I first saw process mining software in 2008, when Fujitsu was showing off their process discovery software/services package, plus an interesting presentation by Anne Rozinat from that year’s academic BPM conference where she tied in concepts of process mining and simulation without really using the term process mining or discovery. Rozinat went on to form Fluxicon, which developed one of the earliest process mining products and really opened up the market, and she spent time with me providing my early process mining education. Fast forward 10+ years, and process mining is finally a hot topic: I’m seeing it from a few mining-only companies (Celonis), and as a part of a suite from process modeling companies (Signavio) or even a larger process automation suite (Software AG). Eindhoven University of Technology, arguably the birthplace of process mining, even offers a free process mining course which is quite comprehensive and covers usage as well as many of the underlying algorithms — I did the course and found it offered some great insights and a few challenges.
Today, Celonis hosted a webinar, featuring Rob Koplowitz of Forrester in conversation with Celonis’ CMO Anthony Deighton, on the role of process improvement in improving digital operations. Koplowitz started with some results from a Forrester survey showing that digital transformation is now the primary driver of process improvement initiatives, and the importance of process mining in that transformation. Process mining continues its traditional role in process discovery and conformance checking but also has a role in process enhancement and guidance. Lucky for those of us who focus on process, process is now cool (again).
Unlike just examining analytics for the part of a process that is automated in a BPMS, process mining allows for capturing information from any system and tracing the entire customer journey, across multiple systems and forms of interaction. Process discovery using a process mining tool (like Celonis) lets you take all of that data and create consolidated process models, highlighting the problem areas such as wait states and rework. It’s also a great way to find compliance problems, since you’re looking at how the processes actually work rather than how they were designed to work.
Koplowitz had some interesting insights and advice in his presentation, not the least of which was to engage business experts to drive change and automation, not just technologists, and use process analytics (including process mining) as a guide to where problems lie and what should/could be automated. He showed how process mining fits into the bigger scope of process improvement, contributing to the discovery and analysis stages that are a necessary precursor to reengineering and automation.
Good discussion on the webinar, and there will probably be a replay available if you head to the landing page.
A few months ago at bpmNEXT, I saw Keith Swenson give an update on the DMN Technology Compatibility Kit, and we’re seeing a bit of a repeat of that presentation here at DecisionCAMP. The TCK defines a set of test cases (as DMN decision models, input data and expected results) that assure conformance to the specification, plus a sample runner application that will pass the models and data to the vendor’s engine and evaluate the results.
There are about 120 test models and 1600 test cases, supporting only DMN 1.2; these tests come from examining the specification as well as cases from practice. It’s easy for a vendor to get involved in the the TCK, both in terms of running it against their engine and in terms of participating through submitting new test models and cases. You can see the vendors that have submitted their results; although many more vendors claim that they “have DMN”, their actual level of compatibility may be suspect.
The TCK committee is getting ready for DMN 1.3, and considering tests for modeling tools in addition to the current tests for the engine. He also floated the idea of a standardized API for DMN as a service, so that the calling application doesn’t need to know which engine it’s calling — possibly something that’s not going to be a big hit with vendors.
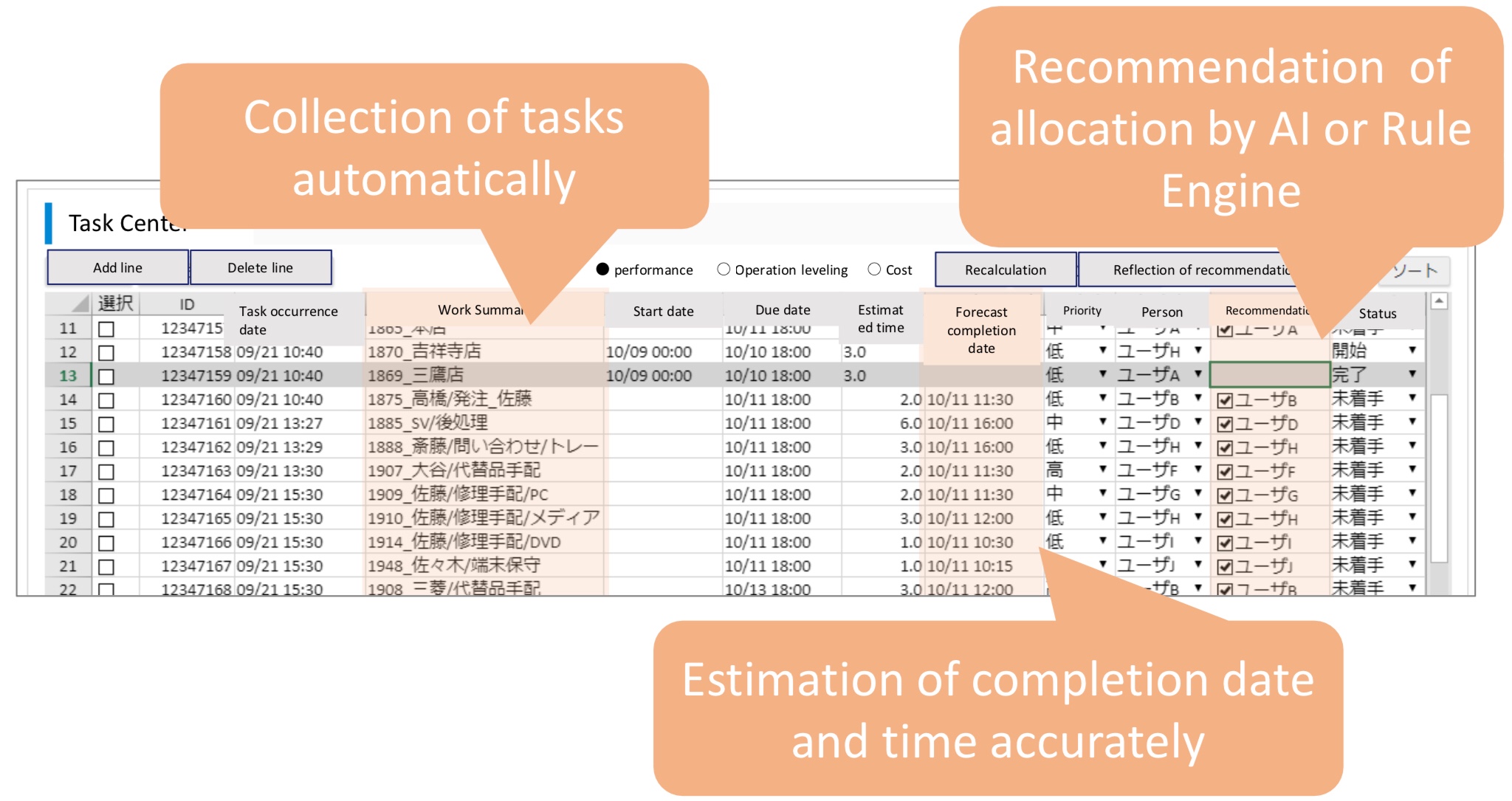
