Not only did Oracle schedule this briefing on Canada Day, the biggest holiday in Canada, but they forced me to download the Real Player plug-in in order to participate. The good part, however, is that it was full streaming audio and video alongside the slides.
Charles Phillips, Oracle President, kicked off with a welcome and some background on Oracle, including their focus on database, middleware and applications, and how middleware is the fastest-growing of these three product pillars. He described how Oracle Fusion middleware is used both by their own applications as well as ISVs and customers implementing their own SOA initiatives.
He outlined their rationale for acquiring BEA: complementary products and architecture, internal expertise, strategic markets such as Asia, and the partner and channel ecosystem. He stated that they will continue to support BEA products under the existing support lifetimes, with no forced migration policies to move off of BEA platforms. They now consider themselves #1 in the middleware market in terms of both size and technology leadership, and Phillips gave a gentle slam to IBM for over-inflating their middleware market size by including everything but the kitchen sink in what they consider to be middleware.
The BEA developer and architect online communities will be merged into the Oracle Technology Network: Dev2Dev will be merged into the Oracle Java Developer community, and Arch2Arch will be broadened to the Oracle community.
Retaining all the BEA development centers, they now have 4,500 middleware developers; most BEA sales, consulting and support staff were also retained and integrated into the the Fusion middleware teams.
Next up was Thomas Kurian, SVP of Product Development for Fusion Middleware and BEA product directions, with a more detailed view of the Oracle middleware products and strategy. Their basic philosophy for middleware is that it’s a unified suite rather than a collection of disjoint products, it’s modular from a purchasing and deployment standpoint, and it’s standards-based and open. He started to talk about applications enabled by their products, unifying SOA, process management, business intelligence, content management and Enterprise 2.0.
They’ve categorized middleware products into 3 categories on their product roadmap (which I have reproduced here directly from Kurian’s slide:
- Strategic products
- BEA products being adopted immediately with limited re-design into Oracle Fusion middleware
- No corresponding Oracle products exist in majority of cases
- Corresponding Oracle products converge with BEA products with rapid integration over 12-18 months
- Continue and converge products
- BEA products being incrementally re-designed to integrate with Oracle Fusion middleware
- Gradual integration with existing Oracle Fusion middleware technology to broaden features with automated upgrades
- Continue development and maintenance for at least 9 years
- Maintenance products
- BEA had end-of-life’d due to limited adoption prior to Oracle M&A
- Continued maintenance with appropriate fixes for 5 years
For the “continue and converge” category, that is, of course, a bit different than “no forced migration”, but this is to be expected. My issue is with the overlap between the “strategic” category, which can include a convergence of an Oracle and a BEA product, and the “continue and converge” category, which includes products that will be converged into another product: when is a converged product considered “strategic” rather than “continue and converge”, or is this just the spin they’re putting on things so as to not freak out BEA customers who have put huge investments into a BEA product that is going to be converged into an existing Oracle product?
He went on to discuss how each individual Oracle and BEA product would be handled under this categorization. I’ve skipped the parts on development tools, transaction processing, identity management, systems management and service delivery, and gone right to their plans for the Service-Oriented Architecture products:
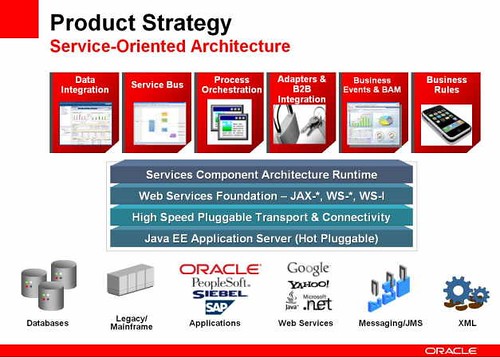
- Strategic:
- Oracle Data Integrator for data integration and batch ETL
- Oracle Service Bus, which unifies AquaLogic Service Bus and Oracle Enterprise Service Bus
- Oracle BPEL Process Manager for service orchestration and composite application infrastructure
- Oracle Complex Event Processor for in-memory event computation, integrated with WebLogic Event Server
- Oracle Business Activity Monitoring for dashboards to monitor business events and business process KPIs
- Continue and converge:
- BEA WL-Integration will be converged with the Oracle BPEL Process Manager
- Maintenance:
- BEA Cyclone
- BEA RFID Server
Note that the Oracle Service Bus is in the “strategic” category, but is a convergence of AL-SB and Oracle ESB, which means that customers of one of those two products (or maybe both) are not going to be happy.
