When I wrote a post yesterday about the slow convergence between BPM and social software, I had forgotten about the analyst briefing that I had scheduled with IBM later in the day for a sneak peak of the new Blueworks Live site. Lombardi has always been at the forefront of the integration of social and BPM, although previously focused purely on the process discovery/design phase, and the IBM acquisition has allowed Lombardi’s social process discovery to be combined with IBM’s online BPM community to create something greater than the sum of the parts. For all my criticism of IBM, they have some incredible pockets of innovation that sometimes burst out into actual product.
Yesterday’s session was hosted by Phil Gilbert; apparently this was the first public viewing of the site, which will be officially unveiled this Saturday, November 20th. Phil, who I’ve known for a number of years through his time at Lombardi, explained some of the motivation for Blueworks Live, and in a weird echo of the post that I wrote just hours before, he said “BPM is ready to meet social networking”. They are trying to reinvent the public BPM community, while avoiding the problems that they perceive with other vendors’ community sites:
- They are mainly product support sites
- They have high membership numbers, but low participation
- A majority of the information is from the sponsor company
- The customer perception is that these sites are proprietary and biased, and that there’s already too many sources of information on BPM
Blueworks Live Community
In their search for a truly public BPM community, they turned to that universal public community: Twitter. They are taking the public BPM-focused Twitter stream, based on both BPM-focused users (including everyone on the analyst call, said Phil) and the #bwlive hashtag, to create a public stream that will be displayed alongside a user’s private activity stream in Blueworks Live. The private activity stream is based on processes and projects in which the user is a participant, or that the user has selected to follow.
Blueworks Live is a combination of the previous BPM BlueWorks Beta community and the (Lombardi) BPM Blueprint process discovery tool; although BPM BlueWorks Beta had some process modeling tools, they were not of the sophistication of Blueprint. However, it’s more than just community and process modeling: Blueworks Live also includes process automation for the long tail of low-volume administrative processes, that is, those simple human-based processes that can’t warrant a BPM implementation that involves IT. IBM estimates that 75% of all business processes fall into this category – including processes from HR, IT, accounting, marketing and a number of other areas – and most end up being done in email.
 We moved on to a product demo by Cliff Vars, a product manager, who started with the view of the site by unregistered (that is, unpaid) users. Without signing in, you can view:
We moved on to a product demo by Cliff Vars, a product manager, who started with the view of the site by unregistered (that is, unpaid) users. Without signing in, you can view:
- Under the Community section, the afore-mentioned public BPM Twitter stream, made up of specific Twitter users and tweets containing the #bwlive hashtag. Although the pricing chart indicated that free users could see both public and private communities, we only saw the public BPM Twitter stream before logging in.
- Under the Library section, blog posts migrated from the old BPM BlueWorks Beta site. I believe that a lot of the content from the old site was written by IBM employees and was moderated, so can’t exactly be considered public community content.
- Also in the Library section, a number of process templates that appear to be in the (Lombardi) Blueprint format – not clear how useful that would be if you weren’t a paid user, since you couldn’t use the Blueprint modeler to open them.
Creating a Process Automation
We then logged on to take a look at how simple process automation works. In the logged-in view, the “Getting Started” section is replaced by the “Work” section, which contains all of the tasks assigned to the user, the process instances that they’ve launched, the ability to launch a new process instance, plus links to create a Blueprint process design or a new automated process. It’s important to recognize that there’s two distinct types of processes here: complex processes modeled in Blueprint (the former Lombardi tool), which may eventually be transferred to an on-premised IBM Lombardi process engine for execution; and simple processes, which are modeled using a completely different tool and executed directly within the Blueworks Live site. When we look at process automation, it’s the latter that we’re seeing.
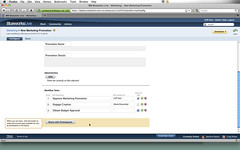 To automate a process, then, you click the big green “Automate a Process button” to get started, then specify the following:
To automate a process, then, you click the big green “Automate a Process button” to get started, then specify the following:
- A process application name.
- The process type, either “Simple Workflow” or “Checklist”. In the demo, we saw a simple workflow type, which is a linear sequence of tasks assigned to users; we didn’t get a look at the checklist type so not sure of the different functionality. These are the only types available for automated processes in Blueworks Live, although they plan to add more in the future.
- Select the space for the process definition, which might be a personal sandbox or a department such as Marketing.
- Add instructions to be provided when an instance of the process is launched.
- Configure some of the labels that will appear in the running process to make them more specific to the process.
- Add one or more tasks, which will be executed sequentially in each process instance. For each task, specify the description, who the task is assigned to (or leave it blank to have it assigned at runtime), and whether the task is an approval step.
- Share the process definition with participants of that space, who will then have it available as a process type to instantiate from their Work section.
