I’ve written another post for the Trisotech blog on end-to-end processes, and how Conway’s Law can prevent good horizontal integration across your organization’s processes. Conway’s Law is an adage that states that organizations design systems that mirror their own communication structure: basically, if your interdepartmental communications is not that great, the underlying systems are unlikely to do a good job of it either.
I go into some detail of the problems that occur when an organization is functionality siloed with poor communication between areas, and how you can start to find your way out of it.
You can find all of the posts that I’m creating for them here.
I really enjoyed my first trip to DecisionCAMP earlier this year, and not just because it was in beautiful Bolzano. In 2020, it will be Oslo, Norway in late June – just after the summer solstice, which is a great time to visit a northern country where the sun (almost) never sets at that time of year.
I’ll be writing a few guest posts over on the Trisotech blog, starting with this one on goal alignment through the hierarchy of your orgnization to make sure that you’re not only doing the right thing, but doing the thing right. As I mention over there, I have this conversation with almost every enterprise client that I talk to, and thought it would be good to put down some thoughts around a goal alignment structure like this:
This is (techinically) sponsored content, although I don’t discuss Trisotech products at all, so I’m not reprinting it here but encourage you to head over there and give it a read.
I thought that I was done with my CamundaCon coverage, but noticed that Jakob Freund is blogging more details about what he covered in his keynote. I spent most of his keynote behind the curtain waiting for my turn to speak, but was able to see it again when they posted the video of his presentation.
He’s doing a five-part series on the themes that he covered, based in part on their experiences with their clients over the past years, with the first two available here:
Part 1: Intro to the four key elements of becoming a digital enterprise
Part 2: The first key element, customer-focused innovation
If he keeps to his posting schedule, the next one should be up tomorrow.
On November 12, I’ll be expanding on some of those themes in a webinar sponsored by Camunda:
Why a monolithic architecture, whether a legacy application or an all-in-one business automation platform, lacks the agility and scalability required for businesses to survive and thrive
How a best-of-breed business automation platform can be assembled from a set of components in a microservices architecture
How to migrate from your legacy systems to a best-of-breed business automation platform
In particular, the new bit on migrating legacy systems is drawn from my best practices developed over years of consulting as a systems architect/designer.
You can sign up for the webinar here; if you can’t make it on that date, sign up anyway and you’ll get a link to the recording.
It seems like just yesterday that we were in beautiful Bolzano, but I’ve been back at my desk for more than a month and still wading through some of the news stories from when I was away.
He also covers some of the particularly interesting topics in more detail, including the need for DMN 2.0, the user-friendliness of FEEL and several real-world use cases.
I also had a note from Dario Campagna regarding the post that I wrote about his presentation; I’ve updated it to reflect that the work that he presented is part of the COMPOSELECTOR project, to which ESTECO is a contributor. My apologies for the omission of the overarching project in the original version of the post, although I was live-blogging so some detail is always missed.
I’m back in my office after the European tour — three weeks, four countries and three conferences — and will be presenting on a webinar this Thursday hosted by Alfresco. I’ll be having a conversation with Dave Giordano, founder and insurance practice lead at Technology Services Group, on how to make insurance claims work better for insurance companies and their customers.
Our expected topics of conversation include:
How claims have become a competitive differentiator in insurance
Challenges in claims processing
Streamlining the ingestion and recognition of digital media and other content
Customer use cases for improving efficiency and automation
You can sign up for the webinar here. As always, if you have any particular questions or comments that you want to send to me ahead of time, just comment on this post or send me a tweet.
