
I listened in on the Camunda 7.8 release webinar this morning – they issue product releases every six months like clockwork – to hear about the new features and upgrades from CEO Jakob Freund and VP of engineering Daniel Meyer.
 They’re obviously getting a broader audience for these release webinars than just their current customers and open source community members, and started with a bit about the company, the product stack and their clients. We heard about a recent case study presented at their first San Francisco community day: 24 Hour Fitness is using Camunda process and decision management for high volume real-time orchestration of their core business processes. With over 190 processes in production, executing 20 million BPMN and 18 million DMN instances per day, this is clearly an enterprise-strength application; they are using the Camunda Enterprise Edition rather than the Community Edition for the additional features and SLA-based support, but the underlying engine and much of the tooling is identical between the products.
They’re obviously getting a broader audience for these release webinars than just their current customers and open source community members, and started with a bit about the company, the product stack and their clients. We heard about a recent case study presented at their first San Francisco community day: 24 Hour Fitness is using Camunda process and decision management for high volume real-time orchestration of their core business processes. With over 190 processes in production, executing 20 million BPMN and 18 million DMN instances per day, this is clearly an enterprise-strength application; they are using the Camunda Enterprise Edition rather than the Community Edition for the additional features and SLA-based support, but the underlying engine and much of the tooling is identical between the products.
The key new features and updates are as follows:
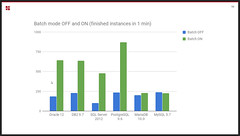 Workflow engine performance improvements. A new batch mode allows 3-4 times more process instances to be executed per minute on several of the supported databases. This is based on grouping database transactions for the same database table (including both operational and audit tables), then doing a single round-trip call between the Camunda server and the database server to execute the batch of inserts, updates and deletes.
Workflow engine performance improvements. A new batch mode allows 3-4 times more process instances to be executed per minute on several of the supported databases. This is based on grouping database transactions for the same database table (including both operational and audit tables), then doing a single round-trip call between the Camunda server and the database server to execute the batch of inserts, updates and deletes.- Cockpit batch operations. It’s now possible to do bulk operations for suspending/activating and modifying running processes instances, and restarting completed process instances. Process instances can be selected by process definition name and by more complex search and filtering operations such as instance variable values, then a batch command issued to suspend, restart, modify or delete instances. A new feature also allows all instances that are at a specific task to be dragged to a new task directly in the process model, whereas this was only possible with single instances before; this can be used either to move the instances to a new task to correct for an error condition or changed process flow, or to restart instances that are sitting at the final end node.
- More Cockpit features. In addition to the batch operations, Cockpit also now has faster BPMN model rendering (from 8 seconds down to 2 seconds), ability to delete process definitions, and a number of other administrative functions.
- Spring Boot Starter. Originally created as a community extension in 2015 (with significant contributions from community members Jan Galinski and Oliver Steinhauer), Camunda adopted this project into the main code base to create an officially-supported version of the Camunda Spring Boot Starter, documented here.
The first two updates are focused squarely on improving performance and administration for high volume operations, likely driven by clients such as 24 Hour Fitness, that will serve Camunda well as they push into more core enterprise business processes. The Spring Boot integration positions them well for deploying BPM services in a microservice architecture.
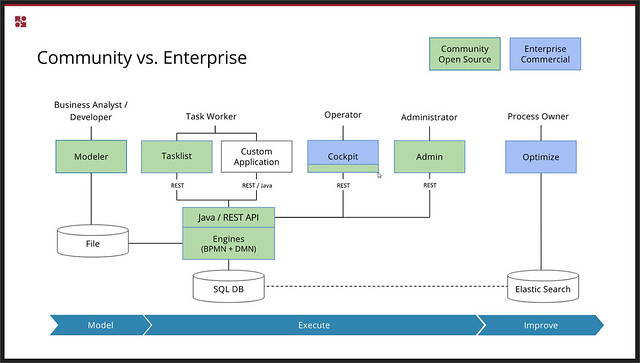
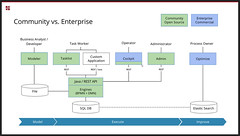
Good summary of the new features in 7.8, and a great Spring Boot coding demo by Meyer, in spite of his grumbling about having to do it on Windows for the webinar. ![]()
The webinar will be available for replay soon; check their website for availability. You can also see their release blog post that links to the release notes and describes many of the things that I saw today in the webinar.
Disclaimer: Camunda has been, but is not currently, a client. They did not provide any incentive to attend and write about this webinar, and these are my own opinions. That’s always the case for what I write here, but it’s good to make it explicit every once in a while.
