I had an update from Pegasystems on their case management offering a while ago, and with the publication of the new Forrester Wave on Dynamic Case Management, the time is right for a quick summary. After last year’s PegaWorld, I published a review of their SmartBPM V6, which was already shipping with Visual Case Manager, but they’ve stepped up the case management functionality since then and have scored a top spot in Forrester’s report (you can see the wave graphic at Pega’s site, and download the report for free after registration).
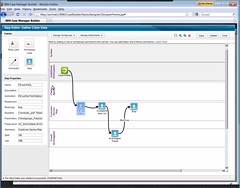
 They have a new portal for case workers and managers, and have improved the ad hoc process design that I saw in last review. There are a number of other enhancements, including some vertical applications, but we focused on the case management core functionality. The Case Designer is used to create the hierarchy of subcases and tasks, including attributes such as which are required versus optional, automatic versus manual start, or have attachments. These Case Type Definitions in the Case Designer are really the heart of defining a case management application: you define the case structure as a hierarchy of subcases, tasks and rules. You can add a new task, and apply rules to the tasks to limit choices or pre-fill information. Creating a new task also creates an empty process associated with it; this can be left completely empty to allow ad hoc process definition at runtime, or a process flow can be defined, which in turn can apply rules at any point in the process. You can specify goals and deadlines at any point in the hierarchy, so SLAs can be nested.
They have a new portal for case workers and managers, and have improved the ad hoc process design that I saw in last review. There are a number of other enhancements, including some vertical applications, but we focused on the case management core functionality. The Case Designer is used to create the hierarchy of subcases and tasks, including attributes such as which are required versus optional, automatic versus manual start, or have attachments. These Case Type Definitions in the Case Designer are really the heart of defining a case management application: you define the case structure as a hierarchy of subcases, tasks and rules. You can add a new task, and apply rules to the tasks to limit choices or pre-fill information. Creating a new task also creates an empty process associated with it; this can be left completely empty to allow ad hoc process definition at runtime, or a process flow can be defined, which in turn can apply rules at any point in the process. You can specify goals and deadlines at any point in the hierarchy, so SLAs can be nested.
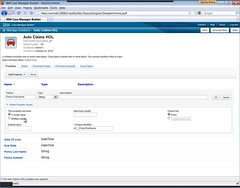
In the insurance claims example that we saw, there was a hierarchy of subcases and tasks: at the top level, a FNOL (first notice of loss) case had subcases for Vehicle Damage and Injury, each of which could be created manually by the user; within the Vehicle Damage subcase, an Adjust task was started automatically when the parent case was created, but an Adjudicate task could be started by the user as required. Case and task definitions can be reused – in the demo, the Adjust and Adjudicate tasks appear in both the Vehicle Damage and Injury cases – which potentially reduces the amount of effort to create similar case types. I’m not really clear on the distinction between (sub)cases and tasks: they both are containers for work and appear to have the same technical functionality, just a different representation on the screen. The terminology is unclear on whether a task is an atomic bit of work done by one user, or if it can have child objects as well. Leaving the subcase/task semantics aside, this definition screen allows you to define all of the activities that might need to be done in the course of a case, and some of their attributes. Although intended for business users/analysts, I think that there’s enough technical information exposed in this environment to make it unsuitable to any but the more technically-minded BAs. Ease of use has long been an issue – or, at least, a perceived issue – for Pega; they’ve made a lot of UI improvements to their modeling suite, but it’s still going to take some technical know-how to get things working. This is true for most BPMS products, in spite of what the vendors might tell you in the demo, and I don’t think that’s necessarily a bad thing for setting up frameworks and more complex processes, although it can inhibit agility if required for any change to a process or case structure. The Pega case designer environment might be better served by presenting a perspective for less technical users and a perspective with all the gory technical details so that the non-techies aren’t intimidated by it.
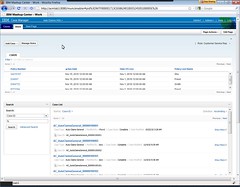
 Moving on to the end-user experience, the newly-designed portal has four tabs/views: Cases, Tasks, Events and Reports. The Cases view shows a list of all cases that the user owns (i.e., that this user instantiated) or has an interest in (i.e., where this user has a task or subcase assigned to them). In the demo example, the cases are all claims; over in the Tasks view, we see the list of tasks assigned to this user, although it’s not clear (to me) if this is a combination of subcases and tasks, or just tasks – back to my earlier discussion on the distinction between the two. In both views, you see the start date, urgency, deadline and status of the case or task. In the Cases view, there is also a button to create a new case; this prompts for the required information for the case, such as claimant and vehicles, and creates the case. The Events view shows a snapshot of activity on all cases, including the user and case identifier, plus a calendar of upcoming deadlines for the cases.