Business innovation of BPO realized by Task Center and AI and Rule Engine. Yoshihito Nakayama, NTT DATA INTRAMART
Yoshihito Nakayama presented on the current challenges of BPO with respect to improving productivity, and how they are resolving this using AI and a rules engine to aggregate and assign human tasks from multiple systems to different team members. This removes the requirement to manually review and assign work, and also provides a dashboard for visualizing work in progress and future forecasts.
AI is used to predict and optimize task classification and assignment, based on time required to complete the task and the individual worker skill level and productivity. It is also used to predict workload for task types and individual workers.
Their visualization dashboard shows drilldowns on current and past productivity, plus future forecasts. The simulation models for forecasting can be fine-tuned to optimize for cost, performance and other factors. It brings together work monitoring from all systems, including RPA processes. They’re also using process mining on a variety of systems to create a digital twin of the organization for better tracking and predictions, as well as other tools such as voice and image identification to recognize what tasks are being done that are not being recorded in any system logs.
They have a variety of case studies across industries, looking at automating non-routine work using case management, BPM, RPA, AI and rules.
Spaghetti Spreadsheets Untangled – Benefits of decision modeling when uncovering complex business logic hidden in spreadsheets. Charlotte Bouvy, M.C. Bouvy Consultancy
Charlotte Bouvy presented on her work done with SVB, the Netherlands social insurance administrator, on implementing business rules management. They are using DMN-based wizards for supporting 1,500 case workers, and the specific case was around the operational control and audit departments and the “lawfulness” of how the assessment work is done. Excel spreadsheets were used to do this, which had obvious problems in terms of being error prone and lacking domain-specific business logic. They implemented their SARA system to replace the spreadsheets with Oracle OPA, which allowed them to more accurately represent knowledge, as well as separate the data from the decision model while creating an executable model.
These type of audit processes require sampling over a wide variety of case files to compare actual payments against expected amounts, with some degree of aggregation within specific laws being applied. Moving to a rules engine allowed them to model calculations and decisions, and separate data and model to avoid errors that occurred when copying and pasting data in spreadsheets. The executable model is now a single source of truth to which version control and change management can be applied. They are trying out different ways of using the SARA system: directly in Oracle Policy Modeler for building and debugging; via a web interview and an RPA robot for data input; and eventually via direct integration with the SVB’s case management system to load data.
To finish up my time at the academic research BPM 2019 conference, I attended one of the industry forum sessions, which highlights initiatives that bring together academic research and practical applications in industry. These are shorter presentations than the research sessions, although still have formal published papers documenting their research and findings; check those proceedings for the full author list for each paper and the details of the research.
Process Improvement Benefits Realization: Insights from an Australian University. Wasana Bandara, QUT
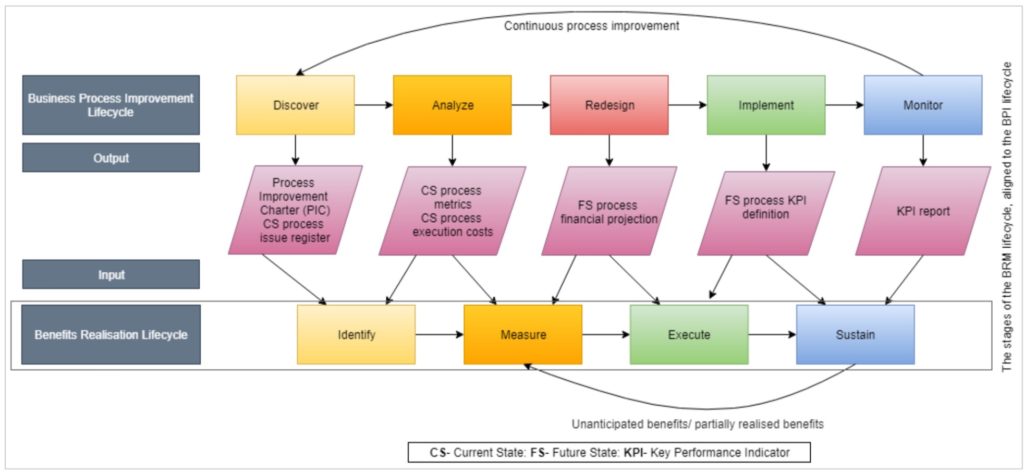
The first presentation was about process improvement at the author’s university. They took on an enterprise business process improvement project in 2017, and have developed a Business Process Improvement Office (BPIO — aka centre of excellence). They wanted to be able to have measurable benefits, and created a benefits realization framework that ran in parallel with their process improvement lifecycle to have the idea and measurement of benefits built in from the beginning of any project.