Modeling Decisions With Embedded Testing. Daniel Schmitz-Hübsch and Ulrich Striffler, Materna
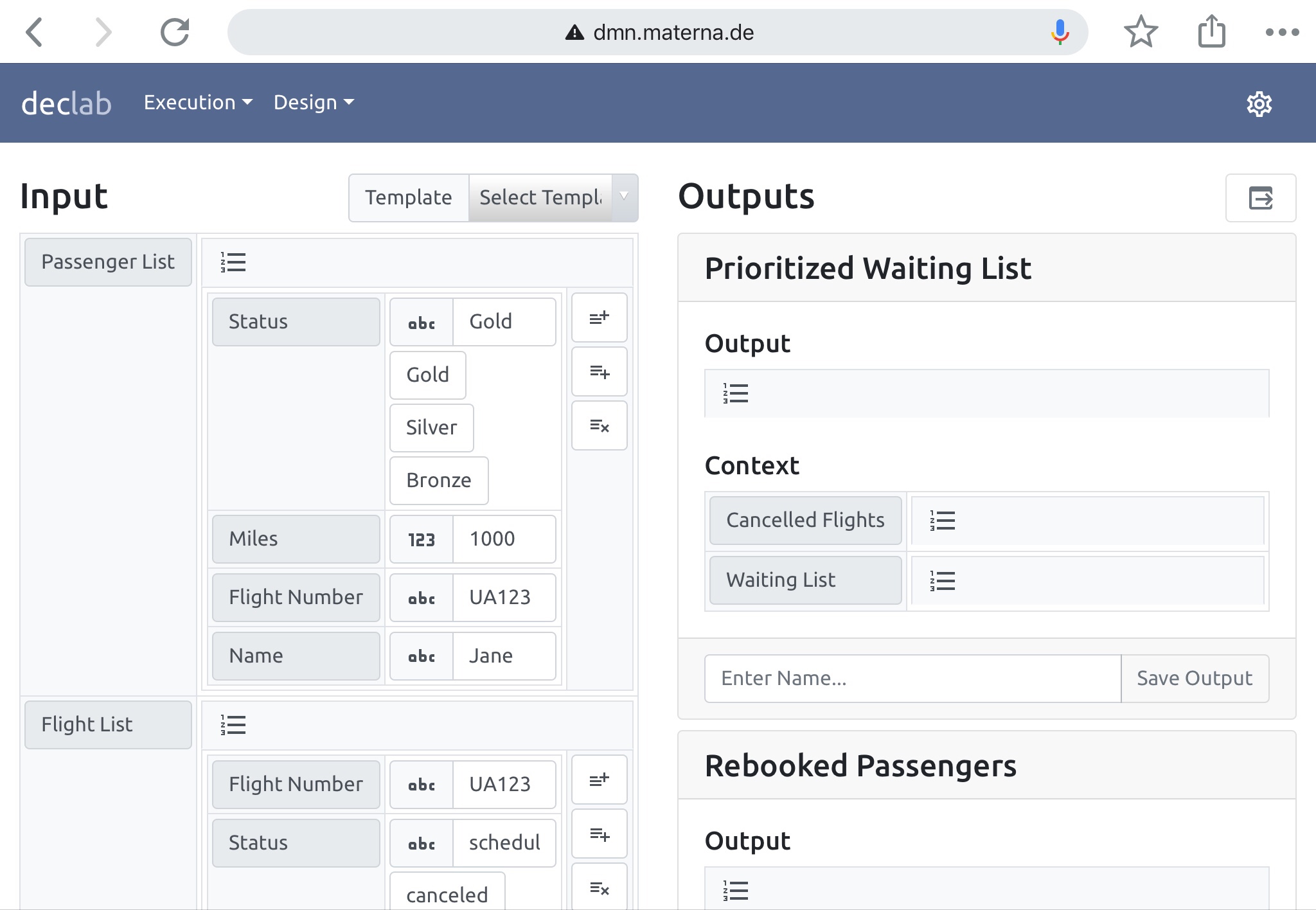
Daniel Schmitz-Hübsch and Ulrich Striffler of Materna, who presented earlier this week on whether FEEL is friendly enough, returned to discuss testing of decision models using a tool that they have developed. The typical life cycle for developing and testing decision models has a business analyst modeling the decisions and creating test cases, but having to pass it off to a developer for executing the test cases and drawing conclusions to feed back into the design. To cut the developer out of the cycle — and therefore shorten the lifecycle — they have developed declab, a browser-based test harness for decision models and test cases. Business analysts can perform ad hoc tests, or build a tree of test cases.
Live demo of declab
This includes FEEL testing, and the business analyst can enter and test and variety of constructs to test out a field function without having to deploy an entire model — envision an analyst with their modeler on one screen and declab on another screen to allow them to do micro-testing as they design decision models.
Materna has released the tool as open source, and it’s based on Red Hat’s DROOLS engine performing the tests in the background. You can try it out online here. Lots of great suggestions and comments from the audience; hopefully some of them will contribute to the open source project.
