The second half of the morning at ISIS Papyrus was a pair of sessions on document output and document input, or as the session titles put it, “unified print, web and mobile output management” and “scan to extract to process”. The first was a great deal more information on yesterday’s session on correspondence generation, and you can check out their website for more information on the features and functions.
The second session, on document capture, started with business drivers for capture and scanning, particularly the link from capture to process. A lot of organizations are doing capture to archive, but a smaller percentage are using recognition technologies (classification and extraction) or triggering processes from the documents. Interestingly, a much larger percentage are using document classification (i.e., what type of document is this) but not data extraction (i.e. what customer-specific information is on the document); there’s a big ROI just in document classification without additional recognition since that can be used to automatically route documents to the right department for handling.
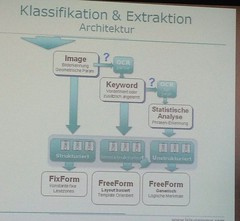 They handle a variety of input channels and devices: scanners (including check scanners), MFPs (“Mit Netzwerkanbindung”, according to the slides
They handle a variety of input channels and devices: scanners (including check scanners), MFPs (“Mit Netzwerkanbindung”, according to the slides ![]() ), fax, email, camera phones, social media and file import. I had a demo yesterday of their recognition and extraction capabilities, and it can be applied to both structured forms and freeform documents. A typical capture path includes steps for rearranging, splitting and merging (often for fax documents, over which there is less control on the input), then document classification, automated extraction and validation, then manual verification and correction. In this way, they provide the same functionality as products such as Kofax or IBM Datacap.
), fax, email, camera phones, social media and file import. I had a demo yesterday of their recognition and extraction capabilities, and it can be applied to both structured forms and freeform documents. A typical capture path includes steps for rearranging, splitting and merging (often for fax documents, over which there is less control on the input), then document classification, automated extraction and validation, then manual verification and correction. In this way, they provide the same functionality as products such as Kofax or IBM Datacap.
Document classification can be based on layout (fixed format), keyword (text or barcode) or text-based (phrases), and their capture design environment allows for learning by example to create any of these. 2D barcodes (which may have been generated by their outbound correspondence module) can be identified and used to match an inbound document to an existing case.
There are a number of administration and monitoring capabilities to track how many documents/batches have been captured and where they are in the processing queues.
They have a number of customers that are capture only – this, in addition to correspondence generation, are two of their key use cases – but provide greater added value if the capture process leads directly into distribution and case creation/management.