The whole process creation took only a couple of minutes, and when we returned to the user’s Work section where we had started, the new process template was available in the sidebar.
Launching and Participating in a Process
We then logged on as a different user to create a process instance from that template. Since this user presumably has access to the space in which the process designer saved the process template, it appears in the sidebar of our Work section. Clicking that link kicks off a process instance:
- The instructions specified by the process designer are displayed.
- Fill in the name and details fields.
- Add a desktop document as an attachment; this is uploaded and shared with all the participants.
- Select a due date for each of the tasks.
- For the task that wasn’t pre-assigned to a user, assign the user.
- Launch it to kick off the first task.
Returning to the main Work section, we can now see that process instance in the “Work I’ve launched” tab, and can open and track its progress from there.
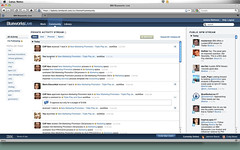 When we move over to the Community section, we can now see our private activity stream, which includes two new events: first, that we launched the workflow, and second, that the first task in that workflow was received by the user to which it was assigned. By default, all of the events for every process that we’ve launched will appear in our activity stream.
When we move over to the Community section, we can now see our private activity stream, which includes two new events: first, that we launched the workflow, and second, that the first task in that workflow was received by the user to which it was assigned. By default, all of the events for every process that we’ve launched will appear in our activity stream.
We then switched back to the original user, who was also the user to whom the first task in the process was assigned, to see what it looks like to participate in a process. An email was already waiting to tell us that we had a new task, complete with a link to the task, or we could have found the task directly in the Work section of Blueworks Live under the “Tasks assigned to me” tab. Regardless of how it was opened, we can then complete the task:
- View the process name and details provided by the process originator.
- View the attached document. It appears that we could also have added more documents at this point, although we didn’t see that.
- Add a comment, which appears in a comments timeline on the side of the process information.
- View the tasks to be completed. Since the first one is assigned to us, and it was an approval task, there are Approve and Reject buttons on the task.
- Click the Approve button to mark the task as completed. I assume that tasks that are not approval tasks have a simple Complete button or something similar so that the participant can mark the task as complete, although we didn’t look at that.
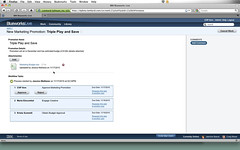 There are a number of other options that appear to be available at this point, although we didn’t explore them, such as reassigning the remaining tasks to different users, but essentially this user is done with their task and the process. If we move to the Community area and look at the private activity stream for this user, we can see that in addition to creating and sharing the process template, the approval task also appears there.
There are a number of other options that appear to be available at this point, although we didn’t explore them, such as reassigning the remaining tasks to different users, but essentially this user is done with their task and the process. If we move to the Community area and look at the private activity stream for this user, we can see that in addition to creating and sharing the process template, the approval task also appears there.
Overall, although there’s nothing really new about this sort of easy sequential workflow design and execution, the user interface is clean and uncluttered, and pop-up tips on the fields assist the user on what to enter. Assuming that you can wrench your users away from using email for these processes, there won’t be much of a learning curve for them to create new processes on their own, and even less to use processes created by others. If you want to see this in action, there’s a Blueworks Live YouTube channel with a couple of videos on creating and participating in a process.
A user with administrative privileges can view some basic aggregate reports on these processes, including some graphical views of process template usage, user participation and on-time completion; this is generated as an Excel spreadsheet that is downloaded and viewed on the desktop, not as an integrated reporting or dashboard view. It’s very rudimentary, but may be sufficient for the types of processes that are likely to be automated using this tool.
To finish up, we also looked at the Library section again; as a logged-in user, we could now see some additional content areas, including links to Blueprint process models, which could then launch the familiar Blueprint environment within Blueworks Live for complex process discovery and modeling. As I mentioned earlier, this is a completely different modeling environment than the “process automation” that I described above; these processes will be exported to an on-premise IBM Lombardi process engine for execution.
There are three levels of Blueworks Live users:
- Community, free, which allows you to view the public and private communities, although it’s not clear what the private community is in the case of a free user.
- Contributor, $10/month, which adds all the functionality of creating and running the simple process applications that I’ve described above, plus the ability to review and comment on Blueprint process models.
- Editor, $50/month, which adds the full Blueprint modeling capability.
Although the paid users now have more than former (paid) Blueprint users with the addition of the simple process automation, free users of the old BPM BlueWorks Beta site have lost a whole bunch of capabilities, unless we just skipped that part of the demo.
The Verdict
In a nutshell, Blueworks Live provides some private and public community functionality, allows you to create (Lombardi) Blueprint process designs, and automate simple processes. But these are two very different tools: the online mini processes with the Blueworks Live automation engine (based on two basic templates, workflow and checklist), and the Blueprint processes, some of which will be moved to an on-premise Lombardi system. Different interfaces, different engines, different everything except that they’re contained within the same portal.
