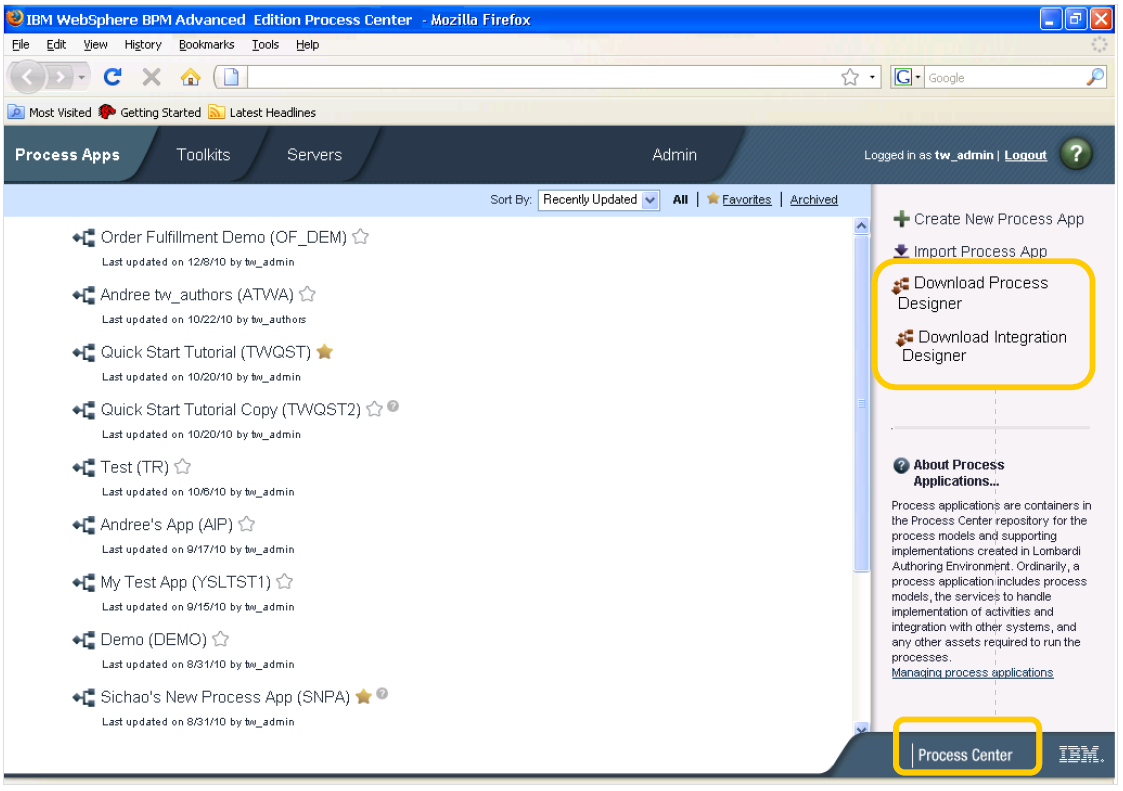 The web-based Process Center is used for managing, deploying and interacting with processes of both types, although the Process Designer and Integration Designer are still applications that must be downloaded and installed locally. Within the Process Designer, there’s the familiar Lombardi “iTunes-style” view of the assets and dependencies. It’s important to point out that the Toolkits are assets that could have originated in either the Process Designer or the Integration Designer; in other words, they could be human workflows running on the BPMN engine or service orchestrations running on the BPEL engine, and can just be dragged and dropped onto BPMN processes as activities. The development environment includes versioning, shared concurrent editing to view what assets that other developers are editing that might impact your project, playback of previous process versions, and all versions of processes viewable for deployment in Process Center. The Process Center view is identical from either design tool, providing an initial common view between these two environments. Linking these two environments through sharing of assets in the Process Center also eases deployment: everything that a process application depends upon, regardless of its origin, can be deployed as a single package.
The web-based Process Center is used for managing, deploying and interacting with processes of both types, although the Process Designer and Integration Designer are still applications that must be downloaded and installed locally. Within the Process Designer, there’s the familiar Lombardi “iTunes-style” view of the assets and dependencies. It’s important to point out that the Toolkits are assets that could have originated in either the Process Designer or the Integration Designer; in other words, they could be human workflows running on the BPMN engine or service orchestrations running on the BPEL engine, and can just be dragged and dropped onto BPMN processes as activities. The development environment includes versioning, shared concurrent editing to view what assets that other developers are editing that might impact your project, playback of previous process versions, and all versions of processes viewable for deployment in Process Center. The Process Center view is identical from either design tool, providing an initial common view between these two environments. Linking these two environments through sharing of assets in the Process Center also eases deployment: everything that a process application depends upon, regardless of its origin, can be deployed as a single package.
