It’s been three years since I looked at ITESOFT | W4’s BPMN+ product, which was prior to W4’s acquisition by ITESOFT. At that time, I had just seen W4 for the first time at bpmNEXT 2014, and had this to say about it:
For the last demo of this session, Jean-Loup Comeliau of W4 on their BPMN+ product, which provides model-driven development using BPMN 2, UML 2, CMIS and other standards to generate web-based process applications without generating code: the engine interprets and executes the models directly. The BPMN modeling is pretty standard compared to other process modeling tools, but they also allow UML modeling of the data objects within the process model; I see this in more complete stack tools such as TIBCO’s, but this is less common from the smaller BPM vendors. Resources can be assigned to user tasks using various rules, and user interface forms are generated based on the activities and data models, and can be modified if required. The entire application is deployed as a web application. The data-centricity is key, since if the models change, the interface and application will automatically update to match. There is definitely a strong message here on the role of standards, and how we need more than just BPMN if we’re going to have fully model-driven application development.
A couple of weeks ago, I spoke with Laurent Hénault and François Bonnet (the latter whom I met when he demoed at bpmNEXT in 2015 and 2016) about what’s happened in their product since then. From their company beginnings over 30 years ago in document capture and workflow, they have expanded their platform capabilities and relabelled it as digital process automation since it goes beyond BPM technology, a trend I’m seeing with many other BPM vendors. It’s not clear how many of their 650+ customers are using many of the capabilities of the new platform versus just their traditional imaging and workflow functions, but they seem to be expanding on the original capabilities rather than replacing them, which will make transitioning customers easier.
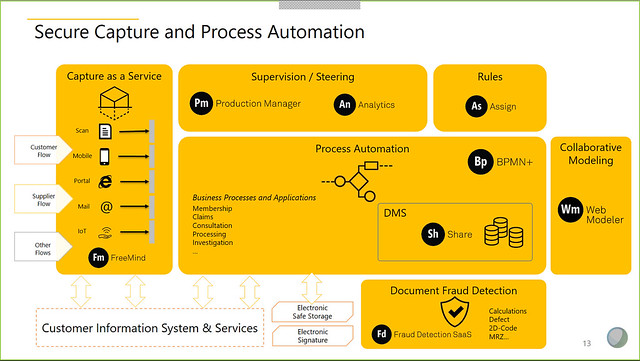
 The new platform, Secure Capture and Process Automation (SCPA), provides capabilities for capture, business automation (process, content and decisions), analytics and collaborative modeling, and adds some nice extras in the area of document recognition, fraud detection and computer-aided process design. Using the three technology pillars of omni-channel capture, process automation, and document fraud detection, they offer several solutions including eContract for paperless customer purchase contracts, including automatic fraud detection on documents uploaded by the customer; and the cloud-based Streamline for Invoices for automated invoice processing.
The new platform, Secure Capture and Process Automation (SCPA), provides capabilities for capture, business automation (process, content and decisions), analytics and collaborative modeling, and adds some nice extras in the area of document recognition, fraud detection and computer-aided process design. Using the three technology pillars of omni-channel capture, process automation, and document fraud detection, they offer several solutions including eContract for paperless customer purchase contracts, including automatic fraud detection on documents uploaded by the customer; and the cloud-based Streamline for Invoices for automated invoice processing.
Their eContract solution provides online forms with e-signature, document capture, creation of an eIDAS-compliant contract and other services required to complete a complex purchase contract bundled into a single digital case. The example shown was an online used car purchase with the car loan offered as part of the contract process: by bundling all components of the contract and the loan into a single online transaction, they were able to double the purchase close rate. Their document fraud detection comes into play here, using graphometric handwriting analysis and content verification to detect if a document uploaded by a potential customer has been falsified or modified. Many different types of documents can be analyzed for potential fraud based on content: government ID, tax forms, pay slips, bank information, and public utility invoices may contain information in multiple formats (e.g., plain text plus encoded barcode); other documents such as medical records often contain publicly-available information such as the practitioner’s registration ID. They have a paper available for more information on combatting incoming document fraud.
