Model-Based Optimization for Effective and Reliable Decision-Making. Robert Fourer, AMPL
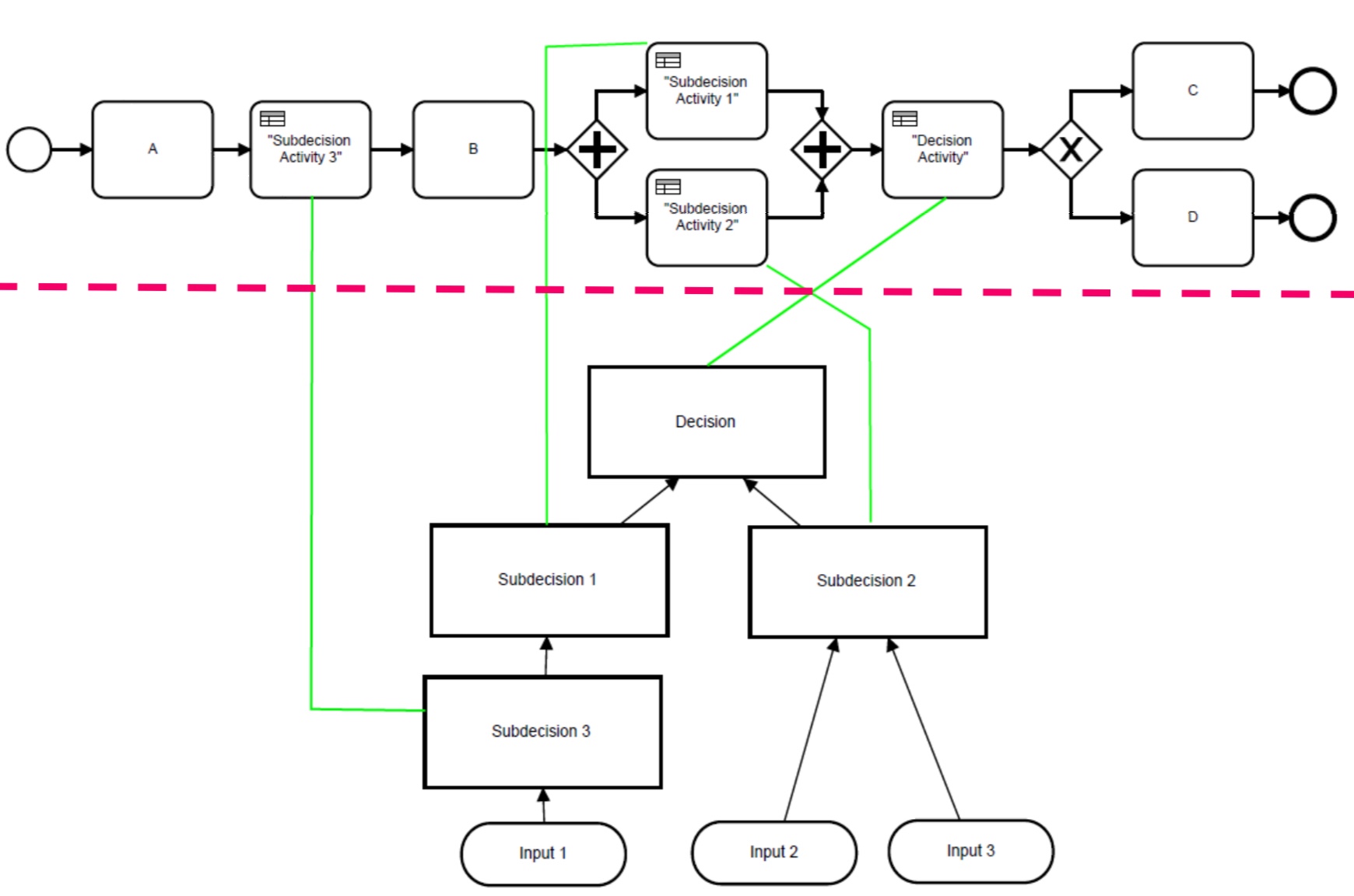
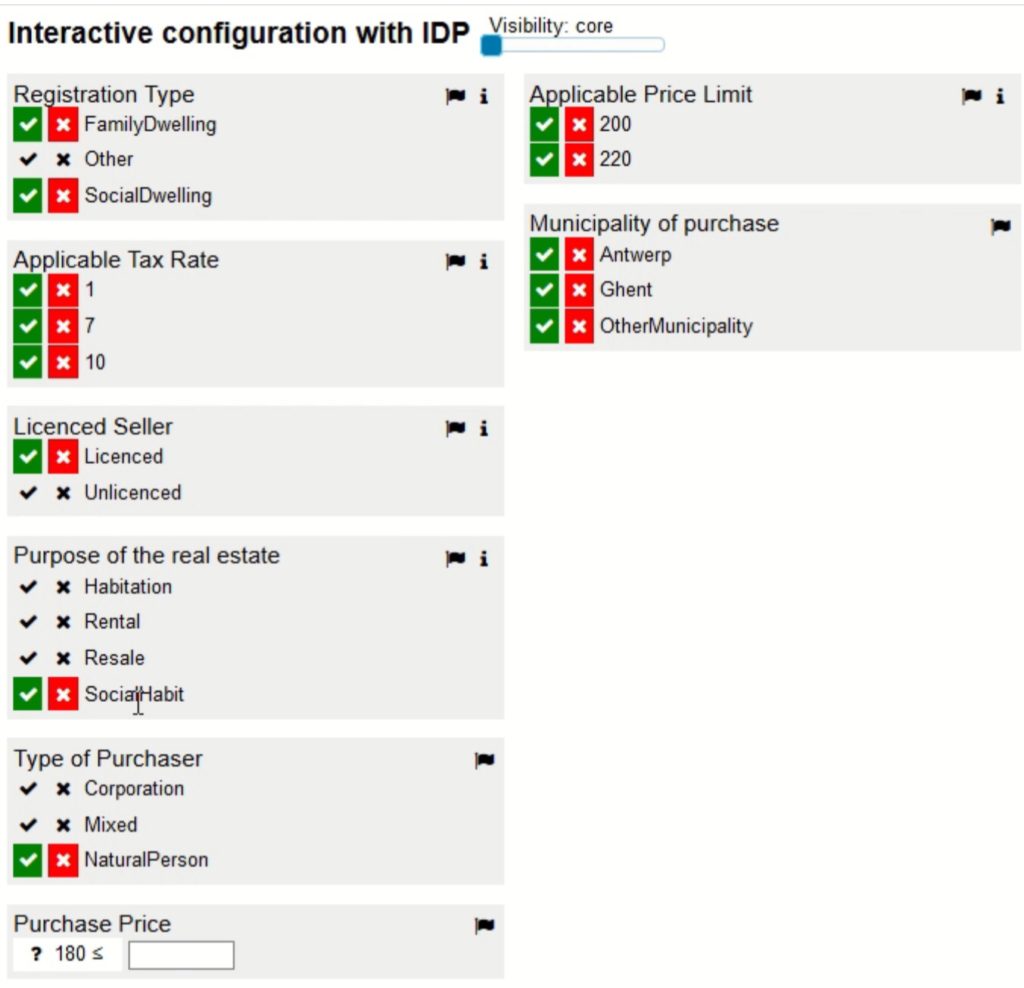
Robert Fourer presented on model-based optimization, starting with a bit of background on mathematical optimization techniques and the optimization cycle in practice. He looked at method-based approaches — which define how a solution should be found — and model-driven approaches — which define what a solution should satisfy. There are several solver solutions (often algebraic in nature) that allow you to solve within a broad problem class that is well understood by providing your specific constraints. When a problem changes, a method-based approach requires rethinking and updating the implementation, whereas a model-based approach will require new variables, expressions and constraints but this is typically easier than updating methods.