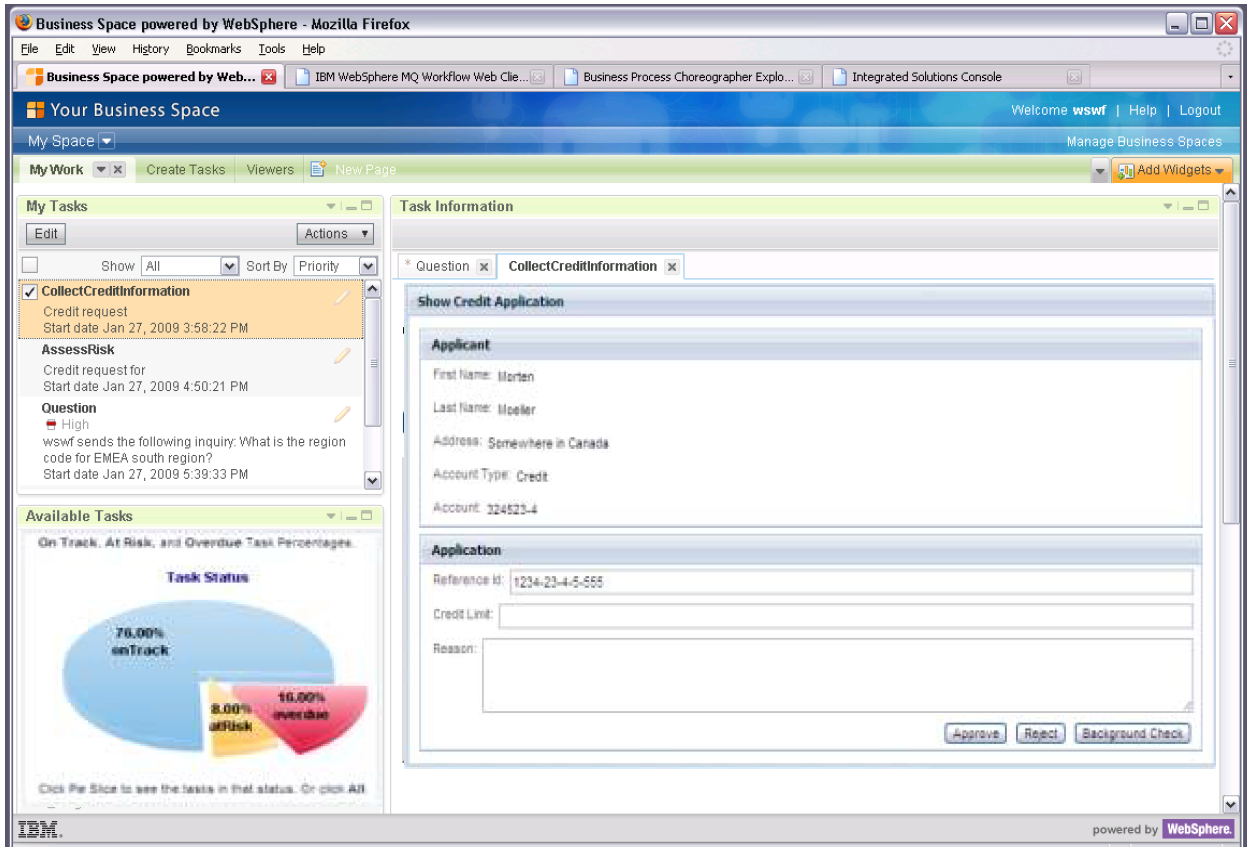
 Not everything comes from the former Lombardi Edition, however: the user interface builder in BPM BPM is based on Business Space, IBM’s composite application development tool, instead of the old Lombardi forms and UI technology; this allows for easy reuse of widgets in portals, and there’s also a REST interface to roll your own UI. Also, the proprietary rules engine in Lombardi is being replaced with ILOG, with the rules editor built right in to the design environments; the ILOG engine is included in the Process Server, but can only be called from processes, not by external applications, so as to not cannibalize the standalone ILOG BRMS business. I’m sure that they will be supporting the old UI and rules for a while, but if you’re using those, you’re going to be encouraged to start migrating at some point.
Not everything comes from the former Lombardi Edition, however: the user interface builder in BPM BPM is based on Business Space, IBM’s composite application development tool, instead of the old Lombardi forms and UI technology; this allows for easy reuse of widgets in portals, and there’s also a REST interface to roll your own UI. Also, the proprietary rules engine in Lombardi is being replaced with ILOG, with the rules editor built right in to the design environments; the ILOG engine is included in the Process Server, but can only be called from processes, not by external applications, so as to not cannibalize the standalone ILOG BRMS business. I’m sure that they will be supporting the old UI and rules for a while, but if you’re using those, you’re going to be encouraged to start migrating at some point.
 There is currently no (announced) plan for IBM BPM process execution in the cloud (except for the simple user-created workflows in Blueworks Live), which I think will impact IBM BPM at some point: I understand that many of the large IBM customers are unlikely to go off premise for a production system, but more and more organizations that I work with are considering cloud-based solutions that they can provision and decommission near-instantaneously as a platform for development and testing, at the very least. They need to rethink their strategy on this, and stop offering expensive custom hosted or private “cloud” platforms as their only cloud alternatives.
There is currently no (announced) plan for IBM BPM process execution in the cloud (except for the simple user-created workflows in Blueworks Live), which I think will impact IBM BPM at some point: I understand that many of the large IBM customers are unlikely to go off premise for a production system, but more and more organizations that I work with are considering cloud-based solutions that they can provision and decommission near-instantaneously as a platform for development and testing, at the very least. They need to rethink their strategy on this, and stop offering expensive custom hosted or private “cloud” platforms as their only cloud alternatives.
Finally, there is the red-headed stepchild in the IBM BPM portfolio: IBM FileNet BPM, which has mostly been made over as the IBM Case Manager product. Interestingly, some of the people from the FileNet product side were present at Impact (usually they would only attend the IOD conference, which covers the Information Management software portfolio in which FileNet BPM is entombed), and there was talk about how Case Manager and the rest of the BPM suite could work together. In my opinion, bringing FileNet BPM into the overall IBM BPM fold makes a lot of sense; as I blogged back in 2006 at the time of the acquisition, and in 2008 when comparing it to the Oracle acquisition, they should have done that from the start, but there seemed (at the time) to be some fundamental misunderstandings about the product capabilities, and they chose to refocus it on content-centric BPM rather than combining it with WebSphere Process Server. Of course, if they had done the latter, we likely would be seeing a very different IBM BPM product mix today.