 Their invoice processing solution also relies heavily on understanding certain types of documents: 650,000 different supplier invoice types are recognized, and they maintain a shared supplier database in their cloud capture environment to allow these formats to be added and modified for use by all of their invoice processing customers. There’s also a learning environment to capture new invoice types as they occur. Keep in mind that the heavy lifting in invoice processing is all around interpreting the vendor invoice: once you have that sorted out, the rest of the process of interacting with the A/P system is straightforward, and the payment of most invoices that relate to a purchase order can be fully automated. Streamline for Invoices won the Accounts Payable/Invoicing product of the year at the 2017 Document Manager Awards.
Their invoice processing solution also relies heavily on understanding certain types of documents: 650,000 different supplier invoice types are recognized, and they maintain a shared supplier database in their cloud capture environment to allow these formats to be added and modified for use by all of their invoice processing customers. There’s also a learning environment to capture new invoice types as they occur. Keep in mind that the heavy lifting in invoice processing is all around interpreting the vendor invoice: once you have that sorted out, the rest of the process of interacting with the A/P system is straightforward, and the payment of most invoices that relate to a purchase order can be fully automated. Streamline for Invoices won the Accounts Payable/Invoicing product of the year at the 2017 Document Manager Awards.
After a discussion of their solutions and some case studies, we dug into a more technical demo. A few highlights:
 The Web Modeler provides a fully BPMN-compliant collaborative process modeling environment, with synchronous model changes and (persistent) discussion thread between users. This is a standalone business analyst tool, and the model must be exported as a BPMN file for import to the engine for execution, so there’s no round-tripping. A cool feature is the ability to scroll back through the history of changes to the model by dragging a timeline slider: each changed snapshot is shown with the specific author.
The Web Modeler provides a fully BPMN-compliant collaborative process modeling environment, with synchronous model changes and (persistent) discussion thread between users. This is a standalone business analyst tool, and the model must be exported as a BPMN file for import to the engine for execution, so there’s no round-tripping. A cool feature is the ability to scroll back through the history of changes to the model by dragging a timeline slider: each changed snapshot is shown with the specific author.- Once the business analyst’s process model has been imported into the BPMN+ Composer tool, the full application can be designed: data model, full process model, low code forms-based user experience, and custom code (if required). This allows a more complex BPMN model to be integrated into a low code application – something that isn’t allowed by many of the low code platforms that provide only simple linear flows – as well as developer code for “beyond the norm” integration such as external portals.
- Supervisor dashboards provide human task monitoring, including task assignment rules and skills matrix that can be changed in real time, and performance statistics.
The applications developed with their tools generally fall into the case management category, although they are document/data based rather than CMMN. Like many BPM vendors, they are finding that there is not the same level of customer demand for CMMN as there was for BPMN, and data-driven case management paradigms are often more understandable to business people.
They’ve OEM’d some of the components (the capture OCR, which is from ABBYY, and the web modeler from another French company) but put them together into a seamless offering. The platform is built on a standard Java stack; some of the components can be scaled independently and containerized (using Microsoft Azure), allowing customers to choose which data should exist on which private and public cloud infrastructure.
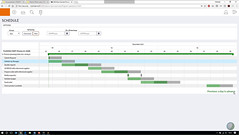 They also showed some of the features that they demoed at the 2017 bpmNEXT (which I unfortunately missed): process guidance and correction that goes beyond just BPMN validation to attempt to add data elements, missing tasks, missing pathways and more; a GANTT-type timeline model of a process (which I’ve seen in BPLogix for years, but is sadly absent in many products) to show expected completion times and bottlenecks, and the same visualization directly in a live instance that auto-updates as tasks are completed within the instance. I’m not sure if these features are fully available in the commercial product, but they show some interesting views on providing automated assistance to process modeling.
They also showed some of the features that they demoed at the 2017 bpmNEXT (which I unfortunately missed): process guidance and correction that goes beyond just BPMN validation to attempt to add data elements, missing tasks, missing pathways and more; a GANTT-type timeline model of a process (which I’ve seen in BPLogix for years, but is sadly absent in many products) to show expected completion times and bottlenecks, and the same visualization directly in a live instance that auto-updates as tasks are completed within the instance. I’m not sure if these features are fully available in the commercial product, but they show some interesting views on providing automated assistance to process modeling.