Exploiting payroll knowledge with Viren. Tim Stuyckens, Teal Partners
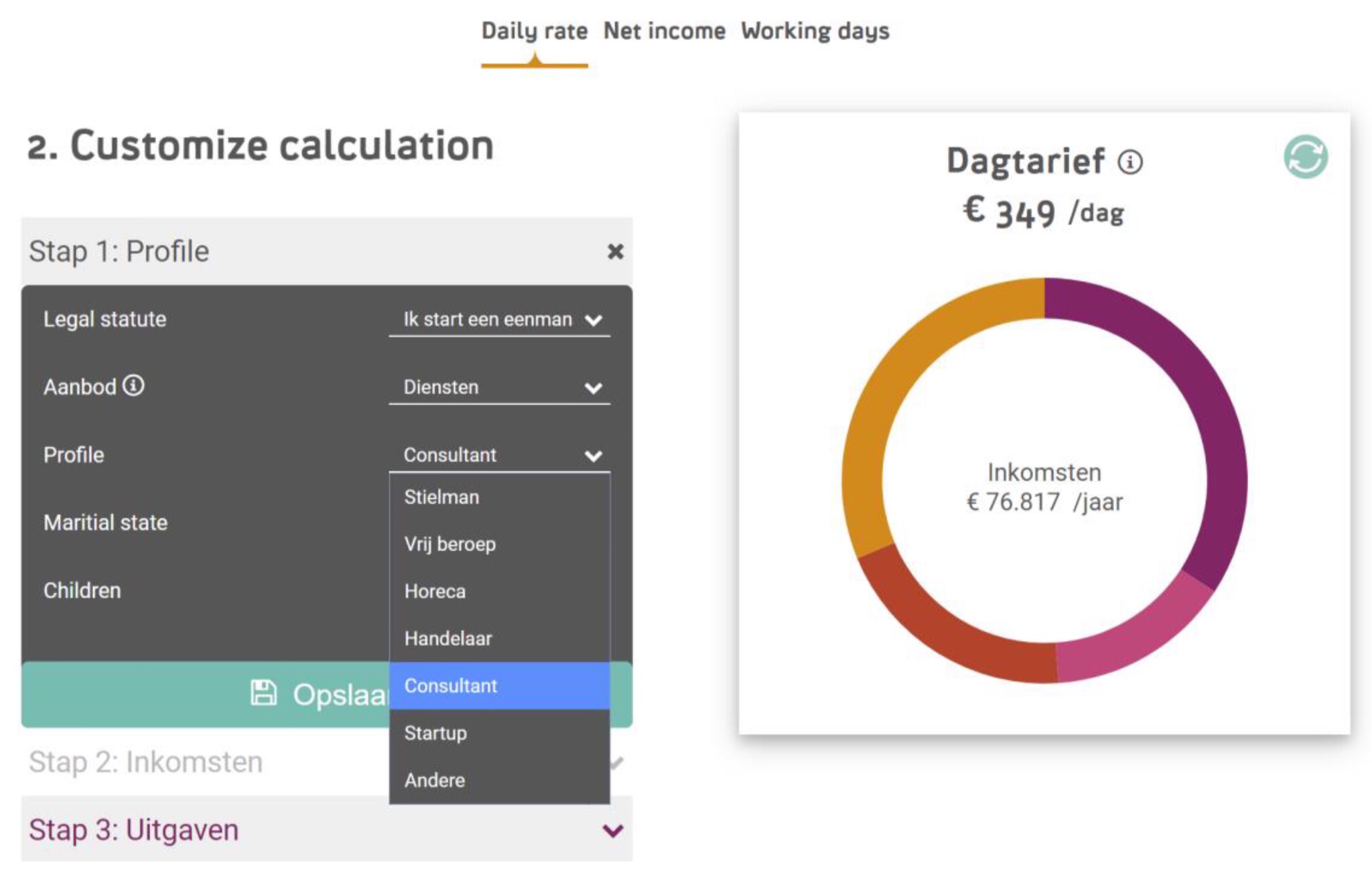
Tinm Stuyckens presented on their Viren decision-based tool for modeling and executing knowledge, specifically for calculating expat tax in payroll software. Payroll tax in Belgium is particularly complex, and sometimes it’s difficult to know which statutes to apply to make the most beneficial calculation.
In addition to straightforward tax calculations, the tool can work backwards from a desired point to the necessary conditions, such as how many days to work in order to earn a certain income, or the optimal day rate to minimize taxes and earn a certain income. Business analysts can enter and modify the knowledge rules and data, while the platform handles versioning, compilation and deployment.
They use declarative rules and structured data to represent knowledge in the system, and apply constraint solvers for optimization with non-linear constraints. They only discovered DMN earlier this year and have embraced it in their tool, providing a unified DRD and decision tables to allow business analysts to more easily step through the decision logic.
The last presentation in this session was by Dennis Aarts on a use case of decision management shared services model at Informatie Vlaanderen, an entity of the Flemish government in Belgium. They provide digital services to other parts of the government, and they were looking at ways to improve the quality and consistency of their services. The solution is Automatisch Advies (Automated Advice) which includes authentic and authorized data sources, orchestration using Camunda BPM, and business rules using IBM ODM. It has an extensible architecture to allow other capabilities to be integrated in the future, such as AI/ML.
