I had a chance to see IBM’s new Case Manager product at IOD last month, and last week Jake Levirne, the product manager, gave me a more complete demo. If you haven’t read my earlier product overview from IOD as well as the pre-IOD briefing on Case Manager and related products, the business analyst view, a quick bit on customizing the UI and the technical roundtable, you may want to do so now since I’ll try not to repeat too much of what’s there already.
Runtime
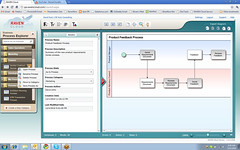
 We started by going through the end-user view of an application for insurance claims. There’s a role-based portal interface, and this user role (CSR) sees a list of cases, can search for a case based on any of the properties, or add a new case – fairly standard functionality. In most cases, as we’ll see later, cases are created automatically on the receipt of a specific document type, but there needs to be the flexibility to have users create their own as well. Opening a case, the case detail view shows case data (metadata) and case information, which comprises documents, tasks and history that are contained within the case. There’s also a document viewer, reminding us that case management is content-centric; the entire view is a bit reminiscent of the previous Business Process Framework (BPF) case management add-on, which has definitely contributed to Case Manager in a philosophical sense if not any of the actual underlying technology.
We started by going through the end-user view of an application for insurance claims. There’s a role-based portal interface, and this user role (CSR) sees a list of cases, can search for a case based on any of the properties, or add a new case – fairly standard functionality. In most cases, as we’ll see later, cases are created automatically on the receipt of a specific document type, but there needs to be the flexibility to have users create their own as well. Opening a case, the case detail view shows case data (metadata) and case information, which comprises documents, tasks and history that are contained within the case. There’s also a document viewer, reminding us that case management is content-centric; the entire view is a bit reminiscent of the previous Business Process Framework (BPF) case management add-on, which has definitely contributed to Case Manager in a philosophical sense if not any of the actual underlying technology.
For those FileNet geeks in the crowd, a case is now a native content type in the FileNet content repository, rather than a custom object type as was used in the BPF; logically, you can think of this as a case folder that contains everything related to the case. The Documents tab is pretty straightforward – a list of documents attached to the case – and the History tab shows a list of events on the case, including documents being added and tasks started/completed. The interesting part, as you might have guessed, is in the Tasks tab, which shows the tasks (small structured processes, in reality) assigned to this case, either as required or optional tasks. Tasks can be added to a case at design time or runtime; when added at runtime, these are predefined processes, although there may be customizable parameters that the user can modify, but the end user can’t change the definition of a task. This gives some flexibility to the user – they can choose whether or not to execute the optional tasks, they can execute tasks in any order, and they can add new tasks to a case – but doesn’t allow the user to create new tasks: they are always selecting from a predefined list of tasks. Depending on the task definition, tasks for their case may end up assigned to them or to someone else, or to a shared queue corresponding to a role. This results in the two lists that we saw back in the first portal view: one is a list of cases based on search criteria, and the other is a list of tasks assigned to this user or a shared queue on which they are working.
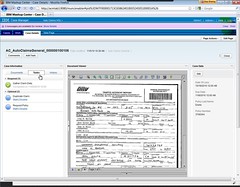 Creating a new case is fairly simple for the user: they click to add a case, and are presented with a list of instructions for filling out the initial case data, such as the date of loss and policy number in our insurance claim example. The data that can be entered using the standard metadata widget is pretty limited and the form isn’t customizable, however, and often there is an e-form included in the case that is used to capture more information. In this situation, there is a First Notice of Loss e-form that the user fills out to gather the claim data; this e-form is contained as a document in the case, but also synchronizes some of its fields with the case metadata. This ability to combine capabilities of documents, e-forms and folders has been in FileNet for quite a while, so it’s no surprise that they’re leveraging it here. It is important to note, however that this e-form would have to be designed in the Lotus forms designer, not in the Case Manager design tools: a reminder that the IBM Case Manager solution is a combination of multiple tools, not a single monolithic system. Whether this is a good or bad thing is a bit of a philosophical discussion: in the case of e-forms, for example, you may want to use this same form in other applications besides Case Manager, so it may make sense that it is defined independently, but it will require additional design skills.
