Bill Lobig, Mike Marin, Peggy (didn’t catch her last name) and Lauren Mayes hosted a freeform roundtable for any technical questions about the new Case Manager product.
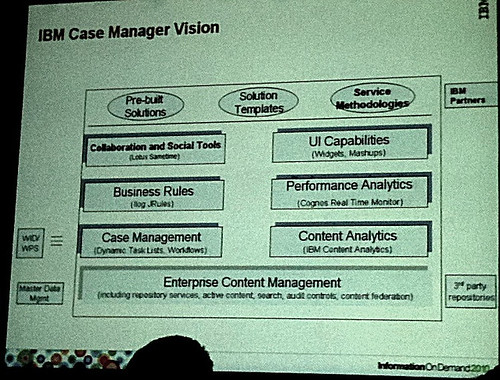
I had a chat with Mike prior to the talk, and he reinforced this during the session, about the genesis of Case Manager: although there were a lot of ideas that came from the old BPF product, Mike and his team spent months interviewing the people who had used BPF to find out what worked and what didn’t work, then built something new that incorporated the features most needed by customers. The object model for the case is now part of the basic server classes rather than being a higher-level (and therefore less efficient) custom object, there are new process classes to map properties between case folders and processes, and a number of other significant architectural changes and upgrades to make this happen. I see TIBCO going through this same pain right now with the lack of upgrade path from iProcess to AMX BPM, and to the guy in the audience who said that it’s not fair that IBM gives you a crappy product, you use it and provide feedback on how to improve it, then they charge you for the new product: well, that’s just how software works sometimes, and vendors will never have true innovation if they always have to be supporting their (and your) entire legacy. There does need to be some sort of migration path at least for the completed case folder objects from BPF to Case Manager native case objects, although that hasn’t been announced, since these are long-term corporate assets that have to be managed the same as any other content; however, I would not expect any migration of the BPF apps themselves.
More process functionality is being built right into the content engine; this is significant in that you’ve always required both ECM and BPM to do any process management, but it sounds like some functionality is being drawn into the content engine. Does this mean that the content and process engines eventually be merged into a single platform and a single product? That would drive further down the road of repositioning FileNet BPM as content-centric – originally done at the time of the FileNet acquisition, I believe, to avoid competition with WebSphere BPM – since if it’s truly content-centric, then why not just converge the engines, including the ACM capabilities? That would certainly make for a more seamless and consistent development environment, especially around issues like object modeling and security.
One consistent message that’s coming across in all the Case Manager sessions is accelerating the development time by allowing a business analyst to create a large part of a case application without involving IT; this is part of what BPF was trying to provide, and even BPM prior to that. I was FileNet’s evangelist for the launch of the eProcess product, which was the first version of the current generation of BPM, and we put forward the idea back in 2000 that a non-technical (or semi-technical) analyst could do some amount of the model-driven application development.
There are obviously still some rough edges in Case Manager still, since version 1.0 isn’t even out yet. In a previous session, we saw some of the kludges for content analytics, dashboarding and business rules, and it sounds like role-based security and e-forms isn’t really fully integrated either. The implications of these latter two are tied up with the ease in which you can migrate a case application from one environment to another, such as from development to test to production: apparently, not completely seamless, although they are able to bundle part of a case application/template and move it between environments in a single operation. Every vendor needs to deal with this issue, and those that have a more tightly integrated set of objects making up an application have a much easier time with this, especially if they also offer a cloud version of their software and need to migrate easily between on premise and cloud environments, such as TIBCO, Fujitsu and Appian. IBM is definitely playing catchup in the area of moving defined applications between environments, as well as their overall integration strategy within Case Manager.