They found that identifying and aligning the ideas of benefits realization early in a project created awareness and increased receptiveness to unexpected benefits. Good discussion following on the details of their framework and how it impacts the business areas as they move their manual processes to more automation and management.
Enabling Process Mining in Aircraft Manufacture: Extracting Event Logs and Discovering Processes from Complex Data. Maria Teresa Gómez López, Universidad de Sevilla
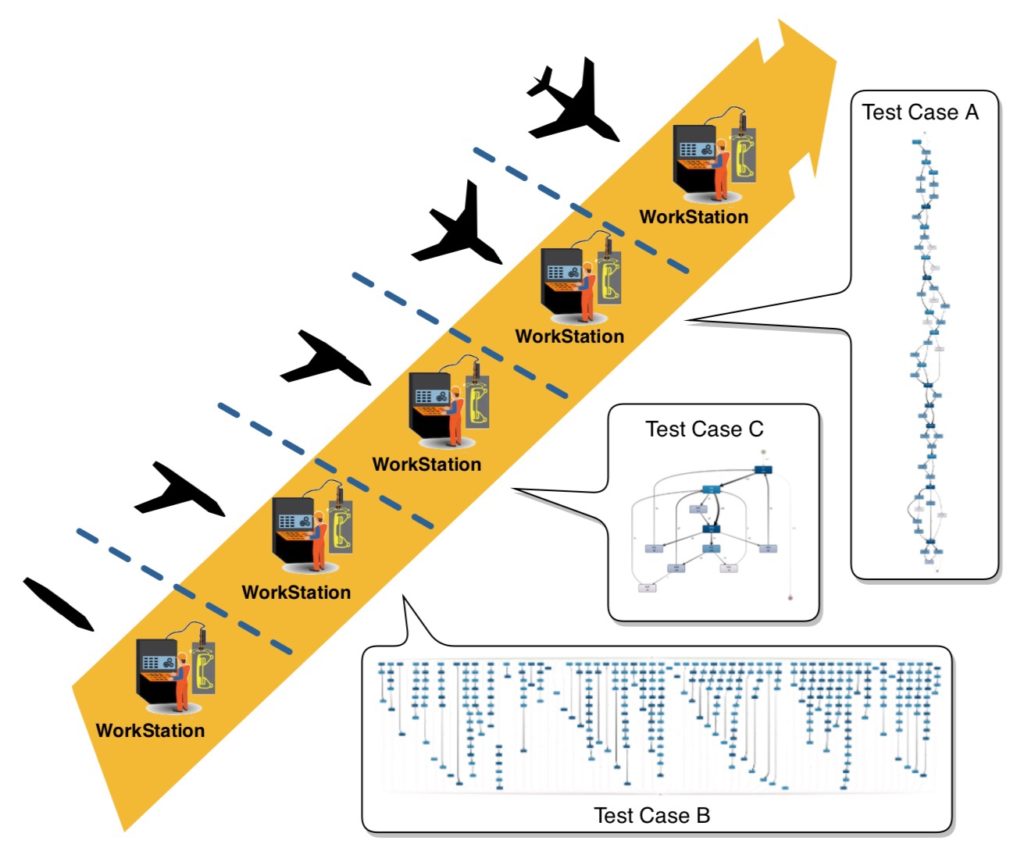
The second presentation was about using process mining to discover the processes used in aircraft manufacture. The data underlying the process mining is generated by IoT manufacturing devices, hence had much higher volumes than a usual business process mining application, requiring preprocessing to aggregate the raw log data into events suitable for process mining. They also wanted to be able to integrate knowledge from engineers involved in the manufacturing process to capture best practices and help extract the right data from the raw data logs.
They had some issues with analyzing the log data, such as incorrect data (an aircraft was in two stations at the same time, or was moving backwards through the assembly process), incomplete or insufficient information. Future research and work on this will include potential integration with big data architectures to handle the volume of raw log data, and and finding new ways of analyzing the log data to have cleaner input to the process discovery algorithms.
The adoption of globally unified process standards via a multilingual management system The case of Marabu, a worldwide manufacturer of printing inks and creative colours of the highest quality. Klaus Cee, Marabu, and Andreas Schachermeier, ConSense
The next presentation was about how Marabu, a printing ink company, standardized and aligned their multinational subsidiaries’ business processes with the parent company. This was not a research project per se, although ConSense is a spinoff consulting company from a university project several years ago, but a process and knowledge management implementation project. They had some particular challenges with developing uniform multi-lingual processes that could have local variants, integrated with needs of quality, environmental and occupational safety management.