Moving on to the end-user experience, the newly-designed portal has four tabs/views: Cases, Tasks, Events and Reports. The Cases view shows a list of all cases that the user owns (i.e., that this user instantiated) or has an interest in (i.e., where this user has a task or subcase assigned to them). In the demo example, the cases are all claims; over in the Tasks view, we see the list of tasks assigned to this user, although it’s not clear (to me) if this is a combination of subcases and tasks, or just tasks – back to my earlier discussion on the distinction between the two. In both views, you see the start date, urgency, deadline and status of the case or task. In the Cases view, there is also a button to create a new case; this prompts for the required information for the case, such as claimant and vehicles, and creates the case. The Events view shows a snapshot of activity on all cases, including the user and case identifier, plus a calendar of upcoming deadlines for the cases.
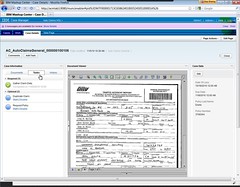
Viewing a case/task, the default view shows the case details and the subject details, although this can be customized since each widget on the screen has user-customizable parameters. Most of what we saw was out of the box, with the exception of the data fields in the Details widget, and the meaning of “Subject” (in this case, client and policy) for linking cases to subjects. The case details shows all of this information, plus attachments , subcases and tasks. In the subject details, which will be specific to the case type, information is shown about the subject – in our example, subjects were clients that were claimants on the case – and links provided to any related cases. This view also provides the option to start a new process associated with the open case/task. Information can be aggregated across subcases and tasks within a case, e.g., calculating a total indemnity amount on a claim as an aggregate of damage, injury and other subcases within the claim.
 Users aren’t limited to just executing pre-defined case definitions, however; they can also add subcases and tasks manually to a case from the Cases view, which shows them a hierarchy similar to what they would see in the Case Designer, but without a lot of the technical underpinnings exposed. They can select a known task from a list on the main case windows, or define a completely new one; parameters for the new task allow them to specify assigned resources, a workbasket, start and end dates, whether this task requires manager approval, and whether to suspend the parent case until this task completes. Once the case has been modified, the resulting case can then be saved as a template, providing a “design by doing” approach that allows business users to create their own versions of case definitions, which can be useful for capturing exceptions that may need to be rolled into the main case definition.
Users aren’t limited to just executing pre-defined case definitions, however; they can also add subcases and tasks manually to a case from the Cases view, which shows them a hierarchy similar to what they would see in the Case Designer, but without a lot of the technical underpinnings exposed. They can select a known task from a list on the main case windows, or define a completely new one; parameters for the new task allow them to specify assigned resources, a workbasket, start and end dates, whether this task requires manager approval, and whether to suspend the parent case until this task completes. Once the case has been modified, the resulting case can then be saved as a template, providing a “design by doing” approach that allows business users to create their own versions of case definitions, which can be useful for capturing exceptions that may need to be rolled into the main case definition.
The Reports view of the end-user portal shows some basic case statistics such as average duration and throughput per user; some standard reports are provided, and the user can create new reports and share them with others.
Taking a look at the Forrester report on Dynamic Case Management (DCM, or what is known in some circles as adaptive case management, or ACM) from last month, in which Pega scores a top spot, they see this still-volatile market as emerging from the human-centric BPM vendors as well as the ECM vendors, but list a number of key features that DCM requires over BPM:
- Placing the case at the center of the focus, rather than a particular process, and therefore be able to run multiple processes against a single case. In other words, instead of the usual BPM paradigm of having content (such as a case folder) being an attachment to a single process, the case folder itself is primary, and can have multiple processes and tasks associated with it simultaneously.
- Associating different types of objects with a case, including documents and other content, but also including structured data and the aforementioned processes.
- Allow users to handle variations, which allows knowledge workers to decide how a case is managed rather than having to follow a pre-defined process. This may include deciding which of a set of pre-defined tasks may be executed, as well as the ability to create completely new tasks and processes that were not envisioned by the original case designer.
- Selective restriction of changes to processes, which can manifest in a variety of ways in different DCM products. Basically, this is about compliance, and making sure that some processes and rules are always followed, even though many of the other tasks may be defined and decided by the knowledge worker. This is where structured BPM, BRM and DCM tend to overlap (and where many of the arguments about the distinction between BPM and DCM originate): in practice, many line-of-business processes have some things that just have to be done a certain way, but need to also allow for a lot of flexibility in other areas.