There were several goals for the project, including productivity (reducing cycle time, reuse of data), regulatory (GDPR requirements) and ease of use (business can make modifications). The solution provides a centralized platform where rules can be developed and used by multiple entities.
Having decisions as a shared service amongst many government entities has many benefits in terms of reuse across entities, and not requiring expertise or maintenance skills for the platform in each entity. Like any shared services IT, however, there are complexities in allocating costs, governance of the decision models, security of models specific to a subset of entities, and maintenance of the rule sets.
This was my last session of DecisionCAMP 2019 — I’m skipping the final vendor statements and the closing remarks to head off and have a few days of vacation before I have to return to real life sometime next week. It’s been a great experience, and thanks to Jacob Feldman for inviting me. It’s been several years since I’ve been in Bolzano, and it’s just as beautiful as I remember.
Beautiful Bolzano!
This has been a bit of an epic trip, having left home almost three weeks ago to attend the academic BPM conference in Vienna, give a keynote at CamundaCon in Berlin, then here for DecisionCAMP. You can find my coverage for each of those events at the links.
A few months ago at bpmNEXT, I saw Keith Swenson give an update on the DMN Technology Compatibility Kit, and we’re seeing a bit of a repeat of that presentation here at DecisionCAMP. The TCK defines a set of test cases (as DMN decision models, input data and expected results) that assure conformance to the specification, plus a sample runner application that will pass the models and data to the vendor’s engine and evaluate the results.
There are about 120 test models and 1600 test cases, supporting only DMN 1.2; these tests come from examining the specification as well as cases from practice. It’s easy for a vendor to get involved in the the TCK, both in terms of running it against their engine and in terms of participating through submitting new test models and cases. You can see the vendors that have submitted their results; although many more vendors claim that they “have DMN”, their actual level of compatibility may be suspect.
The TCK committee is getting ready for DMN 1.3, and considering tests for modeling tools in addition to the current tests for the engine. He also floated the idea of a standardized API for DMN as a service, so that the calling application doesn’t need to know which engine it’s calling — possibly something that’s not going to be a big hit with vendors.
Business innovation of BPO realized by Task Center and AI and Rule Engine. Yoshihito Nakayama, NTT DATA INTRAMART
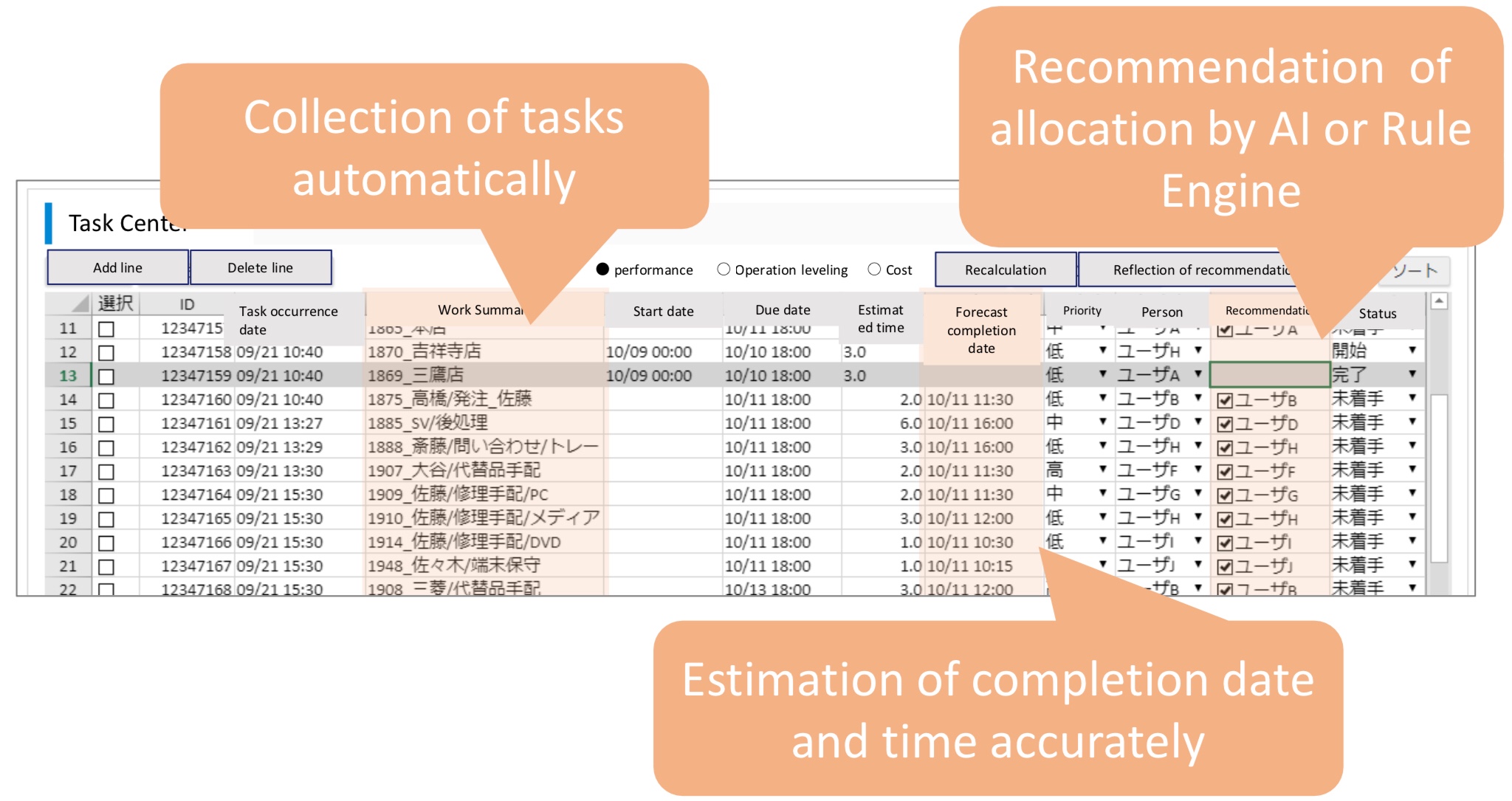
