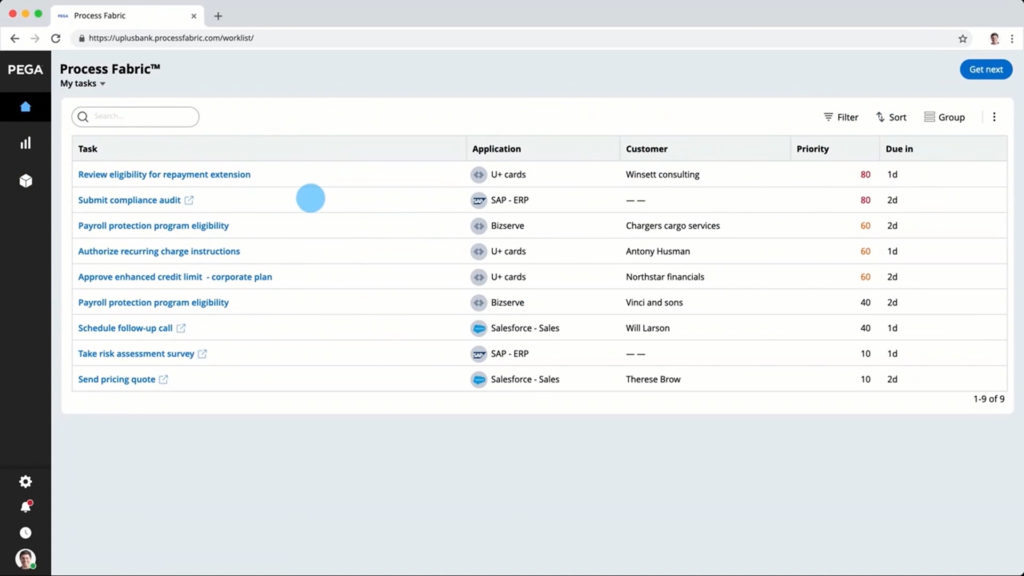
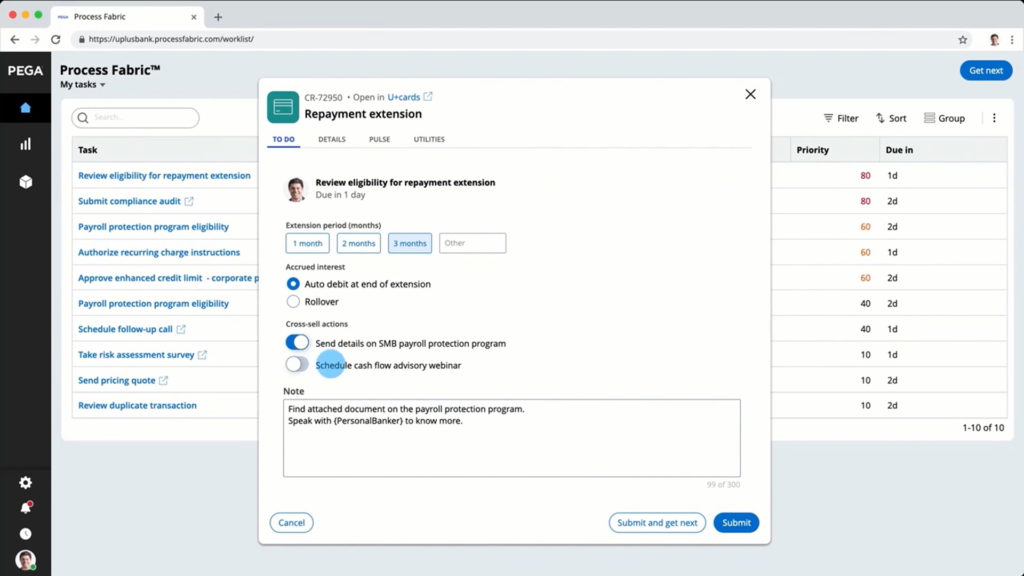
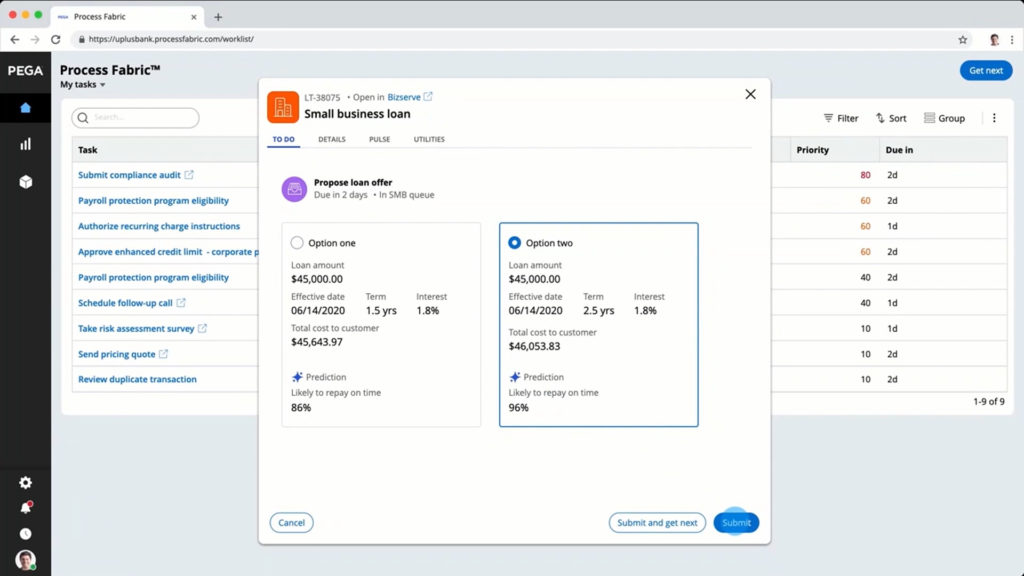
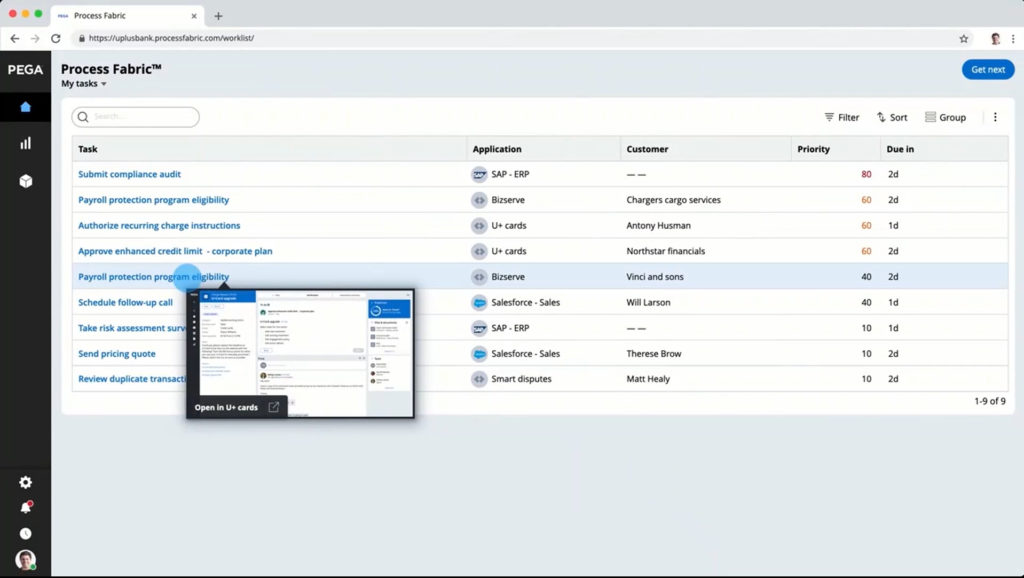
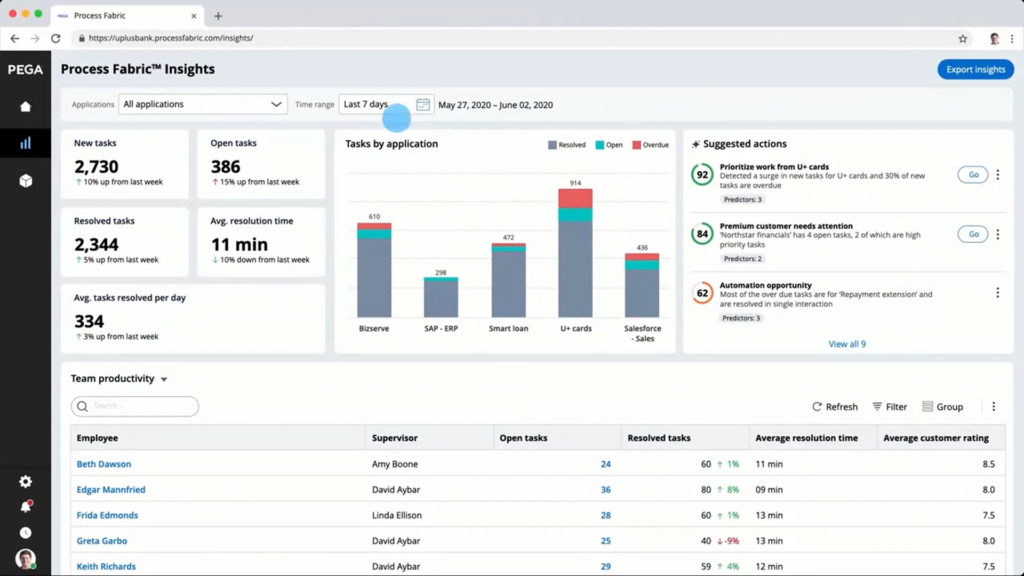
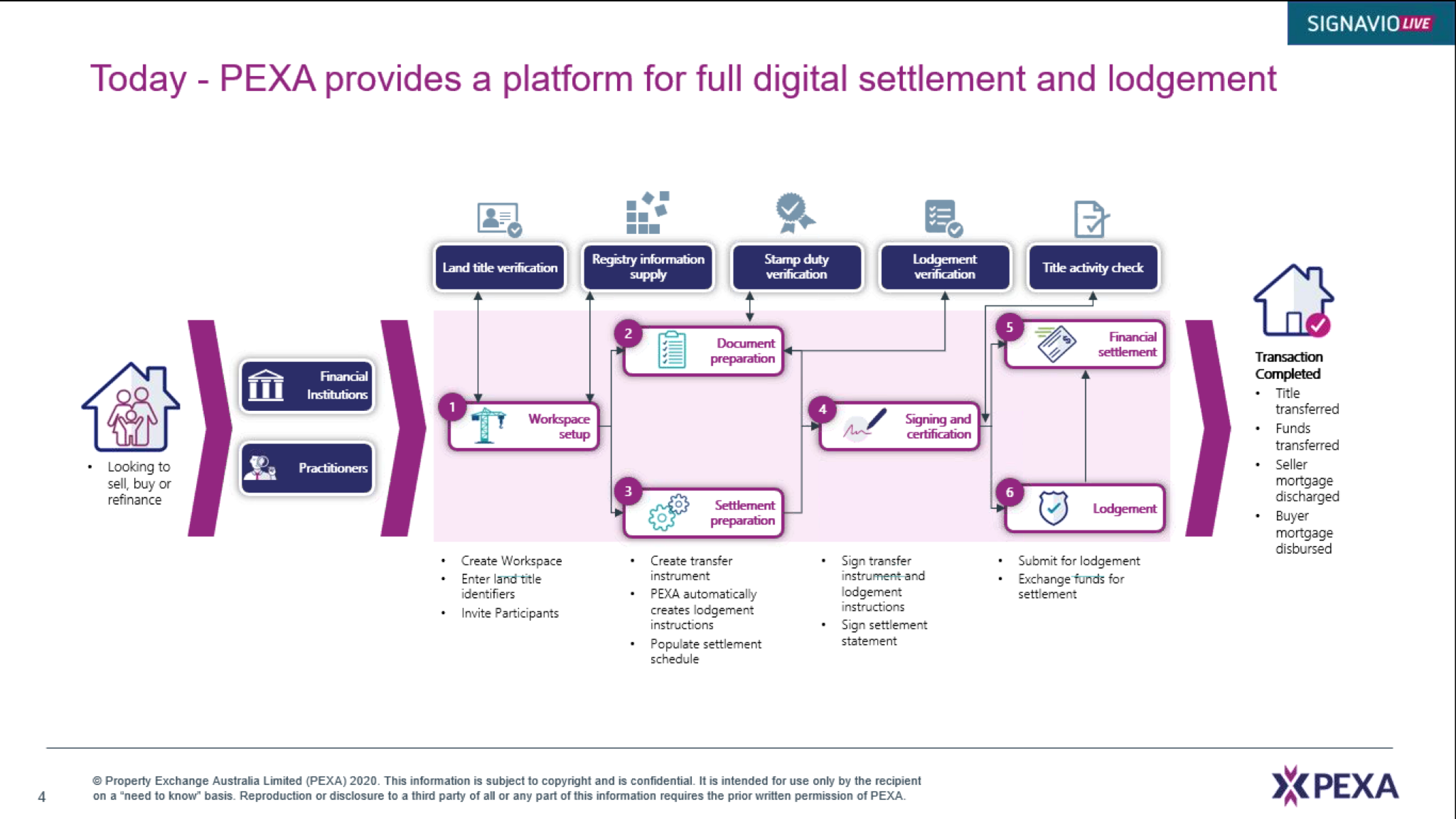
This week, I’m attending the virtual Bizagi Catalyst event, and I’ll be giving a short keynote and interactive discussion tomorrow. Today, the event kicked off with an address by CEO Gustavo Gomez on the impact of technology innovation, and the need for rapid response. This is a message that really resonates right now, as companies need to innovate and modernize, or they won’t make it through this current crisis. Supply chains are upside-down, workforces are disrupted, and this means that businesses need to change quickly to adapt. Gomez’ message was to examine your customer-facing processes in order to make them more responsive: eliminate unnecessary steps; postpone steps that don’t require customer interaction; and automate tasks. These three process design principles will improve your customer experience by reducing the time that they spend waiting while they are trying to complete a transaction, and will also improve the efficiency and accuracy of your processes.

He had the same message as I’ve had for several months: don’t stand still, but use this disruption to innovate. The success of companies is now based on their ability to change, not on their success at repetition: I’m paraphrasing a quote that he gave, and I can’t recall the original source although it’s likely Bill Drayton, who said “change begets change as much as repetition reinforces repetition”.

I unfortunately missed quite a bit of the following session, by Mata Veleta of insurance provider SCOR due to a glitchy broadcast platform. I did see the part of her presentation on how Bizagi supports them on their transformation journey, with a digitalization of a claims assessment application that was live in six weeks from design to go-live during the pandemic — very impressive. They are embracing the motto “think big, start small, move fast”, and making the agile approach a mindset across the business in addition to an application development principle. They’re building another new application for medical underwriting, and have many others under consideration now that they see how quickly they can roll things out.
The broadcast platform then fell over completely, and I missed the product roadmap session; I’m not sure if Bizagi should be happy that they had so many attendees that they broke the platform, or furious with the platform vendor for offering something that they couldn’t deliver. The “all-singing, all-dancing” platforms look nice when you see the demo, but they may not be scalable enough.
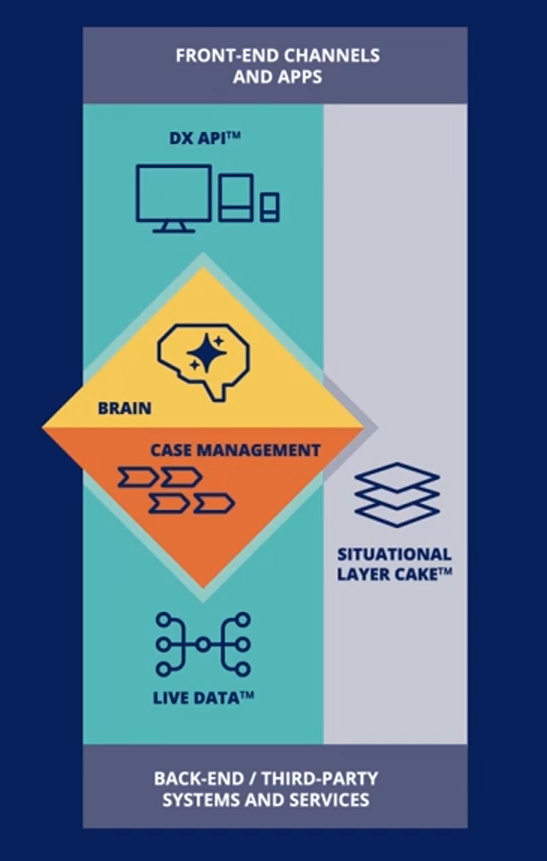
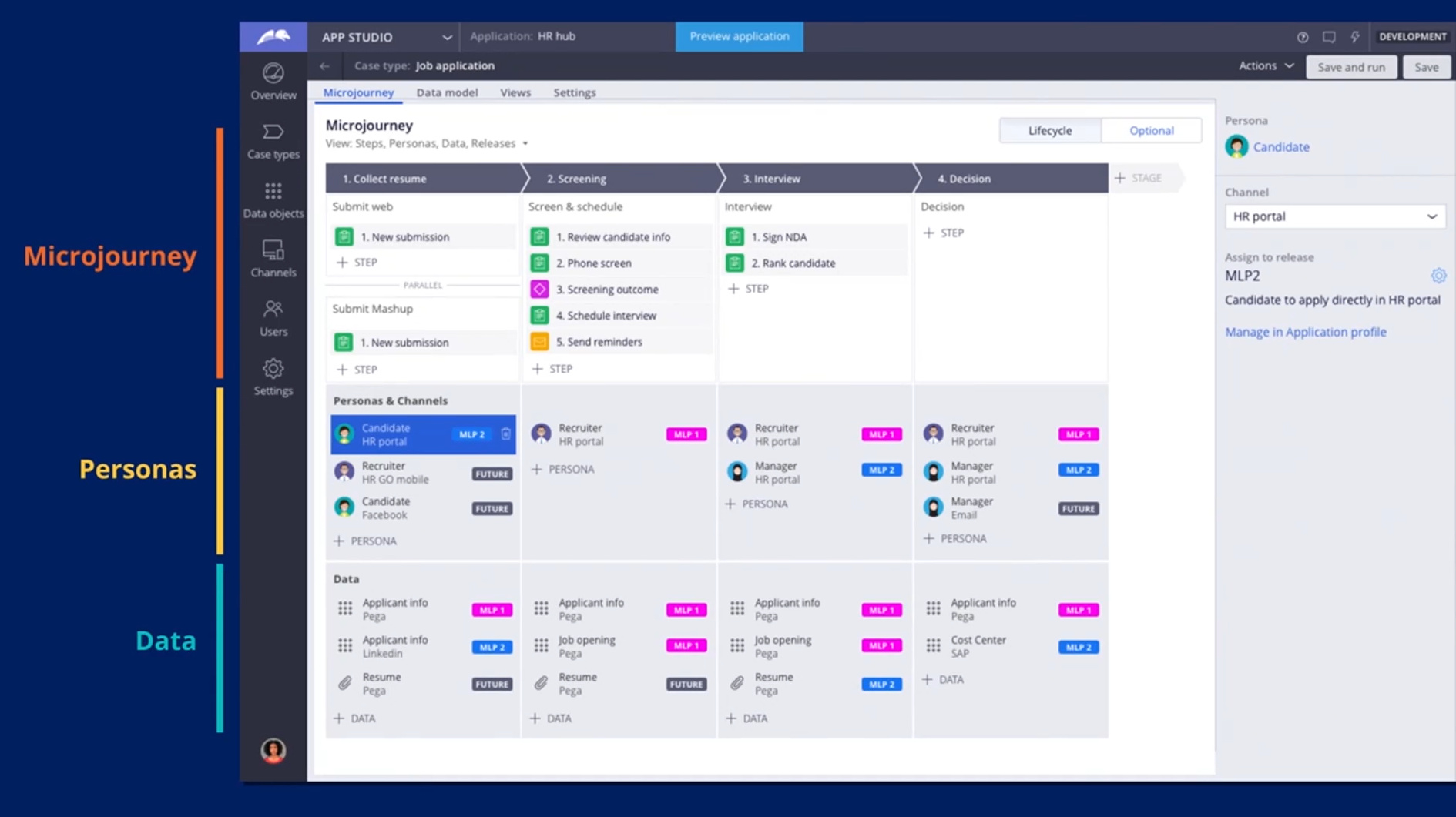
I went back later in the day and watched the roadmap session replay, with Ed Gower, VP Solutions Consulting, and Andrea Dominguez, Product Manager. Their roadmap has a few guiding themes: intelligent automation orchestration primarily through improved connectors to other automation components including RPA; governance to provide visibility into this orchestration; and a refreshed user experience on all devices. Successful low-code is really about what you can integrate with, so the focus on connectors isn’t a big surprise. They have a new connector with ABBYY for capture, which provides best-of-breed classification and extraction from documents. They also have a Microsoft Cognitive Services Connector for adding natural language processing to Bizagi applications, including features such as sentiment analysis. There are some new features coming up in the Bizagi Modeler (in December), including value stream visualizations.

The session by Tom Spolar and Tyler Rudkin of HSA Webster Bank was very good: a case study on how they use Bizagi for their low-code development requirements. They stated that they use another product for the heavy-duty integration applications, which means that Bizagi is used as true no/low-code as well as their collaborative BPMN modeling environment. They shared a lot of best practices, including what they do and don’t do with Bizagi: some types of projects are just considered a poor fit for the platform, which is a refreshing attitude when most organizations get locked into a Maslow’s hammer cognitive bias. They’ve had measurable results: several live deployments, the creation of reusable BPMN capabilities, and reduced case duration.

The final session of the day was a sneak peek at upcoming Bizagi capabilities with Kevin Guerrero, Technical Marketing Manager, and Francisco Rodriguez, Connectors Product Manager. Two of the four items that they covered were RPA-related, including integration with both UiPath and Automation Anywhere. As I saw at the CamundaCon conference last week, BPM vendors are realizing that integration with the mainstream RPA platforms is important for task automation/assistance, even if the RPA bots may eventually be replaced with APIs. Bizagi will be able to trigger UiPath attended bots on the user’s desktop, and start bots from the Bizagi Work Portal to exchange data. We saw a demo of how this is created in Bizagi Studio, including graphical mapping of input/output parameters with the bot, then what it looks like in the user runtime environment. They also discussed their upcoming integration with the cloud-based Automation Anywhere Enterprise A2019, calling cloud-based bots from Bizagi.
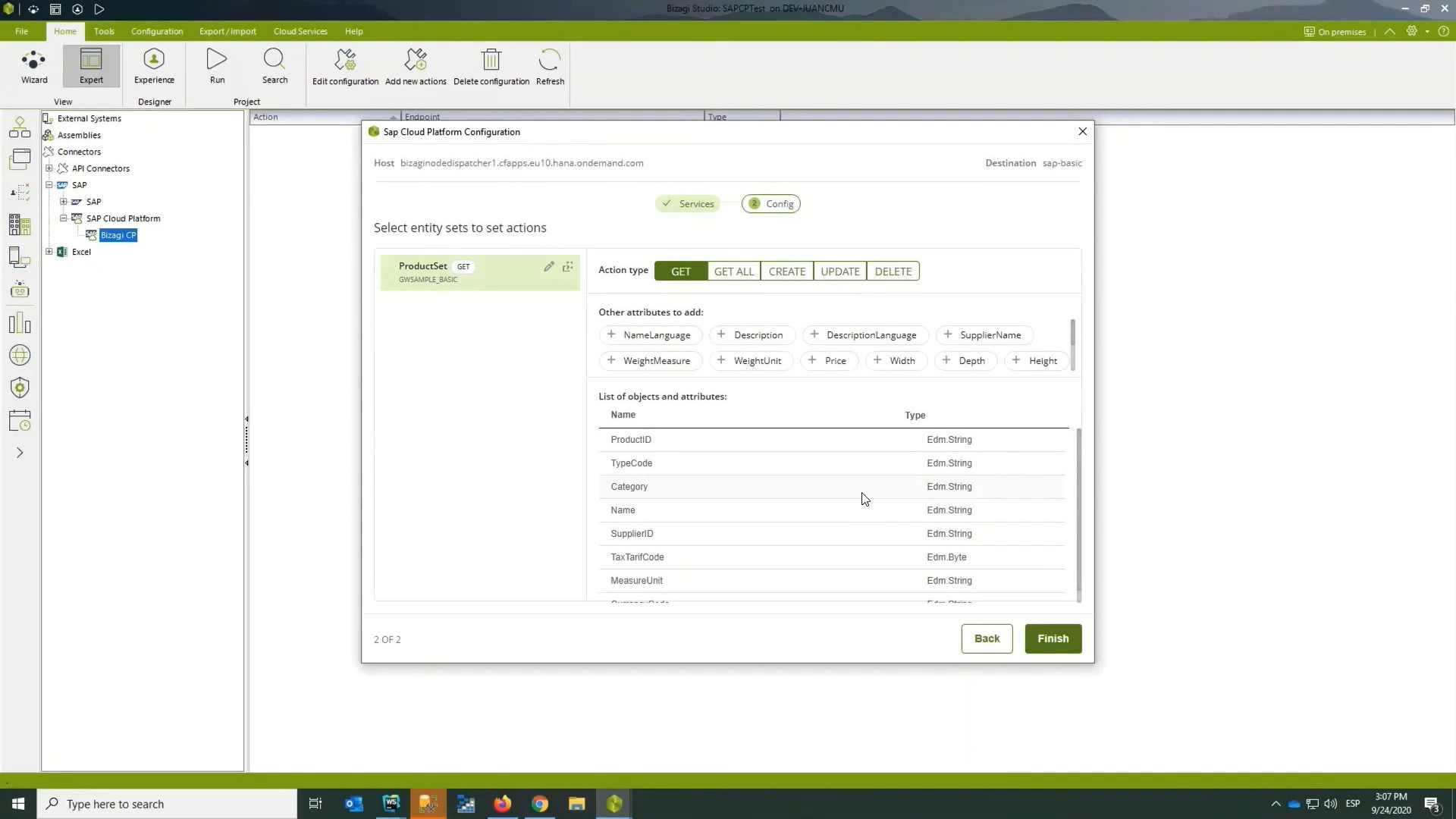
Moving on from RPA, they showed their connector with Microsoft Cognitive Services Form Recognizer, allowing for extraction of text and data from scanned forms if you’re using an Azure and Cognitive Services environment. There are a number of pre-defined standard forms, but you can also train Form Recognizer if you have customized versions of these forms, or even new forms altogether. They finished up with their new SAP Cloud Connector, which works with S/4HANA. We saw a demo of this, with the SAP connection being setup directly in Bizagi Studio. This is similar to their existing SAP connector, but with a direct connection to SAP Cloud.
I’ll be back for some of the sessions tomorrow, but since I have a keynote and interactive Q&A, I may not be blogging much.
Disclosure: I am being compensated for my keynote presentation, but not for anything that I blog here. These are my own opinions, as always.












")
")
")
")
")