Roger King, head of BPM product management, gave us an update on ActiveMatrix BPM and Nimbus.
The most recent updates in AMX BPM have focused on data and case management. As we saw in the previous session on case management, their approach is data-centric with pre-defined process snippets that can be selected by the knowledge worker during execution.
As with most other BPMS platform vendors, they are positioning AMX BPM as an application development platform for digital business, including process, UX across multiple channels and application building tools. Version 4.0, released last year, focused on rapid user experience application development, case management enhancements, and process data and integration enhancements. Previously, you had to be a hard-core coder and afficiando of their APIs to create process applications, but now the app dev is much more accessible with HTML5 UI components (worklist, case, etc.), CSS, JavaScript APIs, and AngularJS and Bootstrap support in addition to the more traditional Java and REST APIs. They’ve also included a number of sample applications to clone and configure, including both worklist and case style. There is a complete app dev portal for administering and configuring applications, and the ability to change themes and languages, and define roles for the applications. Power developers can use their own favorite web app dev tool, or Business Studio can be used for the more integrated experience.
In their case management enhancements, they’ve added process-to-process global signalling with data, allowing any process to throw or catch global signals to allow for easy correlation between processes that are related based on their business data. In the case world, case data signals provide the same capability with the case object as the catching object rather than a process.
A new graphical mapper allows mapping between data objects, acting as a visual layer over their data transformation scripting.