Yoshihito Nakayama presented on the current challenges of BPO with respect to improving productivity, and how they are resolving this using AI and a rules engine to aggregate and assign human tasks from multiple systems to different team members. This removes the requirement to manually review and assign work, and also provides a dashboard for visualizing work in progress and future forecasts.
AI is used to predict and optimize task classification and assignment, based on time required to complete the task and the individual worker skill level and productivity. It is also used to predict workload for task types and individual workers.
Their visualization dashboard shows drilldowns on current and past productivity, plus future forecasts. The simulation models for forecasting can be fine-tuned to optimize for cost, performance and other factors. It brings together work monitoring from all systems, including RPA processes. They’re also using process mining on a variety of systems to create a digital twin of the organization for better tracking and predictions, as well as other tools such as voice and image identification to recognize what tasks are being done that are not being recorded in any system logs.
They have a variety of case studies across industries, looking at automating non-routine work using case management, BPM, RPA, AI and rules.
Spaghetti Spreadsheets Untangled – Benefits of decision modeling when uncovering complex business logic hidden in spreadsheets. Charlotte Bouvy, M.C. Bouvy Consultancy
Charlotte Bouvy presented on her work done with SVB, the Netherlands social insurance administrator, on implementing business rules management. They are using DMN-based wizards for supporting 1,500 case workers, and the specific case was around the operational control and audit departments and the “lawfulness” of how the assessment work is done. Excel spreadsheets were used to do this, which had obvious problems in terms of being error prone and lacking domain-specific business logic. They implemented their SARA system to replace the spreadsheets with Oracle OPA, which allowed them to more accurately represent knowledge, as well as separate the data from the decision model while creating an executable model.
These type of audit processes require sampling over a wide variety of case files to compare actual payments against expected amounts, with some degree of aggregation within specific laws being applied. Moving to a rules engine allowed them to model calculations and decisions, and separate data and model to avoid errors that occurred when copying and pasting data in spreadsheets. The executable model is now a single source of truth to which version control and change management can be applied. They are trying out different ways of using the SARA system: directly in Oracle Policy Modeler for building and debugging; via a web interview and an RPA robot for data input; and eventually via direct integration with the SVB’s case management system to load data.
