The day before the official announcement of IBM’s Case Manager product, Jake Levirne, Senior Product Manager, walked us through the capabilities. He started by defining case management, and discussing how it is about providing context to enable better outcomes rather than prescribing the exact method for achieving that outcome. For those of you who have been following ACM for a while, this wasn’t anything new, although I’m imagining that it is for some of the audience here at IOD.
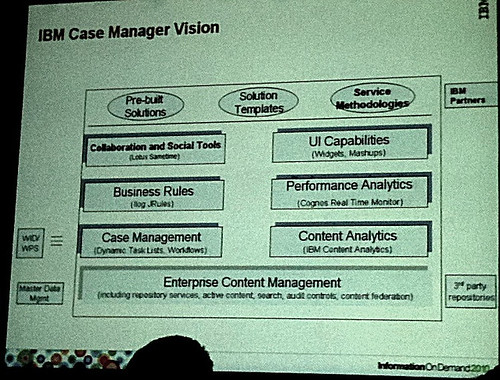
Case Manager is an extension of the core (FileNet) ECM product through the integration of functionality from several other software products across multiple IBM software groups, specifically analytics, rules and collaboration. There is a new design tool targeted at business analysts, and a user interface environment that is the next generation of the old ECM widgets. There’s a new case object model in the repository, allowing the case construct to exist purely in the content repository, and be managed using the full range of content management capabilities including records management. Case tasks can be triggered by a number of different event types: user actions, new content, or updates to the case metadata. By having tasks as objects within the case, each task can then correspond to a structured subprocess in FileNet BPM, or just be part of a checklist of actions to be completed by the case worker (further discussion left it unclear whether even the simple checklist tasks were implemented as a single-step BPM workflow). A task can also call a WebSphere Process Server task; in fact, from what I recall of how the Content Manager objects work, you can call pretty much anything if you want to write a Java wrapper around it, or possibly this is done by triggering a BPM process that in turn calls a web service. The case context – a collection of all related metadata, tasks, content, comments, participants and other information associated with the case – is available to any case worker, giving them a complete view of the history and the current state of the case. Some collaboration features are built in to the runtime, including presence and synchronous chat, as well as simple asynchronous commenting; these collaborations are captured as part of the case context.
As you would expect, cases are dynamic and allow case workers to add new tasks for the case at any time. Business rules, although they may not even be visible to the end user, can be defined during design time in order to set properties and trigger events in the case. Rules can be changed at runtime, although we didn’t see an example of how that would be done or why it might be necessary.
There are two perspectives in the Case Manager Builder design environment: a simplified view for the business analysts to define the high level view of the case, and a more detailed view for the technologists to build in more complex integrations and complex decision logic. This environment allows for either start-from-scratch or template-based case solution definitions, and is targeted at the business analyst with a wizard-based interface. Creating a case solution includes defining the following from the business analyst’s view:
- case properties (metadata)
- roles that will work on this case, which will be bound to users at runtime
- case types that can exist within the same case solution
- document types that can be included in the case or may even trigger the case
- case data and search views
- which case views that each role will see
- default folders to be included in the case
- tasks that can be added to this case, each of which is a process (even if only a one-step process), and any triggering events for the tasks
- the process behind each of the tasks, which is a simple step editor directly in Case Builder; a system lane in this editor can represent the calling of a web service or a WPS process
All of these can be defined on an ad hoc basis, or stubbed out initially using a wizard interface that walks the business analyst through and prompts for which of these things needs to be included in the case solution. Comments can be added on the objects during design time, such as tasks, allowing for collaboration between designers.
As was made clear in an audience question, the design that a business analyst is doing will actually create object classes in both Content Manager and BPM; this is not a requirements definition that then needs to be coded by a developer. From that standpoint, you’ll need to be sure that you don’t let them do this in your production environment since you may want to have someone ensure that the object definitions aren’t going to cause performance problems (that seemed screamingly obvious to me, but maybe wasn’t to the person asking the question).
From what Levirne said, it sounds as if the simple step editor view of the task process can then be opened in the BPM Process Designer by someone more technical to add other information, implying that every task does have a BPM process behind it. It’s not clear if this is an import/export to Process Designer, or just two perspectives on the same model, or if a task always generates a BPM process or if it can exist without one, e.g., as a simple checklist item. There were a lot of questions during the session and he didn’t have time to take them all, but I’m hoping for a more in-depth demo/briefing in the weeks to come.
Case analytics, including both dashboards (Cognos BAM) and reports (Excel and Cognos BI reports) based on case metadata, and more complex analytics based on the actual content (Content Analytics), are provided to allow you to review operational performance and determine root causes of inefficiencies. From a licensing standpoint, you would need a Cognos BI license to use that for reporting, and a limited-license Content Analytics version is included out of the box that can only be used for analyzing cases, not all your content. He didn’t cover much about the analytics in this session, it was primarily focused on the design time and runtime of the case management itself.
The end-user experience for Case Manager is in the IBM Mashup Center, a mashup/widget environment that allows the inclusion of both IBM’s widgets and any other that support the iWidget standard and expose their properties via REST APIs. IBM has had the FileNet ECM widgets available for a while to provide some standard ECM and BPM capabilities; the new version provides much more functionality to include more of the case context including metadata and tasks. A standard case widget provides access to the summary, documents, activities and history views of the case, and can link to a case data widget, a document viewer widget for any given document related to the case, and e-forms for creating more complex user interfaces for presenting and entering data as part of the case.
Someone I know who has worked with FileNet for years commented that Case Manager looks a lot like the integrated demos that they’ve been building for a couple of years now; although there’s some new functionality here and the whole thing is presented as a neat package, it’s likely that you could have done most of this on your own already if you were proficient with FileNet ECM and some of the other products involved.
We also heard from Brian Benoit of Pyramid Solutions, a long-time FileNet partner who has been an early adopter of Case Manager and responsible for building some of the early templates that will be available when the product is released. He demonstrated a financial account management template, including account opening, account maintenance, financial transaction requests and correspondence handling. In spite of IBM’s claim that there is no migration path from Business Process Framework (BPF), there is a very BPF-like nature to this application; clearly, the case management experience that they gained from BPF usage has shaped the creation of Case Manager, or possibly Pyramid was so familiar with BPF that they built something similar to what they knew already. Benoit said that the same functionality could be built out of the box with Case Manager, but that what they have provided is an accelerator for this sort of application.
Levirne assured me that everything in his presentation could be published immediately, although I’ve had analyst briefings on Case Manager that are under embargo until the official announcement tomorrow so I’ll give any of the missing details then.