Service processes are now supported, which are stateless processes for high-speed orchestration.
There is now graphical integration with external REST services, in the same way that you might do with WSDL for SOAP services, to make the integration more straightforward when calling from BPM.
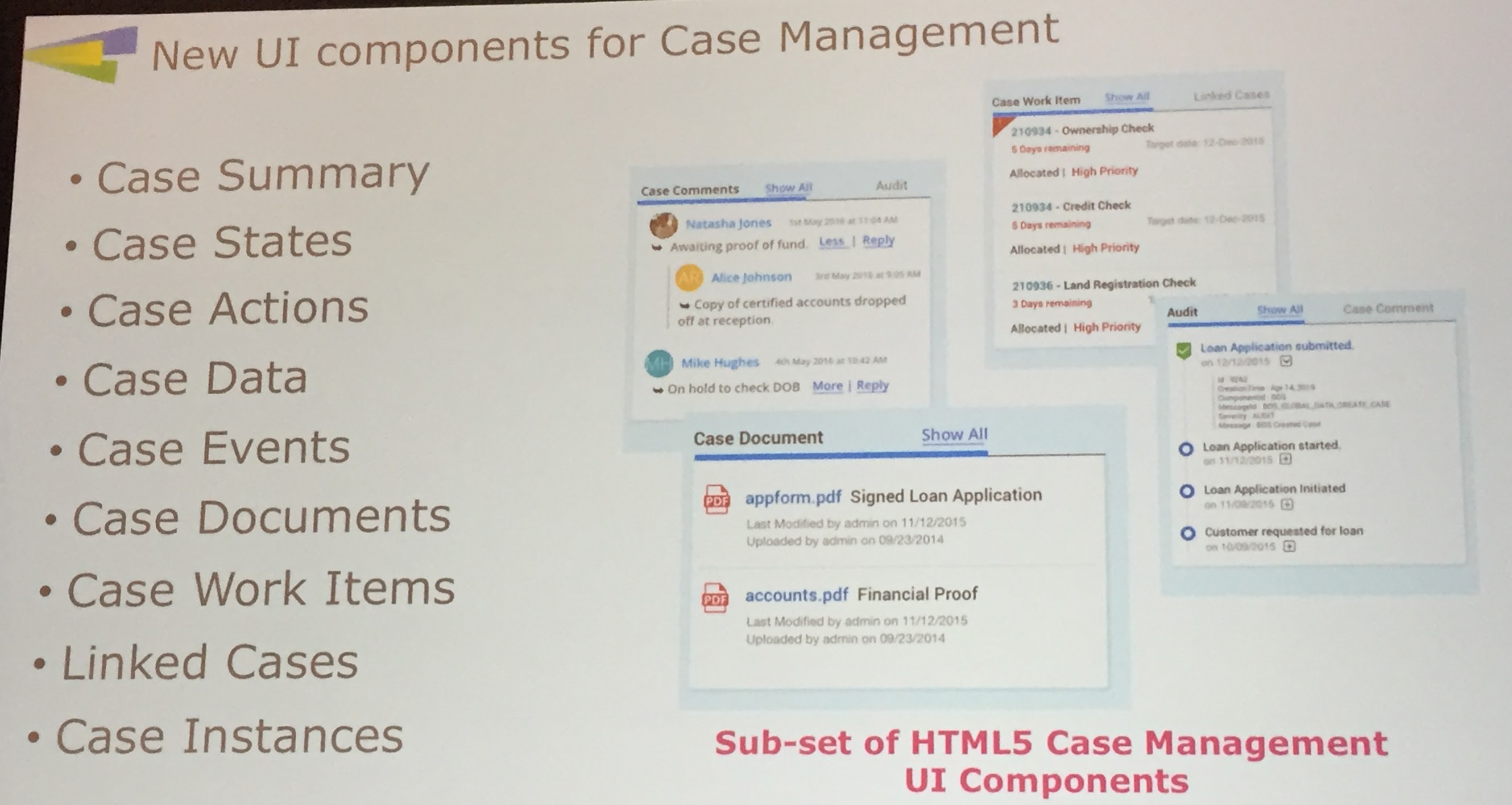
 AMX BPM 4.1 is a smaller release announced here at the conference, with the continued evolution of s a AMX BPM as an app dev platform, some new UI components for case management, and enhancements to the bundled apps for work management and case management styles as a quick-start for building new applications. There are some additional graphical mapper capabilities, and a dependency viewer between projects within Business Studio.
AMX BPM 4.1 is a smaller release announced here at the conference, with the continued evolution of s a AMX BPM as an app dev platform, some new UI components for case management, and enhancements to the bundled apps for work management and case management styles as a quick-start for building new applications. There are some additional graphical mapper capabilities, and a dependency viewer between projects within Business Studio.
On the Nimbus side, the big new thing is Nimbus Maps, which is a stripped-down version of Nimbus that is intended to be more widely used for business transformation by the business users themselves, rather than by process experts. It includes a subset of the full Nimbus feature set focused just on diagramming and collaboration, at a much lower price point.
A flying tour through recent releases, making it very obvious that I’m overdue for a round of TIBCO briefings.
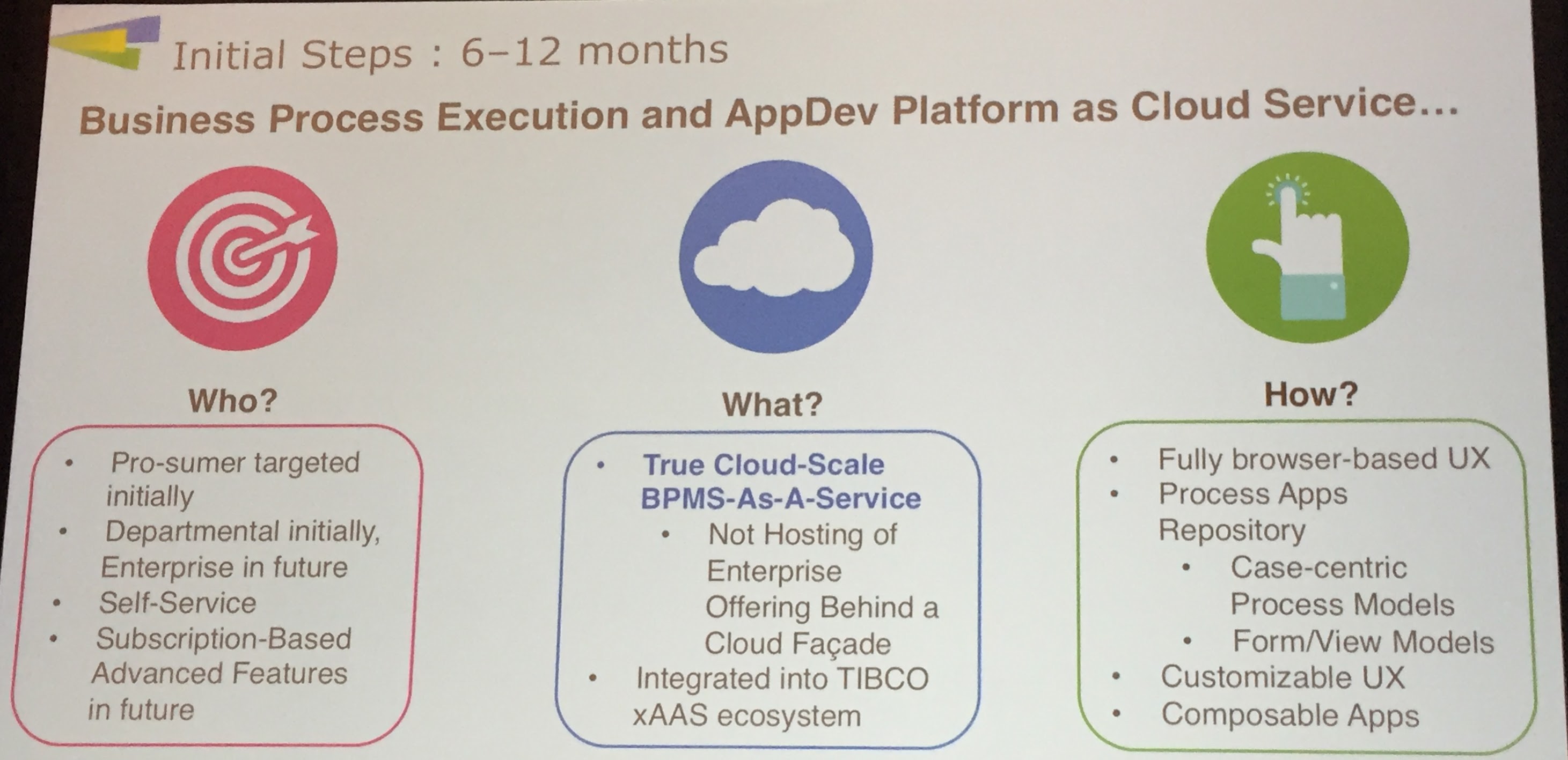
