Clay Richardson of Forrester and Keith Swenson of Fujitsu gave a webinar this afternoon on dynamic BPM platforms. There will be a replay available; I’ll update this post with the link when I get it, or someone can add it to the comments if they get it first.
Richardson started with some fairly generic research by Forrester on business problems such as cross-functional processes and process agility, then defined a dynamic business process as one that is built for change and adaptable to the business context. There’s also a significant collaboration/social software message, where dynamic BPM requires both a high degree of collaboration as well as a high degree of information support.
As he points out, most BPM only tackles the structured parts of a process, but doesn’t interface with things such as personal reminder lists, external email and instant messaging. The entire business process does include those things; it’s just that most organizations are using manual, ad hoc methods to integrate between structured systems (including most BPM) and unstructured activities and systems. He stratifies this into three parallel types of work: ad hoc human activities, structured human activities, and system-intensive processes. Although many BPM solutions can do the latter two, many organizations use very different tools for purely system-to-system interactions than they do for processes that contain human-facing steps.
He stated that dynamic BPM is able to handle ad hoc and collaboration scenarios in the context of a more structured business process: being able to blend structured and unstructured work. This allows knowledge workers to do work on their own terms using the tools that they choose, but by doing this in the context of dynamic BPM, visibility into these ad hoc processes is maintained. In the course of providing this visibility, it also feeds back information to IT on how the processes are executed, allowing for these to potentially be structured and standardized where appropriate.
He then turned it over to Keith Swenson, who reinforced the definition of dynamic BPM as empowering users to get work done their way, specifically in cases where there is no pre-defined “best way”to complete the work. The plan is elaborated while you work, not ahead of time; he used one example of emergency fire response units, and another of a movie rollout by a production studio. In both cases, there is not a fixed process or assembly-line plan for how things should be done; they need to be able to do unpredictable things in the context of completing the work, with decisions about what to do next made by multiple people. In many cases, portions of the work is sub-tasked to others, who use their own judgment to create and execute the plan on the fly.
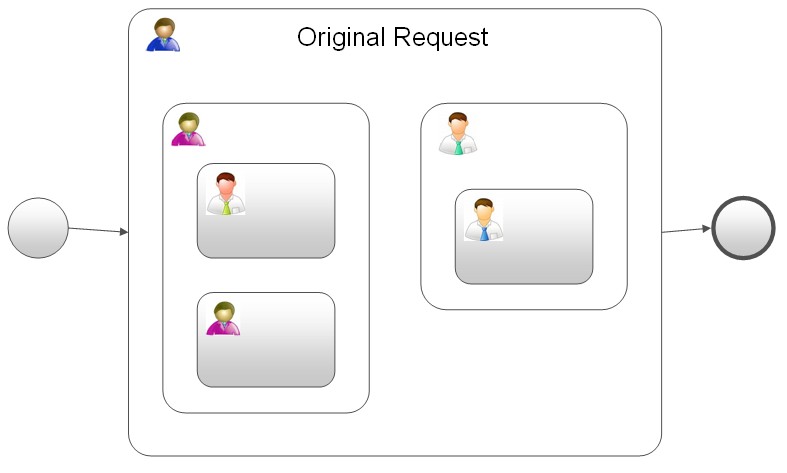 The predominant way that ad hoc processes are handled now is email: people send messages to assign a task to someone, but there’s not a lot of tracking of what work has been assigned to whom, and the status of that work. From a modeling standpoint, consider that this could end up looking like nested subprocesses of ad hoc tasks, where these subprocesses and tasks (and the resources to whom they are assigned) need to be created as they are identified. What we need is smart email, which allows someone to just break out of the structured process, fire off an email to someone who may not have been predefined as a resource, and have that email communication (including the responses) be visible through the standard tracking mechanisms as part of the process.
The predominant way that ad hoc processes are handled now is email: people send messages to assign a task to someone, but there’s not a lot of tracking of what work has been assigned to whom, and the status of that work. From a modeling standpoint, consider that this could end up looking like nested subprocesses of ad hoc tasks, where these subprocesses and tasks (and the resources to whom they are assigned) need to be created as they are identified. What we need is smart email, which allows someone to just break out of the structured process, fire off an email to someone who may not have been predefined as a resource, and have that email communication (including the responses) be visible through the standard tracking mechanisms as part of the process.
I’m not left with any sense of how this might tie into Fujitsu products (or, in fact, any other BPM products), although Swenson is enough of an independent thinker that it may not have a direct link, but be more of an educational push. He did mention something pretty vague about how they did support dynamic BPM, but it’s not clear if this is current standard product offering, future product offering, or services. They are promoting a two-day workshop for visualizing your current dynamic business processes, so this may be more related to what they can offer from a services standpoint since they also have some innovative stuff in process discovery. When you think about it, some part of dynamic BPM is really just process discovery, aimed at finding the parts of the ad hoc processes that can be turned into structured processes for a standard BPM implementation. The rest of it is about creating the linkages between the ad hoc process handling methods – such as email and IM – so that these become first class participants in a business process.
There’s a few of the smaller vendors who are creating direct interfaces with Outlook/Exchange in order to provide this sort of management of email requests and responses, including HandySoft (where, coincidentally, Richardson used to work) and ActionBase (which I reviewed last month), but the larger vendors needs to start including this sort of functionality in their BPM products as well.