The Decision Model for Gate Allocation. Silvie Spreeuwenberg, Librt
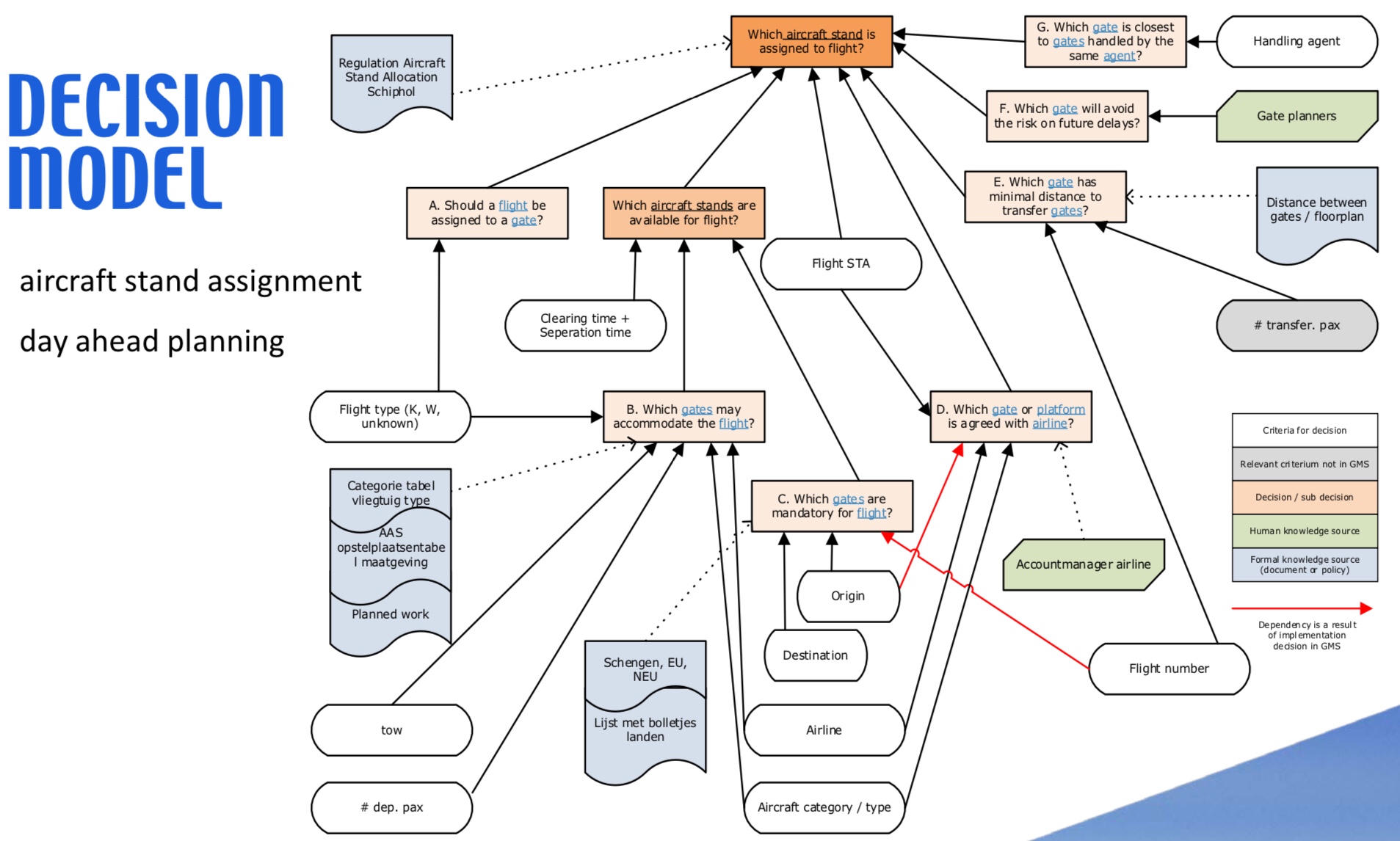
Day 3 of DecisionCAMP 2019 started with three use cases from industry. First, Silvie Spreeuwenberg presented on decision models for allocating airport gates, specifically at Schiphol airport in Amsterdam. Although gate plans are made a day in advance based on flight schedules, they change constantly due to early arrivals, late departures and other unexpected disruptions to the schedule. Any given day, there are 50-100 gate changes one hour before an aircraft arrival; although this was seen as a disruption, this could also be considered an opportunity for optimization.
There were a lot of rules used for the planning and reassignment that had more to do with preferences than actual optimization; they really wanted to drive towards the objective of optimizing asset usage and therefore airport capacity. There are a lot of factors involved, such as having sufficient gate area capacity to handle the number of passengers for a flight, or having buses available to offload flights that can’t be assigned a gate. They have created a policy for aircraft stand allocation which includes some identifiable decision tables, although these are just at the strategy documentation phase.
Definitely a complex problem that has applicability at every major airport around the world.
