I haven’t been to the AIIM conference since the early to mid 90s; I stopped when I started to focus more on process than content (and it was very content-centric then), then stayed away when the conference was sold off, then started looking at it again when it reinvented itself a few years ago. These days, you can’t talk about content without process, so there’s a lot of content-oriented process here as well as AI, governance and a lot of other related topics.
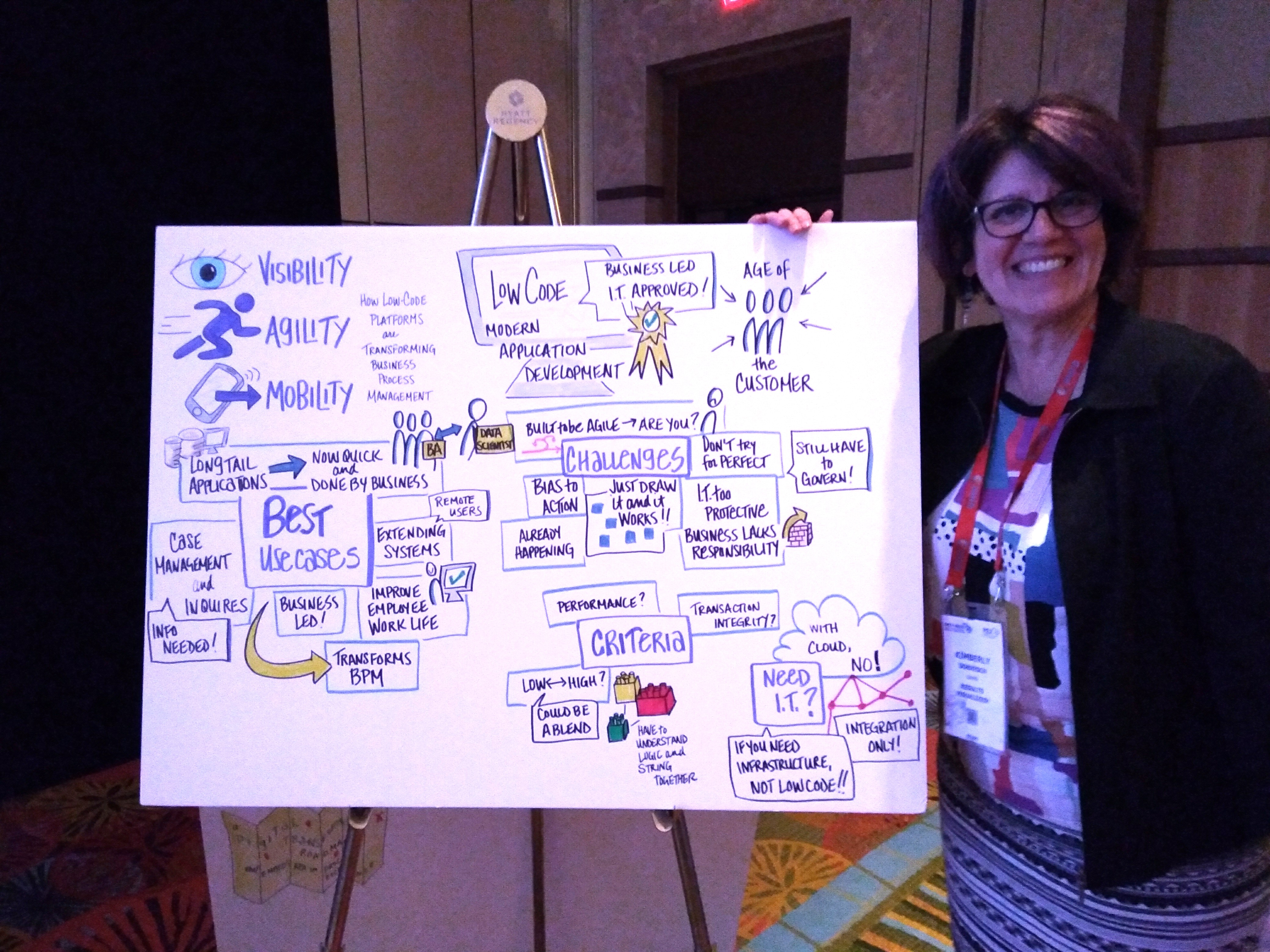
I arrived yesterday just in time for a couple of late-afternoon sessions: one presentation on digital workplaces by Stephen Ludlow of OpenText that hit a number of topics that I’ve been working on with clients lately, then a roundtable on AI and content hosted by Carl Hillier of ABBYY. This morning, I attended the keynote where John Mancini discussed digital transformation and a report released today by AIIM. He put a lot of emphasis on AI and machine learning technologies; specifically, how they can help us to change our business models and accelerate transformation.