Data-driven Deep Learning for Proactive Terminal Process Management. Andreas Metzger, University of Duisburg-Essen
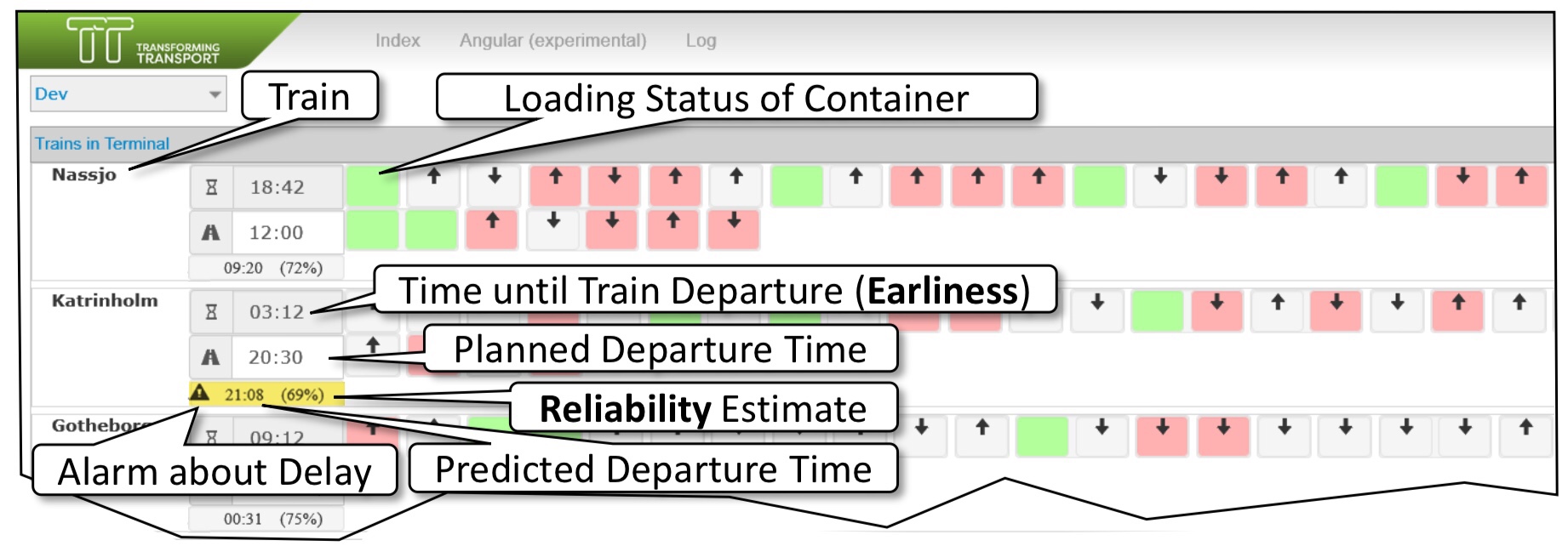
The final paper in this industry forum session was on the digitalization of the Duisberg intermodal container shipping port, a large inland port dealing with about 10,000 containers arriving and departing by rail and truck each month. Data streams from terminal equipment captured information about the movement of containers, cranes and trains; their goal was to predict based on current state whether a given train would be loaded and could depart on time, and proactively dispatch resources to speed up loading when necessary. This sounds like a straightforward problem, but the data collected can lead to erroneous results: waiting for more data to be collected can lead to more accurate predictions, but earlier intervention can resolve the problem faster.
They applied multiple parallel deep learning models (recurrent neural networks) to improve the predictions, dynamically trading off between accuracy and earliness of detection. They were able to increase the number of trains leaving on time by 4.7%, which is a great result when you consider the cost of a delayed train.
They used RNNs as their deep learning models because they can handle arbitrary length process instances without sequence or trace encoding, and can perform predictions at any checkpoint with a single model; there’s a long training time and it’s compute-intensive, but that pays off in this scenario. Lessons that they learned included the fact that the deep learning ensembles worked well out of the box, but also that the quality of the data used as input is a key concern for accuracy: if you’re going to spend time working on something, work on data cleansing before you work on the deep learning algorithms.
The Zaha Hadid-designed Library and Learning Center at UW Wien, our home for the main conference
The last segment following this is a closing panel, so this is the last of my coverage from BPM 2019. I haven’t attended this conference in many years, and I’m glad to be back. Looking forward to next year in Seville!
It’s been great to catch up with a lot of people who I haven’t seen since the last time that I attended, plus a few who I see more often. UW Wien has been a welcoming host as well as having a campus full of extraordinary modern architecture, with a well-organized conference and great evening social events.
With the workshops finished yesterday, we kicked off the main BPM 2019 program with a welcome from co-organizers Jan Mendling and Stefanie Rinderle-Ma, and greetings from the steering committee chair Mathias Weske. We heard briefly about next year’s conference in Sevilla, and 2021 in Rome — I’m already looking forward to both of those — then remarks from WU Rectorate (and Vice-Rector Digitalization) Tatjana Oppitz on the importance of BPM in transforming businesses. This is the largest year for this academic/research BPM conference, with more than 400 submissions and almost 500 attendees from 50 countries, an obvious indication of interest in this field. Also great to see so many BPM vendors participating as sponsors and in the industry track, since I’m an obvious proponent of two-way collaboration between academia and practitioners.
Kalle Lyytinen at BPM 2019 keynote
The main keynote speaker was Kalle Lyytinen of Case Western Reserve University, discussing digitalization and BPM. He showed some of the changes in business due to process improvement and design (including the externalization of processes to third parties), and the impacts of digitalization, that is, deeply embedding digital data and rules into organizational context. He went through some history of process management and BPM, with the goals focused on maximizing use of resources and optimization of processes. He also covered some of the behavioral and economic views of business routines/processes in terms of organizational responses to stimuli, and a great analogy (to paraphrase slightly) that pre-defined processes are like maps, while the performance of those processes forms the actual landscape. This results in two different types of approaches for organized activity: the computational metaphor of BPM, and the social/biological metaphor of constantly-evolving routines.