A hybrid implementation of multi-channel, multi-modal, high volume financial risk monitoring. Martijn Tromm and Marten Schokking, Oracle
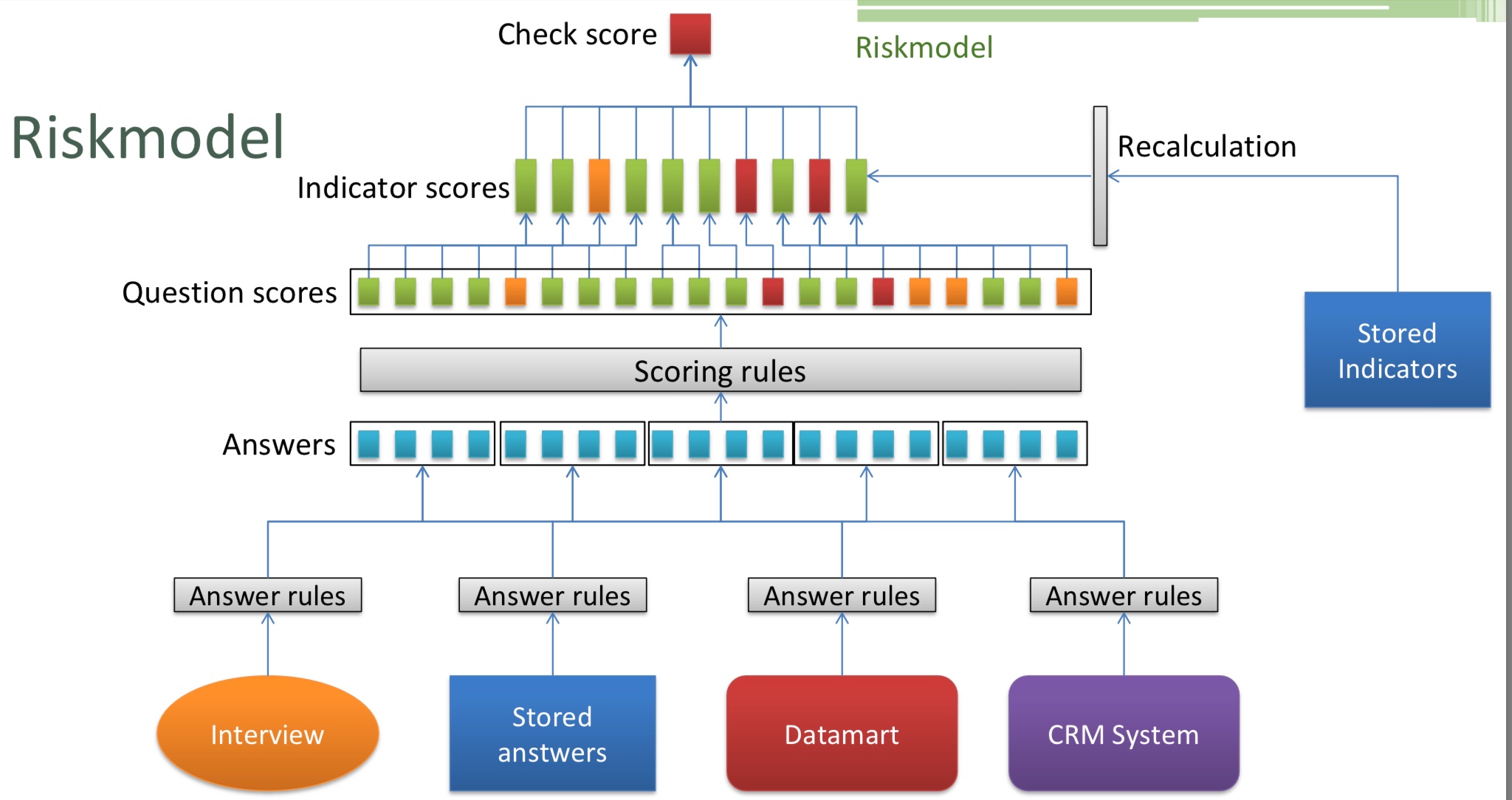
Marten Schokking and Martijn Tromm presented a use case from Rabobank using decision management and machine learning for customer risk assessment in terms of KYC (know your client) and AML (anti-money laundering). This is used during client onboarding, but also during periodic reviews as well as reviews triggered by specific events. There are scoring rules that use data input from a variety of sources, including client information from a CRM, interview responses and policies.
There are government regulations requiring that this be done for all clients at certain times. A triggering event, such as a change in the customer’s circumstances, will cause a customer interview and other data analysis to recalculate the risk; this may result in a more detailed manual review of the risk. At this point, there is still a lot of employee work which is creating a challenge in completing the customer risk assessments within the regulatory deadlines; they are looking at how to automate the basic assessment using machine learning in order to reduce the manual work required.
The risk model has been built using Oracle Policy Automation rules engine integrated with the Siebel CRM. They are reusing rules across channels where possible, and the use of natural language in the rules definition helps with traceability to the policies. They are continuing to innovate with rules, such as having context-driven rules based on user behavior on specific channels, and having a fast two-day turnaround for rule changes related to certain types of policy changes. The ability to predict the impact of policy changes based on actual data allows for operational planning to accommodate those changes.