 He discussed the myth of the simple relationship between automation and employment, and how automating a task does not, in general, put people out of work, but just changes what their job is. People working together with the automation make for more streamlined (automated) standard processes with the people focused on the things that they’re best at: handling exceptions, building relationships, making complex decision, and innovating through the lens of combining human complexity with computational thinking.
He discussed the myth of the simple relationship between automation and employment, and how automating a task does not, in general, put people out of work, but just changes what their job is. People working together with the automation make for more streamlined (automated) standard processes with the people focused on the things that they’re best at: handling exceptions, building relationships, making complex decision, and innovating through the lens of combining human complexity with computational thinking. We’re in a different business and technology environment these days, and a recent survey by AIIM shows that a lot of people think that their business is being (or about to be) disrupted, and digital transformation is and important part of dealing with that. However, very few of them are more than a bit of the way towards their 2020 goals for transformation. In other words, people get that this is important, but just aren’t able to change as fast as is required. Mancini attributed this in part to the escalating complexity and chaos that we see in information management, where — like Alice — we are running hard just to stay in place. Given the increasing transparency of organizations’ operations, either voluntarily or through online customer opinions, staying in the same place isn’t good enough. One contributor to this is the number of content management systems that the average organization has (hint: it’s more than one) plus all of the other places where data and content reside, forcing workers to have to scramble around looking for information. Most companies don’t want to have a single monolithic source of content, but do want a federated way to find things when they need it: in part, this fits in with the relabelling of enterprise content management (ECM) as “Content Services” (Gartner’s term) or “Intelligent Information Managment” (AIIM’s term), although I feel that’s a bit of unnecessary hand-waving that just distracts from the real issues of how companies deal with their content.
We’re in a different business and technology environment these days, and a recent survey by AIIM shows that a lot of people think that their business is being (or about to be) disrupted, and digital transformation is and important part of dealing with that. However, very few of them are more than a bit of the way towards their 2020 goals for transformation. In other words, people get that this is important, but just aren’t able to change as fast as is required. Mancini attributed this in part to the escalating complexity and chaos that we see in information management, where — like Alice — we are running hard just to stay in place. Given the increasing transparency of organizations’ operations, either voluntarily or through online customer opinions, staying in the same place isn’t good enough. One contributor to this is the number of content management systems that the average organization has (hint: it’s more than one) plus all of the other places where data and content reside, forcing workers to have to scramble around looking for information. Most companies don’t want to have a single monolithic source of content, but do want a federated way to find things when they need it: in part, this fits in with the relabelling of enterprise content management (ECM) as “Content Services” (Gartner’s term) or “Intelligent Information Managment” (AIIM’s term), although I feel that’s a bit of unnecessary hand-waving that just distracts from the real issues of how companies deal with their content.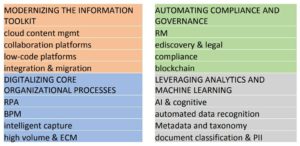 He went through some other key findings from their report on what technologies that companies are looking at, and what priority that they’re giving them; looks like it’s worth a read. He wrapped up with a few of his own opinions, including the challenge that we need to consider content AND data, not content OR data: the distinction between structure and unstructured information is breaking down, in part because of the nature of natively-digital content and in part because of AI technologies that quickly turn what we think of as content into data.
He went through some other key findings from their report on what technologies that companies are looking at, and what priority that they’re giving them; looks like it’s worth a read. He wrapped up with a few of his own opinions, including the challenge that we need to consider content AND data, not content OR data: the distinction between structure and unstructured information is breaking down, in part because of the nature of natively-digital content and in part because of AI technologies that quickly turn what we think of as content into data. A little over a year ago, I wrote a paper on intelligent capture for digital transformation, sponsored by ABBYY, and
A little over a year ago, I wrote a paper on intelligent capture for digital transformation, sponsored by ABBYY, and 