I’m fairly sure that the subtleties of how this relates to decision management have escaped me, although I can see some conceptual links with the earlier discussions on declarative rules: potentially declarative rules could be used to generate the algebraic notation that was presented in order to create inputs for a model-based optimization.
Decision Management Journey at Hiscox Claims. Larry Goldberg, Sapiens, and Harriet Parkinson, Hiscox
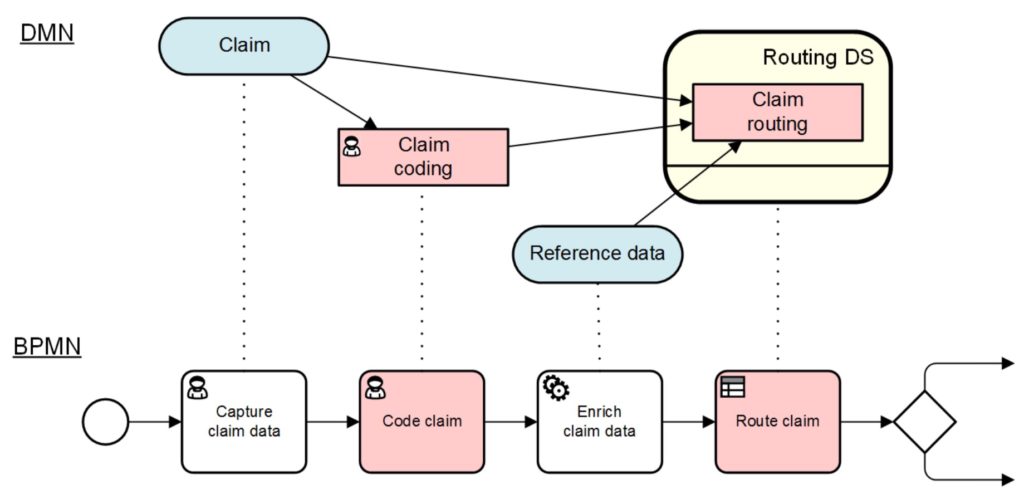
The last presentation on day 2 of DecisionCAMP is a customer case study, with a Sapiens implementation at Hiscox UK Claims. It sounds like they were in the same position as pretty much every insurance claims operation that I’ve seen: little to no automation, and decisions based on the expertise of the claims managers. In other words, a great opportunity for decision management (and process management). As a specialized insurer of high-net-worth customers, however, they have additional drivers for automating the routine administrative parts of claims: their claims adjudicators are highly skilled and well-paid, often lawyers, who do not want to be spending time on admin. There’s also market pressure to start processing claims digitally to reduce the cycle time for less complex claims, or at least triage and process the FNOL (first notice of loss) automatically.
Decision management is especially important for claims in order to ensure consistency: whether the DM system is providing a recommendation to a human claims adjudicator or automating the decision, the decision should be the same from one instance to another given the same inputs and context. Automated decision management is key to increasing the number of day 1 settlements for straightforward claims, while more complex claims will still be done with that human touch. They need to have the ability to change the rules to account for surge scenarios, such as flood that impacts a large number of customers and causes a large number of new claims; this could just change thresholds for determining whether a claim could be automated, or could do some other form of triage on the claim. I talked about scalability for resilience in my CamundaCon keynote last week, and definitely having the ability to quickly change decision parameters is part of that.