Creating a new case is fairly simple for the user: they click to add a case, and are presented with a list of instructions for filling out the initial case data, such as the date of loss and policy number in our insurance claim example. The data that can be entered using the standard metadata widget is pretty limited and the form isn’t customizable, however, and often there is an e-form included in the case that is used to capture more information. In this situation, there is a First Notice of Loss e-form that the user fills out to gather the claim data; this e-form is contained as a document in the case, but also synchronizes some of its fields with the case metadata. This ability to combine capabilities of documents, e-forms and folders has been in FileNet for quite a while, so it’s no surprise that they’re leveraging it here. It is important to note, however that this e-form would have to be designed in the Lotus forms designer, not in the Case Manager design tools: a reminder that the IBM Case Manager solution is a combination of multiple tools, not a single monolithic system. Whether this is a good or bad thing is a bit of a philosophical discussion: in the case of e-forms, for example, you may want to use this same form in other applications besides Case Manager, so it may make sense that it is defined independently, but it will require additional design skills.
Once the case is created, it will follow any initial process flows that are assigned to it, and can kick off manual tasks. For example, there could be automated activities that update a claims systems with the data captured on the FNOL form, and manual tasks created and assigned to a CSR to call the third parties’ insurance carrier. The underlying FileNet content engine has a lot of content-centric event handling baked right into it, so being able to do things such as trigger processes or other actions based on content or metadata updates have been there all along and are being used for any changes to a case or its contents.
Design Time
We moved over to the Case Manager Builder to look at how designers – business analysts, in IBM’s view – define new case types. At the highest level, you first define a “solution”, which can include multiple case types. Although the example that we went through used one case type per solution, we discussed some situations where you might want to have multiple case types in a single solution: for example, a solution for a customer service desktop, where there was a different case type defined for each type of request. Since case types within a single solution can share user interface designs, document types and properties, this can reduce the amount of design work if you plan ahead a bit.
 For each solution, you define the following:
For each solution, you define the following:
- Properties (metadata)
- Roles and the in-baskets (shared work queues) to which they have access
- Document types
- In-baskets associated with this solution
- Case types that make up this solution.
Then, for each case type within a solution, you define the following:
- The document type that will be used to trigger the creation of a case of this type, if any. Cases can be added manually, as we saw in the runtime example, or can be triggered by other events, but the heavily content-centric focus of Case Manager assumes that you might usually want to kick off a case automatically when a certain document type is added to the content repository.
- The default Add Case page, which is a link to a previously-defined page in the IBM Mashup Center that will be used as the user interface on selecting the Add Case button.
- The default Case Details page, which is a link to the Mashup Center page for displaying a case.
- Optionally, overrides for the case details page for each role, which allows different roles to see different views of the case details.
- Properties for this case type, which can be manually inherited from the solution level or defined just at this level. All solution properties are not automatically inherited by each case type, since it was felt that this would make it unnecessarily confusing, but any of the solution properties can be selected for exposure at the case level.
- The property views (subsets) that are displayed in the case summary, case details and case search views. If more than about a dozen properties are used, then IBM recommends using an e-form instead of the standard views, which are pretty limited in terms of display customization. A view can include a group of properties for visual grouping.
- Case folders to organize the content within a case.
- Tasks associated with the case, grouped by required and optional tasks. Unlike the user interfaces, document types and properties, task definitions are not shared across case types within a solution, which requires that similar or identical tasks will require redefining for each case type. This is definitely an area that they can improve in the future; if their claim of loosely-coupled cases and processes is to be fully realized, then task/process definitions should be reusable at least across case types within a solution, if not across solutions.
 Although part of the case type definition, I’ll separate out the task definition for clarity. For each task within a case type, you define:
Although part of the case type definition, I’ll separate out the task definition for clarity. For each task within a case type, you define:
- As noted above, whether it is required or optional for this case type.
- Whether the task starts automatically or manually, or if the user optionally adds the task to the case at runtime.
- Inclusion of the task in a set. Sets provide visual grouping of tasks within a case, but also control execution: a set can be specified as all-inclusive (all tasks execute if any of the tasks execute) or mutually exclusive (only one of the tasks in the set can be executed). The mutually exclusive situation could be used to create a manner of case subtypes, instead of using multiple case types within a solution, where the differences between the subtypes are minimal.
- Preconditions for the task to execute, that is, the task triggers. In many cases, this will be the case start, but could also be when a document of a specific type is added to the case, or a case property value is updated to meet certain conditions, including combinations of property values.