Lyytinen’s research conclusions regarding the impact of digital intensity
He defined digital intensity as the degree to which digitalization is required to perform a task, and considered how changes in digital intensity impact routines: in other words, how is technology changing the way we do things on a micro level? Lyytinen specializes in part on the process of designing systems (since my degree is in Systems Design Engineering, I find this fascinating), and showed some examples of chip design processes and how they changed based on the tools used.
He discussed a research study and paper that he and others had performed looking at the implementation of an SAP financial system in NASA. Their conclusion is that routines — that is, the things that people do within organizations to get their work done — adapted dynamically to adjust to the introduction of the IT-imposed processes. Digitalization initially increases variation in routines, but then the changes decrease over time, perhaps as people become accustomed to the new way of doing things and start using the digital tools. He sees automation and workflow efficiency as an element of a broader business model change, and transformation of routines as complementary to but not a substitute for business model change.
The design of business systems and models needs to consider both the processes provided by digitalization (BPM) and the interactions with those digital processes that are made up by the routines that people perform.
There was a question — or more of a comment — from Wil van der Aalst (the godfather of process mining) on whether Lyytinen’s view of BPM is based on the primarily pre-defined BPM of 20 years ago, and if process mining and more flexible process management tools are a closer match to the routines performed by people. In other words, we have analytical techniques that can then identify and codify processes that are closer to the routines. In my opinion, we don’t always have the ability to easily change our processes unless they are in a BPM or similar system; Lyytinen’s SAP at NASA case study, for example, was very unlikely to have very flexible processes. However, van der Aalst’s point about how we now have more flexible ways of digitally managing processes is definitely having an impact in encoding routines rather than forcing the change of routines to adapt to digital processes.
There was also a good discussion on digital intensity sparked by a question from Michael Rosemann, and how although we might not all become Amazon-like in the digital transformation of our businesses, there are definitely now activities in many businesses that just can’t be done by humans. This represents a much different level of digital intensity from many of our organizational digital process, which are just automated versions of human routines.
BPM, Serverless and Microservices: Innovative Scaling on the Cloud with Philippe Laumay and Thomas Bouffard of Bonitasoft
Turns out that my microservices talk this morning was a good lead-in to a few different presentations: Bonitasoft has moved to a serverless microservices architecture, and the pros and cons of this approach. Their key reason was scalability, especially where platform load is unpredictable. The demo showed an example of starting a new case (process instance) in a monolithic model under no load conditions, then the same with a simulated load, where the user response in the new case was significantly degraded. They then demoed the same scenario but scaling the BPM engine by deploying it multiple times in componentized “pods” in Kubernetes, where Kubernetes can automatically scale up further as load increases. This time, the user experience on the loaded system was considerably faster. This isn’t a pure microservices approach in that they are scaling a common BPM engine (hence a shared database even if there are multiple process servers), not embedding the engine within the microservices, but it does allow for easy scaling of the shared server platform. This requires cluster management for communicating between the pods and keeping state in sync. The final step of the demo was to externalize the execution completely to AWS Lambda by creating a BPM Lambda function for a serverless execution.
Performance Management for Robots, with Mark McGregor and Alessandro Manzi of Signavio
Just like human performers, robots in an RPA scenario need to have their performance monitored and managed: they need the right skills and training, and if they aren’t performing as expected, they should be replaced. Signavio does this by using their Process Intelligence (process mining) to discover potential bottleneck tasks to apply RPA and create a baseline for the pre-RPA processes. By identifying tasks that could be automated using robots, Alessandro demonstrated how they could simulate scenarios with and without robots that include cost and time. All of the simulation results can be exported as an Excel sheet for further visualization and analysis, although their dashboard tools provide a good view of the results. Once robots have been deployed, they can use process mining again to compare against the earlier analysis results as well as seeing the performance trends. In the demo, we saw that the robots at different tasks (potentially from different vendors) could have different performance results, with some requiring either replacement, upgrading or removal. He finished with a demo of their “Lights-On” view that combines process modeling and mining, where traffic lights linked to the mining performance analysis are displayed in place in the model in order to make changes more easily.
The Case of the Intentional Process, with Paul Holmes-Higgin and Micha Kiener of Flowable
The last demo of the day was Flowable showing how they combined trigger, sentry, declarative and stage concepts from CMMN with microprocesses (process fragments) to contain chatbot processes. Essentially, they’re using a CMMN case folder and stages as intelligent containers for small chatbot processes; this allows, for example, separation and coordination of multiple chatbot roles when dealing with a multi-product client such as a banking client that does both business banking and personal investments with the bank. The chat needs to switch context in order to provide the required separation of information between business and personal accounts. “Intents” as identified by the chatbot AI are handled as inbound signals to the CMMN stages, firing off the associated process fragment for the correct chatbot role. The process fragment can then drive the chatbot to walk the client through a process for the requested service, such as KYC and signing a waiver for onboarding with a new investment category, in a context-sensitive manner that is aware of the customer scenario and what has happened already. The chatbot processes can even hand the chat over to a human financial advisor or other customer support person, who would see the chat history and be able to continue the conversation in a manner that is seamless to the client. The digital assistant is still there for the advisor, and can detect their intentions and privately offer to kick off processes for them, such as preparing a proposal for the client, or prevent messages that may violate privacy or regulatory compliance. The advisor’s task list contains tasks that may be the result of conversations such as this, but will also include internally created and assigned tasks. The advisor can also provide a QR code to the client via chat that will link to a WhatsApp (or other messaging platform) version of the conversation: less capable than the full Flowable chat interface since it’s limited to text, but preferred by some clients. If the client changes context, in this case switching from private banking questions to a business banking request, the chatbot an switch seamlessly to responding to that request, although the advisor’s view would show separate private and business banking cases for regulatory reasons. Watch the video when it comes out for a great discussion at the end on using CMMN stages in combination with BPMN for reacting to events and context switching. It appears that chatbots have officially moved from “toy” to “useful”, and CMMN just got real.