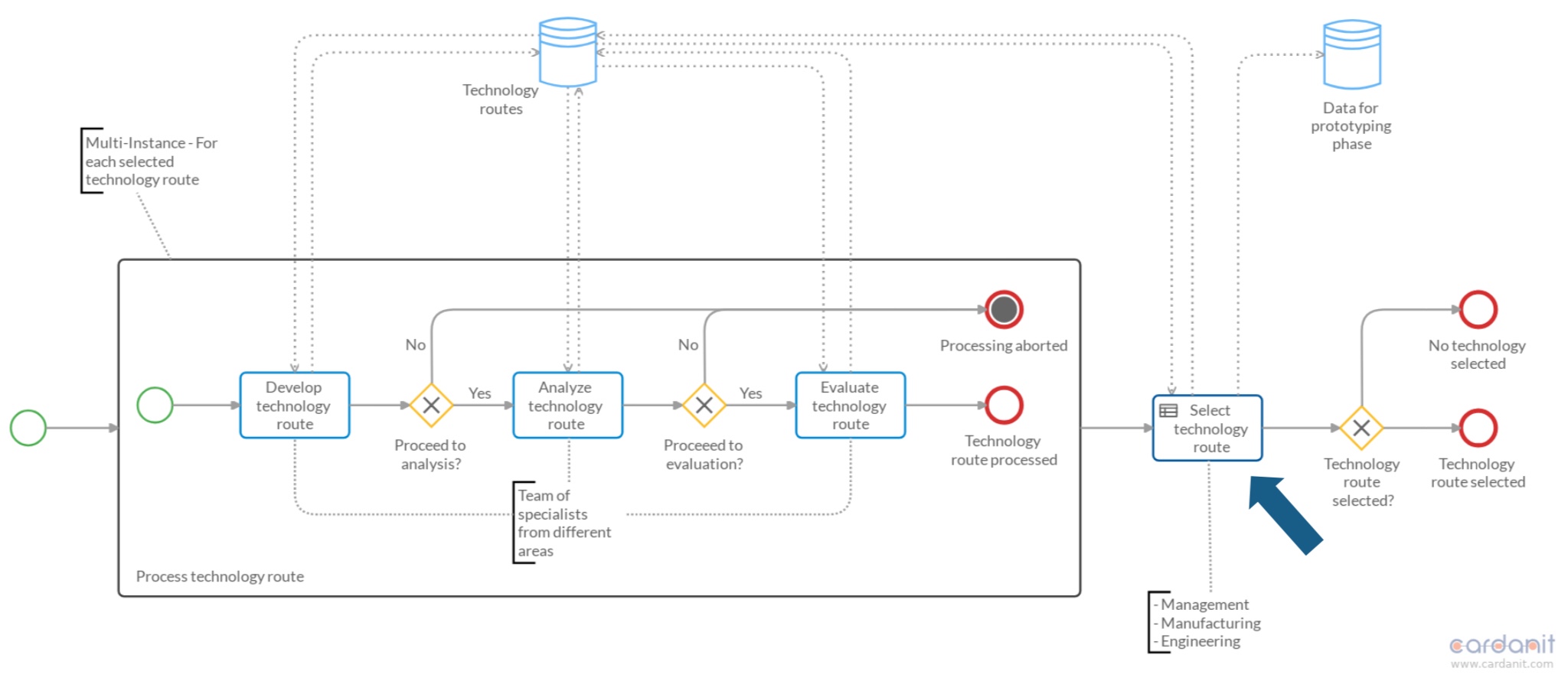
The Role of DMN and BPMN in the Design of Composite Materials. Dario Campagna, ESTECO
Dario Campagna presented on how the COMPOSELECTOR project is integrating material modeling and business process management in a decision support system for composite material design; this type of design can have complex requirements, business decisions and simulation workflows. Using application cases from Dow, Airbus and Goodyear, they modeled the business flow using BPMN and DMN. ESTECO, which creates software tools for engineering design, is a contributor to the COMPOSELECTOR project.
While BPMN is used to model the flow at the business level, DMN decision tables are used to make decisions on the class of materials and manufacturing process, then on the simulation workflows to use based on business and engineering KPIs. DMN provides the link from the business layer to the engineering layer, then to the simulation layer. Using DMN provides a higher level of consistency in decision-making, which leads to better design and lower costs.
We saw a brief video of a demo of the system in use: a business-level manager selects high-level parameters and KPIs for the proposed design; this selects one or more simulation models for the material design, which is then confirmed or decided by an engineer; the results of the simulation are passed back to the manager for final decision-making. This has the effect of integrating the business and technical sides of the design process, and include modeling and simulation results in the business-level (human) decisions in a standardized way.