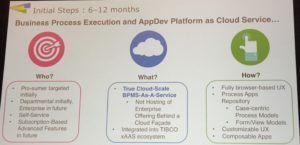 He next gave us a statement of direction on the product lines, including more self-service assessment, proof of concept and purchasing of products for faster selection and deployment. By the end of 2016, expect to see a new cloud-based business process execution and application development product from TIBCO, which will not be just a cloud layer on their existing products, but a new technology stack. It will be targeted at departmental self-service, with good enough functionality at a reasonable price point to get people started in BPM, and part of TIBCO’s overall multi-tenant cloud ecosystem. The application composition environment will be case-centric, although will allow processes to be defined with a simplified BPMN modeling syntax, all in a browser environment. There will be bundled applications that can be cloned and modified.
He next gave us a statement of direction on the product lines, including more self-service assessment, proof of concept and purchasing of products for faster selection and deployment. By the end of 2016, expect to see a new cloud-based business process execution and application development product from TIBCO, which will not be just a cloud layer on their existing products, but a new technology stack. It will be targeted at departmental self-service, with good enough functionality at a reasonable price point to get people started in BPM, and part of TIBCO’s overall multi-tenant cloud ecosystem. The application composition environment will be case-centric, although will allow processes to be defined with a simplified BPMN modeling syntax, all in a browser environment. There will be bundled applications that can be cloned and modified.
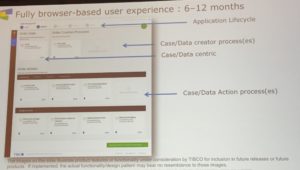
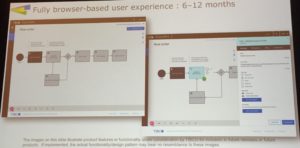
This is not intended to be a replacement for the enterprise products, but to serve a different market and different personas; regardless, I imagine that a lot of the innovation that they develop in this cloud product will end up back in the enterprise applications. The scaling for the cloud BPM offering will use Docker, which will allow for deployment to private cloud at some point in the future.