Is the Citizen Developer Story a Fairytale? by Neil Miller of Kissflow
Given that Kissflow provides a low-code BPM platform, Neil’s answer is that citizen developers are not, in fact, unicorns: given the right tools, non-developers can build their own applications. Their platform allows a citizen developer to create a process-based application by defining a form, then a related process using a flowchart notation. Forms can link to internally-defined (or imported) data sources, and process steps can include links to webhooks to access external services. Simple but reasonably powerful capabilities, easy enough for non-technical analysts and business users to create and deploy single-form applications for their own use and to share with others. He also showed us the new version that is being released next month with a number of new features and tools, including more powerful integration capabilities that are still well within the reach of citizen developers. The new version also includes completely new functionality for unstructured collaborative scenarios, which can include conversation streams and tasks, plus Kanban boards for managing projects and tasks. There’s still a lot missing for this to handle any type of core processes (e.g., versioning, testing) but good for administrative, situational and collaboration processes.
Insightful Process Analysis, by Jude Chagas-Pereira of Wizly, Frank Kowalkowski of Knowledge Consultants, Inc., and Gil Laware of Information by Design
Wizly provides a suite of analysis tools including process analytics, using process mining and other techniques in demo focused on improving an airline’s call center performance. Jude showed how they can compare process history data against a pre-defined model for conformance checking, and a broad range of analysis techniques to discover correlations between activities and customer satisfaction. They can also generate a “DNA analysis” and other data visualizations, then filter and re-slice the data to hone in on the problems. The main tabular interface is similar to Excel-type filtering and pivot charts, so understandable to most business data analysts, with visualizations and extra analytical tools to drive out root causes. This set of process analytics is just part of their suite: they can apply the same tools to other areas such as master data management. We had a previous look at this last year under the name Aftespyre: Frank pointed out that he and Gil develop the intellectual property of the analytical models, while Jude’s company does the tool implementation.
Improving the Execution of Work with an AI Driven Automation Platform, by Kramer Reeves, Michael Lim and Jeff Goodhue of IBM
Jeff took us through a demo of their Business Automation Workflow Case Builder, which is a citizen developer tool for creating case and content-centric applications that can include processes, decisions and services created by technical developers layered on a simpler milestone-based flow. Checklists are built in as a task management and assignment, allowing a business user to create an ad hoc checklist and assign tasks to other users at any point in the case. We also saw the process task interface with an attended RPA bot invoked by the user as a helper to open the task, extract related data from a legacy interface, then update and dispatch the task . Alongside the process task interface, he showed us using a conversational interface to their Watson AI to ask what type of accounts that the client has, and what documents that they have for the client. We also saw the integration of AI into a dashboard to make decision recommendations based on historical data. He finished with their new Business Automation Studio low-code design environment, where we saw how the citizen developer can add integrations that were created by technical developers, and create new pages in a page flow application. It’s taken a long time for IBM to bring together their entire automation platform based on a number of past acquisitions, but now they appear to have a fairly seamless integration between case/content and process (BPM) applications, with low code and Watson sprinkled in for good measure. They’re also trying to move away from their monolithic pricing models to a microservices pricing model, even though their platforms are pretty monolithic in structure: Mike made the point that customers only pay for what they use.
That’s it for day 1 of bpmNEXT 2019; tomorrow morning I’ll be giving a keynote before we start back into demo rounds.
Democratizing Machine Learning with BPM, by Scott Menter and Joby O’Brien of BP Logix
We’re now into the full demo sessions at bpmNEXT, and Scott and Joby are up to talk about they’re making machine learning more accessible to non-data scientists and integrating it into their BPM tool, Process Director. They do this by creating a learner object that pulls in data from an external source, then configure the system to select the predicted data field, the algorithm to use and the input data feature to use for prediction. Their example is whether an employee is at risk for leaving the company (possibly a gentle dig at a bigger company making the same sort of predictions), so select one or more input values from the employee data set such as amount of travel and income. They have some nice visualization tools to use while building the learner object, selecting a couple of input features to see which may be the most interesting in the prediction, then can create the learner object so that it can update forms as data is entered, such as during a performance review. This now allows the output from a fairly sophisticated ML object that is analyzing past data to be used just like any other rule or data source in their BPMS. In general, their tools can be used by someone who knows about data scientists to create learner objects for other people to consume in their processes, but can also be used for those without a lot of data science knowledge to create simple but powerful machine learning predictions on their own.
Leveraging Process Mining to Enable Human and Robot Collaboration, by Michal Rosik of Minit
Michal started with the analysis of an invoice approval process as seen through their process mining tool, but the point of his demo was to perform data mining on UI session recording data, that is, the data collected when a recorder is monitoring a person’s activities to figure out exactly the steps they are taking to perform a task. Unlike a strict RPA training/scripting session, this can use data from users just doing their day-to-day work, filter out the activities that aren’t related to the task, and create a definition of the best RPA path. Or, it can use data from the process when RPA is performing the tasks to see where there are potential problems within the bot’s actions or if the existence of the bot is causing bottlenecks to be shifted to other parts of the process. It can use process variant analysis to look at the differences between the process pre- and post-bot implementation. He also showed their Minit dashboard, being released now, which combines process mining and business intelligence to see a much more predictive environment for business managers.