The Twitter stuff is pretty useless for those of us who are already competent at monitoring Twitter using a tool such as Tweetdeck. I’m never going to go to Blueworks Live to look at the public Twitter stream; I probably already follow the same list of people in my BPM Twitter list, and if I want to see what’s happening with #bwlive, I’ll just add it as a search column. It’s probably good for the Twitter newbies, since they haven’t figured out groups, hashtags or Tweetdeck yet; maybe that’s more representative of the expected user base.
Except for the Twitter stream, the only community content appears to be the current BlueWorks blog content, written mostly by IBM. The online execution isn’t really community, it’s process execution in a semi-collaborative space, which is different. The forums (mostly product/site help) and media library (including webinars, white papers and the various modeling tools such as strategy and capability maps) from the old BPM BlueWorks Beta site are missing, or at least not displayed in the version that we saw. Although Blueworks Live definitely has some improved functionality such as process execution, this is really a collection of non-integrated tools, and it’s not clear that they’ve reached their goals regarding a public BPM community.
They’re not the first to have cloud-based process execution, but they are IBM, and that lends some credibility to the whole notion of running your business processes outside the firewall. Like the entry of other large players into the cloud BPM marketplace, I believe that this will be a benefit to all cloud BPM providers since it will validate and enlarge the market. This validation of cloud-based BPM is a real game-changer, if not Blueworks Live itself.

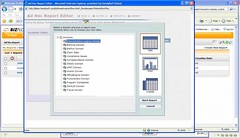 If you’ve seen Jaspersoft (or most other ad hoc reporting tools) at work, there isn’t much new here: you can select the data domain from the list of data marts set up by an administrator, then select the type of report/graph, the fields, filtering criteria and layout. It’s a bit too techie for the average user to actually create a new report definition, since it provides a little much close contact with the database, such as displaying the actual SQL field names instead of aliases, but once the definition is created, it’s easy enough to run from the BizFlow interface. Regular report runs can be scheduled to output to a specific folder in a specific format (PDF, Excel, etc.), based on the underlying Jaspersoft functionality.
If you’ve seen Jaspersoft (or most other ad hoc reporting tools) at work, there isn’t much new here: you can select the data domain from the list of data marts set up by an administrator, then select the type of report/graph, the fields, filtering criteria and layout. It’s a bit too techie for the average user to actually create a new report definition, since it provides a little much close contact with the database, such as displaying the actual SQL field names instead of aliases, but once the definition is created, it’s easy enough to run from the BizFlow interface. Regular report runs can be scheduled to output to a specific folder in a specific format (PDF, Excel, etc.), based on the underlying Jaspersoft functionality.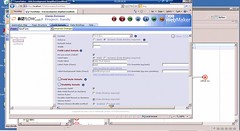 HandySoft’s WebMaker is loosely coupled with BizFlow, so it can be used for any web application development, not just BPM-related applications. It does integrate natively with BizFlow, but can also connect with any web service or JDBC-compliant database (as you would expect) and uses the Model-View-Controller (MVC) paradigm. For a process-based application, you define the process map first, then create a new WebMaker project, define a page (form), and connect the page to the process definition. Once that’s done, you can then drag the process variables directly onto the form to create the user interface objects. There’s a full array of on-form objects available, including AJAX partial pages, maps, charts, etc., as well as the usual data entry fields, drop-downs and buttons. Since the process parameters are all available to the form, the form can change its appearance and behavior depending on the process variables, for example, to allow a partial page group to be enabled or disabled based on the specific step in the process or the value of the process instances variables at that step. This allows a single form to be used for multiple steps in a process that require a similar but not identical look and feel, such as a data entry screen and a QA screen; alternatively, multiple forms can be defined and assigned to different steps in the same process.
HandySoft’s WebMaker is loosely coupled with BizFlow, so it can be used for any web application development, not just BPM-related applications. It does integrate natively with BizFlow, but can also connect with any web service or JDBC-compliant database (as you would expect) and uses the Model-View-Controller (MVC) paradigm. For a process-based application, you define the process map first, then create a new WebMaker project, define a page (form), and connect the page to the process definition. Once that’s done, you can then drag the process variables directly onto the form to create the user interface objects. There’s a full array of on-form objects available, including AJAX partial pages, maps, charts, etc., as well as the usual data entry fields, drop-downs and buttons. Since the process parameters are all available to the form, the form can change its appearance and behavior depending on the process variables, for example, to allow a partial page group to be enabled or disabled based on the specific step in the process or the value of the process instances variables at that step. This allows a single form to be used for multiple steps in a process that require a similar but not identical look and feel, such as a data entry screen and a QA screen; alternatively, multiple forms can be defined and assigned to different steps in the same process.