- Design comments, which could be used simply as documentation, but are primarily intended for use by a non-technical business analyst who created the case type definition up to this point but wants to pass of the creation of the actual process flow to someone more technical.
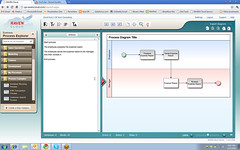
- The process flow associated with this task, using the visual Step Editor. This allows the roles defined for the solution to be added as swimlanes, and the human-facing steps to be plotted out. This supports branching as well as sequential flow, but no automated steps; however, any automated steps that are added via the full Process Designer will appear in the uneditable grey lanes at the top of the Step Editor map. If you’ve used the Process Designer before, the step properties at the left of the Step Editor will appear familiar: they’re a subset of the step properties that you would see in the full Process Designer, such as step deadlines and allowing reassignment of the step to another user.
Being long acquainted with FileNet BPM, a number of my questions were around the connection between the Step Editor and the full BPM Process Designer; Levirne handled some of these, and I also had a few technical discussions at IOD that shed light on this. In short, the Step Editor creates a full XPDL process definition and stores it in the content repository, which is the same as what happens for any process definition created in the Process Designer. However, if you open this process definition with the Process Designer, it recognizes that it was created using the Case Manager Step Editor and performs some special handling. From the Process Designer, a more technical designer can add any system steps required (which will appear, but not be editable, in the Step Editor): in other words, they’ve implemented a fully shared model used by two different tools: the Case Builder Step Editor for a less technical business analyst, and the BPM Process Designer for a developer.  As with any process definition, the Case Manager task process definitions must be transferred to the process engine before they can be used to instantiate new processes: this is done automatically when the solution is deployed.
As with any process definition, the Case Manager task process definitions must be transferred to the process engine before they can be used to instantiate new processes: this is done automatically when the solution is deployed.
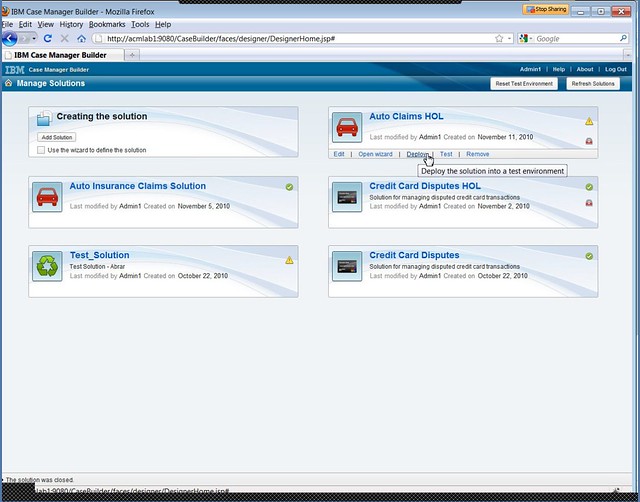
Deploying a solution to a test environment is a one-click operation from the Case Manager Builder main screen, although moving that to another environment isn’t quite as easy: the new release of the P8 platform allows a Case Manager solution to be packaged in order to move it between servers, but there’s still some manual work involved.
We wrapped up with a discussion of the other IBM products that integrate with Case Manager, some easier than others:
- Case Manager includes a limited license of ILOG JRules, but it’s not integrated in the Case Manager Builder environment: it must be called as a web service from the Process Designer. There are already plans for better integration here, which is essential.
- Content Analytics for data mining and analytics on the case metadata and case content, including the content of attached documents.
- Case Analyzer, which is a version of the old BPM Process Analyzer, with enhancements to show analytics at the case level and the inclusion of custom case properties to provide a business view as well as an operational view in dashboard and reports.
They’re working on better integration between Case Manager and the the WebSphere product line, including both WebSphere Process Server and Lombardi; this will be necessary to combat the competition who have a single solution that covers the full range of BPM functionality from structured processes to completely dynamic case management.
Built on one of the best industrial-strength enterprise content management products around, IBM Case Manager will definitely see some adoption in the existing IBM/FileNet client base: adding this capability onto an existing FileNet Content Manager repository could provide a lot of value with a minimal amount of work for the customer, assuming that they actually allowed their business analysts to do the work that IBM intends them to. In spite of the power, however, there is a lack of flexibility in the runtime task definition that may make them less competitive in the open market.