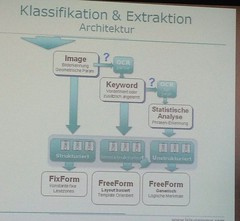
ISIS Papyrus defines (and implements) ACM as the full range (dare I say, a spectrum?) from straight through processes through dynamic processes to completely unstructured process driven by ad hoc content arrival such as email or social media. This, I believe, is at the heart of discussion/argument about BPM versus ACM: this definition has traditional structured BPM as a subset of ACM at the structured end, with ACM covering a much broader range of structure as well as being inherently content (document) centric, and including a number of additional capabilities such as goal orientation and business rules.
At the structured end, this can be fully automated service orchestration, driven by events or by (document) state: this can be modeled as a flow diagram, but the individual tasks are adorned with additional information about state and events that impact that task, such as a task firing when a document reaches a specific state.
At the unstructured end, this provides a collaborative case-oriented environment for a knowledge worker to manage a response to some sort of inbound content, including integrated correspondence management based on the core technology that we saw in detail yesterday.
In any type of application along the spectrum, but especially at the unstructured end, you can have access to social media channels (both inbound and outbound) as well as data from other systems and related documents. External events can impact the case, and business rules created in natural language can be applied to constrain or act upon the case. Tasks within cases are linked to goals, as defined in the business architecture; goals can be linked, and sub-goals defined for more structured dependencies. The system learns as more cases are processed relative to their goals, allowing for the next best action to be suggested to the user on a case based on the history of similar cases; this could, of course, be applied in an automated fashion rather than as a user suggestion, but this level of machine intelligence tends to make some organizations uncomfortable.
Although processes can be represented as flowchart-style models, they can also be represented as Gantt charts (or PERT charts, for that matter) to be able to visualize the critical path through the process and provide some predictions around due dates for various milestones. I’ve seen this representation from other vendors, most noticeably BP Logix, for whom I’m writing a white paper on predictive analytics and the importance of adding a time dimension/representation to processes.
There is a task-specific user interface for the details portion which must be customized for each task type, although the framework includes standard information such as a history of the case activity and resources. The task interfaces are developed using widgets, and a single UI definition can be deployed on any platform (including mobile) without customizing specifically for that platform. A mobile deployment environment is becoming critical in application development, as we saw last week at IBM Impact with their focus on using their Worklight acquisition for mobile development and deployment.
They’ve created the critical round trip between strategy and execution by connecting strategic objectives (in a strategy map) to business architecture (in a capability map) to process goals (balanced scorecard and other KPIs): not only is this top-down, where strategy defines capabilities, which in turn are used to define KPIs, but also feeding back so that the actual performance during execution is compared back to the architecture and strategy.
ISIS Papyrus stresses that ACM is just a capability of their content processing platform, and I think that this is part of the confusion around the definition of ACM: ACM is about how we do work, so requires a combination of activities, content, rules, user interface, and integration with external systems. However, there are a lot of application development environments that provide some or all of that without being defined as ACM, and more traditional BPM products are redefining themselves as ACM by adding some of these capabilities even if it’s not a good fit with their underlying infrastructure.
The ACM market is still emerging and will continue to evolve. Having some good examples of ACM in action through the ACM Awards (for which I’m one of the judges) will help with market understanding, but I anticipate many more discussions on this topic along the way.