Kurian stated that Oracle sees four types of business processes — system-centric, human-centric, document-centric and decision-centric (which match the Forrester divisions) — but believes that a single product/engine that can handle all of these is the way to go, since few processes fall purely into one of these four categories. They support BPEL for service orchestration and BPMN for modeling, and their plan is to converge a single platform that supports both BPEL and BPMN (I assume that he means both service orchestration and human-facing workflow). Given that, here’s their strategy for Business Process Management products:
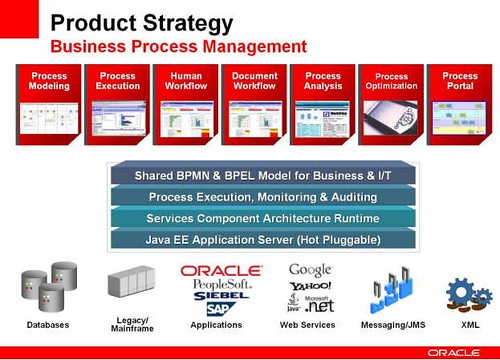
- Strategic:
- Oracle BPA Designer for process modeling and simulation
- BEA AL-BPM Designer for iterative process modeling
- Oracle BPM, which will be the convergence of BEA AquaLogic BPM and Oracle BPEL Process Manager in a single runtime engine
- Oracle Document Capture & Imaging for document capture, imaging and document workflow with ERP integration [emphasis mine]
- Oracle Business Rules as a declarative rules engine
- Oracle Business Activity Monitoring [same as in SOA section]
- Oracle WebCenter as a process portal interface to visualize composite processes
Similar to the ESB categorization, I find the classification of the converged Oracle BPM product (BEA AL-BPM and Oracle BPEL PM) as “strategic” to be at odds with his original definition: it should be in the “continue & converge” category since the products are being converged. This convergence is not, however, unexpected: having two separate BPM platforms would just be asking for trouble. In fact, I would say that having two process modelers is also a recipe for trouble: they should look at how to converge the Oracle BPA Designer and the BEA AL-BPM Designer
In the portals and Enterprise 2.0 product area, Kurian was a bit more up-front about how WebLogic Portal and AquaLogic UI are going to be merged into the corresponding Oracle products:
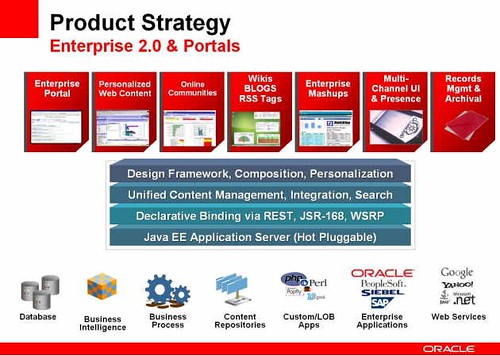
- Strategic:
- Oracle Universal Content Management for content management repository, security, publishing, imaging, records and archival
- Oracle WebCenter Framework for portal development and Enterprise 2.0 services
- Oracle WebCenter Spaces & Suite as a packaged self-service portal environment with social computing services
- BEA Ensemble for lightweight REST-based portal assembly
- BEA Pathways for social interaction analytics
- Continue and converge:
- BEA WebLogic Portal will be integrated into the WebCenter framework
- BEA AquaLogic User Interaction (AL-UI) will be integrated into WebCenter Spaces & Suite
- Maintenance:
- BEA Commerce Services
- BEA Collabra
In SOA governance:
- Strategic:
- BEA AquaLogic Enterprise Repository to capture, share and manage the change of SOA artifacts throughout their lifecycle
- Oracle Service Registry for UDDI
- Oracle Web Services Manager for security and QOS policy management on services
- EM Service Level Management Pack as a management console for service level response time and availability
- EM SOA Management Pack as a management console for monitoring, tracing and change managing SOA
- Maintenance:
- BEA AquaLogic Services Manager
Kurian discussed the implications of this product strategy on Oracle Applications customers: much of this will be transparent to Oracle Applications, since many of these products form the framework on which the applications are built, but are isolated so that customizations don’t touch them. For those changes that will impact the applications, they’ll be introduced gradually. Of course, some Oracle Apps are already certified with BEA products that are now designated as strategic Oracle products.
Oracle has also simplified their middleware pricing and packaging, with products structured into 12 suites:

He summed up with their key messages:
- They have a clear, well-defined, integrated product strategy
- They are protecting and enhancing existing customer investments
- They are broadening Oracle and BEA investment in middleware
- There is a broad range of choice for customer
The entire briefing will be available soon for replay on Oracle’s website if you’re interested in seeing the full hour and 45 minutes. There’s more information about the middleware products here, and you can sign up to attend an Oracle BEA welcome event in your city.