Process Mining and DTO — How to Derive Business Rules and ROI from the Data, with Massimiliano Delsante and Luca Fontanili of Cognitive Technology
DTO – the digital twin of an organization – is the focus of Massimiliano and Luca’s presentation, and how to get from process mining to DTO for analyzing and governing processes in their myInvenio tool. From their process mining model, they can show a number of visualizations: non-conformant cases within the process, manual steps (not yet automated, showing potential for improvement), steps that are in violation of their SLA, and a dashboard combining activity cost and other performance data with the process mining model. They demonstrated how a reference model would be created using BPMN and DMN to allow conformance checking and simulation, or derive the BPMN model – including branching rules – directly from the discovered process model. They’re using machine learning to discover the correlation from which the branching conditions are determined, but the business user/analyst can override the discovered branching rules to define more precise decision rules and decision tables. This “decision mining” is a unique capability in the process mining world (for now). The analyst can also add manual steps to the discovered process model in BPMN mode, which will update the related analytics and visualizations. Their simulation allows each step to not just be simulated as it is currently, but by specifying potential robot replacements of some of the human operators at an activity, comparing the different scenarios.
As a comment on the latter two process mining sessions, I’m really happy to see process mining moving from a purely post-execution analytical tool to an interactive process health check and prediction tool. I’ve done some presentations in the past in which I suggested that process mining would be a great tool for forward-looking simulations and what-if scenarios, and there’s so much more than can be done in this area.
Except for a hiatus in 2017, I’ve been at every bpmNEXT since its inception in 2013, created and hosted by Bruce Silver and Nathaniel Palmer as a showcase for new ideas in BPM and related technologies. This is not a conference for (potential) customers, but a place for vendors, researchers and analysts to come together to exchange ideas about what’s happening in the marketplace and the technology labs. Most of the agenda is made up of 30-minute demo sessions with a few panels and keynotes sprinkled in.
Nathaniel Palmer started our first day with a look forward at the next five years of BPM by considering the five-year span from 2015 to 2020 and how his predictions are playing out from his first predictions keynote. In 2015, he talked about intelligent automation; today, we’re seeing robots and rules-based automation as an integral part of how business is done. This is pretty crucial, because the average number of systems required to present a complete view of a customer is 13.2 (!), 8 of which are external, with 80% of firms stating that they use more than 10 systems to get that a 360 degree view. He talks about the need for an intelligent automation platform that includes robotic automation, AI and machine learning, decision management, and process management, communicating with events and data via an event gateway/bus. He believes that the role of a BPMS is also to provide the framework for development and to build the user interface – an idea that I’ll be debating somewhat in my keynote tomorrow – but sees always-on, context-driven devices such as smart speakers as the future of how we interact with systems rather than traditional computers and smartphones. That means that conversational interaction will take over from worklist metaphors for common processes for consumers and employees; my interpretation of this is that the task-focused activities are those that will be automated, leaving the more fluid activities for people to deal with.
A consideration of this changing nature of automation is how to model this. Our traditional workflows have a pre-defined path, whereas intelligent automation (with more of a case management/ad hoc paradigm) has more adaptable processes driven by rules and business context. It’s more like using Waze for dynamically-adjusted driving directions rather than a pre-conceived idea of what route to follow. The danger with this – in my experience with Waze and adaptable business processes – is that you could end up on a route that is not generally followed, messes up the people who have to get involved along the route, and definitely isn’t repeatable or scalable: better for that specific instance and its participants, but possibly detrimental to others. The potential gain is, of course, that the process as a whole is more resilient because it responds to events by determining an action that will reach the goal, and you may just find a new and better way of doing something. Respond to events, definitely, but at some point take a step back and consider the impact of the new pathways that you’re carving out.
He spoke about problems with AI/ML and training data biases – robots are only as smart as your training data – and highlighted that BPM platforms are a great source of training data via process mining.and analysis.
Insightful as always, and it will be interesting to see these themes play out in the demos over the next three days.
We’re in the home stretch here at bpmNEXT 2018, day 3 has only a couple of shorter demo sessions and a few related talks before we break early to head home.
When Artificial Intelligence meets Process-Based Applications, Bonitasoft
Nicolas Chabanoles and Nathalie Cotte from Bonitasoft presented on their integration of AI with process applications, specifically for predictive analytics for automating decisions and making recommendations. They use an extension of process mining to examine case data and activity times in order to predict, for example, if a specific case will finish on time; in the future, they hope to be able to accurately predict the end time for individual cases for better feedback to internal users and customers. The demo was a loan origination application built on Bonita BPM, which was fairly standard, with the process mining and machine learning coming in with how the processes are monitored. Log data is polled from the BPM system into an elastic search database, then machine learning is applied to instance data; configuration of the machine learning is based (at this point) only on the specification of an expected completion time for each instance type to build the predictions model. At that point, predictions can be made for in-flight instances as to whether each one will complete on time, or its probability of completing on time for those predicted to be late — for example, if key documents are missing, or the loan officer is not responding quickly enough to review requests. The loan officer is shown what tasks are likely to be causing the late prediction, and completing those tasks will change the prediction for that case. Priority for cases can be set dynamically based on the prediction, so that cases more likely to be late are set to higher priority in order to be worked earlier. Future plans are to include more business data and human resource data, which could be used to explicitly assign late cases to individual users. The use of process mining algorithms, rather than simpler prediction techniques, will allow suggestions on state transitions (i.e., which path to take) in addition to just setting instance priority.
Understanding Your Models and What They Are Trying To Tell You, KnowProcess
Tim Stephenson of KnowProcess spoke about models and standards, particularly applied to their main use case of marketing automation and customer onboarding. Their ModelMinder application ingests BPMN, CMMN and DMN models, and can be used to search the models for activities, resources and other model components, as well as identify and understand extensions such as calling a REST service from a BPMN service task. The demo showed a KnowProcess repository initially through the search interface; searching for “loan” or “send memo” returned links to models with those terms; the model (process, case or decision) can be displayed directly in their viewer with the location of the search term highlighted. The repository can be stored as files or an engine can be directly indexed. He also showed an interface to Slack that uses a model-minder bot that can handle natural language requests for certain model types and content such as which resources do the work as specified in the models or those that call a specific subprocess, providing a link directly back to the models in the KnowProcess repository. Finishing up the demo, he showed how the model search and reuse is attached to a CRM application, so that a marketing person sees the models as functions that can be executed directly within their environment.
Instead of a third demo, we had a more free-ranging discussion that had started yesterday during one of the Q&As about a standardized modeling language for RPA, led by Max Young from Capital BPM and with contributions of a number of others in the audience (including me). Good starting point but there’s obviously still a lot of work to do in this direction, starting with getting some of the major RPA vendors on board with standardization efforts. The emerging ideas seem to center around defining a grammar for the activities that occur in RPA (e.g., extract data from an Excel file, write data to a certain location in an application screen), then an event and flow language to piece together those primitives that might look something like BPMN or CMMN. I see this as similar to the issue of defining page flows, which are often done as a black box function that is performed within a human activity in a BPMN flow: exposing and standardizing that black box is what we’re talking about. This discussion is a prime example of what makes bpmNEXT great, and keeps me coming back year after year.
We’re into the afternoon of day 2 of bpmNEXT 2018, with another demo section.
RPA Enablement: Focus on Long-Term Value and Continuous Process Improvement, Cognitive Technology
Massimiliano Delsante of Cognitive Technology presented their myInvenio product for analyzing processes to determine where gaps exist and create models for closing those gaps through RPA task automation. The demo started with loading historical process data for process mining, which created a process model from the data together with activity resources, counts and other metrics; then comparing the model for conformance with a reference model to determine the frequency and performance of conformant and non-conformant cases. The process discovery model can be transformed to a BPMN model, and simulated performance. With a baseline data set of all manual activities, the system identified the cost of each activity, helping to identify which activities would result in the greatest savings if automated, and fed the data for actual resources used into the simulation scenario; adjusting the resources required by specifying the number of RPA robots that could be deployed at specific tasks allows for a what-if simulation for the process performance with an RPA implementation. An analytics dashboard provides visualization of the original process discovery and the simulated changes, with performance trends over time. Predictive analytics can be applied to running processes to, for example, predict which cases will not meet their deadlines, and some root cause analysis for the problems. Doing this analysis requires that you have information about the cost of the RPA robots as well as being able to identify which tasks could be automated with RPA. Good integration of process discovery, simulation, analysis and ongoing monitoring.
Integration is Still Cool, and Core in your BPM Strategy, PMG.net
Ben Alexander from PMG.net focused on integration within BPM as a key element for driving innovation by increasing the speed of application development: integrating services for RPA, ML, AI, IoT, blockchain, chatbots and whatever other hot new technologies can be brought together in a low-code environment such as PMG. His demo showed a vendor onboarding application, adding a function/subprocess for assessing probability of vendor approval using machine learning by calling AzureML, user task assignment using Slack integration or SMS/phone support through a Twilio connector, and RPA bot invocation using a generic REST API. Nice demo of how to put all of these third-party services together using a BPM platform as the main application development and orchestration engine.
Paul Holmes-Higgin and Micha Keiner from Flowable presented on their Engage product for customer engagement via chat, using chatbots to augment rather than replace human chat, and modeling the chatbot behavior using standard modeling tools. In particular, they have found that a conversation can be modeled as a case with dynamic injection of processes, with the ability to bring intelligence into conversations, and the added benefit of the chat being completely audited. The demo was around the use case of a high-wealth banking client talking to their relationship manager using chat, with simultaneous views of both the client and relationship manager UI in the Flowable Engage chat interface. The client mentioned that she moved to a new home, and the RM initiated the change address process by starting a new case right in the chat by invoking a context-sensitive digital assistant. This provided advice to the RM about address change regulatory rules, and provided a form in situ to collect the address data. The case is now progressed through a combination of chat message to collaborate between human players, forms filled directly in the chat window, and confirmation by the client via chat by presenting them with information to be updated. Potential issues, such as compliance regulations due to a country move, are raised to the RM, and related processes execute behind the scenes that include a compliance officer via a more standard task inbox interface. Once the compliance process completes, the RM is informed via the chat interface. Behind the scenes, there’s a standard address change BPMN diagram, where the chat interface is integrated through service activities. They also showed replacing the human compliance decision with a decision table that was created (and manually edited if necessary) based on a decision tree generated by machine learning on 200,000 historical address change cases; rerunning the scenario skipped the compliance officer step and approved the change instantaneously. Other chat automated tasks that the RM can invoke include setting reminders, retrieving customer information and more using natural language processing, as well as other types of more structured cases and processes. Great demo, and an excellent look at the future of chat interfaces in process and case management.