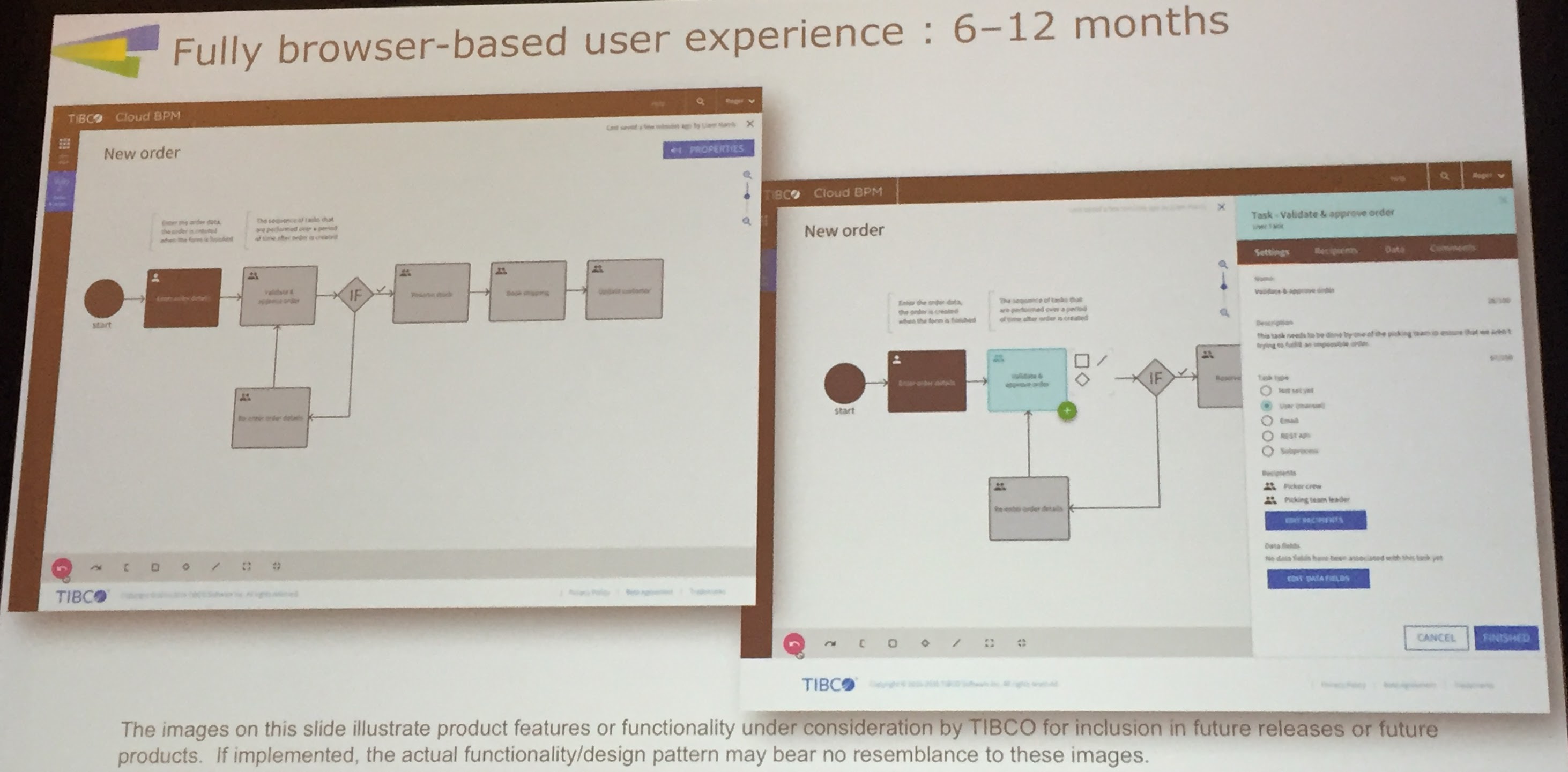
With the cloud pivot in progress, the enterprise product development will slow down a bit, but Nimbus will gain a new browser-based user experience.

 I wrote a paper a few months back on bimodal IT: a somewhat controversial subject, since many feel that IT should not be bimodal. My position is that it already is – with a division between “heavy” IT development and lighter-weight citizen development – and we need to deal with what’s there with a range of development environments including low-code BPMS. From the opening section of the paper:
I wrote a paper a few months back on bimodal IT: a somewhat controversial subject, since many feel that IT should not be bimodal. My position is that it already is – with a division between “heavy” IT development and lighter-weight citizen development – and we need to deal with what’s there with a range of development environments including low-code BPMS. From the opening section of the paper: