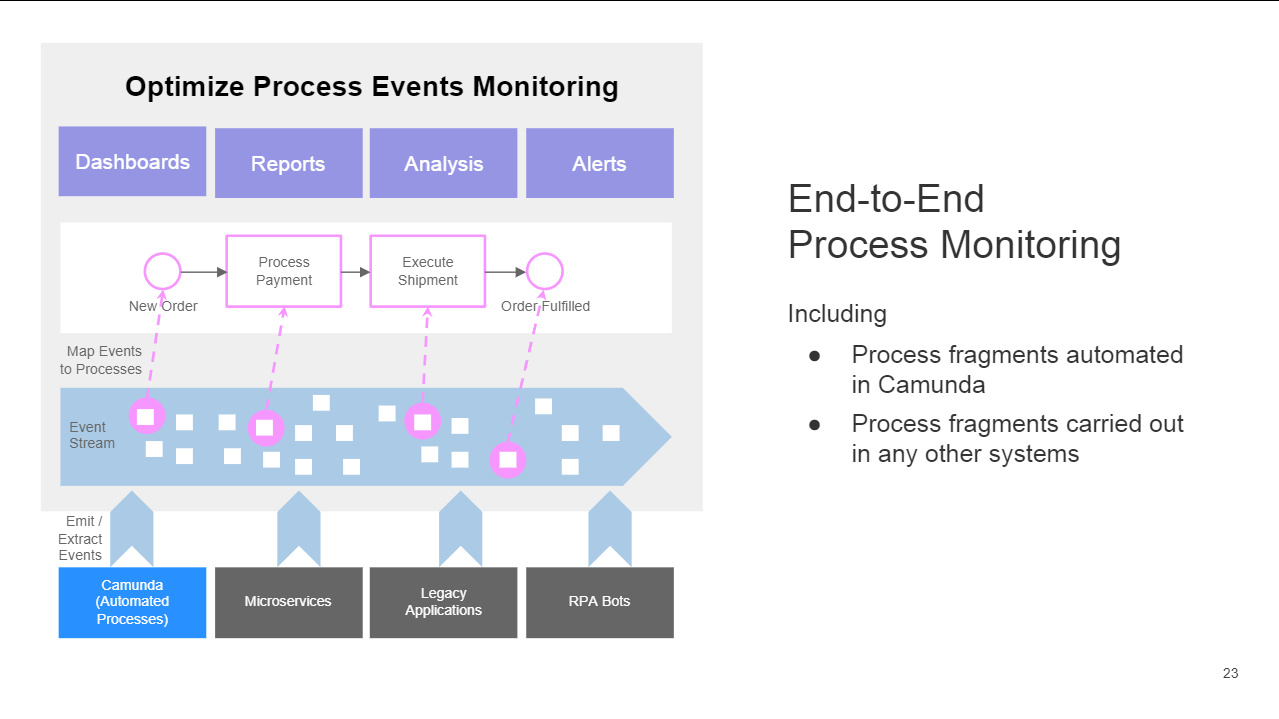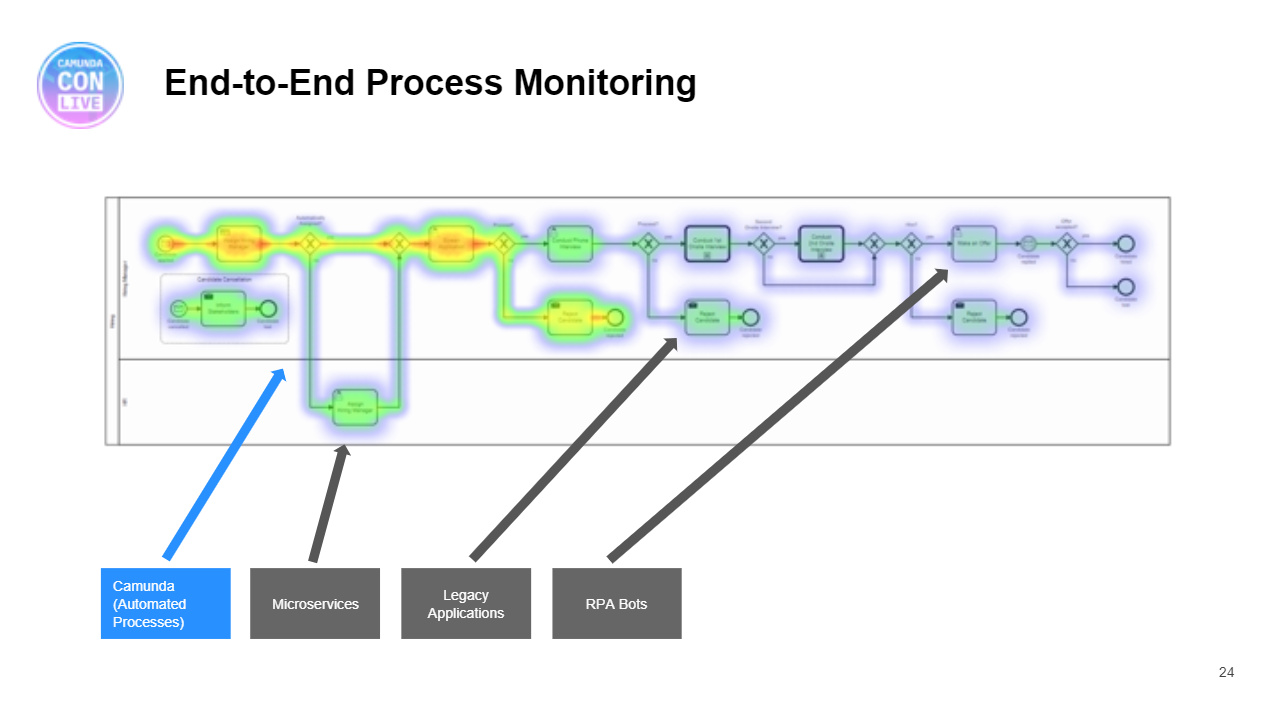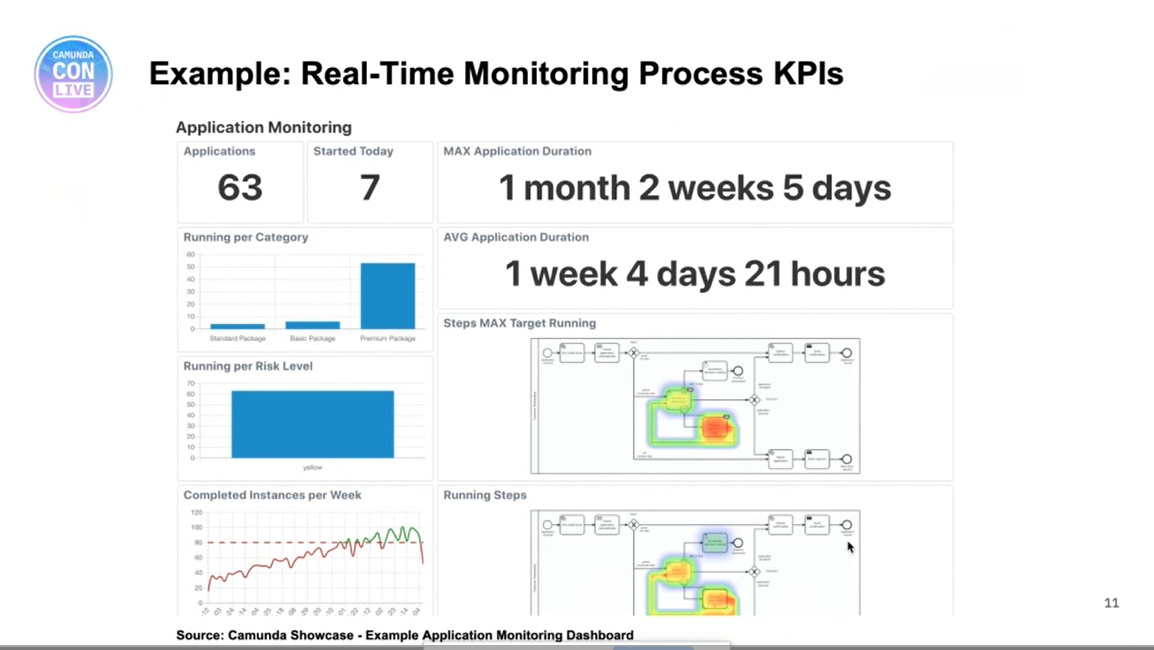
We continued the first day of CamundaCon Live (virtual) 2020 with Felix Mueller, senior product manager, presenting on how to use Camunda Optimize for driving continuous improvement in processes. I attended the Optimze 3.0 release webinar a couple of weeks ago, and saw some of the new things that they’re doing with monitoring and optimization of event-based processes — this allows processes that are not part of Camunda to be included in Optimize. The CamundaCon session started with a broader view of Optimize functionality, showing how it collects information then can be used for root cause analysis of process bottlenecks as well as displaying realtime metrics. They have some good case studies for Optimize, including insurance provider Visana Group.

He then moved to show the event-based process monitoring, and how Optimize can ingest and aggregate information from any external system with a connector, such as RabbitMQ (which they have built). His demo showed a customer onboarding process that could be triggered either by an online form that would be a direct Camunda process instantiation, or via a mailed-in form that was scanned into another system that emitted an event that would trigger the process.
It was very obvious that this was a live presentation, because Mueller was scrambling against the clock since the previous session went a bit long, having to speed through his demo and take a couple of shortcuts. Although you might think of this as a logistical “bug”, I maintain that it’s an interactivity “feature”, and made the experience much closer to an in-person conference than a set of pre-recorded presentations that were just queued up in sequence.

This was followed by a presentation by Kris Barczynski of Nokia Bell Labs about a really interesting use case: they are using Camunda to guide visiting groups on tours through the Nokia Campus customer experience spaces, and interact with devices including the guests’ wearables, drones and robots. Visitors are welcomed and guided by a robot, and they can interact with voice-controlled drones; Camunda is orchestrating the processes behind the scenes. He talked about some of their design decisions, such as using Camunda JavaScript workers to call external services, and building a custom Android app. Really interesting combination of physical and virtual processes.
Next was a panel discussion on the future of RPA, with Vittorio Dal Bianco of Nokia, Marco Einacker of Deutsche Telekom, Paul Jones of NatWest Group, and Camunda CEO Jakob Freund, moderated by Jason Bloomberg of Intellyx Research. The three customer presenters are involved with the RPA initiatives at their own organizations, and also looking at how to integrate that with their Camunda processes. Panels are always a challenge to live-blog, but here’s some of the points discussed (attributed where I remembered):
- The customer panelists agreed that RPA has allowed people to move to more interesting/valuable work, rather than doing routine tasks such as copying and pasting between application screens. Task automation through RPA reduces resources/costs, decreases cycle time, and also improves quality/compliance.
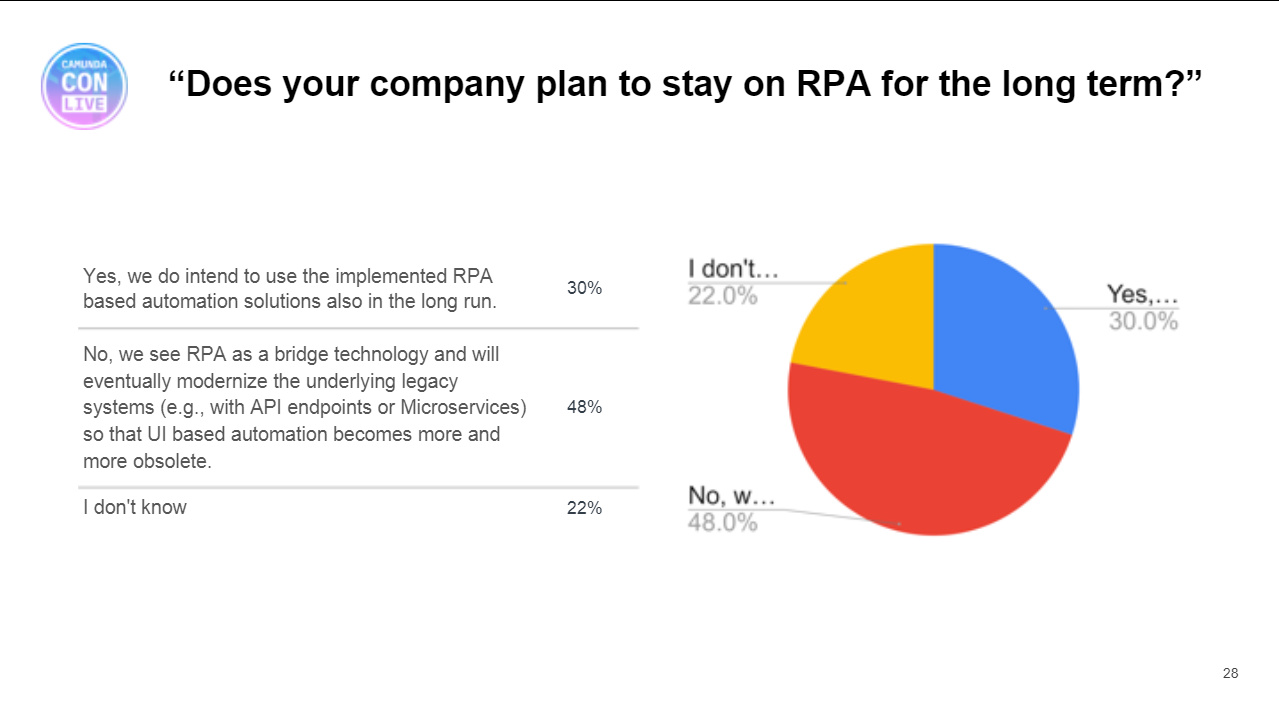
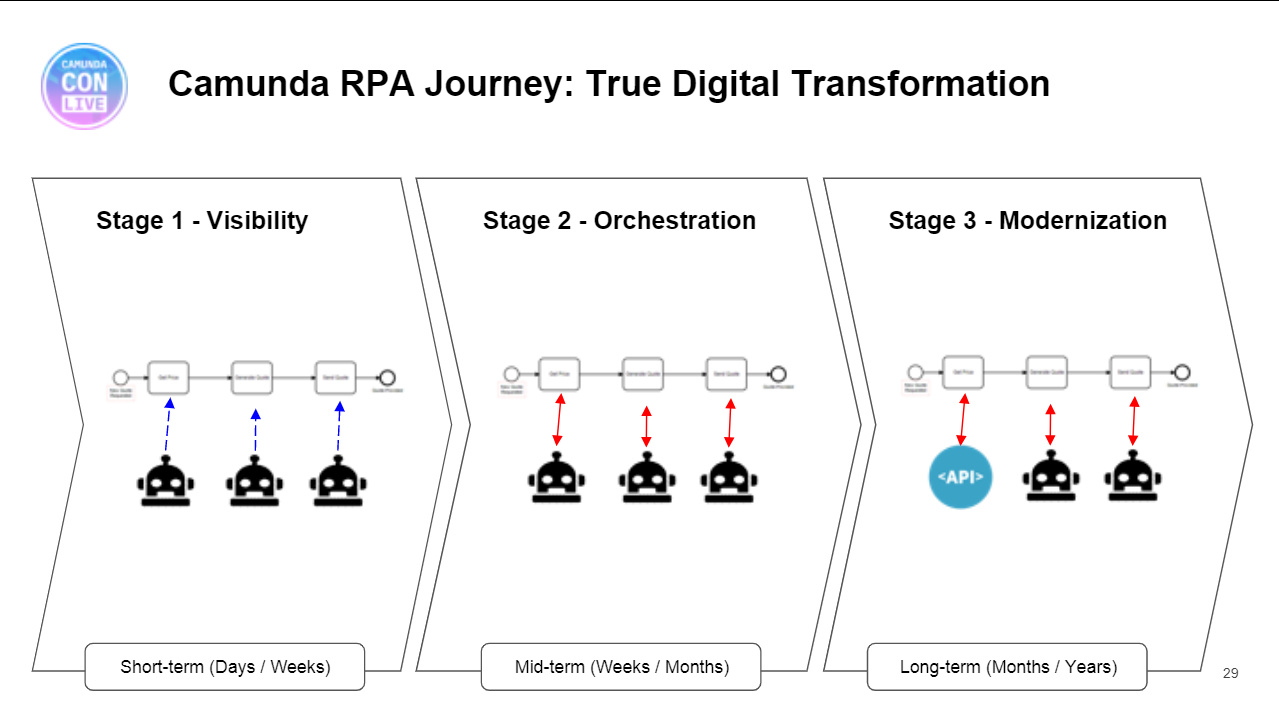
- RPA is a “short-term bandaid” driven from outside the IT organization in order to get some immediate efficiency benefits. It’s maintenance-intensive, since any changes to the appliations being integrated means that the bots need to be reprogrammed. Deutsche Telekom is moving from RPA front-end integration/automation to drive the more strategic BPMS/API automation, so sees that RPA has been an important step on the strategic journey but not the endpoint. NatWest recognizes RPA as a key automation tool, but see it as a short-term tactical tool; they classify RPA as part of their technical debt, and it is not a part of their long-term architecture. Nokia thinks that RPA will remain in niche pockets for applications that will never have a proper API, such as Excel-based applications.
- Nokia uses Blue Prism for RPA. NatWest uses UIPath RPA, and has a group that is building the integration for having Camunda execute a UIPath task — although I would have thought this would be a relatively simple service call or external task. Deutsche Telekom is using seven different RPA platforms, three of which are commercial including Another Monday and Kryon; they are just starting to look at the integration between Camunda and RPA with a plan to have Camunda orchestrate steps, and one “microbot” performing an atomic task at that step. As their core system offers an API for that task, the RPA bot will be replaced with a direct API call. This last approach is definitely aligned with Camunda’s vision of how their BPM can work with RPA bots as well as any other “task performers”.
- More discussion on the role of RPA in digital transformation: recommendations to go ahead and use it, but consider it as a stop-gap measure to get a quick win before you can get the APIs built out in the systems that are being integrated. It’s considered technical debt because it will be replaced in the future as the APIs of the core systems become available. It’s a painkiller, not a cure.
- Although some of the companies are using business people to build their own bots, that has a mixed degree of success and other companies do not classify RPA as citizen developer technology. This is pretty much the same as we’re seeing with other low-code environments, where they are often sold as application development platforms for non-professional developers, but the reality is that many applications require a professional developer because of the technical complexity of systems being integrated.
- Cost and effort of RPA bot maintenance can be significant, in some cases more than back-end integration. Bot fixes may be fairly quick, but are required much more frequently such as when a password changes: bots require babysitting.
- The customers had a few Camunda product requests, such as better connectors to more of the RPA tools. In general, however, they don’t want Camunda to build/acquire their own RPA offering, but just see it as another example of where you can pick a best-of-breed RPA tool and use it for task automation at individual steps within a Camunda process.
- Best practices/lessons learned:
- Separate the process orchestration layer from the bot execution layer from the beginning, with the process orchestration being done by Camunda and the bot task execution being done by the RPA tool.
- Use process mining first to objectively identify what should be automated; of course, this would also require that you mine the user interaction processes that would be automated with bots, not just the system logs.
- Have a centralized control center for bot control.
- Develop bot templates that can be more quickly modified and deployed.
Looking at how the panel worked, there are definitely aspects of online panels that work better than in-person panels, specifically how they respond to audience questions. Some people don’t want to speak up in front of an audience, while others get up and bloviate without actually asking a question. With online-only questions, the moderator can browse through and aggregate them, then select the ones that are best suited to the panel. With video on each of the presenters (except for one who lost his connection and had to dial in), it was still possible to see reactions and have a sense of the live nature of the panel.

The last session of the day was Jimmy Floyd of 24 Hour Fitness on their massive Camunda implementation of five billion (with a “B”) process node executions per month. You can see his presentation from CamundaCon Berlin 2018 as a point of comparison with today’s numbers. Pretty much everything that happens at 24 Hour Fitness is controlled by a Camunda process, from their internal processes to customer-facing activities such as a member swiping their card to gain access to a club. It hasn’t been without hiccups along the way: they had to turn off process history logging to attain this volume of data, and can’t easily drill down into processes that call a lot of other processes, but the use of BPMN and DMN has greatly improved the interactions between product owners and developers, sometimes allowing business people to make a rule change without involving developers.

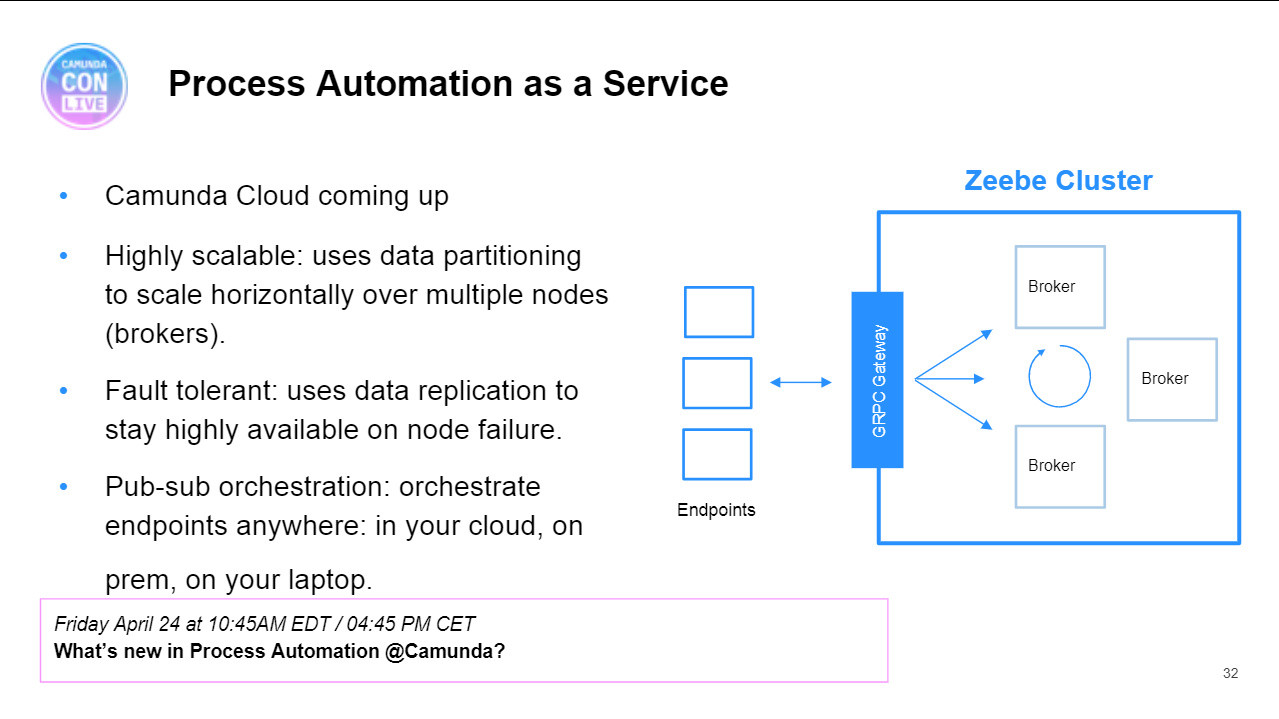
He had a lot of technical information on how they built this and their overall architecture. Their use is definitely custom code, but using Camunda with BPMN and DMN gave them a huge step-up versus just writing code. Even logic inside of microservices is implemented with Camunda, not written in code. Their entire architecture is based on Camunda, so it’s not a matter of deciding whether or not to use it for a new application or to integrate in a new external solution. They are taking a look at Zeebe to decide if it’s the right choice of them moving forward, but it’s early days on that: it would be a significant migration for them, they would likey lose functionality (for BPMN elements not yet implemented in Zeebe, among other things), and Zeebe has only just achieved production readiness.
Camunda is changing how they handle history data relative to the transactional data, in part likely due to input from high-throughput customers, and this may allow 24 Hour Fitness to turn history logging back on. They’re starting to work with Optimize via Kafka to gain insights into their processes.
Day 1 finished with a quick wrapup from Jakob Freund; in spite of the fact that it’s probably been a really long day for him, he seemed pretty happy about how well things went today. Tomorrow will cover more on microservices orchestration, and have customer case studies from Cox Automotive, Capital One and Goldman Sachs.
As you probably gather from my posts today, I’m finding the CamundaCon online format to be very engaging. This is due to most of the presentations being performed live (not pre-recorded as is seen with most of the online conferences these days) and the use of Slack as a persistent chat platform, actively monitored by all Camunda participants from the CEO on down. They do need a little bit more slack in the schedule however: from 10am to 3:45pm there was only one 15-minute break scheduled mid-way, and it didn’t happen because the morning sessions ran overtime. If you’re attending tomorrow, be prepared to carry your computer to the kitchen and bathroom with you if you don’t want to miss a minute of the presentations.
As I finish off my day at the virtual CamundaCon, I notice that the videos of presentations from earlier today are already available — including the panel session that only happened an hour ago. Go to the CamundaCon hub, then change the selection from “Upcoming” to “On Demand” above the Type/Day/Track selectors.