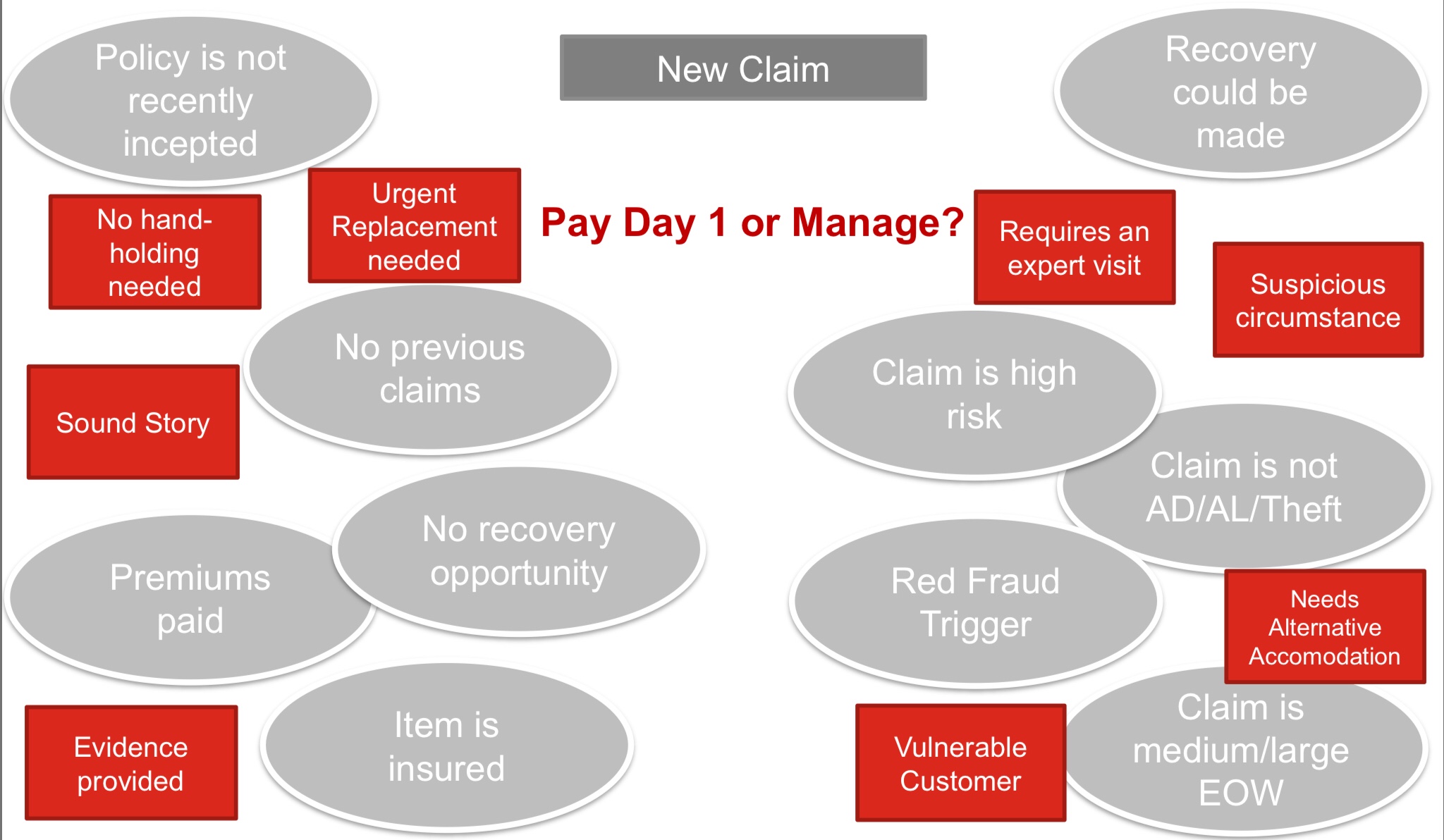
They’ve been through the design sessions and the implementation is underway; the final decision models will be built and tested this year, with the full implementation integrated with their claims management system in 2020. Changes to the rules can be done by business analysts, most without IT involvement. In addition to managing decisions that are part of the claims process, the Sapiens system will provide next-best-question support for interactive customer self-service forms (or maybe a chatbot in the future) that can perform an initial triage to determine if a claim can be handled automatically or requires a claims adjudicator to talk to the claimant. One lesson learned is that the initial models took much longer than they expected: almost a year versus the estimate of a couple of months to get a consistent model that was accepted by all business users.
I’m up next to moderate a vendor panel, which will close out this second day of DecisionCAMP. Back tomorrow for a last full day of sessions.