 We’re in a different business and technology environment these days, and a recent survey by AIIM shows that a lot of people think that their business is being (or about to be) disrupted, and digital transformation is and important part of dealing with that. However, very few of them are more than a bit of the way towards their 2020 goals for transformation. In other words, people get that this is important, but just aren’t able to change as fast as is required. Mancini attributed this in part to the escalating complexity and chaos that we see in information management, where — like Alice — we are running hard just to stay in place. Given the increasing transparency of organizations’ operations, either voluntarily or through online customer opinions, staying in the same place isn’t good enough. One contributor to this is the number of content management systems that the average organization has (hint: it’s more than one) plus all of the other places where data and content reside, forcing workers to have to scramble around looking for information. Most companies don’t want to have a single monolithic source of content, but do want a federated way to find things when they need it: in part, this fits in with the relabelling of enterprise content management (ECM) as “Content Services” (Gartner’s term) or “Intelligent Information Managment” (AIIM’s term), although I feel that’s a bit of unnecessary hand-waving that just distracts from the real issues of how companies deal with their content.
We’re in a different business and technology environment these days, and a recent survey by AIIM shows that a lot of people think that their business is being (or about to be) disrupted, and digital transformation is and important part of dealing with that. However, very few of them are more than a bit of the way towards their 2020 goals for transformation. In other words, people get that this is important, but just aren’t able to change as fast as is required. Mancini attributed this in part to the escalating complexity and chaos that we see in information management, where — like Alice — we are running hard just to stay in place. Given the increasing transparency of organizations’ operations, either voluntarily or through online customer opinions, staying in the same place isn’t good enough. One contributor to this is the number of content management systems that the average organization has (hint: it’s more than one) plus all of the other places where data and content reside, forcing workers to have to scramble around looking for information. Most companies don’t want to have a single monolithic source of content, but do want a federated way to find things when they need it: in part, this fits in with the relabelling of enterprise content management (ECM) as “Content Services” (Gartner’s term) or “Intelligent Information Managment” (AIIM’s term), although I feel that’s a bit of unnecessary hand-waving that just distracts from the real issues of how companies deal with their content.
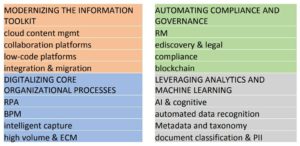 He went through some other key findings from their report on what technologies that companies are looking at, and what priority that they’re giving them; looks like it’s worth a read. He wrapped up with a few of his own opinions, including the challenge that we need to consider content AND data, not content OR data: the distinction between structure and unstructured information is breaking down, in part because of the nature of natively-digital content and in part because of AI technologies that quickly turn what we think of as content into data.
He went through some other key findings from their report on what technologies that companies are looking at, and what priority that they’re giving them; looks like it’s worth a read. He wrapped up with a few of his own opinions, including the challenge that we need to consider content AND data, not content OR data: the distinction between structure and unstructured information is breaking down, in part because of the nature of natively-digital content and in part because of AI technologies that quickly turn what we think of as content into data.
There’s a full slate of sessions today, stay tuned.

 The
The  A little over a year ago, I wrote a paper on intelligent capture for digital transformation, sponsored by ABBYY, and
A little over a year ago, I wrote a paper on intelligent capture for digital transformation, sponsored by ABBYY, and